Fig. 4.
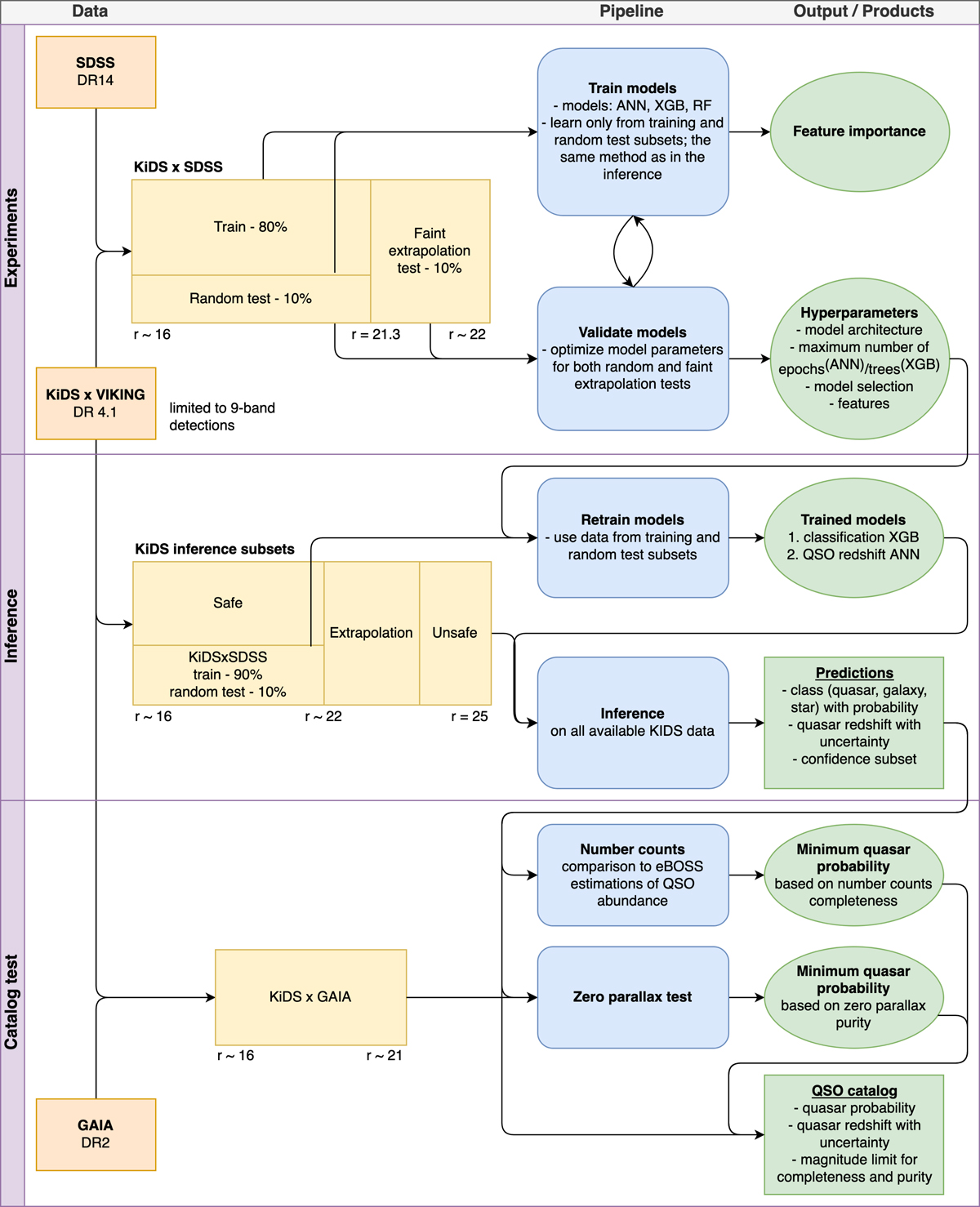
Methodology diagram. The procedure consists of three main parts: experiments as well as inference and catalog tests. The experiments are based on the cross-match between KiDS and SDSS data, and they include the repeatable process of training and evaluating ML models. The training is based only on the train and random test subsets, while the hyper-parameter tuning uses both random and faint extrapolation tests. The best hyper-parameters found are used in the inference to train new models, now on the whole range of magnitudes available in the training data. The raw predictions were then tested with number counts and Gaia parallaxes to calibrate the final catalog with probability cuts for the optimal purity-completeness trade-off.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.