Fig. A.2
Download original image
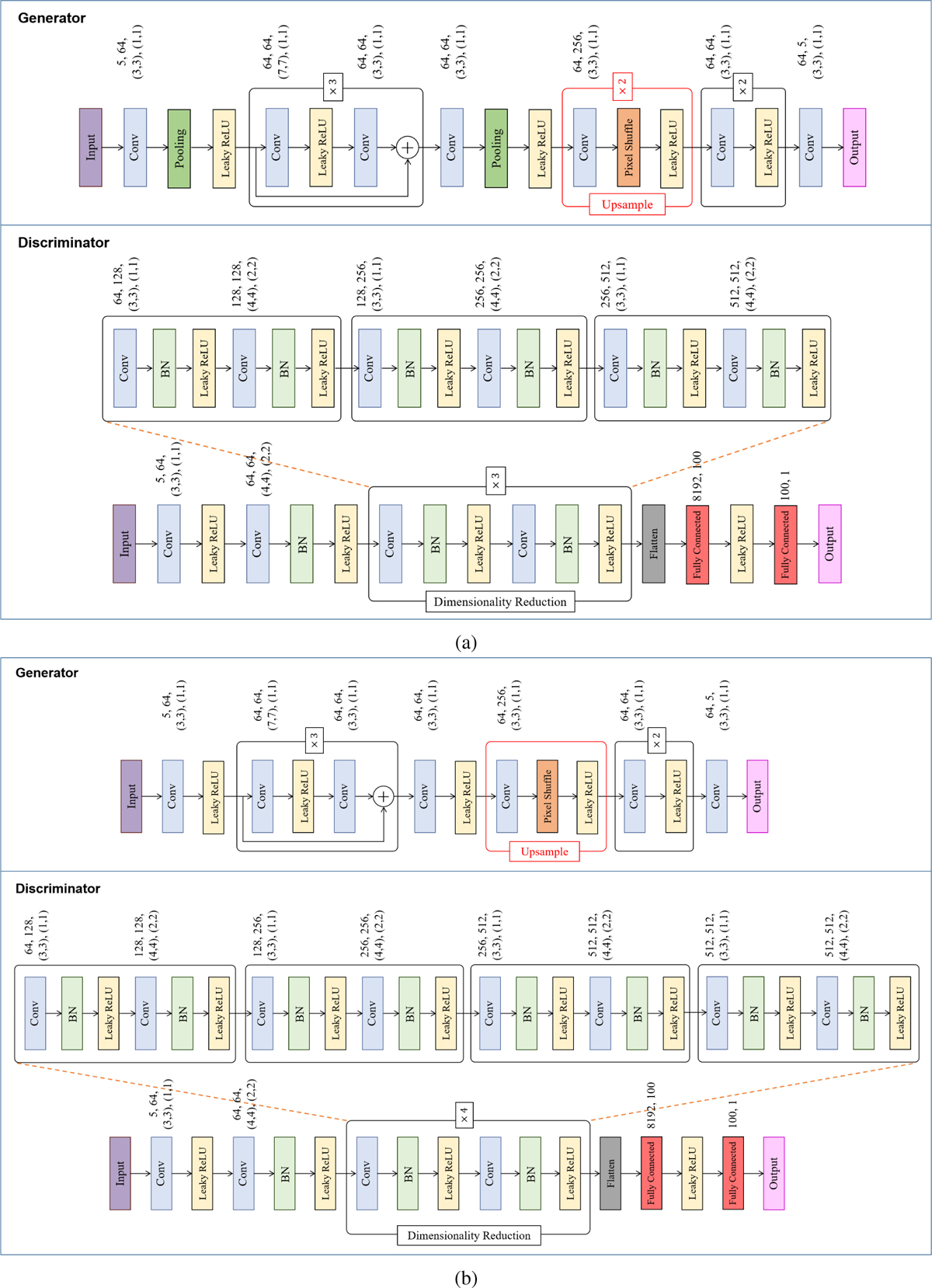
Architectures of the SRGAN for the S2S and S2C translations, illustrated in subfigures (a) and (b), respectively. The generator and discriminator architectures both mainly consist of convolutional layers and batch normalization (BN) operations. Two 2 × 2 average pooling layers for downsampling and two pixel shuffle layers for upsampling are implemented in the generator for the S2S translation, while a pixel shuffle layer is implemented for the S2C translation. There are also skip connections in the two generators. The blocks that are repeated multiple times are marked with “×N”. The Leaky ReLU activation applied in the generators and discriminators has leaky ratios of 0.01 and 0.2, respectively. Same as Fig. A.1, the numbers next to each convolutional layer refer to the number of input channels, the number of output channels, the kernel size, and the stride. The “same” padding is applied in all the convolutional layers. The stride-2 convolutional layers are implemented in the discriminators for dimensionality reduction, followed by flattening and fully connected layers. The numbers next to each fully connected layer refer to the number of input dimensions and the number of output dimensions.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.