Fig. 5
Download original image
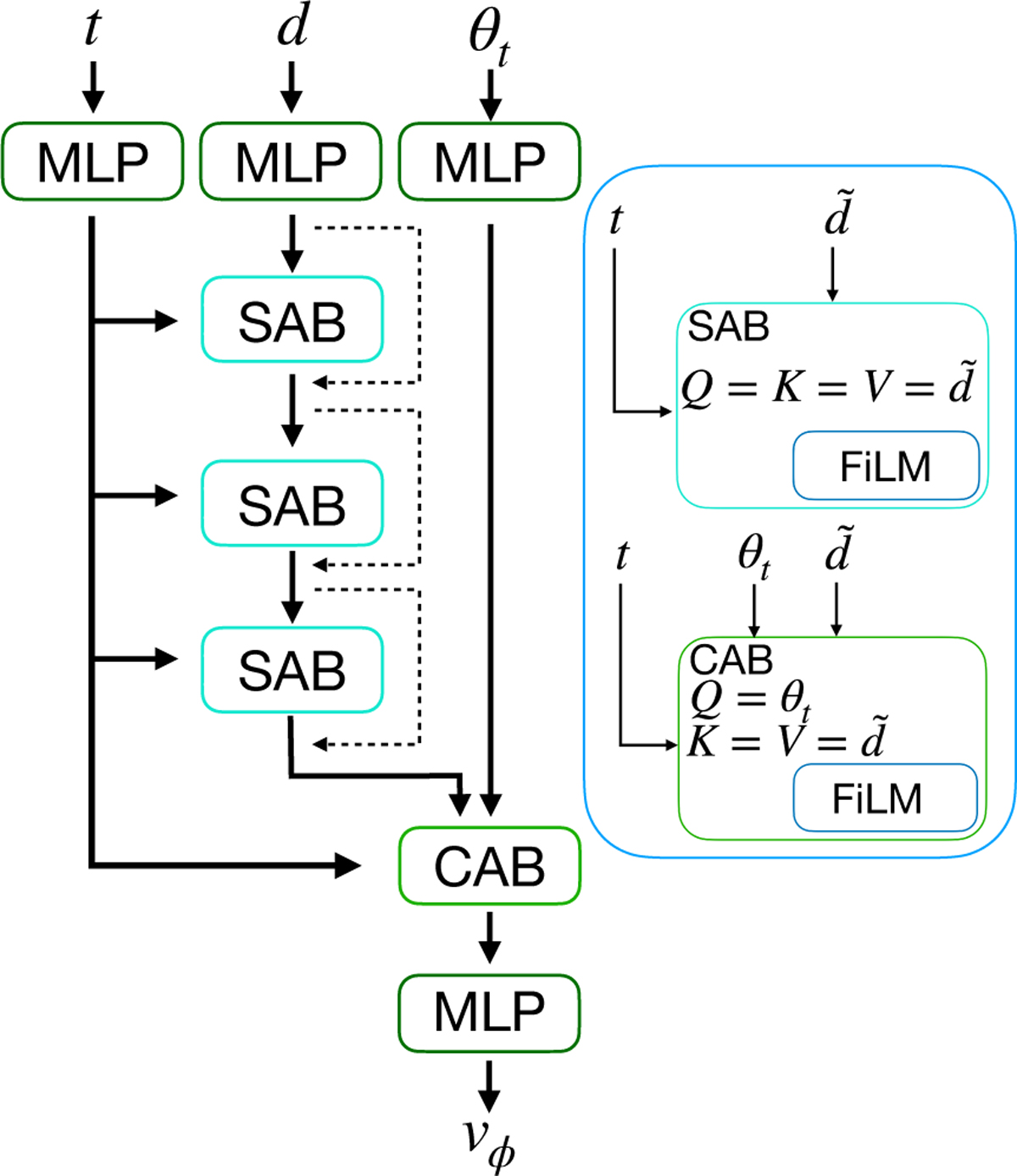
Flow matching SetTransformer. We indicate with d̃ both the observation (d) and the intermediate output of the attention blocks. To embed each of the stars in the observation (d) the parameter state θt at the ODE time t, we used a simple MLP with 128 neurons with a SiLU activation function. We then passed d̃ through three stacked SABs with a skip connection (dashed line) to encode the correlations between the particles while modulating the output of each block on t using FiLM. Then we used a CAB with a FiLM modulation to focus the attention mechanism on finding the relevant feature in d̃ to regress the parameters θ. The vector field vφ was obtained by compressing the output of the CAB through an MLP with output dimensions equal to the dimensionality of θ, in our case 13 dimensions.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.