Fig. B.1
Download original image
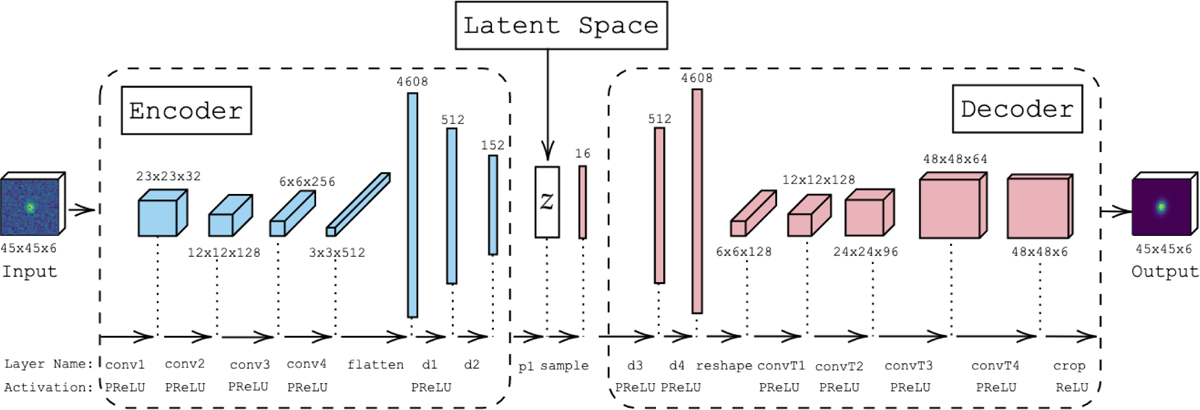
Variational autoencoder architecture. The conv1, conv2, conv3, and conv4 layers refer to the four convolutional layers of the encoder, all of which use a kernel size of 5 and a stride of 2. Following the convolutional layers are the dense layers d1 and d2 that predict the parameters of the latent space distribution. The probabilistic layer p1 uses the output of layer d2 to construct the latent space z, which is a multivariate normal distribution of 16 dimensions. Finally, the decoder takes as input a sample from the latent space distribution and applies a set of dense layers d3 and d4, followed by transposed convolutional layers (convT1, convT2, convT3, and convT4) also with kernel size 5 and stride 2; Finally, the output of convT4 is cropped to match the size of the input.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.