Fig. B.2
Download original image
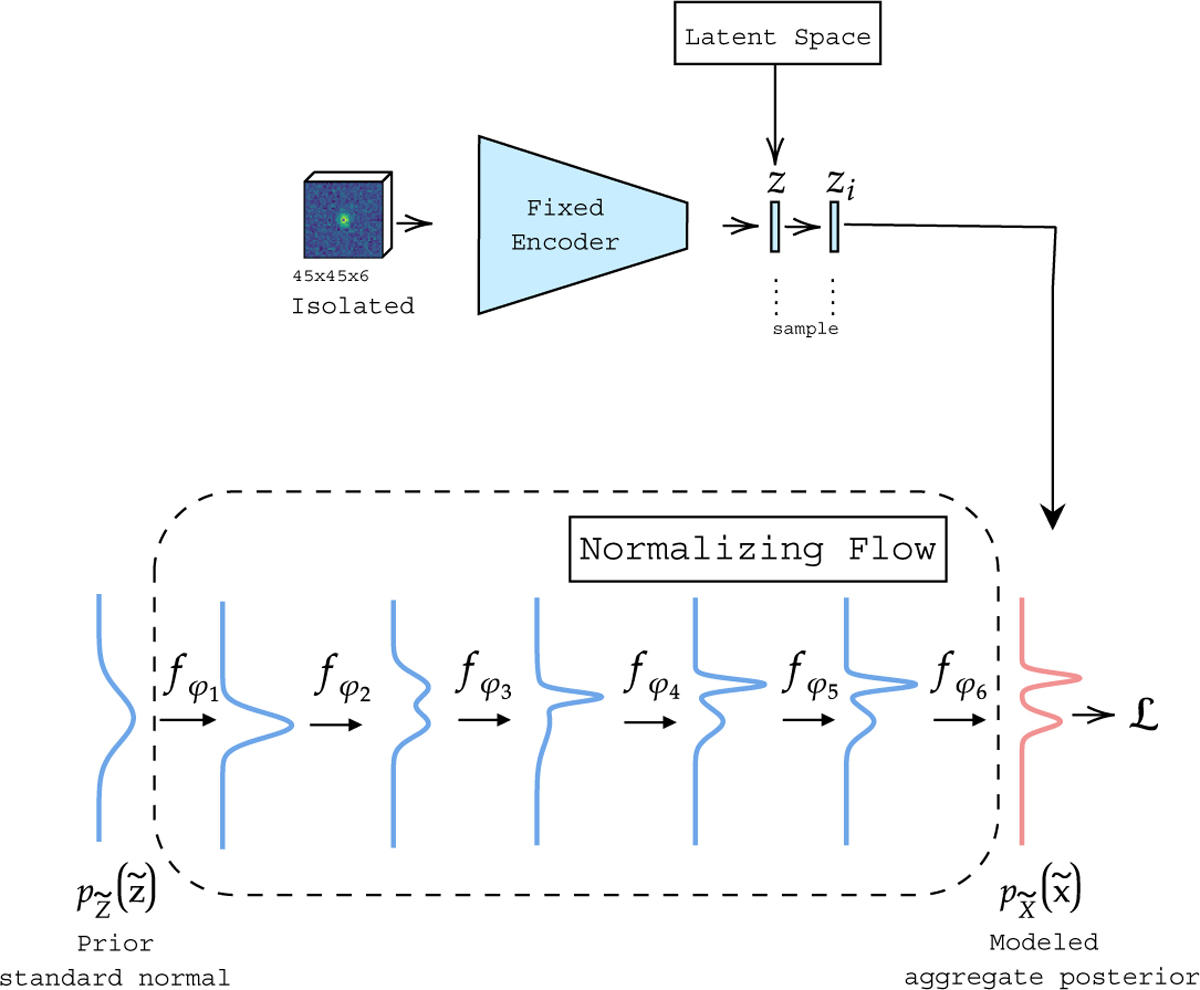
Schematic of the training of the normalizing flow. The encoder is the pre-trained network illustrated in Figure B.1 and the normalizing flow consists of 6 bijective transformations fφi where the ith transformation is parameterized by φi, which represents the weights of the MAF layer containing (32, 32) units with tanh activations followed by a permutation layer. Additionally, a batchnorm layer is added as the first layer within fφ1.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.