Fig. 5
Download original image
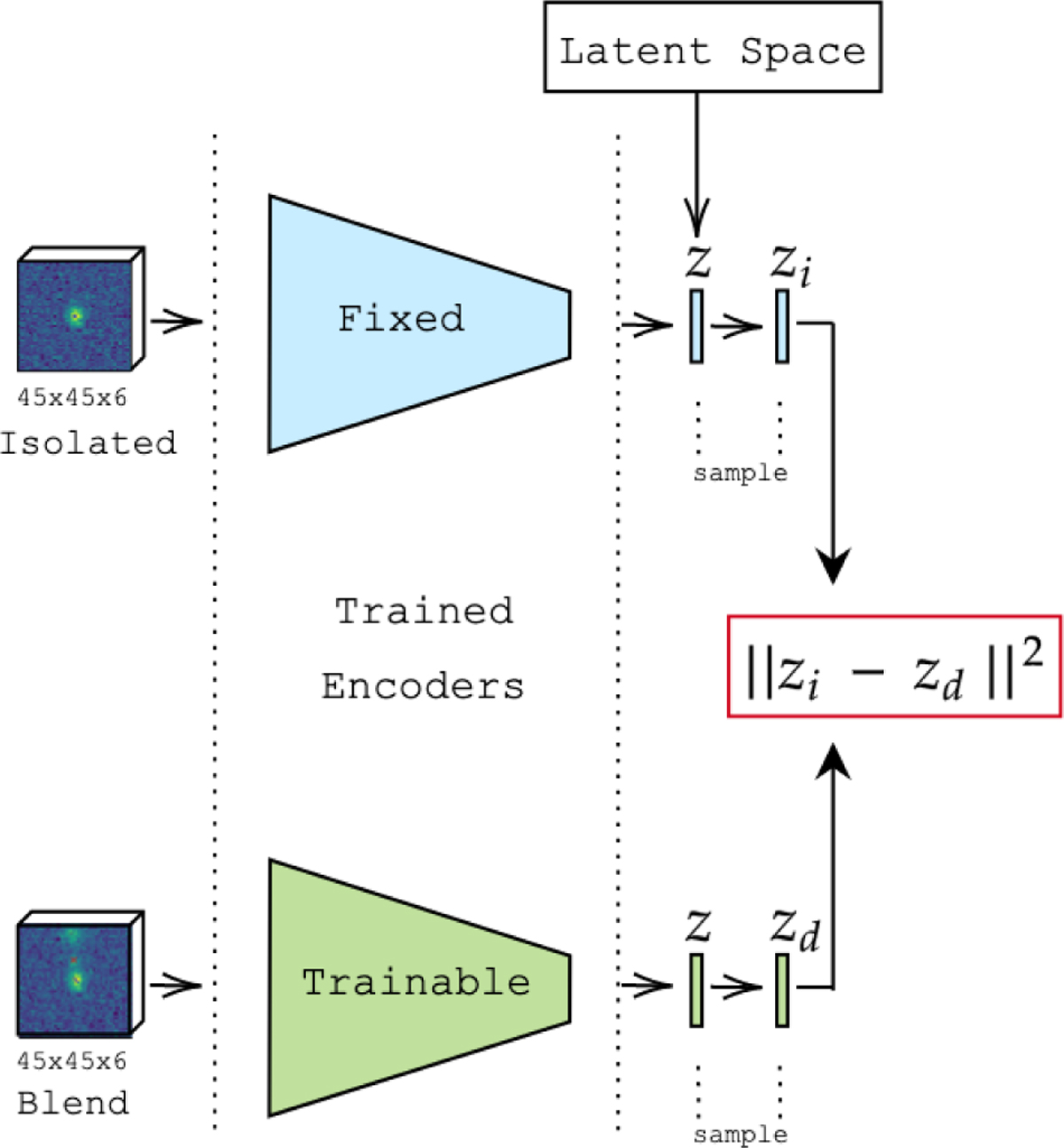
Schematic of the training of the VAE-deblender using two copies of the encoder network illustrated in Figure B.1. The trainable network learns to predict the latent space representation of the central galaxy by minimizing the Euclidian distance (marked in red) between its prediction (zd) and the representation of the isolated galaxy (zi) obtained by the fixed encoder trained as described in Appendix B.1.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.