Fig. 3
Download original image
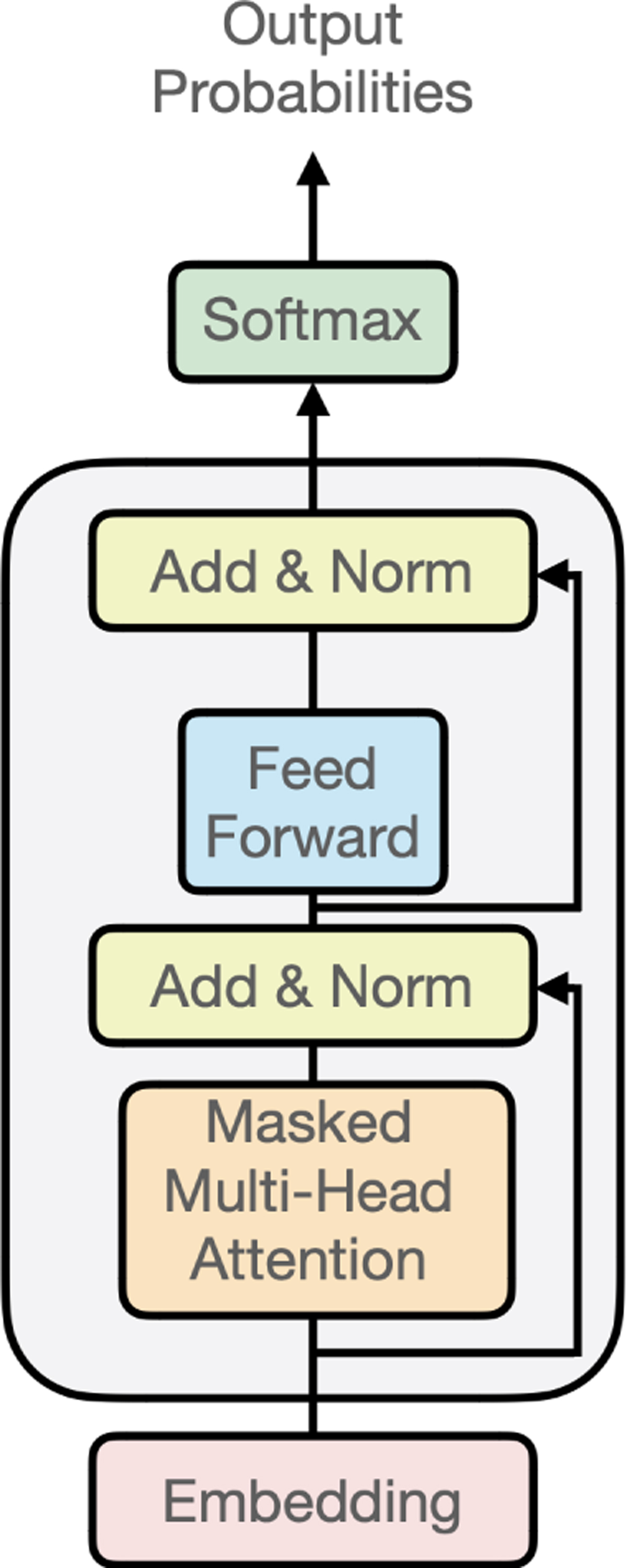
Model architecture. The model is made of one embedding layer (dimension 16 to 128), two to eight blocks (grey rectangle) and one soft-max layer that predicts the probability of each character knowing all the previous ones. Each block is made of a masked multi-head attention layer (between one and eight heads), followed by a normalisation layer, a feed-forward neural network (one hidden layer, the number of units being four times the size of the embedding size), and a second normalisation layer. The different architectures tested (number of blocks, size of the embedding layer, and number of attention heads) as well as the best obtained cross-entropy loss are indicated in Table 1.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.