| Issue |
A&A
Volume 702, October 2025
|
|
|---|---|---|
| Article Number | A215 | |
| Number of page(s) | 14 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202555585 | |
| Published online | 22 October 2025 | |
Toward mapping turbulence in the intracluster medium
IV. Using NewAthena/X-IFU and simulation-based inference to constrain turbulence
1
IRAP, Université de Toulouse, CNRS, CNES, UT3-PS, Av. du Colonel Roche 9, 31400 Toulouse, France
2
Centre National d’Etudes Spatiales, Centre spatial de Toulouse, 18 avenue Edouard Belin, 31401 Toulouse Cedex 9, France
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
20
May
2025
Accepted:
8
August
2025
Abstract
Context. The NewAthena mission planned for launch in the late 2030s will carry X-IFU, an integral field unit spectrometer that will obtain unique insights into the X-ray hot Universe through its combination of spectral and spatial capabilities. Its ability to deliver spatially resolved observations with a high spectral resolution will allow for detailed mapping of turbulent velocities in the hot gas of galaxy clusters, offering capabilities beyond those of previous missions to study their complex dynamics.
Aims. This is the fourth in a series of papers aimed at forecasting the ability to investigate turbulence in the intracluster medium through the observation of the centroid shift caused by turbulent motions of the gas. In this paper we improve on previous methods by investigating the ability of simulation-based inference (SBI) to constrain the underlying nature of velocity fluctuations through the use of standard observational diagnostics, such as the structure function.
Methods. We rely on a complex architecture of neural networks including masked autoencoders in order to model the likelihood and posterior distributions relevant to our case. We investigate its capability to retrieve the turbulence parameters on mock observations, and explore its capability to use alternative summary statistics.
Results. Our trained models are able to infer the parameters of the intracluster gas velocity power spectrum in independently simulated X-IFU observations of a galaxy cluster. We evaluated the precision of the recovery for different models. We show the necessity to use methods such as SBI to avoid an underestimation of the sources of variance by comparing the results to our previous paper. We confirm that cluster-to-cluster variations in the stochastic velocity field (i.e., sample variance) severely impact the precision of recovered turbulent features. Our results demonstrate the need for advanced modeling methods to tackle the complexity of the physical information nested within future high-resolution spectroscopic X-ray observations, such as the ones expected from X-IFU/NewAthena.
Key words: turbulence / techniques: imaging spectroscopy / galaxies: clusters: intracluster medium / X-rays: galaxies: clusters
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Galaxy clusters are the end result of the hierarchical structure assembly of matter, making them the largest gravitationally bound objects. They are permeated by the intracluster medium (ICM), which is a highly ionized plasma that accounts for 80% of their baryonic mass content. Turbulence within the ICM is believed to play an important role in dissipating the energy injected by a variety of gravitational and nongravitational processes. These processes include feedback from active galactic nuclei (AGNs) (McNamara & Nulsen 2012; Eckert et al. 2021; Voit et al. 2017), merger events and accretion (ZuHone & Su 2022; Voit 2018; Nelson et al. 2012), either with sub-halos and galaxies, other clusters, or by the continuous accretion of matter from the surrounding medium and filaments of the cosmic web. Turbulence is expected to contribute to the nonthermal pressure support of galaxy clusters and thus it needs to be accounted for when inferring the total mass of galaxy clusters from the distribution of intracluster gas (Biffi et al. 2016; Voit 2018; Pratt et al. 2019).
Studying turbulence within galaxy clusters allows one to get an insight into the mechanisms driving the dynamics of the ICM, and is a way to estimate the fraction of nonthermal support (Vazza et al. 2018; Angelinelli et al. 2020).
Previous studies in the X-ray have used surface brightness fluctuations to constrain turbulence in clusters (e.g., Schuecker et al. 2004; Churazov et al. 2012; Zhuravleva et al. 2012, 2018; Simionescu et al. 2019; Dupourqué et al. 2023, 2024b). This technique requires an assumption about the relation between density fluctuations and the underlying turbulent motions of the gas.
The ICM is an optically thin medium in the X-ray. Any movement within the gas is traced as a spectral distortion (e.g., broadening, Doppler shifts) of the emitted spectrum, and in particular the emission lines of the heavy elements (Inogamov & Sunyaev 2003). Direct observations of turbulence become possible through the study of line centroid shifts and broadening. Probing turbulent motion requires a high spectral resolution. Current imaging spectrometers (such as EPIC on board XMM-Newton or ACIS on board Chandra) enable at best 100 − 150 eV resolution, corresponding to a resolving power of R ∼ 10. Such resolving power is insufficient to capture spectral line distortions acting at a level of, for example, ∼100 km/s. Instruments relying on dispersive spectroscopy, such as grating-based spectrometers (e.g., RGS on board XMM-Newton) have a greater resolution but suffer from mixing of spatial scales (see e.g., Pinto et al. 2015; Sanders et al. 2011, for upper constraints on turbulence using RGS, with a sample of clusters). Only recently have arrays of microcalorimeters had a sufficient spectral and spatial resolution to deliver the first maps of ICM motions, with observations using SXS on board Hitomi (Hitomi Collaboration 2016; Aharonian et al. 2018) and its copy Resolve on board XRISM (XRISM Collaboration 2025c,a,b).
The NewAthena space telescope is a planned mission of the European Space Agency, to be launched in the mid-2030s. The mission is destined for the observation of the hot and energetic Universe in X-ray between 0.2 and 12 keV (Nandra et al. 2013). Relying on silicon pore optics for its mirror (Vernani et al. 2024), NewAthena will combine a high collecting area, with 1.2 m2 at 1 keV, and a spatial resolution twice that of XMM-Newton, with a point spread function (PSF) of 8–9 arcseconds half-equivalent width. NewAthena will embark with two instruments. The Wide Field Imager, using DEPFET sensors, will allow wide-field imaging at a high pixel density Müller-Seidlitz et al. (2024). The X-IFU will consist of a hexagonal array of 1504 transition edge sensors, each providing a resolution of 4 eV or less (with 3eV currently considered the goal Barret et al. 2023). The spectral and spatial resolutions of X-IFU will allow us to get an unprecedented insight into the motions of the ICM with the spatial mapping of X-ray emission line shifts and broadening. The NewAthena space telescope, and hence the X-IFU instrument, has undergone a phase of important reformulation since our previous paper, leading to a substantially different mirror and readout design. The results presented in this paper incorporate these latest updates to the X-IFU performance specifications (unless otherwise stated).
Addressing the wide and complex topic of turbulence is an observationally challenging task. A first-order approach involves constraining simplified parametric models capturing the main features of the random motions in the hot baryonic gas. In return, these models can then predict the nonthermal pressure support and the correction to hydrostatic equilibrium. It is commonly assumed that all turbulence within the cluster can be described by an isotropic velocity power spectrum. Assuming that the turbulent field can be described by a Gaussian random field, this power spectrum is parametrized by a handful of physical parameters (slope, amplitude, etc.). The parameters of this power spectrum are then the parameters to recover through observations.
The 2D structure function derived from a reconstructed (projected) velocity map is a statistical description of the velocity map. It encapsulates the amplitude of fluctuations at different scales and it is correlated with the physical parameters underlying the power spectrum of the velocity field (e.g., Zhang et al. 2024; XRISM Collaboration 2025a). The analytical prediction of the exact shape and in particular the exact error budget of the structure function for a given observation setup (i.e., binning map, emissivity model) is a highly challenging task because of the nature of this problem. In context, there is no analytical formulation for the likelihood of the 2D structure function on a binned velocity map. Traditional inference methods, such as gradient descent or Monte Carlo Markov chain sampling, require an assumption about the form of the likelihood. Accurately estimating the associated error budget requires one to account for all possible sources of variance. In particular, sample variance, or cosmic variance as coined by ZuHone et al. (2016), describes the fact that each turbulent random field is only a single finite-size realization among an infinity with the same underlying power spectrum.
In our first two papers (Clerc et al. 2019; Cucchetti et al. 2019), we focused first on analytical cases, analyzing the 2D structure function of velocity maps and its associated sources of variance and errors. With the third paper (Beaumont et al. 2024, B24 hereafter), we applied these developed capabilities of predicting accurately the structure function and its errors to the case of mock X-IFU observations. Working from an idealized observational setup, we assessed the constraints that could be put on the turbulent spectrum. We assumed the form of the likelihood to be Gaussian, with Gaussian errors on the structure function and zero covariance. Results were shown for mock observations of 19 adjacent pointings on a z = 0.1 cluster, mapping the cluster out to R500, assuming an unrealistically large total exposure time and ignoring the effect of astrophysical and instrumental backgrounds.
In this paper, we leverage simulation-based inference (SBI hereafter) through the sbi Python package (Tejero-Cantero et al. 2020) to infer the parameters of the power spectrum with X-IFU observations of a galaxy cluster. Simulation-based inference relies on a neural network, optimized for this task. The network learns the relation between the observables and the parameters used to generate them, fed with a large number of simulations giving pairs of parameters, θi, and observations, Xi. Since it is trained with simulations that include the stochasticity of random Gaussian fields, this method naturally accounts for this source of variance. The need for cumbersome and computationally heavy analytical computations is then less of a concern. We use this new method to investigate mock observations identical to our previous paper. This method has successfully been used in astrophysics (see e.g., pulsar population synthesis Graber et al. (2024), weak lensing analysis Lin et al. (2023), X-ray spectra fitting (Barret & Dupourqué 2024)) as well as for constraining turbulence from surface brightness fluctuation maps in Dupourqué et al. (2023, 2024b). In addition, if one is able to provide different observable properties arising from the same process, it is straightforward to add them to the inference with SBI. Moreover, the problem of dealing with the sample variance can be seen as an issue of marginalizing the likelihood over all possible realizations of the turbulent velocity field. Simulation-based inference is naturally suited for tackling marginalization over nuisance parameters, which further motivates its use in this problem.
The paper is organized in the following way. In Section 2 we introduce the method used for X-IFU/NewAthena mock observations. In Section 3 we introduce SBI, and the model used for training, and we compare the results with our previous paper. In Section 4 we use this new approach on the new X-IFU configuration. We look into the impact of adding astrophysical and instrumental background. We also investigate the effectiveness of adding further summary statistics of the observables for the constraining power of our SBI base method. In Section 5 we provide conclusions on this new data analysis strategy, and on our inferred capabilities to derive constraints on the turbulence of the ICM with the X-IFU instrument.
This study has been conducted with the assumption of a ΛCDM cosmology, with H0 = 70 km s−1 Mpc−1, Ωm = 0.3, and ΩΛ = 0.7. With such parameters, at a redshift of z = 0.1, 1 kiloparsec (kpc) corresponds to an angular extent of 0.54 arcseconds (arcsec), and one pixel has a projected size of 10 kpc.
All corner plots shown in this paper show the 1 and 2σ contours as shaded regions. The marginalized distributions in the diagonal show the 1σ region as shaded.
2. Simulated X-IFU/NewAthena observations
The following section introduces the tools and models used to produce realistic mock X-IFU observations. As this work relies heavily on the simulations introduced in B24, we invite the reader to refer to this paper for a full description, and provide only the essentials below.
2.1. Cluster toy model
The X-IFU field of view (FoV) and the NewAthena telescope PSF constrain the maximal and minimal spatial scales observable in a single pointing. Their values are, respectively, ∼4 arcmin and ∼9 arcsec. In this study we chose a cluster at a redshift of z = 0.1 with a physical characteristic scale of R500 = 1300 kpc, following our previous paper. This size allows us to grasp the cluster entirely within a few pointings in radius. R500 is the radius at which the mean density of the cluster is 500 times the critical density of the Universe at this redshift. At that redshift, the size of the PSF and the FoV correspond approximately to 18 kpc and 490 kpc, respectively. This allows one to grasp most of the inertial range of turbulence within this medium, which is believed to range from a few hundreds of kiloparsecs down to a few kiloparsecs or even sub-kiloparsec scales.
We assume spherical symmetry for simplicity. The density model and temperature profile models are taken from Ghirardini et al. (2019). The metallicity profile is taken from Mernier et al. (2017), and the abundances are taken from Anders & Grevesse (1989). The exact parametrization of profiles can be found in Appendix A.
Finally, the emission model is the astrophysical plasma emission code (bapecSmith et al. 2001) model in xspec (Arnaud 1996, apec v12.13.0c). This model includes the continuum, dominated by Bremsstrahlung emission, as well as all the emission lines for elements up to zinc in a optically thin and collisional plasma at equilibrium, with a thermal broadening. An absorption component (phabs model under xspec) multiplies the emission and is representative of the absorption by hydrogen along the line of sight. The hydrogen column density is fixed to a value of nH = 3 ⋅ 1020 cm−2.
Cluster properties were computed on a discrete 3D grid. For computational issues, we fixed the size of a cell in physical units to less than half of the PSF (i.e., 5 kpc). The grid extended to ±10.8 × R500 along the line of sight and ±1.4 × R500 on the plane of the sky, respectively. The cluster properties were then coupled at the level of each grid cell to the emission model through a random sampling of photons in the corresponding cell spectrum. Stacked over the whole grid, we obtained a photon list emitted by the cluster for the given exposure time. This photon list served as an input to the SIXTE simulator described in Sect. 2.4. We strictly followed the procedure by Cucchetti et al. (2018), to which we refer the reader for a detailed description.
2.2. Turbulent velocity
In order to model turbulence in the cluster, we assumed a single isotropic and homogeneous power spectrum. Our chosen parametrization follows that of ZuHone et al. (2016), Dupourqué et al. (2023), and is written as
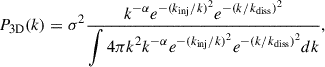 (1)
(1)
where k is the norm of the 3D wavenumber, kinj, kdiss are the inverse of the injection and dissipation scales (Linj, Ldiss), respectively, α is the slope of the cascade, and σ the norm of the spectrum, corresponding to the total dispersion of the 3D speed. The norm is set such that the 3D integral of the power spectrum gives σ2. Similarly to B24, we kept identical values for these parameters, 300 kpc for the injection scale, 10 kpc for the dissipation scale, −11/3 for the slope, and 250 km/s for the norm. This cube of turbulent speed is used as the input for the redshift of the simulated grid of emission properties within the cluster. We thus computed a 3D grid of turbulent speed used together with other physical properties to compute the cluster emission.
2.3. Background and foreground emissions
The astrophysical foreground and background emissions in our simulations are accounted for by following the model proposed by Lotti et al. (2014). There are three components, which are the unabsorbed thermal model representing the local bubble, the absorbed one for the Galactic halo, and the absorbed power law for the cosmic X-ray background (CXB). They are modeled under XSPEC as apec, phabs*apec, and phabs*powerlaw, respectively. The parametrization of these models is provided by Lotti et al. (2014). The hydrogen column density is kept at the same value as for the cluster model. We assume that these diffuse components have no spatial variation across the X-IFU FoV.
We also accounted for the instrumental background in our simulations. The SIXTE tool, described in the next section, allows one to model the instrumental background, which is set according to the X-IFU requirements of 5 × 10−3 counts/s/cm2/keV (Peille et al. 2025). The main source of instrumental background is the high-energy cosmic rays hitting the instrument in the neighborhood of the detectors, and it dominates the background budget at high energies (beyond ∼4 keV). The instrumental background has been updated to a value of 8 × 10−3 counts/s/cm2/keV during the writing of this work; however, we assessed that this change only has a negligible impact on the measurement error described in Sect. 3.1.
2.4. Instrument model and post-processing
For a complete model of the X-IFU instrument, we relied on the SIXTE simulator (Wilms et al. 2014; Dauser et al. 2019). This simulator takes as inputs instrument configuration files and a photon list, and produces a list of events for the given observation time and instrument attitude. It accounts for the entire instrument, from the mirrors to the electronics, resulting in a high-fidelity simulation of X-IFU observations. Throughout all of this paper, we use a mosaic of 19 X-IFU pointings, with 125 ks of observation for each pointing. This configuration is the same as the one presented in B24. It was chosen as a simple demonstration case of an ideal low statistical error observation. The latter is ensured by the 125 ks per pointing, a value close to the ad hoc 100 ks commonly adopted in the initial Athena’s white paper (Nandra 2013) and supporting papers (Pointecouteau et al. 2013; Ettori et al. 2013). In B24 and the present work, this configuration allowed for a mapping of the cluster up to ∼1 and ∼0.7 R500 with a FoV of 5’ and 4’ equivalent diameter of the pre and post-reformulation of the X-IFU performance parameters by ESA, respectively.
The SIXTE simulator outputs a mock event list of the X-IFU observation. The events are binned in regions on the detector array by using Voronoi binning (Cappellari & Copin 2003) to produce bins of an equal signal-to-noise ratio of 200, with this ratio defined as the square root of the total number of counts in each bin. This produces bins of ∼10 pixels at the center and ∼1000 pixels on the outskirts. A spectrum is produced in each bin and fit with the spectral model for the emission of the cluster (bapec under XSPEC), together with the model for the background (see the above section). The fitting procedure is carried over the 0.2–12 keV energy band, without priors on the free parameters: the cluster model norm, temperature, redshift (line centroid), line broadening, metallicity, and background model norm.
For each physical parameter of the fit for the cluster emission, we produce a map where we assign the best fit value in each bin. The norm, temperature, and abundance of the bapec model are recovered within ∼1% of their input values. Two parameters of the bapec are of particular interest here: firstly, the velocity, which is the Doppler shifting of the emission lines of the medium (deduced from the best fit redshift value); and secondly, the velocity broadening that results from the Doppler broadening of the emission lines of the medium. Both are quantities integrated along the line of sight. This allows for the production of velocity and broadening maps, which can then be used directly or indirectly as observable quantities to constrain the ICM’s turbulence. An example of such maps is shown in Fig. 1
 |
Fig. 1. Centroid shift (top) and line broadening (bottom) maps extracted from a mock observation of 19 X-IFU pointings simulated with SIXTE, centered on a galaxy cluster with a turbulent ICM. The R500/2 size of the cluster is shown as a circle on the maps. |
For each observation simulation, we also produce a set of maps, called input maps, which are the emission-weighted projections of the input quantities of the simulation. These input maps are binned similarly to the output maps and are therefore directly comparable. The corresponding input maps to those shown in Fig. 1 are shown in Fig. 2.
 |
Fig. 2. Similar figure as Fig. 1, showing expected values (inputs maps, see text) of centroid shift and line broadening free of any instrumental noise. |
2.5. Structure function
One way to summarize the velocity or broadening information is the 2D structure function. Assuming a binned map of the quantity, C, the 2D structure function of this map wascomputed as
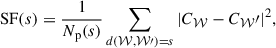 (2)
(2)
where s is a given separation, 𝒲 is a given bin, d(𝒲, 𝒲′) is the distance between the centers of two bins, C𝒲 is the value of the observed quantity in the given bin, and Np(s) is the number of pairs of bins that satisfy this separation distance. It is closely related to the 2D power spectrum as it gives out the average power contained in the fluctuations of the mapped quantity at different scales.
The structure function depends on the spatial binning that is used. For the same velocity field projected through emission weighting, different binning schemes will (marginally) affect the shape and normalization of the structure function, and more specifically its average value and variance. As is illustrated in B24, folding the shape and surface of the Voronoi cells in the theoretical computation of the structure function is nontrivial. However, we properly account for the chosen binning scheme by reproducing it in the modeling process of the structure function. Throughout our study, we keep the spatial binning defined for the mock reference observation constant for all simulations generated to train the neural network in our SBI process (see next section). In this way, the binning scheme is properly accounted for in the inference process.
2.6. Reference realization
Throughout this paper, we present results on a single realization of a turbulent field within a cluster. This was simulated with SIXTE, and chosen as a reference. Figure 3 shows the structure function of this reference realization. The predicted distribution of structure functions for the true input parameters are also displayed. This realization was chosen as reference because its structure function is close to the average of the predicted distribution. The following results were reproduced with two mock observations of two realizations, with structure functions lying above and below the average. These are presented in Appendix B.
 |
Fig. 3. Centroid shift (top) and line broadening (bottom) structure functions extracted from an observation of 19 X-IFU pointings simulated with SIXTE, with the predicted structure function distributions as percentile envelopes. |
3. Simulation-based inference
3.1. Streamlined model of turbulent field observations
Simulation-based inference relies on training what is called a neural density estimator, a form of neural network relying on normalizing flows. It is optimized for reproducing the distribution of observables from the distribution of input parameters of a training sample. In order to train each density estimator, it is necessary to provide a large amount of simulated observations, on the order of 105. To achieve that, we could not rely on the SIXTE simulator as it is too computationally heavy to allow the production of such a number of mock observations. We thus implemented a practical model of turbulent field observations and the reconstruction of structure functions.
For each mock observation generated by SIXTE, we have to generate a training set for the neural network to train on, because the observable quantities depend on the features of the observation, such as the binning and the measurement error, which may vary from one observation to the other. The training set is composed of an ensemble of parameters and associated observations {θi, Xi}. For each realization of parameters, θi, we generated a Gaussian random field from the corresponding power spectrum, 𝒫3D(θi), on a fixed grid. We used emission weighting to project the grid on the X-IFU pixel array, and convolved this projection with the instrument PSF. Then, we averaged the velocity obtained in each bin, following the binning scheme of the SIXTE mock observation, again weighting by the emission, to produce a centroid shift map. Doing the same with a weighted standard deviation of the velocity allowed us to produce a line broadening map. Finally, the measurement error of the centroid shift was added as a Gaussian random variable to the value of each bin. The observable quantity of interest, Xi, was then either the structure functions of the output maps or some other summary statistic that we could compute from the maps. In order to produce such a large amount of training samples, we relied on the JAX (Frostig et al. 2019) library, allowing the computation to be run on GPU, which drastically decreased the computation time, with only 5 hours required to produce 500 000 simulations1.
The transverse size of the velocity cubes is driven by the size of the X-IFU mosaic. In order to make a comparison with our previous paper, we generated mosaics of 19 pointings, corresponding to a size of 232 X-IFU pixels in the dimension perpendicular to the line of sight. Along the line of sight, the size of the velocity cube is driven by the need to sample the cluster out to ∼2.5 R500. The size of the cubes is then 232 × 232 × 1160 pixels. Because of memory limitations on GPU, the sampling is kept to one point per X-IFU pixel. This sets the smallest scale in the simulated velocity cubes to exactly the adopted dissipation scale (i.e., 10 kpc).
3.2. Algorithm and priors
We require a fast drawing of samples from the posterior distributions in order to alleviate the need to leverage a complete sampler such as MCMC or NUTS for each posterior distribution. The SNPE_C (that we call SNPE in the remainder of the paper) model (Greenberg et al. 2019) allows just that. In this algorithm, the trained network learns the mapping between the distribution of the input parameters and the distribution of the observable quantities. An independent SNPE density estimator was trained for each choice of summary statistic (see Sect. 4). For each trained estimator, we generated 500 000 training samples, with the parameters sampled from uniform distributions such that α ∼ 𝒰(0.1, 8.8), log10(Linj[kpc]) ∼ 𝒰(2, 3) and σ ∼ 𝒰(50, 500)[km/s]. We do not expect the constraints on the slope to be tight and left a large prior. The upper edge at 8.8 prevents slopes that are too steep and that cause numerical issues in the power spectrum and Gaussian random field generation.
3.3. Modeling the measurement error
To estimate the measurement error that is made for the reference realization, we simulated ten different draws of the photons input to SIXTE. Each mock observation requires the generation and processing of 19 X-IFU pointings through the SIXTE simulator. For computational aspects, we had to limit ourselves to ten draws, though this limited number only provides a crude estimate of the measurement error. However, a more general method of estimating the measurement error that does not involve generating multiple draws for each single realization of a velocity field would be preferred for generalization purposes.
These ten observations were processed with the same method, which produces a set of output maps each for the different parameters. By comparing the output maps to the ideal input maps, we can evaluate the measurement error for each parameter. This is shown in Figure 4, in which the difference between the input and output map is plotted as a function of the distance to the center for all ten observations. This plot allows us to outline the radial dependence of the measurement error for both the centroid shift and the line broadening. In our model, we then incorporate the measurement error on the centroid shift, ΔCmes, and line broadening as such:
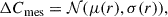 (3)
(3)
 |
Fig. 4. Scatter plots of the binned differences between the output and input maps of centroid shift and broadening, as a function of the distance from the center of the cluster. The different radial bins used for modeling this difference are plotted as vertical lines. The distribution in each radial bin is shown as a violin plot, with the mean shown as a black line and 1σ values shown as blue lines. |
with μ(r) and σ(r) taking the nearest value of the mean and standard deviation in each radial bin shown in Fig. 4. We proceeded in the same fashion for the line broadening, except that it is drawn from a truncated normal distribution, with bounds {0; +∞}.
One might be compelled to compare this measurement error with the errors presented on the broadening measurement with the Resolve instrument on board XRISM. For example, in XRISM Collaboration (2025c), errors on the centroid shift and broadening were reported to be on the order of 1–10 km/s. The error that is reported from the XRISM measurements represents the estimated error made in fitting the centroid shift and broadening from a model to the observed spectrum. It also accounts for the calibration of the instrument.
The error that we report is not estimated from the spectral fitting procedure. Our measurement error is estimated from the spread of the difference between 1) the emission weighted projection of the spectral properties of each point in the cluster, and 2) the observed output maps. Because the output maps are obtained with spectral fitting, the measurement error naturally includes the uncertainties in the fitting of the spectra. The measurement error thus represents the error that is made in representing the output maps by the input model. The observed measurement error obtained in Figure 4 is then naturally explained. In larger spatial bins, far from the cluster center, the mixing of different spatial regions leads to more variation in the observed centroid shift and line broadening from the spectral fitting when compared to an emission weighted value. In the central bins, the observed centroid shift, which is the emission weighted average of the velocity cube, is driven by the peaked emission profile, i.e., a limited spatial region in the center. Because the centroid shift is sensitive to the representativeness of the projection with respect to the value obtained from spectral fitting, a bias can be observed in the innermost annulus. This bias is observed as an underestimation of the measured value compared to the input expectation. The broadening is not as sensitive to the projection effects and shows no similar bias.
The measurement error that we report here is derived from the comparison between an idealized, known input and ten simulated observations. If this estimation is fit for our purpose, as it stands it does not allow us to draw any conclusions for actual measurements such as those provided by XRISM. A systematic study would be needed in order to assess any projection effects and biases that could arise from the complex spectral fitting process. Such an investigation is outside the scope of the present paper.
3.4. Validation of the trained density estimators
In order to validate the trained neural density estimators, we used mock observations, each produced with the model used for the generation of training data, where each observation represents a single realization of the velocity field. The input parameters were set to the values mentioned in Sect. 2, used for the SIXTE simulation. For each mock observation, we retrieved the posterior distribution, and computed its mean and standard deviation. Figure 5 shows the distributions of the retrieved parameters, summarized as a single mean and standard deviation for each mock observation. This is shown here for the density estimator that was trained on the structure functions of the centroid shift and line broadening. On average, the parameters are well retrieved, despite some offset on the power spectrum normalization parameter, σ, where the averages of the samples retrieved from SBI are biased on average toward larger values. Nevertheless, when we account for the spread of the distributions by computing the residuals, they are centered on zero. In addition to that, the reduced χ2 is close to 1, with a value of 1.22 in the worst case. These elements show the good reconstruction of the input parameters and validate the ability of our methodology to retrieve the input parameters with the structure function. This analysis was carried out for each trained model, showing similar, or better, results. In particular, the addition of other summary statistics shows even better reconstruction.
 |
Fig. 5. Retrieved average value and standard deviation of the marginalized posterior distribution of each parameter, obtained for 100 observations of 100 velocity field realizations generated with the same input parameters. The density estimator used SNPE with default parameters and was trained using the structure function of the centroid shift and the broadening. |
In addition to validating the reconstruction of the parameters, we used this new framework to compare posterior distributions obtained from the observations presented in the previous paper Beaumont et al. (2024). The result is shown in Figure 6, where we compare the results obtained on the 19 pointings 125 ks observation mosaic using the X-IFU specification before reformulation. In concordance with our previous paper, we used the same prior for the slope of the power spectrum, α, and deliberately fixed the dissipation scale to its input value. We used the SNLE model for convenience, as it gives access to the likelihood and the addition of a prior on the parameters is thus straightforward. We also show the posterior distribution of the SNLE density estimator used without any prior other than what was used for the training set (as is described above). The posterior distributions obtained from SBI are larger than those obtained from the analytical method. This underlines that the approximations made in B24, in particular, neglecting the covariance of the structure function bins, are likely to have produced an underestimation of the errors, resulting in narrower distributions for the inferred parameters. However, the same degeneracy between the parameters can still be observed, giving us confidence that the general statistics of the problem captured by the trained neural networks follows the same underlying physics as the analytical description.
 |
Fig. 6. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the observation used in Beaumont et al. (2024). A Gaussian prior has been used for the slope, α, and is plotted with the black curve. The input values of the observation are plotted with dotted black lines. |
4. Results
4.1. Using the structure functions
In Fig. 7 we show the posterior distribution obtained with training our inference network with the structure functions. We compare the result of using uniquely the centroid shift structure function, on one side, with that of using the centroid shift together with the broadening structure functions, on the other side. The two posterior distributions obtained are comparable in shape and extent. This is a result of structure function of the broadening being dominated by the measurement error. This can be seen in the difference between the input and output broadening maps in Figures 2 and 1, where the structure seen in the input map cannot be distinguished in the output map because of the fluctuation in each spatial region.
 |
Fig. 7. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization. The blue posterior shows the result for the density estimator trained with both the centroid shift and broadening structure functions (C-SF and S-SF). The yellow posterior shows the result of the density estimator trained only with the centroid shift structure function. The input values of the simulation are plotted with dotted black lines. |
4.2. With additional summary statistics
Simulation-based inference allows for the addition of summary statistics in a straightforward manner. It allows us to use basic summary statistics in addition to the structure function, which is already a good description of the spatial structure of the observed maps, and hence of the structure of the ICM velocity field. If we write Ci, the value of the centroid shift in the bin, i, of the map, and Bi, the value of the broadening, then the statistics we used can be written as 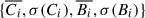 , corresponding to the mean and standard deviation of the binned values obtained in each map. The resulting posterior distribution is shown in Fig. 8. The high correlation between the average value of the broadening vector and the normalization of the power spectrum, σ, is captured well in the tight constraint obtained on the latter.
, corresponding to the mean and standard deviation of the binned values obtained in each map. The resulting posterior distribution is shown in Fig. 8. The high correlation between the average value of the broadening vector and the normalization of the power spectrum, σ, is captured well in the tight constraint obtained on the latter.
 |
Fig. 8. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization with different summary statistics. The input values are plotted with dotted black lines. The blue posterior was obtained with SNPE trained uniquely on the structure functions. The green posterior was obtained with SNPE trained on the structure functions together with additional statistics of the output maps. The red posterior was obtained with SNPE trained on the raw output maps with an embedding network. |
In addition, we tested the use of an embedding neural network on the “raw” data, i.e., on the binned values of the output maps, represented as vectors. In other words, instead of computing the structure function from the output maps, we trained a neural network to extract significant features directly from the binned maps. This neural network was made available by the sbi package and was trained together with the neural density estimator. For its architecture, we chose a fully connected network2 as it is the most relevant one to capture the covariances between the different bins of the data. The architecture was chosen as follows: the input layer has dimension N, with N the size of the input vectors, while the output layer has dimension 16 as it is the power of two closest to the size of the structure function (in our case 20 points), allowing for a summary of the vectors in a few prominent features. We chose to have four layers, as a compromise between exceeding the minimum layers (input + output) and adding more layers, which increased the computation time during training. Changing these parameters did not result in any particular improvement in the performance of the network. The training of the embedding network was done together with the training of the neural density estimator. The resulting posterior distribution after sampling from the density estimator on the reference realization is given in Fig. 8. It is comparable to the posterior obtained with SNLE trained on the structure functions and additional statistics. In particular, the embedding network also allowed the extraction of a better constraint on σ compared to using only the structure functions. The embedding network is therefore unable to guide our intuition toward additional summary statistics that could improve the inference, and only achieves at best similar constraints to those obtained from the density estimator trained with the structure function and statistics.
To complement the validation presented in Sect. 3.4, we used the posterior predictive check. It consists of running the model on parameter samples drawn from the posterior distribution, and comparing the output distribution with the observable used for the inference. For this check, we used 1000 samples drawn from the posterior distribution. In Fig. 9, we show the result of the posterior predictive check for the model “SNPE SF + stats” with the structure function. In Fig. 10 we show the result with the additional statistics used. The distributions obtained from the posterior predictive check show a good recovery of the properties of the reference realization. The medians of the predicted distributions are close to the reference observation properties. The non-Gaussian shape of the distributions is explained by two facts. Firstly the posterior distribution of the parameters is not a multivariate Gaussian, and secondly the mapping between the space of posterior parameters and observed properties is not straightforward, so there is no reason for the distribution of the predictive posterior check to be perfectly Gaussian.
 |
Fig. 9. Posterior predictive check for the model SNPE trained with the structure function and additional statistics, evaluated on the reference realization. It shows the predicted distribution of the structure functions of the centroid shift and line broadening distributions as envelopes, with parameters sampled from the posterior distribution. The reference realization is plotted in orange and is the same as Fig. 3. |
 |
Fig. 10. Posterior predictive check for the model SNPE trained with the structure function and additional statistics, evaluated on the reference realization. It shows the predicted distribution of averages and standard deviations of the binned values of the centroid shift and broadening. The median value of each distribution is plotted as a dotted black line. The reference realization is plotted in orange. |
4.3. Summary
In Fig. 11, we summarized the posterior distributions obtained for each model with its average value and standard deviation. None of the models are able to put a constraint on α better than approximately ±1, showing the difficulty in retrieving this parameter from such observations. The precision on the injection scale, Linj, is approximately −50, +100 kpc; however, for this particular realization, the retrieved injection scale is biased toward values lower than the true input. This order of magnitude for the precision of the injection scale would allow different turbulence driving mechanisms (AGN feedback, sloshing, structure assembly) to be distinguished between. The norm of the power spectrum, σ, is the parameter that is best retrieved, with a constraint of ±5 km/s with the SNPE trained on the structure functions with additional statistics. This error connects directly to the precision of the estimated nonthermal pressure support. The offsets between these average values and the true input values is explained by the cosmic variance, as is shown in Fig. 5, in which any particular realization can exhibit properties that lead the inference to obtain parameters that are offset from the true values.
 |
Fig. 11. Summary plot of the average values and ±1σ errors of marginalized distributions of each parameter for different models, obtained on the reference realization. The true input parameters are plotted as a vertical dotted line. The depicted errors include the full budget of the inference uncertainty including sample variance and measurement errors. |
5. Discussion
5.1. Limitations of the model hypotheses
The toy model used for simulating the galaxy cluster considered in this study is an approximation, which assumes spherical symmetry with no departure from the ideal thermodynamical profiles. A realistic simulation would need to account for such effects and their statistics across a galaxy cluster population. Moreover, the parameters of the turbulent field are expected to vary within individual galaxy clusters (Dupourqué et al. 2024b; Eckert et al. 2019). Then, modeling the turbulent field as a single homogeneous and isotropic field with a single set of turbulent parameters is an approximation that would need to be refined to capture the complex dynamics and substructures present in galaxy clusters. This is likely to considerably increase the complexity of the reconstruction of turbulence power spectrum parameters in a single cluster.
In the present paper, we used xspec for fitting the spectra in the different spatial regions. In order to facilitate the fitting procedure, we binned the data in spatial regions of an equal signal-to-noise ratio of 200, using Voronoi binning. Using Bayesian methods for fitting (such as Buchner et al. 2014; Dupourqué et al. 2024a; Barret & Dupourqué 2024) would allow us to greatly reduce the size of the spatial regions, with no need to rely on such a high signal-to-noise ratio, and would allow us to make use of the uncertainty in the inferred spectral parameters. Leveraging surrogate models such as SUSHI (Lascar et al. 2024) could also allow us to retrieve the spatial spectral properties of the emission to a higher degree of spatial precision, without sacrificing the resolution. These methods may be investigated in a future paper, and should be noted as existing alternatives to the current method.
In the present study, extended work was required to ensure that the model used for producing the training data was comparable with the outputs of the SIXTE simulations. In particular, the measurement error is fine-tuned to correspond to a particular realization, which has two shortcomings. Firstly, this measurement error represents the error with respect to a “true” known input, which is only possible in simulations such as ours. Secondly, it requires one to generate a training set for SBI for each realization that serves as a reference. Ideally, one would have a training set that is valid for any realization of any velocity cube. In order to achieve that, one would reproduce the result shown in Fig. 4 for different velocity cubes simulated within a cluster observed with X-IFU through SIXTE. Then, the statistics of the measurement error could be generalized for all velocity cubes.
5.2. Impact of background
The impact of the astrophysical background has been assessed to be negligible for the measurement of turbulence for the toy model cluster simulated in the present work. It should be noted that the level of the astrophysical background is low compared to the instrumental background. The SIXTE simulator allows a flagging of the events that are sampled from the background. By excluding these events from the generation of spectra and producing observed centroid shift and broadening maps for the reference realization, we are able to reproduce the observation of the reference realization in the absence of background. The resulting structure functions are shown in Fig. 12. This shows that the background has a negligible effect on the retrieved structure functions of the centroid shift and line broadening. The obtained posterior distribution with and without background are shown in Fig. 13, and are identical. However, we only simulated a uniform diffuse background, neglecting the presence of any point-like source in the FoV. Indeed, a more complete approach would be to sample AGNs from a population, include them in the observation, mask all those that are resolved, and treat the unresolved component as a diffuse background (see e.g., Cucchetti et al. 2019; Castellani et al. 2024). Nevertheless, the main differences to our approach would be twofold. Firstly, masked sources would appear in the mosaic of pointings, which would have only a little impact on the observable properties of turbulence. Masking point sources only reduces the signal-to-noise by reducing the total area from which the structure function is computed. Secondly, the sources that might have not been properly masked would show as additional residual fluctuations in the CXB.
 |
Fig. 12. Structure functions of the centroid shift (top) and broadening (bottom) maps, produced for a reference observation. The orange curve shows the observation including background, the purple curve shows the observation with the background excluded from the modeling. |
 |
Fig. 13. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization. The blue posterior shows the result of the density estimator evaluated on the realization that included background. The orange posterior shows the result of the density estimator evaluated on the realization which included no background. The input values of the realization are plotted with dotted black lines. |
5.3. Sample variance
Our analysis demonstrates the full potential of SBI-based methods for doing inference on problems where the likelihood is either ill defined, difficult to express analytically, or costly to evaluate numerically. In the context of evaluating turbulence in galaxy clusters, the structure function of the maps of the centroid shift and broadening, as computed in our analysis, is subject to a high level of sample variance. That is, a single set of turbulent parameters can give rise to a wide range of observed velocity fields and associated structure functions, due to the fact that the underlying turbulent field is stochastic and acting at scales comparable to that of the cluster itself. This was already outlined in Beaumont et al. (2024), and is emphasized again in our present paper. The analytical description of the contribution of cosmic variance is a complex task, which can lead to an underestimation of the full error budget despite careful accounting due to necessary approximations, in particular, neglecting the covariance of the structure function bins to make the computation tractable. The posterior retrieved by sampling the analytical likelihood is much narrower than the posterior obtained from using SBI, showing how SBI fully encapsulates the total variance of the structure function, resulting in wider inferred distributions.
In this paper, we only presented results for the “reference realization”, which was picked as its structure function lies close to the average predicted structure functions for the set of input parameters, in order to facilitate the interpretation of the results. To provide a more complete view of the results of inference on different realizations, in Appendix B we show the posterior distributions obtained with the same set of models on two different realizations for which the structure function lies, respectively, higher (on average, the centroid shift SF is 1.9σ above the mean predicted centroid shift SF, see Fig. B.1, left panel) and lower (on average, the centroid shift SF is 0.7σ below the mean predicted centroid shift SF, see Fig. B.1, right panel). This is in line with the results shown in Fig. 5, which shows that the high level of sample variance causes a large spread in the retrieved distributions with respect to the true input values. This further emphasizes the importance of accounting for the impact of the sample variance when retrieving turbulence parameters. This effect could be mitigated by averaging observations of several targets, considering each of them as independent observations, i.e., realizations, of the same stochastic physical process.
5.4. Comparison to existing work
Besides our previous work, another feasibility study of X-IFU abilities to measure turbulence in galaxy clusters has been conducted by Roncarelli et al. (2018, R18 hereafter). The authors used a Coma-like hydrodynamical simulation of a galaxy cluster at z = 0.1 including physically implemented turbulence. They simulated a single X-IFU pointing at the cluster center for an exposure of ∼2 Ms, allowing them to measure the structure function for different Mach numbers of the parent hydro-simulation, at low separations and with low statistical errors. The higher statistics due to their exposure time over a single pointing demonstrated the ultimate capability of X-IFU, such as mapping physical properties at the instrument pixel level. In contrast, our 125 ks exposure time per pointing provides a much more realistic view of expected pointings with X-IFU, but at the expense of the statistical precision. R18’s preliminary work, however, was performed with an early instrumental configuration of NewAthena/X-IFU, whereas our current study used the latest performance parameters for NewAthena/X-IFU. As was acknowledged in R18, a single pointing limits the range of accessible scales needed to fully characterize the turbulent cascade. Moreover they also did not account for the stochastic nature of the turbulence and the induced sample variance, whereas we demonstrate in this study (Sect. 5.3) and throughout our series of papers the key impact on the total error budget when measuring turbulent velocities. Properly accounting for this error component will be instrumental for our actual ability to extract and interpret the role of ICM turbulence in the formation and the evolution of the galaxy cluster population. The work of Zhang et al. (2024) must also be mentioned in investigating the capabilities of the Line Emission Mapper (LEM) proposed to NASA as a high-resolution integral field unit focused on low-energy observations. In particular, they are able to show its ability to measure the injection scale from a 1 Ms simulated observation of a hydrodynamical simulation, by using the second-order structure function of the velocity field. A key development in this study is a new spectral model enabling Gaussian-distributed emission measures while generating velocity-broadened lines. It thus partially addresses those problematic projection effects along the line of sight.
On the side of observations, the recent measurements from the Resolve instrument on board XRISM are paving the way for direct measurements of gas motions in galaxy clusters. The reported nonthermal pressure supports derived from the observed spectral lines shifts and broadening are on the order of ∼1 − 4%, suggesting lower levels of turbulence than are expected from numerical simulations (XRISM Collaboration 2025c,a,b). Although Resolve has an exquisite spectral resolution (better than 5 eV) and is obtaining transformational measurements, the spatial mixing induced by the PSF (∼1 arcmin full width at half maximum), the limited number of pixels paving the FoV (35 active pixels over 3 × 3 arcmin2) and the relatively low effective area of its telescope (Porter et al. 2024) limit XRISM’s ability to map spectral features or cover larger scales, and allow only access to nearby clusters. As a consequence, this also restricts the current constraints produced on structure functions to a few separations, leading to an inherent very high sample variance (XRISM Collaboration 2025c). However, these measurements pave the way for future observation with Athena/X-IFU as illustrated in the present work. Results from XRISM will drive future approaches. For instance, if low levels of turbulence were to be confirmed over a larger sample of galaxy clusters, deeper feasibility studies with X-IFU would need to account for it. To that end, we would need to devise the best observing and analysis strategies to extract line centroid shift and broadening to further fathom the role of turbulence in galaxy clusters.
6. Conclusions
In this paper, we have investigated the use of SBI for the retrieval of turbulent power spectrum parameters from X-ray observations of galaxy clusters with the X-IFU instrument on board the NewAthena space observatory. We followed the framework introduced in the previous installment of this series of papers, with the simulation of a mosaic of 19 X-IFU pointings, updated to the current X-IFU instrument configuration. We can summarize our work with the following points:
-
We performed end-to-end simulations of an observation of a z = 0.1 galaxy cluster with a mosaic of 19 × 125 ks pointings of the X-IFU instrument, using a physically motivated thermodynamical toy model and underlying turbulent velocity field.
-
We developed a model for generating observed centroid shift and line broadening maps rapidly, and used this model for generating a large amount of training samples. We used these samples to train the SNPE model as implemented in the sbi package, which is a neural network trained to map the correspondence between distributions of observable properties and the parameters used for the generation of these observables. This method naturally encompasses all sources of variance, and in particular the sample variance arising from the stochastic nature of the turbulent velocity field. Because the injection scale of turbulence we modeled is on the order of the typical radius of the emissivity field, the sample variance has a notable impact on the inference of the turbulent of parameters, which needs to beaccounted for.
-
We showed that the trained networks were able to retrieve the turbulent parameters of the underlying field with reasonable accuracy (see Fig. 5). In particular, we were able to compare the posterior distribution issued from this method to the one issued from sampling the analytical likelihood, as was done in Beaumont et al. (2024). The posterior distribution obtained with SBI is much larger (see Fig. 6), as it accounts for the full error budget including the sample variance inherent to the physical nature of turbulence, whereas, in the analytical model, it is only partially captured, leading to underestimatederrors.
-
We conducted inference by using the structure function as a summary statistic of the centroid shift and broadening maps, and we also explored the use of additional summary statistics. Notably, the use of the structure functions jointly with the average and standard deviation of the binned values within the maps has proven to be the most effective in constraining the norm of the power spectrum. We explored the use of a fully connected neural network to automatically learn relevant summary statistics from the maps. It showed a similar performance to using the structure functions with the averages and standard deviations (see Fig. 8).
In a subsequent study, we shall investigate observation strategies with X-IFU, in trying to maximize the scientific output for a given total exposure. Overcoming sample variance is likely to be the most challenging aspect. This could be achieved through the observation of a sample of targets, as joining the observations of N clusters should reduce the error on each parameter by a factor of 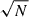 . Such a task will be a major endeavor for the X-IFU instrument. Finally, we might investigate the joint utilization of X-IFU and wide field imager (WFI), leveraging both direct measurements of turbulence as well as surface brightness fluctuations seen by WFI.
. Such a task will be a major endeavor for the X-IFU instrument. Finally, we might investigate the joint utilization of X-IFU and wide field imager (WFI), leveraging both direct measurements of turbulence as well as surface brightness fluctuations seen by WFI.
On an NVIDIA Volta V100 GPU.
One of the architectures available in the sbi package, the other architectures being best adapted for extracting features out of images or out of sequential data such as time series.
Acknowledgments
AM, SD, EP, FP and NC acknowledge the support of CNRS/INSU and CNES. AM thanks F. Mernier and A. Mahesh for their help and comments. This work was granted access to the HPC resources of CALMIP supercomputing center under the allocation 2016-P22052. The following python packages have been used throughout this work : astropy (Astropy Collaboration 2013, 2018, 2022), chainconsumer (Hinton 2016), cmasher (van der Velden 2020), jax (Frostig et al. 2019), matplotlib (Hunter 2007) and sbi (Tejero-Cantero et al. 2020).
References
- Aharonian, F., Akamatsu, H., Akimoto, F., et al. 2018, PASJ, 70, 1 [Google Scholar]
- Anders, E., & Grevesse, N. 1989, Geochim. Cosmochim. Acta, 53, 197 [Google Scholar]
- Angelinelli, M., Vazza, F., Giocoli, C., et al. 2020, MNRAS, 495, 864 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, K. A. 1996, in Astronomical Data Analysis Software and Systems V, eds. G. H. Jacoby, & J. Barnes, ASP Conf. Ser., 101, 17 [NASA ADS] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Barret, D., & Dupourqué, S. 2024, A&A, 686, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barret, D., Albouys, V., Herder, J.-W., d, et al. 2023, Exp. Astron., 55, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Beaumont, S., Molin, A., Clerc, N., et al. 2024, A&A, 686, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Biffi, V., Borgani, S., Murante, G., et al. 2016, ApJ, 827, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J., Georgakakis, A., Nandra, K., et al. 2014, A&A, 564, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cappellari, M., & Copin, Y. 2003, MNRAS, 342, 345 [Google Scholar]
- Castellani, F., Clerc, N., Pointecouteau, E., et al. 2024, A&A, 682, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Churazov, E., Vikhlinin, A., Zhuravleva, I., et al. 2012, MNRAS, 421, 1123 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Cucchetti, E., Pointecouteau, E., & Peille, P. 2019, A&A, 629, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cucchetti, E., Pointecouteau, E., Peille, P., et al. 2018, A&A, 620, A173 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cucchetti, E., Clerc, N., Pointecouteau, E., Peille, P., & Pajot, F. 2019, A&A, 629, A144 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dupourqué, S., Clerc, N., Pointecouteau, E., et al. 2023, A&A, 673, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dupourqué, S., Barret, D., Diez, C. M., Guillot, S., & Quintin, E. 2024a, A&A, 690, A317 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dupourqué, S., Clerc, N., Pointecouteau, E., et al. 2024b, A&A, 687, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eckert, D., Gaspari, M., Gastaldello, F., Le Brun, A. M. C., & O’Sullivan, E. 2021, Universe, 7, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Eckert, D., Ghirardini, V., Ettori, S., et al. 2019, A&A, 621, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ettori, S., Pratt, G. W., de Plaa, J., et al. 2013, The Hot and Energetic Universe: The Astrophysics of Galaxy Groups and Clusters [Google Scholar]
- Frostig, R., Johnson, M. J., & Leary, C. 2019, SysML Conference 2018 [Google Scholar]
- Ghirardini, V., Eckert, D., Ettori, S., et al. 2019, A&A, 621, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Graber, V., Ronchi, M., Pardo-Araujo, C., & Rea, N. 2024, ApJ, 968, 16 [CrossRef] [Google Scholar]
- Greenberg, D., Nonnenmacher, M., & Macke, J. 2019, Proceedings of the 36th International Conference on Machine Learning (PMLR), 2404 [Google Scholar]
- Hinton, S. R. 2016, JOSS, 1, 00045 [NASA ADS] [CrossRef] [Google Scholar]
- Hitomi Collaboration (Aharonian, F., et al.) 2016, Nature, 535, 117 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Inogamov, N. A., & Sunyaev, R. A. 2003, Astron. Lett., 29, 791 [NASA ADS] [CrossRef] [Google Scholar]
- Lascar, J., Bobin, J., & Acero, F. 2024, A&A, 686, A259 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, K., Wietersheim-Kramsta, M., Joachimi, B., & Feeney, S. 2023, MNRAS, 524, 6167 [NASA ADS] [CrossRef] [Google Scholar]
- Lotti, S., Cea, D., Macculi, C., et al. 2014, A&A, 569, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McNamara, B. R., & Nulsen, P. E. J. 2012, New J. Phys., 14, 055023 [NASA ADS] [CrossRef] [Google Scholar]
- Mernier, F., De Plaa, J., Kaastra, J. S., et al. 2017, A&A, 603, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Müller-Seidlitz, J., Andritschke, R., Emberger, V., et al. 2024, in Space Telescopes and Instrumentation 2024: Ultraviolet to Gamma Ray, eds. J.-W. A. den Herder, S. Nikzad, & K. Nakazawa, International Society for Optics and Photonics (SPIE), 13093, 130930T [Google Scholar]
- Nandra, K. 2013, Athena White Paper [Google Scholar]
- Nandra, K., Barret, D., Barcons, X., et al. 2013, ArXiv e-prints [arXiv:1306.2307] [Google Scholar]
- Nelson, K., Rudd, D. H., Shaw, L., & Nagai, D. 2012, ApJ, 751, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Peille, P., Barret, D., Cucchetti, E., et al. 2025, Exp. Astron., 59, 18 [Google Scholar]
- Pinto, C., Sanders, J. S., Werner, N., et al. 2015, A&A, 575, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pointecouteau, E., Reiprich, T. H., Adami, C., et al. 2013, ArXiv e-prints [arXiv:1306.2319] [Google Scholar]
- Porter, F. S., Kilbourne, C. A., Chiao, M., et al. 2024, in Space Telescopes and Instrumentation 2024: Ultraviolet to Gamma Ray, eds. J.-W. A. den Herder, S. Nikzad, & K. Nakazawa, International Society for Optics and Photonics (SPIE), 13093, 130931K [Google Scholar]
- Pratt, G. W., Arnaud, M., Biviano, A., et al. 2019, Space Sci. Rev., 215, 25 [Google Scholar]
- Roncarelli, M., Gaspari, M., Ettori, S., et al. 2018, A&A, 618, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanders, J. S., Fabian, A. C., & Smith, R. K. 2011, MNRAS, 410, 1797 [NASA ADS] [Google Scholar]
- Schuecker, P., Finoguenov, A., Miniati, F., Böhringer, H., & Briel, U. G. 2004, A&A, 426, 387 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Simionescu, A., ZuHone, J., Zhuravleva, I., et al. 2019, Space Sci. Rev., 215 [Google Scholar]
- Smith, R. K., Brickhouse, N. S., Liedahl, D. A., & Raymond, J. C. 2001, ApJ, 556, L91 [Google Scholar]
- Tejero-Cantero, A., Boelts, J., Deistler, M., et al. 2020, J. Open Source Softw., 5, 2505 [NASA ADS] [CrossRef] [Google Scholar]
- van der Velden, E. 2020, J. Open Source Softw., 5, 2004 [Google Scholar]
- Vazza, F., Angelinelli, M., Jones, T. W., et al. 2018, MNRAS, 481, L120 [NASA ADS] [CrossRef] [Google Scholar]
- Vernani, D., Valsecchi, G., Marioni, F., et al. 2024, in Space Telescopes and Instrumentation 2024: Ultraviolet to Gamma Ray, eds. J.-W. A. den Herder, S. Nikzad, & K. Nakazawa, International Society for Optics and Photonics (SPIE), 13093, 130934W [Google Scholar]
- Voit, G. M. 2018, ApJ, 868, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Voit, G. M., Meece, G., Li, Y., et al. 2017, ApJ, 845, 80 [Google Scholar]
- Wilms, J., Brand, T., Barret, D., et al. 2014, in Space Telescopes and Instrumentation 2014: Ultraviolet to Gamma Ray, SPIE, 9144, 1775 [Google Scholar]
- XRISM Collaboration (Audard, M., et al.) 2025a, ApJ, 985, L20 [Google Scholar]
- XRISM Collaboration (Audard, M., et al.) 2025b, ApJ, 982, L5 [Google Scholar]
- XRISM Collaboration (Audard, M., et al.) 2025c, Nature, 638, 365 [Google Scholar]
- Zhang, C., Zhuravleva, I., Markevitch, M., et al. 2024, MNRAS, 530, 4234 [NASA ADS] [CrossRef] [Google Scholar]
- Zhuravleva, I., Churazov, E., Kravtsov, A., & Sunyaev, R. 2012, MNRAS, 422, 2712 [NASA ADS] [CrossRef] [Google Scholar]
- Zhuravleva, I., Allen, S. W., Mantz, A., & Werner, N. 2018, ApJ, 865, 53 [CrossRef] [Google Scholar]
- ZuHone, J., & Su, Y. 2022, Handbook of X-ray and Gamma-ray Astrophysics (Springer Nature Singapore), 1 [Google Scholar]
- ZuHone, J. A., Miller, E. D., Simionescu, A., & Bautz, M. W. 2016, ApJ, 821, 6 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A:
We summarize the cluster density and temperature profiles as follows. The profiles were taken from the joint analysis of eight non-cool core clusters presented in the XMM-Newton Cluster Outskirts Project (X-COP Ghirardini et al. 2019). The temperature profile is described as:
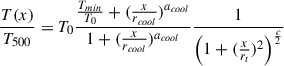 (A.1)
(A.1)
where x = r/R500, and {T0, Tmin, rcoolacool, rt, c/2} are six temperature, radius and shape parameters, with T500 following a parametrization on the redshift, see Ghirardini et al. (2019). The values of these parameters are provided in Table A.1.
Values of the parameters used for the temperature and emission models, obtained from the best-fit of these profiles to observed clusters (Ghirardini et al. 2019).
The density profile is described as:
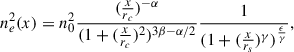 (A.2)
(A.2)
with x = r/R500 and {γ, n0, rc, rs, α, β, ϵ} are six shape parameters, with values provided in Table A.1. We set an arbitrary upper limit on the electron density value at 0.05 cm−3, in order to avoid divergence as the center of the cluster.
The metallicity profile follows the shape derived by Mernier et al. (2017), which was obtained from the study of a sample of 44 nearby cool-core clusters, groups, and ellipticals observed with XMM-Newton:
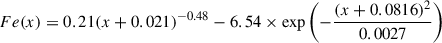 (A.3)
(A.3)
with x = r/R500. The solar abundances are fixed to those of Anders & Grevesse (1989).
Appendix B:
 |
Fig. B.1. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on two realizations with different summary statistics. The input values of two realization are plotted with black dotted lines. (Top) Results for ’Obs. high’ (Bottom) results for ’Obs. low’. |
 |
Fig. B.2. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization with different summary statistics. The input values of the realization are plotted with black dotted lines. The blue posterior was obtained with SNPE trained uniquely on the structure functions. The green posterior was obtained with SNPE trained on the structure functions together with additional statistics of the output maps. The red posterior was obtained with SNPE trained on the raw output vectors with an embedding network. |
In Fig. B.1 we show the results of the models presented in the Results section of the paper on two mock realizations of a mosaic of 19 X-IFU pointings obtained by with SIXTE, ’Real. high’ and ’Real. low’, the structures functions of which are shown in Fig. B.2.
All Tables
Values of the parameters used for the temperature and emission models, obtained from the best-fit of these profiles to observed clusters (Ghirardini et al. 2019).
All Figures
|
Fig. 1. Centroid shift (top) and line broadening (bottom) maps extracted from a mock observation of 19 X-IFU pointings simulated with SIXTE, centered on a galaxy cluster with a turbulent ICM. The R500/2 size of the cluster is shown as a circle on the maps. |
| In the text | |
|
Fig. 2. Similar figure as Fig. 1, showing expected values (inputs maps, see text) of centroid shift and line broadening free of any instrumental noise. |
| In the text | |
|
Fig. 3. Centroid shift (top) and line broadening (bottom) structure functions extracted from an observation of 19 X-IFU pointings simulated with SIXTE, with the predicted structure function distributions as percentile envelopes. |
| In the text | |
|
Fig. 4. Scatter plots of the binned differences between the output and input maps of centroid shift and broadening, as a function of the distance from the center of the cluster. The different radial bins used for modeling this difference are plotted as vertical lines. The distribution in each radial bin is shown as a violin plot, with the mean shown as a black line and 1σ values shown as blue lines. |
| In the text | |
|
Fig. 5. Retrieved average value and standard deviation of the marginalized posterior distribution of each parameter, obtained for 100 observations of 100 velocity field realizations generated with the same input parameters. The density estimator used SNPE with default parameters and was trained using the structure function of the centroid shift and the broadening. |
| In the text | |
|
Fig. 6. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the observation used in Beaumont et al. (2024). A Gaussian prior has been used for the slope, α, and is plotted with the black curve. The input values of the observation are plotted with dotted black lines. |
| In the text | |
|
Fig. 7. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization. The blue posterior shows the result for the density estimator trained with both the centroid shift and broadening structure functions (C-SF and S-SF). The yellow posterior shows the result of the density estimator trained only with the centroid shift structure function. The input values of the simulation are plotted with dotted black lines. |
| In the text | |
|
Fig. 8. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization with different summary statistics. The input values are plotted with dotted black lines. The blue posterior was obtained with SNPE trained uniquely on the structure functions. The green posterior was obtained with SNPE trained on the structure functions together with additional statistics of the output maps. The red posterior was obtained with SNPE trained on the raw output maps with an embedding network. |
| In the text | |
|
Fig. 9. Posterior predictive check for the model SNPE trained with the structure function and additional statistics, evaluated on the reference realization. It shows the predicted distribution of the structure functions of the centroid shift and line broadening distributions as envelopes, with parameters sampled from the posterior distribution. The reference realization is plotted in orange and is the same as Fig. 3. |
| In the text | |
|
Fig. 10. Posterior predictive check for the model SNPE trained with the structure function and additional statistics, evaluated on the reference realization. It shows the predicted distribution of averages and standard deviations of the binned values of the centroid shift and broadening. The median value of each distribution is plotted as a dotted black line. The reference realization is plotted in orange. |
| In the text | |
|
Fig. 11. Summary plot of the average values and ±1σ errors of marginalized distributions of each parameter for different models, obtained on the reference realization. The true input parameters are plotted as a vertical dotted line. The depicted errors include the full budget of the inference uncertainty including sample variance and measurement errors. |
| In the text | |
|
Fig. 12. Structure functions of the centroid shift (top) and broadening (bottom) maps, produced for a reference observation. The orange curve shows the observation including background, the purple curve shows the observation with the background excluded from the modeling. |
| In the text | |
|
Fig. 13. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization. The blue posterior shows the result of the density estimator evaluated on the realization that included background. The orange posterior shows the result of the density estimator evaluated on the realization which included no background. The input values of the realization are plotted with dotted black lines. |
| In the text | |
|
Fig. B.1. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on two realizations with different summary statistics. The input values of two realization are plotted with black dotted lines. (Top) Results for ’Obs. high’ (Bottom) results for ’Obs. low’. |
| In the text | |
|
Fig. B.2. Posterior distributions of the parameters of the turbulent power spectrum estimated with SBI on the reference realization with different summary statistics. The input values of the realization are plotted with black dotted lines. The blue posterior was obtained with SNPE trained uniquely on the structure functions. The green posterior was obtained with SNPE trained on the structure functions together with additional statistics of the output maps. The red posterior was obtained with SNPE trained on the raw output vectors with an embedding network. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.