Open Access
Table B.1
Hyper-parameter configurations.
| Parameter | Value |
|---|---|
| Architecture Parameters | |
| Encoder convolutional layers size | (128, 256, 512) |
| Encoder convolutional filters size | (5, 11, 21) |
| Encoder fully connected layers size | (128, 64, 32) |
| Decoder layers size | (32, 64, 128) |
| Training Parameters | |
| Optimizer | Adam (Kingma 2014) |
| Maximum learning rate | 10−3 |
| Learning rate scheduler | 1Cycle (Smith & Topin 2019) |
| Training steps | 4000 |
| Batch size | 512 |
| Weighting Parameters (Eq. (7)) | |
| β | 5 × 10−3 |
| λ | 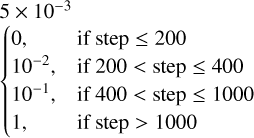 |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.