| Issue |
A&A
Volume 704, December 2025
|
|
|---|---|---|
| Article Number | A279 | |
| Number of page(s) | 16 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/202555376 | |
| Published online | 22 December 2025 | |
Toward model-free stellar chemical abundances
Potential applications in the search for chemically peculiar stars in large spectroscopic surveys
1
Instituto de Estudios Astrofísicos, Facultad de Ingeniería y Ciencias, Universidad Diego Portales,
Av. Ejercito 441,
Santiago,
Chile
2
Inria Chile Research Center,
Av. Apoquindo 2827, piso 12, Las Condes,
Santiago,
Chile
3
INAF – Osservatorio Astrofisico di Torino,
Strada Osservatorio 20,
I-10025
Pino Torinese (TO),
Italy
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
2
May
2025
Accepted:
11
November
2025
Abstract
Context. Chemical abundance determinations from stellar spectra are challenged by observational noise, limitations in stellar models, and departures from simplifying assumptions. While traditional and supervised machine learning methods have made remarkable progress in estimating atmospheric parameters and chemical compositions within existing physical models, these factors still constrain our ability to fully exploit the vast datasets provided by modern spectroscopic surveys.
Aims. We aim to develop a self-supervised, disentangled representation learning framework that extracts chemically meaningful features directly from spectra, without relying on externally imposed label catalogs.
Methods. We built a variational autoencoder-based representation learning model with a physics-inspired structure comprising multiple decoders, each of which focuses on spectral regions dominated by a particular element, enforcing that each latent dimension maps to a single abundance. To evaluate the potential application of our framework, we trained and validated the model on low-resolution, low signal-to-noise synthetic spectra focusing on [Fe/H],[C/Fe], and [α/Fe]. We then demonstrate how the trained model can be used to flag stars as chemically enhanced or depleted in these abundances based on their position within the latent distribution.
Results. Our model successfully learns a representation of spectra whose axes correlate tightly with the target abundances (r= 0.92 ± 0.01 for [Fe/H], r=0.92 ± 0.01 for [C/Fe], and r=0.82 ± 0.02 for [α/Fe]). The disentangled representations provide a robust means to distinguish stars based on their chemical properties, offering an efficient and scalable solution for large spectroscopic surveys.
Key words: stars: abundances / stars: atmospheres / stars: chemically peculiar
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Extracting reliable chemical information from stellar spectra has long been a central challenge in astrophysics, especially given the vast datasets produced by modern spectroscopic surveys. Large-scale programs–including the Gaia-ESO Survey (Gilmore et al. 2022; Randich et al. 2022), the Galactic Archaeology with HERMES (GALAH) Survey (De Silva et al. 2015; Buder et al. 2021), the Dark Energy Spectroscopic Instrument (DESI), the Sloan Digital Sky Survey (SDSS; Smee et al. 2013; Kollmeier et al. 2019), the Apache Point Observatory Galactic Evolution Experiment (APOGEE, Majewski et al. 2017), and the Baryon Oscillation Spectroscopic Survey (BOSS; Dawson et al. 2013)–provide enormous numbers of stellar spectra that enable comprehensive studies of stellar populations and Galactic evolution. However, analyzing these datasets is challenging due to imperfect theoretical models, observational uncertainties, and the difficulty of ensuring consistent abundance determinations across different surveys (Jofré et al. 2019).
In this era, supervised machine learning methods–such as The Cannon (Ness et al. 2015), AstroNN (Leung & Bovy 2019), and Payne (Ting et al. 2019)-have become widely used for chemical analysis, with many chemical abundance catalogs now produced using neural networks trained on synthetic or observed spectral grids. Yet, these methods still depend heavily on high-quality training data, typically derived from traditional template-fitting techniques. Their performance is sensitive to the quality, coverage, and representativeness of the training sets, and they often struggle with rare or chemically peculiar stars (e.g., Goodfellow et al. 2016; Li et al. 2025). Also, astrophysical correlations in the training data can lead to biases, where inferred abundances may reflect indirect associations with stellar parameters rather than the true chemical properties (e.g., Ting 2024). More fundamentally, because the training labels themselves are based on theoretical models rather than direct observational ground truth, these approaches remain model-driven at their core, incorporating assumptions about the underlying physics of stellar atmospheres indirectly through their training datasets. As a result, neither theoretical models nor, consequently, supervised learning models fully capture the information contained in stellar spectra.
Addressing these challenges requires novel approaches that mitigate biases and enhance generalization across diverse stellar populations. Unsupervised learning techniques offer a promising avenue, as they do not depend on extensive labeled training samples and can uncover hidden structures in spectral data on their own. For example, Autoencoders (AEs, Goodfellow et al. 2016) are deep neural networks trained to reconstruct their input, a self-supervised strategy (see, e.g., Gui et al. 2023) that enables them to compress high-dimensional spectra into compact latent spaces. This reconstruction objective can allow the model to capture intrinsic chemical variations while mitigating the impact of noise (e.g., Fang et al. 2021; Carbajal et al. 2021).
In this work, we propose a self-supervised deep learning framework for representation learning in stellar spectra designed to learn low-dimensional representations where latent variables exhibit explicit relationships with chemical abundances. Consequently, this structured representation is physically interpretable and facilitates downstream tasks such as chemical abundance estimation.
The Milky Way’s stellar halo provides an ideal environment for applying these unsupervised methods. As a relic of past accretion events, the halo preserves the chemical imprints of disrupted dwarf galaxies and clusters (e.g., Venn et al. 2004; De Lucia & Helmi 2008; Belokurov & Kravtsov 2024). While their spatial coherence is eventually erased, chemical abundances remain intact, offering a unique proxy to reconstruct the accretion history of the Milky Way. For example, dwarf galaxies, with their slow star formation and small gravitational potentials, are typically metal-poor and exhibit a lower ratio of α-elements to iron (e.g., Hudson et al. 2015; Johnson et al. 2023). In the metal-poor environment of the halo, a significant fraction of stars exhibit enhanced carbon abundances (Yong et al. 2013; Placco et al. 2014; Yoon et al. 2018). These high carbon abundances at low metallicities suggest enrichment from multiple astrophysical sources, such as massive stars, binary interactions, and various types of supernovae (Beers & Christlieb 2005). Among these, some show carbon enhancement without signs of s-process enrichment or binarity (Norris et al. 2013; Hansen et al. 2016; Arentsen et al. 2019). These stars likely inherited their carbon from the early interstellar medium enriched by the first generations of stars (Spite et al. 2013; Sharma et al. 2018; Hartwig & Yoshida 2019).
Overall, studying the chemical signatures of resolved stars in the halo can be used for tracing the first generations of stars, understanding the role of accreted systems in shaping the Milky Way, and reconstructing the Galaxy’s nucleosynthetic and accretion history (Frebel et al. 2007; Frebel & Norris 2015; Helmi 2020). We demonstrate the effectiveness of our approach on low-resolution synthetic stellar spectra, exploring its potential for identifying chemically enhanced or depleted stars–specifically α-poor, metal-poor (α PMP), and carbon-enhanced metal-poor (CEMP) stars–without requiring explicit labels. By applying deep representation learning in a self-supervised setting, our approach offers a scalable, data-driven tool for exploring the chemical diversity of the Milky Way.
A variety of approaches–including template-based, hybrid, and machine learning methods–have been developed to extract chemical information from low-resolution spectra. For example, Lee et al. (2011, 2013) developed techniques to determine carbon abundances in metal-poor stars using SDSS spectra, while Xiang et al. (2019) estimated α-element abundances from LAMOST spectra. Similarly, Marsteller et al. (2009) employed automated spectral synthesis to infer metallicities and carbon abundances, and Bu et al. (2016) used an Extreme Learning Machine (Huang et al. 2006) to estimate α-element abundances. Although these methods demonstrate the potential of low-resolution spectroscopic data for chemical abundance analysis, they rely on predetermined templates or labeled training sets, which may limit their applicability to rare or unusual spectral types.
Beyond traditional and supervised approaches, representation learning techniques have gained traction in spectral analysis. Autoencoders and variational autoencoders (VAEs) have been used as a preprocessing step to extract compact spectral representations, facilitating parameter estimation and transfer learning across different observational datasets (Yang & Li 2015; Mas-Buitrago et al. 2024; Leung et al. 2023; Buck & Schwarz 2024). An advancement in this field is disentangled representation learning (DRL, Bengio et al. 2013), which aims to separate independent generative factors in the data. In a disentangled representation, each latent variable is sensitive to changes in a single underlying generative factor of the data, while being invariant to changes in the others. This property improves explainability by ensuring that learned features align with meaningful generative factors. Additionally, it improves generalization by isolating task-relevant features from irrelevant variations in the data (Dittadi et al. 2020; Mu et al. 2021; Zhang et al. 2022; Li et al. 2022; Yoo et al. 2023).
While DRL has been extensively explored in domains such as computer vision (e.g., Wang et al. 2023), robotics (e.g., Emukpere et al. 2025), and natural language processing (e.g., Carvalho et al. 2022), its principles naturally extend to astrophysical spectra, which arise from a combination of independent physical properties–such as temperature, gravity, and individual elemental abundances–each contributing distinct features to the observed signal. de Mijolla et al. (2021), Santoveña et al. (2024) successfully applied this approach to learn spectral representations that isolate variations in chemical abundances in simulated stellar spectra, while Manteiga et al. (2025) demonstrated it on data from the Gaia Radial Velocity Spectrograph (Recio-Blanco et al. 2023).
In this work, we developed a self-supervised deep learning framework for learning disentangled chemical representations from stellar spectra. Our approach was based on a VAE to encode high-dimensional spectra into a structured, low-dimensional latent space where each latent feature was associated with a specific chemical element and captures variations in its abundance. We chose a VAE for its probabilistic framework, which regularizes the latent space and promotes smoother and more regular representations (Kingma & Welling 2013).
Because unsupervised disentanglement is impossible without additional constraints, as multiple latent representations can explain the data equally well (Locatello et al. 2018), we incorporated physically motivated inductive biases to obtain meaningful, element-specific representations. In this context, inductive biases act as a bridge between physical interpretability and model freedom: they constrain the solution space just enough to make the learned factors physically meaningful, while avoiding the need for complete and explicit supervision.
Our approach can therefore be viewed as a step toward model-free abundance inference: the model learns directly from spectra rather than relying on synthetic atmosphere models or externally fitted labels, while remaining consistent with basic spectroscopic principles. It yields latent variables that are physically interpretable, regularized, and sensitive to abundancedriven spectral variations and provides reconstruction residuals that act as indicators of deviations from the learned chemical manifold.
With these properties, the model can serve as a tool for guiding further spectroscopic analysis with varying amounts of labeled data, such as chemical abundance estimation and anomaly detection in large-scale surveys. In this first study, we specifically focus on learning disentangled representations of three chemically relevant dimensions – metallicity, carbon, and α-element abundances – from synthetic spectra and show that these representations have the potential to uncover chemically enhanced or depleted stars-specifically, α-poor, metal-poor (α PMP), and CEMP stars-in a self-supervised manner.
This paper is organized as follows. In Section 2, we describe the proposed methodology, including the architecture and training of our model and the subsequent search for chemically enhanced and depleted stars. Section 3 details the synthetic spectral dataset, and Sect. 4 presents our experimental results, highlighting findings on α-poor, metal-poor, and CEMP stars. Finally, Section 5 discusses the implications of our work for understanding the Milky Way’s formation history and outlines prospects for future applications to large-scale spectroscopic datasets.
2 Methods
In this section we present our method, which consists of two main stages: (1) learning a structured representation of stellar spectra that depends only on chemistry and (2) leveraging this representation to identify chemically enhanced or depleted stars. Our approach is inspired by de Mijolla et al. (2021), with key modifications to ensure disentanglement of spectral features linked to different chemical abundances.
Section 2.1 introduces the problem formulation and the philosophy behind our approach. Sections 2.2, 2.3 and 2.4 detail the deep learning framework and model architecture, emphasizing the structured latent space that enables interpretability. Finally, in Section 2.5, we describe how this learned representation is used to identify chemically distinct stars. While these stars may not be clearly separated in chemical space, our method enables their detection by characterizing their position relative to the overall distribution of latent variables, allowing us to highlight departures from typical abundance patterns.
2.1 Problem definition
The observed spectrum s ∈ ℝd can be expressed as
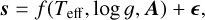 (1)
where Teff is the effective temperature, log g is the logarithm of the surface gravity, A=(A1, A2, …, Am) represents the chemical abundances, where m is the number of elemental abundances considered, and ε accounts for observational uncertainties, measurement noise, and unmodeled spectral variations. Because the dominant variations in s are driven by Teff and log g, stars with different chemical compositions may still have similar spectra. We focus on Teff and log g as the main atmospheric parameters, since additional quantities-such as micro-turbulence, macroturbulence, or mixing length-are artifacts introduced in 1D models to approximate convective effects, and are not required in more realistic 3D simulations where such processes are treated self-consistently (Magic et al. 2013, 2014, 2015).
(1)
where Teff is the effective temperature, log g is the logarithm of the surface gravity, A=(A1, A2, …, Am) represents the chemical abundances, where m is the number of elemental abundances considered, and ε accounts for observational uncertainties, measurement noise, and unmodeled spectral variations. Because the dominant variations in s are driven by Teff and log g, stars with different chemical compositions may still have similar spectra. We focus on Teff and log g as the main atmospheric parameters, since additional quantities-such as micro-turbulence, macroturbulence, or mixing length-are artifacts introduced in 1D models to approximate convective effects, and are not required in more realistic 3D simulations where such processes are treated self-consistently (Magic et al. 2013, 2014, 2015).
We mapped the spectra into a lower-dimensional latent space, capturing the essential generative factors of the data:
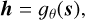 (2)
where gθ is a function, parameterized by θ, which maps the input spectrum s to a latent representation h=h(Teff, log g, A) ∈ ℝd′, d′ ≪ d. Without additional constraints, the resulting latent representation is likely to be dominated by variations in Teff and log g, rather than isolating chemical information. If each component of h retains information about Teff and log g, chemically similar stars at different temperatures or gravities are likely to appear dissimilar in each component of the latent space. To obtain a chemically meaningful representation, we required at least a portion z of the latent space to capture only variations in chemical abundances:
(2)
where gθ is a function, parameterized by θ, which maps the input spectrum s to a latent representation h=h(Teff, log g, A) ∈ ℝd′, d′ ≪ d. Without additional constraints, the resulting latent representation is likely to be dominated by variations in Teff and log g, rather than isolating chemical information. If each component of h retains information about Teff and log g, chemically similar stars at different temperatures or gravities are likely to appear dissimilar in each component of the latent space. To obtain a chemically meaningful representation, we required at least a portion z of the latent space to capture only variations in chemical abundances:
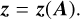 (3)
(3)
Finally, we imposed additional structures such that each latent variable zi corresponded directly to a single abundance Ai:
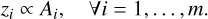 (4)
While this formulation is general and can accommodate any number m of chemical elements, in this work we focus on metallicity, carbon, and α-element abundances. Thus, we set m=3 and
(4)
While this formulation is general and can accommodate any number m of chemical elements, in this work we focus on metallicity, carbon, and α-element abundances. Thus, we set m=3 and
![Mathematical equation: $z=\left(z_{\mathrm{M}}, z_{\mathrm{C}}, z_{\alpha}\right) \propto([\mathrm{Fe} / \mathrm{H}],[\mathrm{C} / \mathrm{Fe}],[\alpha / \mathrm{Fe}]).$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq5.png) (5)
(5)
2.2 Disentanglement from nonchemical generative factors
To obtain a representation space that is independent of nonchemical generative factors, in this case Teff and log g, we employed disentangled representation learning, following an approach similar to de Mijolla et al. (2021). Our representation learning model is based on VAEs, neural networks composed of an encoder-decoder pair. The encoder, which models gθ, maps spectra s to a lower-dimensional latent representation, h=gθ(s) (Eq. (2)). We split this representation into two components:
A chemical latent space z, which is designed to encode information about chemical abundances.
An auxiliary latent space w, which captures variations due to the nonchemical generative factors u=(Teff, log g).
A decoder hφ then reconstructs the spectrum using both:
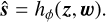 (6)
Unlike previous approaches (e.g., de Mijolla et al. 2021) that provide u explicitly as inputs to the decoder, this formulation designs the encoder to disentangle u from z, while still allowing u to influence the encoding of the spectra.
(6)
Unlike previous approaches (e.g., de Mijolla et al. 2021) that provide u explicitly as inputs to the decoder, this formulation designs the encoder to disentangle u from z, while still allowing u to influence the encoding of the spectra.
To further encourage independence between the chemical latent representation z and the nonchemical parameters u, we integrated an adversarial training mechanism inspired by Fader Networks (Lample et al. 2017). We introduced an auxiliary neural network dψ, often referred to as the adversary, which attempts to infer u from z. Concurrently, the encoder gθ, was trained to minimize the discrepancy between reconstructed and original spectra, while also producing a representation z that prevents this adversary from accurately recovering u.
This adversarial setup was implemented as a minimax optimization: the adversary is optimized to minimize its prediction loss ℒadv, while the encoder is optimized to maximize it. Once the adversary fails to extract any information about u from z, we can conclude that z has become independent of nonchemical factors, ensuring a disentangled representation that primarily encodes chemical abundances. Additionally, during training, we optimized a linear rescaling ll of w to predict u, which further aligns the auxiliary latent space with the nonchemical parameters.
Thus, the goal of training is to find the parameters θ, φ, ψ, l that minimize the overall objective function:
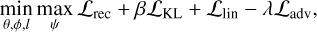 (7)
where ℒrec is the reconstruction loss, which we chose to implement as the log-likelihood, and ℒKL is the KL divergence regularization term from the VAE, encouraging the latent space to follow a Normal distribution. In the standard setup, this prior distribution is diagonal, encouraging independence across latent dimensions. Here, we extended it to a more general Gaussian prior, with a covariance matrix informed by astrophysical knowledge of abundance trends. This does not fix the correlations in the data, but rather acts as a soft inductive bias: the reconstruction loss still drives the model to recover the true abundance structure, while the prior regularizes the latent dimensions.
(7)
where ℒrec is the reconstruction loss, which we chose to implement as the log-likelihood, and ℒKL is the KL divergence regularization term from the VAE, encouraging the latent space to follow a Normal distribution. In the standard setup, this prior distribution is diagonal, encouraging independence across latent dimensions. Here, we extended it to a more general Gaussian prior, with a covariance matrix informed by astrophysical knowledge of abundance trends. This does not fix the correlations in the data, but rather acts as a soft inductive bias: the reconstruction loss still drives the model to recover the true abundance structure, while the prior regularizes the latent dimensions.
The adversarial loss ℒadv is defined as the sparse categorical cross-entropy, a classification loss. Since the labels u are continuous and 2D, we discretized them into 1D bins. By choosing classification over regression – i.e., predicting discrete classes instead of continuous values–we simplified the task for the adversary, making the adversarial training process more stable and, consequently, improving disentanglement.
Finally, the linear loss ℒlin is the mean squared error between the ll(w) and u. The definition of these losses are presented in Appendix A. Although multiple loss terms are involved, each contributes to compatible objectives, ensuring that the overall complexity remains manageable and aligned with the primary goal of disentangling the latent representation.
In our implementation, the coefficients controlling the relative importance of latent space regularization and disentanglement (β and λ in Eq. (7), respectively) were updated according to a stepwise schedule based on the training iteration (see Appendix B). We found that the stepwise schedule prevents the adversary from collapsing into a dummy classifier early in training, ensuring more effective disentanglement.
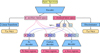 |
Fig. 1 Main model. A spectrum is given as input. An encoder maps it to the latent space, divided into chemical latent space z=(zM, zC, zα), and auxiliary latent space w. Three decoders map different components of z, along with w, to separate regions of the input spectrum. A linear transform is applied to the auxiliary space to obtain (Teff, log g). The discriminator is trained to predict the nonchemical parameters (Teff, log g) from z, while the encoder is trained to make this impossible for the discriminator to predict these parameters from z alone. The dotted gray arrows represent the absence of gradient propagation (see Sect. 2.4). At inference time the decoders, the discriminator and the linear transform module are discarded. |
2.3 The model
To link each latent feature to specific chemical abundances, we developed a structured encoder-decoder architecture where different decoders specialize in reconstructing spectral regions dominated by particular chemical elements. As we are interested in three chemical abundances, our model, illustrated in Fig. 1, consists of a single encoder and three decoders, each responsible for reconstructing different spectral regions:
The metal-decoder receives two latent features: zM, which captures general metallicity and zC, shared with the carbondecoder (described below). It reconstructs spectral regions dominated by iron while also taking w as input.
The carbon-decoder shares zM with the metal-decoder but has an additional feature, zC, specific to carbon. It reconstructs spectral regions dominated by carbon while also taking w as input.
The α-decoder builds upon the representations learned by the other decoders: it shares zM with the metal-decoder, zC with the carbon-decoder, and incorporates a separate feature zα, dedicated to α-elements. It reconstructs spectral regions dominated by α-element lines while also taking w as input.
This design is modular and readily extensible to accommodate any number of chemical components by introducing additional decoders specialized to reconstruct different spectral regions. The specific spectral regions-whether broad bands, individual absorption lines, or other wavelength intervals-assigned to each decoder will depend on the resolution, wavelength coverage, and other properties of the instrument.
Our autoencoder follows the architecture proposed by Melchior et al. (2023), which employs a convolutional encoder and a fully connected decoder for galaxy spectra. The encoder uses a PReLU activation function (He et al. 2015), while the decoders use an activation function of the form,
![Mathematical equation: $a(x)=\left[\gamma+\frac{1-\gamma}{\left(1+\mathrm{e}^{-\beta \odot x}\right)}\right] \odot x,$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq8.png) (8)
where γ and β are trainable parameters (Alsing et al. 2020). This activation function allows the model to handle smooth features for small β and sharp changes in gradients as β → ∞, making it particularly effective for spectral line modeling. This type of network and activation function has also been utilized in Buck & Schwarz (2024), showing also its suitability for stellar spectra.
(8)
where γ and β are trainable parameters (Alsing et al. 2020). This activation function allows the model to handle smooth features for small β and sharp changes in gradients as β → ∞, making it particularly effective for spectral line modeling. This type of network and activation function has also been utilized in Buck & Schwarz (2024), showing also its suitability for stellar spectra.
The adversary is a feed-forward neural network. Specifics are reported in Appendix B.
2.4 Training with selective gradient flow
In standard training, the reconstruction loss from each decoder is typically backpropagated through the entire latent space. This means, for example, that the α-decoder can update not only the latent feature associated with α-elements, but also those associated with iron or carbon. As a result, latent features may become entangled, with each one capturing mixed information from multiple chemical factors. This is especially problematic in stellar spectra, where strong features such as metallicity can dominate the learning signal and suppress weaker patterns, such as those associated with α-elements.
To address this, we implemented a selective gradient flow strategy, restricting the propagation of reconstruction losses to their relevant latent dimensions. Specifically:
The α-decoder backpropagates gradients only to the latent feature associated with α-elements (zα).
The carbon-decoder backpropagates gradients only to the latent feature associated with carbon (zC).
The metallicity (iron) latent feature (zM) is used by all decoders but remains unaffected by the reconstruction losses from the α and carbon decoders.
This means that, the loss from the α-decoder influences only the latent feature for α-elements, the carbon-decoder’s loss affects only the latent feature associated with carbon, and the metal-decoder’s loss affects only the latent feature associated with metallicity. This prevents reconstruction losses in each region from affecting the latent features associated with the other regions. Put differently, each decoder can still leverage information from other latent features (e.g., the α-decoder still uses zM and zC to account for metallicity and carbon contributions in its spectral region), but it cannot affect them.
By maintaining this selective gradient flow, we ensured that each latent feature distinctly represents a specific chemical factor. Without this control, the strong metallicity features in stellar spectra would dominate the latent space, making it difficult for the model to learn representations for other chemical abundances (see Appendix C for a comparison of results with and without selective gradient flow).
2.5 Identifying chemically enhanced and/or depleted stars
After training, the latent space is chemically structured by design: each chemical latent feature is aligned with a specific chemical abundance – in our case one with [Fe/H], another with [α/Fe], and a third with [C/Fe]. Moreover, thanks to the KL divergence regularization term (A.2), the latent features follow approximately Normal distributions (mean μ=0 and standard deviation σ=1). This means that uncommon stars appear in the tails of the distribution, and we can define a star as enhanced or depleted if it lies beyond a chosen threshold k of standard deviations in any of the latent features. This statistically principled approach directly exploits the Gaussian nature of the latent space, offering an efficient and interpretable method for flagging stars with arbitrary levels of rarity.
To assess these capabilities, we focus on two categories of chemically interesting stars. We evaluate our model on the quality of the flagging of α-poor, metal-poor stars (α PMP), and CEMP. These stars, rather than forming separate, isolated clusters in chemical space, are distributed within a continuous space, with approximate boundaries. α PMP stars can be defined as stars with [α/Fe]<0.0 and [Fe/H]<−1.0 (e.g., Nissen & Schuster 1997; Ramírez et al. 2012; Hawkins et al. 2014; Li et al. 2022), CEMP stars as metal-poor stars with [C/Fe]>0.7 (e.g., Aoki et al. 2007) and [Fe/H]<−1.0.
We transformed these cuts into the latent space by computing their locations in terms of standard deviations from the expected chemical distribution’s mean. In this representation, α PMP stars are identified as those lying beyond the chosen k σ thresholds in both zα (low values) and zM (low values), while CEMP stars correspond to high zC and low zM.
3 Simulated dataset
To generate our dataset, we synthesized spectra using iSpec (Blanco-Cuaresma et al. 2014; Blanco-Cuaresma 2019), which wraps the Turbospectrum spectral synthesis code (Plez 2012), with MARCS atmospheric models (Gustafsson, B. et al. 2008). Atomic data were taken from the VALD line list (Piskunov et al. 1995).
We created a set of five simulated catalogs of 40 000 low-resolution (R=2200) spectra each, covering a wavelength range of [4 000, 10 400] Å, sampled with a logarithmic step of Δ log10(λ/Å)=0.0001. These values were chosen to roughly reflect typical characteristics of spectra from modern large-scale surveys of the Galactic Halo, providing a realistic yet flexible setup for testing our approach. The spectral regions we selected for each decoder, based on element-specific features within this resolution and wavelength range, are detailed in Appendix D.
Since we are interested in three chemical abundances, we synthesized spectra that depend on five parameters: effective temperature (Teff), surface gravity (log g), metallicity ([Fe/H]), α-elements abundance ([α/Fe]), and carbon abundance ([C/Fe]). For each spectrum, Teff and log g were generated by sampling from uniform distributions with range [3000, 7000] K and [2.5, 6] dex, respectively. While these distributions do not match the usual parameter spaces covered by stellar surveys, they provide a wider range of variability, increasing the complexity of the training set.
The chemical abundances were sampled from the joint distribution:
![Mathematical equation: $r([\mathrm{Fe} / \mathrm{H}],[\mathrm{C} / \mathrm{Fe}],[\alpha / \mathrm{Fe}])$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq9.png) (9)
(9)
![Mathematical equation: $=\frac{1}{Z} p([\mathrm{Fe} / \mathrm{H}],[\mathrm{C} / \mathrm{Fe}]) \times q([\mathrm{Fe} / \mathrm{H}],[\alpha / \mathrm{Fe}]),$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq10.png) (10)
where p and q are the probability distribution functions (PDFs) for the pairs ([Fe/H],[C/Fe]) and ([Fe/H],[α/Fe]), respectively, observed in the Galactic Halo population (e.g., Ardern-Arentsen et al. 2025; Chiappini 2001, see Fig. 2). Z is a normalization constant:
(10)
where p and q are the probability distribution functions (PDFs) for the pairs ([Fe/H],[C/Fe]) and ([Fe/H],[α/Fe]), respectively, observed in the Galactic Halo population (e.g., Ardern-Arentsen et al. 2025; Chiappini 2001, see Fig. 2). Z is a normalization constant:
![Mathematical equation: $Z=\int p \times q d[\mathrm{Fe} / \mathrm{H}] d[\mathrm{C} / \mathrm{Fe}] d[\alpha / \mathrm{Fe}].$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq11.png) (11)
(11)
In this distribution we find the following:
![Mathematical equation: $\mu_{[\mathrm{Fe} / \mathrm{H}]}=-1.23, \quad \sigma_{[\mathrm{Fe} / \mathrm{H}]}=0.57,$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq12.png) (12)
(12)
![Mathematical equation: $\mu_{[\mathrm{C} / \mathrm{Fe}]}=0.62, \quad \sigma_{[\mathrm{C} / \mathrm{Fe}]}=0.75,$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq13.png) (13)
(13)
![Mathematical equation: $\mu_{[\alpha / \mathrm{Fe}]}=0.22, \quad \sigma_{[\alpha / \mathrm{Fe}]}=0.15.$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq14.png) (14)
(14)
To better mimic realistic observations, we added Gaussian noise to the continuum-normalized spectra, with mean zero and a standard deviation of σ=1 /(S/N), where the signal-to-noise ratio (S/N) is drawn from a normal distribution with a mean of 50 and a standard deviation of 10. In addition to spectral noise, we perturb Teff and log g by applying a 2% relative random error, to train the disentanglement mechanism under uncertain stellar parameters.
 |
Fig. 2 Abundance distributions for the simulated stellar sample. PDFs for the chemical abundances used to sample the stellar properties in our dataset, with lighter colors indicating higher probability densities. Left panel: PDF of [C/Fe] versus [Fe/H]. Right panel: PDF of [α/Fe] vs. [Fe/H]. In both panels, the pink contours show the abundance distributions of halo stars from the APOGEE survey, as provided by the astroNN catalog. APOGEE does not reach the lowest metallicities present in our simulated dataset, which explains the differences at low [Fe/H]. |
4 Results
We implemented the architecture introduced in Sect. 2.3 with PyTorch (Paszke et al. 2019) and trained it for 4000 epochs using the Adam optimizer (Kingma 2014) and the 1Cycle learning rate schedule (Smith & Topin 2019) with a maximum learning rate of 10−3. The model was trained and evaluated separately on the five simulated catalogs described in Sect. 3, using 70% of the spectra for training and the remaining 30% for evaluation. On an NVIDIA RTX A4000 GPU, training takes approximately six hours. Unless otherwise specified, reported results are either representative samples or averages over different simulated catalogs.
4.1 Evaluating reconstruction capabilities
To assess reconstruction quality, we compare the original and reconstructed spectra. Figure 3 presents representative examples, illustrating the agreement between input and output.
The average relative L2 error (Eq. (A.5)) for all the samples in the validation set is 0.006. For α-poor, metal-poor stars, the error is 0.01, for carbon-rich, 0.005, and for solar-like composition stars, 0.004. These results align with expectations, as the model training is focused more on reconstructing the most common stars in the dataset. In particular, only ≈ 10% are α-poor, metal-poor stars. Overall, the model achieves a reconstruction error below the noise level in the spectra. This implies that the latent space effectively captures the essential spectral information.
4.2 Latent space as a representation of chemical composition
The central goal of our architecture is to learn a latent space that captures only chemical information, disentangled from non-chemical physical parameters such as effective temperature and surface gravity, u=(Teff, log g), with each feature aligned to a specific chemical element. This disentanglement and alignment with the intended chemical abundances is quantified in Table 1, in terms of the average absolute Pearson correlation coefficients (r) between latent features and both chemical abundances and atmospheric parameters. Each latent feature shows strong correlation with its intended chemical abundance and negligible correlation with Teff and log g. Cross-correlations between latent features and other chemical abundances reflect intrinsic correlations in the dataset, suggesting that the model preserves the natural structure of chemical abundances.
To test for potential multivariate nonlinear dependencies between the latent space and the atmospheric parameters, we applied a regressor (XGBoost, Chen & Guestrin 2016) to predict u from the learned chemical latent features z. The regressor performs no better than a dummy baseline that simply predicts the mean of the training data, suggesting that the latent space contains no meaningful information about these physical parameters. This confirms that the model has successfully isolated chemical information in the latent space, leaving Teff and log g disentangled.
We plot each latent feature against its corresponding abundance in Fig. 4. These plots further demonstrate how zM captures metallicity, zα captures α abundance, and zC captures carbon abundance, effectively encoding distinct chemical properties in each feature as a rescaled representation. When splitting the sample into low, medium, and high Teff bins, the latent–abundance relations for metallicity and carbon remain nearly unchanged, while the α-latent shows a modest slope variation. This is consistent with the weaker imprint of α-elements in stellar spectra, which makes their latent representation more susceptible to residual dependence on stellar parameters.
As a sanity check, we also tested how well the learned latent features can be rescaled into abundances and compared them to a traditional supervised learning algorithm. Since the comparison involves different levels of prior knowledge and optimization, we defer the details to Appendix E.
 |
Fig. 3 Representative reconstructions. Comparison of original (before noise perturbation, blue) and reconstructed spectra (pink) for three chemical types: an α-poor, metal-poor star (top row), a CEMP star (middle row), and a solar-like star (bottom row). The residuals (reconstructed minus original) are shown in red in the bottom subpanels. The shaded regions highlight spectral domains handled by the different decoders, as indicated in the legend. |
4.3 Identifying chemically enhanced and depleted stars in the latent space
Since our latent space successfully disentangles chemical information (Sect. 4.2), we now apply this learned representation to identify chemically peculiar stars. By leveraging the model’s ability to separate chemical features in the latent space, we can systematically search for outliers in an unsupervised manner.
As described in Sect. 2, we evaluated our model based on its ability to flag two categories of interesting stars: α PMP stars and CEMP stars. These classes do not occupy distinct, isolated regions in chemical space but are instead defined by approximate thresholds in elemental abundances: α PMP stars are identified as those with [α/Fe]<0.0 and [Fe/H]<−1.0; CEMP stars satisfy both conditions: [C/Fe]>0.7 and [Fe/H]<−1.0.
To assess the significance of these cuts, we determined their locations in terms of standard deviations from the mean of the dataset’s chemical distributions. The [Fe/H] threshold for MP stars corresponds to k=0.4 standard deviations from the mean, the α cutoff for α-poor stars is at k=1.5, and the [C/Fe] threshold for CE stars is at k=0.1.
In our approach, we then flag as enhanced and/or depleted any star that is located more than k standard deviations from the mean in any of the three latent features. Assuming an approximately Gaussian distribution in the latent space, this thresholding approach provides a simple yet effective method to identify rare cases.
Because the relationship between latent features and chemical abundances is not explicitly constrained to be positive, we must first establish the sign of correlation before applying thresholds. This can be done using a small set of labeled samples or by visually inspecting spectra–for example, by comparing stars from different regions of the latent space and verifying which ones have higher metallicity, α abundance, or carbon content. Once the sign of the correlation is established, we flag as chemically enhanced or depleted any star with a latent feature value exceeding k standard deviations from the mean in the appropriate direction. Table 2 summarizes the precision and recall (Eqs. (A.7) and (A.6)) for α PMP and CEMP stars. We note that these values are tied to the specific characteristics of our dataset and may vary in real-world scenarios, potentially improving with higher signal-to-noise ratios or spectral resolution.
For α PMP stars, the model achieves a high precision of 0.84 ± 0.04, meaning that nearly all flagged stars truly belong to this category. While the recall is lower at 0.11 ± 0.02, this suggests that the model is highly selective, prioritizing confidence over completeness. This is not necessarily a drawback, as it ensures that the flagged stars are indeed α PMP, making the method particularly useful for identifying the most chemically distinct cases. The lower recall may also reflect the challenges of estimating α-elements abundances, especially in low-resolution spectra, where individual α-elements absorption features can be blended or difficult to distinguish.
For CEMP stars, the precision is similarly high at 0.96 ± 0.09, while the recall is substantially better at 0.68 ± 0.05. This indicates that the model captures a larger fraction of true CEMP stars while still maintaining a low false-positive rate. The higher recall for CEMP stars suggests that they are more clearly separated in the latent space, potentially due to stronger spectral features associated with carbon enhancements. Figure 5 illustrates the distribution of stars in chemical space, color-coded by their predicted class.
Overall, these results demonstrate that our approach successfully identifies chemically enhanced or depleted stars with high confidence, making it a valuable tool for selecting candidates for follow-up analyses of uncommon abundance patterns. The high precision across both categories confirms that the flagged stars are true positives, while the differences in recall highlight the varying challenges in identifying distinct chemical signatures.
Correlations of latent features with atmospheric parameters.
 |
Fig. 4 Latent-abundance relations for the learned representation. Contour plot of latent features (from left to right, zM, zα, zC) and their corresponding chemical abundances. The scatter points represent individual data points, and the contour lines represent data density, with lighter contours indicating regions of higher density. Straight lines show linear fits to the latent-abundance relations for stars in three Teff bins, as indicated in the legend. |
Precision and recall for detection of chemically peculiar stars.
 |
Fig. 5 Distribution of stars in the true chemical space. Left panel: [C/Fe] vs. [Fe/H]. Right panel: [α/Fe] vs. [Fe/H]. The color represents the predicted class, with blue indicating stars not flagged as enhanced and/or depleted, and pink indicating those flagged as enhanced and/or depleted. The pink-highlighted regions indicate the approximate boundaries for α PMP and CEMP stars, as described in Sect. 2.5, where α PMP stars are defined by [α/Fe]<0.0 and [Fe/H]<−1.0, and CEMP stars by [C/Fe]>0.7 and [Fe/H]<−1.0. |
 |
Fig. 6 Abundance-prediction residuals as a function of S/N. Residuals [X̃]−[X], defined as the difference between the abundance predicted via linear regression from the latent features (zM, zα, zC) and the true values, shown as a function of S/N. From left to right: [Fe/H],[α/Fe], and [C/Fe]. Red markers indicate the mean residuals in bins of S/N (with width 10, ranging from 15 to 85), and the error bars show the standard deviation within each bin. |
4.4 Robustness to noise and sensitivity to perturbations
We tested the robustness of the learned chemical latent space to varying S/N ratios by examining whether noise in the input spectra affects the chemical content encoded by each latent feature. For each latent dimension, we performed a linear regression against its corresponding chemical abundance (e.g., zM → [Fe/H̃] ≈ [Fe/H]) and computed the residuals. These residuals quantify deviations from the expected chemical abundance based on the learned latent representation. Note that this is not intended as an abundance estimation task but rather serves as a proxy to check for potential deviations from the expected linear correlation due to noise in the spectra.
We plot the residuals as a function of S/N to identify any potential trends of prediction quality with respect to noise in Fig. 6. A flat residual distribution would indicate that the encoding of chemical information is stable and unaffected by the noise level of the input spectrum. Indeed, we observe no significant correlation between the residuals and S/N, confirming that the quality of the latent representation remains robust across a wide range of spectral noise conditions. This demonstrates that our model captures chemically informative features whose encoding is largely unaffected by observational noise. We further verified this behavior by training the model on datasets with both high and low S/N and evaluating the reconstruction error separately for each regime as a function of the training set size, as detailed in Appendix F.
We also explored the model’s sensitivity to more extreme cases of spectral degradation. In particular, we assessed its ability to handle both heavy random perturbations and systematic distortions that might occur in practice due to artifacts or data corruption. To this end, we applied random Gaussian noise (with a standard deviation of 30%) and introduce severe modifications, such as inserting high-amplitude spikes at random wavelengths or replacing short spectral segments (≈ 100 pixels) with zeros or ones–thereby generating anomalous spectra. These perturbed spectra were used to evaluate the model’s response to such distortions and its ability to distinguish true anomalies from “normal” data. We computed the Euclidean norm of the latent chemical representation and the reconstruction error for both stellar and anomalous spectra. In Fig. 7, we show the distributions of these values for both types of input data (normal spectra vs. anomalous data). We obtain a clear separation between the two distributions, with anomalous spectra exhibiting significantly larger reconstruction error and norm.
The reconstruction error, in particular, serves as a reliable metric for detecting and removing real, global anomalies, a strategy commonly used in anomaly detection. Since anomalous samples, which deviate in overall spectral properties rather than just in chemistry, are by definition rare, the model cannot learn to represent them well, resulting in poor reconstruction and thus higher errors. This makes the reconstruction error a highly effective way to identify and remove such outliers from the dataset (e.g., Sánchez-Sáez et al. 2021; Holly et al. 2022; Angiulli et al. 2023).
As an experiment on real data, we trained our model on a subset of LAMOST DR10 low-resolution spectra. The details of this experiment and the results are reported in Appendix G.
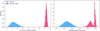 |
Fig. 7 Latent space norms for normal and anomalous spectra. Distribution of the Euclidean norm of the latent representation for stellar spectra (blue) and anomalous data (pink). The clear separation between these distributions indicates that the network distinguishes true spectral features from noise. |
5 Conclusions and outlook
We set out to develop a data-driven approach focused on disentangling chemical abundances that minimizes reliance on model-based assumptions and instead operates as close as possible to the observed data space. To this end, we introduced a neural network architecture for modeling stellar spectra using a differentiable, data-driven, and physics-constrained approach. Rather than relying on a classical autoencoder, our design employs an encoder-multiple decoders architecture that explicitly disentangles spectral features associated with different chemical abundances from those driven by nonchemical atmospheric parameters. By structuring the latent space in this manner, each latent variable corresponds to a chemically meaningful component of the stellar atmosphere, improving interpretability and ensuring that the representations are independent of nonchemical factors.
Tests on simulations reveal that our architecture enables a precise reconstruction of spectra, even for chemically peculiar stars. Each decoder specializes in reconstructing spectral regions dominated by specific elements (iron, α-elements, and carbon), while targeted gradient control prevents dominant metallicity and carbon features from overshadowing the weaker α-element signatures. The resulting latent space is highly structured and interpretable, with individual features strongly correlated with [Fe/H],(r=0.92 ± 0.01),[C/Fe](r=0.92 ± 0.01), and [α/Fe] (r=0.82 ± 0.02). To further quantify the degree to which chemical abundances are encoded in the latent space, we trained simple linear regressors to map from latent features back to abundance estimates. The resulting predictions exhibit low residuals, with RMSEs of 0.21 dex for [Fe/H], 0.08 dex for [α/Fe], and 0.31 dex for [C/Fe].
Moreover, the imposed Gaussian prior on the chemical latent space facilitates a straightforward framework that can flag stars with unusual chemical compositions. For α PMP stars, the model achieves a high precision of 0.84 ± 0.04 and a recall of 0.11 ± 0.02. While the recall can be considered modest, the high precision suggests the model is selective and robust against false positives. For CEMP stars, the model performs even better, with a precision of 0.96 ± 0.09 and a recall of 0.68 ± 0.05. This demonstrates that the model can reliably identify chemically enhanced or depleted stars, with higher recall for CEMP stars suggesting that carbon enhancements are more clearly separated in the latent space.
We examined how varying noise levels in the spectra affect the structure of the latent space. By analyzing deviations from linear correlations between latent features and chemical abundances across different S/N regimes, we found that the learned representations remain robust, with no significant distortions even at low S/N. Overall, these results demonstrate that our approach is not only capable of reconstructing stellar spectra accurately but also provides an easy to implement tool for detecting chemically enhanced or depleted stars, offering potential for advancing studies of stellar populations and Galactic archaeology.
Beyond its application to synthetic low-resolution spectra as a proof of concept, our approach is highly general and can be applied to any large-scale spectroscopic survey. In particular, higher-resolution datasets-such as those from APOGEE–are likely to benefit even more from this architecture. Increased spectral resolution provides more detailed information about individual absorption features, which should enhance both the reconstruction accuracy and the specialization of the latent space to elemental abundances. The main required adaptation is in the choice of spectral regions assigned to each decoder, which can consist of individual absorption lines or broader spectral intervals, depending on the resolution and the chemical feature of interest. This flexibility makes our method a promising tool for analyzing stellar populations across a wide range of observational contexts.
While our synthetic spectra provide a controlled dataset for training and evaluation, they are subject to certain limitations when transferring the method to real data. First, the atmospheric models used do not account for carbon or α-elements in the model structure, meaning that the spectra may be less sensitive to variations in these abundances compared to real observations. Some of the cooler models in our dataset may reach temperatures where the completeness and accuracy of the VALD line list begin to break down, due to the prominence of molecular bands that can result in missing or inaccurate features (Piskunov et al. 1995; Ryabchikova et al. 2015).
Additionally, the synthesis may not fully capture the complexities of metal-poor stars, where departures from local thermodynamic equilibrium (LTE) and 3D effects become significant (e.g., Asplund et al. 1999; Asplund 2001; Jofré et al. 2014). As a result, the synthetic spectra are likely less sensitive to chemical variations than real data, especially for carbon-enhanced and metal-poor stars (see, e.g., Eitner et al. 2025).
Furthermore, in real observations, certain spectral bins may be flagged as unreliable, for example, due to the presence of cosmic rays or other detector artifacts, and these regions are typically masked during analysis. Since our current model requires complete spectral inputs for effective processing, missing or unreliable data must be addressed. One approach is to impute the missing values, essentially filling in the flagged regions with estimates based on surrounding data. Alternatively, the model itself could be adapted to handle missing data directly, allowing it to learn how to ignore or properly interpret these unreliable regions without requiring explicit imputation (e.g., Dupuy et al. 2024). This flexibility would ensure that the model can work with real-world data while maintaining the accuracy of its learned representations. Moreover, in VAE- or AE-based approaches, artifacts and other unsystematic effects are naturally filtered out during training (provided the training dataset is sufficiently large and diverse) since such effects do not contribute to the systematic spectral variation (e.g., Aquilué-Llorens & Soria-Frisch 2025). As a result, when such artifacts are encountered during inference, they typically produce large reconstruction errors, as we observed in Sect. 4.4. Another important direction is the treatment of uncertainties in both spectra and conditioning parameters. Our reconstruction loss already incorporates measurement errors through a weighted log-likelihood (Eq. (A.1)), which down-weights noisy fluxes and ensures that the training focuses on well-measured regions. A similar strategy could be extended to the auxiliary parameters Teff and log g in partially supervised settings, by incorporating their uncertainties as weights in the corresponding loss terms. Also, while in this work the auxiliary latent space w is learned deterministically, one could instead model it probabilistically by predicting both mean and variance and sampling from this distribution, in analogy to the chemical latent space z, which is already treated variationally in our model.
In future work, we foresee several avenues for applying, extending, and refining this research:
Observational application and high-resolution follow-up: as a simple proof of concept, we tested the framework on LAMOST low-resolution data (Appendix G), showing that it can be trained on real survey spectra. However, broader application requires additional caution, particularly regarding data selection, artifact removal, and label reliability; The natural next step is to extend this to larger and more diverse spectroscopic surveys, enabling the identification of candidate chemically enhanced or depleted stars. These candidates could then be targeted for high-resolution spectroscopic follow-up, allowing for the precise determination of chemical abundances and a deeper understanding of the accretion events and enrichment processes that have shaped the Milky Way;
Improved chemical modeling: the model can be readily extended to include additional chemical elements. This can be achieved in any large scale survey, of any resolution. We expect that the model will be even more effective in high-resolution datasets, where the spectral features are more pronounced and the disentangling and alignment of different chemical components is clearer;
Cross-domain applications: the core principles behind our approach–structured latent spaces and disentangled repre–sentations–are not specific to stellar spectroscopy. Similar architectures could be adapted to other domains where data reflect multiple, interacting sources of variation. Examples might include atmospheric retrievals in exoplanet spectroscopy, modeling galaxy spectral energy distributions, or identifying drivers of variability in time-domain surveys of variable stars and transients.
Overall, our approach demonstrates that a physics-constrained, data-driven framework can effectively disentangle chemical information from stellar spectra, producing interpretable representations that align with physical drivers of variation. Compared to existing pipelines that map spectra directly to precomputed labels, our framework offers a complementary, interpretability-driven perspective. Rather than fitting the data to synthetic models or externally calibrated labels, it learns how spectra encode chemical information in a self-consistent, low-dimensional space guided by physical constraints to compensate for the lack of complete supervision. The result is a step toward model-free abundance estimation, where chemical information emerges naturally from the data themselves: each latent feature corresponds to the direction that best reconstructs the observed spectra, rather than the one that best matches a theoretical model. This makes the framework particularly promising for Galactic Archaeology studies, facilitating the exploration of regions of chemical space where models or calibrations are uncertain (such as metal-poor or chemically peculiar stars) and the discovery of new chemical structures and rare stellar populations directly from the data, without relying on existing grids or supervised training labels, where such peculiar stars might not be included. Applying the framework reliably to real data, however, will require additional validation and tuning, for example to handle survey-specific systematics and calibrations, which are beyond the present scope.
It is also important to note that in the total absence of chemical labels, interpretation of the learned features is not trivial: interpreting necessarily requires some knowledge; otherwise, one is merely looking. In practice, a minimal calibration (such as a simple linear regression step to rescale latent features into physical abundance units or to determine the direction of correlation) is sufficient. This step does not impose a model but instead provides a physical reference that makes the learned manifold interpretable and comparable across surveys.
As spectroscopic surveys continue to grow in scale and quality, we believe that such methods can offer a powerful alternative philosophy to fully supervised pipelines for extracting chemical information and advancing our understanding of stellar and Galactic evolution. We will thus make our code publicly available, providing a foundation for future research in unsupervised stellar spectroscopy.
Data availability
All code accompanying this manuscript will be made available upon publication on GitHub at https://github.com/theosig/stellar-physRL.
Acknowledgements
TS acknowledges financial support from Inria Chile ANID project CTI230007. PJ acknowledges partial financial support of FONDECYT Regular Grant Number 1231057. The authors thank Bruno Cavieres for his contributions during the initial stages of this project, Pablo Aníbal Peña Rojas for his helpful assistance, and the referee for a very constructive review of the paper.
References
- Alsing, J., Peiris, H., Leja, J., et al. 2020, ApJS, 249, 5 [CrossRef] [Google Scholar]
- Angiulli, F., Fassetti, F., & Ferragina, L., 2023, arXiv e-prints [arXiv:2305.10464] [Google Scholar]
- Aquilué-Llorens, D. & Soria-Frisch, A., 2025, arXiv e-prints [arXiv:2502.08686] [Google Scholar]
- Aoki, W., Beers, T. C., Christlieb, N., et al. 2007, ApJ, 655, 492 [NASA ADS] [CrossRef] [Google Scholar]
- Ardern-Arentsen, A., Kane, S. G., Belokurov, V., et al. 2025, MNRAS, 537, 1984 [Google Scholar]
- Arentsen, A., Starkenburg, E., Shetrone, M. D., et al. 2019, A&A, 621, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., 2001, in ASPCS, 223, 11th Cambridge Workshop on Cool Stars, Stellar Systems and the Sun, eds. R. J. Garcia Lopez, R. Rebolo, & M. R. Zapaterio Osorio, 217 [Google Scholar]
- Asplund, M., Nordlund, Å., & Trampedach, R. 1999, in ASPCS, 173, Stellar Structure: Theory and Test of Connective Energy Transport, eds. A. Gimenez, E. F. Guinan, & B. Montesinos, 221 [Google Scholar]
- Beers, T. C., & Christlieb, N., 2005, ARA&A, 43, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Belokurov, V., & Kravtsov, A., 2024, MNRAS, 528, 3198 [CrossRef] [Google Scholar]
- Bengio, Y., Courville, A., & Vincent, P., 2013, IEEE Trans. Pattern Anal. Mach. Intell., 35, 1798 [CrossRef] [Google Scholar]
- Blanco-Cuaresma, S., 2019, MNRAS, 486, 2075 [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., & Jofré, P., 2014, A&A, 569, A111 [CrossRef] [EDP Sciences] [Google Scholar]
- Bu, Y., Zhao, G., Pan, J., & Bharat Kumar, Y., 2016, ApJ, 817, 78 [Google Scholar]
- Buck, T., & Schwarz, C., 2024, arXiv e-prints [arXiv:2410.16081] [Google Scholar]
- Buder, S., Sharma, S., Kos, J., et al. 2021, MNRAS, 506, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Carbajal, G., Richter, J., & Gerkmann, T., 2021, in 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 126 [Google Scholar]
- Carvalho, D. S., Mercatali, G., Zhang, Y., & Freitas, A., 2022, arXiv e-prints [arXiv:2210.02898] [Google Scholar]
- Chen, T., & Guestrin, C., 2016, arXiv e-prints [arXiv:1603.02754] [Google Scholar]
- Chiappini, C., 2001, Am. Sci., 89, 506 [Google Scholar]
- Csiszar, I., 1975, Ann. Probab., 3, 146 [Google Scholar]
- Cui, X.-Q., Zhao, Y.-H., Chu, Y.-Q., et al. 2012, Res. Astron. Astrophys., 12, 1197 [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- De Lucia, G., & Helmi, A., 2008, MNRAS, 391, 14 [NASA ADS] [CrossRef] [Google Scholar]
- de Mijolla, D., Ness, M. K., Viti, S., & Wheeler, A. J., 2021, ApJ, 913, 12 [NASA ADS] [CrossRef] [Google Scholar]
- De Silva, G., Freeman, K., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [Google Scholar]
- Dittadi, A., Träuble, F., Locatello, F., et al. 2020, arXiv e-prints [arXiv:2010.14407] [Google Scholar]
- Dupuy, M., Chavent, M., & Dubois, R., 2024, mDAE: modified Denoising AutoEncoder for missing data imputation [Google Scholar]
- Eitner, P., Bergemann, M., Hoppe, R., et al. 2025, A&A, 703, A199 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Emukpere, D., Deffayet, R., Wu, B., et al. 2025, Disentangled Object-Centric Image Representation for Robotic Manipulation [Google Scholar]
- Fang, H., Carbajal, G., Wermter, S., & Gerkmann, T., 2021, in ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 676 [Google Scholar]
- Frebel, A., & Norris, J. E., 2015, ARA&A, 53, 631 [NASA ADS] [CrossRef] [Google Scholar]
- Frebel, A., Johnson, J. L., & Bromm, V., 2007, MNRAS, 380, L40 [NASA ADS] [CrossRef] [Google Scholar]
- Gilmore, G., Randich, S., Worley, C., et al. 2022, A&A, 666, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A., 2016, Deep Learning (MIT Press) [Google Scholar]
- Gui, J., Chen, T., Zhang, J., et al. 2023, arXiv e-prints [arXiv:2301.05712] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hansen, T. T., Andersen, J., Nordström, B., et al. 2016, A&A, 586, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hartwig, T., & Yoshida, N., 2019, ApJ, 870, L3 [Google Scholar]
- Hawkins, K., Jofré, P., Gilmore, G., & Masseron, T., 2014, MNRAS, 445, 2575 [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J., 2015, in Proceedings of the IEEE International Conference on Computer Vision, 1026 [Google Scholar]
- Helmi, A., 2020, ARA&A, 58, 205 [Google Scholar]
- Ho, A. Y. Q., Ness, M. K., Hogg, D. W., et al. 2017, ApJ, 836, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Holly, S., Heel, R., Katic, D., et al. 2022, arXiv e-prints [arXiv:2210.08011] [Google Scholar]
- Huang, G.-B., Zhu, Q.-Y., & Siew, C.-K., 2006, Neurocomputing, 70, 489 [CrossRef] [Google Scholar]
- Hudson, M. J., Gillis, B. R., Coupon, J., et al. 2015, MNRAS, 447, 298 [Google Scholar]
- Jofré, P., Heiter, U., & Soubiran, C., 2019, ARA&A, 57, 571 [Google Scholar]
- Jofré, P., Heiter, U., Soubiran, C., et al. 2014, A&A, 564, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johnson, J. W., Conroy, C., Johnson, B. D., et al. 2023, MNRAS, 526, 5084 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D. P., 2014, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kingma, D. P., & Welling, M., 2013, arXiv e-prints [arXiv:1312.6114] [Google Scholar]
- Kollmeier, J., Anderson, S. F., Blanc, G. A., et al. 2019, in Bulletin of the American Astronomical Society, 51, 274 [Google Scholar]
- Lample, G., Zeghidour, N., Usunier, N., et al. 2017, arXiv e-prints [arXiv:1706.00409] [Google Scholar]
- Lee, Y. S., Beers, T. C., Prieto, C. A., et al. 2011, AJ, 141, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, Y. S., Beers, T. C., Masseron, T., et al. 2013, AJ, 146, 132 [Google Scholar]
- Leung, H. W., & Bovy, J., 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Leung, H. W., Bovy, J., Mackereth, J. T., & Miglio, A., 2023, MNRAS, 522, 4577 [NASA ADS] [CrossRef] [Google Scholar]
- Li, H., Aoki, W., Matsuno, T., et al. 2022, ApJ, 931, 147 [NASA ADS] [CrossRef] [Google Scholar]
- Li, H., Wang, X., Zhang, Z., & Zhu, W., 2022, IEEE Trans. Knowl. Data Eng., 35, 7328 [Google Scholar]
- Li, G., Lu, Z., Wang, J., & Wang, Z., 2025, arXiv e-prints [arXiv:2502.15300] [Google Scholar]
- Liu, H., Du, C., Deng, M., & Zhang, J., 2025, MNRAS, 541, 58 [Google Scholar]
- Locatello, F., Bauer, S., Lucic, M., et al. 2018, arXiv e-prints [arXiv:1811.12359] [Google Scholar]
- Magic, Z., Collet, R., Asplund, M., et al. 2013, A&A, 557, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Magic, Z., Collet, R., & Asplund, M., 2014, arXiv e-prints [arXiv:1403.6245] [Google Scholar]
- Magic, Z., Weiss, A., & Asplund, M., 2015, A&A, 573, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154 [Google Scholar]
- Manea, C., Hawkins, K., Ness, M. K., et al. 2024, ApJ, 972, 69 [Google Scholar]
- Manteiga, M., Santoveña, R., Álvarez, M. A., et al. 2025, A&A, 694, A326 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marsteller, B., Beers, T. C., Sivarani, T., et al. 2009, AJ, 138, 533 [Google Scholar]
- Mas-Buitrago, P., González-Marcos, A., Solano, E., et al. 2024, A&A, 687, A205 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Melchior, P., Liang, Y., Hahn, C., & Goulding, A., 2023, AJ, 166, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Mu, J., Qiu, W., Kortylewski, A., et al. 2021, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 13001 [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H. W., Ho, A. Y. Q., & Zasowski, G., 2015, ApJ, 808, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Nissen, P. E., & Schuster, W. J., 1997, A&A, 326, 751 [NASA ADS] [Google Scholar]
- Norris, J. E., Yong, D., Bessell, M. S., et al. 2013, ApJ, 762, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, arXiv e-prints [arXiv:1912.01703] [Google Scholar]
- Piskunov, N. E., Kupka, F., Ryabchikova, T. A., Weiss, W. W., & Jeffery, C. S., 1995, A&AS, 112, 525 [Google Scholar]
- Placco, V. M., Frebel, A., Beers, T. C., & Stancliffe, R. J., 2014, ApJ, 797, 21 [Google Scholar]
- Plez, B., 2012, Turbospectrum: Code for spectral synthesis, Astrophysics Source Code Library [record ascl:1205.004] [Google Scholar]
- Ramírez, I., Meléndez, J., & Chanamé, J., 2012, ApJ, 757, 164 [Google Scholar]
- Randich, S., Gilmore, G., Magrini, L., et al. 2022, A&A, 666, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Recio-Blanco, A., de Laverny, P., Palicio, P. A., et al. 2023, A&A, 674, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ryabchikova, T., Piskunov, N., Kurucz, R. L., et al. 2015, Phys. Scr, 90, 054005 [Google Scholar]
- Sánchez-Sáez, P., Lira, H., Martí, L., et al. 2021, AJ, 162, 206 [CrossRef] [Google Scholar]
- Santoveña, R., Dafonte, C., & Manteiga, M., 2024, arXiv e-prints [arXiv:2411.05960] [Google Scholar]
- Sharma, M., Theuns, T., Frenk, C. S., & Cooke, R. J., 2018, MNRAS, 473, 984 [Google Scholar]
- Smee, S. A., Gunn, J. E., Uomoto, A., et al. 2013, AJ, 146, 32 [Google Scholar]
- Smith, L. N., & Topin, N., 2019, in Artificial Intelligence and Machine Learning for Multi-domain Operations Applications, 11006, SPIE, 369 [Google Scholar]
- Spite, M., Caffau, E., Bonifacio, P., et al. 2013, A&A, 552, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ting, Y.-S., 2024, arXiv e-prints [arXiv:2412.05806] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P., 2019, ApJ, 879, 69 [Google Scholar]
- Venn, K. A., Irwin, M., Shetrone, M. D., et al. 2004, AJ, 128, 1177 [NASA ADS] [CrossRef] [Google Scholar]
- Walsen, K., Jofré, P., Buder, S., et al. 2024, MNRAS, 529, 2946 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, X., Chen, H., & Zhu, W., 2023, in Proceedings of the 31st ACM International Conference on Multimedia, MM‘23 (New York, NY, USA: Association for Computing Machinery), 9702 [Google Scholar]
- Wheeler, A., Ness, M., Buder, S., et al. 2020, ApJ, 898, 58 [Google Scholar]
- Wu, Y., Du, B., Luo, A., Zhao, Y., & Yuan, H., 2014, in IAU Symposium, 306, Statistical Challenges in 21st Century Cosmology, eds. A. Heavens, J.-L. Starck, & A. Krone-Martins, 340 [Google Scholar]
- Xiang, M., Ting, Y.-S., Rix, H.-W., et al. 2019, ApJS, 245, 34 [Google Scholar]
- Yang, T., & Li, X., 2015, MNRAS, 452, 158 [CrossRef] [Google Scholar]
- Yong, D., Norris, J. E., Bessell, M. S., et al. 2013, ApJ, 762, 26 [Google Scholar]
- Yoo, H., Lee, Y.-C., Shin, K., & Kim, S.-W., 2023, in Proceedings of the ACM Web Conference 2023, 231 [Google Scholar]
- Yoon, J., Beers, T. C., Dietz, S., et al. 2018, ApJ, 861, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, H., Zhang, Y.-F., Liu, W., et al. 2022, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8024 [Google Scholar]
Appendix A Losses and metrics
This appendix describes the loss functions and metrics used throughout training and evaluation. Let xi j be the value of feature j of the data sample i, and let x̃i j be the corresponding reconstructed feature. Each data sample consists of d features, and n is the number of data samples under consideration. The uncertainty on xi j is denoted by σi j. The latent space has a dimension d′ (in this work d′=m=3), with μi k and εi k denoting the mean and standard deviation of the kth latent feature of data sample i.
ℒrec represents the reconstruction loss, which we chose to implement as the log-likelihood loss:
![Mathematical equation: $\mathcal{L}_{\text {rec }}=-\frac{1}{2 n} \sum_{i=1}^{n}\left[\log (2 \pi)+\frac{1}{d} \sum_{j=1}^{d}\left(\log \sigma_{i j}^{2}+\frac{\left(\tilde{x}_{i j}-x_{i j}\right)^{2}}{\sigma_{i j}^{2}}\right)\right],$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq15.png) (A.1)
This loss gives more weight to precise measurements and less to noisy ones.
(A.1)
This loss gives more weight to precise measurements and less to noisy ones.
ℒKL is the Kullback-Leibler divergence between the approximate posterior q(z ∣ x)= 𝒩 (μ, Σq) and the prior distribution p(z)=𝒩(0, Σprior) (Csiszar 1975):
![Mathematical equation: $\mathcal{L}_{\mathrm{KL}}=\frac{1}{2 n} \sum_{i=1}^{n}\left[\log \frac{\operatorname{det} \Sigma_{\text {prior }}}{\operatorname{det} \Sigma_{q, i}}-d^{\prime}+\operatorname{Tr}\left(\Sigma_{\text {prior }}^{-1} \Sigma_{q, i}\right)+\mu_{i}^{\top} \Sigma_{\text {prior }}^{-1} \mu_{i}\right],$](/articles/aa/full_html/2025/12/aa55376-25/aa55376-25-eq16.png) (A.2)
where μi is the mean vector for sample i, and
(A.2)
where μi is the mean vector for sample i, and 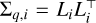 is its covariance matrix obtained via the Cholesky factor Li produced by the encoder.
is its covariance matrix obtained via the Cholesky factor Li produced by the encoder.
In this work, Σprior is not the identity matrix but a fixed correlation matrix with unit diagonal elements and nonzero off-diagonal terms, encoding prior knowledge about correlations between abundances. For example, we set correlations ρFe, α= −0.3 and ρFe,C = −0.17, while keeping other entries zero. This design allows the latent space to reflect correlations between elements, while preserving unit variance for each dimension. For reference, the common special case of a diagonal posterior q(z ∣ x)=𝒩(μ, diag(ε2)) and an isotropic prior p(z)=𝒩(0, I) reduces Eq. (A.2) to:
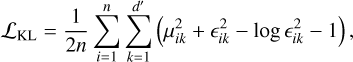 (A.3)
which is the standard expression often used in VAEs.
(A.3)
which is the standard expression often used in VAEs.
ℒclass is the classification loss defined as the sparse categorical cross entropy
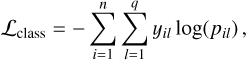 (A.4)
where yi l is the true label of the sample i and pi l is the predicted probability for it belonging to the lth class. The encoder-decoders are trained to maximize this ℒclass (in order to have a representation that is uninformative about the nonchemical physical parameters), as shown by the minus sign in Eq. (7), while the classifier is trained in order to minimize it. After training we evaluate the reconstruction performance using the relative L2 error:
(A.4)
where yi l is the true label of the sample i and pi l is the predicted probability for it belonging to the lth class. The encoder-decoders are trained to maximize this ℒclass (in order to have a representation that is uninformative about the nonchemical physical parameters), as shown by the minus sign in Eq. (7), while the classifier is trained in order to minimize it. After training we evaluate the reconstruction performance using the relative L2 error:
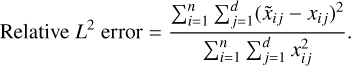 (A.5)
(A.5)
Hyper-parameter configurations.
Two metrics are used to evaluate the classification performance for identifying chemically enhanced or depleted stars. Let c denote the positive class, i.e., the chemically enhanced or depleted stars of interest:
The recall(c) represents the fraction of true positive-class stars that are correctly identified:
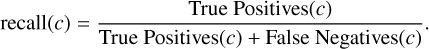 (A.6)
A high recall indicates that most positive-class stars are successfully detected, whereas a low recall suggests many are missed.
(A.6)
A high recall indicates that most positive-class stars are successfully detected, whereas a low recall suggests many are missed.The precision(c) indicates the fraction of stars predicted to belong to class c that truly do:
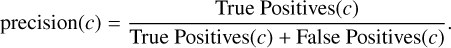 (A.7)
High precision means that most stars flagged as belonging to class c are indeed correct. Precision is sometimes referred to as purity.
(A.7)
High precision means that most stars flagged as belonging to class c are indeed correct. Precision is sometimes referred to as purity.
Appendix B Hyper-parameters
In Table B.1 we detail the hyper-parameters used in our training setup. We note that the specific architecture parameters (such as the number and size of encoder layers) had a relatively minor effect on the overall performance in our experiments. The batch size was chosen to ensure that each batch fits into GPU memory during training, but it can be increased on systems with more available memory.
Appendix C Effect of disabling selective gradient flow
To assess the impact of selective gradient flow (Sect. 2.4), we trained an otherwise identical model without restricting decoder gradients. In this setup, each decoder can backpropagate its reconstruction loss through all latent dimensions.
Correlations of latent features with atmospheric parameters, without selective gradient flow.
Table C.1 reports the average absolute Pearson correlation coefficients between each latent feature and the stellar parameters, computed over multiple random realizations of training and validation sets when selective gradient flow is not applied. The corresponding differences in correlations obtained with and without selective gradient flow are shown in Fig. C.1.
We observe that: (i) the mapping between each latent and its nominal chemical abundance (e.g., zM with [Fe/H]) becomes weaker; (ii) off-diagonal correlations (e.g., zC vs. [Fe/H], zM vs. [C/Fe]) increase, indicating stronger mixing of chemical information across latent dimensions; and (iii) the dispersion of these correlations across random realizations is larger, implying that the latent to abundance mapping is less stable from run to run.
The average relative L2 error on the validation set is slightly lower in this case (0.004 vs. 0.006 with selective gradient flow). This can be explained by the additional freedom gained when gradient constraints are removed, allowing the model to further minimize the reconstruction loss.
We conclude that disabling selective gradient flow improves raw reconstruction but undermines both the interpretability and the robustness of the latent axes: they become more entangled and less repeatable across random seeds. As expected, selective gradient control therefore promotes a clearer and more stable mapping between latent features and their targeted chemical abundances, at the cost of a negligible penalty in reconstruction quality.
Appendix D Spectral regions
In this appendix, we report the spectral regions associated with each decoder, selected based on the presence of strong lines or bands characteristic of each corresponding element. Table D.1 presents the regions for the α-elements decoder, while Table D.2 shows the regions for the carbon decoder.
Target spectral regions for the α-elements decoder.
 |
Fig. C.1 Correlation gains induced by selective gradient flow. Gain in correlations when the model is trained with and without selective gradient flow (SGF and no SGF, respectively), color-coded according to the legend. The shaded areas highlight the latent feature associated with each chemical label. Positive values for the corresponding feature, combined with negative values for the others, indicate that selective gradient flow has a strong positive impact. |
Appendix E Abundance estimation from learned representations
While not intended as a replacement for supervised models (at least not yet), we assess the capabilities of our representation to perform direct abundance estimation. To do so, and to provide context for its performance, we compare it with The Cannon (Ness et al. 2015), a widely used supervised method for abundance analysis (e.g., Wheeler et al. 2020; Walsen et al. 2024; Manea et al. 2024). We adopt this method because of its simplicity and fast training, which makes it well suited for a quick sanity check. More complex deep-learning methods (e.g., astroNN) require substantial training and tuning, which are outside the scope of this work.
Target spectral regions for the carbon decoder.
We trained The Cannon on 1 000 randomly selected spectra (with the same S/N as used in our VAE experiments) using exact, unperturbed labels, and evaluated it on a test set of 1 000 random spectra. The resulting root mean squared errors (RMSEs) for [Fe/H],[C/Fe], and [α/Fe] are 0.26, 0.14, and 0.35 dex, respectively. Our representation learning model, by contrast, is trained in a self-supervised fashion with no access to chemical abundance labels. It is, however, conditioned on stellar parameters (Teff and log g), which are treated as known inputs during training. Using then a simple supervised univariate linear regression from the learned latent features to chemical abundances, we obtained lower RMSEs of 0.21 dex for [Fe/H], 0.08 dex for [α/Fe], and 0.31 dex for [C/Fe].
In fairness to The Cannon, we note that it must simultaneously learn all stellar labels–including Teff and log g-while our method disentangles chemical information directly from spectra under the assumption that these physical parameters are already known. In our approach, we first learn a latent representation conditioned on Teff and log g, and abundance prediction is performed only afterward via a separate regression step. Moreover, we used The Cannon with default settings and a randomly selected training set; with more careful tuning or data selection, its performance is likely to improve.
Regardless, despite the simplicity of the regression step and the absence of chemical labels during representation learning, our model achieves competitive performance in abundance estimation–even with a simple univariate linear regressor that can, in principle, be trained on as few as two labeled examples per abundance. The regression step primarily serves to rescale each latent feature into dex, effectively acting as a lightweight calibration. Although this is not a direct comparison-due to differing assumptions and training setups-these results highlight the potential of our method to support chemical abundance estimation in regimes where supervision is sparse.
Appendix F Effect of S/N and training set size on reconstruction error
Variational autoencoders are known to act as denoising models: the low-dimensional latent bottleneck prevents the network from memorizing high-dimensional random noise and forces reconstructions to lie close to the underlying data manifold. This implies that, when trained on a large enough number of noisy spectra, the model should still recover cleaner representations than the inputs themselves.
 |
Fig. F.1 Reconstruction error as a function of training set size for spectra with S/N ∼ 20 (blue) and ∼ 100 (pink). |
 |
Fig. G.1 LAMOST DR10 normalized spectra with highest reconstruction errors. |
 |
Fig. G.2 Latent-abundance relations for the learned representation for LAMOST spectra. Contour plot of latent features (from left to right, zM, za, zC) and their corresponding chemical abundances for LAMOST spectra. The scatter points represent individual data points, and the contour lines represent data density, with lighter contours indicating regions of higher density. In red we show the 20 spectra with largest reconstruction errors. |
To verify this property in our setting, we trained the model separately on spectra with low S/N (∼ 𝒩(20, 4)) and high S/N (∼ 𝒩(100, 20)), and evaluated the reconstruction error with respect to the corresponding clean synthetic spectra (before noise was added) as a function of training set size. The results are shown in Fig. F.1: blue for training with low-S/N data, and pink for high-S/N. In both cases, the reconstruction error remains below the input noise variance, confirming that the model does not reproduce random fluctuations. The denoising effect becomes stronger with larger training sets, as the manifold is more densely sampled, but is already visible with small datasets. We also note that the reconstruction error for models trained on low-S/N spectra never reaches the level achieved with high-S/N training, indicating that while the model learns cleaner representations than the noisy inputs, it does not completely ignore the noise. Moreover, this experiment assumes purely Gaussian noise; real observations may contain additional systematics or non-Gaussian effects that could further affect reconstruction quality. In this context, advanced strategies such as data augmentation or explicit noise modeling could help the model disentangle signal from noise better and reduce the performance gap between low- and high-S/N regimes, although exploring these directions is beyond the scope of the present work.
Appendix G An experiment on LAMOST data
To test the applicability of our method to real survey spectra, we performed an experiment on LAMOST DR10 low-resolution (LRS) data (Cui et al. 2012). We selected stars with no spectral flags and required that the first 250 flux points (corresponding to the bluer part of the spectrum) have S/N>20. We adopted stellar parameters Teff, log g,[Fe/H], and [α/Fe] from the LAMOST stellar parameter pipeline (LASP, Wu et al. 2014), restricting the sample to Teff ∈[3000, 7000] K, log g ∈[2.5, 6] dex, and relative errors on Teff below 3%.
After correcting the spectra for radial velocity, we interpolated them onto a common grid between 4000 and 9000 Å. This selection resulted in a sample of ∼ 40000 stars. For carbon abundances (not provided by LASP), we adopted convolutional neural networks-derived labels from Liu et al. (2025). We used the same model and wavelength regions as in the synthetic experiments (see Sect. D), excluding regions outside the LAMOST coverage. Training the model from scratch on this dataset, we evaluated the same diagnostics as in the synthetic case:
The average relative L2 error is 0.013, very close to the value obtained for synthetic noisy spectra (0.014; in the main body of the paper we reported the error with respect to the original, unperturbed spectra). Figure G.1 shows the input spectra of the stars with the largest reconstruction errors. Many of these spectra display strong artifacts that were not flagged in the survey pipeline, suggesting that additional quality cuts or artifact removal would improve training. Importantly, the model also retains its capability to recognize anomalous spectra, as discussed in Sect. 4.4, where high reconstruction errors naturally highlight outliers and artifacts.
The auxiliary latent space w retains predictive power for Teff and log g, with RMSE of ∼ 0.12, compared to 0.11 in the synthetic case. These values are computed on features rescaled to zero mean and unit variance, so they should be interpreted in relative rather than absolute physical units.
The latent dimensions correlate with LAMOST metallicities, α-element abundances, and the CNN-derived carbon abundance, though less strongly than in the synthetic experiments. Specifically, zM correlates with [Fe/H] at r ≈ 0.89, zα with [α/Fe] at r ≈ 0.65, and zC with [C/Fe] at r ≈ 0.40. Figure G.2 illustrates these relations, highlighting in red the 20 spectra with the largest reconstruction errors. While the relation between zC and [C/Fe] is noisy, stars with higher [C/Fe] values still occupy the high end of zC, indicating that the model might still be extracting some meaningful carbon information. We note, however, that individual abundance measurements in LAMOST–particularly those derived from external CNN-based estimates-can be subject to biases (e.g., Ho et al. 2017) and substantial uncertainties, which may contribute to the weaker observed correlation. In contrast, [Fe/H] is typically the most reliable abundance measurement in low-resolution surveys, as it is constrained by numerous features and is the primary calibration target of most survey pipelines, which likely explains its stronger correlation with zM.
In this test, we found that stopping training at ∼ 1000 iterations gave the best results. While additional hyper-parameter tuning might further improve performance, this is outside the scope of the present work.
Overall, the model can be trained successfully on real low-resolution survey data, achieving reconstruction quality comparable to the synthetic case. The experiment also highlights the importance of careful data selection and validation: enforcing S/N cuts (especially in the blue), filtering out spectra with artifacts (as seen in the largest-error cases), and checking survey products such as continuum normalization and object type classifications. The weaker correlations between latent features and abundances likely reflect limitations in the survey-derived labels themselves, which vary in reliability across elements and pipelines. This does not diminish the utility of the synthetic experiments presented in the main text, which provide a controlled proof of concept. Rather, it shows that fully exploiting and validating such methods on real survey data requires additional care in sample selection, artifact handling, label reliability and hyper-parameter tuning.
All Tables
Correlations of latent features with atmospheric parameters, without selective gradient flow.
All Figures
|
Fig. 1 Main model. A spectrum is given as input. An encoder maps it to the latent space, divided into chemical latent space z=(zM, zC, zα), and auxiliary latent space w. Three decoders map different components of z, along with w, to separate regions of the input spectrum. A linear transform is applied to the auxiliary space to obtain (Teff, log g). The discriminator is trained to predict the nonchemical parameters (Teff, log g) from z, while the encoder is trained to make this impossible for the discriminator to predict these parameters from z alone. The dotted gray arrows represent the absence of gradient propagation (see Sect. 2.4). At inference time the decoders, the discriminator and the linear transform module are discarded. |
| In the text | |
|
Fig. 2 Abundance distributions for the simulated stellar sample. PDFs for the chemical abundances used to sample the stellar properties in our dataset, with lighter colors indicating higher probability densities. Left panel: PDF of [C/Fe] versus [Fe/H]. Right panel: PDF of [α/Fe] vs. [Fe/H]. In both panels, the pink contours show the abundance distributions of halo stars from the APOGEE survey, as provided by the astroNN catalog. APOGEE does not reach the lowest metallicities present in our simulated dataset, which explains the differences at low [Fe/H]. |
| In the text | |
|
Fig. 3 Representative reconstructions. Comparison of original (before noise perturbation, blue) and reconstructed spectra (pink) for three chemical types: an α-poor, metal-poor star (top row), a CEMP star (middle row), and a solar-like star (bottom row). The residuals (reconstructed minus original) are shown in red in the bottom subpanels. The shaded regions highlight spectral domains handled by the different decoders, as indicated in the legend. |
| In the text | |
|
Fig. 4 Latent-abundance relations for the learned representation. Contour plot of latent features (from left to right, zM, zα, zC) and their corresponding chemical abundances. The scatter points represent individual data points, and the contour lines represent data density, with lighter contours indicating regions of higher density. Straight lines show linear fits to the latent-abundance relations for stars in three Teff bins, as indicated in the legend. |
| In the text | |
|
Fig. 5 Distribution of stars in the true chemical space. Left panel: [C/Fe] vs. [Fe/H]. Right panel: [α/Fe] vs. [Fe/H]. The color represents the predicted class, with blue indicating stars not flagged as enhanced and/or depleted, and pink indicating those flagged as enhanced and/or depleted. The pink-highlighted regions indicate the approximate boundaries for α PMP and CEMP stars, as described in Sect. 2.5, where α PMP stars are defined by [α/Fe]<0.0 and [Fe/H]<−1.0, and CEMP stars by [C/Fe]>0.7 and [Fe/H]<−1.0. |
| In the text | |
|
Fig. 6 Abundance-prediction residuals as a function of S/N. Residuals [X̃]−[X], defined as the difference between the abundance predicted via linear regression from the latent features (zM, zα, zC) and the true values, shown as a function of S/N. From left to right: [Fe/H],[α/Fe], and [C/Fe]. Red markers indicate the mean residuals in bins of S/N (with width 10, ranging from 15 to 85), and the error bars show the standard deviation within each bin. |
| In the text | |
|
Fig. 7 Latent space norms for normal and anomalous spectra. Distribution of the Euclidean norm of the latent representation for stellar spectra (blue) and anomalous data (pink). The clear separation between these distributions indicates that the network distinguishes true spectral features from noise. |
| In the text | |
|
Fig. C.1 Correlation gains induced by selective gradient flow. Gain in correlations when the model is trained with and without selective gradient flow (SGF and no SGF, respectively), color-coded according to the legend. The shaded areas highlight the latent feature associated with each chemical label. Positive values for the corresponding feature, combined with negative values for the others, indicate that selective gradient flow has a strong positive impact. |
| In the text | |
|
Fig. F.1 Reconstruction error as a function of training set size for spectra with S/N ∼ 20 (blue) and ∼ 100 (pink). |
| In the text | |
|
Fig. G.1 LAMOST DR10 normalized spectra with highest reconstruction errors. |
| In the text | |
|
Fig. G.2 Latent-abundance relations for the learned representation for LAMOST spectra. Contour plot of latent features (from left to right, zM, za, zC) and their corresponding chemical abundances for LAMOST spectra. The scatter points represent individual data points, and the contour lines represent data density, with lighter contours indicating regions of higher density. In red we show the 20 spectra with largest reconstruction errors. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.