Fig. 1
Download original image
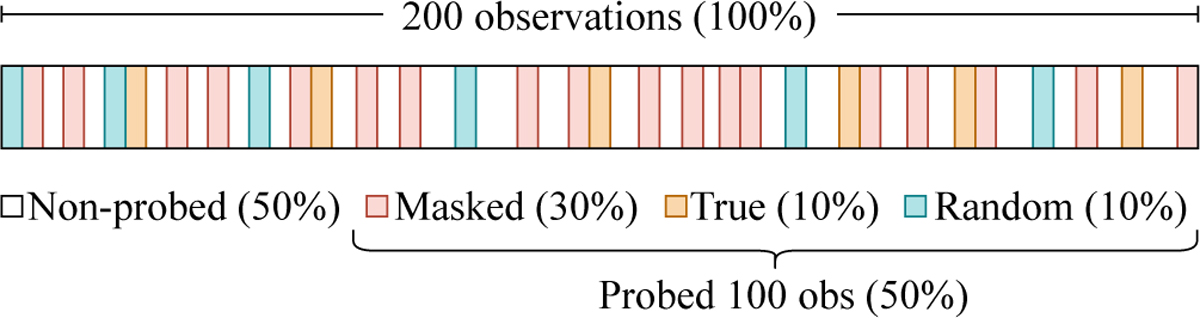
Self-supervised masking strategy used for pretraining. For each light curve, 50% of the observation points are selected as the probed subset, which the model must predict. This subset consists of three components: 30% of the points are fully masked (hidden), 10% are replaced with random magnitudes, and 10% remain visible. This strategy forces the model to learn from context rather than simply memorizing positions.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.