Table C.1
Compilation of the granulation background model specific priors used for the three prescriptions in Table 1.
| Model specific fit parameters | Model J | Model H | Model T |
|---|---|---|---|
| Correlated-inference setup (Sect. 3.1) | |||
| σa | –Samples a freely as below– | lognormal 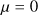 |
lognormal 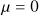 |
| σb | 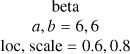 |
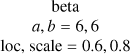 |
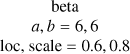 |
| σd | 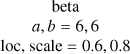 |
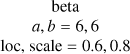 |
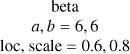 |
| Free variable inference | |||
| a | 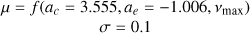 |
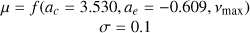 |
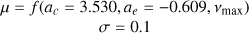 |
| b | 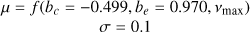 |
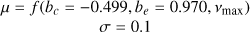 |
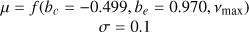 |
| d | 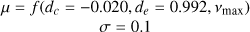 |
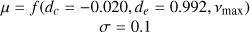 |
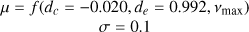 |
| Universal parameter priors | |||
| c | – | 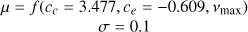 |
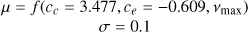 |
| e | – | – | lognormal 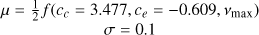 |
| f | – | – |  |
| l | 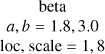 |
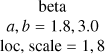 |
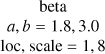 |
| k | 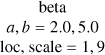 |
beta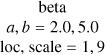 |
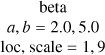 |
| m | – | – | beta 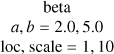 |
1 Amplitude prior for model J follows the prescription in Larsen et al. (2025).
2 Shape parameters a(m), b(m) set according to bounds such that mode lies just above vmax.
Notes. The log-space coefficients for the power law f (constant, exponent, vmax)=constant+log10(vmax)exponent are specified directly when used and originate from Kallinger et al. (2014), except for the amplitude a of model J which is from Larsen et al. (2025). When the prior uses vmax as input, it is the observed value obtained as specified in Sect. 2.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.