Fig. 2.
Download original image
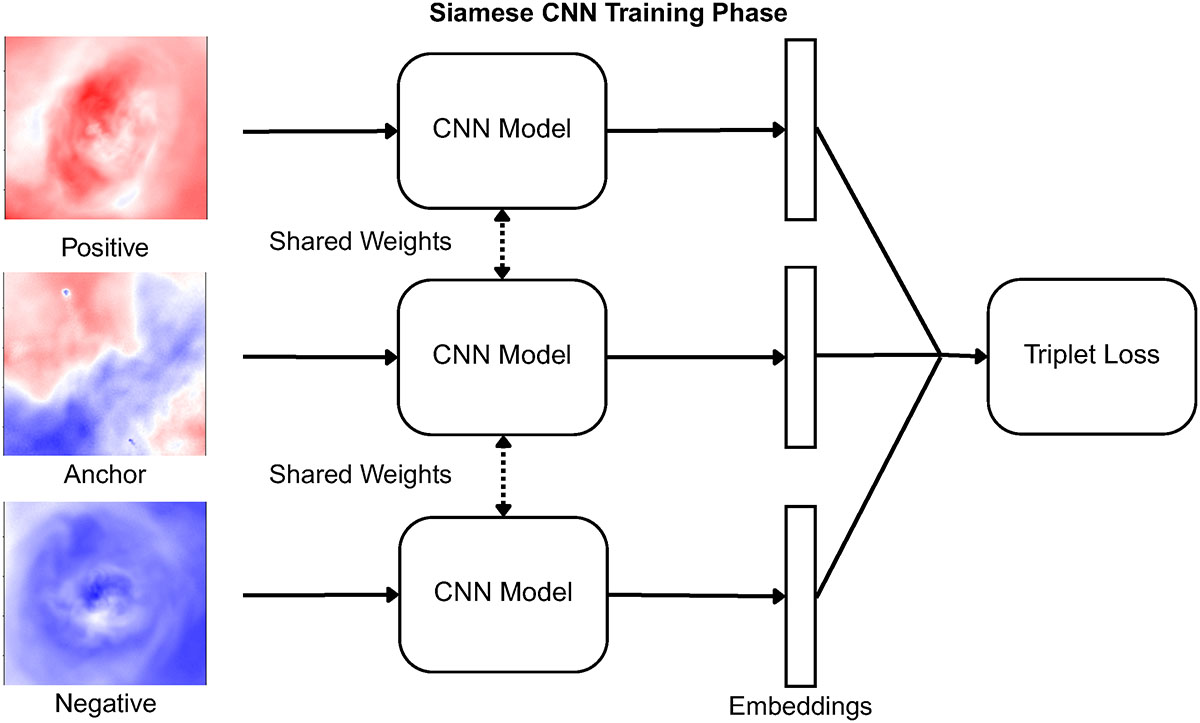
Diagram of the Siamese CNN training phase. During training, triplets of velocity maps are passed through identical CNN encoders with shared weights. Each triplet consists of a reference (Anchor), a matched projection from the same simulated cluster (Positive), and a mismatched projection from a different simulated cluster (Negative). The network learns to produce similar embeddings for the Anchor–Positive pairs and dissimilar embeddings for the Anchor–Negative pairs by minimizing the triplet loss. This process teaches the model to recognize the underlying kinematic structure of clusters, independent of projection and resolution differences.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.