| Issue |
A&A
Volume 704, December 2025
|
|
|---|---|---|
| Article Number | A155 | |
| Number of page(s) | 17 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202554880 | |
| Published online | 11 December 2025 | |
Astrophotometric search for massive stars in the Milky Way
Confronting random forest predictions with available spectroscopy
1
Departamento de Astronomía, Universidad de La Serena,
Avenida Juan Cisternas 1200,
La Serena,
Chile
2
European Southern Observatory,
Karl-Schwarzschild-Str. 2,
85748
Garching,
Germany
3
Anton Pannekoek Institute for Astronomy, University of Amsterdam,
Science Park 904,
1098
XH
Amsterdam,
The Netherlands
4
Instituto de Física y Astronomía, Universidad de Valparaíso,
Avenida Gran Bretaña 1111,
Valparaíso,
Chile
5
Gemini Observatory, NSF’s NOIRLab,
Av. J. Cisternas 1500 N,
1720236
La Serena,
Chile
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
31
March
2025
Accepted:
26
August
2025
Abstract
Massive stars play a significant role in different branches of astronomy, from shaping the processes of star and planet formation to influencing the evolution and chemical enrichment of the distant universe. Despite their high astrophysical significance, these objects are rare and difficult to detect. With Gaia’s advent, we now possess extensive kinematic and photometric data for a significant portion of the Galaxy that can unveil, among others, new populations of massive star candidates. In order to produce bonafide bright (G magnitude <12) massive-star candidate lists (threshold set to spectral type B2 or earlier but with slight changes in this threshold also explored) in the Milky Way subject to be followed up by future massive spectroscopic surveys, we developed a Gaia DR3 plus literature data based methodology. We trained a balanced random forest (BRF) with the spectral types from the Skiff compilation as labels. Our approach yields a completeness of ~80% and a purity ranging from 0.51 ± 0.02 for probabilities between 0.6 and 0.7, up to 0.85 ± 0.05 for the 0.9–1.0 range. To externally validate our methodology, we searched for and analyzed archival spectra of moderate- to high-probability (p > 0.6) candidates that are not contained in our catalog of labels. Our independent spectral validation confirms the expected performance of the BRF, spectroscopically classifying 300 stars as B3 or earlier (due to observational constraints imposed on the B0–3 range), including 107 new stars. Based on the most conservative yields of our methodology, our candidate list could increase the number of bright massive stars by ~50%. As a byproduct, we developed an automatic methodology for spectral typing optimized for LAMOST spectra, based on line detection and characterization that guides a decision path.
Key words: methods: data analysis / methods: statistical / techniques: spectroscopic / catalogs / surveys / stars: early-type
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
It is commonly agreed that the galactic stellar mass distribution peaks at ~0.5 M⊙, and that its shape has a certain universality (Bastian et al. 2010). However, the slopes toward the higher and lower mass ends are still under debate. Despite their lower numbers in our Galaxy, the effect of massive stars (M > 8 M⊙) on their surroundings is critical. These stars play a fundamental role in astrophysics, from shaping the processes of star and planet formation (Bally & Zinnecker 2005) to providing us with key knowledge of the distant universe (Eldridge & Stanway 2022). In terms of direct outcomes, massive stars can produce a wide range of phenomena, such as Type II supernovae (Smartt 2009), neutron stars, black holes (Heger et al. 2003), and gamma-ray bursts (Izzard et al. 2004; Nakar 2007), and due to their high multiplicity fraction (Sana et al. 2012; Moe & Di Stefano 2017; Barbá et al. 2017), they are sources of gravitational waves (Schneider et al. 2001).
Observational classification of stars regarding their mass cannot be directly achieved (as the mass is not an observable). However, classification systems such as the MK (Morgan & Keenan 1973) aim to map observables (spectral types) to masses. This system is anchored with a set of standard stars, and classification relies on comparing spectral morphology with these standards. The system focuses on the blue part of the optical spectrum, which historically were the regions of highest sensitivity in photograph plates (Pickering 1890; Walborn 1972; Gray & Corbally 2009; Sota et al. 2011, 2014). Regarding massive stars, the 8 M⊙ boundary corresponds to spectral type B2 for dwarfs (V), B5 for giants (III), and B9 for supergiants (Ia/Ib, Morgan 1951; Gray & Corbally 2009; Maíz Apellániz et al. 2024).
Focusing mostly on the Milky Way, extensive efforts have been made to identify and spectroscopically classify massive stars. These include, among others, targeted studies (Sota et al. 2011; Simón-Díaz et al. 2011a,b; Maíz Apellániz et al. 2013; Sota et al. 2014; Simón-Díaz et al. 2015; Li 2021), specialized compilations such as Pantaleoni González et al. (2021), and broader spectral type compilations (Skiff 2014). Combined, these works yield a total of ~7500 stars spectroscopically classified as B2 or earlier.
This low figure has been subject of a heated debate for several decades. Kroupa & Weidner (2003) reported an apparent lack of massive stars in the field when compared to their relative number with respect to late-type stars in clusters. This finding is supported by observational studies such as Rybizki & Just (2015); however, due to the low number and nonhomogeneous distribution of high-mass stars, the slope of the mass function above 10 M⊙ is an extrapolation. One possible explanation for the apparent deficit of field massive stars is provided by the integrated galaxy initial mass function theory (Kroupa et al. 2024), but see Cerviño et al. (2013b) and Cerviño et al. (2013a) for statistical counterarguments. It is therefore necessary to obtain more complete and robust censuses of high-mass stars.
Astronomy is undergoing a transformative phase with an unprecedented influx of data from large-scale surveys. The Gaia mission with its Data Release 3 (Gaia DR3, Gaia Collaboration 2023) has delivered six-parameter astrometric data for nearly 900 million stars. This information will soon be complemented by upcoming spectroscopic surveys, for instance, the 4-metre Multi-Object Spectroscopic Telescope (4MOST) (de Jong et al. 2016; de Jong et al. 2019), the WHT Enhanced Area Velocity Explorer (WEAVE) (Jin et al. 2024), and the Sloan Digital Sky Survey-V (SDSS-V) (Kollmeier et al. 2019). Additionally, VLT/MOONS (Gonzalez et al. 2022) will be equipped with 1000 fibers, significantly more than any existing near-infrared spectrograph. Therefore, to fully and efficiently exploit these extensive capabilities, it is essential to inform the surveys with the most robust candidate lists.
Within this context, Zari et al. (2021) presented a comprehensive catalog of hot, luminous stellar candidates with estimated spectral types from O to A in the Milky Way. An immediate goal of the work was to provide robust candidates for an SDSS-V follow-up (Kounkel et al. 2023). The candidate catalog consisted of ~990 000 sources with G < 16 mag selected with Gaia Early Data Release 3 (Gaia eDR3; Gaia Collaboration 2021) photometry and astrometry and Two Micron All Sky Survey (2MASS; Skrutskie et al. 2006) photometry. The sample was designed to be more complete than pure with a reported purity of 20% for stars with temperatures consistent with spectral type B7V.
In this work, we present a supervised machine-learning approach designed to improve the yield of massive star candidates with spectral types B2 or earlier in the Milky Way. The method builds on an updated version (fully Gaia DR3) the selection criteria proposed by Zari et al. (2021). In order to validate our approach, we mined spectroscopic archival data for our candidates. As a byproduct, we derived a decision path for the classification of low-resolution spectra of massive star candidates. The path relies on the equivalent width and the presence or absence of specific spectral lines.
This paper is organized as follows: in Section 2, we describe the parental catalog along with its characteristics, and we describe the sources of spectroscopic labels. In Section 3, we explain the methodology employed to identify moderate- to high-probability candidates. In Section 4, we present the BRF results and the moderate- to high-probability candidates of spectral type B2 or earlier. In Section 5, we discuss the validation of our methodology, including external spectroscopic diagnostics and the comparison with databases and catalogs specialized to massive stars. Finally, in Section 6, we present the conclusions and summarize the main results of this work.
2 The data
2.1 OBA GDR3: Parental catalog
The Zari et al. (2021) catalog consisted of sources in Gaia Data Release 2 (Gaia DR2, Gaia Collaboration 2018) crossmatched with 2MASS (see Section 2.1 of Zari et al. 2021). Posterior to the matching, the authors updated the Gaia photometry and astrometry to those of the Gaia Early Data Release 3 (Gaia eDR3, Gaia Collaboration 2021). Their selection criteria filtered stars brighter than G < 16 mag, and then applied simple photometric cuts to select stars of approximate spectral type OBA.
To define our parental catalog, we took advantage of the availability of Gaia DR3 and the existing Gaia DR3–2MASS crossmatch1. We applied their selection function to this updated release. From now on, we refer to this catalog as OBA GDR3, which contains 1 016 743 entries, ~3% more than OBA GR2. This difference maps naturally to the difference in “seed” catalog as Gaia DR3, as a whole, contains ~7% more sources than Gaia DR2.
Figure 1 presents a color–color diagram of the entire G < 16 mag population in Gaia DR3, together with the OBA GDR3 subsample corresponding to a slightly updated version of Fig. 2 in Zari et al. (2021).
 |
Fig. 1 Recreation of the color–color diagram of Zari et al. (2021) adapted to the full DR3 from Gaia. The entire population brighter than Gmag < 16 is shown in black, while the OBA GDR3 astrophotometric sample is depicted in red. In this plot, it is easy to distinguish that the brighter stars occupy specific positions in the color–color diagram. |
2.2 OBA GDR3: Features description
We used photometric, astrometric, and color information as features in our analysis. Regarding photometry, the Gaia bands (G, GBP, and GRP) covered the optical domain and the 2MASS ones (J, H, and Ks), the near-infrared. In addition, we considered 15 color indexes resulting from the combination (differences) of pairs of photometric bands. The astrometric parameters considered were parallax (![Mathematical equation: $\[\bar{\omega}\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq1.png) ), proper motion in right ascension (μα) and declination (μδ) with their respective errors (
), proper motion in right ascension (μα) and declination (μδ) with their respective errors (![Mathematical equation: $\[\sigma_{\bar{\omega}}, \sigma_{\mu_{\alpha}}\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq2.png) , and σμδ).
, and σμδ).
Finally, we incorporated six quality indicators that measure the goodness of fit of the astrometric solution, such as the astrometric_sigma5d_max (ASM), astrometric_excess_noise (AEN), Renormalized Unit Weight Error (RUWE), astrometric_gof_al (AGOFAL), ipd_gof_harmonic_amplitude (IPDGOFHA), and astrometric_excess_noise_sig (AENS). Extreme values of these features have been interpreted in the literature as signs of multiplicity (Belokurov et al. 2020; Dodd et al. 2024). For more detailed information on these parameters, refer to the Gaia Data Release 3 documentation2.
2.3 OBA GDR3: Spectral type compilation
The aim of this work is to identify reliable early type candidates based on the features presented in the previous section. We tackled this problem as a supervised classification one with a taxonomy based on spectral types. Obviously, not all objects in the OBA DR3 catalog have spectral type determinations, but a subset do and those compose the “universal truth” that we want to propagate with our methodology. The spectral types are referred to as “labels” from now on, and we used two sources for them: the spectroscopic catalog from Skiff (2014), hereafter referred to as Skiff, and the wider and very commonly used database, SIMBAD (Wenger et al. 2000). We note that SIMBAD is a manually curated survey that may include mismatches and fall behind the current literature; however, it is the most complete stellar database available at present.
To assign labels to the entries of the OBA GDR3 catalog, we performed two independent crossmatchings: to SIMBAD and Skiff. In both cases, we kept every entry from OBA GDR3 and employed a 2″ radius for coordinate matching.
Regarding multiple counterparts, over 95% of targets in SIMBAD had a one to one correspondence in the defined radius, and hence, in case of multiple-match, we opted to use as “true” counterpart, the closest target in terms of angular distance. The situation was drastically different in the matching with Skiff, where over 70% of the targets have indeed multiple counterparts. This was expected, as Skiff, by construction, does not prevent multiple entries for the same astrophysical object, in Sect. 2.3.2 we present our approach to dealing with duplications.
2.3.1 Numerical encoding
The labels provided in Skiff and SIMBAD are alphanumerical quantities that we proceeded to encode in numerical tuples to preserve the ordered relation of the labels (an O stars is closer in properties to a B star than to an A and so forth). These encodings are used in Section 3 to train the model and revised in Section 5.3 to assess possible limitations.
For the first element of the tuple, the letter, O to M, was mapped to integer values in increments of 10, ranging from 0 to 60. If a subtype was reported in either catalog, its integer value (0–9) was added. Otherwise, in cases where a subtype was not present, an integer was sampled from a uniform distribution of possible values and then added. For instance, a star classified only as type B was initially encoded as 10. We then sampled a random integer from 0 to 9; if the result was 1, the final encoded label was set to 11, corresponding to B1. We noticed that this may introduce noise in the labels; however, this uncertainty with the subspectral types only affects 1.6% of the labels.
In addition, whenever uncertain values or ranges (e.g., B9/A0, F1–F3) were reported, the individual encoding for the extremes was computed and used as the inclusive limits for a distribution to be uniformly sampled. It must be noted that this sampling artificially “produces” spectral types for which no spectra of standard stars may exist (Maíz Apellániz et al. 2024). However, the classifier (presented in Sect. 3) will be trained on a lightened binary taxonomy “earlier or later than B2,” and hence this (ease of computation motivated) artifact can be neglected. Finally, when the uncertainty in the spectral classification spanned more than one main spectral type (e.g., OB), the label was saved as a known label but excluded from the training, while targets with reported composite spectral types (such as kA2hA9mF23) were discarded. Although Table A.1 provides the full encoding of the spectral types here described, when training the random forest classifier we simplified our labels to two: 0 for encoded spectral type > 12 (“negative” class), and 1 for encoded spectral type ≤12 (“positive” class).
Since the different elements used as attributes among themselves (photometry and kinematics) and labels are not coetaneous, for objects exhibiting extreme variability this could pose some source of noise in the modeling. However, we expect the number of such cases to be negligible. For example, the fraction of extreme variability cases reported in the VISTA Variables in the Via Lactea (VVV) survey (Minniti et al. 2010) is below 10−5% (Lucas et al. 2024).
2.3.2 Addressing repeated entries
While the (2″radius) crossmatch of OBA GDR3 data with Skiff may yield multiple entries for the same astronomical sources, either due to different sources or to multiple spectral classifications of the same source, the crossmatch with SIMBAD does not. Thus, in order to faithfully compare both crossmatched datasets against each other in the following subsection, we first performed an internal match within the Skiff-correlated set with respect to its astrometric coordinates, as to identify and group multiple records that describe the same object. The match threshold criterion was a maximum radius of 2″ of angular distance. For each group, we computed the mean and standard deviation of their spectral type encodings. Specifically, grouped entries with standard deviation values greater than 1.0, 3.0, and 5.0 (i.e., 1, 3, and 5 units of spectral subtype) were discarded, resulting in three filtered sets. This standard deviation will hereafter be referred to as σliterature·
2.3.3 Comparing the two sources of labels
We compared SIMBAD and Skiff in detail to assess the differences between these two databases. Fig. 2 shows the number of spectral types recorded in Skiff and SIMBAD, considering the previously discussed σliterature. We collected spectral type information for approximately 55 000 stars, which represented 5% of the OBA GDR3 sample. In all cases, SIMBAD contains more stars with spectral type information than Skiff. For O stars in Skiff, the number increases by 30% when the σliterature threshold rises from 1 to 3 and by 5% when it increases from 3 to 5, with a similar trend observed for other spectral types. Based on this, we adopt a 3 − σliterature threshold for grouping Skiff data, achieving a balance between robustness and sample size.
The complete description of the encoding for the luminosity class can be found in Appendix A. In Fig. 3, however, we do incorporate this information in the comparison between SIMBAD and Skiff to offer a complete view. As can be seen in the figure, both databases exhibit a similar distribution, with dwarfs being the most abundant class. However, there is a discrepancy in the number of subgiants (class IV), due to uncertainties in the luminosity classifications in Skiff (e.g., IV/V or V/IV), which are encoded as intermediate between these classes (see Section 2.3.1). When combined with the binning process used in the histogram, these uncertainties result in a higher contribution for subgiants.
Figure 4 compares the labels identified for the same object in the two databases for those cases where the luminosity class is in agreement. We included various dispersion metrics for comparison: the mean absolute error (MAE), root mean square error (RMSE), coefficient of determination (R2), Pearson correlation coefficient (r), and Spearman’s rank correlation coefficient (ρ), available in Pedregosa et al. (2011). The MAE and RMSE were 0.36 and 0.91, respectively, with differences remaining below one spectral subtype unit. The other metrics were very close to 1, confirming a strong correlation between the two databases and indicating that they were highly comparable.
We identified a few outliers above the bulk of the data and investigated them using both the SIMBAD and Skiff databases. In most cases, we could not retrieve the reference listed in SIMBAD. In a few others, we found misreferences in Skiff or more updated spectral classifications in one of the two databases. We did not exclude them from our analysis, since all these stars are later than B2 and represent only a very small fraction of the labeled data.
Given this strong correlation, we ultimately decided to use the Skiff database for our analysis. This choice is motivated because approximately ~1000 objects in SIMBAD lack references for their spectral types; ~7000 objects potentially suffer from suboptimal astrometry, with a positional precision of 8–12″ compared to the ~1″ coordinate precision guarantee in Skiff. Finally, Skiff ensures spectroscopic origins for its compilation, whereas SIMBAD does not. Although it was possible to combine classifications from both databases to increase the sample size, this approach could have introduced additional dispersion or variance due to the inclusion of objects classified through different techniques.
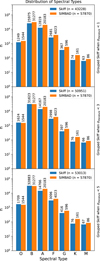 |
Fig. 2 Distribution of OBAFGKM spectral types for Skiff and SIMBAD. The subplots from top to bottom correspond to different σliterature thresholds for Skiff (see text). |
 |
Fig. 3 Distribution of luminosity classes for Skiff and SIMBAD. The luminosity class reported for Skiff is based on a σliterature threshold of 3. |
 |
Fig. 4 Comparison of spectral types for Skiff and SIMBAD. The different colors represent luminosity classes. Only luminosity classes that coincide in both databases were considered. |
2.3.4 Simplification of encoded labels and adopted threshold
We simplified the encoded labels into more global and representative categories. Since the fundamental truth sample is meant to provide “standard examples” of each class, we filtered out phase-dependent spectral types (e.g., OBe), stellar spectra with reported uncertainties in the classification, and non-MK classifications (e.g., Wolf-Rayet stars, white dwarfs, planetary nebulae, and carbon stars; see Table 1). Additionally, “em” designations were removed, as they lack information about the primary spectral type. Lastly, we excluded the ~2000 systems reported in the catalog as multiples, due to the limited number of cases (only 2%) in which spectral types for both components are provided. This decision could be seen as at odds with the fact that multiplicity is known to scale with primary mass. However, the uncertainty introduced by the lack of individual spectral types (and hence across the period – mass-ratio parameter space) for these systems was deemed detrimental to the training process.
The “boundary” between massive and not massive stars is not a simple cut in terms of spectral type for B stars, as the luminosity class has to be considered. However, more than half of the available encoded labels lack this information. Promoting purity over completeness, we set B2 as the threshold, as this spectral type corresponds to a massive star across all luminosity classes (Maíz Apellániz et al. 2024).
3 Methodology: Balanced random forest
In this section, we discuss the simplification of the encoded labels introduced in Section 2.3 and the features detailed in Section 2.2 to address the classification of massive stars as a supervised learning problem. We applied a balanced random forest (BRF), suitable for handling imbalanced training datasets (Chen et al. 2004). We trained the BalancedRandomForestClassifier method from the imbalanced-learn4 using the simplification of the encoded labels from Skiff within the OBA GDR3 sample and applied the classification to the unlabeled data.
3.1 Preprocessing features
We removed sources with NaN values in any feature or duplicate J, H, and Ks photometry. The percentage of duplicate sources using the tmass_oid identifier was 0.013%. Then, we defined the minimum and maximum values for each feature by calculating the 1st and 99th percentiles of the encoded labeled data. We only selected the pool of new candidates that fell within these boundaries. This ensured that all unlabeled candidates were within the specified feature restrictions, as shown in Table C.1.
We aimed to quantify how representative the OBA encoded labeled data are with respect to the pool of new candidates for each feature. In Fig. 5, we present a similarity test using the Wasserstein distance5 between these samples. In Fig. 6, we show the cumulative number of sources per bin of G magnitude.
The similarity test was normalized between the maximum and minimum distance for each bin of magnitude. The most distinct feature across all magnitude bins was AENS, followed by ![Mathematical equation: $\[\sigma_{\bar{\omega}}\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq3.png) , the second most important feature for the model (see Section 4). This feature reached a minimum at G = 11 mag and began to increase for both bright and faint stars. From Fig. 6, we observed that for bright stars (G = 10 mag), the number of OBA encoded labeled sources at G = 10 mag is limited, which may explain the larger distance in this magnitude bin. For fainter stars, starting around G ≈ 12, there was no noticeable increase in the cumulative number of OBA encoded labels. This suggested a bias in the labeled sample toward brighter stars, making extrapolation to fainter magnitudes uncertain. To be more conservative, we selected stars brighter than Gmag ≤ 12 as a compromise between completeness and purity. The final sample consisted of 99 388 stars up to G = 12 mag, of which 35 465 had spectral types and 63 923 were unlabeled.
, the second most important feature for the model (see Section 4). This feature reached a minimum at G = 11 mag and began to increase for both bright and faint stars. From Fig. 6, we observed that for bright stars (G = 10 mag), the number of OBA encoded labeled sources at G = 10 mag is limited, which may explain the larger distance in this magnitude bin. For fainter stars, starting around G ≈ 12, there was no noticeable increase in the cumulative number of OBA encoded labels. This suggested a bias in the labeled sample toward brighter stars, making extrapolation to fainter magnitudes uncertain. To be more conservative, we selected stars brighter than Gmag ≤ 12 as a compromise between completeness and purity. The final sample consisted of 99 388 stars up to G = 12 mag, of which 35 465 had spectral types and 63 923 were unlabeled.
 |
Fig. 5 Normalized Wasserstein distance between the OBA encoded labels and the pool of new candidates for each feature per G-band magnitude. Each feature is shown in gray, while the four most important features for the model (see Section 4) are highlighted in red. |
 |
Fig. 6 Cumulative number of sources for different G-band magnitude cuts for the OBA encoded labels and the pool of new candidates. |
Number of classifications excluded.
3.2 Metrics
We evaluated the model’s performance using Recall, Precision, F1-score, Geometric Mean, and Index Balanced Accuracy (IBA). In the text, we refer to completeness and purity as recall and precision, respectively. The last two metrics, designed for imbalanced datasets, were taken from the imbalanced-learn package (Lemaître et al. 2017)6. The IBA incorporates any metric (M) and allows emphasis on specific classes through a weighting parameter (α). These metrics helped assess model construction, final classification, and comparison with other models. The metrics are presented as follows:
![Mathematical equation: $\[\text { Recall }=\frac{T P}{T P+F N},\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq4.png) (1a)
(1a)
![Mathematical equation: $\[\text { Precision }=\frac{T P}{T P+F P},\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq5.png) (1b)
(1b)
![Mathematical equation: $\[\text { F1 Score }=2 \times \frac{\text { Precision \times Recall }}{\text { Precision }+ \text { Recall }} \text {, }\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq6.png) (1c)
(1c)
![Mathematical equation: $\[T N R=\frac{T N}{T N+F P},\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq7.png) (1d)
(1d)
![Mathematical equation: $\[{ Dom }={ recall }-T N R,\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq8.png) (1e)
(1e)
![Mathematical equation: $\[G\text{-}{ mean }=\sqrt{\text { Recall } \times T N R},\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq9.png) (1f)
(1f)
![Mathematical equation: $\[I B A_\alpha(M)=(1+\alpha \cdot D o m) \cdot M,\]$](/articles/aa/full_html/2025/12/aa54880-25/aa54880-25-eq10.png) (1g)
(1g)
where TP is the number of true positives, FP the false positives, FN the false negatives, and TN true negatives. See Sections 3.3 and 4.1 for the use and results of these metrics.
3.3 Building the model
The random forest (RF) is a tree-based algorithm that consists of an ensemble of decision trees (Breiman 2001). Each tree is constructed using a random subsample with replacement (a bootstrap sample) from the training set, and the final prediction is determined by a majority vote among all the trees.
The structure of a decision tree consists of a root node, internal nodes, and terminal (leaf) nodes. Data are classified based on decision rules inferred from features at different levels, from the root node (level 0) to the terminal nodes (maximum depth). A terminal node is reached when all training examples within it belong to the same class. These components are defined by hyperparameters: n_estimators indicates the number of decision trees, max_features denotes the subset of features used to determine the best split at each node, and max_depth sets the limit for recursive division.
Traditional RFs show high performance in different problems. However, they underperform on highly imbalanced datasets since bootstrap samples often underrepresent the minority class. Instead, we used the balanced random forest (BRF), a variation of RFs that modifies the sample distribution to ensure equal class representation in each tree. We selected the BRF from the Imbalanced-learn module, which offers various under-sampling strategies for bootstrapping: “majority,” “not minority,” “not majority,” “all,” and “auto.” We tested independent strategies for binary classification: majority, not majority, and all.
To optimize BRF construction, we used Grid Search CV with stratified k-fold cross-validation. This method systematically explores hyperparameter combinations from a predefined grid. It divides the data into “k” folds, using “k-1” folds for training and the remaining fold for testing. We used a 5-fold stratified cross-validation and selected the IBA combined with Gmean2 as the scoring metric, setting α = 0.1, as recommended in García et al. (2012). Table 2 presents the tested and optimal hyperparameters.
Hyperparameters tested for the random forest and the best value.
4 Results: Candidates from BRF
In the following, we discuss the built model and the preprocessed features used to train a BRF and extend the classification to the unlabeled data. We also present the performance metrics of the algorithm and the moderate to high-probability massive-star candidates.
4.1 Performance of the BRF
We defined the BRF using the best combination of hyperparameters and evaluated the performance of the model roughly following Sánchez-Sáez et al. (2021). We created 20 random permutations of the training and test sets using StratifiedShuffleSplit from scikit-learn, allocating 80% of the data for training and 20% for testing in each permutation. This corresponded to 28 372 sources in the training set and 7093 in the test set per split. Across the full dataset, 4393 sources were classified as B2 or earlier, and 31 072 as later than B2. Subsequently, we trained 20 BRFs, each on a separate splitting iteration using the training sample, and evaluated their performance with the respective test sets. We used a probability threshold of 0.6, above which stars are classified as spectral type B2 or earlier. We did not include oversampling techniques, as the ratio between the majority and minority classes is approximately seven, significantly lower than the ~42 reported in the original SMOTE paper (Chawla et al. 2002).
Figure 7 summarizes the results obtained for the 20 random permutations for each test set. TP, TN, FP, and FN values are averaged over these permutations, with the error defined as their standard deviation. We obtained a TN fraction of ~88% and an FP fraction of ~12%. The TP fraction was ~80%, while the FN fraction was ~20%. We measured a standard deviation of 0.47% for stars with spectral type later than B2, lower than that of stars with spectral type B2 or earlier.
Figure 8 shows the variations of the relevance of each feature in the deciding power of the 20 models. When the randomness of the different models is taken into account, the relevance of most features is indistinguishable, with two exceptions: the parallax and the parallax over error.
The H–G color was the least informative for the model’s performance, although it traces the slope of the stellar spectrum. We explored this effect using the spectral energy distributions (SEDs) of 100 nearby sources (<1kpc) with high predicted probabilities of spectral type B2 or earlier. These SEDs were fit using VOSA (Bayo et al. 2008), allowing extinction to vary freely within the catalog provided limits. The results showed that H–G is highly degenerate with extinction, which explains its low relevance with respect to effective temperature.
We trained the final BRF classifier using a single data split, motivated by the small variation observed in the confusion matrices across different k-folds. All features were used to train the model, which was then applied to classify the OBA candidates in GDR3. We used 80% of the data for training and 20% for testing, applying the best hyperparameters from Table 2. Fig. 9 shows the kernel density estimates (KDE) for our test sets by metric. The left panel presents the BRF probability, while the right panel displays its distribution across spectral types. The TN peak was near 0.15, transitioning smoothly from lower probabilities before distorting as it approached 0.5, where the model had the highest classification confusion. For stars with probabilities above 0.6, TP and FP clearly overlapped. In the right panel, the metrics were associated with the spectral type, with the TN peak corresponding to A0 stars, while the FP peak was centered around B5 stars.
The peak in FP around spectral type B5 might be explained by the subtleties in spectral classification. The main spectroscopic difference between a B5 and a B2 star is the disappearance of silicon lines (very weak absorption features), accompanied by a strengthening of the Mg II 4481 line. Given that it is informed only with photometry (“even worse”, broad band photometry), the model has not been exposed to data that traces such subtle differences and, therefore, struggles to distinguish between these spectral types.
Table 3 presents the performance metrics for the test sets. We observe high recall for stars with spectral types later than B2 and B2 or earlier. While precision remains high for stars later than B2, it is lower for B2 or earlier stars, indicating a high fraction of false positives. Fig. 10 shows how precision improves at higher probability thresholds. In addition, as noted in Section 2.3, the classification of massive stars based on spectral type is a working approximation, typically set at B2 or earlier. However, some authors, such as Zinnecker & Yorke (2007) (see Table 1), have considered B3 or earlier stars as massive. Therefore, we also presented the results using this alternative threshold in Appendix B. Finally, this trade-off between high completeness and lower purity can be addressed, as the final classification of massive stars requires spectroscopic confirmation.
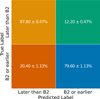 |
Fig. 7 Confusion matrix for stars earlier than B2 and later than B2. The confusion matrix was obtained by generating 20 distinct training and testing sets, and training independent models on each. After training, the models were applied to their respective testing sets. We report the mean and standard deviation across all testing sets. |
4.2 Moderate to high-probability massive-star candidates
From the sample of 99 388 stars with G ≤ 12 mag, we classified the 63 923 unlabeled candidates using the BRF. We show the galactic distribution of our candidates in Fig. 11. The colors indicate the probability of classification as a star with spectral type B2 or earlier. We observed that the highest probabilities are more concentrated near the Galactic plane, even without RA and Dec coordinates as input for the algorithm.
Figure 12 shows the probability distribution for Em, OB, and OBe stars, which are the most abundant simplified encoded labels that were not included in the training or test sets. The distributions for OB and OBe stars are skewed toward higher probabilities, reflecting their predominance as early-type stars. In contrast, the Em distribution shows two peaks at low and high probabilities, suggesting the presence of both early- and late-type stars with emission. These trends suggest that the simplification of the encoded labels captured the global phenomenon without an evident systematic pattern for phase-variable spectral types.
Other spectral classes not considered in the training were excluded due to the feature space cuts applied during sample construction. As a result, we do not have a statistically significant number of objects from these classes to evaluate model performance reliably. In addition, assessing the classifier’s performance on Be stars is difficult because the Gaia and 2MASS photometry, the labels, and the spectroscopic data are nonsimultaneous. Since emission lines are time-dependent features, this prevents us from drawing reliable conclusions. However, we expect Be stars to show distinct patterns in the Gaia feature space (Radley et al. 2025).
From the ~100 000 stars analyzed, we identified 9089 moderate to high-probability massive-star candidates (probability >0.6) that were not included in our encoded labeled dataset. According to Table 3, this threshold corresponds to an expected precision of ~0.5 for identifying massive stars. Based on the FP and TP rates shown in Fig. 9, we expect the FP to be centered around B5 stars. This sample is more than twice the number of massive stars used for the development of the model, significantly expanding the set of potential massive stars and representing a valuable target for spectroscopic follow-up.
 |
Fig. 8 Feature importance for the BRF, sorted by significance. The importance is calculated as the mean and standard deviation of the accumulated reduction in variance across all trees and individual splitting iterations. |
 |
Fig. 9 Kernel density plots for the metrics in the test set. The left panel shows the distribution in the probability of the BRF. The right panel shows the distribution of the different spectral types. |
Performance metrics for the test sets.
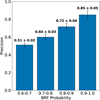 |
Fig. 10 BRF precision for the test set in detecting B2 or earlier stars at different probability thresholds. |
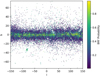 |
Fig. 11 Galactic distribution of the candidate samples. This shows the distribution of stars outside our encoded labeled sample. The color represents the probability of an object being a star with spectral type B2 or earlier. |
5 Discussion
5.1 Multiplicity considerations
The process of simplification of the numerical encoding of labels discussed in Section 2.3.4, implied the removal of multiple systems. However, as previously mentioned, multiplicity is a very common feature of massive stars (Offner et al. 2023). In order to assess the performance of our (singled source trained) algorithm in detecting multiple systems with a massive primary, we analyzed the predictions of the model for a sample of 29 confirmed binaries from the Skiff catalog. The number of systems was limited, as we only considered multiple systems that were not used in the previous analysis.
Figure 13 shows the spectral type of the primary stars against the BRF probability, with the spectral type of the secondary indicated by color. Systems with mass ratio (q ~ 1) have similar spectral types and are therefore expected to exhibit similar colors. We observe that most systems with a massive primary and q~ 1 are identified by our methodology as massive indeed. On the other hand, the recovery efficiency is not 100% as two systems with a B primary and a close to 1 mass ratio lie just below threshold probability. With this small test we can assess that, although we introduced a bias removing multiples from the training set, this does not seem to have a very strong effect (barring the small numbers of the experiment) in correctly predicting multiples with a massive primary.
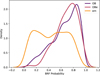 |
Fig. 12 Kernel density plots for labeled data left out from our label codification. |
 |
Fig. 13 BRF probability of binary systems as a function of the primary’s spectral type. The spectral type of the secondary components is indicated by different colors. |
5.2 Homogeneous validation dataset: LAMOST spectroscopy
We searched for spectral information in the Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST, Zhao et al. 2012) to validate the classifier performance. This survey can obtain 4 000 spectra in one exposure for a limiting magnitude of 19 in r band and a spectral resolving power R ~ 1800 around the g band. It has a Field of View (FoV) larger than 20 square degrees and a fiber scale of 3.3″ on the focal plane. The last public data release (DR10)7 contained low-resolution spectra for 11 100 139 stars, covering approximately −10° < DEC < 89°, making it a valuable database for large-scale spectroscopic studies.
5.2.1 Automatic spectral classification
We found 1066 spectra in LAMOST within a 5″radius for the moderate to high-probability massive-star candidates, considering all matches. To enhance the precision of our selection, we only considered counterparts located at the intersection of the initial 5″radius and a 5″wide band along the star’s proper motion direction. We discarded 106 spectra that showed anomalous offsets inconsistent with the expected proper motion direction. The final sample contained 880 spectra, from which we identified 585 unique sources. For each source with multiple observations, we retained the spectrum with the highest signal-to-noise ratio (S/N).
To derive spectral types for this sample, we developed an automatic methodology for classifying the low-resolution LAMOST spectra, based on a ground-truth sample of 50 massive standard stars of luminosity class V with spectral types O, B, and A collected from Didelon (1982); Sota et al. (2011); Maíz Apellániz et al. (2016); Martins (2018). The ground-truth spectra were obtained using the High-Efficiency and highResolution Mercator Echelle Spectrograph (HERMES; Raskin et al. 2011) and the Fiber-fed Extended Range Optical Spectrograph (FEROS; Kaufer et al. 1999), with resolutions of 85 000 and 48 000, respectively.
We degraded the high-resolution spectra of standard dwarfs to match LAMOST’s observational capabilities using the specutils package (Earl et al. 2024)8. We applied convolution based smoothing to the spectrum using a Gaussian kernel, reducing the resolution to R~1300, which is the expected resolution for LAMOST at He I λ4471 (see Figure 2 of Zhu et al. 2006), an important line for distinguishing O and B stars. We resampled the flux to the LAMOST dispersion grid while preserving the integrated flux and added normal noise to compensate for the increase in S/N caused by the resolution reduction. We used a Wasserstein distance to compare the S/N distributions before and after adding noise. The distance decreased from 0.008 to 0.001, making the S/N of both distributions more similar. In Fig. 14, we show the spectrum of the massive standard star HD 242926, classified as O7Vz (Sota et al. 2011), as observed with HERMES, along with its degraded version at LAMOST resolution. For comparison, we also include the LAMOST spectrum of the O7V((f))z star HD 277878 (Roman-Lopes & Roman-Lopes 2019).
We selected 18 spectral lines used in Kyritsis et al. (2022) and tested those detected in the standard dwarfs with low resolution. For the detection of the lines, we combined the methodology presented in Bayo et al. (2011) and Kyritsis et al. (2022). The first approach detected the continuum of the line in a completely automatic way, while the second one used static spectral windows, taking into account the surroundings of each line.
We present an example of the detection of the He I λ4471 line in Fig. 15, the same procedure was applied to each line. We defined two fixed spectral regions (R1 and R2), in terms of central wavelength and width, to model the continuum, following Kyritsis et al. (2022), and a third one to trace the line (hereafter, the “line region”). An initial estimate of the continuum was derived from a linear fit to the R1 and R2 regions. This continuum was then refined by applying a one-sigma clipping. Once the final local continuum was identified, we assessed the significance of a detection by comparing the flux within the line region to the dispersion of the continuum. We subtracted the continuum and considered a detection whenever the peak of the line (defined as the 95 percentile of the flux distribution) was above 5 sigma.
We calculated the equivalent width (EW) of the line if it was detected. We considered that the line follows a Gaussian profile and calculated the associated σ. We performed three types of line fitting to characterize different scenarios: isolated line, blended line, and core emission line using a single Gaussian fit, a double Gaussian fit, and double inverted Gaussian fit, respectively. We selected the best fit using the Bayesian Information Criterion (BIC). This criterion is useful for model selection, giving priority to models with fewer parameters.
The line region was defined as ±4σ around the center of the fitting model. We found that this threshold provided the best separation between the He I λ4471 and Mg II λ4481 lines in early-type stars when these lines are not blended. For consistency, the same criterion was applied to all other lines. Finally, we calculated the EW over the measured flux (not the fit line), within the line region.
We applied the automatic methodology to characterize line detection in low-resolution spectra of dwarf massive standard stars. For a given spectral line, its detection can be influenced by the S/N of the spectra. To quantify the impact of S/N on line detection, we selected S/N values sampled from the distribution of moderate- to high-probability candidates and assessed the corresponding detections in the low-resolution spectra of massive dwarf standard stars.
We performed 20 iterations, each using a different S/N value. In each experiment, we calculated the detection rate for all lines across the sample. The resulting matrix, shown in Fig. 16, reports the mean and standard deviation of the detection rates for each spectral type and line. This results are highly compatible with the results from Kyritsis et al. (2022). The He I lines are clearly identified in B-type stars, while the He II lines are systematically observed in O-type stars. The Si lines remain challenging to detect in both studies.
From this matrix, we selected the following lines for classification: He I λ4471, Mg II λ4481, He I λ4144, He II λ4541, He II λ4686, Fe II λ4233, He I + He II λ4026. These lines are consistent with the expected spectral types, and based on them, we created an empirical decision path to classify the LAMOST spectra. It is important to note that we are only able to spectroscopically confirm stars of type B3 or earlier, due to the difficulty of detecting silicon lines at this resolution using an automatic approach, as illustrated in Fig. 16 and in agreement with Kyritsis et al. (2022).
Figure C.1 summarizes the empirical decision path using automated line detection to classify O and early B stars. The first selection focused on He II λ4686 and He II λ4541, as these lines were consistently present in O stars. To minimize false positives due to the S/N in B-type stars, we applied a strict detection criterion for both lines. We then used the detection and EW ratio of He I λ4471 and Mg II λ4481, which is useful to classify helium-normal stars later than B3 (Gray & Corbally 2009), with a ratio near 1 for B6-B7 stars (Ramírez-Preciado et al. 2020). The Mg II λ4481 line was consistently detected from B3 to A1, while He I λ4471 became undetectable from B9 onward and was almost always absent in A1 stars. We combined the detection of He I + He II λ4026, which is always present in O and B stars, with the detection of He I λ4144, primarily observed up to B3. For stars later than A1, we used the Fe II λ4233 line, characteristic of A1 stars, and kept the designation "later" since we did not include spectra of standard stars of later types.
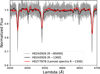 |
Fig. 14 Massive standard star HD 242926, classified as O7Vz, shown at high resolution (grayline) and degraded to LAMOST resolution (black line), compared to the O7V((f))z star HD 277878, observed by LAMOST (red line). |
 |
Fig. 15 Automatic method to detect the continuum of the He I λ4471 spectral line. The points used to estimate the reference continuum are indicated in gray. In red, full circles represent the points used to estimate the final local continuum. The Q95 (in purple) is used to determine if the peak or absorption exceeds 5σ above the continuum. |
5.2.2 Estimated spectral types for the validation dataset
We applied the automatic methodology and empirical decision path to classify the LAMOST spectra of moderate to high-probability massive-star candidates. Fig. 17 presents the classification percentages, while Fig. 18 illustrates examples of spectra classified with an S/N in the g band detection in SDSS of approximately 250. We classified 57.2% of the sample as massive stars. Approximately 19.6% were misclassified as mid B-type stars (B4–B7). The results could improve by considering the luminosity class; however, developing an automated methodology for luminosity classification is beyond the scope of this work. We refer to Negueruela et al. (2024) for the standard classification of B stars. Additionally, 16% of the sample corresponds to stars later than type A, representing the lower limit of the model’s misclassification.
Figure 19 illustrates the number of stars classified into different spectral type groups, separated by the probability assigned by the BRF. At the top of each bar, we present the detection rate of massive stars, calculated as the percentage of the O-B0 and B0-B3 groups relative to all other spectral types within each probability interval. The detection rates align with the expected precision of 0.564 ± 0.009 for detecting B3 or earlier spectral types, as shown in Table 3. We observe that the detection rate increases with higher probabilities, while the total number of classified stars decreases. This reduction in moderate- to high-probability candidates is due to the selection function of the LAMOST survey, which does not cover the Galactic center, where a higher concentration of massive star candidates is expected.
 |
Fig. 16 Percentage of undetected lines across different spectral types of massive standard stars. For each iteration, we used a random sample of S/N values from the distribution of S/Ns in LAMOST candidates. We present the mean detection rate and the standard deviation for 20 iterations. |
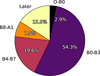 |
Fig. 17 Spectroscopic classification percentages of moderate to high-probability massive-star candidates in the LAMOST sample, determined using the automatic methodology and empirical decision path. |
 |
Fig. 18 Examples of spectra from the LAMOST sample, classified into spectral type groups, with an S/N in the G-band detection in SDSS of approximately 250. |
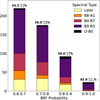 |
Fig. 19 Number of stars classified in different spectral type groups, divided by the probability given by the BRF. The top of each bar shows the detection rate of massive stars. |
5.3 Comparison with state-of-the-art massive star databases and catalogs
We selected dedicated studies focused on the spectroscopic classification of massive stars to evaluate the performance of our BRF algorithm. Specifically, we examined the IACOB spectroscopic database (Simón-Díaz et al. 2011a), GOSSS (Maíz Apellániz et al. 2013), Chini et al. (2012), Li (2021), and the ALS compilation (Pantaleoni González et al. 2021). Within a 2″search radius, we identified 124, 36, 17, 29, and 831 stars, respectively, that were not included in our training or test sets.
Figure 20 presents the probability distribution for different studies. The GOSSS and Li (2021) samples are more concentrated at high probabilities, as they consist exclusively of O-type stars. In the GOSSS sample, we classified all stars with a probability greater than 0.5, whereas in the Li (2021) sample, we misclassified two O9 stars. The comparison with the Chini et al. (2012), showed the poorest classifier performance, with most misclassifications resulting from intermediate B-type stars present in this sample. Among the five misclassified stars, three were B4 V stars, one was a B2 V star, and one was a B1 III star. In the IACOB and ALS samples, we classified approximately 10% and 20% of the stars, respectively, with probabilities below 0.5. However, not all stars in these studies had luminosity classifications, and some belonged to later B spectral types. In general, the probabilities were high, with a missed detection rate consistent with the algorithm’s expected metrics.
 |
Fig. 20 Probability distribution of the BRF for dedicated studies of massive stars. |
6 Summary and conclusions
In this paper, we presented a moderate- to high-probability catalog of massive star candidates with estimated spectral types B2 or earlier in the Milky Way. We defined our parental catalog using stars with spectral type O to A with astrometry and photometry from Gaia DR3, combined with photometry from 2MASS. We defined a subsample spectroscopically confirmed from the literature to serve as a source of labels. Since the labeled sample is biased toward brighter stars, we restricted our sample to G < 12 mag. In addition, we discarded possible outliers by discarding objects with any feature outside of the 1–99 percentile range.
A BRF classifier was trained on the encoded labeled data, simplifying the taxonomy to “B2 or earlier” or “later than B2” spectral types. The trained model was used to predict spectral types in this binary fashion on the unlabeled sample. The performance of our classifier shows high completeness of 0.8 and a purity ranging from 0.51 ± 0.02 for probabilities between 0.6 and 0.7, up to 0.85 ± 0.05 for the 0.9–1.0 range.
We mined spectroscopic archives for data on our moderateto high-probability candidates (estimated “B2 or earlier spectral type” with P > 0.6). The most homogeneous subsample obtained consisted of 534 objects with available spectra from the LAMOST survey. We developed an automatic methodology to detect the presence and characteristics of spectral lines on a sample of dwarf massive standard stars. Based on the extracted line(s) information, we designed a decision path capable of differentiating stars with spectral types O–B0, B0–B3, B4–B7, B8–A1, and later than A1. Applying this scheme to the 534 validation set, we obtained a confirmation rate of ~54%. We further explored the dependence of this confirmation rate on the probability cut from the model, reaching 83% for P > 0.9. From the validation set (534 sources), to the best of our knowledge, 107 are completely new discoveries.
As a result of our work, we obtain a catalog of ~9000 moderate to high probability (P > 0.6) “B2 or earlier” bright (G<12 mag) stars. From those, 5158 are not present in known massive stars databases (or general databases such as SIMBAD). The remaining, 3931 are not present in our homogeneous set of encoded labels but have been reported in other studies in the literature. The number of new candidates presented in this work (5158) is therefore comparable to the currently known number of stars spectroscopically confirmed with spectral type B2 or earlier, 7500 and 5793 for G < 12 mag, respectively (Simón-Díaz et al. 2011a; Chini et al. 2012; Maíz Apellániz et al. 2013; Skiff 2014; Pantaleoni González et al. 2021; Li 2021). Assuming our metrics hold for the full sample, we expect to increase the known population of massive stars by approximately 50%.
Acknowledgements
We thank the anonymous referee for the helpful comments that improved the quality of this work. We acknowledge the use of TOPCAT (Taylor 2005) and the following Python libraries used in this research: pandas (pandas development team 2020), matplotlib (Hunter 2007), numpy (Harris et al. 2020), ray (Moritz et al. 2017), scikit-learn (Pedregosa et al. 2011), imblearn (Lemaître et al. 2017), astropy (Astropy Collaboration 2013, 2018, 2022), scipy (Virtanen et al. 2020), and specutils (Earl et al. 2024). We acknowledge support from the National Agency for Research and Development (ANID) through the Scholarship Program DOCTORADO BECAS CHILE/2021 – 21211323. A.B acknowledges support from the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC 2094 – 390783311. Based on observations made with the Mercator Telescope, operated on the island of La Palma by the Flemish Community, at the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofísica de Canarias. Based on observations obtained with the HERMES spectrograph, which is supported by the Research Foundation – Flanders (FWO), Belgium, the Research Council of KU Leuven, Belgium, the Fonds National de la Recherche Scientifique (F.R.S.-FNRS), Belgium, the Royal Observatory of Belgium, the Observatoire de Genève, Switzerland and the Thüringer Landessternwarte Tautenburg, Germany. Guoshoujing Telescope (the Large Sky Area Multi-Object Fiber Spectroscopic Telescope LAMOST) is a National Major Scientific Project built by the Chinese Academy of Sciences. Funding for the project has been provided by the National Development and Reform Commission. LAMOST is operated and managed by the National Astronomical Observatories, Chinese Academy of Sciences. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
References
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Bally, J., & Zinnecker, H. 2005, AJ, 129, 2281 [NASA ADS] [CrossRef] [Google Scholar]
- Barbá, R. H., Gamen, R., Arias, J. I., & Morrell, N. I. 2017, in IAU Symposium, 329, The Lives and Death-Throes of Massive Stars, eds. J. J. Eldridge, J. C. Bray, L. A. S. McClelland, & L. Xiao, 89 [Google Scholar]
- Bastian, N., Covey, K. R., & Meyer, M. R. 2010, ARA&A, 48, 339 [Google Scholar]
- Bayo, A., Rodrigo, C., Barrado Y Navascués, D., et al. 2008, A&A, 492, 277 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bayo, A., Barrado, D., Stauffer, J., et al. 2011, A&A, 536, A63 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Belokurov, V., Penoyre, Z., Oh, S., et al. 2020, MNRAS, 496, 1922 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Cerviño, M., Román-Zúñiga, C., Bayo, A., et al. 2013a, A&A, 553, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cerviño, M., Román-Zúñiga, C., Luridiana, V., et al. 2013b, A&A, 553, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. 2002, J. Artif. Intell. Res., 16, 321 [CrossRef] [Google Scholar]
- Chen, C., Liaw, A., Breiman, L., et al. 2004, Univ. Calif. Berkeley, 110, 24 [Google Scholar]
- Chini, R., Hoffmeister, V. H., Nasseri, A., Stahl, O., & Zinnecker, H. 2012, MNRAS, 424, 1925 [Google Scholar]
- de Jong, R. S., Barden, S. C., Bellido-Tirado, O., et al. 2016, in Ground-based and Airborne Instrumentation for Astronomy VI, 9908, eds. C. J. Evans, L. Simard, & H. Takami, International Society for Optics and Photonics (SPIE), 99081O [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- Didelon, P. 1982, A&AS, 50, 199 [NASA ADS] [Google Scholar]
- Dodd, J. M., Oudmaijer, R. D., Radley, I. C., Vioque, M., & Frost, A. J. 2024, MNRAS, 527, 3076 [Google Scholar]
- Earl, N., Tollerud, E., O’Steen, R., et al. 2024, astropy/specutils: v1.19.0 [Google Scholar]
- Eldridge, J. J., & Stanway, E. R. 2022, ARA&A, 60, 455 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Smart, R. L., et al.) 2021, A&A, 649, A6 [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García, V., Sánchez, J., & Mollineda, R. 2012, Knowl. Based Syst., 25, 13 [Google Scholar]
- Gonzalez, O., Cirasuolo, M., Taylor, W., et al. 2022, SPIE Conf. Ser., 12184, 1218412 [Google Scholar]
- Gray, R. O., & Corbally, Christopher, J. 2009, Stellar Spectral Classification [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Heger, A., Fryer, C. L., Woosley, S. E., Langer, N., & Hartmann, D. H. 2003, ApJ, 591, 288 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Izzard, R. G., Ramirez-Ruiz, E., & Tout, C. A. 2004, MNRAS, 348, 1215 [NASA ADS] [CrossRef] [Google Scholar]
- Jin, S., Trager, S. C., Dalton, G. B., et al. 2024, MNRAS, 530, 2688 [NASA ADS] [CrossRef] [Google Scholar]
- Kaufer, A., Stahl, O., Tubbesing, S., et al. 1999, The Messenger, 95, 8 [Google Scholar]
- Kollmeier, J., Anderson, S. F., Blanc, G. A., et al. 2019, in Bulletin of the American Astronomical Society, 51, 274 [NASA ADS] [Google Scholar]
- Kounkel, M., Zari, E., Covey, K., et al. 2023, ApJS, 266, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., & Weidner, C. 2003, ApJ, 598, 1076 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., Gjergo, E., Jerabkova, T., & Yan, Z. 2024, arXiv e-prints [arXiv:2410.07311] [Google Scholar]
- Kyritsis, E., Maravelias, G., Zezas, A., et al. 2022, A&A, 657, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lemaître, G., Nogueira, F., & Aridas, C. K. 2017, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Li, G.-W. 2021, ApJS, 253, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Lucas, P. W., Smith, L. C., Guo, Z., et al. 2024, MNRAS, 528, 1789 [NASA ADS] [CrossRef] [Google Scholar]
- Maíz Apellániz, J., Sota, A., Morrell, N. I., et al. 2013, in Massive Stars: From alpha to Omega, 198 [Google Scholar]
- Maíz Apellániz, J., Sota, A., Arias, J. I., et al. 2016, ApJS, 224, 4 [CrossRef] [Google Scholar]
- Maíz Apellániz, J., Negueruela, I., & Caballero, J. A. 2024, arXiv e-prints [arXiv:2410.07301] [Google Scholar]
- Martins, F. 2018, A&A, 616, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minniti, D., Lucas, P. W., Emerson, J. P., et al. 2010, New A, 15, 433 [Google Scholar]
- Moe, M., & Di Stefano, R. 2017, ApJS, 230, 15 [Google Scholar]
- Morgan, W. W. 1951, Publ. Michigan Observ., 10, 33 [Google Scholar]
- Morgan, W. W., & Keenan, P. C. 1973, ARA&A, 11, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Moritz, P., Nishihara, R., Wang, S., et al. 2017, arXiv e-prints [arXiv:1712.05889] [Google Scholar]
- Nakar, E. 2007, Phys. Rep., 442, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Negueruela, I., Simón-Díaz, S., de Burgos, A., Casasbuenas, A., & Beck, P. G. 2024, A&A, 690, A176 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Offner, S. S. R., Moe, M., Kratter, K. M., et al. 2023, in Astronomical Society of the Pacific Conference Series, 534, Protostars and Planets VII, eds. S. Inutsuka, Y. Aikawa, T. Muto, K. Tomida, & M. Tamura, 275 [Google Scholar]
- pandas development team, T. 2020, pandas-dev/pandas: Pandas [Google Scholar]
- Pantaleoni González, M., Maíz Apellániz, J., Barbá, R. H., & Reed, B. C. 2021, MNRAS, 504, 2968 [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pickering, E. C. 1890, Ann. Harvard Coll. Observ., 27, 1 [Google Scholar]
- Radley, I. C., Oudmaijer, R. D., Vioque, M., & Dodd, J. M. 2025, MNRAS, 539, 1964 [Google Scholar]
- Ramírez-Preciado, V. G., Roman-Lopes, A., Román-Zúniga, C. G., et al. 2020, ApJ, 894, 5 [Google Scholar]
- Raskin, G., van Winckel, H., Hensberge, H., et al. 2011, A&A, 526, A69 [CrossRef] [EDP Sciences] [Google Scholar]
- Roman-Lopes, A., & Roman-Lopes, G. F. 2019, MNRAS, 484, 5578 [CrossRef] [Google Scholar]
- Rybizki, J., & Just, A. 2015, MNRAS, 447, 3880 [NASA ADS] [CrossRef] [Google Scholar]
- Sana, H., de Mink, S. E., de Koter, A., et al. 2012, Science, 337, 444 [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Schneider, R., Ferrari, V., Matarrese, S., & Portegies Zwart, S. F. 2001, MNRAS, 324, 797 [NASA ADS] [CrossRef] [Google Scholar]
- Simón-Díaz, S., Castro, N., Garcia, M., Herrero, A., & Markova, N. 2011a, Bull. Soc. Roy. Sci. Liege, 80, 514 [Google Scholar]
- Simón-Díaz, S., Garcia, M., Herrero, A., Maíz Apellániz, J., & Negueruela, I. 2011b, in Stellar Clusters & Associations: A RIA Workshop on Gaia, 255 [Google Scholar]
- Simón-Díaz, S., Negueruela, I., Maíz Apellániz, J., et al. 2015, in Highlights of Spanish Astrophysics VIII, eds. A. J. Cenarro, F. Figueras, C. Hernández-Monteagudo, J. Trujillo Bueno, & L. Valdivielso, 576 [Google Scholar]
- Skiff, B. A. 2014, VizieR Online Data Catalog, B/mk [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Smartt, S. J. 2009, ARA&A, 47, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Sota, A., Maíz Apellániz, J., Walborn, N. R., et al. 2011, ApJS, 193, 24 [Google Scholar]
- Sota, A., Maíz Apellániz, J., Morrell, N. I., et al. 2014, ApJS, 211, 10 [Google Scholar]
- Taylor, M. B. 2005, in Astronomical Society of the Pacific Conference Series, 347, Astronomical Data Analysis Software and Systems XIV, eds. P. Shopbell, M. Britton, & R. Ebert, 29 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Walborn, N. R. 1972, AJ, 77, 312 [NASA ADS] [CrossRef] [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zari, E., Rix, H. W., Frankel, N., et al. 2021, A&A, 650, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhao, G., Zhao, Y.-H., Chu, Y.-Q., Jing, Y.-P., & Deng, L.-C. 2012, Res. Astron. Astrophys., 12, 723 [NASA ADS] [CrossRef] [Google Scholar]
- Zhu, Y., Hu, Z., Zhang, Q., Wang, L., & Wang, J. 2006, SPIE Conf. Ser., 6269, 62690M [Google Scholar]
- Zinnecker, H., & Yorke, H. W. 2007, ARA&A, 45, 481 [Google Scholar]
ESAC’s external crossmatch catalog service.
This corresponds to A2 for the Ca K-line subtype (k), A9 for the hydrogen-line type (h), and F2 for the metallic-line type (m).
Appendix A Complementary spectroscopic codification
For spectral classifications that contain additional information beyond the spectral type and subtype, such as luminosity class and spectral peculiarities, we provide complementary data in the catalog. This information is included only for targets that were not discarded during the encoding process described in Section 2.3.1. Each luminosity class, from hypergiants to subdwarfs, was assigned an integer value from 0 to 5 (as hypergiants and supergiants were grouped with the value of 0). For intermediate classes (e.g., II-III, II/III) the mean value, rounded to one decimal was adopted (for instance 2.5 was adopted for III/IV). In addition to the tuple, reported spectral peculiarity information was propagated by means of five, not mutually exclusive, flags (uncertain, miscellaneous, line-broadening, emission, and nitrogen/carbon enriched, see Table A.1).
Categories of possible peculiarities.
Appendix B Effects on the spectral type threshold in the BRF
The limit of massive stars can be different depending on the work and on the luminosity class, as we mention in Section 2.3.4. During the body of the work “B2” was used as a threshold. However, in this appendix we show the impact that a slight change in threshold to “B3” would have in our results. To this effect, we trained a new BRF following the same procedure described before but using B3 as the boundary between the two classes. The confusion matrix of this new model is shown in Fig. B.1. In addition, we also performed the same flow described in the text for external validation with LAMOST spectroscopy. The final results of this external validation are shown in Fig. B.2.
Even though the difference in performance of the algorithm is not significant when comparing the two confusion matrices (Figs 7 and B.1), the external validation procedure seems to indicate an underestimation of the contamination in the 0.6-0.7 probability bin for the case where B3 was used as a threshold. Therefore, thresholding with “B2”, provides more robust results.
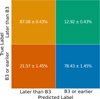 |
Fig. B.1 Confusion matrix for stars earlier than B3 and later than B3. The confusion matrix was obtained by generating 20 distinct training and testing sets, and training independent models on each. After training, the models were applied to their respective testing sets. We report the mean and standard deviation across all testing sets. |
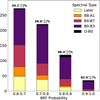 |
Fig. B.2 Number of stars classified in different spectral type groups, divided by the probability given by the BRF using B3 thresholds candidates. The top of each bar shows the detection rate of massive stars. |
Appendix C Spectroscopic classification and astrophotometric Selection Criteria
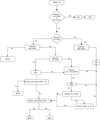 |
Fig. C.1 Empirical decision tree based on the massive standard stars. The decision is based on the detection and EW of the He I, He II, Mg II, and Fe II lines at low resolution (R ~ 1300). |
Minimum and maximum values for different features.
All Tables
All Figures
|
Fig. 1 Recreation of the color–color diagram of Zari et al. (2021) adapted to the full DR3 from Gaia. The entire population brighter than Gmag < 16 is shown in black, while the OBA GDR3 astrophotometric sample is depicted in red. In this plot, it is easy to distinguish that the brighter stars occupy specific positions in the color–color diagram. |
| In the text | |
|
Fig. 2 Distribution of OBAFGKM spectral types for Skiff and SIMBAD. The subplots from top to bottom correspond to different σliterature thresholds for Skiff (see text). |
| In the text | |
|
Fig. 3 Distribution of luminosity classes for Skiff and SIMBAD. The luminosity class reported for Skiff is based on a σliterature threshold of 3. |
| In the text | |
|
Fig. 4 Comparison of spectral types for Skiff and SIMBAD. The different colors represent luminosity classes. Only luminosity classes that coincide in both databases were considered. |
| In the text | |
|
Fig. 5 Normalized Wasserstein distance between the OBA encoded labels and the pool of new candidates for each feature per G-band magnitude. Each feature is shown in gray, while the four most important features for the model (see Section 4) are highlighted in red. |
| In the text | |
|
Fig. 6 Cumulative number of sources for different G-band magnitude cuts for the OBA encoded labels and the pool of new candidates. |
| In the text | |
|
Fig. 7 Confusion matrix for stars earlier than B2 and later than B2. The confusion matrix was obtained by generating 20 distinct training and testing sets, and training independent models on each. After training, the models were applied to their respective testing sets. We report the mean and standard deviation across all testing sets. |
| In the text | |
|
Fig. 8 Feature importance for the BRF, sorted by significance. The importance is calculated as the mean and standard deviation of the accumulated reduction in variance across all trees and individual splitting iterations. |
| In the text | |
|
Fig. 9 Kernel density plots for the metrics in the test set. The left panel shows the distribution in the probability of the BRF. The right panel shows the distribution of the different spectral types. |
| In the text | |
|
Fig. 10 BRF precision for the test set in detecting B2 or earlier stars at different probability thresholds. |
| In the text | |
|
Fig. 11 Galactic distribution of the candidate samples. This shows the distribution of stars outside our encoded labeled sample. The color represents the probability of an object being a star with spectral type B2 or earlier. |
| In the text | |
|
Fig. 12 Kernel density plots for labeled data left out from our label codification. |
| In the text | |
|
Fig. 13 BRF probability of binary systems as a function of the primary’s spectral type. The spectral type of the secondary components is indicated by different colors. |
| In the text | |
|
Fig. 14 Massive standard star HD 242926, classified as O7Vz, shown at high resolution (grayline) and degraded to LAMOST resolution (black line), compared to the O7V((f))z star HD 277878, observed by LAMOST (red line). |
| In the text | |
|
Fig. 15 Automatic method to detect the continuum of the He I λ4471 spectral line. The points used to estimate the reference continuum are indicated in gray. In red, full circles represent the points used to estimate the final local continuum. The Q95 (in purple) is used to determine if the peak or absorption exceeds 5σ above the continuum. |
| In the text | |
|
Fig. 16 Percentage of undetected lines across different spectral types of massive standard stars. For each iteration, we used a random sample of S/N values from the distribution of S/Ns in LAMOST candidates. We present the mean detection rate and the standard deviation for 20 iterations. |
| In the text | |
|
Fig. 17 Spectroscopic classification percentages of moderate to high-probability massive-star candidates in the LAMOST sample, determined using the automatic methodology and empirical decision path. |
| In the text | |
|
Fig. 18 Examples of spectra from the LAMOST sample, classified into spectral type groups, with an S/N in the G-band detection in SDSS of approximately 250. |
| In the text | |
|
Fig. 19 Number of stars classified in different spectral type groups, divided by the probability given by the BRF. The top of each bar shows the detection rate of massive stars. |
| In the text | |
|
Fig. 20 Probability distribution of the BRF for dedicated studies of massive stars. |
| In the text | |
|
Fig. B.1 Confusion matrix for stars earlier than B3 and later than B3. The confusion matrix was obtained by generating 20 distinct training and testing sets, and training independent models on each. After training, the models were applied to their respective testing sets. We report the mean and standard deviation across all testing sets. |
| In the text | |
|
Fig. B.2 Number of stars classified in different spectral type groups, divided by the probability given by the BRF using B3 thresholds candidates. The top of each bar shows the detection rate of massive stars. |
| In the text | |
|
Fig. C.1 Empirical decision tree based on the massive standard stars. The decision is based on the detection and EW of the He I, He II, Mg II, and Fe II lines at low resolution (R ~ 1300). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.