| Issue |
A&A
Volume 708, April 2026
|
|
|---|---|---|
| Article Number | A148 | |
| Number of page(s) | 12 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202658857 | |
| Published online | 03 April 2026 | |
Estimating the peak energy of Swift gamma-ray bursts using supervised machine learning
1
College of Physics and Electronic Information Engineering, Guilin University of Technology, Guilin 541004, China
2
Key Laboratory of Low-dimensional Structural Physics and Application, Education Department of Guangxi Zhuang Autonomous Region, Guilin 541004, China
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
4
January
2026
Accepted:
2
March
2026
Abstract
Gamma-ray bursts (GRBs) are among the most energetic explosive phenomena in the Universe, and their peak energy (Ep) is a key physical quantity for understanding the prompt emission mechanism. However, due to the limited energy coverage of the Swift satellite, a large fraction of Swift GRBs lack reliable peak energy measurements. Therefore, developing an accurate and efficient method for estimating Ep is of great importance. In this work, we propose a method based on the SuperLearner framework that integrates multiple supervised machine learning algorithms to estimate the Ep of Swift/BAT GRBs. We used the Swift/BAT observational data from December 2004 to September 2022 as training features, and adopted the peak energies of 516 GRBs jointly detected by Swift and either Fermi/GBM or Konus-Wind as training labels. After training and testing multiple supervised models, the final SuperLearner ensemble yields a more robust and reliable predictive model. In 100 iterations of five-fold cross-validation, the estimated E′p values show a tight correlation with the observed Ep, with an average Pearson correlation coefficient of r = 0.72. Compared with previous Bayesian estimates, our model provides estimations that are likely closer to the true values. Based on the trained model, we further estimated the peak energies of 650 Swift GRBs, significantly increasing the number of GRBs with estimated peak energies and providing new statistical support for constraining GRB emission mechanisms and energy origins.
Key words: gamma-ray burst: general
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Gamma-ray bursts (GRBs) are among the most energetic and active high-energy transients in the Universe, serving as key probes of extreme physical processes. Their prompt emission directly traces the initial energy dissipation of ultra-relativistic jets, providing insight into jet dynamics and radiation mechanisms. This emission typically exhibits a nonthermal spectrum, which in the νFν representation shows a prominent peak that corresponds to the peak energy (Ep). As a fundamental physical quantity characterizing the spectral properties, Ep reflects the characteristic energy of the radiating particles, encodes information on radiation mechanisms and jet dynamics (Lithwick & Sari 2001; Pe’er & Ryde 2011; Piran 2004), and plays a central role in spectrum-energy correlations. These include the Ep, z − Eiso relation (known as the Amati relation), the Ep, z − Liso relation (Yonetoku relation), and other empirical correlations (Amati et al. 2002; Amati 2006; Wei & Gao 2003; Yonetoku et al. 2004; Ghirlanda et al. 2008; Liang et al. 2015), where Ep, z is rest frame peak energy, Ep, z = Ep(1 + z), and Eiso and Liso are the isotopic energy and peak luminosity of the GRB prompt emission, respectively. Such correlations establish GRBs as potential probes of high-redshift astrophysics and cosmology (Han et al. 2024; Du et al. 2025; Han et al. 2026).
Accurately measuring Ep is challenging. Obtaining a reliable peak energy typically requires broadband spectral coverage – from tens of keV to several MeV – to capture the full spectral shape across both the low- and high-energy ranges. GRB spectra are commonly fitted with a broken power-law (PL) function, typically represented by the Band function (Band et al. 1993), which consists of a low- and a high-energy component. In some cases, the spectra can also be described well by a cutoff power-law (CPL) model. For a subset of GRBs, the high-energy cutoff cannot be detected due to the limited energy range of the instruments, and their spectra are thus fitted with a simple PL model (Sakamoto et al. 2008, 2011), making it difficult to determine the peak energy.
Thanks to the rapid and accurate localization capabilities of the Swift satellite, we now have a large sample of GRBs with measured redshifts, which has enabled a deeper exploration of their intrinsic properties and progenitors, including the evolution of their early afterglows. However, the Swift Burst Alert Telescope (BAT) operates in a relatively narrow energy range of 15–150 keV, which is significantly lower than the typical GRB prompt emission energies (tens of keV to several MeV; Gruber et al. 2014; Bošnjak et al. 2014). As a result, Swift is often unable to provide reliable constraints on the spectral parameters during the prompt emission phase. Specifically, owing to the inherent limitations of the BAT detector, the spectra of a large fraction of Swift GRBs can only be modeled using a PL function (Zhang et al. 2007b; Sakamoto et al. 2006). In such cases, the observed photon index (Γ) merely reflects the spectral slope along the tail of the Band function rather than the intrinsic low-energy index (α), thereby obscuring the spectral curvature around the peak energy and precluding a reliable determination of their peak energies. When Swift GRBs are jointly detected by other broadband instruments such as Konus-Wind or Fermi Gamma-ray Burst Monitor (GBM), their spectra can typically be fitted with the Band function; however, such joint detections account for only a small fraction of the Swift sample. Therefore, obtaining reliable estimates of Ep for Swift GRBs has long been a major challenge but is crucial for systematically investigating the intrinsic radiation mechanisms of GRBs.
Several studies have attempted to estimate Ep using empirical correlations involving the spectral index (Virgili et al. 2012; Zhang et al. 2007a; Sakamoto et al. 2006) or spectral hardness (Cui et al. 2005; Zhang et al. 2007b; Shahmoradi & Nemiroff 2010). These works typically combine observations from multiple instruments to construct more reliable estimation models. However, linear relations constructed from only two parameters often exhibit large intrinsic scatter and strong sample dependence. In contrast, Butler et al. (2007) introduced a Bayesian approach that incorporates additional observational parameters and prior knowledge, yielding more accurate estimates of Ep. More recently, Li & Wang (2024) exploited the spectral curvature within the BAT band to infer lower limits on Ep for bursts with Ep > 150 keV, providing a complementary pathway when direct constraints are unavailable.
However, traditional methods for estimating Ep are generally constrained by their reliance on crude, low-dimensional empirical correlations. To overcome this limitation, we seek methods capable of incorporating richer observational information and capturing the complex, nonlinear relationships between GRB observables and Ep. With the rapid advancement of data-driven techniques, machine learning (ML) provides precisely such capabilities and has been increasingly applied in astrophysics (Rodriguez et al. 2022; Fotopoulou 2024; Wang et al. 2025), including for the classification of transient sources such as GRBs (Chen et al. 2024; Zhu et al. 2024, 2025a,b) and fast radio bursts (FRBs; Luo et al. 2023; Sun et al. 2025, 2026), as well as the estimation of GRB redshifts (Aldowma & Razzaque 2024; Narendra et al. 2025). ML thus offers a flexible framework for modeling such high-dimensional dependences. In this work, we focus on Swift GRB observations and apply supervised ML models to estimate Ep from multiple observable features.
The ML framework used in this study includes several base learners – random forest, extreme gradient boosting, linear regression, and kernel ridge regression – which, after extensive training, exhibit good stability and reliable generalization. These models were then integrated using the SuperLearner ensemble method, which assigns optimal weights based on cross-validated performance. This strategy has proven highly effective for estimating the redshifts of active galactic nuclei and GRBs (Dainotti et al. 2021; Narendra et al. 2022; Dainotti et al. 2024, 2025), enabling the ensemble to exploit the complementary strengths of individual algorithms and achieve higher predictive accuracy.
In Sect. 2 we describe the sample and the data selection criteria used in this work. In Sect. 3 we present the selection of predictive parameters, the dataset partitioning strategy, and a detailed discussion of the training and optimization of the supervised ML algorithms. Section 4 reports the main estimation results and compares the performance of the SuperLearner ensemble method with other approaches to estimating the peak energy of Swift GRBs. Finally, Sect. 5 summarizes our work.
2. Data sample selection
2.1. Data
Since 2004, Swift/BAT has continuously monitored the sky, providing a large dataset for GRB studies. In this work, we selected BAT observations from December 2004 to September 2022, retrieved from the Swift archive1, comprising a total of 1557 GRBs (hereafter referred to as the BAT sample). Among them, 229 GRBs can be well fit with the CPL model and have reliably determined Ep values; these GRBs were therefore excluded from our generalization sample. The remaining 1328 GRBs can only be fitted with a PL model and lack measured Ep values.
For training the ML models, we used Ep values from GRBs simultaneously observed by Swift and the broadband instruments Fermi/GBM and Konus-Wind. The Fermi/GBM sample includes GRBs detected between June 2008 and September 2022 that are temporally coincident with Swift triggers and have consistent sky positions (RA/Dec), with data obtained from the online Fermi GRB catalog2. The Konus-Wind sample consists of GRBs observed concurrently with Swift between December 2004 and September 2022, with data primarily drawn from Svinkin et al. (2016) and Tsvetkova et al. (2017, 2021). For both Fermi and Konus-Wind spectra, only GRBs whose spectra are best fitted by the Band or CPL functions were selected to ensure the reliability of Ep values.
2.2. Feature selection and dataset partitioning
Based on previous experience, to ensure that supervised ML algorithms achieve stable and reliable generalization performance, it is necessary to use sufficiently large and balanced training samples. To satisfy these requirements while ensuring that basic observational parameters are available for each GRB, we selected four physical parameters from the BAT sample as input features for training: spectral index (Γ, obtained from simple PL fits), peak flux (Fp), fluence (Sγ), and duration (T90; hereafter, these four observational parameters are referred to as “input features”). GRBs lacking any of these four parameters were excluded, resulting in the removal of 162 GRBs. The final BAT sample thus contains 1166 GRBs with complete observational data, of which only 516 are simultaneously detected by Fermi or Konus-Wind and have reliable Ep measurements (248 observed by Fermi and 268 observed by Konus-Wind).
The sample was ultimately divided into a training set and a generalization set. The training set was used to train the ML models, enabling them to acquire stable and reliable generalization capability, while the generalization set was employed to estimate the originally unknown Ep values using the trained models. Specifically, the training set consists of 516 GRBs with reliable Ep measurements and corresponding BAT observational parameters, including 470 long GRBs (LGRBs) and 46 short GRBs (SGRBs), which are listed in Table 1. The generalization set comprises 650 GRBs lacking Ep values but possessing complete observational data, including 591 LGRBs and 59 SGRBs.
List of the 516 BAT GRBs in the training set (extract).
It is worth noting that ML models typically require the training data to exhibit approximately normal distributions. To better satisfy this condition, all three input features except Γ were used in logarithmic form. The parameter distributions for the training and generalization sets are displayed in Fig. 1. From this figure, we find that the training set tends to have larger Fp and Sγ values and smaller Γ values compared to the generalization set, while the distributions of T90 appear broadly similar between the two sets. The distribution of Ep for the 516 GRBs in the training set is presented in Fig. 2.
 |
Fig. 1. Distributions of the four input quantities, Γ, T90, Sγ, and Fp, for the training set (blue region) and the generalization set (orange region). |
 |
Fig. 2. Distribution of Ep in the training set. |
In addition, to better illustrate the relationships among the parameters in the training set, we present their correlation matrix in Fig. 3. The results show that Γ exhibits the strongest negative correlation with Ep (Pearson’s r = −0.69), followed by Fp (r = 0.13) and T90 (r = −0.12). Beyond linear correlation analysis, Fig. 4 shows the relative feature importance derived from the random forest algorithm, which reflects the contribution of each input feature to the model’s learning and estimation of Ep (see the next section for training details). The results indicate that Γ is the most informative feature, providing the dominant contribution to the estimation of Ep. In comparison, the other three parameters have weaker and relatively similar importances, with T90 ranking second among them.
 |
Fig. 3. Correlation heatmap of various parameters in the training set. |
 |
Fig. 4. Feature importance scores trained by the random forest algorithm, reflecting the relative importance of the four input features in the random forest training set. |
3. Methodology
3.1. ML algorithms
To obtain reliable estimates of Ep using supervised ML algorithms, we first trained the models on the training set. To maximize model accuracy and ensure stable generalization, each algorithm was trained 100 times via random data resampling: in each iteration, 80% of the training set was used for model fitting, while the remaining 20% served as a validation set (hereafter referred to as the test set). We evaluated model performance by comparing the estimated E′p with the known Ep in the test set, using the root-mean-square error (RMSE) and the Pearson correlation coefficient. This procedure was repeated 100 times, and the average results were used to assess model accuracy. Notably, each of the 100 random resampling iterations involved independent model training, ensuring that the evaluation was not affected by information leakage between different subsets and thus providing an unbiased assessment of model performance.
In the second step, the trained ML models were applied to estimate Ep in the generalization set. We ultimately employed the SuperLearner technique to combine multiple trained models into a single ensemble, leveraging the strengths of each model to generate the estimated E′p values. The individual estimations were then aggregated to produce the final estimates, which allowed the SuperLearner to achieve greater accuracy than any single algorithm alone. The ML algorithms used in this work are listed below:
-
The random forest algorithm is an ensemble method based on decision trees. It constructs multiple independent decision trees, each trained separately, and combines their outputs to improve the accuracy of the final prediction (Breiman 2001). Random forest has been widely applied in both classification and regression tasks, particularly excelling in handling high-dimensional and complex data. In addition, the algorithm is sensitive to outliers and requires careful consideration when evaluating feature importance and handling missing data. An important aspect of using random forest is selecting the optimal tree depth and the number of trees according to the complexity and structure of the data.
-
The Extreme Gradient Boosting (XGBoost) algorithm also achieves its performance by combining multiple decision trees and represents an improved version of gradient-boosted decision trees, addressing some limitations of traditional decision trees (Chen & Guestrin 2016). It enhances model accuracy by sequentially fitting the residuals of previous predictions, with each tree trained based on the errors of the preceding tree, thereby iteratively improving predictive performance. Additionally, XGBoost incorporates regularization to control tree complexity and prevent overfitting, and employs parallelization to accelerate computation, resulting in higher efficiency and prediction accuracy.
-
Linear regression is one of the simplest and most widely used regression models. Its core idea is to establish a linear relationship between the predicted outcome and the input features, with model parameters estimated by minimizing the sum of squared errors.
-
Kernel ridge regression extends linear regression into the feature space. Unlike traditional ridge regression, the kernelized version replaces the inner product with a kernel function, allowing nonlinear patterns in the original low-dimensional space to be mapped into a higher-dimensional space. A ridge regression model is then constructed in this high-dimensional space to predict new data points. The algorithm also incorporates a regularization term to prevent overfitting, thereby improving the model’s generalization ability.
3.2. Model training and optimization
During the training of supervised ML algorithms, hyperparameter tuning was performed to ensure that each algorithm achieved optimal performance on the data without underfitting or overfitting. Taking the random forest algorithm as an example, excessively deep trees can lead to overfitting and reduced generalization, whereas too few trees can result in underfitting and lower predictive accuracy. Therefore, methods such as cross-validation and grid search are typically used to determine the optimal tree depth and number of trees. Generally, increasing the number of trees improves accuracy but also increases computational complexity, requiring a balance between predictive performance and efficiency.
In this work, the optimization criteria were the lowest RMSE and the highest Pearson correlation coefficient observed during tuning. The algorithms primarily optimized in this study were the tree-based ensemble methods, random forest and XGBoost. For random forest, the main hyperparameters adjusted include the number of trees and tree depth, while the maximum number of leaf nodes is kept at the default value due to the limited number of input features. The optimization process for random forest is illustrated in Fig. 5, which shows the algorithm’s performance across different tree numbers and depths. The lowest RMSE and highest Pearson correlation were achieved with a tree depth of 5 and 250 trees, which were adopted as the optimal hyperparameters in this study. All other parameters were set to their default values.
 |
Fig. 5. Optimization plot of hyperparameters in the random forest algorithm. Panels (a) and (b) show the variations in RMSE and Pearson correlation coefficient with the number of trees and the maximum tree depth, respectively. |
A similar optimization procedure was applied to the XGBoost algorithm. We first explored the dependence of model performance on the tree depth and the number of trees. As shown in Figs. 6a and b, the residuals and Pearson correlation coefficients indicate that the optimal configuration is achieved with a tree depth of 2 and 90 trees. We then fixed the tree depth at this value and examined the impact of different learning rates for varying numbers of trees, as illustrated in Figs. 6c and d. These results show that the best performance is obtained with 90 trees and a learning rate of 0.07. All remaining XGBoost parameters were kept at their default settings. The linear regression model used in this work contains no essential tunable hyperparameters, while the kernel ridge regression model adopted a polynomial kernel with α = 0.6, degree = 2, and coef0 = 2.5.
 |
Fig. 6. Optimization of XGBoost hyperparameters. Panels (a) and (b) show the dependence of the RMSE and the Pearson correlation coefficient on the number of trees and the maximum tree depth, respectively. Panels (c) and (d) show their dependence on the number of trees and the learning rate, respectively. |
Different ML algorithms exhibit distinct strengths on the same dataset. In this work, we employed the SuperLearner algorithm to combine multiple models and maximize overall performance, with the detailed procedure described in the following subsection.
3.3. SuperLearner
After training each individual ML algorithm 100 times on randomly sampled datasets, we integrated them into a SuperLearner ensemble. SuperLearner is an ensemble method that combines multiple base algorithms using V-fold cross-validation (van der Laan et al. 2007). For a given dataset, it is often difficult to determine a priori which algorithm will perform best, and SuperLearner effectively addresses this challenge. During cross-validation, it adaptively assigns higher weights to algorithms that are better suited to the current training data (hereafter also referred to as predictors) while reducing the weights of lower-performing models. Specifically, weights are assigned to each algorithm based on its residuals during cross-validation, with algorithms producing lower residuals receiving higher coefficients; all coefficients are non-negative and sum to one. These properties allow SuperLearner to leverage the unique strengths of different algorithms, constructing an ensemble model that effectively minimizes estimation residuals.
In this work, we employed five-fold cross-validation, in which the training set of 516 GRBs was randomly divided into five complementary subsets. SuperLearner trains on four subsets while using the remaining subset as a validation set to guide model adjustment. This process is repeated five times so that each subset serves once as the validation set. During these iterations, SuperLearner automatically assigns optimal weights to each predictor based on the data, thereby optimizing the estimation of Ep across all validation sets. We repeated this entire procedure 100 times, i.e., performing 100 iterations of five-fold cross-validation with random data splits and model training, which enabled a robust assessment of the SuperLearner ensemble’s stability and reduced dependence on any specific random data partition. Considering the limited size of the current BAT training sample and the accuracy of the observational data, this step is critical for evaluating and optimizing model performance.
Generally, using too many folds could make model training overly sensitive to local features within subsets, thereby reducing generalization, whereas too few folds limit the diversity of training samples, hindering effective learning. Therefore, we chose to use five-fold cross-validation to achieve a SuperLearner ensemble with stronger generalization, rather than ten- or three-fold. In fact, our experiments confirm that this choice yields the best performance.
All ML algorithms in this work were implemented in Python. Random forest, linear regression, and kernel ridge regression were implemented using Scikit-learn3, XGBRegressor was from XGBoost4, and the SuperLearner ensemble was implemented using the Mlens package (v0.2.3)5.
4. Results and analysis
4.1. Model performance and estimation results
In this work, the final SuperLearner model used for both training and generalization integrated the four optimized predictors described in Sect. 3.1. Figure 7 presents the results from 100 independent random training runs, where the horizontal axis represents the observed Ep and the vertical axis shows the model-estimated E′p. The results yield a Pearson correlation coefficient of r = 0.725 and a RMSE of 0.267 between the true and estimated Ep values. According to the outlier definition proposed by Jones & Singal (2020), only about 5% of the training data are identified as catastrophic outliers, i.e., GRBs with |ΔEp|> 2σ, which lie outside the black lines in Fig. 7. Beyond training performance, the model’s behavior on the test set is of greater significance, as it provides a more realistic measure of predictive accuracy. Figure 8 illustrates a representative example of the SuperLearner’s performance on the test set, where the fraction of catastrophic outliers similarly remains at approximately 5%.
 |
Fig. 7. Relation between the estimated peak energy (E′p) obtained with the SuperLearner model and the observed peak energy (Ep) for the training set. The solid red line shows the best-fit relation, while the solid black lines mark the 2σ confidence bounds. |
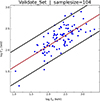 |
Fig. 8. Relation between the estimated peak energy (E′p) obtained with the SuperLearner model and the observed peak energy (Ep) for the test set. The solid red line denotes the best-fit relation, and the solid black lines indicate the corresponding 2σ confidence bounds. |
Figure 9 shows the distributions of the correlation coefficients and residuals obtained from 100 rounds of five-fold cross-validation. The results from these independent training runs demonstrate that, aside from a few special cases where the predictors exhibit slightly higher or lower performance, the overall generalization ability remains stable. The averaged performance across all runs yields a Pearson correlation coefficient of r = 0.72 and an RMSE of 0.27, providing a solid foundation for applying the trained model to the generalization sample.
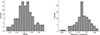 |
Fig. 9. Distributions of root mean squared error (left) and Pearson correlation coefficient (right) over 100 runs of five-fold cross-validation. |
Table 2 summarizes the performance comparison between the SuperLearner ensemble and the four individual predictors used in this study. Across 100 randomized training iterations, the SuperLearner consistently achieves higher average correlation coefficients and lower residuals, demonstrating its superior generalization performance.
Performances of SuperLearner and the four individual predictors.
4.2. Bias correction
It can be seen from Fig. 7 that some GRBs with low Ep are estimated with higher values, while those with high Ep are estimated with lower ones, a typical indication of estimation bias. Such bias usually arises from data imbalance; for example, low- or high-Ep GRBs are relatively scarce in the observed sample, preventing the model from being adequately trained on these regions. However, data imbalance is not the only cause. Limitations in the intrinsic performance of the learning algorithm or the presence of more complex nonlinear relations between input features and Ep at the low or high ends may also contribute to this issue.
We fitted a linear relation between the estimated E′p and the observed Ep to correct for systematic bias. The correction formula is expressed as
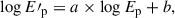 (1)
(1)
where E′p and Ep denote the estimated and observed peak energies, respectively, and a and b are the slope and intercept of the linear fit. In this work, we obtained a = 0.606 and b = 0.902. This makes it possible to correct the bias in the estimations of the generalization set, which is discussed in the following subsection.
4.3. Estimation on the generalization set
We then applied the model to estimate the peak energies of 650 GRBs in the generalization set. The final estimation results are presented in Table 3. Figure 10 compares the distributions of E′p in the generalization set and Ep in the training set. A substantial overlap is observed between the two distributions. However, the estimated E′p values in the generalization set are systematically lower. As discussed in Sect. 2.2, the four predictive variables in the generalization set exhibit distinct distributional differences from those in the training sample. Specifically, Fp and Sγ are generally lower, while Γ tends to be higher. Considering the positive correlations of Ep with Sγ and Fp and its inverse correlation with Γ (as shown in the correlation heatmap in Fig. 3), the overall lower E′p values estimated for the generalization set are therefore physically reasonable.
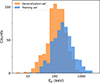 |
Fig. 10. Comparison of the peak energy distribution of the 516 GRBs in the training set (blue region) with that of the 650 GRBs in the SuperLearner generalization set (orange region). |
List of the 650 BAT GRBs in the generalization set (extract).
We further examined the overall distribution of peak energies in the BAT sample by considering the training and generalization sets as a single dataset. Observations from the past decade by the Fermi satellite provide a useful reference (von Kienlin et al. 2020; Poolakkil et al. 2021), as the GBM’s wide energy coverage and large sample size make it highly representative. Figure 11 compares Ep distributions of the BAT and GBM samples, showing that the BAT sample generally exhibits lower Ep values.
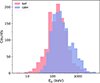 |
Fig. 11. Distribution of the peak energy of the GRBs in the BAT and GBM samples. The purple region represents the BAT sample, which is composed of the training set and the generalization set in this work. The green region represents the GBM sample, which is composed of observational data from Fermi from between 2008 and 2018. |
To more specifically characterize the differences of peak energy, we show the following statistical results: the BAT sample exhibits an Ep range of 4-3516 keV with a median value of 152 keV, whereas the GBM sample spans 24 − 5092 keV with a median value of 214 keV. Obviously, while the BAT GRBs cover a broader Ep range, their average peak energy is lower than that of the GBM GRBs. This discrepancy likely arises from the intrinsically broader energy coverage of GBM, whereas BAT’s sensitivity at lower energies may bias the measurements of predictive parameters (e.g., lower Fp and Sγ), which in turn affects the estimated Ep. Beyond instrumental effects, limitations in the ML models also contribute to residual biases. To further mitigate potential biases in the estimated E′p, we applied the correction formula described in Sect. 4.2; the corrected results are listed in Table 3. After correction, the highest estimated E′p in the generalization set exceeds 6000 keV, and the number of GRBs with 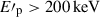 increases substantially, better reflecting the true distribution of GRB peak energies. The present results are based on training with only 516 GRBs, and the dataset size remains limited. Nevertheless, the proposed model provides a valuable framework for estimating the peak energies of BAT GRBs. As future joint observations from Fermi, Konus-Wind, and Swift accumulate more GRB data, this limitation is expected to be alleviated, enabling more reliable estimations of BAT GRB peak energies.
increases substantially, better reflecting the true distribution of GRB peak energies. The present results are based on training with only 516 GRBs, and the dataset size remains limited. Nevertheless, the proposed model provides a valuable framework for estimating the peak energies of BAT GRBs. As future joint observations from Fermi, Konus-Wind, and Swift accumulate more GRB data, this limitation is expected to be alleviated, enabling more reliable estimations of BAT GRB peak energies.
4.4. Spectrum-energy correlations
The Amati and Yonetoku relations are two of the most widely studied spectrum-energy correlations in GRBs (Amati et al. 2002; Yonetoku et al. 2004; Amati 2006; Zhang et al. 2012; Ito et al. 2019). By estimating peak energies for a large Swift sample, we examined these correlations in the BAT GRBs. We have compiled the most comprehensive redshift dataset currently available for BAT GRBs, including 392 GRBs with complete redshift and parameter measurements (Table 4). The redshift information was primarily taken from the website6. This large sample provides a valuable opportunity to revisit the spectrum-energy correlations of GRBs.
Properties of BAT GRBs with redshift (extract).
To derive the isotropic peak energies (Eiso) and luminosities (Liso) for these 392 GRBs, we considered both the Band and CPL models. Specifically, for BAT GRBs for which the CPL model is identified as the best fit and for which the low-energy spectral index (α) and other observational parameters are available, we used the CPL model in the calculations. For the majority of GRBs that are only fitted with PL model, we adopted the Band model to estimate, assigning typical values of α = −1 and β = −2.25 for the low- and high-energy spectral indices, respectively (Preece et al. 2000).
The isotropic energy and luminosity of a GRB are derived from the following relations, with all values corrected to the 1 − 10 000 keV energy band:
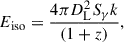 (2)
(2)
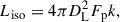 (3)
(3)
where DL is the luminosity distance, Sγ and Fp denote the time-integrated fluence and peak flux, respectively, and k is the correction factor, defined as
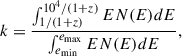 (4)
(4)
with emin and emax representing the instrument’s energy band, and N(E) denoting the GRB spectral model. In this work, we adopted the Band and CPL spectral forms as in Eqs. (5) and (6):
![Mathematical equation: $$ \begin{aligned} N(E)&= {\left\{ \begin{array}{ll} A\left( \frac{E}{100\,\mathrm{keV}} \right)^\alpha \exp \left( -\frac{E}{E_0} \right),&E < (\alpha - \beta )E_0, \\ \begin{aligned}&\textstyle A\left( \frac{E}{100\,\mathrm{keV}} \right)^\beta \left[ \frac{(\alpha - \beta )E_0}{100\,\mathrm{keV}} \right]^{\alpha -\beta } \\ &\textstyle \qquad \times \exp (\beta - \alpha ), \end{aligned}&E \ge (\alpha - \beta )E_0, \end{array}\right.} \end{aligned} $$](/articles/aa/full_html/2026/04/aa58857-26/aa58857-26-eq36.gif) (5)
(5)
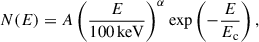 (6)
(6)
where α and β are the low- and high-energy photon spectral indices, and Ec and E0 denote the cutoff energies, with Ec = E0 = Ep/(2 + α), where Ep is the peak energy. The final calculated values are listed in Table 4, with all uncertainties propagated via standard error propagation.
Figures 12 and 13 show the Amati and Yonetoku relations for LGRBs, respectively. Orange and green circles denote GRBs with measured Ep (285 GRBs) and those with estimated E′p from the SuperLearner model (81 GRBs). We analyzed all LGRBs together. Using a least-squares fitting, we obtained the Amati relation for the Swift/BAT LGRB sample as
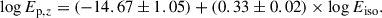 (7)
(7)
 |
Fig. 12. Relationship between Ep, z and Eiso of BAT GRBs. Deep blue (light blue) dots represent SGRBs in the training (generalization) set, and orange (green) dots represent LGRBs in the training (generalization) set. The solid red line represents the best-fit line for all LGRBs, and the dashed line represents the 2σ confidence interval. |
This result is consistent with previous studies (Minaev & Pozanenko 2020; Zhu et al. 2023). In our BAT sample, a clear positive correlation persists between log Ep, z and log Eiso for LGRBs, with a Pearson correlation coefficient of r = 0.65 and a slope of a = 0.33. We find that the 366 LGRBs in our BAT sample are consistent with the updated Amati relation reported recently by Li (2023).
Similarly, analysis of the LGRB sample reveals a very tight correlation between log Ep, z and log Liso, as shown in Fig. 13. Both the estimated and observed LGRBs follow a consistent trend, with no noticeable differences. Furthermore, we fitted the correlation between the peak energy and the isotropic luminosity for LGRBs, yielding the following Yonetoku relation:
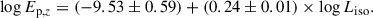 (8)
(8)
 |
Fig. 13. Relationship between Ep, z and Liso of BAT GRBs. The caption is the same as that of Fig. 12. |
The Pearson correlation coefficient between Ep, z and Liso is 0.73, with a slope of a = 0.24. This slope is somewhat lower than that reported in most previous studies (Zhang et al. 2012, 2018; Zhu et al. 2023), although some works have also found coefficients around 0.2 (Xu et al. 2023). It remains uncertain whether this deviation originates from the estimation errors in E′p, from intrinsic variations in a larger sample, or from selection effects. Nevertheless, the existence of a Yonetoku relation in our LGRB sample is well supported.
In addition, the SGRBs with measured Ep and those with estimated E′p are shown as dark and light blue circles in Figs. 12 and 13, respectively. Since only 26 SGRBs have known redshifts, the limited number of data points is insufficient to reliably constrain the spectrum-energy correlations for SGRBs. Therefore, we did not plot the fitting correlation lines for them. Nevertheless, we attempted to fit the spectrum-energy relations of SGRBs, and the corresponding results are summarized in Table 5.
Results of regression analysis for spectrum-energy correlations.
Interestingly, the fitting parameters of the Yonetoku relation are found to be very similar between LGRBs and SGRBs, indicating that their Ep, z − Liso correlations are largely consistent. This similarity suggests that LGRBs and SGRBs share similar radiation mechanisms, as also reported in several previous studies (Zhang et al. 2009; Ghirlanda et al. 2009; Guiriec et al. 2013; Zhu et al. 2023). Overall, our results provide a large Swift sample of 392 GRBs for spectrum-energy correlation analysis, showing that the 366 LGRBs in the Swift catalog still follow the Amati and Yonetoku correlations.
5. Discussion
Since the Bayesian method for estimating GRB peak energies was proposed by Butler et al. (2007), it has been widely adopted. We collected 728 estimated peak energies of GRBs from the online repository of Butler et al. (2007) up to December 2018. To evaluate the performance of the SuperLearner method, we selected 419 GRBs for which the estimated peak energies are available from both methods (i.e., the overlapping sample) for comparison. As shown in Fig. 14, the peak energies of GRBs estimated by the Bayesian method tend to be lower than those estimated by the SuperLearner. After accounting for the 90% credible intervals of the Bayesian estimates, the estimated peak energies from the two methods are broadly consistent for the majority of GRBs. However, for approximately 18% (77/419) of the GRBs, the SuperLearner estimations fall outside the Bayesian credible intervals. These discrepancies largely arise because the Bayesian upper bounds are often too low to encompass the higher E′p values inferred by the SuperLearner.
 |
Fig. 14. Comparison of the estimated peak energies from the SuperLearner (E′p) and the Bayesian (E′p, B) methods. |
To more directly assess the discrepancy between estimated and observed values, we further selected 309 GRBs from 2004–2018 with both reliable observed Ep and Bayesian-derived E′p, B (Fig. 15). The horizontal axis represents the observed Ep, and the vertical axis shows the Bayesian-estimated E′p, B. It is evident that the Bayesian estimates are systematically lower than the observed values, particularly for Ep > 60 keV. Furthermore, even when simultaneously accounting for the Bayesian 90% credible intervals and the reported observational uncertainties of the observed Ep, ∼14% (44/309) of the GRBs show no overlap between the two ranges. Importantly, in these non-overlapping cases, the observed peak energies predominantly exceed the Bayesian upper bounds. Both the comparison with the SuperLearner estimations and the direct observational validation consistently indicate a systematic underestimation of peak energies by the Bayesian approach. Taken together, these comparisons provide indirect evidence that the SuperLearner estimations are likely less biased and closer to the intrinsic peak energies.
 |
Fig. 15. Comparison of the observed peak energy with the estimated peak energy derived from the Bayesian method. |
To further assess the reliability of the SuperLearner model, we compiled the CPL-fitted peak energies (Ep, CPL) of 229 GRBs from the BAT sample, which we obtained from the online table7. The estimated peak energies of these GRBs were then estimated with the SuperLearner ensemble and compared with the Ep, CPL. Figure 16 shows the relation between the SuperLearner-estimated E′p and Ep, CPL. It is evident that Ep, CPL tends to be systematically lower than E′p. This discrepancy arises because Swift/BAT is primarily sensitive to low energies, which limits its ability to constrain the prompt radiation spectrum. As a result, direct spectral fitting of Swift GRBs tends to systematically underestimate the peak energy (Cabrera et al. 2007). In contrast, the SuperLearner model trained with the peak energies measured by Fermi/GBM or Konus-Wind effectively alleviates this bias, thereby indirectly confirming the physical reliability of its estimations.
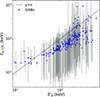 |
Fig. 16. Comparison of the peak energies estimated from the SuperLearner method with those obtained from the CPL model fitting. |
6. Conclusions
We propose a SuperLearner-based framework that integrates multiple supervised ML algorithms to estimate the peak energy of Swift GRBs using multidimensional observational parameters, i.e., Γ, Fp, Sγ, and T90. This method fully exploits the intrinsic correlations among these quantities, overcoming the limitations of traditional statistical methods in modeling nonlinear relationships and thereby enabling a more accurate and robust estimation of GRB peak energies. The main conclusions of this study are summarized as follows:
-
Through 100 iterations of five-fold cross-validation, the SuperLearner model achieves an average RMSE of 0.27 and a correlation coefficient of r = 0.72 on the test set, demonstrating superior generalization performance compared to individual algorithms.
-
A comparison with the Bayesian estimation method proposed by Butler et al. (2007) shows that the SuperLearner estimations are more consistent with the true peak energies. This work therefore provides a new and more reliable approach for estimating the peak energies of Swift GRBs.
-
Based on this method, we estimated the peak energies for 650 GRBs in the BAT sample. To account for potential biases introduced by ML algorithms, we further performed bias correction on the estimated values, and the corrected results are listed in Table 3.
-
Using the estimated peak energies together with 392 GRBs with measured redshifts, we revisited the Ep, z − Eiso and Ep, z − Liso correlations for the Swift sample. Our results show that both the Amati and Yonetoku relations remain evident for 366 LGRBs in the BAT sample. Although the number of SGRBs in this analysis is limited, their distribution in the Yonetoku relation exhibits a nearly identical trend to that of LGRBs, suggesting that the two classes share similar radiation mechanisms.
This study represents the first attempt to estimate GRB peak energies by combining multidimensional observational parameters with supervised ML techniques. The proposed approach benefits from both the extensive observational data accumulated by multiple detectors and the rapid advancement of ML methodologies, offering a new perspective and a tool for GRB peak energy estimation. As more observational data become available, we will further optimize the model to improve estimation accuracy and provide more robust data support for GRB studies.
Data availability
The full versions of Tables 1, 3, and 4 are available at the CDS via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/708/A148
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (No. 12463008), and by the Guangxi Natural Science Foundation (No. 2022GXNSFDA035083).
References
- Aldowma, T., & Razzaque, S. 2024, MNRAS, 529, 2676 [Google Scholar]
- Amati, L. 2006, MNRAS, 372, 233 [Google Scholar]
- Amati, L., Frontera, F., Tavani, M., et al. 2002, A&A, 390, 81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Band, D., Matteson, J., Ford, L., et al. 1993, ApJ, 413, 281 [Google Scholar]
- Bošnjak, Ž., Götz, D., Bouchet, L., Schanne, S., & Cordier, B. 2014, A&A, 561, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Butler, N. R., Kocevski, D., Bloom, J. S., & Curtis, J. L. 2007, ApJ, 671, 656 [Google Scholar]
- Cabrera, J. I., Firmani, C., Avila-Reese, V., et al. 2007, MNRAS, 382, 342 [Google Scholar]
- Chen, J.-M., Zhu, K.-R., Peng, Z.-Y., & Zhang, L. 2024, MNRAS, 527, 4272 [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16 (New York, NY, USA: Association for Computing Machinery), 785 [Google Scholar]
- Cui, X.-H., Liang, E.-W., & Lu, R.-J. 2005, Chin. J. Astron. Astrophys., 5, 151 [Google Scholar]
- Dainotti, M. G., Bogdan, M., Narendra, A., et al. 2021, ApJ, 920, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Taira, E., Wang, E., et al. 2024, ApJS, 271, 22 [Google Scholar]
- Dainotti, M. G., Bhardwaj, S., Cook, C., et al. 2025, ApJS, 277, 31 [Google Scholar]
- Du, G. H., Li, T. N., Ling, J. L., et al. 2025, arXiv e-prints [arXiv:2510.26355] [Google Scholar]
- Fotopoulou, S. 2024, Astron. Comput., 48, 100851 [Google Scholar]
- Ghirlanda, G., Nava, L., Ghisellini, G., Firmani, C., & Cabrera, J. I. 2008, MNRAS, 387, 319 [Google Scholar]
- Ghirlanda, G., Nava, L., Ghisellini, G., Celotti, A., & Firmani, C. 2009, A&A, 496, 585 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gruber, D., Goldstein, A., Weller von Ahlefeld, V., et al. 2014, ApJS, 211, 12 [Google Scholar]
- Guiriec, S., Daigne, F., Hascoët, R., et al. 2013, ApJ, 770, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Han, T., Jin, S.-J., Zhang, J.-F., & Zhang, X. 2024, Eur. Phys. J. C, 84, 663 [Google Scholar]
- Han, T., Zhang, J.-F., & Zhang, X. 2026, Eur. Phys. J. C, 86, 8 [Google Scholar]
- Ito, H., Matsumoto, J., Nagataki, S., et al. 2019, Nat. Commun., 10, 1504 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, E., & Singal, J. 2020, PASP, 132, 024501 [Google Scholar]
- Li, L. 2023, ApJS, 266, 31 [Google Scholar]
- Li, L., & Wang, Y. 2024, arXiv e-prints [arXiv:2412.08226] [Google Scholar]
- Liang, E.-W., Lin, T.-T., Lü, J., et al. 2015, ApJ, 813, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Lithwick, Y., & Sari, R. 2001, ApJ, 555, 540 [NASA ADS] [CrossRef] [Google Scholar]
- Luo, J.-W., Zhu-Ge, J.-M., & Zhang, B. 2023, MNRAS, 518, 1629 [Google Scholar]
- Minaev, P. Y., & Pozanenko, A. S. 2020, MNRAS, 492, 1919 [NASA ADS] [CrossRef] [Google Scholar]
- Narendra, A., Gibson, S. J., Dainotti, M. G., et al. 2022, ApJS, 259, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Narendra, A., Dainotti, M. G., Sarkar, M., et al. 2025, A&A, 698, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pe’er, A., & Ryde, F. 2011, ApJ, 732, 49 [CrossRef] [Google Scholar]
- Piran, T. 2004, Rev. Mod. Phys., 76, 1143 [Google Scholar]
- Poolakkil, S., Preece, R., Fletcher, C., et al. 2021, ApJ, 913, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Preece, R. D., Briggs, M. S., Mallozzi, R. S., et al. 2000, ApJS, 126, 19 [Google Scholar]
- Rodriguez, J.-V., Rodriguez-Rodriguez, I., & Woo, W. L. 2022, Wiley Interdisciplinary Reviews-data Mining Knowledge Discovery, 12 [Google Scholar]
- Sakamoto, T., Sato, G., Barbier, L., et al. 2006, AAS/High Energy Astrophysics Division, 9, 17.04 [Google Scholar]
- Sakamoto, T., Barthelmy, S. D., Barbier, L., et al. 2008, ApJS, 175, 179 [NASA ADS] [CrossRef] [Google Scholar]
- Sakamoto, T., Barthelmy, S. D., Baumgartner, W. H., et al. 2011, ApJS, 195, 2 [Google Scholar]
- Shahmoradi, A., & Nemiroff, R. J. 2010, MNRAS, 407, 2075 [Google Scholar]
- Sun, W.-P., Zhang, J.-G., Li, Y., et al. 2025, ApJ, 980, 185 [Google Scholar]
- Sun, W.-P., Zhang, Y.-K., Zhang, J.-G., et al. 2026, ApJ, 998, 339 [Google Scholar]
- Svinkin, D. S., Frederiks, D. D., Aptekar, R. L., et al. 2016, ApJS, 224, 10 [CrossRef] [Google Scholar]
- Tsvetkova, A., Frederiks, D., Golenetskii, S., et al. 2017, ApJ, 850, 161 [NASA ADS] [CrossRef] [Google Scholar]
- Tsvetkova, A., Frederiks, D., Svinkin, D., et al. 2021, ApJ, 908, 83 [NASA ADS] [CrossRef] [Google Scholar]
- van der Laan, M. J., Polley, E. C., & Hubbard, A. E. 2007, Stat. Appl. Genet. Molecul. Biol., 6, 1 [Google Scholar]
- Virgili, F. J., Qin, Y., Zhang, B., & Liang, E. 2012, MNRAS, 424, 2821 [CrossRef] [Google Scholar]
- von Kienlin, A., Meegan, C. A., Paciesas, W. S., et al. 2020, ApJ, 893, 46 [Google Scholar]
- Wang, Z.-N., Qiang, D.-C., & Yang, S. 2025, Universe, 11, 355 [Google Scholar]
- Wei, D. M., & Gao, W. H. 2003, MNRAS, 345, 743 [Google Scholar]
- Xu, F., Huang, Y.-F., Geng, J.-J., et al. 2023, A&A, 673, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yonetoku, D., Murakami, T., Nakamura, T., et al. 2004, ApJ, 609, 935 [Google Scholar]
- Zhang, B., Zhang, B.-B., Liang, E.-W., et al. 2007a, ApJ, 655, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, B., Zhang, B.-B., Virgili, F. J., et al. 2007b, ApJ, 655, 989 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, B., Zhang, B.-B., Virgili, F. J., et al. 2009, ApJ, 703, 1696 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, F.-W., Shao, L., Yan, J.-Z., & Wei, D.-M. 2012, ApJ, 750, 88 [Google Scholar]
- Zhang, Z. B., Zhang, C. T., Zhao, Y. X., et al. 2018, PASP, 130, 054202 [CrossRef] [Google Scholar]
- Zhu, S.-Y., Liu, Z.-Y., Shi, Y.-R., et al. 2023, ApJ, 950, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Zhu, S.-Y., Sun, W.-P., Ma, D.-L., & Zhang, F.-W. 2024, MNRAS, 532, 1434 [Google Scholar]
- Zhu, S.-Y., Deng, H.-Y., Zhang, F.-W., Mo, Q.-Z., & Tam, P.-H. T. 2025a, MNRAS, 541, 3236 [Google Scholar]
- Zhu, S.-Y., Shao, L., Tam, P.-H. T., & Zhang, F.-W. 2025b, A&A, 702, A173 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Distributions of the four input quantities, Γ, T90, Sγ, and Fp, for the training set (blue region) and the generalization set (orange region). |
| In the text | |
|
Fig. 2. Distribution of Ep in the training set. |
| In the text | |
|
Fig. 3. Correlation heatmap of various parameters in the training set. |
| In the text | |
|
Fig. 4. Feature importance scores trained by the random forest algorithm, reflecting the relative importance of the four input features in the random forest training set. |
| In the text | |
|
Fig. 5. Optimization plot of hyperparameters in the random forest algorithm. Panels (a) and (b) show the variations in RMSE and Pearson correlation coefficient with the number of trees and the maximum tree depth, respectively. |
| In the text | |
|
Fig. 6. Optimization of XGBoost hyperparameters. Panels (a) and (b) show the dependence of the RMSE and the Pearson correlation coefficient on the number of trees and the maximum tree depth, respectively. Panels (c) and (d) show their dependence on the number of trees and the learning rate, respectively. |
| In the text | |
|
Fig. 7. Relation between the estimated peak energy (E′p) obtained with the SuperLearner model and the observed peak energy (Ep) for the training set. The solid red line shows the best-fit relation, while the solid black lines mark the 2σ confidence bounds. |
| In the text | |
|
Fig. 8. Relation between the estimated peak energy (E′p) obtained with the SuperLearner model and the observed peak energy (Ep) for the test set. The solid red line denotes the best-fit relation, and the solid black lines indicate the corresponding 2σ confidence bounds. |
| In the text | |
|
Fig. 9. Distributions of root mean squared error (left) and Pearson correlation coefficient (right) over 100 runs of five-fold cross-validation. |
| In the text | |
|
Fig. 10. Comparison of the peak energy distribution of the 516 GRBs in the training set (blue region) with that of the 650 GRBs in the SuperLearner generalization set (orange region). |
| In the text | |
|
Fig. 11. Distribution of the peak energy of the GRBs in the BAT and GBM samples. The purple region represents the BAT sample, which is composed of the training set and the generalization set in this work. The green region represents the GBM sample, which is composed of observational data from Fermi from between 2008 and 2018. |
| In the text | |
|
Fig. 12. Relationship between Ep, z and Eiso of BAT GRBs. Deep blue (light blue) dots represent SGRBs in the training (generalization) set, and orange (green) dots represent LGRBs in the training (generalization) set. The solid red line represents the best-fit line for all LGRBs, and the dashed line represents the 2σ confidence interval. |
| In the text | |
|
Fig. 13. Relationship between Ep, z and Liso of BAT GRBs. The caption is the same as that of Fig. 12. |
| In the text | |
|
Fig. 14. Comparison of the estimated peak energies from the SuperLearner (E′p) and the Bayesian (E′p, B) methods. |
| In the text | |
|
Fig. 15. Comparison of the observed peak energy with the estimated peak energy derived from the Bayesian method. |
| In the text | |
|
Fig. 16. Comparison of the peak energies estimated from the SuperLearner method with those obtained from the CPL model fitting. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.