| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A83 | |
| Number of page(s) | 14 | |
| Section | Astrophysical processes | |
| DOI | https://doi.org/10.1051/0004-6361/202554133 | |
| Published online | 03 September 2025 | |
Identifying potential binary neutron star merger events from the Fermi GBM Gamma-Ray Burst Catalog
1
Università degli Studi di Napoli Federico II, Dipartimento di Fisica “Ettore Pancini”, Naples, Italy
2
INAF, Osservatorio Astronomico di Capodimonte, Salita Moiariello 16, I-80131 Naples, Italy
3
DARK, Niels Bohr Institute, University of Copenhagen, Jagtvej 128, 2200 Copenhagen, Denmark
4
Mashfrog Group, Via Giacomo Peroni 400, 00131 Rome, Italy
5
INAF, Osservatorio Astronomico di Padova, vicolo dell’Osservatorio 5, 35122 Padova, Italy
6
INFN, Sezione di Napoli, I-80126 Napoli, Italy
7
ICRANet, Piazza della Repubblica 10, I-65122 Pescara, Italy
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
14
February
2025
Accepted:
9
July
2025
Abstract
Context. Short gamma-ray bursts are expected to be associated with compact object mergers, such as binary neutron star or neutron star-black hole systems, and are key high-energy multimessenger events. The detection of GRB 170817A, coinciding with the gravitational wave signal GW170817 from a BNS merger, confirmed the link between sGRBs and compact object mergers. Similarly, GRB 150101B displayed remarkable similarities to GRB 170817A, further supporting its association with compact binary mergers.
Aims. The objective of this study is to uncover the intrinsic properties that differentiate merger-associated sGRBs from other GRBs by analyzing the Fermi GBM Burst Catalog and using GRB 170817A and GRB 150101B as reference events, enhancing our ability to select events from this class and promptly to search for their electromagnetic counterpart.
Methods. We employed a clustering technique to classify GRBs based on their observed properties in gamma-rays (T90, Epeak and fluence). Prior to clustering, we tested three dimensionality reduction techniques, among which Uniform Manifold Approximation and Projection demonstrated the best performance making it the preferred technique for our analysis. This combination of dimensionality reduction and clustering analysis allowed us to group GRBs with similar characteristics, with a focus on identifying those most likely associated with BNS mergers.
Results. Our analysis successfully identified a cluster of sGRBs events with characteristics consistent with sGRB merger-associated. A comparison between our sample of candidates and known kilonova candidates associated with sGRBs, identified through other methodologies, further validated our approach.
Key words: methods: data analysis / gamma-ray burst: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The advent of multimessenger astronomy is transforming our understanding of gamma-ray bursts (GRBs), particularly those linked to compact object mergers such as binary neutron stars (BNSs) or neutron star-black hole (NS-BH) systems. These catastrophic events produce high-energy gamma-ray emissions and gravitational waves (GWs), enabling detections across multiple observational channels. The detection of GRB 170817A (Goldstein et al. 2017), coincident with the GW signal GW170817 (Abbott et al. 2017), marked a milestone in multimessenger astronomy. This event not only confirmed the association between short gamma-ray bursts (sGRBs) and compact object mergers but also revealed an optical kilonova (KN) counterpart, AT2017gfo, powered by the radioactive decay of r-process elements synthesized in the merger ejecta (Smartt et al. 2017; Kasen et al. 2017; Pian et al. 2017).
The sGRBs are characterized by ultrarelativistic, highly collimated jets with Lorentz factors of 100–1000 and prompt gamma-ray emissions lasting under two seconds (Kouveliotou et al. 1993). These jets are typically observed along the axis of the burst, known as the on-axis view, which results in a highly focused and intense emission. Off-axis GRBs, on the other hand, occur when the relativistic jet is observed from an angle outside its core, leading to reduced beaming effects and a diminished observed flux. The Doppler boosting, which typically amplifies emission for on-axis observations, becomes less effective as the viewing angle increases (Salafia et al. 2016). This reduction in the effective Lorentz factor shifts the observed peak energy to lower frequencies and softens the spectrum, making off-axis GRBs appear fainter and more challenging to detect (Gill et al. 2020; Lamb & Kobayashi 2017; Lazzati et al. 2018). Additionally, slightly off-axis GRBs typically exhibit longer apparent durations compared to on-axis events, as the emission from the outer regions of the jet, including cocoon emission, reaches the observer later in time. This broader angular distribution, along with variations in photon arrival times, leads to extended signals (Chakyar et al. 2025; Salafia et al. 2016), providing invaluable insights into jet structures and energy distributions (Lazzati et al. 2017). In the context of compact binary mergers, off-axis GRBs may play a crucial role, as they are expected to outnumber on-axis events due to their wider angular distribution (Fong et al. 2015). However, they remain often undetected due to large error regions in their localization, complicating follow-up searches for optical counterparts. GRB 170817A exemplified an off-axis GRB, where the relativistic jet was observed at an angle away from its core, leading to fainter prompt gamma-ray emission. Despite this, the event highlighted the potential for identifying similar cases that might otherwise be missed due to jet misalignment (Goldstein et al. 2017; Lazzati et al. 2018). Its simultaneous detection of gamma rays, electromagnetic counterpart and GWs reinforced the value of multimessenger observations. Another notable case, GRB 150101B, exhibited features akin to GRB 170817A, reinforcing the link between sGRBs and compact mergers even without a GW counterpart. Observed in a luminous elliptical galaxy with no star formation, it displayed a bright optical counterpart consistent with a luminous KN and an extended X-ray afterglow (Troja et al. 2018).The development of methodologies to identify these elusive off-axis events is essential for the full characterization of the GRB population resulting from compact binary mergers and for facilitating the detection of their KN counterparts, a critical component of multimessenger follow-up.
This study builds on the multimessenger framework with the aim of improving the identification of potential electromagnetic counterparts to compact object mergers through the application of machine learning techniques. The objective of this approach is to facilitate the identification of GRB candidates, particularly those detected by the same detector or instrument, that are likely to result from compact binary mergers. We employed a clustering algorithm to isolate GRBs with characteristics similar to known KN-associated events, such as GRB 150101B (Troja et al. 2018) and GRB 170817A (Goldstein et al. 2017), by analyzing the Fermi Gamma-Ray Burst Monitor (GBM) Catalog. While purely statistical, this approach can help identify GRBs with similar intrinsic properties, potentially highlighting events that share characteristics with the known off-axis sGRBs from binary neutron star mergers, which features are reported in Table 1.
Properties of GRBs with confirmed association to a KN.
Since identifying off-axis GRBs based only on prompt emission is challenging, given that the off-axis nature is typically inferred from afterglow behavior, the clustering algorithm does not explicitly distinguish between on- and off-axis events. Our approach focuses on identifying events in the Fermi dataset that exhibit prompt emission properties similar to the two known GRBs associated with KNe. The goal is to develop an algorithm capable of flagging or sending alerts for events detected by Fermi that may be indicative of short GRBs viewed off-axis, thus facilitating follow-up observations and improving the likelihood of detecting electromagnetic counterparts to compact binary mergers. This prompt-based methodology provides a rapid tool for early classification of the most promising GRB candidates for follow-up that might otherwise be overlooked in gamma-ray observations. Specifically, it can determine whether a newly detected GRB falls within the cluster of interest in under two minutes, making it well suited for real-time follow-up prioritization. In addition, a pipeline has been implemented for associating host galaxies for potential nearby GRB events. By refining our ability to pinpoint host galaxies of nearby sGRBs, we can improve the precision of localization and the prompt detection of KNe. Both the clustering methodology and the host galaxy association pipeline have been tailored for events detected by the Fermi GBM, ensuring methodological consistency and robustness. By focusing on a single instrument’s observations, our approach mitigates potential biases introduced by data from multiple detectors, ultimately increasing the reliability and precision of our results in identifying sGRBs with characteristics indicative of compact binary mergers.
The paper is organized as follows: Section 2 describes the dataset utilized in this study, while Section 3 details the applied methodology. The results of the clustering analysis are presented in Section 4, and the properties of the merger-associated sub-sample are discussed in Section 5. Section 6 provides a broader discussion on the host galaxy association pipeline. A general discussion of the results, including a comparison with previous studies, is presented in Section 7. Finally, Section 8 summarizes the key findings and conclusions.
2. Data sample
Our methodology was applied to the Fermi GBM Burst Catalog (Von Kienlin et al. 2020; Gruber et al. 2014; von Kienlin et al. 2014; Bhat et al. 2016), a comprehensive dataset that collects GRBs detected by the GBM on board the Fermi spacecraft. Fermi-GBM consists of two main detectors: two BGOs, covering the high energy range from 200 keV up to 40 MeV, and twelve NaI scintillation detectors, sensitive to low-energy GRB and covering the range from 8 keV to ∼1 MeV(Meegan et al. 2009; Connaughton et al. 2015). The nearly continuous monitoring of the sky and the sensitivity to a broad range of GRBs make the Fermi GBM a suitable choice for our goal of identifying KN-associated events. Since the beginning of Fermi operations in 2008, over 3000 GRB bursts have been recorded, each systematically classified and cataloged for further study1. Among the parameters included, we specifically selected fluence, Epeak, and T90, as these are the only parameters in the Fermi Burst Catalog that are directly related to the intrinsic properties of an event, encapsulating information about the energy release and temporal profile of GRBs. The fluence represents the total energy emitted by the burst per unit area, integrated over the entire duration of the event and across the detector’s energy band. The T90 parameter is defined as the time interval during which 90% of the burst’s total fluence is accumulated. Finally, we utilized the peak energy Epeak derived from the Band model. While these parameters are not sufficient to distinguish between different progenitor types (e.g., BNS, NSBH, or NSWD mergers), they provide a robust framework for characterizing each burst, thereby facilitating the identification of subgroups with similar prompt emission properties.
Since our goal is to identify clusters within the GRB population, we included all events, regardless of duration, in our clustering analysis. This approach captures underlying patterns in the data, thereby facilitating a robust identification of relevant subpopulations. Analyzing both long and short GRBs ensures comprehensive coverage, offering insights into global GRB properties while refining the search for sGRB candidates as potential optical counterparts to GW events.
The data was retrieved from the catalog in January 2025. While the catalog contains over 3917 GRB events, our analysis was limited to bursts with available measurements for fluence, Epeak, and T90. Applying this restriction reduced the dataset to a subset of 3585 GRBs.
3. Methodology
In this section, we outline the methodology designed to identify subpopulations within the Fermi GBM catalog. Data pre-processing (Section 3.1) is an essential first step in this process, as it mitigates the impact of extreme values. We then applied dimensionality reduction techniques, which serve to highlight key features in the dataset. The three different techniques tested are discussed in this Section 3.2. Following this, clustering was performed, applying the algorithm introduced in Section 3.3 on all the dimensionality reduction techniques tested. Finally, Section 3.4 details the strategy for selecting the optimal number of clusters ncluster and dimensionality reduction technique. This process includes metric-based selections followed by additional computations to evaluate the quality of the chosen ncluster.
3.1. Pre-processing phase
Given that our selected parameters span a broad range of values, initial pre-processing is crucial for effective clustering. To reduce the impact of extreme values and outliers, we applied a logarithmic transformation to the raw data using the numpy Python module. Following this, we standardized the data to ensure that each feature contributed equally to the clustering process. Standardization is a critical pre-processing step, especially for distance-based clustering algorithms like those relying on Euclidean distance, which are sensitive to the scale of input features. Without normalization, features with inherently larger scales could dominate those with smaller ones, distorting the clustering results. To achieve this, we used the StandardScaler class implemented in the sklearn.preprocessing module in Python. The StandardScaler employs the Z-score formula (Mohamad & Usman 2013), in which, given a raw set of data for each feature, the Z-score for each data point xij is calculated as:
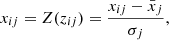 (1)
(1)
where 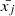 and σj are the sample mean and standard deviation of the j feature, respectively, and i indexes the individual data points within that feature. This transformation centers each feature around a mean of zero with unit variance, ensuring both the magnitude and variability of features are equalized. The fit_transform method efficiently computes these statistics and applies the standardization, thereby enhancing feature comparability and improving the reliability of the clustering process.
and σj are the sample mean and standard deviation of the j feature, respectively, and i indexes the individual data points within that feature. This transformation centers each feature around a mean of zero with unit variance, ensuring both the magnitude and variability of features are equalized. The fit_transform method efficiently computes these statistics and applies the standardization, thereby enhancing feature comparability and improving the reliability of the clustering process.
3.2. Dimensionality reduction techniques
Dimensionality reduction techniques are essential for simplifying complex, high-dimensional datasets, particularly in the context of clustering and visualization. In this study, we applied three complementary methods: principal component analysis (PCA), t-distributed stochastic neighbor embedding (t-SNE), and uniform manifold approximation and projection (UMAP). While all three techniques aim to reduce dimensionality, they differ fundamentally in their approach. The PCA is a linear method that focuses on preserving global variance, making it well suited for datasets with predominantly linear structures. In contrast, t-SNE and UMAP are nonlinear methods, excelling at capturing local relationships and uncovering latent patterns in data with complex, nonlinear structures. By leveraging the strengths of these diverse techniques, we gain complementary insights into the data, enabling both robust clustering and detailed visualization. In all the approaches the parameter n_components was set to 2, thereby reducing the data to two dimensions and facilitating both the clear visualization of the dataset’s structure and the highlighting of its most relevant features. Additionally, the methodology presented in this section was performed without applying dimensionality reduction to assess its impact on clustering performance. The results are discussed in Appendix A.
3.2.1. PCA
The PCA is a linear dimensionality reduction technique that seeks to identify the directions (principal components) along which the variance in a dataset is maximized (Maćkiewicz & Ratajczak 1993). The technique transforms high-dimensional data into a set of orthogonal components, ranked by their variance, where the first component captures the most variance, the second the next highest, and so on. The method first computes the covariance matrix on standardized data, and performs eigenvalue decomposition to extract principal components. The data is then projected onto a subset of these components to reduce dimensionality while preserving most of the variance. For the purposes of this study, the PCA class implemented in the sklearn.decomposition module in Python was used.
3.2.2. t-SNE
The t-SNE is a nonlinear dimensionality reduction technique (Van der Maaten & Hinton 2008) that maps high-dimensional data into a lower-dimensional space–typically two or three dimensions–where clusters and patterns become visually interpretable. The method first computes pairwise similarities between data points in the high-dimensional space, with perplexity serving as a critical parameter that balances the representation of local and global structures, thereby influencing the scale of patterns captured. These similarities are subsequently projected into a lower-dimensional space using a t-distribution, which preserves local relationships while maintaining separation between dissimilar points. The projection is refined iteratively through gradient descent, minimizing the Kullback-Leibler divergence between the high- and low-dimensional representations, ultimately revealing latent structures within the data.
For our implementation, we used the TSNE class implemented in the sklearn.manifold module in Python. The perplexity parameter was configured to a value of 30, which balances local and global structure representation, though values generally range from 5 to 50 depending on dataset size and density. Finally the fit_transform was applied to simultaneously compute and perform the dimensionality reduction.
3.2.3. UMAP
The UMAP is a nonlinear dimensionality reduction technique designed to map high-dimensional data to a lower-dimensional space while preserving both local and global data structures (McInnes et al. 2018). The algorithm constructs a weighted graph of nearest neighbors in the high-dimensional space, with the n_neighbors parameter controlling the balance between local and global data preservation. Optimization is then performed using stochastic gradient descent to minimize a cross-entropy loss function, aligning the high-dimensional relationships with their low-dimensional representations. In our analysis, we employed the UMAP class implemented in the umap- learn library in Python with n_neighbors = 15, min_dist = 0.1 and metric=‘euclidean’.
3.3. K-Means clustering algorithm
We employed K-Means, an unsupervised machine learning clustering algorithm, to uncover patters within our pre-processed Fermi GBM catalog. The K-Means algorithm operates by assigning each data point to the nearest cluster centroid, thereby minimizing the within-cluster sum of squares (WCSS). In this context, machine learning serves as a powerful tool for pattern recognition, allowing us to classify GRB candidates into distinct groups based on their similarities. Similar methodologies have been successfully applied in astrophysical data analysis, such as the classification of GRBs based on their physical properties (Chen et al. 2025). The algorithm is particularly effective for identifying underlying structures in complex datasets, as it enables the segmentation of the data into k clusters based on shared observational characteristics fluence, T90, and Epeak in this analysis.
We implemented K-Means using the K-Means module from the sklearn.cluster package. This method selects initial centroids randomly from the dataset, which, while straightforward, may introduce variability in the clustering results. However, to counteract this, we conducted multiple iterations max_iter = 100 000 with different random initializations to enhance the robustness and stability of the clustering outcomes. After the initial selection of centroids, K-Means iteratively minimizes WCSS through a process of assigning data points to the nearest centroid and recalculating centroid positions until the cluster assignments stabilize (Lloyd 1982). This iterative refinement allows for effective clustering, even when starting from random points.
3.4. Cluster number selection
The selection of the optimal number of clusters is a critical step in any clustering analysis, as it directly influences the interpretability and reliability of the results. K-Means does not automatically determine the optimal number of clusters ncluster and to address this issue we compared the clustering quality across the three different dimensionality reduction techniques (PCA, t-SNE, and UMAP) using the Silhouette score and the Davies–Bouldin index (DBI) for values of ncluster ranging from 2 to 8. Both metrics provide complementary insights into the clustering performance. The Silhouette method is a widely used technique for evaluating the consistency of clustering by assessing the quality of different ncluster configurations (Rousseeuw 1987). This metric quantifies the similarity of each data point to its designated cluster relative to neighboring clusters, thereby evaluating the distinctiveness and separation between the various clusters in the dataset. The resulting Silhouette score provides a measure of cluster quality, ranging from −1, indicating poor separation, to 1, which signifies well defined clusters. This method is also particularly useful for determining the optimal number of clusters, as it reveals how compact and distinct each grouping is. Then another parameter that evaluates the goodness of the clustering is the already mentioned DBI (Davies & Bouldin 1979). The DBI quantifies the average similarity ratio of each cluster with its most similar cluster, effectively measuring how well separated and compact the clusters are. Specifically, for each cluster, the DBI is calculated as the ratio of the sum of intra-cluster distances (how dispersed the points are within the same cluster) to the inter-cluster distances (the distance between cluster centroids). A lower DBI, ≤1, indicates better clustering performance, suggesting that clusters are not only well separated but also cohesive within themselves, while higher scores suggest overlapping clusters. The clustering computation through Silhouette and DBI have been performed with the silhouette_score and the davies_bouldin_score modules from sklearn.metrics.
The lower end of the tested range, specifically ncluster = 2 and 3, given the specific interest in GRBs with merger-like properties, might be too simplistic to capture the nuanced differences among merger-related events. Higher values, such as ncluster = 8, were considered to account for potential substructures within the data, which might reveal smaller, distinct subgroups that could reflect subtle variations in properties such as host galaxy characteristics or physical offsets. The Silhouette and DBI metrics, when accounting for these previous considerations, indicated that configurations with ncluster = 4 or ncluster = 5 (see Table 2) achieved relatively high-quality clustering. However, the final choice of ncluster = 5 was motivated by further analysis. With ncluster = 5, the clusters became more distinct and cohesive, making it easier to interpret and assign data points to specific groups. Importantly, choosing ncluster = 5 does not result in the loss of information. In fact, the cluster containing the two reference GRBs (GRB 170817A and GRB 150101B) remained consistently grouped together in the most effective combination (UMAP associated with K-Means), with both ncluster = 4 and ncluster = 5, ensuring the preservation of key scientific insights.
Comparison of clustering scores across PCA, t-SNE, and UMAP.
3.5. Comparison of results from different methods
Following the selection of ncluster, the consistency of the outcomes from the three dimensionality reduction techniques applied to K-Means was investigated. For this purpose, adjusted rand index (ARI) and normalized mutual information (NMI) were employed, as these metrics evaluate the alignment and consistency between clustering results derived from different algorithms. Specifically, ARI quantifies the similarity between clusterings by evaluating the number of data points that are correctly grouped. This metric ranges from −1 to 1, with 1 indicating a higher degree of alignment. The NMI measures the shared information between two clustering and ranges from 0 to 1. A score near 1 defines a high degree of similarity between the clustering, reflecting well defined clusters, whereas a value close to 0 suggests minimal agreement. The results (see Table 3) revealed moderate-to-high agreement among the methods, reflecting the varying nature of each approach. Interestingly, the highest agreement was observed between UMAP and t-SNE, as both techniques aim to preserve the local structure of the data while reducing its dimensionality. In this analysis the adjusted_rand_score and normalized_mutual_info_score modules from the sklearn_metrics Python library were employed.
Comparison of clustering scores for ncluster = 5 across PCA, t-SNE, and UMAP combinations.
Additionally, ARI and NMI were also computed to compare the clustering results within K-Means and DBSCAN. DBSCAN (Density-based spatial clustering of applications with noise) is a density-based clustering algorithm that groups points based on their proximity and density. While this algorithm was not part of our GRB clustering analysis, the score computation was conducted to further reinforce our selection of ncluster = 5 by demonstrating agreement within different methodologies. The results are discussed in Appendix B.
In order to further analyze the consistency and overlap between clusters generated by the three different dimensionality reduction approaches, heatmaps were computed for nclusters = 5. These heatmaps (see Figure 1) illustrate the degree of overlap between clusters obtained through PCA, t-SNE, and UMAP. The results indicated a high degree of agreement in the clustering assignments, particularly for the cluster of primary interest. This cluster consistently exhibits strong overlap across the three methods, thereby reinforcing the reliability of the clustering results and providing confidence in the interpretation of this subgroup as a distinct population.
 |
Fig. 1. Cluster overlap across the three dimensionality reduction techniques. The label of the clusters of interest are highlighted in red. (a) Cluster overlap between PCA and UMAP. (b) Cluster overlap between UMAP and t-SNE. (c) Cluster overlap between PCA and t-SNE. |
4. Clustering results
Based on the evaluation of clustering metrics, we applied our clustering algorithm to the Fermi GBM dataset with ncluster = 5 for all three dimensionality reduction methods, revealing distinct subgroups within the GRB dataset. Each cluster, illustrated in Figure 2, represents a statistical division of the GRB sample based on machine learning techniques and is characterized by similar values of T90, fluence, and Epeak. The full parameter distributions for each cluster are shown in Appendix C.
 |
Fig. 2. From top to bottom, t-SNE-based, UMAP-based and PCA-based results for the n = 5 selection clustering. |
A notable outcome of the clustering we obtained is the consistent grouping of GRB 150101B and GRB 170817A across all three dimensionality reduction methods, underscoring their shared physical characteristics. In Figure 2 these two GRBs are prominently marked as black stars to highlight their proximity within the identified clusters. As indicated by the superior Silhouette and DBI scores (see Table 2), UMAP emerged as the most effective dimensionality reduction technique for this analysis. Therefore, from this point forward, we primarily reference results derived from this method.
Among the five clusters obtained with UMAP dimensionality reduction, Cluster 2 likely identifies a subpopulation of potential KN candidates, as it includes both reference GRBs, suggesting it encompasses GRBs with intrinsic properties similar to those of merger-associated events. This reinforces the robustness of our clustering approach and highlights Cluster 2 as a promising subgroup for further investigation. The properties of Cluster 2 are detailed in Table 5 and the centroids of the five clusters are summarized in Table 4. To facilitate interpretation, we applied an inverse transformation to map the centroids back to the original 3D space, allowing us to recover the corresponding values of the main observable features. Notably, the centroid of Cluster 2 exhibits a clear alignment with the sGRB class while the other clusters exhibit features close to long GBRs. Moreover, the high Epeak centroid of Cluster 2 may reflect the presence of both on-axis and off-axis events. Several GRBs within the cluster exhibit Epeak values consistent with off-axis sGRBs, such as GRB 170817A, 150101B, and 160821B, which show comparatively lower Epeak values. At the same time, the cluster includes very energetic events like GRB 090510. This suggests that the centroid value represents an average across a broad distribution and does not exclude the presence of off-axis sGRBs within the cluster. Therefore, it remains reasonable to assume that such events are part of this population. These findings also suggest that, in our analysis, T90 is likely the key parameter driving the classification of GRBs as merger-like events versus collapsars. This interpretation is further supported by the exclusion of GRB 200826A from our merger-like cluster (see Figure 3). Although its rest-frame duration (0.5 s) places it within the short GRB category, GRB 200826A exhibited several features typical of collapsars (Rossi et al. 2022; Wang et al. 2022): it was energetically soft, followed the Amati relation, and was accompanied by an optical/NIR bump consistent with a supernova.
Centroids properties in the original three-dimensional space. n represents the number of elements in each cluster.
Key parameters for Cluster 2 resulting from the UMAP-based clustering methodology, and containing GRBs with potential off-axis characteristics.
To strengthen our association of this cluster with sGRBs, we investigated the sGRB catalog by Fong et al. (2022). By narrowing our analysis to the events detected by Fermi, we identified the majority of their sGRBs within our cluster. As illustrated in Figure 3 a few elements of their sample are distributed in other clusters. In particular, within Cluster 1 we found GRB 211211A which has been linked to a KN (see Section 7 for further details).
 |
Fig. 3. Comparison between our clustering results and the sGRBs from Fong et al. (2022) catalog, with sGRBs marked as black stars. Additionally, the plot highlights in red the GRB200826A associated with a collapsar and the two long GRBs associated with KNe (GRB211211A and GRB230307A). The discussion on the long kN-associated GRBs can be found in Section 7. |
The other two GRBs located outside our cluster, GRB 170728B (Cluster 3) and GRB 151229A (Cluster 5), exhibit an effective observed duration in the Fermi GBM catalog that is longer than typical short GRBs. These GRBs have been considered as sGRBs in the work of Fong et al. (2022), given that their T90 observed duration is shorter than 2s as reported by the Swift/BAT detector (Ukwatta et al. 2017; Lien et al. 2015).
Following the identification of Cluster 2, an additional filtering step was applied to its elements in order to further refine the selection of candidates. The new constraint required that only GRBs with an error radius of no more than 0.1 degrees were considered. This threshold was selected to enhance the precision of localization, ensuring that the GRB possess well defined positions, which is a crucial factor when searching for optical counterparts or host galaxies. It is important to note that we did not apply this filter at the beginning of the clustering process in order to avoid the introduction of a bias. The error radius may be influenced by the overlap of data from other facilites, which may have measured the redshift of detected the X-ray afterglow. By applying this filter only after the clustering, we aim to ensure a comprehensive analysis of the dataset, without excluding any potential candidate. The error radius filter reduced the Cluster 2 dimension from 657 to 75 GRBs. Subsequently, a detailed characterization of these candidates was conducted, and the “gold” sample included those events that not only displayed an X-ray afterglow but also exhibited reliable redshift measurement. This procedure led to the identification of a sample of nine “gold” events, including our references GRBs (Table 6).
Properties of the reference GRBs and the most promising candidates identified by the clustering procedure.
5. Merger-associated GRB sample
In this section we discuss the “gold” sample selected through both clustering and filtering procedures, and which properties are illustrated in Table 6. Aside for the two known KN-associated events, four of the nine gold events emerged as a particularly promising subset due to distinctive characteristics that align closely with KN outbursts:
GRB 080905A lacks any associated supernova (SN) but enabled the detection of a faint afterglow within its host galaxy at redshift z = 0.122 (Guelbenzu et al. 2021), a large spiral structure. This burst was observed in a region of minimal star formation and at a considerable distance from the galactic center, making a massive star progenitor unlikely and aligning with environments typical for sGRBs (Rowlinson et al. 2010). The optical counterpart appears to adhere to a standard afterglow model, although the steep early X-ray decay and absence of X-ray detections beyond 1000 seconds indicate a constrained late-time afterglow, potentially allowing for faint KN contributions.
GRB 090510A was an energetic event, detected also by Fermi-LAT (Ackermann et al. 2010). It was precisely localized by the Nordic Optical Telescope (Olofsson 2009), thereby facilitating the immediate association with its host galaxy, which was determined to be a late-type galaxy at z = 0.903 (Rau et al. 2009). The burst exhibited key characteristics, including duration, environment, and spectral hardness, which are consistent with an origin in a compact-object merger (Ghirlanda et al. 2010; Ruffini et al. 2016). Swift XRT observations (0.3–10 keV) revealed the presence of non-thermal X-ray emission, a weak precursor signal, and GeV-range emission. These distinct characteristics also align with the expected signatures of a KN-powered burst.
GRB 160821B exhibited one of the best-sampled afterglows among sGRBs, as evidenced by a comprehensive multi-wavelength dataset that includes X-ray, optical, and radio observations (Lamb et al. 2019). The KN component, identified by excess red and nIR emission in the days following the burst, is consistent with models of neutron star mergers ejecting neutron-rich material. The burst’s environment and characteristics support a compact binary merger origin, with observations consistent with those of other sGRBs associated with KN emissions (Troja et al. 2019).
GRB 210323A was a short-hard burst. The event exhibited a long-lasting X-ray plateau, lasting approximately 104 s, followed by a rapid decay. While an optical counterpart was not detected, Shan et al. (2024) proposed that a supra-massive magnetar, formed after the merger of two neutron stars, could be the central engine responsible for the event. The extended plateau emission, combined with the subsequent sharp decline, is consistent with models involving energy injection from a supra-massive neutron star that eventually collapses into a black hole.
Our gold sample includes three others GRBs: 090927, 131004A and 191031D. These GRBs lack a confirmed SN associations and their classification remains uncertain, although a collapsar progenitor has been considered for GRBs 090927 (Guelbenzu et al. 2012). However, limitations in current data prevent us from drawing firm conclusions about their origins.
6. Host Association pipeline for nearby GRB events
Our clustering approach allows us to select sGRBs detected by Fermi potentially linked to a KN and aid follow-up observations. To further enhance the search of the electromagnetic counterpart, we developed a pipeline to identify potential host galaxies, assuming the sGRB in consideration occurs within a relatively nearby region of the universe, as it was for GRB 170817A.
The pipeline utilizes the NASA/IPAC Extragalactic Database (NED) Local Volume Sample (LVS), chosen for its extensive completeness up to a distance of 80 Mpc (Cook et al. 2023), which outperforms other databases like GLADE+ (Dálya et al. 2018) or HECATE (Kovlakas et al. 2021) in terms of completeness within this range. Beyond this, NED remains robust, achieving 70% completeness out to roughly 300 Mpc. This ensures that the majority of potential host galaxies in the local universe are included, maximizing the reliability of our candidate selection. The filtering process begins by selecting galaxies within a 1 square degree search region around the Fermi GRB position. This search area is chosen to narrow down the number of galaxies and reduce the probability of false associations with unrelated objects.
We also considered a physical offset constraint for the association GRB-host galaxy, limiting their offset to values lower than 40 kpc. This threshold is consistent with typical sGRB offsets observed in the literature, reflecting the tendency of these bursts to occur at significant distances from their host galaxy centers, likely due to natal kicks during binary neutron star formation (Fong & Berger 2013; Fong et al. 2022; Nugent et al. 2024). Finally, a flag is applied based on the specific star formation rate (sSFR), highlighting galaxies within a range from 10−12 yr−1 to 10−8 yr−1 (illustrated in Figure 4). To determine this range, we analyzed sGRBs features from the catalog by Nugent et al. (2024), deriving their sSFR values. This interval is consistent with the association of sGRBs with environments that exhibit low star formation activity, such as elliptical or lenticular galaxies (Berger 2014). It is important to stress that this is not a filtering parameter; rather, it highlights the nature of potentially selected galaxies with older stellar populations within the broader set of candidates identified by our pipeline. As a demonstration of the pipeline’s effectiveness, we tested it on GRB 170817A, the only event in the "gold" sample close enough to fall within the limits of the NED LVS catalog (see Table 6). The pipeline successfully identified its known host galaxy, NGC 4993, further validating the utility of our approach for nearby events.
 |
Fig. 4. Distribution of the sSFRs as a function of the physical offsets. Data from the catalog by Nugent et al. (2024). |
To assess the utility of the pipeline, we performed a retroactive search for the 66 Fermi GRBs of Cluster 2 not in the “gold” sample and for which no redshift was measured. For this purpose, we referenced the Transient Name Server (TNS) catalog2 in order to identify potential optical counterparts that are close to the host galaxies identified using the above pipeline. Although the TNS catalog is limited to GRBs discovered since 2014, it provides a sufficient level of statistical significance to validate our method, as it contains extensive observations of optical transients over nearly a decade. For GRBs with known afterglows, we performed a search within a 10-arcsec radius of the X-ray position, targeting the immediate vicinity for any associated optical counterparts. For GRBs without detected afterglows, candidate host galaxies were first identified using the NED LVS database, and then the search was performed in TNS. Additionally, a filter was applied to the discovery time of the potential optical counterparts, selecting only events detected within a range of three months from the burst. Our search identified one candidate as a potential counterpart of GRB 220412713. We selected 82 possible host galaxies within 1 square degree of the Fermi GRB position. In a crossmatch with the TNS catalog, we identified AT 2022kpe at 3.68 arcseconds from WISEA J212432.06-000919.7, located at approximately 36 kpc from the GRB, suggesting a possible positional association. However, this transient was discovered by ZTF on May 19, one month after the GRB detection, as a rising source, suggesting that this event is unrelated with GRB 220412713.
The methodology we propose holds significant potential for future applications, particularly in KN event searches. By systematically identifying and prioritizing likely host galaxies, combined with the ability to pinpoint a GRB class with properties similar to GRB 170817A and GRB 150101B, our pipeline offers a valuable tool for enhancing targeted follow-up observations as GRB catalogs and GW detections expand. While currently limited to nearby events, this approach could be particularly beneficial for telescopes without wide-field capabilities, simplifying observational campaigns for optical counterparts. Furthermore, as facilities like the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST) (Ivezić et al. 2019) become operational, their wide-field observations could complement our pipeline. The LSST’s ability to survey large sections of the Fermi error box and identify numerous galaxies will allow for efficient crossmatching with our results, further improving follow-up efforts.
7. Discussion
Our methodology effectively identified a promising cluster of GRBs that exhibit characteristics consistent with potential sGRB-merger associations. The results align with previous studies that have found similar structures within GRB populations. In particular, the selection of ncluster = 5 is further supported by prior studies that consistently identified five clusters as optimal, despite variations in datasets, parameter choices, and clustering methodologies. For instance, Acuner & Ryde (2018) analyzed the Fermi GBM dataset, incorporating spectral parameters such as Epeak, fluence, and T90, and employed Gaussian Mixture Models (GMM) for clustering. Their analysis highlighted the presence of five distinct groups, which were interpreted as representing different emission mechanisms, specifically distinguishing between photospheric and synchrotron origins during the GRB prompt phase. Similarly, Dimple et al. (2023) and Dimple & Arun (2024) explored clustering using the Swift/BAT and Fermi GBM datasets, respectively, employing combinations of dimensionality reduction techniques such as PCA and t-SNE. They also included both spectral and temporal parameters in their analyses, enabling a detailed characterization of the GRB population. Both studies reported a consistent five-cluster solution, with two clusters identified as KN-associated groups based on the inclusion of known KN-associated GRBs. Furthermore, Chattopadhyay & Maitra (2017) applied K-Means and Gaussian Mixture Models to the BATSE dataset and reported five clusters, attributing the separation to differences in burst energetics and durations. These findings underscore the robustness and potential universality of the five-cluster framework across diverse instruments, energy ranges, and parameter selections, establishing it as a valuable tool for exploring GRB subpopulations and their properties.
To further validate our selection methodology, we compared our results with the sample of KN candidates identified by Troja (2023) in their comprehensive review of Swift-detected GRBs. Swift, launched in 2004, is a multi-wavelength instrument equipped with the Burst Alert Telescope (BAT) (Barthelmy et al. 2005), which operates in the 15–150 keV energy range, focusing on the detection of GRBs in the lower-energy regime. In contrast, Fermi-GBM covers a broader energy range, from 8 keV up to 40 MeV, making it more sensitive to high-energy gamma-ray emissions. Swift’s additional instruments, the X-Ray Telescope (XRT) (Burrows et al. 2005) and the Ultraviolet/Optical Telescope (UVOT) (Roming et al. 2005), enable precise afterglow localization and multi-wavelength follow-up observations. Together, these features make Swift a critical tool for identifying GRBs and their associated counterparts.
We found that all three GRB events classified by Troja (2023) as ideal KN candidates (referred to as Group 1) and that have been observed by Fermi are in our cluster. These candidates are characterized by robust host galaxy associations, reliable redshift measurements, and an optical/near-infrared (nIR) excess consistent with KN emission above the non-thermal afterglow. The Troja (2023) Group 1 contains nine GRBs and the candidates not included in our analysis were either undetected by Fermi or occurred before its operational period. The lack of detection of some Swift GRBs reported by Troja (2023) can be attributed to Fermi’s sensitivity to higher energies, further supporting the hypothesis that off-axis GRBs are predominantly soft events (Band 2003). Moreover, identifying the same candidates using Fermi data, derived from an instrument with distinct energy coverage and detection capabilities, underscores the robustness of our clustering method. This highlights the complementarity of Swift and Fermi: while Swift excels in the precision localization and follow-up of GRBs, Fermi’s sensitivity to a broader energy range captures additional details of the gamma-ray emission.
It is also worth noting that the only two long events, namely GRB 211211A (Rastinejad et al. 2022; Troja et al. 2022) and GRB 230307A (Levan et al. 2024; Dichiara et al. 2023), associated with KN events and detected by Fermi, did not fall within our cluster. These GRBs have durations that significantly exceed 2 seconds, distinguishing them from other GRBs typically associated with KNe. Their absence from our cluster suggests that the underlying mechanisms behind these events may be more complex than previously understood, or that they are on-axis events. Interestingly, we found that these two events were part of a separate cluster in our analysis, Cluster 1, which properties are summarized in Table 7. While our study primarily focuses on sGRBs, the observation of GRB 211211A and GRB 230307A challenge the traditional short-long classification paradigm and may require a separate discussion. However, long GRBs are generally dominated by events like broad-lined Type Ic SNe (Galama et al. 1999; Hjorth et al. 2003), and their population also includes a large number of low-luminosity, soft GRBs whose peak emission is often below the energy range interval of Fermi GBM. Including long GRBs without clear selection criteria would introduce a strong observational bias due to Fermi’s reduced sensitivity to low-energy transients. A more robust investigation of potential long-duration merger-driven GRBs requires more sensitive instruments at soft X-rays, such as SVOM Bernardini et al. (2021), Atteia et al. (2022), Einstein Probe Yuan et al. (2022), or THESEUS Amati et al. (2018), and a significantly larger sample.
Key parameters for Cluster 1 resulting from the UMAP-based clustering methodology.
Still, the presence of these two events within the same subpopulation hints a potential similarity in their origin and highlights the need for further research into the physical processes driving these bursts and their relationship with KNe. This finding aligns with the results of Dimple & Arun (2024), who also identified a close proximity between these two events within their clustering analysis. This evidence also suggests the possibility of a similar progenitor, further supporting the hypothesis of a second distinct subpopulation potentially associated with KNe. Additional investigations into this cluster are in progress.
8. Conclusion
The confirmation of the connection between sGRBs and compact object mergers by groundbreaking events such as GRB 170817A has highlighted the necessity for systematic methods for identifying similar events when a simultaneous GW detection is missing. Building on this framework, our study developed a clustering methodology and an integrated pipeline to isolate GRBs with merger-like properties and select potential host galaxies, tailored to analyze the Fermi GBM bursts.
-
The clustering methodology identified a subset of GRBs with properties consistent with known sGRBs and off-axis merger events: GRB 170817A and GRB 150101B. This approach demonstrates the potential of unsupervised learning techniques, such as K-Means, to isolate astrophysical events with specific characteristics, even within large and diverse datasets. Evaluation of clustering quality and consistency across dimensionality reduction techniques validated the robustness of the identified clusters.
-
A significant number of sGRBs in our selected sample with known redshifts exhibit characteristics indicative of merger-like origins, such as low star formation rates and significant physical offsets from galaxy centers. The selected sample in this study is constrained to an error radius of no more than 0.1 degrees to ensure better localization. The complete Cluster 2 includes a larger number of candidates, which is currently undergoing further analysis.
-
We developed a pipeline that identifies potential host galaxies for sGRBs using the NED LVS. The pipeline successfully identified the host galaxy of GRB 170817A, confirming its effectiveness for nearby events and demonstrating its potential for future KN-associated GRB searches. Additionally, we tested it through a retroactive search on the GRBs within our Cluster 2 but without redshift measurements, although no new optical counterparts were found. The pipeline also has strong potential to complement current and upcoming facilities, such as the Vera C. Rubin Observatory’s LSST and gravitational wave detectors like LIGO, Virgo, and KAGRA, by streamlining follow-up observations of sGRBs likely associated with KNe.
-
Results from previous studies support our cluster number selection. Additionally, a comparison with the sGRB and KN candidate sample from Troja (2023) reinforces our approach, as we successfully recover most of their Group 1 candidates.
-
Overall, the clustering and filtering pipeline provides a scalable framework for future KN searches, facilitating the rapid identification of sGRBs with merger-like properties. This methodology allows for the classification of newly detected GRBs in few minutes, offering a time-efficient tool for real-time follow-up prioritization. As sGRB and GW catalogs expand with increasing detector sensitivity, this method can significantly improve the efficiency of multimessenger follow-up observations.
Moreover, this approach can complement the capabilities of existing and forthcoming GW detectors, such as LIGO (Aasi et al. 2015), Virgo (Acernese et al. 2014), and KAGRA (Aso et al. 2013), by focusing follow-up observations on the γ-ray events most likely to be associated with mergers and host environments for sGRBs. As detector sensitivity improves with the Einstein Telescope for GWs (Punturo et al. 2010) and new facilities for GRB detection, such as Einstein Probe (Yuan et al. 2022) and SVOM (Bernardini et al. 2021; Atteia et al. 2022), the probability of detecting nearby sGRB-GW associations will only increase. Looking forward, our methodology can be expanded to analyze both GW-associated and non-GW-associated GRBs, offering the potential to uncover a broader population of merger-related events. Additionally, integrating joint temporal studies and spectroscopic analyses (Negro et al. 2025; Camisasca et al. 2023) will further refine candidate identification, enhancing our ability to probe the physical properties of these bursts and advancing our understanding of compact object mergers.
The Fermi GBM burst catalog can be queried at the following link https://heasarc.gsfc.nasa.gov/w3browse/fermi/fermigbrst.html
Acknowledgments
LI acknowledges financial support from the YES Data Grant Program (PI: Izzo) Multi-wavelength and multi messenger analysis of relativistic supernovae. IFG acknowledges financial support from Piano Nazionale di Ripresa e Resilienza (PNRR) through the ETIC – Einstein Telescope Infrastructure Consortium (Missione 4/Componente 2/Investimento 3.1 – IR0000004). EC acknowledges support from MIUR, PRIN 2020 METE (grant 2020KB33TP). Software: pandas (The Pandas Development Team 2020), matplotlib (Hunter 2007), numpy (Harris et al. 2020), scikit-learn (Pedregosa et al. 2011), UMAP (McInnes et al. 2018).
References
- Aasi, J., Abbott, B., Abbott, R., et al. 2015, Class. Quant. Grav., 32, 074001 [Google Scholar]
- Abbott, B. P., Abbott, R., Abbott, T., et al. 2017, Phys. Rev. Lett., 119, 161101 [CrossRef] [Google Scholar]
- Acernese, F., Agathos, M., Agatsuma, K., et al. 2014, Class. Quant. Grav., 32, 024001 [Google Scholar]
- Ackermann, M., Asano, K., Atwood, W. B., et al. 2010, ApJ, 716, 1178 [NASA ADS] [CrossRef] [Google Scholar]
- Acuner, Z., & Ryde, F. 2018, MNRAS, 475, 1708 [NASA ADS] [CrossRef] [Google Scholar]
- Amati, L., O’Brien, D., Goetz, E., et al. 2018, Adv. Space Res., 62, 191 [Google Scholar]
- Aso, Y., Michimura, Y., Somiya, K., et al. 2013, Phys. Rev. D, 88, 043007 [NASA ADS] [CrossRef] [Google Scholar]
- Atteia, J.-L., Cordier, B., & Wei, J. 2022, Int. J. Mod. Phys. D, 31, 2230008 [NASA ADS] [CrossRef] [Google Scholar]
- Band, D. L. 2003, ApJ, 588, 945 [NASA ADS] [CrossRef] [Google Scholar]
- Barthelmy, S. D., Barbier, L. M., Cummings, J. R., et al. 2005, Space Sci. Rev., 120, 143 [Google Scholar]
- Berger, E. 2014, ARA&A, 52, 43 [CrossRef] [Google Scholar]
- Bernardini, M. G., Cordier, B., & Wei, J. 2021, Galaxies, 9, 113 [Google Scholar]
- Bhat, P. N., Meegan, C. A., Von Kienlin, A., et al. 2016, ApJS, 223, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Burrows, D. N., Hill, J., Nousek, J., et al. 2005, Space Sci. Rev., 120, 165 [NASA ADS] [CrossRef] [Google Scholar]
- Camisasca, A., Guidorzi, C., Amati, L., et al. 2023, A&A, 671, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chakyar, S. P., Prabhavu, J. S., Resmi, L., et al. 2025, ApJ, 982, 57 [Google Scholar]
- Chattopadhyay, S., & Maitra, R. 2017, MNRAS, 469, 3374 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, J.-M., Zhu, K.-R., Peng, Z.-Y., & Zhang, L. 2025, ApJS, 276, 62 [Google Scholar]
- Connaughton, V., Briggs, M., Goldstein, A., et al. 2015, ApJS, 216, 32 [Google Scholar]
- Cook, D., Mazzarella, J., Helou, G., et al. 2023, ApJS, 268, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Dálya, G., Galgóczi, G., Dobos, L., et al. 2018, MNRAS, 479, 2374 [Google Scholar]
- Davies, D. L., & Bouldin, D. W. 1979, IEEE Trans. Pattern Anal. Mach. Intell., 1, 224 [Google Scholar]
- Dichiara, S., Tsang, D., Troja, E., et al. 2023, ApJ, 954, L29 [NASA ADS] [CrossRef] [Google Scholar]
- Dimple, M. K., & Arun, K. G. 2024, ApJ, 974, 55 [Google Scholar]
- Dimple, K., Misra, K., & Arun, K. G. 2023, ApJ, 949, L22 [Google Scholar]
- Fong, W.-F., & Berger, E. 2013, ApJ, 776, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Fong, W.-F., Berger, E., Margutti, R., & Zauderer, B. A. 2015, ApJ, 815, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Fong, W.-F., Nugent, A. E., Dong, Y., et al. 2022, ApJ, 940, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Galama, T. J., Vreeswijk, P. M., Van Paradijs, J., et al. 1999, A&AS, 138, 465 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghirlanda, G., Ghisellini, G., & Nava, L. 2010, A&A, 510, L7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gill, R., Granot, J., & Kumar, P. 2020, MNRAS, 491, 3343 [Google Scholar]
- Goldstein, A., Veres, P., Burns, E., et al. 2017, ApJ, 848, L14 [CrossRef] [Google Scholar]
- Gompertz, B. P., Nicholl, M., Smith, J. C., et al. 2023, MNRAS, 526, 4585 [NASA ADS] [CrossRef] [Google Scholar]
- Gruber, D., Goldstein, A., von Ahlefeld, V. W., et al. 2014, ApJS, 211, 12 [Google Scholar]
- Guelbenzu, A. N., Klose, S., Greiner, J., et al. 2012, A&A, 548, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guelbenzu, A. N., Klose, S., Schady, P., et al. 2021, ApJ, 923, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., Van Der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hjorth, J., Sollerman, J., Møller, P., et al. 2003, Nature, 423, 847 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Kasen, D., Metzger, B., Barnes, J., Quataert, E., & Ramirez-Ruiz, E. 2017, Nature, 551, 80 [Google Scholar]
- Kouveliotou, C., Meegan, C. A., Fishman, G. J., et al. 1993, ApJ, 413, L101 [NASA ADS] [CrossRef] [Google Scholar]
- Kovlakas, K., Zezas, A., Andrews, J. J., et al. 2021, MNRAS, 506, 1896 [NASA ADS] [CrossRef] [Google Scholar]
- Lamb, G. P., & Kobayashi, S. 2017, MNRAS, 472, 4953 [NASA ADS] [CrossRef] [Google Scholar]
- Lamb, G. P., Tanvir, N., Levan, A., et al. 2019, ApJ, 883, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Lazzati, D., Deich, A., Morsony, B. J., & Workman, J. C. 2017, MNRAS, 471, 1652 [NASA ADS] [CrossRef] [Google Scholar]
- Lazzati, D., Perna, R., Morsony, B. J., et al. 2018, Phys. Rev. Lett., 120, 241103 [NASA ADS] [CrossRef] [Google Scholar]
- Levan, A., Gompertz, B. P., Salafia, O. S., et al. 2024, Nature, 626, 737 [NASA ADS] [CrossRef] [Google Scholar]
- Lien, A. Y., Barthelmy, S. D., Cummings, J. R., et al. 2015, GRB Coordinates Network, 18751, 1 [Google Scholar]
- Lloyd, S. 1982, IEEE Trans. Inf. Theory, 28, 129 [Google Scholar]
- Maćkiewicz, A., & Ratajczak, W. 1993, Comput. Geosci., 19, 303 [CrossRef] [Google Scholar]
- McInnes, L., Healy, J., Melville, J., et al. 2018, J. Open Source Softw., 3, 861 [CrossRef] [Google Scholar]
- Meegan, C., Lichti, G., Bhat, P., et al. 2009, ApJ, 702, 791 [NASA ADS] [CrossRef] [Google Scholar]
- Mohamad, I. B., & Usman, D. 2013, Res. J. Appl. Sci. Eng. Technol., 6, 3299 [Google Scholar]
- Negro, M., Cibrario, N., Burns, E., et al. 2025, ApJ, 981, 14 [Google Scholar]
- Nugent, A. E., Fong, W.-F., Castrejon, C., et al. 2024, ApJ, 962, 5 [NASA ADS] [CrossRef] [Google Scholar]
- O’Connor, B., Troja, E., Dichiara, S., et al. 2022, MNRAS, 515, 4890 [CrossRef] [Google Scholar]
- Olofsson, G. 2009, GRB Coordinates Network Circular Service, 1, 880 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pian, E., D’Avanzo, P., Benetti, S., et al. 2017, Nature, 551, 67 [Google Scholar]
- Punturo, M., Abernathy, M., Acernese, F., et al. 2010, Class. Quantum Grav., 27, 194002 [CrossRef] [Google Scholar]
- Rastinejad, J. C., Gompertz, B. P., Levan, A. J., et al. 2022, Nature, 612, 223 [NASA ADS] [CrossRef] [Google Scholar]
- Rau, A., McBreen, S., & Kruehler, T. 2009, GRB Coordinates Network, 9353, 1 [NASA ADS] [Google Scholar]
- Roming, P. W., Kennedy, T. E., Mason, K. O., et al. 2005, Space Sci. Rev., 120, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Rossi, A., Rothberg, B., Palazzi, E., et al. 2022, ApJ, 932, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Rousseeuw, P. J. 1987, J. Comput. Appl. Math., 20, 53 [Google Scholar]
- Rowlinson, A., Wiersema, K., Levan, A. J., et al. 2010, MNRAS, 408, 383 [Google Scholar]
- Ruffini, R., Muccino, M., Aimuratov, Y., et al. 2016, ApJ, 831, 178 [Google Scholar]
- Salafia, O. S., Ghisellini, G., Pescalli, A., Ghirlanda, G., & Nappo, F. 2016, MNRAS, 461, 3607 [NASA ADS] [CrossRef] [Google Scholar]
- Shan, Y., Liu, X.-X., Yang, X., Yuan, H., & Lu, H. 2024, Res. Astron. Astrophys., 24, 085003 [Google Scholar]
- Smartt, S., Chen, T.-W., Jerkstrand, A., et al. 2017, Nature, 551, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Stanbro, M., & Meegan, C. 2017, GRB Coordinates Network, 21383, 1 [Google Scholar]
- The Pandas Development Team 2020, https://doi.org/10.5281/zenodo.3509134 [Google Scholar]
- Troja, E. 2023, Universe, 9, 245 [Google Scholar]
- Troja, E., Ryan, G., Piro, L., et al. 2018, Nat. Commun., 9, 4089 [NASA ADS] [CrossRef] [Google Scholar]
- Troja, E., Castro-Tirado, A. J., Becerra González, J., et al. 2019, MNRAS, 489, 2104 [Google Scholar]
- Troja, E., Fryer, C., O’Connor, B., et al. 2022, Nature, 612, 228 [NASA ADS] [CrossRef] [Google Scholar]
- Ukwatta, T. N., Barthelmy, S. D., Cenko, S. B., & a. GRB Coordinates 2017, Network, 21384, 1 [Google Scholar]
- Van der Maaten, L., & Hinton, G. 2008, JMLR, 9, 2579 [Google Scholar]
- von Kienlin, A., & Meegan, C. 2015, GRB Coordinates Network, 18756, 1 [Google Scholar]
- von Kienlin, A., Meegan, C. A., Paciesas, W. S., et al. 2014, ApJS, 211, 13 [Google Scholar]
- Von Kienlin, A., Meegan, C., Paciesas, W., et al. 2020, ApJS, 893, 46 [Google Scholar]
- Wang, X. I., Zhang, B.-B., & Lei, W.-H. 2022, ApJ, 931, L2 [Google Scholar]
- Yuan, W., Zhang, C., Chen, Y., & Ling, Z. 2022, Handbook of X-ray and Gamma-ray Astrophysics, 1 (Springer) [Google Scholar]
Appendix A: Clustering without dimensionality reduction
In order to ensure a comprehensive analysis, the dataset was tested without dimensionality reduction, with the application of only a logarithmic transformation and standardization. As in the previous case, a range of ncluster from 2 to 8 was analyzed. In each case, the two KN-associated GRBs were consistently clustered together, as was observed with the dimensionality-reduced data (see Figure A.1). However, the clustering goodness remained poor across all values of ncluster, suggesting that dimensionality reduction is necessary. In particular, we observe a DBI score close to 1, indicating poor clustering performance, along with a low Silhouette score, further confirming weak cluster separation (see Table A.1). These low metric values imply not only significant contamination between clusters, but also a lack of compactness and separability, and a high level of noise masking any underlying structure. Therefore, we excluded the non-reduced case from further consideration. The dimensionality reduction step is essential for improving the quality and interpretability of the clustering, as it helps highlight the most relevant components of the dataset and mitigate the impact of noisy or redundant information.
 |
Fig. A.1. K-Means clustering results with ncluster = 5, without the application of dimensionality reduction techniques. |
Clustering score without the application of the dimensionality reduction for ncluster = 4 and 5.
Appendix B: DBSCAN comparison
To further validate our choice of ncluster = 5 we evaluated the consistency of the clustering results across different algorithms. We compared the degree of agreement between K-Means and an alternative clustering method: DBSCAN, both applied on the three dimensionality reduction techniques. We employed the DBSCAN module from sklearn.cluster. In this case, the ARI and NMI scores for ncluster = 5 were consistently higher as shown in Table B.1). This comparison reinforces our choice of ncluster = 5, as it demonstrates that this clustering configuration remains stable and consistent, irrespective of the method used.
Comparison of clustering performance scores between DBSCAN and K-Means for ncluster = 4 and 5, across dimensionality reduction techniques PCA, t-SNE, and UMAP.
Appendix C: Cluster distributions
 |
Fig. C.1. Distributions of T90, fluence, and Epeak for each cluster obtained using UMAP. |
Appendix D: GRBs Sample
Cluster 2 GRBs selected through UMAP dimensionality reduction and refined by filtering based on error radius.
All Tables
Comparison of clustering scores for ncluster = 5 across PCA, t-SNE, and UMAP combinations.
Centroids properties in the original three-dimensional space. n represents the number of elements in each cluster.
Key parameters for Cluster 2 resulting from the UMAP-based clustering methodology, and containing GRBs with potential off-axis characteristics.
Properties of the reference GRBs and the most promising candidates identified by the clustering procedure.
Key parameters for Cluster 1 resulting from the UMAP-based clustering methodology.
Clustering score without the application of the dimensionality reduction for ncluster = 4 and 5.
Comparison of clustering performance scores between DBSCAN and K-Means for ncluster = 4 and 5, across dimensionality reduction techniques PCA, t-SNE, and UMAP.
Cluster 2 GRBs selected through UMAP dimensionality reduction and refined by filtering based on error radius.
All Figures
|
Fig. 1. Cluster overlap across the three dimensionality reduction techniques. The label of the clusters of interest are highlighted in red. (a) Cluster overlap between PCA and UMAP. (b) Cluster overlap between UMAP and t-SNE. (c) Cluster overlap between PCA and t-SNE. |
| In the text | |
|
Fig. 2. From top to bottom, t-SNE-based, UMAP-based and PCA-based results for the n = 5 selection clustering. |
| In the text | |
|
Fig. 3. Comparison between our clustering results and the sGRBs from Fong et al. (2022) catalog, with sGRBs marked as black stars. Additionally, the plot highlights in red the GRB200826A associated with a collapsar and the two long GRBs associated with KNe (GRB211211A and GRB230307A). The discussion on the long kN-associated GRBs can be found in Section 7. |
| In the text | |
|
Fig. 4. Distribution of the sSFRs as a function of the physical offsets. Data from the catalog by Nugent et al. (2024). |
| In the text | |
|
Fig. A.1. K-Means clustering results with ncluster = 5, without the application of dimensionality reduction techniques. |
| In the text | |
|
Fig. C.1. Distributions of T90, fluence, and Epeak for each cluster obtained using UMAP. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.