| Issue |
A&A
Volume 703, November 2025
|
|
|---|---|---|
| Article Number | A291 | |
| Number of page(s) | 18 | |
| Section | Interstellar and circumstellar matter | |
| DOI | https://doi.org/10.1051/0004-6361/202453264 | |
| Published online | 27 November 2025 | |
Multiscale turbulence synthesis: Validation in 2D hydrodynamics
1
Laboratoire de Physique de l’École Normale Supérieure, ENS, Université PSL, CNRS, Sorbonne Université, Université Paris Cité,
75005
Paris,
France
2
LUX, Observatoire de Paris, Université PSL, Sorbonne Université,
75014
Paris,
France
3
Institut de recherche en astrophysique et planétologie Université Toulouse III – Paul Sabatier, Observatoire Midi-Pyrénées, Centre National de la Recherche Scientifique,
UMR5277,
Toulouse,
France
4
Sorbonne Université, CNRS, UMR7095, Institut d’Astrophysique de Paris,
98 bis Boulevard Arago,
75014
Paris,
France
5
DPHY, ONERA, Université Paris-Saclay,
91120
Palaiseau,
France
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
2
December
2024
Accepted:
28
June
2025
Abstract
Context. Numerical simulations can follow the evolution of fluid motions through the intricacies of developed turbulence. However, they are rather costly to run, especially in 3D. In the past two decades, generative models have emerged that produce synthetic random flows at a computational cost equivalent to no more than a few time steps of a simulation. These simplified models qualitatively bear some characteristics of turbulent flows in specific contexts (incompressible 3D hydrodynamics or magnetohydrodynamics) but generally struggle with the synthesis of coherent structures.
Aims. We aim to generate random fields (e.g. velocity, density, magnetic fields) with realistic physical properties for a large variety of governing partial differential equations and at a small cost relative to time-resolved simulations.
Methods. We propose a set of simple steps applied to given sets of partial differential equations: we filter from large to small scales, derive a first order time evolution approximation from Gaussian random initial conditions during a prescribed coherence time, and finally sum over scales to generate the fields.
Results. We test the validity of our method in the simplest framework: 2D decaying incompressible hydrodynamical turbulence. We compare the results of 2D decaying simulations with snapshots of our synthetic turbulence. We first quantitatively assess the difference with standard statistical tools: power spectra, increments, and structure functions. These indicators can be reproduced by our method during up to about a third of the turnover timescale. We also consider recently developed scattering transforms statistics, which are able to efficiently characterise non-Gaussian structures. This reveals a more significant discrepancy; however, this can be bridged by bootstrapping. Finally, the number of Fourier transforms necessary for one synthesis scales logarithmically in the resolution, compared to linearly for time-resolved simulations.
Conclusions. We have designed a multiscale turbulence synthesis (MuScaTS) method to efficiently short-circuit costly numerical simulations to produce realistic instantaneous fields.
Key words: hydrodynamics / magnetohydrodynamics (MHD) / turbulence / ISM: structure
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Turbulence has distinctive features that are hard to characterise quantitatively. Nevertheless, our experience tells us that a lot of information is encoded even in a single 2D projection of a tracer in a 3D turbulent flow. Indeed, when we vigorously push a puff of smoke, it soon develops convoluted motions and diverging trajectories blur the initial impulse, but nevertheless some characteristic signatures remain. When we look at a still picture of smoke trailing in the wake of a candle or an incense stick, our brain not only immediately recognises the context, it also grasps a sense for the fluid shearing and spiralling motions in vortices and gets a feeling of the large-scale wind direction. Astronomers who study the interstellar medium are very much in the same situation; the sky before their eyes is a still projection of tracers evolving through the fluid dynamics at play in these dilute media, which the astronomers attempt to infer.
Quantitative probes of the nature of the underlying fluid dynamics, however, are quite elusive. Turbulence research so far has only managed to isolate a few generic statistical properties shared by turbulent flows. In the case of incompressible hydrodynamics (HD), power-law scalings for the velocity power spectrum were first obtained by Kolmogorov (1941) using conservation arguments across scales. However, scaling laws for the velocity and magnetic fields power spectra are still a matter of debate, even in the relatively simple case of incompressible magnetohydrodynamic (MHD) turbulence (Iroshnikov 1963; Kraichnan 1965; Goldreich & Sridhar 1995; Schekochihin 2022). Then, anomalous scalings for the structure functions were discovered (Kolmogorov 1962), which led to a large legacy of intermittency models and observations of statistical properties on the increments of velocity, energy dissipation rates, vorticity, or magnetic fields (Frisch 1996; She & Leveque 1994; Grauer et al. 1994; Politano & Pouquet 1995). Finally, a few exact analytical results were predicted, such as the Kárḿan–Howarth–Monin 4/5th relation (de Karman & Howarth 1938; Monin 1959; Frisch 1996) in 3D incompressible HD and its analogues in compressible or MHD turbulence (Galtier & Banerjee 2011; Banerjee & Galtier 2013, 2014, 2016).
In contrast, time-resolved simulations can accurately predict the evolution of fluid motions from random initial conditions and we could try to assess what statistical laws control their outcomes. However, such simulations are rather costly to run, especially in 3D and in a developed turbulent regime, which limits the number of possible independent realisations of these experiments.
In the past two decades, several authors have developed efficient techniques to produce random fields that bear some of the known characteristics of turbulence. A natural starting step is simply to produce a Gaussian velocity field with a prescribed power spectrum (Mandelbrot & van Ness 1968). The application of a non-linear transformation to this fractional Gaussian field can then yield some degree of non-Gaussianity, such as inter-mittency. However, these non-Gaussianities may have nothing to do with actual physics. For instance, it is challenging to generate asymmetries in the longitudinal velocity increments that generate non-zero energy transfer, let alone transfer in the right scale direction.
Some techniques focus on advection. Rosales & Meneveau (2006) (multiscale minimal Lagrangian map, MMLM) and Rosales & Meneveau (2008) (multiscale turnover minimal Lagrangian map, MTML) transport ballistically an initial fractional Gaussian velocity field under its own influence in a hierarchy of embedded smoothing scales. They show this procedure generates anomalous scalings and energy transfer although they do not compare it quantitatively to experiments. Subedi et al. (2014) later extended the same approach in MHD. More recently Lübke et al. (2024) showed they could initiate the formation of some current sheets if they applied the same technique to an already non-Gaussian initial field.
Other techniques focus on deformation and neglect advection. Chevillard & Meneveau (2006) and Chevillard et al. (2011) deform a Gaussian field with a stretching matrix exponential to produce a tunable random field with given power spectrum and intermittency properties. Durrive et al. (2020) generalise the same ideas to incompressible MHD. However, these models fail to reproduce coherent structures seen in direct numerical simulations (DNS, see Momferratos et al. 2014; Richard et al. 2022), so Durrive et al. (2022) extend their model to include prescribed random dissipative sheets.
In this paper, we present a set of generic ideas that enable us to produce synthetic models for many types of turbulent flows (HD incompressible or isothermal, self-gravitating or not, incompressible MHD). We present our multiscale turbulence synthesis (MuScaTS) technique in Section 2 and compare it to previous models in Section 3. In Section 4, we carefully assess its validity in the simplest framework of 2D incompressible hydro-dynamical turbulence. With this aim, on one hand we compute the results of DNS evolving an initial Gaussian field after some finite time, and, on the other hand, we generate snapshots of synthetic turbulence using several variants of our method. In order to quantitatively compare the two, we computed power spectra, increments statistics, transfer functions and we finally assessed the quality of the textures we generated by computing scattering transforms statistics (see Allys et al. 2019). We discuss our results in Section 5 and develop the prospects of the MuScaTS method in Section 6.
2 Synthetic models of turbulence: The MuScaTS technique
In the following subsections, we present the ingredients of our framework: a multiscale filtering (2.1), and a generic form (2.2) for partial differential equations which survives filtering under some additional approximations (2.3). This allows us to build a synthetic flow with a sweep from large to small scales (2.4). We then discuss in more details our two main approximations regarding time evolution (2.4.1) and coherence time estimation (2.4.2).
2.1 Isotropic filtering
The purpose of this section is to define a continuous series of filters labelled by their respective scales. In particular, this allows us to reconstruct any zero mean field from its filtered components, and to separate it into a small and a large-scale components.
We consider tensor fields (such as the density or the velocity fields, for example) on a space domain Ɗ = ℝd of dimension d. For a field f, we define its filtered version fℓ at a scale ℓ through
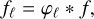 (1)
(1)
where the sign * denotes convolution and φℓ is a bandpass filter that selects scales on the order of ℓ.
We define a continuous collection of filters labelled by all possible scales ℓ ∈ ℝ+ by dilation from a single mother filter φ through the formula
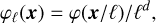 (2)
(2)
where the mother filter φ selects scales on the order of 1, i.e. its Fourier transform 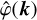 is real positive, decays at small and large wavenumbers and peaks at around |k| = 1, where |k| denotes the norm of k. Note that since
is real positive, decays at small and large wavenumbers and peaks at around |k| = 1, where |k| denotes the norm of k. Note that since 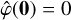 , φ has zero mean and so has fℓ. The dilation formula in Fourier space then takes the form
, φ has zero mean and so has fℓ. The dilation formula in Fourier space then takes the form
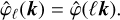 (3)
(3)
We further assume isotropic filtering, i.e. 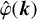 depends only on |k| through the function Φ(s) defined for s ∈ ℝ+ such that
depends only on |k| through the function Φ(s) defined for s ∈ ℝ+ such that
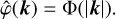 (4)
(4)
Now, let us define
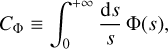 (5)
(5)
or equivalently, using a short-hand notation that we use throughout the paper for such integrals,
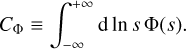 (6)
(6)
We assume that this integral is finite (0 < CΦ < +∞), which implicitly constrains the shape of our mother filter 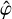 because
because 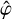 should decay fast enough at both |k| → 0 and |k| → +∞ in order to keep this integral finite. Without loss of generality, we can assume that
should decay fast enough at both |k| → 0 and |k| → +∞ in order to keep this integral finite. Without loss of generality, we can assume that
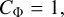 (7)
(7)
by redefining Φ → Φ/CΦ. For example, the choice
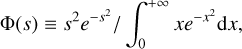 (8)
(8)
results in a normalised CΦ.
In Appendix A, we show that the normalisation (7) allows us to reconstruct simply any field f (with zero mean) from its filtered components fℓ, namely we have the following reconstruction formula
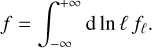 (9)
(9)
Finally, we denote
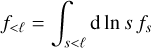 (10)
(10)
and
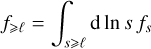 (11)
(11)
the components of f at scales respectively smaller and larger than a given ℓ, so that
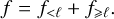 (12)
(12)
2.2 Scope of our method: Generic evolution equations
We present here a generic form of the partial differential equations for which the approximations inherent to our method can be more easily justified. Consider a n-components vector W characterising the state of the gas as a field on our space domain Ɗ. For example, for incompressible 3D fluid dynamics, we can take W = (w), with w the vorticity vector. Or we could use W = (w, ρ) with ρ the mass density for compressible HD.
We then consider evolution equations in the form
![Mathematical equation: ${\partial _t}W + \left( {v \left[ W \right] \cdot \nabla } \right)W = S\left[ W \right] \cdot + D\left[ W \right],$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq18.png) (13)
(13)
where v is an advection velocity vector (i.e. it has the same number of components d as the space dimension), S is a n × n deformation matrix and D is a term with n components which can (generally but not always) characterise the diffusion or dissipation terms. Here, the brackets [W] indicate that v, S and D are affine functions of the state variables field W. In other words, we require the non-linearities to be at most quadratic in the state vector W. We keep the freedom of v having a linear dependence on W, to accommodate future cases where the advection velocity might be more complicated, but all practical results presented in this paper are for v[W] = u, where u is the velocity component in the state vector W.
In the following paragraphs, we give a few explicit examples of evolution equations which fit our framework, for the vorticity and divorticity in incompressible 2D hydrodynamics, and for the vorticity in 3D incompressible hydrodynamics. We then list a few more examples without giving proof.
2.2.1 Incompressible 2D hydrodynamics
As a first example, consider the evolution equation for 2D incompressible hydrodynamics, which reads
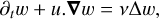 (14)
(14)
where w is the vorticity component along the normal to the space domain, u is the fluid velocity and v is the kinematic viscosity coefficient. It takes the form (13) if we simply set W = (w), v[W] = u, the fluid velocity as expressed from w by the 2D Biot-Savart formula (without the boundaries’ term)
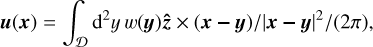 (15)
(15)
where 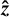 is the unit vector normal to the space domain Ɗ, S = 0 and D[W] = v∆w. Note that Equation (15) can be efficiently computed by using Fourier transforms.
is the unit vector normal to the space domain Ɗ, S = 0 and D[W] = v∆w. Note that Equation (15) can be efficiently computed by using Fourier transforms.
2.2.2 Divorticity in 2D hydrodynamics
In 2D incompressible hydrodynamics, it turns out one can also write evolution equations for the curl of the vorticity, also known as the divorticity (Kida 1985; Shivamoggi et al. 2024):
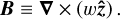 (16)
(16)
Taking the curl of the evolution equation of vorticity (14), it results in
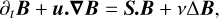 (17)
(17)
where S is the velocity gradient matrix, so that S.B = u.∇B. This equation is in the form (13) when we set W = (B), and it is also strikingly similar to the equation for the evolution of vorticity in 3D, see (18) below. Note that the velocity field can be recovered from the divorticity by inverting the curl twice, which is a linear operation, and so the matrix S also depends linearly on the field B. We use Equation (17) as a test bed in 2D on how to handle the respective advection and deformation terms.
2.2.3 3D incompressible hydrodynamics
For 3D incompressible hydrodynamics, the evolution equation for the vorticity w reads
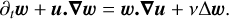 (18)
(18)
To show that this equation takes our generic form (13), we can set W = w ≡ ∇ × u the vorticity vector, and then (again, v[W] = u as explained in the introduction of Section 2.2)
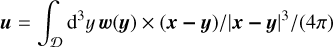 (19)
(19)
(3D Biot-Savart formula without the boundaries’ term). Symbole S denotes the velocity gradient matrix and D[W] = v∆w is simply the diffusion term.
Note that if we write the incompressible Navier-Stokes equation for the velocity evolution, with the specific pressure p ≡ P/ρ (with P the thermal pressure and p the mass density):
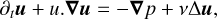 (20)
(20)
it does not take the form (13). Indeed, for the choice W = u, the specific pressure field and its gradient can classically be recovered in the Leray formulation (Majda & Bertozzi 2001, Section 1.8) by solving for p in ∆p = -∂iuj.∂jui, but ∇p then cannot seem to be put into the form S[u].u with S[u] affine in u. However, this is not a restriction since we can simply use Equations (18) with (19), but we feel this example clarifies the subtleties in the scope of the generic form (13).
 |
Fig. 1 Example of the performance of our method. Panel a shows the common initial (Gaussian) vorticity field used in the two other panels, namely a standard 2D incompressible hydrodynamics simulation (panel b) and one of our synthesis (panel c). Panel b shows the vorticity field after the field has been evolved for about one third of a turnover time, using more than 300 standard simulation steps. Panel c shows the resulting synthesis after only four MuScaTS steps for a total computer processing unit (CPU) cost 17 times smaller. |
2.2.4 Other cases
The evolution equations for reduced MHD, incompressible MHD, or self-gravitating isothermal gases can also be massaged into our generic form (13). However, we could not make compressible MHD strictly fit our framework, as the Lorentz term combines a product of three primitive variables (and our attempts at changing variables always led to a product of three variables).
In the context of large-scale structure formation in cosmology, Euler-Poisson equations in the dust approximation (zero pressure) are easily cast into our generic form (13) for the state vector W = (u, ρ). Indeed, Poisson equation for the gravitational potential is linear in the density. The expansion of the Universe can also be incorporated by switching to properly defined comoving variables. We use this in Section 3.3 to create a link with the multiscale Zel’dovich approximation (Bond & Myers 1996; Monaco et al. 2002; Stein et al. 2019). Nevertheless, the form (13) allows for a large variety of fluid evolution equations.
2.3 Derivation of the filtered evolution equations
In this section, we present a series of approximations leading to a simplified description of the dynamics, namely Equation (28). From Section 2.4 and onwards, the latter equation is the central focus, as, instead of trying to time integrate the more complicated full partial differential Equation (13), we mimic the dynamics from (28). Thus, we are able to generate cheap but realistic turbulent fields, as illustrated in Figure 1.
As a first step, let us recast the evolution Equation (13) into the form (24) below, which spells out how the various scales contribute to the dynamics. To do so, note that because our filtering (1) is a convolution product, it commutes with linear functions1, so we have in particular
![Mathematical equation: $\matrix{ {v {{\left[ W \right]}_\ell } = v \left[ {{W_\ell }} \right],} \hfill \cr {S{{\left[ W \right]}_\ell } = S\left[ {{W_\ell }} \right],} \hfill \cr {D{{\left[ W \right]}_\ell } = D\left[ {{W_\ell }} \right],} \hfill \cr } $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq27.png) (21)
(21)
and, filtering (13) with a given bandpass filter φℓ,
![Mathematical equation: ${\partial _t}{W_\ell } = {\varphi _\ell }*\left( { - v \left[ W \right].\nabla W + S\left[ W \right].\nabla W} \right) + D\left[ {{W_\ell }} \right].$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq28.png) (22)
(22)
Then, using the scale decomposition (12), we separate the large and small-scale parts of the velocity field as
![Mathematical equation: $v = v \left[ {{W_{ < \ell }} + {W_{ \ge \ell }}} \right] = v \left[ {{W_{ < \ell }}} \right] + v \left[ {{W_{ \ge \ell }}} \right] = {v _{ < \ell }} + {v _{ \ge \ell }},$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq29.png) (23)
(23)
and doing the same for S we rewrite the filtered evolution Equation (22) as
![Mathematical equation: $\eqalign{ & {\partial _t}{W_\ell }{_x} = D\left[ {{W_\ell }} \right]{_x} \cr & - \int_D {{{\rm{d}}^d}\,y} \,{\varphi _\ell }{_y}{v _{ \ge \ell \cdot }}\nabla W{_{x - y}} - \int_D {{{\rm{d}}^d}\,y} \,{\varphi _\ell }{_y}{v _{ < \ell \cdot }}\nabla W{_{x - y}} \cr & + \int_D {{{\rm{d}}^d}\,y} \,{\varphi _\ell }{_y}{S_{ \ge \ell \cdot }}W{_{x - y}} + \int_D {{{\rm{d}}^d}\,y} \,{\varphi _\ell }{_y}{S_{ \ge \ell \cdot }}W{_{x - y}}, \cr} $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq30.png) (24)
(24)
where Ɗ is the space domain. We expressed convolution products with a notation of the form 」… to help the reader keep track of which variable each field depends on. In particular bear in mind that (24) is evaluated at position x.
The above lengthy but explicit formulation of the dynamics is the viewpoint from which we now proceed to a series of simplifying assumptions, which will result in the approximate evolution Equation (28).
Our first approximation consists in considering that the factors v≥ ℓ and S≥ ℓ appearing inside two of the integrals in (24) are slowly varying in space compared to the filter φℓ, which can be understood as a scale separation approximation. Since these factors presumably remain approximately constant over the local kernel of φℓ, we pull them out of the integrals and write
![Mathematical equation: $\matrix{ {{\partial _t}{W_\ell } \simeq - {v _{ \ge \ell \cdot }}\nabla {W_\ell } + {S_{ \ge \ell \cdot }}{W_\ell } + D\left[ {{W_\ell }} \right]} \cr { - \int_D {{{\rm{d}}^d}\,y\,{\varphi _\ell }{_y}{v _{ < \ell \cdot }}\nabla W{_{x - y}} + } \int_D {{{\rm{d}}^d}\,y\,{\varphi _\ell }{_y}{S_{ < \ell \cdot }}W{_{x - y}}.} } \cr } $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq31.png) (25)
(25)
In so doing, we have also taken the ∇ sign out of the integrals, an operation allowed by the property of the gradient of a convolution product ∂i(ƒ * 𝑔) = f * ∂i𝑔 for multivariable functions ƒ and 𝑔. The last two terms on the right hand side are solely due to scales ℓ and below, and represent respectively advection and deformation from small scales convolved with the filter at scale ℓ.
As a second approximation, we consider that these last two terms evolve more rapidly in time than the previous large-scale terms, and somewhat chaotically, i.e. scales smaller than ℓ introduce some stochastic perturbations which affect the scale ℓ. Schematically:
![Mathematical equation: $\eqalign{ & {\partial _t}{W_\ell } \simeq - {v _{ \ge \ell }}\nabla {W_\ell } + {S_{ \ge \ell }}{W_\ell } + D\left[ {{W_\ell }} \right] \cr & \,\,\,\,\,\,\,\,\,\,\,\,\,\, + {\rm{smaller}}\,{\rm{scales}}\,{\rm{stochasticity}}{\rm{.}} \cr} $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq32.png) (26)
(26)
Nevertheless, we expect the evolution to remain coherent over some time τℓ at a given scale ℓ. Thereafter, we either prescribe or estimate this timescale τℓ from the larger scale fields, and we provide several ways to estimate it in Section 2.4.1 below. For now, since τℓ controls the timescale over which two initially adjacent fluid particles diverge from each other, it can be seen as the inverse of the largest positive Lyapunov exponent under the combined effects of the advection flow v≥ ℓ and the deformation matrix S≥ ℓ.
This sensitivity to the initial conditions implies that it is not quite necessary to integrate precisely the flow equations during more than a coherence time. Indeed, if the conditions had been slightly different one coherence time before, the current state of the fluid might now be completely different, to a point these initial conditions might as well be chosen randomly. Therefore, rather than solving a complicated stochastic equation, we also assume that the effect of the chaos in the small scales is equivalent to randomly reshuffle initial conditions every coherence time τℓ.
Thanks to this hypothesis, we do not need to integrate the evolution from the beginning, but only during the length of the last coherent time interval. At each scale ℓ, we hence assume that the chaotic evolution can be approximated by deterministically integrating to the targeted time t from random conditions at time t − τℓ during a coherence time interval τℓ . We denote this change by adding tildes over the vectors subject to this approximation. As a result, we approximate the evolution of the field as:
![Mathematical equation: ${\partial _t}{\tilde W_\ell } = - {v _{ \ge \ell }}\nabla {\tilde W_\ell } + {S_{ \ge \ell }}{\tilde W_\ell } + D\left[ {{{\tilde W}_\ell }} \right],$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq33.png) (27)
(27)
starting from random conditions 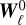 at intermediate time
at intermediate time 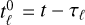 (these intermediate times might hence depend on scale).
(these intermediate times might hence depend on scale).
The law of 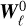 still needs to be specified. The chaos induced by the small scales might well be nontrivial, but in a first step we are going to assume that it follows a Gaussian law. Hence we assume that
still needs to be specified. The chaos induced by the small scales might well be nontrivial, but in a first step we are going to assume that it follows a Gaussian law. Hence we assume that 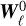 is a filtered version
is a filtered version 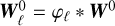 of a Gaussian field W0, for which the spectrum needs to be prescribed. Further-more, to reflect the property that neighbouring scales are in fact not independent (we expect the behaviour of the fluid to be continuous across scales), we assume that the fields
of a Gaussian field W0, for which the spectrum needs to be prescribed. Further-more, to reflect the property that neighbouring scales are in fact not independent (we expect the behaviour of the fluid to be continuous across scales), we assume that the fields 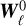 are filtered versions of a single random field W0.
are filtered versions of a single random field W0.
We approximate the evolution equation one step further by using the advection velocity field 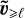 computed from the synthetic state variable
computed from the synthetic state variable 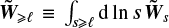 in Equation (27), and similarly for S≥ℓ, for which we use
in Equation (27), and similarly for S≥ℓ, for which we use 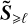 . Finally, the line of reasoning detailed above ultimately leads to the following approximate evolution equation for the dynamics at a given scale ℓ
. Finally, the line of reasoning detailed above ultimately leads to the following approximate evolution equation for the dynamics at a given scale ℓ
![Mathematical equation: ${\partial _t}{\tilde W_\ell } \simeq - {\tilde v _{ \ge \ell }}\nabla {\tilde W_\ell } + {S_{ \ge \ell }}{\tilde W_\ell } + D\left[ {{{\tilde W}_\ell }} \right].$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq43.png) (28)
(28)
Interestingly, it is almost in the initial generic form (13), except that the advection velocity and deformation matrix now depend on all scales above ℓ.
In the following, we introduce yet more approximations, now tailored to solve approximately the approximate evolution Equation (28) we just derived, i.e. we present our turbulence synthesis procedure. At this stage, the reader may legitimately be worried that such an accumulation of (even small) losses of information is too drastic, and can eventually only move us far away from the correct evolution. If so, we invite the reader to recall Figure 1 (or to have a glimpse at the more detailed Figures 3 and 4) were we showed a non-trivial case were the synthesis and the full simulation do match very well. Therefore, to some extent the whole procedure does keep enough relevant information to be of practical use, i.e. we have meaningful examples where it seems to extract the essence of the dynamics.
2.4 Turbulence synthesis
Our last Equation (28) is in closed form for all scales above ℓ: the evolution for 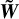 at scale ℓ can be solved once all scales s above ℓ are known. We can hence sweep all scales from the largest down to the smallest and compute
at scale ℓ can be solved once all scales s above ℓ are known. We can hence sweep all scales from the largest down to the smallest and compute 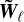 at all scales ℓ (we discuss how we deal with the largest scale in the numerical implementation below, see Section 2.5). The resulting synthesised field can finally be reconstructed as
at all scales ℓ (we discuss how we deal with the largest scale in the numerical implementation below, see Section 2.5). The resulting synthesised field can finally be reconstructed as 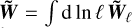 . Variants of our model will now be defined by the way we approximate the evolution Equation (28) (detailed in Section 2.4.1) and the way we estimate the coherence time τℓ (developed in Section 2.4.2).
. Variants of our model will now be defined by the way we approximate the evolution Equation (28) (detailed in Section 2.4.1) and the way we estimate the coherence time τℓ (developed in Section 2.4.2).
2.4.1 Time evolution approximations
Here, we focus on our approximations to solve the evolution Equation (28). We assume that the fields 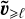 and
and 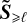 evolve slowly compared to the fields at scale ℓ, as they are based on larger scales. We therefore assume they remain constant during the time interval τℓ. For instance, we assume that the fluid parcels move ballistically with the velocity
evolve slowly compared to the fields at scale ℓ, as they are based on larger scales. We therefore assume they remain constant during the time interval τℓ. For instance, we assume that the fluid parcels move ballistically with the velocity 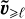 during a coherence time τℓ to integrate (28) in time.
during a coherence time τℓ to integrate (28) in time.
We first focus on a case where S = D = 0 and v ≠ 0. In this case, we only need to randomly draw the initial vorticity field 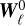 at time
at time 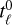 and remap it at positions
and remap it at positions 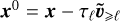 where the fluid parcel used to be
where the fluid parcel used to be
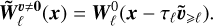 (29)
(29)
Possible shell crossing is discussed in the Section 2.4.2.
We now focus on the case v = D = 0 (S ≠ 0). Since 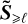 is constant during τℓ, the solution of
is constant during τℓ, the solution of 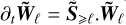 is obtained as a matrix exponential:
is obtained as a matrix exponential:
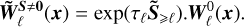 (30)
(30)
For the general case, we combine the two previous steps as
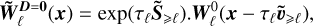 (31)
(31)
and we finally apply the diffusion step as
![Mathematical equation: ${\tilde W_\ell } \simeq \tilde W_\ell ^{D = 0} + {\tau _\ell }D\left[ {\tilde W_\ell ^{D = 0}} \right].$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq58.png) (32)
(32)
We take those three steps in a particular order: advection, deformation, then diffusion. We feel it is justified by the need to use the quantities v and S at a time as advanced as possible (i.e. as close as possible to the time at which we compute the synthesised flow). Also the computation of the gradients in the deformation matrix requires a synchronous evaluation, so deformation might be better evaluated after advection. We finish by the diffusion step because it somewhat smooths the fronts generated at the convergence points of advection trajectories and where the deformation introduces stretching (a property sought for in adhesion models, for example, see Gurbatov et al. 1989). This also allows to alleviate the small scales generated outside the current filter by the non-linear action of advection and deformation (see discussion in Section 5.6, also). However, in the limit where τℓ is very small, time evolution is linear and the order does not matter.
2.4.2 Coherence time estimates
So far, we have defined the coherence time in this work as the time during which the evolution of the fluid can be considered deterministic at a given length scale. We now examine three ways to estimate this time.
1. It is at first tempting to identify it to the correlation timescale. For example, in the direct enstrophy cascade of 2D turbulence, below the injection scale, the correlation timescale is constant, equal to the injection timescale. It would then make sense to adopt τℓ = constant at all scales.
2. The notion of coherence also appeals to the sensitivity to initial conditions. The rate at which fluid trajectories deviate from each other is linked to the symmetric part of the velocity gradient matrix, which characterises the evolution of distances between nearby fluid parcels. We define the stretching time as the inverse of its largest eigenvalue which in incompressible fluids writes as:
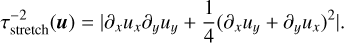 (33)
(33)
This eigenvalue can also be seen as the largest instantaneous Lyapunov exponent for fluid trajectories. The above expression for incompressible hydrodynamics (in which ∂xux = −∂yuy) can be recast into
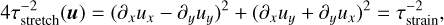 (34)
(34)
which expresses the stretch rate as a sum of squares of the normal and shear strains. That timescale is hence also naturally related to the deformation of fluid elements. Indeed, in some places the fluid might be rotating in a vorticity clump and its evolution at scales below the size of that vortex could be considered deterministic. On the contrary, fluid parcels in between vortices experience strong deformation through shearing motions. Adopting τℓ = τstretch(uℓ) would also ensure that fluid elements retain their integrity (i.e. they are not too deformed and it still makes sense to follow the same fluid particle).
3. Since we resort to a ballistic approximation for the advection of the fluid, our modelled fluid trajectories may cross each other after some finite time. This shell-crossing time can be defined as the inverse of the largest eigenvalue of the velocity gradient (by contrast to its symmetric part above):
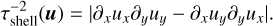 (35)
(35)
Integration of ballistic trajectories for more than this timescale does not make sense. Note that this constraint is more related to our ballistic approximation than to the stochastic behaviour of the fluid, and may be relaxed once we resort to a higher order approximation. However, in the case of 2D incompressible hydrodynamics, this timescale is related to the physically motivated Okubo-Weiss (Okubo 1970; Weiss 1991; Haller 2021; Shivamoggi et al. 2024) criterion 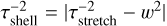 . That last expression can also be used to show that requesting τℓ = τshell is slightly less stringent than the stretch criterion (τstretch ≤ τshell).
. That last expression can also be used to show that requesting τℓ = τshell is slightly less stringent than the stretch criterion (τstretch ≤ τshell).
To conclude, because it is not yet clear which of these approaches is best suited, we have tested four choices for the coherence time (from less to more stringent (τstrain < τstretch ≤ τshell ):
Constant τℓ = t
Shell-crossing based
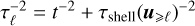
Stretch based
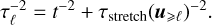 .
.Strain based
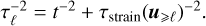 .
.
The minus-two powers in the above expressions take soft minima between the various timescales involved and the integration time t. Indeed, when we compare our method to actual simulations, we compute the evolution of the fluid over a finite time t from random initial conditions. In this case, it is not necessary to integrate the evolution of the synthesised flow over times longer than t.
As a final note, most of these definitions imply that the coherence time τℓ(x, t) depends on both scale, position in space and total evolution time t as long as this one is not too long compared to local times of the flow. The initial conditions 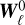 should hence not be understood as starting conditions at a synchronous time. Rather, they are random parameters which reflect the sensitivity to initial conditions.
should hence not be understood as starting conditions at a synchronous time. Rather, they are random parameters which reflect the sensitivity to initial conditions.
2.5 Numerical implementation
2.5.1 Discrete filters
A numerical implementation of the above method requires a space domain with a finite extent and a finite space resolution. As a result, the Fourier domain spans a finite number of wavenumbers, and only a finite number of scales is necessary to recover a given field. We choose to consider a cubic (square in 2D) domain of size L = 2π gridded with N pixels and we adopt periodic boundary conditions. The available wavevectors therefore span a regular grid of unit kJ = 2π/L = 1. We restrict ourselves to a discrete set of J + 1 filters 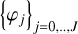 logarithmically distributed in scales in such a way that
logarithmically distributed in scales in such a way that
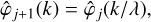 (36)
(36)
with λ ∈]0, 1[ the ratio between the typical scales of two consecutive filters. This parameter controls the resolution in scales. In the present application, we mostly use λ = 1/2 but we also tested a finer set of scales with 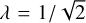 (hence with twice as many filters), without noticing much change.
(hence with twice as many filters), without noticing much change.
We request each filter to be selective in logarithmic scales, in order to be able to use the scale separation arguments at the base of our approximations. The filters 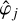 hence select concentric coronas in Fourier space and are centred around wavenumbers kj = kJλj−J with a relative width of 1/λ. In other words, the typical scale associated with filter j is
hence select concentric coronas in Fourier space and are centred around wavenumbers kj = kJλj−J with a relative width of 1/λ. In other words, the typical scale associated with filter j is
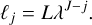 (37)
(37)
We point out that these physical scales go in increasing order from the smallest to the largest as j increases.
The discretised version of our normalisation condition (7) will simply be to enforce 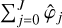 for any k contained in the computational domain. Indeed, then the reconstruction formula works as
for any k contained in the computational domain. Indeed, then the reconstruction formula works as
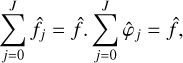 (38)
(38)
from which we deduce 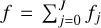 . We present two example filters we used in the present application in the Appendix B.
. We present two example filters we used in the present application in the Appendix B.
2.5.2 Algorithm
The initial Gaussian field W0 is first drawn in real space as a Gaussian white noise. We then convolve it with the desired spectrum by multiplying its Fourier coefficients.
We present below the steps of the algorithm we use to generate turbulent fields 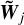 at all scales j from the initial Gaussian field W0. We write
at all scales j from the initial Gaussian field W0. We write 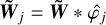 and
and 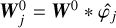 .
.
To initiate the first j = J step of our iterative algorithm, at the largest scale, we simply assume 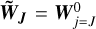 . We then parse the successive scales downwards, and we successively apply the following operations at each scale:
. We then parse the successive scales downwards, and we successively apply the following operations at each scale:
At stage j < J, the fields
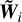 are known for all i > j.
are known for all i > j.We write
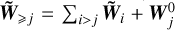 . We compute the advection velocity
. We compute the advection velocity ![Mathematical equation: ${v _{ \ge j}}v \left[ {{{\tilde W\limits^ }_{ \ge j}}} \right]$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq81.png) and similarly
and similarly ![Mathematical equation: ${S_{ \ge j}}S\left[ {{{\tilde W\limits^ }_{ \ge j}}} \right]$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq82.png) .
.We estimate
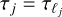 (for which we might need v ≥ j if we use the local stretch or shell crossing times, for example).
(for which we might need v ≥ j if we use the local stretch or shell crossing times, for example).-
We now replace these values in the construction formulas (31) and (32). We compute the time-evolved field at scale ℓj (without diffusion) as
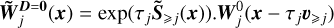 (39)
(39)where we use a first order linear interpolation scheme to compute
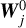 at positions in between grid points.
at positions in between grid points. We finally apply diffusion to the resulting field to get
![Mathematical equation: ${\tilde W_j} = \tilde W_j^{D = 0} + {\tau _j}D\left[ {\tilde W_j^{D = 0}} \right]$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq86.png) . We now have
. We now have 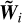 known for all i > j − 1 and we can proceed further back to operation 1 down to the next scale j − 1.
known for all i > j − 1 and we can proceed further back to operation 1 down to the next scale j − 1.
The loop stops when we hit the smallest scale labelled by j = 0. The final field then results from 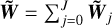 .
.
For the interpolation at operation 4, we use RegularGridlnterpolator from the scipy.interplolate Python package. One of the caveats of this interpolation remapping is that it is not divergence and mean preserving. One may need to reproject the divergence free fields and adjust preserved quantities after the interpolation process. In our 2D hydrodynamical application in Section 4, we remove its average from the vorticity field to recover the zero mean. The same holds for the deformation step.
The matrix exponential at operation 4 makes use of the Padé approximant implementation from the EXPOKIT package (Sidje 1998), for which we implemented a vectorised wrapper in order to gain efficiency (essentially to call it from Python in a more efficient way for an array of vectors).
Diffusion at operation 5 is computed in Fourier assuming it proceeds over a homogenised time 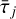 averaged over the computational domain. In this simplified case, the effect of incompressible viscous diffusion ∂tw = D[w] = v∆w during time
averaged over the computational domain. In this simplified case, the effect of incompressible viscous diffusion ∂tw = D[w] = v∆w during time 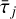 is simply to multiply by exp(
is simply to multiply by exp(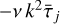 ) the Fourier coefficients of the initial field w. Note that because τj is not necessarily uniform over the computational domain, we resort to using a volume averaged value for τj. Otherwise, there is to our knowledge no convenient way to integrate the viscous diffusion term.
) the Fourier coefficients of the initial field w. Note that because τj is not necessarily uniform over the computational domain, we resort to using a volume averaged value for τj. Otherwise, there is to our knowledge no convenient way to integrate the viscous diffusion term.
2.5.3 CPU cost scaling
If we neglect the cost of the matrix exponentiation and the remapping (proportional to the number of pixels), most of the computational cost will amount to Fourier transforms. At each scale index j > 0 we need to Fourier transform back and forth because some operations are more efficiently performed in Fourier space (computing the advection velocity, the deformation matrix, or applying the diffusion process) while others are better done in real space (interpolation remap and deformation). To be more precise, the 2D synthesis uses ten calls to the fast Fourier transform (FFT) for each scale level: two for the advection velocity, four for the deformation matrix, two around the remap step, and two around the diffusion step. A 3D synthesis would require three for the advection velocity, nine for the deformation matrix, and six for each of the remap and diffusion steps: a total of 24 calls to a scalar FFT. In general, the method hence requires 10J (2D) or 24J (3D) Fourier transforms to generate one field. Since the CPU cost of a Fourier transform in d dimensions is on the order of Nd log2 Nd operations and J scales like log2 N, the cost of one field generation scales as
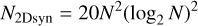 (40)
(40)
operations in 2D and
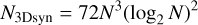 (41)
(41)
in 3D.
The cost of one time step of a pseudo-spectral code is proportional to the order of the time integrator: a Runge–Kutta order 4, such as we use in Section 4.1, requires four evaluations of the time derivative of the quantities at play. Each of these evaluation costs five FFTs in 2d (two for the velocity, two for the diagonal components of the vorticity gradient, one to get back to Fourier space), and 3+3+9+3=18 in 3D where the whole velocity gradient terms are also needed. At a Courant number of 1, the Courant–Friedriech–Lewy condition constrains the time-step to be less than tturnover/N: one requires N time steps to reach one turnover time. The cost of a 2D simulation is hence on the order of
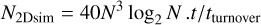 (42)
(42)
operations for our Runge-Kutta order 4 implementation, and
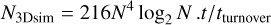 (43)
(43)
in 3D.
For a simulation over the length of one turnover time, the CPU time gain factor is therefore 2N/ log2(N) in 2D and 3N/ log2(N) in 3D. Both 2D and 3D scalings for simulations and MuScaTS syntheses are displayed on Figure 2. The scalings are all calibrated on a 2D N = 1024 simulation run (rightmost blue circle) using our pseudo-spectral code (see Section 4.1) compiled with Fortran on the totoro server at the mesoscale centre mesoPSL. For reference, the CPU hardware on this server is Intel(R) Xeon(R) Gold 6138 CPU, 2.00GHz. Other circles indicate the scaling of simulations at N = 256 and N = 512: they scale slightly less well than the theory predicts, because we ran our code in parallel on 32 cores, so the communication overhead in the FFT at smaller computational domains (smaller N) deteriorates the scaling. The light red squares show the CPU cost on the same hardware for a python 2D implementation of our MuScaTS synthesis.
As a final note, we point out that the current implementation could be further optimised with respect to the multiscale treatment. For a proper choice of filters, we could indeed afford using coarser grids at larger scales than for the smaller scales. This would considerably accelerate the computation at largest scales and lower the number of effective number of scales which enter the CPU cost scaling.
 |
Fig. 2 CPU cost scaling estimates for 2D (light colours) and 3D (dark colours) hydrodynamics simulations (solid, blue) and MuScaTS syntheses (dashed, red). The scalings are computed according to text and calibrated on a 2D simulation (pseudo-spectral code implemented in Fortran) at N = 1024 for one turnover time (rightmost blue circle). The total CPU cost for simulations at N = 256 and N = 512 (the other two blue circles) is also indicated. Red squares stand for the CPU cost of a few 2D MuScaTS syntheses. |
3 Comparison to other methods
We investigate how our MuScaTS technique compares to selected existing works. We compare to Rosales & Meneveau (2006), Chevillard et al. (2011) and then to Zel’dovich’s multi-scale approximation.
3.1 Comparison to Rosales & Meneveau (2006)
For 3D hydrodynamics, if we neglect the deformation and the diffusion terms, our method is extremely similar to the minimal multiscale Lagrangian map (MMLM) of Rosales & Meneveau (2006) provided we use τℓ as in their Equation (9): 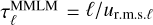 where ur.m.s.ℓ is the prescribed r.m.s. velocity in the initial field at scale ℓ. The only remaining difference is: we would advect the vorticity field and build the velocity from a Biot-Savart formula, while their Lagrangian map is directly applied to the velocity. They have to reproject their velocity field on ∇.u = 0 while we get divergence free fields by construction. We hence expect our method should be more realistic, as both vorticity stretching effects and diffusion are retained while in effect, they neglect pressure terms and diffusion.
where ur.m.s.ℓ is the prescribed r.m.s. velocity in the initial field at scale ℓ. The only remaining difference is: we would advect the vorticity field and build the velocity from a Biot-Savart formula, while their Lagrangian map is directly applied to the velocity. They have to reproject their velocity field on ∇.u = 0 while we get divergence free fields by construction. We hence expect our method should be more realistic, as both vorticity stretching effects and diffusion are retained while in effect, they neglect pressure terms and diffusion.
In a later paper, the same authors Rosales & Meneveau (2008) noticed that they could improve their method by cutting single Lagrangian steps into smaller ones as scales become finer. They considerably improved the realism of the anomalous exponents using this approach, which they call multiscale turnover Lagrangian map (MTLM for short). We note that we could also incorporate this multi-stepping into our MuScaTS method, although it would increase its cost. Our method could perhaps also benefit from the fast algorithms designed by Malara et al. (2016) to improve the efficiency of the MTLM method.
Finally, Subedi et al. (2014) designed an incompressible MHD version of the MMLM method. MuScaTS without diffusion or deformation applied to the choice of variable W = (∇ × u, B) and using 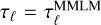 should amount to the same model except we advance the vorticity ∇ × u rather than the velocity, which directly generates divergence free fields (we would however still have to clean the divergence of the magnetic field). The extension of Subedi et al. (2014) by Lübke et al. (2024) proceeds with advection from an already non-Gaussian field and produced convincing coherent structures. Our own implementation will advect along an already deformed field which contains physically motivated non-Gaussianities: we hence expect that the MHD version of MuScaTS should perform equally well if not better, but this remains to be demonstrated.
should amount to the same model except we advance the vorticity ∇ × u rather than the velocity, which directly generates divergence free fields (we would however still have to clean the divergence of the magnetic field). The extension of Subedi et al. (2014) by Lübke et al. (2024) proceeds with advection from an already non-Gaussian field and produced convincing coherent structures. Our own implementation will advect along an already deformed field which contains physically motivated non-Gaussianities: we hence expect that the MHD version of MuScaTS should perform equally well if not better, but this remains to be demonstrated.
3.2 Comparison to Chevillard et al. (2011) (CRV)
The link between MuScaTS and CRV is slightly less direct. We need to rework the equations quite a bit to highlight the similarities and differences.
First, we expose part of our model in a way that eases the comparison. The work of CRV is in the context of 3D Navier-Stokes incompressible equations, so in our framework we take W = (w) where w is the vorticity. We neglect diffusion, or in other words we focus on the inertial range. If we now neglect advection rather than deformation, as in CRV, then only the exponential term remains in Equation (30) which we rewrite more precisely here as
![Mathematical equation: $\tilde w_\ell ^{S \ne 0}\left( x \right) = \exp \left( {{\tau _\ell }S\left[ {{{\tilde w}_{ \ge \ell }}} \right]} \right).w_\ell ^0\left( x \right),$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq98.png) (44)
(44)
to make clear the intricate dependence of S on the larger scales. If to parallel the work of CRV we now approximate the argument of S by its value ab initio, we get
![Mathematical equation: ${\tilde w_\ell }\left( x \right) = \exp \left( {{\tau _\ell }S\left[ {w_{ \ge \ell }^0} \right]} \right) \cdot w_\ell ^0\left( x \right)$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq99.png) (45)
(45)
or now using Equation (11), we obtain
![Mathematical equation: ${\tilde w_\ell }\left( x \right) = \exp \left( {\int_{s \ge \ell } {{\rm{d}}\,\ln \,s\,} {\tau _\ell }S\left[ {w_s^0} \right]} \right).w_\ell ^0\left( x \right),$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq100.png) (46)
(46)
and, integrating over all scales, we finally get
![Mathematical equation: ${\tilde w^{{\rm{MuScaTS}}}} = \int_{ - \infty }^{ + \infty } {{\rm{d}}\,\ln } \,\ell \,\exp \left( {\int_{s \ge \ell } {{\rm{d}}\,\ln \,s\,} {\tau _\ell }S\left[ {w_s^0} \right]} \right).w_\ell ^0.$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq101.png) (47)
(47)
This formula is our comparison point to CRV’s work below.
Then, let us reformulate part of CRV’s model. In their work, they construct a non-Gaussian random velocity field as the result of the vortex stretching of some initial Gaussian vorticity field w0. Concretely, they consider for w0 a Gaussian white noise vector (that we here denote η) and insert into a Biot-Savart-type formula a proxy for the vorticity field of the form
![Mathematical equation: ${w^{{\rm{CRV}}}} = \exp \left( {{\tau _{{\rm{CRV}}}}{S^{{\rm{CRV}}}}\left[ {{w^0}} \right]} \right).{w^0},$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq102.png) (48)
(48)
where τCRV is a parameter which controls the amount of stretching, as it relates2 to the correlation timescale of the velocity gradients, and SCRV[w0] is a matrix field encoding the stretching of w0 during a typical time τCRV. Now, as a general rule, given a vorticity field w the stretch matrix field reads3
![Mathematical equation: $S\left[ w \right]\left( x \right) \propto \int {{{\rm{d}}^3}\,y{{r\, \otimes \left( {r \times w\left( y \right)} \right) + \left( {r \times w\left( y \right)} \right) \otimes r} \over {{r^5}}}} ,$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq103.png) (49)
(49)
where r ≡ x − y and ⊗ denotes the tensor product. In addition, an important feature which is universally observed in both experiments and numerical simulations of turbulence, is that turbulent fields are multi-fractal and have long-range correlations. This formally translates into S[w] being log-correlated in space, and a key point in CRV’s work which greatly increases the realism of their model, is to implement this feature into their formulae through a simple, effective rule4, namely by just changing the exponent in the power-law r5 of the denominator of the general form (49). Specifically, by choosing η for their w0 they adopt the rule r5 → r7/2, i.e. they consider (cf. CRV, Equation (12))
![Mathematical equation: ${S^{{\rm{CRV}}}}[\eta ]\left( x \right) \propto \int {{{\rm{d}}^3}\,y{{r\, \otimes \left( {r \times \eta \left( y \right)} \right) + \left( {r \times \eta \left( y \right)} \right) \otimes r} \over {{r^{7/2}}}}} ,$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq104.png) (50)
(50)
and this simple tweak makes their stretch field log-correlated as it should.
Hence, in CRV’s work, log-correlation appears through a cunning but somewhat artificial change of exponent, while the stretching timescale τCRV remains a mere parameter: in particular it is scale-independent. Inspired by their line of thinking, we now suggest an alternative approach in which we retain the physical scaling for the stretch, but we now introduce a scale-dependency of the stretching timescale to achieve log-correlation. Concretely, starting from expressions (48) and (49), and imposing log-correlation with a similar scaling argument as CRV’s, we now build expression (55) below, which is reminiscent of the scale-decomposition (47) of our model and may thus be interpreted in terms of a scale-dependent stretching timescale.
To improve on the physical interpretation of CRV, instead of choosing as initial condition w0 the simple Gaussian white noise η we also adopt a slightly more sophisticated Gaussian field w0 with the Kolmogorov (1941) power spectrum of the vorticity (i.e. with a spectrum scaling as 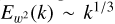 . But doing so first raises the question: how is CRV’s effective rule then modified? To answer this, we suggest the following rough scaling argument. In Fourier space, for a given corona of radius k and infinitesimal thickness dk, by definition of the spectrum
. But doing so first raises the question: how is CRV’s effective rule then modified? To answer this, we suggest the following rough scaling argument. In Fourier space, for a given corona of radius k and infinitesimal thickness dk, by definition of the spectrum 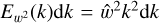 , so our choice of Kolmogorov scaling implies
, so our choice of Kolmogorov scaling implies 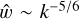 . Then, since the Fourier transform of a power law r−α is kα−d where d = 3 is the dimension of space, our scaling in Fourier space corresponds to a scaling w ~ r5/6−3 in position space. Hence, compared to CRV’s case, we have an additional power r5/6−3 in the numerator of the ratio in (50), so log-correlation requires that we adjust the exponent in the denominator to compensate it, i.e. we consider
. Then, since the Fourier transform of a power law r−α is kα−d where d = 3 is the dimension of space, our scaling in Fourier space corresponds to a scaling w ~ r5/6−3 in position space. Hence, compared to CRV’s case, we have an additional power r5/6−3 in the numerator of the ratio in (50), so log-correlation requires that we adjust the exponent in the denominator to compensate it, i.e. we consider
![Mathematical equation: ${S^{{\rm{CRV}}}}[{w^0}]\left( x \right) \propto \int {{{\rm{d}}^3}\,y{{r\, \otimes \left( {r \times {w^0}\left( y \right)} \right) + \left( {r \times {w^0}\left( y \right)} \right) \otimes r} \over {{r^{4/3}}}}} ,$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq108.png) (51)
(51)
where the denominator should be understood as r7/2+(5/6−3) = r4/3. This is our modification to CRV’s effective rule.
Now, to draw a parallel with the MuScaTS construction, let us build this stretch matrix SCRV[w0] from a continuous series of narrow filters, by decomposing it into various scales with (9) and using the linearity property (21). We thus have
![Mathematical equation: ${S^{{\rm{CRV}}}}[{w^0}] = \int_{ - \infty }^{ + \infty } {{\rm{d}}\ln } \,\ell \,{S^{{\rm{CRV}}}}[w_\ell ^0],$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq109.png) (52)
(52)
but in fact, to be complete, since in CRV’s model what drives the dynamics is the full argument of the matrix exponential in (48), we also need to take into account the τCRV parameter. Here instead of this mere parameter, we introduce some scale-dependent τℓ in the scale-decomposition (52) such that
![Mathematical equation: ${\tau _{{\rm{CRV}}}}{S^{{\rm{CRV}}}}[{w^0}] = \int_{ - \infty }^{ + \infty } {{\rm{d}}\ln } \,\ell \,{\tau _\ell }S[w_\ell ^0],$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq110.png) (53)
(53)
where S is the real, physical stretch (49), i.e. with a r5 denominator. Then, to reconcile the r4/3 requirement for log-correlation of (51) with the real physical r5 dependency of the stretching, we argue (pursuing the hand-wavy reasoning consisting in keeping track and matching length scales) that a power-law dependency
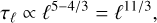 (54)
(54)
is adequate. Finally, using in (48) expression (53) and the scale decomposition (9) for w0, we rewrite the CRV random field in the following form, which is close to our (47),
![Mathematical equation: ${w^{{\rm{CRV}}}} = \int_{ - \infty }^{ + \infty } {{\rm{d}}\ln } \,\ell \,\exp \left( {\int_{ - \infty }^{ + \infty } {{\rm{d}}\ln } \,s\,{\tau _s}S[w_s^0]} \right) \cdot w_\ell ^0,$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq112.png) (55)
(55)
with τℓ given by (54) when the vorticity has a Kolmogorov (1941) power-law spectrum. It is in this sense that we mean that the change of power-law to enforce log-correlation in CRV could be interpreted as an integration time varying with scale, with a typical timescale τℓ ∝ ℓ11/3.
This unusual perspective on their theory enables us to explain more of the original physical grounds behind CRV’s construction. Thanks to the freedom introduced by the scale dependent stretch parameter, we can both retain the physical expression for the stretch (with 1/r5 scaling) and assimilate the generating Gaussian field as the initial vorticity (using Kolmogorov scaling instead of a white noise).
Now, comparing the above reformulations of both formalisms, we reveal three noteworthy differences. First, as can be seen in (46), we use a stretch field in the larger scales which has already been advanced, while CRV uses the initial stretch field at all scales. Second, (47) confronted to (55) shows that in our formulation the effective timescale τℓ applies to all scales above while it is local in scales in CRV. Third, the integration bounds differ: we integrate only the scales above ℓ while CRV uses the whole range of scales. In other words, our method suppresses the effects of the smaller scales deformation at a given scale. This might yield less intermittency because the smallest scales which can lead to the largest exponentiated spikes will be suppressed. On the other hand, it may be an improvement for the coherence of the resulting structures compared to Chevillard et al. (2011). Indeed, smoothing avoids strong deformations from very small scales which could result in less correlation between contiguous scales as the strongest peaks at the smallest scales might dominate every scale. In the case of the Zel’dovich Approximation, it was in fact recognised that some smoothing improved the accuracy of the approximation for a given targeted evolution time, which led to the truncated Zel’dovich Approximation (e.g. Coles et al. 1993).
Future investigations of the MuScaTS method in the 3D incompressible HD case will decide which formulation performs best. Finally, note that MuScaTS also retains both advection (neglected in CRV) and diffusion (approximated by a regularisation cut-off at small scales in CRV).
3.3 Links to the Zel'dovich multiscale approximation
In cosmology, the concept of multiscale is directly related to hierarchical formation of structures, in particular dark matter haloes. In the concordance model of large-scale structure formation, dark matter haloes are the hosts of galaxies and clusters of galaxies and their history consists of successive mergers. In this bottom-up scenario, small haloes form first and then merge together to form a population of larger haloes. The Lagrangian regions occupied by these haloes define a smoothing scale, which can itself be associated with a mass and a timescale of halo formation (Press & Schechter 1974). In this picture, mergers are equivalent to connections between Lagrangian regions.
As a result, the dynamical process at play can also be described with a multiscale approach accounting for dynamical collapse times of haloes of various masses associated with a smoothing level.
The Zel’dovich approximation (ZA) consists in a ballistic integration of initial velocities. Smoothing initial conditions to the ZA was shown to improve the solution, because it avoids the dispersion resulting from shell crossing. This led to the so-called truncated ZA (e.g. Coles et al. 1993) or higher order Lagrangian truncated perturbation theory (e.g. Bernardeau et al. 2002, and references therein), where the level of truncation is the smoothing scale. In the hierarchical formation of haloes described above, the truncated ZA (or its higher order equivalent) can be improved further by a multiscale approach : a smoothing length depending on the local position is defined. This multiscale synthesis of dark matter dynamics, has been implemented with success by different authors (see e.g. Bond & Myers 1996; Monaco et al. 2002; Stein et al. 2019). In these existing multiscale approaches, at every initial position, one finds the largest smoothing scale which does not collapse at the targeted redshift. This identifies both the smoothing length and the evolution time during which this Lagrangian region is evolved.
As mentioned in Section 2.2.4, the equations of large scale structure formation including the expansion of the Universe can be cast in our generic form (13), and we use a ballistic approximation which in this context amounts to ZA. A multiscale ZA can therefore directly emerge from our MuScaTS framework. In our MuScaTS approach, we suggest to identify the coherence time with the Press & Schechter (1974) collapse time at a given smoothing length, capped by the total time corresponding to the targeted redshift. This results in two subtle differences compared to existing ZA approaches. First, the collapse time at an intermediate scale is computed on a field which has already been advanced at the targeted redshift on the largest scales. Second, every bandpass filtered density field is evolved separately during its own timescale. This may result in different performances compared to existing methods, and it remains to be checked whether they are better or worse. However, the principle of the resulting method is still very close to the original multiscale ZA approaches.
4 Validation for 2D incompressible hydrodynamics
In the previous sections, we presented our MuScaTS framework to generate random realisations of a variety of flows. We provided a possible numerical implementation of the procedure. We also connected our synthesis to previously known generating methods in a few specific contexts.
We now turn to validate the method in the simplest possible setup: incompressible 2D hydrodynamics. Our generative procedure deforms an initial Gaussian field under the influence of the flow. We assess to what extent our synthesis is able to recover the statistics obtained when the flow evolves from an initial Gaussian field with a prescribed spectrum.
To that end, we run accurate simulations of the flow (using a pseudo-spectral code presented below in Section 4.1) starting with a large number (here, 30) of independent initial random realisations of Gaussian fields with a prescribed power-law spectrum. As remarked in the presentation of our framework above, several methodological choices need to be defined. We consider a fiducial version of our synthesis method, which we call the ‘basic’ synthesis, and introduce a few variants in Section 4.2 that span several ways of estimating the divorticity evolution and the coherence time. We quantitatively compare the performances of our syntheses first in the eyes of classical statistical indicators (Section 4.3) and second with the help of texture sensitive statistics (Section 4.4).
4.1 Reference 2D simulations
Throughout this work we use reference simulations to test our synthetic model. We briefly state here the details of our numerical implementation of a pseudo-spectral code to evolve 2D incompressible hydrodynamics.
We integrate the evolution Equation (14) on a square periodic domain. We choose the length scale normalisation such that the domain size is L = 2π and define our velocity scale such that the expectancy of the initial velocity squared is unity, namely E[〈u2〉] = 1 where E is the expectancy over all our realisations and 〈.〉 denote the average over our computational domain. Note that we do not require that the initial r.m.s. velocity is unity for every realisation, as this would destroy the Gaussianity of our initial process. The Reynolds number is hence on average ![Mathematical equation: ${R_e} = E\left[ {\sqrt { < {u^2} > } } \right]L/\nu = 2\pi /\nu $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq113.png) initially, and then decays as time proceeds while velocity is dissipated by viscous friction. Simulations are run with a pseudo-spectral method at a Courant number of 1, with a Runge-Kutta integration scheme of order 4, using a 2/3 truncation rule.
initially, and then decays as time proceeds while velocity is dissipated by viscous friction. Simulations are run with a pseudo-spectral method at a Courant number of 1, with a Runge-Kutta integration scheme of order 4, using a 2/3 truncation rule.
The initial field is chosen to be random, Gaussian with a prescribed Fourier spectrum Eu (k) ∝ kβ. More specifically, we draw a random Gaussian white noise in real space, compute the Fourier coefficients, imprint the spectrum by multiplying the resulting coefficients by Cβkβ where Cβ is chosen to comply with E[〈u2〉] = 1, and finally we get back to real space. The initial turnover timescale averaged over our realisations is hence ![Mathematical equation: $L/\sqrt {E\left[ {\left\langle {{u^2}} \right\rangle } \right]} = 2\pi $](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq114.png) in our units. The seed of the random noise is controlled by the integer parameter seed in the intrinsic FORTRAN random generator, which allows us to select various independent but deterministic realisations of the noise.
in our units. The seed of the random noise is controlled by the integer parameter seed in the intrinsic FORTRAN random generator, which allows us to select various independent but deterministic realisations of the noise.
The resolution is set by the number N of grid elements per side of the square domain, hence the pixel size is simply ∆x = L/N = 2π/N. The time step length is variable, defined by the Courant number parameter CFL through the relation ∆t = CFL∆x/|u|mαx. We set the Courant number to CFL = 1. The top-left panel a on Figure 3 illustrates one such initial vorticity map.
Our basic run is N = 1024 pixels aside for a viscous coefficient v = 10−4 with an initial power-law spectrum with a slope β = −3. This power-law spectrum corresponds to the power-law slope predicted in stationary 2D turbulence for the enstrophy cascade from the injection scale towards the small scales (Kraichnan 1967).
We evolve the simulation from these initial conditions during a total integration time t. The bottom-left panel e on Figure 3 illustrates the vorticity map after the initial Gaussian field has been evolved to t = 2, i.e. during about a third of a turnover timescale. Figure 4 present the same results after one turnover timescale. Clumps of vorticity quickly form, positive blobs rotate clockwise while negative ones (with w < 0) rotate counter-clockwise, displaying distinctive trailing spiral arms. Fluid in between the vorticity clumps gets sheared into filaments extremely elongated after about one turnover time (t = 6).
4.2 Basic synthesis and variants
We compare the above reference simulation to several variants of our synthesis method. We first present the parameters for our basic synthesis. It advects vorticity, using a coherence time τℓ based on the local strain time and the target ’age’ t of the simulation (see Section 2.4.2). The filtering is realised with our cosine isotropic filter (see Appendix B). We use the same resolution N, spectral index β and viscosity v as for the simulations, and we compare results at the same global evolution time t (see panels e and f in Figure 3 for t = 2 and Figure 4 at t = 6).
We now develop our investigation of the variants around our basic synthesis. In the remaining panels of Figures 3 and 4 (panels b-d and g-h), we consider several variants of a MuScaTS synthesis based on the divorticity field. In particular, we assess the relative importance of the advection and deformation (stretch in 2D) terms, both in order to prepare for the 3D case and in order to link to the previous works of CRV and Rosales & Meneveau (2006). We investigate the effect of the ordering of the advection term before or after the deformation term (see panels c and g of Figure 3). We investigate the effect of including only deformation as in CRV or only advection as in Rosales & Meneveau (2006) (see panels d and h in Figure 3). Finally, we test the effect of computing the deformation at first order instead of developing it fully through a matrix exponential (panel b in Figure 3).
Visual inspection of Figure 3 reveals that our basic synthesis (panel (f) for our synthesis on vorticity) does a rather good job at capturing the spiralling shape of the vorticity clumps, but the texture of the vorticity feels more patchy than in the simulation, specially at late times (see Figure 4). The three syntheses based on divorticity which retain both advection and deformation (panels b, c and g) seem to perform slightly less well, although the first order version of the deformation (panel b) is close to our basic synthesis (panel f). The two divorticity syntheses which skip one of these two terms (panels d and h) perform significantly less well. The stretch only case (panel d) recovers part of the filamentary texture and the advection only case (panel h) seems the worst, although the positions of the two large scale clumps of vorticity seem reproduced.
We also played with the coherence time τℓ. We tested a constant τℓ, which leads to a significant loss of realism (not shown here). And we tested a τℓ based on the local shell crossing time or the local stretch time (see Section 2.4.2), without observing significant improvement from the strain based time. Finally, we tried both the Cosine and spline filters (see Appendix B) without observing much of a difference.
Figures 3 and 4 present a simulation and a few synthesis variants for a single common initial Gaussian field. We now assess the statistical quality of each variant of our synthesis by running a reference set of simulations with 30 independent initial Gaussian conditions. In the next sections, we compute a selection of statistics on these 30 independent realisations to estimate their mean and variance. We then compare the same statistics on each variant of our syntheses generated from thirty other independent Gaussian fields. We thus get quantitative estimates of the performance of our synthesis for each choice of statistical indicators.
 |
Fig. 3 Vorticity maps for various cases (see text), all based on the same original Gaussian field (displayed in panel a). The panels show the following: (a) initial conditions; (b–d) divorticity syntheses with (b) first order deformation, (c) advection then deformation, and (d) deformation only; (e) reference simulation at t = 2 (about 1/3rd turnover timescale); (f) basic synthesis for vorticity; (g, h) divorticity syntheses with (g) deformation then advection and (h) advection only. All syntheses are shown at the same time, t, as for the simulation and a coherence time based on the local strain time (See Section 2.4.2). |
4.3 Classical statistical indicators
After Kolmogorov (1941) discovered his famous power-spectrum law for 3D incompressible hydrodynamics, Kraichnan (1967) was the first to extend it to 2D incompressible hydrodynamics. He predicted that in forced 2D turbulence the velocity power spectrum should scale as k−5/3 above the injection scale (indirect energy cascade) and as k−3 below it (direct enstrophy cascade). This was later verified both in soap film experiments (Rutgers 1998; Bruneau & Kellay 2005) and in simulations (Boffetta 2007).
Intermittent corrections to these power-law behaviours were shown to be very weak in the indirect cascade (Boffetta et al. 2000). Very weak non-Gaussianities were detected in the velocity increments probability distribution functions (PDFs), whether measured in experiments (Paret & Tabeling 1998) or simulations (Boffetta et al. 2000; Pasquero & Falkovich 2002). The PDF of vorticity increments on the other hand were predicted to display exponential tails by Falkovich & Lebedev (2011). Indeed, significant deviations from Gaussianity were observed for the vorticity increments in simulations by Tan et al. (2014). As a result, we choose to focus on vorticity increments rather than velocity increments since those provide an easier measurement of intermittency compared to velocity increments.
Analogues of the exact Kármán Howarth Monin relation in 3D exist for both the indirect cascade of energy and the direct cascade of enstrophy in 2D. Eyink (1996) showed that in the indirect cascade, the energy transfer function
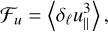 (56)
(56)
where brackets denote both space and ensemble averaging, has to be positive and proportional to ℓ. This is linked to slight asymmetries in the PDFs of the longitudinal velocity increments, with a bias towards positive values for δℓu|| at large values of δℓu||. On the other hand, in the direct cascade, the enstrophy transfer function
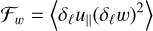 (57)
(57)
was predicted to be negative and proportional to ℓ (Paret & Tabeling 1998), see also Bernard (1999). This second result also involves asymmetries of the longitudinal velocity increments, but correlated to the vorticity increment (which is itself symmetric): it is caused by a bias for negative values of δℓu|| conditioned on large vorticity increments. In the following we examine both the energy and enstrophy transfer functions ℱu and ℱw as probes of these second order behaviours of the increments PDFs.
The above results were obtained at steady state in driven turbulence. However, here we deal with decaying turbulence, so none of these results may hold. Nevertheless, we use these classical indicators, power spectra, increments PDFs and transfer functions, as quantitative measurements to assess how our syntheses perform compared to actual simulations.
 |
Fig. 5 Classical statistics averaged over 30 realisations for (a) power spectrum, (b) vorticity increments (for lags of 1, 4, and 32 pixels), (c) the energy transfer function, ℱu, and (d) the enstrophy transfer function, ℱw. Green is for the initial conditions (of the syntheses), red for the MuScaTS syntheses (basic run), and blue for the simulations at time t = 2. Shaded areas give the one-sigma error around the mean over the 30 independent realisations (i.e. mean plus or minus standard deviation divided by |
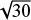
4.3.1 Power spectra
In panel a of Figure 5, we compare the average power spectra over all 30 realisations (reference simulations in blue and synthesis in red, while initial conditions are in green). Both the slope in the inertial range power-law behaviour and the power spectrum shape in the dissipation range seem equally well recovered. On these figures, the shaded area give the error on the mean as estimated from the dispersion over our 30 realisations. It should be stressed that these error estimates are similar between the simulations and the synthesis. In other words, the synthesis is able to reproduce not only the average, but also the variance of the power spectrum across the 30 members of our statistical ensemble. After about one turnover timescale, both the power spectrum and its variance are still well accounted for (see Figure 6).
4.3.2 Increments statistics
We compute δℓX(r) = X(r + ℓ) − X(r) as the increment of a quantity X over a lag ℓ at position r in the map. We then examine the statistics of all increments which have their lag ℓ in a corona of width 1 pixel around a prescribed norm in pixels. For instance, the PDF of vorticity increments at various lags (in pixels) is displayed in panel b of Figure 5. The PDF in the simulation experience large departures from Gaussianity. If we take as metric the logarithm of the PDF wings, at t = 2 (i.e. a third of a turnover time), a significant fraction of the non-Gaussianity of vorticity increments is reproduced (synthesis takes us more than half way between Gaussian and initial conditions). Also, the relative dispersion of these results is well estimated, too. At one turnover timescale (see Figure 6), the discrepancy between the PDFs from simulations and synthesis is larger (simulations have slightly increased their departure from Gaussianity while syntheses are still at about the same place).
4.3.3 Transfer functions
As mentioned above, in steady state forced 2D turbulence, the energy transfer function ℱu is expected to be positive (indirect cascade) for scales above the forcing scale, while the enstro-phy transfer function ℱw should be negative for scales below. Although we have no forcing here, our decaying turbulence simulations display the same signs for the energy transfer functions. Early 3D generative models such as Rosales & Meneveau (2006) or Chevillard et al. (2011) recognised that it is a real challenge to obtain random fields which can account for the non-zero transfer of energy. Here, our synthesis is able to account not only for the correct sign of these transports but also for their shape, as shown in panel c and d of Figure 5. Their magnitude however is underestimated in the syntheses. The agreement is actually better at later times (see Figure 6) because as time proceeds the total energy in the simulation decays while the syntheses become frozen as the strain time is reached everywhere. Finally, most of the relative dispersion of these quantities is reproduced by the synthesis, at all times.
4.4 Scattering transform statistics
Scattering transform statistics are a modern and powerful tool characterising textures (Mallat 2012). In the context of cos-mological simulations, Allys et al. (2020) have shown that wavelet phase harmonics are able to predict many other non-Gaussian indicators (increment statistics, Minkowsky functionals, bi-spectrum).
Here, we present an analysis of our results using wavelet scattering transform (WST) coefficients. The first layer WST coefficients of a field X are defined as
 (58)
(58)
where 〈〉θ denotes the combination of ensemble average, spatial average over the computational domain and average over θ. They constitute a statistical probe similar to the power spectrum, with additional sensitivity to sparsity5 introduced by the use of the L1-norm instead of the L2-norm. We do not show the results, as they are very similar to those obtained for the power spectra (see Section 4.3.1).
We then define normalised layer 2 coefficients as
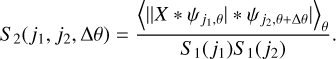 (59)
(59)
The layer 2 coefficients (S 2) estimate the coupling between two angles θ1 and θ2 = θ1 + ∆θ and two scales 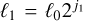 and
and 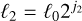 labelled by j1 and j2, with ℓ0 the smallest scale considered (note that by convention scales are labelled by increasing order in WST coefficients). In our case, thanks to isotropy, the coefficients depend only on the difference ∆θ = θ1 − θ2 and we have checked that indeed there is very little dispersion of the coefficients at fixed ∆θ, j1 and j2 when θ1 varies. The shaded areas on Figure 7 actually reflect the dispersion resulting from the spatial average over the vorticity fields, the ensemble average over our 30 realisations and from the angular average over θ1. These shaded area are so thin that they look like solid lines. With our 1024 pixels resolution, we chose nine dyadic scales along with 16 angles. On Figure 7 we plot the normalised S2 coefficients at t = 2 (i.e. about one third of a turnover time).
labelled by j1 and j2, with ℓ0 the smallest scale considered (note that by convention scales are labelled by increasing order in WST coefficients). In our case, thanks to isotropy, the coefficients depend only on the difference ∆θ = θ1 − θ2 and we have checked that indeed there is very little dispersion of the coefficients at fixed ∆θ, j1 and j2 when θ1 varies. The shaded areas on Figure 7 actually reflect the dispersion resulting from the spatial average over the vorticity fields, the ensemble average over our 30 realisations and from the angular average over θ1. These shaded area are so thin that they look like solid lines. With our 1024 pixels resolution, we chose nine dyadic scales along with 16 angles. On Figure 7 we plot the normalised S2 coefficients at t = 2 (i.e. about one third of a turnover time).
This powerful tool is much more stringent than the increments and probes much more accurately the defects of our synthesis. The synthesis correctly captures the relative variation of the coefficients with ∆θ but fails at reproducing the proper slope of the power-law decay with ∆j = (j2−j1) (although the decay is still somewhat power-law like). At later times (not shown here), the angular variation is also lost by the synthesis. We stress here that although the classical indicators shown in Section 4.3 were poorly sensitive to the texture differences, the WST coefficients provide a much better quantitative assessment of the discrepancies detected by an eye inspection of Figure 3. Indeed, WST statistics are known to produce remarkable syntheses (Allys et al. 2019) and constitute a very practical tool to partly assess quantitatively what our eyes are able to probe. First, in this metric, the distance between simulations and syntheses relative to the distance between initial conditions and final result is much larger compared to classical indicators. The synthesis works us a much smaller path towards the actual non-Gaussianities in the eyes of scattering statistics. Second, the discrepancy has a lot more statistical significance: the very small amount of dispersion for these layer 2 coefficients greatly helps us disentangle the results between the simulations and our generative models.
We also attempted to find good reduced models for the variation of the layer two coefficients with respect to the relative angle ∆θ, in the spirit of the reduced WST presented in Allys et al. (2019). We found that the generic shape S2(i, j, ∆θ) ∝ αi−j + βi−j cos(2∆θ) + γi−j cos(4∆θ) provides a good fit to the data, but opted not to show the resulting adjustments to prevent overloading the paper.
 |
Fig. 7 Mean over 30 realisations of layer 2 WST coefficients S2(j1, j2, ∆θ) (see text) for initial conditions (green), the reference simulation (blue) at about a third of a turnover time (t = 2), and MuScaTS basic syntheses over a time t = 2 (red). The main length scale runs from its index j1 = 0 (smallest) to j1 = J − 3 = 7. The secondary scale j2 is labelled by ∆j = j2 − j1. The relative angle ∆θ runs from 0 to π from left to right in each broken line of fixed j1 and ∆ j. The width of the lines indicates the standard deviation of this mean over our 30 realisations, the computational domain, and the absolute angle θ1. |
 |
Fig. 8 Same as Figure 7 but with a four-step bootstrap (see text of Section 5.4 and see also Figure 9). |
5 Discussion
In this section, we provide a brief account of the parameter space investigation we have conducted. We also discuss a few of the shortcomings of our method.
5.1 Filter shape
Although all the results of the present paper are computed with a bank of filters based on our cosine filters, we have also investigated B3-spline filters (see Appendix B). There are very slight differences between the two, hardly significant statistically and we do not show them here. We chose to present the cosine filters because they can cover the Fourier space at a slightly lower cost. In a paper which inspired us for this work, Lewalle (2010) showed how Gaussian based wavelets (Mexican hats) greatly simplify the analytical expressions for the filtered equations. Mexican hats might hence be best suited for theoretical work based on our MuScaTS framework (their weak selective power may hinder the quality of the syntheses, though).
5.2 Divorticity
As shown above (see Section 2.2.2), the evolution equations for 2D incompressible hydrodynamics for the divorticity also suit our generic formalism (13), with both an advection and a deformation term present, very similar to the structure obtained for the 3D vorticity evolution equations.
We find that our method performs very slightly better when we base it on the vorticity evolution equation rather than on the divorticity equation. This might be due of the presence of two terms (advection and deformation) in the divorticity evolution equation. Also, it may be due to the fact that the divorticity power spectrum is even more biased towards the small scales than the vorticity spectrum. Finally, the divorticity remapping introduces spurious non zero divergence in this divergence free field, while the vorticity field does not suffer from this, as it is a scalar in 2D.
We have investigated several variants in the implementation of our method applied to divorticity in 2D. We swapped the order between advection and deformation, without finding significant change (compare panels c and g on Figure 3). We tested the full matrix exponential implementation of Equation (31) and its linearised version in τℓ, with a slight preference for the latter implementation (compare panels b and c on Figure 3). This might be due to the better consistency between the ballistic approximation for the advection term and a first order approximation in time for the deformation. Classical indicators are almost blind to whether vorticity or divorticity is advanced, with a slight preference for the latter method for the vorticity increments while transfer functions are better reproduced in the former case. Vorticity maps and WST coefficients give a slight preference to the treatment of vorticity rather than divorticity.
The above choices retaining both advection and deformation for the implementation of MuScaTS on the divorticity were not critical. But we found a huge difference when either the advection or the deformation term were omitted, as panels d and h in Figure 3 can testify. Even the classical indicators suffer from the loss of either of these terms. This is a good sign for future implementation of our method in the 3D case which should perform even better when compared to existing methods such as Rosales & Meneveau (2006) or Chevillard et al. (2011) and their extensions.
5.3 Choosing the coherence time
Most results presented here have used a coherence time based on a smooth minimum between the local strain time (see our last choice in Section 2.4.2) and the global target time. However, we have also investigated the usage of a constant global target time, with significantly less accurate results. We also tested a coherence time uniform in space, but dependent on scale as a power-law (which resulted in significantly less accuracy). And finally we tested the other options based on the local shell crossing time or the local stretch time and found the method appeared slightly less accurate in view of the statistical indicators we tested. Perhaps future investigations in compressible or 3D applications will help us better understand which version of the coherence time is most appropriate.
5.4 Bootstrapping
Since our method performs better during a smaller fractions of the initial turnover timescale, it is natural to try and start a new MuScaTS step from the resulting snapshot obtained instead of using the initial Gaussian conditions. We have hence split the integration step in two or four smaller successive MuScaTS steps to test the convergence of the method, a process we denote as bootstrapping. The resulting improvement on the vorticity maps is striking, as quantified by the WST coefficients (see Figure 8) and as illustrated by the vorticity maps displayed on Figure 9.
Bootstrapping is a poor man’s way of probing higher order schemes, hence it augurs well for the performance of future higher order methods. It is also a sign that for steady state turbulence we need better statistics than Gaussian conditions to randomly reshuffle our stochastic terms: including some non-Gaussianity (that of the previous step, when bootstrapping) in these pseudo initial conditions makes an important improvement. This resonates with the findings of Lübke et al. (2024) who found realistic coherent MHD structures when they started the method of Subedi et al. (2014) with a non-Gaussian initial field. Finally, the realism of the resulting solution shows that despite the strong approximations we made in deriving our filtered equations, we did not lose too much of the essential physics.
5.5 Power spectrum shape
All results shown in this paper are based on an initial velocity power spectrum proportional to k−3. However, we have also tested a less steep power spectrum, scaling as k−5/3, corresponding to the indirect energy cascade. This last spectrum is less dominated by the large scales, and in particular the vorticity field and more importantly the stretching field is then dominated by the small scales. This may explain why we have found our statistical comparison is significantly less good in this shallower spectrum case (not shown here).
Indeed, in the current application of our method we apply a single sweep through scales from the largest to the smallest, implicitly considering scale causality in a unique direction. In future work, we will investigate the possibility of implementing corrections to account for the feedback of the small scales to the largest (see further discussion in Section 5.6).
In this paper, we have investigated only decaying turbulence. In principle, it is easy to incorporate a forcing term in our partial differential equations. However, a shortcoming of our method is that we have to introduce a power spectrum for the ’initial conditions’ 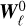 . To estimate this power spectrum, we could resort to theoretical inputs, we could bootstrap our method until we get a steady power spectrum, or there may exist analytical considerations on energy conservation to provide the power spectrum shape from the filtered equations alone.
. To estimate this power spectrum, we could resort to theoretical inputs, we could bootstrap our method until we get a steady power spectrum, or there may exist analytical considerations on energy conservation to provide the power spectrum shape from the filtered equations alone.
 |
Fig. 9 Vorticity maps for one realisation of our basic case at t = 2. The four panels, labeled from (a) to (d), show respectively: (a) the simulation, (b) the same as panel d of Figure 3, (c) a two-steps bootstrap (∆t = 1) and (d) a four steps bootstrap (∆t = 0.5). See text for more details. |
5.6 Small-scale terms
We have currently bundled all small-scale terms of our scale filtered Equation (25) into a ’stochastic small scales’ term with which we deal with in an extremely expedient manner. A large legacy of literature tackles coarse-graining or Reynolds averaging, which leads to convective terms, turbulent diffusion, small scale dynamo, eddy viscosity which all result from the filtering of the small scales terms. Estimation of these terms requires some sort of closure. Most methods adopt some sort of linear approximation to compute correlations between small-scale terms, such as the first order smoothing approximation (FOSA), also known as second order correlation approximation (SOCA), as introduced in Krause & Raedler (1980), or mixing length theory approaches (MLT, see Lesaffre et al. 2013; Jermyn et al. 2018, and references therein). Test-field techniques have sometimes been used to validate these approaches in numerical simulations (Brandenburg et al. 2008; Käpylä et al. 2020).
Here, we simply have short-circuited these considerations by randomly reshuffling the state variables of the gas over one coherence timescale. However, once we have a first guess for the properties of our flow thanks to a first sweep from large to small scales, we could imagine refining the scale filtered evolution equations thanks to these terms which can be readily computed on that first guess. This would recover some of the causal influence of the small scales onto the large ones that our method currently completely neglects.
It seems paradoxical that we can still get correlations such as energy transfers from small to large scales (as in our 2D example above where we get a positive energy transfer function). This means that in our 2D HD synthesis, large scales conspire to arrange velocities in such a way that there is a net energy transfer towards larger scales. Only, due to the single direction of our sweep from large to small scales, that energy transfer is not imprinted on the evolution equations. In our current investigation, it does not seem to be critical. However, there may be applications where it could be important, in particular when the spectrum is shallower, but also in cases when small-scales dynamos are at play (i.e. when some small scales instabilities lead to exponential growth of larger scale averaged quantities).
We finally point here to a slight inconsistency in our formalism: the filtered field 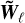 at scale ℓ may acquire power at other scales from its approximate filtered evolution Equation (28). This may happen through convergence and divergence of trajectories in the ballistic step, for example, but any non-linear term will generate scales outside the initial range of the filter at scale ℓ. At this stage, we are not sure whether it is a potential drawback or an actual advantage of our method (smaller scales build more efficiently, and in a natural way). In practice, however, we checked that the power generated at a scale ℓ did not overlap too much on neighbouring scales.
at scale ℓ may acquire power at other scales from its approximate filtered evolution Equation (28). This may happen through convergence and divergence of trajectories in the ballistic step, for example, but any non-linear term will generate scales outside the initial range of the filter at scale ℓ. At this stage, we are not sure whether it is a potential drawback or an actual advantage of our method (smaller scales build more efficiently, and in a natural way). In practice, however, we checked that the power generated at a scale ℓ did not overlap too much on neighbouring scales.
5.7 Extending the scope of our method
We look back here on the scope of our method. The generic form of the evolution Equation (13) allows already for quite a few situations which were not dealt with before with generative methods. We chose this form because it behaves well under filtering and because it readily expresses advection and deformation, which clearly are useful concepts in fluid mechanics. This also allows us to easily link to previous works which had separately focused on either one of these two terms. However, it may not be the most general form which is amenable to our hierarchical filtering. To start with, we could accept various components of W to be advected individually with different speeds (as in the Elsasser formulation of incompressible MHD where Z+ is advected by Z− and conversely) as long as these speeds remain linear in the state vector W. There may also exist more general forms which survive filtering and the conservative form is certainly one which should attract our attention.
In addition, if we now stick to our generic form (13), it is also not always easy to transform common partial differential equations towards it. For instance in the simple case of incompressible HD, we could not find a way to write down the velocity evolution equation (Navier–Stokes) in this form (there might be one that we could not see, or there might be a way to still apply the rest of the formalism to it, we simply have not found it yet).
Finally, even in cases where we could not strictly fit an evolution equation to our framework, as in the case of compressible isothermal MHD, it may be that hiding isolated problematic terms into our stochastic reshuffling may not be too detrimental to the accuracy of our method.
6 Summary and prospects
We investigated a set of several simple ideas applied to a large class of partial differential equations: hierarchical smoothing and first order evolution from random intermediate initial conditions during a scale- and space-dependent coherence time. With this procedure, we efficiently generated fields with realistic statistical properties compared to the results of the full time integration, at least in the simplest case of 2D incompressible HD.
Previous generative methods applied to 3D HD or MHD have focused either on advection (Rosales & Meneveau 2006; Subedi et al. 2014; Lübke et al. 2024) or on deformation (Chevillard et al. 2011; Durrive et al. 2020, 2022). The present approach retains every physical term in the equations, including diffusion, and provides a general framework suitable to a large class of partial differential equations. In the 2D incompressible HD case, for the evolution of divorticity, we show that it is critical to include both advection and deformation at the same time: this brings hope that, when applied to 3D HD or MHD, our method may significantly outperform the existing techniques.
Classical statistical indicators remain relatively well reproduced by our approximations during a significant fraction of the turnover time (about one third). A few coherent structures such as vorticity clumps with spiralling arms are also reproduced, with the proper winding sense of rotation according to the vorticity sign. However, more stringent probes of the texture such as scattering statistics are not fooled and show a discrepancy between simulations and syntheses. Yet a limited amount of bootstrap is able to bridge that gap; higher order integration schemes are likely to yield syntheses of much better quality at a smaller computational cost than bootstrap.
With the advent of deep learning, very efficient generative methods that rely on deep learning architectures have emerged, such as diffusion models (see Genuist et al. 2024, and references therein). However, these techniques suffer from two significant shortcomings: the generative procedure is often difficult to apprehend and it usually needs a training set of considerable volume, which in this context means that a lot of fully fledged numerical simulations have to be run prior to training the generative model. Our method, on the contrary, is directly fed with the physics contained in the partial differential equations and provides generated fields at the cost of a handful of simulation steps. Incidentally, our method could potentially be used to build large approximate training sets instead of resorting to actual simulations, or to complement a smaller set of accurate simulations with a large number of MuScaTS generated snapshots. Other generative methods, such as maximum entropy models conditioned by scattering transform statistics, are also being developed (Bruna & Mallat 2019; Zhang & Mallat 2021; Cheng et al. 2024) that require a very small training set (only a handful of simulations and sometimes even a single snapshot). However, these methods generate a significant extra numerical cost and offer less control of the distance to the physical solutions compared to the method we propose.
The original purpose of the synthesis methods as set up by Rosales & Meneveau (2006) was to reduce the time spent by simulations in the initial transient phase from arbitrary initial conditions towards fully developed turbulence. Incidentally, this reduces the carbon footprint of such simulations. Of course, the present model can still be used for the same aim. Here, we propose a range of other future applications. The low generating cost could be used with Monte Carlo Markov chain techniques to adjust a synthetic field to some observational constraints. For example, one could imagine generating 3D synthetic fields with prescribed projections; it would be interesting to consider the extent to which we can recover the underlying 3D structure behind plane-of-sky astrophysical images using this method. Similar methods may be used to estimate a turbulent field outside regions where it is measured, which could be useful in weather forecasting applications where reliable measurements are sometimes sparsely located. Finally, we hope our simplified models can be used as a theoretical basis to understand existing or predict new statistical laws of turbulent flows.
Acknowledgements
The authors express gratitude to the referee for having read the paper so carefully and for the constructive comments. They also acknowledge Interstellar Institute’s programmes “With Two Eyes” and “II6” and the Paris-Saclay University’s Institut Pascal for hosting discussions that nourished the development of the ideas behind this work. PL acknowledges enlightening discussions with Marie Farge who accepted to read through an early version of the paper. PL acknowledges support from the European Research Council, under the European Community’s Seventh framework Programme, through the Advanced Grant MIST (FP7/2017-2022, No. 742719). Computations were carried out on the totoro machine financed by the same ERC grant and hosted at the meso-center mesoPSL.
References
- Allys, E., Levrier, F., Zhang, S., et al. 2019, A&A, 629, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Allys, E., Marchand, T., Cardoso, J. F., et al. 2020, Phys. Rev. D, 102, 103506 [Google Scholar]
- Banerjee, S., & Galtier, S. 2013, Phys. Rev. E, 87, 013019 [NASA ADS] [CrossRef] [Google Scholar]
- Banerjee, S., & Galtier, S. 2014, J. Fluid Mech., 742, 230 [Google Scholar]
- Banerjee, S., & Galtier, S. 2016, Phys. Rev. E, 93, 033120 [NASA ADS] [CrossRef] [Google Scholar]
- Bernard, D. 1999, Phys. Rev. E, 60, 6184 [Google Scholar]
- Bernardeau, F., Colombi, S., Gaztañaga, E., & Scoccimarro, R. 2002, Phys. Rep., 367, 1 [Google Scholar]
- Boffetta, G. 2007, J. Fluid Mech., 589, 253 [Google Scholar]
- Boffetta, G., Celani, A., & Vergassola, M. 2000, Phys. Rev. E, 61, R29 [Google Scholar]
- Bond, J. R., & Myers, S. T. 1996, ApJS, 103, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Brandenburg, A., Rädler, K. H., & Schrinner, M. 2008, A&A, 482, 739 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bruna, J., & Mallat, S. 2019, Math. Statist. Learn., 1, 257 [CrossRef] [Google Scholar]
- Bruna, J., Mallat, S., Bacry, E., & Muzy, J.-F. 2015, Ann. Statist., 43, 323 [Google Scholar]
- Bruneau, C. H., & Kellay, H. 2005, Phys. Rev. E, 71, 046305 [NASA ADS] [CrossRef] [Google Scholar]
- Cheng, S., Morel, R., Allys, E., Ménard, B., & Mallat, S. 2024, PNAS Nexus, 3, pgae103 [Google Scholar]
- Chevillard, L. 2015, Accreditation to Supervise Research (ENS Lyon) [Google Scholar]
- Chevillard, L., & Meneveau, C. 2006, Phys. Rev. Lett., 97, 174501 [Google Scholar]
- Chevillard, L., Robert, R., & Vargas, V. 2011, in Journal of Physics Conference Series, 318, Journal of Physics Conference Series, 042002 [Google Scholar]
- Coles, P., Melott, A. L., & Shandarin, S. F. 1993, MNRAS, 260, 765 [NASA ADS] [Google Scholar]
- de Karman, T., & Howarth, L. 1938, Proc. Roy. Soc. Lond. Ser. A, 164, 192 [Google Scholar]
- Durrive, J.-B., Lesaffre, P., & Ferrière, K. 2020, MNRAS, 496, 3015 [Google Scholar]
- Durrive, J.-B., Changmai, M., Keppens, R., et al. 2022, Phys. Rev. E, 106, 025307 [Google Scholar]
- Eyink, G. L. 1996, Physica D Nonlinear Phenomena, 91, 97 [Google Scholar]
- Falkovich, G., & Lebedev, V. 2011, Phys. Rev. E, 83, 045301 [Google Scholar]
- Frisch, U. 1996, Turbulence (Cambridge University Press), 310 [Google Scholar]
- Galtier, S., & Banerjee, S. 2011, Phys. Rev. Lett., 107, 134501 [NASA ADS] [CrossRef] [Google Scholar]
- Genuist, W., Savin, É., Gatti, F., & Clouteau, D. 2024, Working paper or preprint [Google Scholar]
- Goldreich, P., & Sridhar, S. 1995, ApJ, 438, 763 [Google Scholar]
- Grauer, R., Krug, J., & Marliani, C. 1994, Phys. Lett. A, 195, 335 [NASA ADS] [CrossRef] [Google Scholar]
- Gurbatov, S. N., Saichev, A. I., & Shandarin, S. F. 1989, MNRAS, 236, 385 [Google Scholar]
- Haller, G. 2021, J. Fluid Mech., 908, A25 [Google Scholar]
- Iroshnikov, P. S. 1963, AZh, 40, 742 [NASA ADS] [Google Scholar]
- Jermyn, A. S., Lesaffre, P., Tout, C. A., & Chitre, S. M. 2018, MNRAS, 476, 646 [Google Scholar]
- Kida, S. 1985, J. Phys. Soc. Jpn., 54, 2840 [Google Scholar]
- Kolmogorov, A. N. 1941, Akad. Nauk SSSR Dokl., 32, 16 [Google Scholar]
- Kolmogorov, A. N. 1962, J. Fluid Mech., 13, 82 [Google Scholar]
- Kraichnan, R. H. 1965, Phys. Fluids, 8, 1385 [Google Scholar]
- Kraichnan, R. H. 1967, Phys. Fluids, 10, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Krause, F., & Raedler, K. H. 1980, Mean-field Magnetohydrodynamics and Dynamo Theory (Oxford: Pergamon Press) [Google Scholar]
- Käpylä, P. J., Rheinhardt, M., Brandenburg, A., & Käpylä, M. J. 2020, A&A, 636, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lesaffre, P., Chitre, S. M., Potter, A. T., & Tout, C. A. 2013, MNRAS, 431, 2200 [Google Scholar]
- Lewalle, J. 2010, Physica D Nonlinear Phenomena, 239, 1232 [Google Scholar]
- Lübke, J., Effenberger, F., Wilbert, M., Fichtner, H., & Grauer, R. 2024, Europhys. Lett., 146, 43001 [CrossRef] [Google Scholar]
- Majda, A. J., & Bertozzi, A. L. 2001, Vorticity and Incompressible Flow, Cambridge Texts in Applied Mathematics (Cambridge University Press) [Google Scholar]
- Malara, F., Di Mare, F., Nigro, G., & Sorriso-Valvo, L. 2016, Phys. Rev. E, 94, 053109 [Google Scholar]
- Mallat, S., 2012, Communications on Pure and Applied Mathematics, 65, 1331 [Google Scholar]
- Mandelbrot, B. B., & van Ness, J. W. 1968, SIAM Rev., 10, 422 [CrossRef] [MathSciNet] [Google Scholar]
- Momferratos, G., Lesaffre, P., Falgarone, E., & Pineau des Forêts, G. 2014, MNRAS, 443, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Monaco, P., Theuns, T., Taffoni, G., et al. 2002, ApJ, 564, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Monin, A. S. 1959, Sov. Phys. Dokl., 4, 271 [Google Scholar]
- Okubo, A. 1970, Deep Sea Res. A, 17, 445 [Google Scholar]
- Paret, J., & Tabeling, P. 1998, Phys. Fluids, 10, 3126 [Google Scholar]
- Pasquero, C., & Falkovich, G. 2002, Phys. Rev. E, 65, 056305 [Google Scholar]
- Pereira, R. M., Moriconi, L., & Chevillard, L. 2018, J. Fluid Mech., 839, 430 [Google Scholar]
- Politano, H., & Pouquet, A. 1995, Phys. Rev. E, 52, 636 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [Google Scholar]
- Richard, T., Lesaffre, P., Falgarone, E., & Lehmann, A. 2022, A&A, 664, A193 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rosales, C., & Meneveau, C. 2006, Phys. Fluids, 18, 075104 [Google Scholar]
- Rosales, C., & Meneveau, C. 2008, Phys. Rev. E, 78, 016313 [Google Scholar]
- Rutgers, M. A. 1998, Phys. Rev. Lett., 81, 2244 [Google Scholar]
- Schekochihin, A. A. 2022, J. Plasma Phys., 88, 155880501 [NASA ADS] [CrossRef] [Google Scholar]
- She, Z.-S., & Leveque, E. 1994, Phys. Rev. Lett., 72, 336 [Google Scholar]
- Shivamoggi, B. K., van Heijst, G. J. F., & Kamp, L. P. J. 2024, J. Plasma Phys., 90, 905900214 [Google Scholar]
- Sidje, R. B. 1998, ACM Trans. Math. Softw., 24, 130 [CrossRef] [Google Scholar]
- Starck, J.-L., & Murtagh, F. 2002, Astronomical Image and Data Analysis (Springer) [Google Scholar]
- Stein, G., Alvarez, M. A., & Bond, J. R. 2019, MNRAS, 483, 2236 [NASA ADS] [CrossRef] [Google Scholar]
- Subedi, P., Chhiber, R., Tessein, J. A., Wan, M., & Matthaeus, W. H. 2014, ApJ, 796, 97 [Google Scholar]
- Tan, H. S., Huang, Y. X., & Meng, J. 2014, Phys. Fluids, 26, 015106 [Google Scholar]
- Weiss, J. 1991, Physica D Nonlinear Phenomena, 48, 273 [Google Scholar]
- Zhang, S., & Mallat, S. 2021, Appl. Computat. Harmonic Anal., 53, 199 [CrossRef] [Google Scholar]
For affine functions, the affine constant becomes filtered, so the notations have to be slightly amended, but the derivation is the same.
The focus in this section is on the scale dependency of parameters (power-law variation in ℓ) so throughout this section we omit numerical factors, as in (49), but it is worth mentioning that strictly speaking, τCRV does not have the dimension of a time. It is a parameter controlling the intermittency (non-Gaussianity) of the resulting velocity field which appears in CRV’s construction from an equation governing the dynamics of stretching, so we choose this τ notation to help the reader get some intuition, notably since the longer stretching occurs, the larger this parameter is. For more details see CRV’s work (Chevillard et al. 2011; Chevillard 2015).
For simplicity and since we focus on the inertial range in this discussion, we omitted the numerical prefactor, the regularisation and the principal value present in CRV.
In follow-ups of their CRV work, such as Chevillard (2015) and Pereira et al. (2018), they do support this with very rigorous but rather lengthy derivations, and we here stick to their simple reasoning that yields the correct result.
The sparsity of a signal refers to its property to have a large fraction of its values being close to 0. It can be measured by comparing its L1 and L2 norms. Such a measure can be used to characterize the intermittent nature of turbulent flows (Bruna et al. 2015).
Appendix A Reconstruction formula
In this appendix, we justify the reconstruction formula (9).
Let us take the Fourier transform of the right hand side of (9), considering it at a fixed given non zero k. By linearity of the Fourier transform (interchanging the integral of the Fourier definition with the integral over scales ℓ),
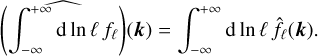 (A.1)
(A.1)
Moreover, by the convolution theorem (the Fourier transform of the convolution of two functions is the product of their Fourier transforms) relation (1) in Fourier space, combined with (3) and (4), lets us rewrite the integrand on the right hand side of (A.1) as
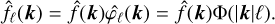 (A.2)
(A.2)
Then, as 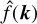 is independent of ℓ it can be pulled out of the integral, and using the change of variable s = |k|ℓ (possible since k is fixed and assumed to be non zero), we get that
is independent of ℓ it can be pulled out of the integral, and using the change of variable s = |k|ℓ (possible since k is fixed and assumed to be non zero), we get that
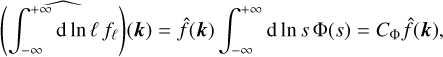 (A.3)
(A.3)
where definition (6) has been used in the last step. Given our normalisation (7), relation (A.3) demonstrates that both sides of (9) have the same Fourier transform for all non zero k. For the special k = 0 case, this statement remains true provided 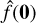 (i.e. ƒ has a zero mean) because all filters have zero means. Finally, by inverse Fourier transform, we obtain the reconstruction formula (9).
(i.e. ƒ has a zero mean) because all filters have zero means. Finally, by inverse Fourier transform, we obtain the reconstruction formula (9).
Appendix B Two example filters
In the present application, we tested two sets of filters. The first one is based on a cosine window in the logarithm of the scale. We first define the bump-like function
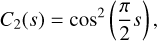 (B.1)
(B.1)
for s in [−1, 1], and zero elsewhere. We then define our list of filters as
![Mathematical equation: $\hat \varphi _j^C\left( k \right) = {C_2}\left( {\ln \left[ {\left| k \right|{k_j}} \right]/\,\ln \left[ \lambda \right]} \right),$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq130.png) (B.2)
(B.2)
where λ is the scale ratio between two adjacent scales. Our normalisation condition requires J = JC = ⌊ln(N/2)/ In λ⌋ (where ⌊…⌋ denotes the integral part or floor function) in order to have 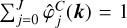 for all wavenumbers in the computational domain. Note that the maximum wave-number represented in our Fourier space is
for all wavenumbers in the computational domain. Note that the maximum wave-number represented in our Fourier space is 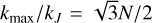 for a 3D grid, or
for a 3D grid, or 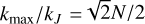 for a 2D grid, and since the non-linearities in our method are quadratic, we use the two-third truncation rule in Fourier.
for a 2D grid, and since the non-linearities in our method are quadratic, we use the two-third truncation rule in Fourier.
Our second set of filters is based on the box spline of 3rd order (often used in astrophysical applications due to its implementation efficiency, see appendix A of Starck & Murtagh 2002, for example). Consider the B3-spline cubic function (a box convolved three times with itself)
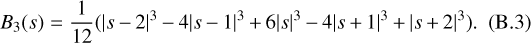 (B.3)
(B.3)
 |
Fig. B.1 Series of cosine (left) and box spline (right) filters for a cubic periodic domain of size N = 512 pixels. Their total sum is indicated as well as the wavenumber boundaries for a 3D domain (kmin = 1, |
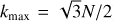
B3(s) is non zero only within the interval [−2, 2]. It makes a smooth transition between 2/3 at s = 0 and 0 at s = 2. We can use this smooth step property to build a smooth logarithmic window:
![Mathematical equation: $\hat \varphi _j^S\left( k \right) = {3 \over 2}\left[ {{B_3}\left( {\left| k \right|/{k_{j + 1}}} \right) - {B_3}\left( {\left| k \right|/{k_j}} \right)} \right],$](/articles/aa/full_html/2025/11/aa53264-24/aa53264-24-eq136.png) (B.4)
(B.4)
where the 3/2 coefficient is chosen to comply with our normalisation condition. The sum 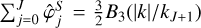 has limit 1 when |k|/kJ+1 goes to inifinity, i.e. when J is large enough for kJ+1 to be well above the maximum effective k reached by the wavenumbers (
has limit 1 when |k|/kJ+1 goes to inifinity, i.e. when J is large enough for kJ+1 to be well above the maximum effective k reached by the wavenumbers (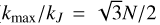 for a 3D grid, or
for a 3D grid, or 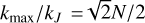 for a 2D grid). The normalisation condition is hence only approximately realised in this case.
for a 2D grid). The normalisation condition is hence only approximately realised in this case.
Figure B.1 displays series of filters for these two choices of mother filter, along with the normalisation condition. The cosine filters are slightly narrower in scales compared to the splines. The spline filters do not match the condition exactly but only to the limit where we take a large number of filters. However, in practice, only the small scales will suffer from lack of power, which is in line with diffusion processes anyway, so it turns out that the use of JS = JC + 1 = ⌊ln(N/2)/ In λ⌋ + 1 for the spline filters appears quite well converged, with only about 14% of the total power missing compared to the limiting case (estimated from using J = JC + 10), and only 1% missing at J = JC + 2, which we adopted in the present work.
All Figures
|
Fig. 1 Example of the performance of our method. Panel a shows the common initial (Gaussian) vorticity field used in the two other panels, namely a standard 2D incompressible hydrodynamics simulation (panel b) and one of our synthesis (panel c). Panel b shows the vorticity field after the field has been evolved for about one third of a turnover time, using more than 300 standard simulation steps. Panel c shows the resulting synthesis after only four MuScaTS steps for a total computer processing unit (CPU) cost 17 times smaller. |
| In the text | |
|
Fig. 2 CPU cost scaling estimates for 2D (light colours) and 3D (dark colours) hydrodynamics simulations (solid, blue) and MuScaTS syntheses (dashed, red). The scalings are computed according to text and calibrated on a 2D simulation (pseudo-spectral code implemented in Fortran) at N = 1024 for one turnover time (rightmost blue circle). The total CPU cost for simulations at N = 256 and N = 512 (the other two blue circles) is also indicated. Red squares stand for the CPU cost of a few 2D MuScaTS syntheses. |
| In the text | |
|
Fig. 3 Vorticity maps for various cases (see text), all based on the same original Gaussian field (displayed in panel a). The panels show the following: (a) initial conditions; (b–d) divorticity syntheses with (b) first order deformation, (c) advection then deformation, and (d) deformation only; (e) reference simulation at t = 2 (about 1/3rd turnover timescale); (f) basic synthesis for vorticity; (g, h) divorticity syntheses with (g) deformation then advection and (h) advection only. All syntheses are shown at the same time, t, as for the simulation and a coherence time based on the local strain time (See Section 2.4.2). |
| In the text | |
 |
Fig. 4 Same as Figure 3, but at time t = 6, i.e. at about one turnover timescale. |
| In the text | |
|
Fig. 5 Classical statistics averaged over 30 realisations for (a) power spectrum, (b) vorticity increments (for lags of 1, 4, and 32 pixels), (c) the energy transfer function, ℱu, and (d) the enstrophy transfer function, ℱw. Green is for the initial conditions (of the syntheses), red for the MuScaTS syntheses (basic run), and blue for the simulations at time t = 2. Shaded areas give the one-sigma error around the mean over the 30 independent realisations (i.e. mean plus or minus standard deviation divided by |
| In the text | |
 |
Fig. 6 Same as Figure 5 but at time t = 6, i.e. at about one turnover timescale. |
| In the text | |
|
Fig. 7 Mean over 30 realisations of layer 2 WST coefficients S2(j1, j2, ∆θ) (see text) for initial conditions (green), the reference simulation (blue) at about a third of a turnover time (t = 2), and MuScaTS basic syntheses over a time t = 2 (red). The main length scale runs from its index j1 = 0 (smallest) to j1 = J − 3 = 7. The secondary scale j2 is labelled by ∆j = j2 − j1. The relative angle ∆θ runs from 0 to π from left to right in each broken line of fixed j1 and ∆ j. The width of the lines indicates the standard deviation of this mean over our 30 realisations, the computational domain, and the absolute angle θ1. |
| In the text | |
|
Fig. 8 Same as Figure 7 but with a four-step bootstrap (see text of Section 5.4 and see also Figure 9). |
| In the text | |
|
Fig. 9 Vorticity maps for one realisation of our basic case at t = 2. The four panels, labeled from (a) to (d), show respectively: (a) the simulation, (b) the same as panel d of Figure 3, (c) a two-steps bootstrap (∆t = 1) and (d) a four steps bootstrap (∆t = 0.5). See text for more details. |
| In the text | |
|
Fig. B.1 Series of cosine (left) and box spline (right) filters for a cubic periodic domain of size N = 512 pixels. Their total sum is indicated as well as the wavenumber boundaries for a 3D domain (kmin = 1, |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.