| Issue |
A&A
Volume 706, February 2026
|
|
|---|---|---|
| Article Number | A323 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202556609 | |
| Published online | 24 February 2026 | |
Closing the evidence gap: reddemcee, a fast adaptive parallel tempering sampler
Next-generation ladder adaptation and evidence estimators for parallel tempering
1
Instituto de Estudios Astrofísicos, Facultad de Ingeniería y Ciencias, Universidad Diego Portales,
Av. Ejército 441,
Santiago,
Chile
2
Centro de Astrofísica y Tecnologías Afines (CATA),
Casilla 36-D,
Santiago,
Chile
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
July
2025
Accepted:
17
December
2025
Abstract
Context. Markov chain Monte Carlo (MCMC) excels at sampling complex posteriors, but traditionally lags behind nested sampling in accurate evidence estimation, which is crucial for model comparison in astrophysical problems.
Aims. We introduce reddemcee, an adaptive parallel tempering ensemble sampler, aiming to close this gap by simultaneously presenting next-generation automated temperature-ladder adaptation techniques and robust, low-bias evidence estimators.
Methods. reddemcee couples an affine-invariant stretch move with five interchangeable ladder-adaptation objectives – a uniform swap-acceptance rate, swap mean distance, Gaussian area overlap, a small Gaussian gap, and equalised thermodynamic length – implemented through a common differential update rule. Three evidence estimators are provided: curvature-aware thermodynamic integration (TI+), geometric-bridge stepping stones (SS+), and a novel hybrid algorithm that blends both approaches (H+). The performance and accuracy of the sampler are benchmarked on n-dimensional Gaussian shells, Gaussian egg-box, Rosenbrock functions, and the real exoplanet radial-velocity time-series dataset of HD 20794.
Results. Across shells up to 15 dimensions, reddemcee achieves roughly 7 times the effective sampling speed of the best dynamic nested sampling configuration. The TI+, SS+, and H+ estimators recover estimates to within |∆ ln 𝒵|≲3% and supply realistic error bars with as few as six temperatures. In the HD 20794 case study, reddemcee reproduces literature model rankings and yields tighter yet consistent planetary parameters compared with dynesty, with evidence errors that track run-to-run dispersion.
Conclusions. By unifying fast ladder adaptation with reliable evidence estimators, reddemcee delivers strong throughput and accurate evidence estimates, often matching, and occasionally surpassing, dynamic nested sampling, while preserving the rich posterior information that makes MCMC indispensable for modern Bayesian inference.
Key words: methods: numerical / methods: statistical / planets and satellites: individual: HD 20794
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
In scientific research, any measured data needs to be tested against a suitable hypothesis. As such, robust statistical techniques are indispensable for parameter estimation and model comparison. Science frequently faces the challenge of characterising probability distributions arising from complex, high-dimensional models ridden with nuisance parameters, uncertainties, and degeneracies. Markov chain Monte Carlo (MCMC) methods are widely recognised as a vital tool in many areas of science. They enable researchers to characterise parameter uncertainties precisely and compare models rigorously. Research areas that rely on precise inference, such as phylogenetics (Rannala & Yang 1996; Drummond et al. 2002), physio-chemistry (Hansmann 1997; Sugita & Okamoto 1999), gravitational waves (van der Sluys et al. 2008; Veitch et al. 2015), and exoplanet discovery (Jenkins et al. 2020; Vines et al. 2023), benefit from the flexibility of MCMC techniques to explore difficult posterior landscapes.
Early exoplanet radial-velocity (RV) detections were often confirmed by identifying significant peaks in periodograms – in which false-alarm probabilities were calculated to establish the significance of a planetary candidate – and performing nonlinear least-squares fitting for Keplerian orbits. Such was the case for 51 Pegasi b (Mayor & Queloz 1995) – the first exoplanet around a Sun-like star – and for the many Jovian planets that quickly followed this discovery (Gonzalez 1997; Marcy & Butler 2000).
However, as RV data grew and multi-planet systems became common, more sophisticated statistical tools were needed to extract the more difficult exoplanet signals, which could be subtle, degenerate, and embedded in considerable noise. This led to the introduction of MCMC methods (Ford et al. 2005), revolutionising exoplanet RV fitting with robust estimation of orbital parameters with realistic uncertainties, even for nonlinear parameters (such as eccentricity and longitude of periastron). Far from perfect, MCMC still has its caveats. Poorly tuned chains could wander slowly or get trapped in local maxima.
To thoroughly explore multi-modal parameter spaces (common in multi-planet systems, for example), Gregory (2005) pioneered the use of the parallel tempering (PT) MCMC method (Swendsen & Wang 1986; Earl & Deem 2005) in relation to RV-signal detection and characterisation. This approach runs several chains in parallel to sample different powers (a temperature ladder) of the posterior distribution, each tempered to a different level. Hotter chains traverse the parameter space with more freedom, while colder chains sample the fine details. Inter-chain communication allows the sampler to explore distant high-probability nodes with ease. Furthermore, PT enables the algorithm to estimate the marginalised posterior (or evidence), a crucial quantity for model comparison. Gregory (2005) shows that this method is capable of efficiently exploring all regions of the phase space, lessening the burden of multi-modality. However, this early implementation was not capable of estimating the evidence reliably without a huge performance loss.
The affine-invariant ensemble samplers (Goodman & Weare 2010) also found their way into the exoplanet domain (Hou et al. 2012a). This MCMC variant, instead of a single chain, utilises an ensemble of ‘walkers’, drawing multiple samples per step, making the sampler insensitive to parameter covariances, and thus providing an enormous computational performance boost.
As an extra Keplerian in one’s model can always fit noise, efforts turned to providing an accurate model comparison framework, leading to the usage of nested sampling (NS) algorithms (Skilling 2004) to calculate the Bayesian evidence for competing models (with differing number of planets or noise models), allowing one to select the most likely model (Feroz & Hobson 2008; Feroz et al. 2011). Building on NS, dynamic NS (DNS, Higson et al. 2019; Speagle 2020) introduces an adaptive allocation of ‘sampling effort’ to higher-probability areas of the phase space, further increasing the efficiency of reaching the target evidence precision, finding use in RV fitting (Diamond-Lowe et al. 2020).
MCMC excels in parameter posterior estimation, yielding reliable uncertainties, even for complex or correlated parameters. However, while evidence estimation is certainly possible under this algorithm, it is as a by-product of the posterior exploration. Therefore, increasing the accuracy of the evidence estimation does not necessarily translate into increased posterior accuracy, while carrying a substantial computational burden. On the other hand, NS is primarily designed for efficient evidence estimation by systematically shrinking the likelihood volume. As a by-product, it provides posterior samples, which can be used to model the parameter posteriors. Consequently, this method inherently does not provide as many samples from the parameter distribution as a well-tuned MCMC, conveying less precise parameter estimates.
This work presents reddemcee1, an adaptive PT MCMC Python algorithm for any scientific-sampling-related endeavour that handles complex, high-dimensional, multi-modal posteriors, with several competing models. Leveraging five different automated tuning strategies for the temperature ladder – two classic ones, uniform swap acceptance, and posterior area overlap; and three new implementations based on average energy differences, the system’s specific heat, and the swap mean distance (SMD) – while providing original adaptations for evidence estimation, such as the stepping stones algorithm (SS, Xie et al. 2011) with a per-stone geometric-bridge, thermodynamic integration (TI, Gelman & Meng 1998) enhanced by curvature-aware interpolation, and a novel hybrid approach.
2 Bayesian framework
A full description of Bayesian inference and MCMC methods is beyond the scope of this manuscript, and we therefore refer the reader to Gelman et al. (2004). Nonetheless, a summary of essential concepts is provided.
Bayesian inference generally consists of depicting the posterior probability distribution over the parameters θ ∈ Θ of the hypothesise model, M, depicting some known measured data, D:
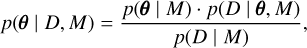 (1)
where p(θ | M) corresponds to the prior distribution, p(D | θ, M) to the likelihood function, and p(D | M) to the marginalised likelihood, frequently denoted as the Bayesian evidence, 𝒵, or simply ‘evidence’ (as it is in this manuscript). Throughout this work, proper priors are assumed (∫Θ p(θ | M) = 1), so the evidence is well defined and finite.
(1)
where p(θ | M) corresponds to the prior distribution, p(D | θ, M) to the likelihood function, and p(D | M) to the marginalised likelihood, frequently denoted as the Bayesian evidence, 𝒵, or simply ‘evidence’ (as it is in this manuscript). Throughout this work, proper priors are assumed (∫Θ p(θ | M) = 1), so the evidence is well defined and finite.
The evidence quantifies the overall support for model M and is crucial for Bayesian model comparison. However, the evidence integral generally has no closed-form solution and must be estimated numerically (Oaks et al. 2018). The MCMC methods, while excelling at drawing samples from the posterior, do not directly provide 𝒵.
Within MCMC methods, several evidence-estimation techniques have been developed (Maturana-Russel et al. 2019). For PT MCMC, two common approaches are TI (Gelman & Meng 1998) and stepping stones (Xie et al. 2011). How PT works and how TI and SS leverage the tempered ensemble to estimate the evidence are briefly outlined below.
2.1 Parallel tempering MCMC
Parallel tempering MCMC runs an ensemble of B parallel chains, each sampling a different power of the posterior distribution (at a different temperature, Ti; Swendsen & Wang 1986; Earl & Deem 2005; Miasojedow et al. 2013). The inverse of the temperature is 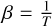 , with 1 = β1 > β2 > … > βB−1 > βB ≥ 0, and the full chain
, with 1 = β1 > β2 > … > βB−1 > βB ≥ 0, and the full chain 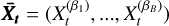 . By convention, β1 = 1 for the cold chain (sampling the original posterior) and βB ≈ 0 for the hottest chain (sampling a highly flattened landscape, approaching the prior as βB → 0). Each chain,
. By convention, β1 = 1 for the cold chain (sampling the original posterior) and βB ≈ 0 for the hottest chain (sampling a highly flattened landscape, approaching the prior as βB → 0). Each chain, 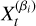 , samples a tempered posterior where the likelihood has been raised to the power βi,
, samples a tempered posterior where the likelihood has been raised to the power βi,
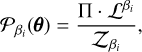 (2)
where
(2)
where 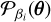 is the posterior distribution , Π the prior,
is the posterior distribution , Π the prior, 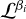 the tempered likelihood, and
the tempered likelihood, and 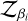 the evidence.
the evidence.
In 𝒫β(θ), hotter temperatures flatten and broaden peaks, reducing the risk of getting trapped in local maxima, and effectively making the posterior easier to sample. As such, hot chains are able to rapidly sample a large portion of the parameter space, whilst cold chains provide precise local sampling. By allowing chains at different temperatures to swap states, PT achieves a fast, thorough sampling of the posterior. Swaps in PT are implemented with a Metropolis-like acceptance rule. The pairwise swap (Goggans & Chi 2004), which is when two adjacent chains 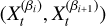 propose to switch states, is accepted with probability
propose to switch states, is accepted with probability
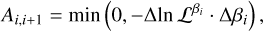 (3)
where ∆ln
(3)
where ∆ln 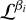 is the log-likelihood difference between the two chain states. This criterion (derived by simplifying the detailed balance condition for swapping two Boltzmann-distributed ensembles) shows that swaps are more probable when a high-likelihood state from a hotter chain is proposed for a colder chain. Without adjacent posteriors overlapping enough to allow regular swaps, efficiency plummets. By tuning the temperature ladder (the set of βi values), PT aims to maintain a reasonably high swap-acceptance rate (SAR) across all adjacent pairs, ensuring a thorough exploration of the posterior landscape and providing a natural framework for estimating the evidence, 𝒵, via the ladder of tempered distributions.
is the log-likelihood difference between the two chain states. This criterion (derived by simplifying the detailed balance condition for swapping two Boltzmann-distributed ensembles) shows that swaps are more probable when a high-likelihood state from a hotter chain is proposed for a colder chain. Without adjacent posteriors overlapping enough to allow regular swaps, efficiency plummets. By tuning the temperature ladder (the set of βi values), PT aims to maintain a reasonably high swap-acceptance rate (SAR) across all adjacent pairs, ensuring a thorough exploration of the posterior landscape and providing a natural framework for estimating the evidence, 𝒵, via the ladder of tempered distributions.
Although our APT implementation does not provide independent draws, we next set up the classic methods for evidence estimation (which assume IID-based errors). In .4Sect. 3.3, we address how to handle this problem.
2.2 Thermodynamic integration
Thermodynamic integration is an indirect method of computing the evidence, 𝒵, by leveraging the continuous sequence of intermediate posteriors between prior and posterior (Gelman & Meng 1998; Goggans & Chi 2004; Lartillot & Philippe 2006). The basic formula arises from the identity (in statistical mechanics) that relates the derivative of the log-partition function to the average energy. In Bayesian terms:
![Mathematical equation: $\ln {\cal Z} = \ln {{\cal Z}_1} - \ln {{\cal Z}_0} = \mathop \smallint \limits_0^1 {_\beta }[\ln {\cal L}]d\beta $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq12.png) (4)
where 𝔼β […] is the expectation with respect to 𝒫β(θ), the tempered posterior at inverse temperature β. Since 𝒵0 = 1 for proper priors (so ln 𝒵0 = 0), the integral directly yields ln 𝒵. With B the number of temperatures, the integral is calculated via the trapezoidal rule:
(4)
where 𝔼β […] is the expectation with respect to 𝒫β(θ), the tempered posterior at inverse temperature β. Since 𝒵0 = 1 for proper priors (so ln 𝒵0 = 0), the integral directly yields ln 𝒵. With B the number of temperatures, the integral is calculated via the trapezoidal rule:
![Mathematical equation: $\ln {\hat {\cal Z}_{TI}} \approx \mathop \sum \limits_{i = 1}^{B - 1} {{{_{{\beta _{i + 1}}}}[\ln {\cal L}] + {_{{\beta _i}}}[\ln {\cal L}]} \over 2} \cdot {\rm{\Delta }}{\beta _i}.$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq13.png) (5)
(5)
2.3 Stepping stones
The stepping-stones algorithm (Xie et al. 2011) expresses the evidence ratio 𝒵=𝒵1/𝒵0 as a telescopic product across the temperature ladder:
![Mathematical equation: $\matrix{ {{{\hat Z}_{SS}} = \mathop \prod \limits_{i = 1}^{B - 1} {{{{\cal Z}_{{\beta _i}}}} \over {{{\cal Z}_{{\beta _{i + 1}}}}}} = \mathop \prod \limits_{i = 1}^{B - 1} {r_i},} & {{r_i} \equiv {{{{\cal Z}_{{\beta _i}}}} \over {{{\cal Z}_{{\beta _{i + 1}}}}}} = {_{{\beta _{i + 1}}}}\left[ {{{\cal L}^{{\beta _i} - {\beta _{i + 1}}}}} \right],} \cr } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq14.png) (6)
with ri the stepping-stones ratios and 𝔼β […] the expectation with respect to 𝒫β(θ). It is often convenient to work in log-space for numerical stability, yielding
(6)
with ri the stepping-stones ratios and 𝔼β […] the expectation with respect to 𝒫β(θ). It is often convenient to work in log-space for numerical stability, yielding
![Mathematical equation: $\ln {\hat {\cal Z}_{SS}} = \mathop \sum \limits_{i = 1}^{B - 1} \ln \left[ {{1 \over {{N_i}}}\mathop \sum \limits_{n = 1}^{{N_i}} {{\cal L}^{{\beta _i} - {\beta _{i + 1}}}}} \right],$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq15.png) (7)
where Ni is the number of posterior samples per chain used to approximate each expectation. SS has the advantage of typically delivering improved accuracy over TI when the number of temperatures is limited, since it more directly ‘bridges’ distributions to evaluate each incremental evidence ratio.
(7)
where Ni is the number of posterior samples per chain used to approximate each expectation. SS has the advantage of typically delivering improved accuracy over TI when the number of temperatures is limited, since it more directly ‘bridges’ distributions to evaluate each incremental evidence ratio.
2.4 Evidence error estimation
For TI, Lartillot & Philippe (2006) identified two sources of error: one from the sampling itself, 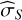 , calculated as the MC standard error affecting the log-likelihood averages, and another from the discretisation of the integral,
, calculated as the MC standard error affecting the log-likelihood averages, and another from the discretisation of the integral, 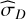 . This quantity can be estimated by considering the worst-case contribution of the trapezoidal rule (essentially misrepresenting the whole triangular part):
. This quantity can be estimated by considering the worst-case contribution of the trapezoidal rule (essentially misrepresenting the whole triangular part):
![Mathematical equation: ${{\hat \sigma }_D} \simeq {{\left| {{_{{\beta _i}}}[\ln {\cal L}] - {_{{\beta _{i + 1}}}}[\ln {\cal L}]} \right|} \over 2} \cdot {\rm{\Delta }}{\beta _i}.$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq18.png) (8)
(8)
For the SS method, the product of unbiased estimators, 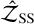 , is also unbiased; nevertheless, changing to log scale introduces a bias. Xie et al. (2011) estimated the error as
, is also unbiased; nevertheless, changing to log scale introduces a bias. Xie et al. (2011) estimated the error as
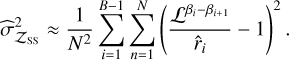 (9)
(9)
3 Temperature ladder
Extending the parallelisms with statistical thermodynamics, the specific heat, Cν, is defined with the energy U = − ln ℒ:
![Mathematical equation: ${C_v}(\beta ) = {{d{_\beta }[U]} \over {dT}} = {\beta ^2}\left( {{_\beta }\left[ {{U^2}} \right] - {_\beta }{{[U]}^2}} \right) = {\beta ^2}Va{r_\beta }[U].$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq21.png) (10)
(10)
This quantity governs the energy fluctuations at different temperatures, and is closely related to both the temperature ladder and the SAR. The mean SAR – derived from Eq. (3) – for a small temperature gap can be expressed as
![Mathematical equation: $\matrix{ {{{\bar A}_{i,i + 1}}} \hfill &; { = {_{{\beta _i},{\beta _i} + 1}}\left[ {\exp \left( { - {\rm{\Delta }}{U_i} \cdot {\rm{\Delta }}{\beta _i}} \right)} \right]} \hfill \cr {} \hfill & { \propto {_{{\beta _i}}}\left[ {{\rm{\Delta }}{U_i} \cdot {\rm{\Delta }}{\beta _i}} \right] = {{\sqrt {{C_v}\left( {{\beta _i}} \right)} } \over {{\beta _i}}}{\rm{\Delta }}{\beta _i}.} \hfill \cr } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq22.png) (11)
(11)
In the PT scheme, the temperature ladder must be chosen to maximise the efficiency of the cold chain. To ensure that this chain has good mixing, from the SAR (see Eq. (11)), it would suffice to minimise both ∆βi and ∆Ui for every single chain. This way, samples from the hot chain can easily traverse to the cold chain. As a secondary aim, the temperature ladder serves to estimate the evidence as well, so allocating the temperatures aimed at favouring either the TI or SS method also has its benefits. Achieving a uniform SAR across all chains is generally considered a good strategy for healthy mixing (Sugita & Okamoto 1999; Predescu et al. 2004; Kone & Kofke 2005; Roberts & Rosenthal 2007; Vousden et al. 2016).
3.1 Geometric spacing
Kofke (2002) and later Predescu et al. (2004), by analysing the constant specific heat scenario, concluded that adjacent temperatures geometrically spaced should approximate to a uniform SAR. With a constant ratio, 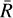 , each β would be defined by
, each β would be defined by
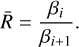 (12)
(12)
This is the starting point for ladder design, and it illustrates why adaptive methods are needed: geometric spacing assumes constant Cν, which does not hold true in complex posteriors.
3.2 Adaptive methods
Adaptive parallel tempering (APT) MCMC dynamically updates the temperature ladder during the run to improve mixing efficiency (Gilks et al. 1998; Roberts & Rosenthal 2007; Miasojedow et al. 2013; Vousden et al. 2016). Such an algorithm inherently fails to be ergodic and may not preserve the stationarity of the cold chain. In practice, reddemcee uses a decaying adaptive rate (see Eq. (14)), allowing the ladder to stabilise over time. Then, the adaptation can be discontinued, after which detailed balance is preserved and standard ergodicity theorems apply. This procedure was adopted for all benchmarks that follow. Next, five different adaptation strategies are shown. The first two – uniform SAR and Gaussian area overlap – are commonly seen in the literature, while for the latter three – SMD, small Gaussian gap (SGG), and equalised thermodynamic length (ETL) – we present our implementations, as effective alternatives, especially when Cν is non-uniform.
3.2.1 Uniform swap-acceptance rate
Vousden et al. (2016) propose that the dynamic adjustments of the temperature ladder are guided by the SAR. They define the ladder in terms of logarithmic temperature intervals, S i, between adjacent chains. Therefore, the adaptation rate corresponds to 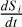 . The adaptation includes a diminishing factor, κ(t), where limt→∞ κ(t) = 0, here expressed as a hyperbolic decay:
. The adaptation includes a diminishing factor, κ(t), where limt→∞ κ(t) = 0, here expressed as a hyperbolic decay:
![Mathematical equation: $\matrix{ {{S_i} \equiv \ln \left( {{T_i} - {T_{i + 1}}} \right),} & {{{d{S_i}} \over {dt}} = \kappa (t)\left[ {{A_i}(t) - {A_{i + 1}}(t)} \right]} \cr } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq26.png) (13)
(13)
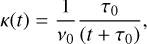 (14)
with Ai(t) the measured SAR, τ0 the decay half-life, and ν0 the evolution timescale. This leaves both β1 and βB static, while the intermediate temperatures settle to achieve a uniform SAR.
(14)
with Ai(t) the measured SAR, τ0 the decay half-life, and ν0 the evolution timescale. This leaves both β1 and βB static, while the intermediate temperatures settle to achieve a uniform SAR.
3.2.2 Gaussian area overlap
Rathore et al. (2005), by studying the correlation between replicas of the SAR and the area of overlap of likelihoods in Gaussian distributions, found a relation to control the acceptance rate by spacing temperatures:
![Mathematical equation: ${A_{{\rm{overlap}}}} = {\rm{erfc}}\left[ {{{{\rm{\Delta }}\ln {\cal L}} \over {2\sqrt 2 {\sigma _m}}}} \right]\,\,\,\, \Rightarrow \,\,\,{\left. {{{{\rm{\Delta }}\ln {\cal L}} \over {{\sigma _m}}}} \right|_{\beta i}} = {\left[ {{{{\rm{\Delta }}\ln {\cal L}} \over {{\sigma _m}}}} \right]_{{\rm{target}}}},$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq28.png) (15)
where σm = (σ1 + σ2)/2 is the mean of the deviations of the adjacent temperature log-likelihoods. While also aiming for uniform SAR, this ladder evolution is informed by a different mechanism, which may compensate for the effects of having a non-uniform Cν.
(15)
where σm = (σ1 + σ2)/2 is the mean of the deviations of the adjacent temperature log-likelihoods. While also aiming for uniform SAR, this ladder evolution is informed by a different mechanism, which may compensate for the effects of having a non-uniform Cν.
3.2.3 Uniform swap mean distance
Considering that a non-uniform Cν is more realistic for complex systems (as in exoplanet discovery), Katzgraber et al. (2006) presented a feedback-optimised method that maximises the round trips of each replica between the extremal temperatures. This allows information about the likelihood landscape to travel faster from the hot chain to the cold chain. A well-tempered chain (where the posterior shape has changed significantly compared to the target posterior) should propose far-away states that, if accepted, would contribute more to healthy mixing than a swap so close that it is equivalent to the intra-chain evolution. Therefore, a ladder where adjacent swaps are done by maximising the swap distance would maximise the crossing of ‘useful’ information across the replicas. By normalising all dimensions in the system to unity, the mean distance of adjacent swaps for all walkers at a given temperature is
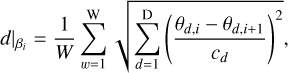 (16)
where W is the number of walkers, D the number of dimensions, and cd the range of the prior for dimension d. Hereafter this method is referred to as the SMD. Intuitively, this encourages swaps that carry proposals farther across the parameter space, which may be specifically beneficial in high-dimensional problems, where local swaps might exchange nearly similar states.
(16)
where W is the number of walkers, D the number of dimensions, and cd the range of the prior for dimension d. Hereafter this method is referred to as the SMD. Intuitively, this encourages swaps that carry proposals farther across the parameter space, which may be specifically beneficial in high-dimensional problems, where local swaps might exchange nearly similar states.
3.2.4 Small Gaussian gap
This scheme (SGG) targets a uniform SAR by using a Gaussian approximation for small temperature gaps. If adjacent βs are very close, the energy difference, ∆Ui, has approximately a Gaussian distribution of ∼(0, 2Var[Ui]). In this small-gap regime, one can show that the product (∆βi)2Var[Ui] largely controls the SAR (Predescu et al. 2004), from Eq. (11):
![Mathematical equation: $\matrix{ {{{\bar A}_{i,i + 1}}} \hfill & { = {_{{\beta _i},{\beta _i} + 1}}\left[ {\exp \left( { - {\rm{\Delta }}{U_i} \cdot {\rm{\Delta }}{\beta _i}} \right)} \right]} \hfill \cr {} \hfill & { \approx \exp \left( {{1 \over 2}{{\left( {{\rm{\Delta }}{\beta _i}} \right)}^2}\left( {2{\rm{Va}}{{\rm{r}}_{{\beta _i}}}[U]} \right)} \right) = \exp \left( {{{\left( {{\rm{\Delta }}{\beta _i}} \right)}^2}\left( {{\rm{Va}}{{\rm{r}}_{{\beta _i}}}[U]} \right)} \right).} \hfill \cr } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq30.png) (17)
(17)
Thus, keeping the product (∆βi)2(Var[Ui]) constant implies a roughly uniform SAR.
3.2.5 Equalised thermodynamic length
The thermodynamic length is defined as
![Mathematical equation: $L(\beta ) = \int_{{\beta _{\min }}}^{{\beta _{\max }}} {\sqrt {{\rm{Va}}{{\rm{r}}_\beta }[{\rm{U}}]} d\beta } = \int_{{\beta _{\min }}}^{{\beta _{\max }}} {{{\sqrt {{C_v}} (\beta )} \over \beta }d\beta } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq31.png) (18)
(18)
Intuitively L(β) corresponds to the local metric that measures how quickly (or far) the distribution changes with β. Setting neighbouring replica distributions so that they are the same ‘distance’ apart translates to placing them uniformly in L space, effectively populating the regions where Cν peaks with more chains. This ensures denser sampling where the posterior changes most rapidly. Each interval of this integral can be approximated as
![Mathematical equation: ${\rm{\Delta }}{L_i} \approx {{{\rm{\Delta }}{\beta _i}} \over 2}\left( {\sqrt {{\rm{Va}}{{\rm{r}}_{{\beta _i}}}[{\rm{U}}]} + \sqrt {{\rm{Va}}{{\rm{r}}_{{\beta _{i + 1}}}}[{\rm{U}}]} } \right).$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq32.png) (19)
(19)
Then, the discrete estimate for thermodynamic distance is
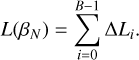 (20)
(20)
Shenfeld et al. (2009) arrived at the same conclusion, further demonstrating that under constant Cν the ETL forms a geometric progression as well.
3.2.6 Ladder adaptation in reddemcee
reddemcee implements each of the methods discussed above by setting the adaptation as 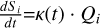 . This way, choosing a definition for Qi determines the adaptive approach – be it a uniform SAR, Gaussian area overlap (GAO), uniform SMD, SGG, or ETL:
. This way, choosing a definition for Qi determines the adaptive approach – be it a uniform SAR, Gaussian area overlap (GAO), uniform SMD, SGG, or ETL:
![Mathematical equation: ${Q_i} = \left\{ {\matrix{{{\rm{[}}{A_i}{\rm{(}}t{\rm{) - }}{A_{i{\rm{ + 1}}}}{\rm{(}}t{\rm{)]}}} \hfill & {{\rm{for SAR (see Sect}}{\rm{. 3}}{\rm{.2}}{\rm{.1)}}} \hfill \cr {{{\Delta {U_i}} \over {{\sigma _m}}}} \hfill & {{\rm{for GAO (see Sect}}{\rm{. 3}}{\rm{.2}}{\rm{.2)}}} \hfill \cr {{{\left. d \right|}_{{\beta _i}}}} \hfill & {{\rm{for SMD (see Sect}}{\rm{. 3}}{\rm{.2}}{\rm{.3)}}} \hfill \cr {\exp \left( {{{(\Delta {\beta _i})}^2}(Var[{U_i}])} \right)} \hfill & {{\rm{for SGG (see Sect}}{\rm{. 3}}{\rm{.2}}{\rm{.4)}}} \hfill \cr {{{\Delta {L_i}} \over {L({\beta _N})}}} \hfill & {{\rm{for ETL (see Sect}}{\rm{. 3}}{\rm{.2}}{\rm{.5)}}} \hfill \cr } .} \right.$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq35.png) (21)
(21)
3.3 Revisiting evidence
The APT implementation does not provide independent draws; each walker’s proposal is based on its current position, meaning successive samples retain memory until the integrated autocorrelation time has passed. The stretch move also couples walkers, influencing each other’s proposals (Goodman & Weare 2010). Furthermore, the swap move creates a cross-temperature coupling as well. To account for all these effects in correlated draws, we replaced IID-based errors with autocorrelation-adjusted MC standard errors (Flegal & Jones 2008), using overlapping batch means (OBM, Wang et al. 2018). This technique, which is consistent for MCMC under standard ergodicity conditions, also propagates cross-temperature covariance across the ladder. We used this as 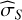 for both methods.
for both methods.
Both TI and SS rely on the shape of the 𝔼β[U](β) curve, for which we considered three factors: (1) the ladder size is relatively small, providing few samples for either TI or SS; (2) temperatures are not uniformly spaced; (3) 𝔼β[U](β) is a monotonically increasing function. With these points in mind, two different solutions for a better 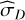 come to mind. One approach is to use the Richardson extrapolation, which entails computing the evidence estimate on two different grids (one coarse and one fine). The difference between these estimates is then used to extrapolate the discretisation error, leveraging the known convergence order of the trapezoidal rule. Another approach is to estimate the local curvature of the 𝔼β[U](β) curve (since the leading trapezoidal-rule error term is proportional to the second derivative) to derive a tailored error estimate for each interval. In the following paragraphs, two original implementations based on these ideas are presented, leveraging the properties of 𝔼β[U](β) for a more precise ln 𝒵 estimation.
come to mind. One approach is to use the Richardson extrapolation, which entails computing the evidence estimate on two different grids (one coarse and one fine). The difference between these estimates is then used to extrapolate the discretisation error, leveraging the known convergence order of the trapezoidal rule. Another approach is to estimate the local curvature of the 𝔼β[U](β) curve (since the leading trapezoidal-rule error term is proportional to the second derivative) to derive a tailored error estimate for each interval. In the following paragraphs, two original implementations based on these ideas are presented, leveraging the properties of 𝔼β[U](β) for a more precise ln 𝒵 estimation.
Piecewise interpolated thermodynamic integration. Building on the TI method, an interpolation on the curve 𝔼β[U](β) was applied with the local piecewise cubic hermite interpolating polynomial (PCHIP), which preserves monotonicity (physically expected) and prevents overshooting for non-smooth data (few temperatures; Fritsch & Butland 1984). For 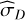 , we formed a coarse ladder by dropping every other temperature, built the corresponding PCHIP, and computed another coarser evidence estimate. We used its difference with respect to the finer one as the discretisation error.
, we formed a coarse ladder by dropping every other temperature, built the corresponding PCHIP, and computed another coarser evidence estimate. We used its difference with respect to the finer one as the discretisation error.
The total error is then 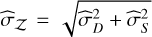 . It is worth noting that this approach addresses the discretisation error more explicitly, reducing bias at the cost of possibly smaller (but more realistic) error bars, as is shown in Section 4. More details on the method can be found in Appendix C.2.
. It is worth noting that this approach addresses the discretisation error more explicitly, reducing bias at the cost of possibly smaller (but more realistic) error bars, as is shown in Section 4. More details on the method can be found in Appendix C.2.
Geometric-bridge stepping stones. The SS evidence estimator, 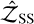 (see Eq. 9), estimates the ratio, ri, with an expectation under a single distribution,
(see Eq. 9), estimates the ratio, ri, with an expectation under a single distribution, ![Mathematical equation: ${_{{\beta _i} + 1}}[ \cdot ]$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq41.png) (see Eq. 6). We replaced the ratios with geometric-bridge sampling (Meng & Wong 1996; Gronau et al. 2017):
(see Eq. 6). We replaced the ratios with geometric-bridge sampling (Meng & Wong 1996; Gronau et al. 2017):
![Mathematical equation: ${r_i} = {{{_{{\beta _i}}}\left[ {{{\cal L}^{{\rm{\Delta }}{\beta _i}/2}}} \right]} \over {{_{{\beta _{i + 1}}}}\left[ {{{\cal L}^{ - {\rm{\Delta }}{\beta _i}/2}}} \right]}}$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq42.png) (22)
(22)
By using samples from both ends, we expect to diminish the estimator variance when the temperature gap is large, as the per-stone ratio would degrade less rapidly. Using the same APT samples has no additional computational cost, and by halving the exponent we reduce the dynamic range, improving numerical stability. A more detailed explanation can be read in Appendix C.1.
Hybrid method. Consider a temperature mid-point, β∗, so TI is applied in β ∈ [0, β∗], and stepping stones in β ∈ [β∗, 1]. Provided that continuity is ensured around β∗, separating where each method is stronger leads to a fair estimation of ln 𝒵. From Eq. (5) the overall log-evidence can be decomposed as
![Mathematical equation: $\ln {\cal Z} = \int_0^1 {{_\beta }[U]d\beta = } \int_0^{{\beta _ * }} {{_\beta }[U]d\beta + } \int_{{\beta _ * }}^1 {{_\beta }[U]d\beta } $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq43.png) (23)
(23)
The transition between the ‘pure prior’ region (β=0) to a moderately informed distribution (small β) changes statistics more dramatically than other areas. Intuitively, any sharp change in posterior shape can be seen as a phase transition, which is also reflected as a peak in Cν(β). Since most temperature ladders are proportional in some form to Cν, chains are denser in this region, and therefore a straightforward method such as TI works well. Near β=1, SS is more efficient at handling ratios, since the posterior is strongly peaked and ∆β tends to increase. By decomposing the TI trapezoidal area contribution of each interval, the mid-point is selected to be where the rectangular area is larger than twice the triangular area, ensuring that we are in a region where ∆Ui dominates over ∆βi, and where the energy slope is pronounced:
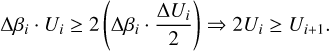 (24)
(24)
4 Benchmarks
This section seeks to validate the proposed ladder adaptation algorithms as well as the evidence estimators. Taken together, these tests probe the different problems that matter most when contrasting an APT sampler with DNS. Gaussian shells, Gaussian egg-box, and the hybrid Rosenbrock function capture the three classic challenges when sampling from a multimodal distribution: mode-finding, mode-hopping, and in-mode mixing, all of which are intensified as dimensionality increases. Hereafter, two distinct qualities are compared: first, the sampler performance (comprising both the intra-chain mixing and the computational cost, measured in effective samples per second or ‘kenits’); and second, the evidence estimation (comprising the estimated evidence value and its uncertainty). This was measured by both the difference found with the analytical evidence 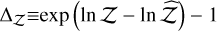 , validating the accuracy of the estimator, and the log-likelihood
, validating the accuracy of the estimator, and the log-likelihood 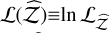 , validating the credibility of the uncertainties, for
, validating the credibility of the uncertainties, for 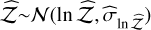 , where ln
, where ln 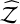 is the estimate of the evidence, and
is the estimate of the evidence, and 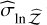 the estimate of the evidence uncertainty. Each benchmark was run 11 times with different known random seeds, and the reported values correspond to the mean and standard deviation of all runs.
the estimate of the evidence uncertainty. Each benchmark was run 11 times with different known random seeds, and the reported values correspond to the mean and standard deviation of all runs.
 |
Fig. 1 2D Gaussian shells likelihood. Radius r=2 and width w=0.1. Parameter boundaries are imposed as ±6. Likelihood values are coloured from blue (low) to red (high) to facilitate the visualisation of the figure. |
4.1 n-d Gaussian shells
Sampling from an n-dimensional Gaussian shell is an analytically tractable problem widely used in the literature (Feroz & Hobson 2008; Speagle 2020). The likelihood contours are curved, thin, and nearly singular (see Fig. 1). Random-walk steps are inefficient, so this multimodal function stresses proposal geometry and temperature allocation. For n dimensions, radius r, width w, and peaks’ centres ci, the likelihood is
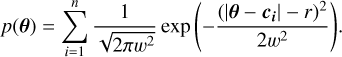 (25)
(25)
This benchmark was used to assess the behaviour of the different samplers in efficiency and evidence estimation. reddemcee was set up with [16, 320, 640, 1] temperatures, walkers, sweeps, and steps, respectively, for a total of 3 276 800 samples. The adaptation hyper-parameters, τ0, ν0, were set as one tenth of the sweeps and one hundredth of the walkers, respectively. We adapted the temperature ladder during the first half of the sweeps, and then froze it. This entire adaptive phase was treated as burn-in: those samples were discarded before any statistical inference, but the time spent was included in the reported run-time (i.e. it affects the kenits metric). For comparison, the DNS runs were performed using dynesty (Speagle 2020) with its automated settings, testing three sampling modes: uniform, slice, and random-slice.
For dynesty, we calculated kenits using the reported number of likelihood calls, effectively measuring the sampling efficiency (fraction of independent samples) times all likelihood evaluations divided by the total run-time. For reddemcee, efficiency was defined as the inverse of the average autocorrelation time of the cold-chain, and kenits were computed as this efficiency multiplied by the number of likelihood evaluations (discarding burn-in samples, but not their run-time) over the full run-time. This method ensures a fair kenits comparison.
Sampler performance. All adaptive ladder methods are statistically similar (see Table 1); variance between ladder algorithms (0.042) is smaller than the run-to-run variance of each method (≈0.122), delivering ≈3.6–3.8 kenits. The best DNS method, dyn-rs, achieves 0.94±0.05 kenits, which is 26% of the APT average. This method also finishes the fastest, at 13.4s. It is worth mentioning that once converged, the efficiency does not radically change, so even by demanding a higher total iteration count as a stop condition, the kenits (and efficiency) would not dramatically increase. The dynamic algorithm stops at target precision, which, in the dyn-u case, required a much longer run-time with many more samples, whereas the slice methods finished faster with far fewer independent samples. In other words, there is a trade-off between thorough posterior sampling and evidence-estimation convergence speed. The same reasoning can be extended to MCMC, preserving much richer posterior information.
Evidence estimation. The proposed evidence estimation methods in Sect. 2.4 were tested and compared against the analytical value for the 2D case, ln 𝒵=−1.746 (see Table 2). The default TI method has 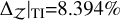 , whereas the improved TI+ version achieves
, whereas the improved TI+ version achieves 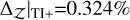 (an order of magnitude closer to the true value). The likelihood improves as well, with a ratio of exp(2.80 – 0.92) = 6.58. By contrast, the default SS has the highest
(an order of magnitude closer to the true value). The likelihood improves as well, with a ratio of exp(2.80 – 0.92) = 6.58. By contrast, the default SS has the highest 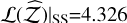 alongside a low
alongside a low 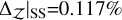 . The SS+ counterpart shows slightly more conservative uncertainties (0.006 instead of 0.005) with
. The SS+ counterpart shows slightly more conservative uncertainties (0.006 instead of 0.005) with
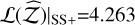 , and a slightly higher accuracy,
, and a slightly higher accuracy,
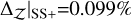 . The H+ method achieves the highest accuracy of all,
. The H+ method achieves the highest accuracy of all, 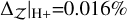 , along with a high likelihood,
, along with a high likelihood, 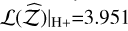 . Out of the DNS methods, dyn-u is the most reliable with
. Out of the DNS methods, dyn-u is the most reliable with 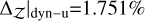 , and a log-likelihood of
, and a log-likelihood of 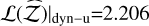 .
.
2D Gaussian shells performance benchmark.
4.2 Gaussian egg-box
The Gaussian egg-box, dubbed after its likelihood shape (see Fig. 2), presents a periodic landscape with several equally high peaks, separated by deep troughs. It is an ideal stress test for mode completeness. Missing a single peak would render catastrophically wrong evidence. The likelihood function is
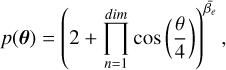 (26)
where
(26)
where 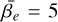 was used, defining the narrowness of the peaks. The prior volume was limited to [0, 10π], and a fine grid integration gives ln 𝒵=235.856, which was used as the true value. We used the same set-up as in Sect. 4.1.
was used, defining the narrowness of the peaks. The prior volume was limited to [0, 10π], and a fine grid integration gives ln 𝒵=235.856, which was used as the true value. We used the same set-up as in Sect. 4.1.
Sampler performance. For the ladder adaptation methods, the SAR and SMD methods rank best at 5.79 ± 0.29 and 5.66 ± 0.23 kenits with overlapping uncertainties, followed closely by the other methods (see Table 3). Out of the DNS methods, dyn-rs has the lowest wall-time as well as the highest kenits count, 0.82 ± 0.07, 14.2% of the SAR kenits.
Evidence estimation. As seen in Table 4, the TI algorithm misses the mark by Δ𝒵=11.53%, with the worst overall likelihood: 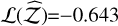 . TI+ improves this to Δ𝒵=1.43%, with a likelihood ratio of exp(2.658 − (−0.643)) = 26.87. The SS yields a log-likelihood of
. TI+ improves this to Δ𝒵=1.43%, with a likelihood ratio of exp(2.658 − (−0.643)) = 26.87. The SS yields a log-likelihood of 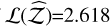 . Its SS+ counterpart marginally reduces Δ𝒵 from 1.25% to 1.21%, with
. Its SS+ counterpart marginally reduces Δ𝒵 from 1.25% to 1.21%, with 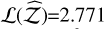 . The H+ method outperforms SS+ and TI+, achieving
. The H+ method outperforms SS+ and TI+, achieving 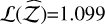 and
and 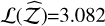 . Out of the DNS methods, dyn-u finds all modes (extremely accurate Δ𝒵=0.201), albeit at the cost of many likelihood calls. Meanwhile, slice-based samplers are faster but slightly undersample some modes (evidence biases). dyn-u has the highest log-likelihood out of the DNS methods, at 1.828. Against H+, it gives a ratio of exp(3.082 – 1.828) = 3.5, which is almost four times as likely.
. Out of the DNS methods, dyn-u finds all modes (extremely accurate Δ𝒵=0.201), albeit at the cost of many likelihood calls. Meanwhile, slice-based samplers are faster but slightly undersample some modes (evidence biases). dyn-u has the highest log-likelihood out of the DNS methods, at 1.828. Against H+, it gives a ratio of exp(3.082 – 1.828) = 3.5, which is almost four times as likely.
2D Gaussian shells SAR evidence estimation comparison.
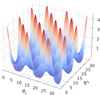 |
Fig. 2 Gaussian egg-box likelihood, with 16 different modes. Likelihood values are coloured from blue (low) to red (high) to facilitate visualisation. |
Egg-box performance benchmark.
Egg-box evidence SAR estimation comparison.
4.3 Hybrid Rosenbrock function
The Rosenbrock function is a long, thin, curved valley with strong non-linear correlations, slightly resembling a banana. The hybrid-Rosenbrock function is an extension that provides analytic evidence for any dimension (Pagani et al. 2019). Its likelihood is
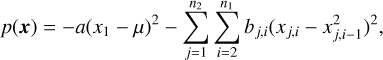 (27)
where x j,i, μ ∈ ℝ, and a, bj,i ∈ ℝ+ are arbitrary constants. Its evidence is
(27)
where x j,i, μ ∈ ℝ, and a, bj,i ∈ ℝ+ are arbitrary constants. Its evidence is
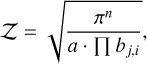 (28)
where n = (n1 − 1) - n2 + 1, and n1 is the number of dimensions in each of the n2 groups. Per Goodman & Weare (2010), a scale factor of 1/20 was chosen, with a = 1/20 and all bj,i = 100/20, so the distribution is shaped like a narrow ridge, providing a challenging posterior shape (see Fig. 3).
(28)
where n = (n1 − 1) - n2 + 1, and n1 is the number of dimensions in each of the n2 groups. Per Goodman & Weare (2010), a scale factor of 1/20 was chosen, with a = 1/20 and all bj,i = 100/20, so the distribution is shaped like a narrow ridge, providing a challenging posterior shape (see Fig. 3).
To assess temperature evolution in the 2D case, the APT setup was changed to [24, 120, 1024, 1], increasing the number of temperatures to 24 and the sweeps to 1 024, while decreasing the walkers to 120, roughly maintaining the total iterations the same as in previous benchmarks.
Sampler performance. The SAR method ranks best with 14.65 ± 0.59 kenits, followed closely by SGG, GAO, and ETL. SMD ranks last, with 6.40 ± 0.41 kenits. For the DNS methods, dyn-rs ranks first with 0.77 ± 0.02 kenits, and dyn-u ranks last with 0.34 ± 0.02 kenits, and almost twice the wall-time (see Table 5). In this scenario, SAR presents increased kenits over dyn-rs by a factor of 19.03, almost 20 times more efficient at producing independent samples.
Evidence estimation. The H+ method relies completely on SS+, dropping TI+ segments (see Table 6). This can be attested by the poor TI+ performance compared to SS+. The slicesampling methods present negative log-likelihoods, indicating substantially underestimated errors.
A 3D case for the Rosenbrock function was also explored (results discussed in Section 6). Generally, the trends held, with reddemcee outperforming in sampling efficiency, and all ladder methods producing accurate evidences (see Table 11).
 |
Fig. 3 Probability contour of the 2D Rosenbrock function. The inset key shows how the colours relate to the probability. |
2D hybrid Rosenbrock performance benchmark.
2D hybrid Rosenbrock SAR evidence-estimation comparison.
5 Exoplanet detection from radial velocities
A real-world application of the APT ladder dynamics developed in Section 3 and evidence-estimation methods introduced in Section 2.4 is presented for the nearby G-dwarf HD 20794. Hosting at least three super-Earths whose RV semi-amplitudes are lower than 1 m s−1, the system combines low amplitudes, multiplicity, and a long-period planet, all features that make model selection and evidence estimation particularly demanding. The innermost signals at 18 and 90 days were first identified in the HARPS discovery paper (Pepe et al. 2011), while subsequent analyses revealed an outer candidate with a period of ~650d that spends a significant fraction of its eccentric orbit inside the stellar habitable zone (Nari et al. 2025).
As such, this system provides an ideal test-bed for assessing the performance of our APT dynamics and evidence-estimation algorithms on a real-world example. The main features that make exoplanet RV fitting challenging are directly reflected in the previous benchmarks: the strong phase transition in Cν is captured by the Gaussian shells, multi-modality and mode completeness in a many-alias situation (for a sparsely sampled period) in the Gaussian egg-box, and the curved, highly correlated ridges typically seen in the angular orbital parameters are emulated by the hybrid Rosenbrock function. In this section, the work by Nari et al. (2025) was followed, with us applying reddemcee to the combined HARPS+ESPRESSO time series, contrasting the resulting evidence with that reported in the literature.
5.1 Model and likelihood
Each exoplanet is characterised by five Keplerian parameters, P – the period, K – the semi-amplitude, e – the eccentricity, 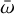 – the longitude of periastron, and M0 – the phase of periastron passage,
– the longitude of periastron, and M0 – the phase of periastron passage,
![Mathematical equation: ${{\cal K}_j}(t) = {K_j} \cdot \left[ {\cos \left( {{v_j}\left( {t,{P_j},{e_j},{M_{0j}}} \right) + {{\bar \omega }_j}} \right) + {e_j}\cos \left( {{{\bar \omega }_j}} \right)} \right],$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq88.png) (29)
where the subscript j indicates each exoplanet and νj is the true anomaly. In addition, each instrument is given an offset, γ (an additive constant), and a jitter, σINS (added in quadrature to the measurement error, corresponding to a white noise component). Therefore, under the assumption of Gaussian-like errors, the loglikelihood is
(29)
where the subscript j indicates each exoplanet and νj is the true anomaly. In addition, each instrument is given an offset, γ (an additive constant), and a jitter, σINS (added in quadrature to the measurement error, corresponding to a white noise component). Therefore, under the assumption of Gaussian-like errors, the loglikelihood is
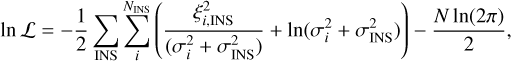 (30)
where the sub-indices i and INS correspond to the i-th RV measurement (taken at a time ti) and to each instrument, respectively. The residuals, ξi,INS, are defined as the difference between the data and the model. Three distinct datasets plus three Keplerian signals add up to a total of 21 parameters or dimensions.
(30)
where the sub-indices i and INS correspond to the i-th RV measurement (taken at a time ti) and to each instrument, respectively. The residuals, ξi,INS, are defined as the difference between the data and the model. Three distinct datasets plus three Keplerian signals add up to a total of 21 parameters or dimensions.
5.2 Parameter estimation and model selection
For an in-depth methodology follow-up, refer to Appendix B. The models compared are: (1) just white noise (H0); (2) a single sinusoid (1S); (3) two sinusoids (2S); (4) three sinusoids (3S); (5) three Keplerians (3K); and (6) four Keplerians (4K). The sinusoidal models (S) treat planets as having circular orbits. The 3K model corresponds to the three confirmed planets, and 4K to the inclusion of an additional candidate.
For the evidence estimation (see Table 7), dyn-rs is consistent with SAR, up to the most complex models. For the 3S , 3K, and 4K models, they have a 4.6, 6.8, and 4.6 In 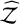 difference, respectively. On the other hand, the SAR log-evidence is all within the reference values’ uncertainties except for the 1S case, which shows a moderate discrepancy (8.7). This could be due to random variation or differences in how noise was treated, but importantly the model ranking is unaffected.
difference, respectively. On the other hand, the SAR log-evidence is all within the reference values’ uncertainties except for the 1S case, which shows a moderate discrepancy (8.7). This could be due to random variation or differences in how noise was treated, but importantly the model ranking is unaffected.
Table 8 compares the estimated evidence errors to the actual run-to-run scatter (the ratio 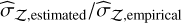 ). An ideal ratio is 1. Values ≪1 mean the method underestimates its true uncertainty, and ≫1 means overestimation. The dyn-rs ratios are all very low for complex models (0.04–0.12), severely underestimating the uncertainty with overly confident evidences, whereas reddemcee yields values much closer to unity (e.g., 0.63 for the 3K). Underestimation of error in multi-planet cases could lead to overconfident claims of detection; therefore, reddemcee (along the H+ estimator) provides more reliable uncertainties.
). An ideal ratio is 1. Values ≪1 mean the method underestimates its true uncertainty, and ≫1 means overestimation. The dyn-rs ratios are all very low for complex models (0.04–0.12), severely underestimating the uncertainty with overly confident evidences, whereas reddemcee yields values much closer to unity (e.g., 0.63 for the 3K). Underestimation of error in multi-planet cases could lead to overconfident claims of detection; therefore, reddemcee (along the H+ estimator) provides more reliable uncertainties.
Performance-wise, APT achieves a higher kenits count in the simpler models, with a turnover point at 3K in favour of dyn-rs. This may be attributable to the modest fixed number of walkers (256) in the APT sampler (see Appendix B for details). In practice, one could adjust the walker count for efficiency’s sake, but it was kept constant for consistency between benchmarks.
For the parameter estimation, the two methods produce consistent results (see Table 9). Notably, the APT-derived parameter posteriors are slightly more asymmetrical and tighter (see K2 and K3). Also, the eccentricity estimates seem less averse to boundary solutions, as is seen in 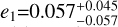 and
and 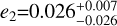 , both of which are consistent with e = 0.
, both of which are consistent with e = 0.
HD 20794 evidence-estimation comparison.
HD 20794 evidence-estimation uncertainty and performance.
6 Discussion
The evidence-estimation algorithms introduced in Section 2.4 have proven to be far more reliable than their unmodified counterparts. Furthermore, whether to apply the TI or the SS method is mostly problem-dependent, and the hybrid algorithm seems to be a good compromise when there is no a priori information about the problem at hand. Moreover, our proposed evidence estimators provide a solid, if not better, alternative to dedicated evidence-sampling methods. This is exemplified by the real-world case studied in Section 5.
Across the simplest problems we tested (few dimensions, nearly constant specific heat), all ladder strategies converge to an almost geometric ladder and yield a similar performance. Differences emerge as the problem’s complexity grows, and since a common problem astrophysicists face is that of dimensionality, we discuss it further next.
HD 20794 parameter estimation.
Gaussian shells with increasing dimensions’ performance.
6.1 Increasing dimensionality
We took the Gaussian shells problem described in Sect. 4.1 and increased its dimensionality without modifying any hyperparameters, in order to demonstrate how the methods scale. As dimensionality grows, we see a very much expected efficiency decrease (see Table 10), as well as the SMD outperforming other methods. At 15 dimensions, it becomes the most effective, with a margin far exceeding the run-to-run scatter. In second place, GAO and ETL come tied (with overlapping confidence intervals), being around 14% slower, followed by the SAR – 19% slower – and the SGG – 34% slower. This supports the intuition that maximising swap distance is beneficial in high-dimensional spaces where local energy traps abound. On the other hand, dyn- rs, still the best DNS method, presents kenits at ~13% of the SMD average.
For evidence estimation, with the modest amount of temperatures proposed for this benchmark, the TI method degrades considerably, with a Δ𝒵 of ~ 72% (see Table A.1). The TI+ soothes this, with Δ𝒵 11.3%. Nevertheless, the error due the discretisation remains a problem in this benchmark. For the SS method, the evidence estimate is excellent (Δ𝒵=2.56), with the highest 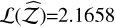 . The SS+ method presents a slight deterioration over its classic counterpart. The H+ presents a higher likelihood (and lower Δ𝒵) than either TI+ or SS+.
. The SS+ method presents a slight deterioration over its classic counterpart. The H+ presents a higher likelihood (and lower Δ𝒵) than either TI+ or SS+.
By increasing the dimensionality of the Rosenbrock function to 3D, the evidence estimation results (H+) are best for ETL with 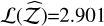 , followed by SGG and GAO, with
, followed by SGG and GAO, with 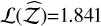 and 1.561, respectively (see Table 11). The kenits values present a similar trend to that of the shells, with 2.98 (SAR), 2.50 (SMD), 3.46 (SGG), 3.03 (GAO), and 2.85 (ETL), and 0.02 (dyn-u), 0.55 (dyn-s), and 0.74 (dyn-rs).
and 1.561, respectively (see Table 11). The kenits values present a similar trend to that of the shells, with 2.98 (SAR), 2.50 (SMD), 3.46 (SGG), 3.03 (GAO), and 2.85 (ETL), and 0.02 (dyn-u), 0.55 (dyn-s), and 0.74 (dyn-rs).
Hybrid 3D Rosenbrock evidence estimation.
6.2 Burn-in
How fast the adaptation optimally distributes the ladder depends on both the problem at hand and the adaptation hyper-parameters ν0 and τ0. We stress-tested adaptation by setting the 15D shells with 640 sweeps (as in Sect. 4.2 and Sect. 6.1) to use 320, 160, 64, and 32 sweeps as burn-in (see Table A.2). H+ is the method most resilient to an uncalibrated ladder. It is the only method that retains positive 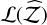 values after the 25% burn-in, with values of In
values after the 25% burn-in, with values of In 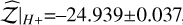 , –24.980±0.031, –24.984±0.034, and –24.996±0.041 for 50%, 25%, 10%, and 5%, respectively.
, –24.980±0.031, –24.984±0.034, and –24.996±0.041 for 50%, 25%, 10%, and 5%, respectively.
6.3 Ladder adaptation
For low-dimensional targets (2D shells, egg-box), every method settles on an almost geometric ladder, due to Cν(β) being almost flat. As the dimensionality grows, Cν develops a broad peak around the phase-transition region, and the objectives react differently. For example, the SAR spreads the temperatures uniformly in swap probability, and therefore stretches the ladder on both sides of the peak, while SMD concentrates the replicas where the specific heat is large, maximising the average information transfer, as is seen by its clear lead at 15D in Table 10.
Longer runs are realised for this scenario, 15D shells, with 10 000 sweeps instead of 640, to examine the convergence of the ladder adaptation. All schemes compress the first ~200 sweeps into a fast logistic-like relaxation of the temperature gaps, after which the diminishing adaptive factor, κ(t) (Eq. (14)), forces a slow power-law tail. In practice, almost the whole ladder shape is set in under 5% of the computational budget, supporting the choice of freezing the ladder after a user-defined burn-in.
Fig. 4 displays the ladder evolution of the SAR and SMD methods, respectively. A notable difference is that the SMD method has a layered swap rate, whereby the cold chain swaps frequently (0.7) and the hot chain seldom does (0.2), whereas the SAR keeps a steady swap rate of 0.5 for all temperatures.
Fig. 5 shows the final ladders as chain density (proportional to Cν) as a function of temperature. The dashed vertical lines indicate where Δβ is smaller, as well as where the transition between TI and SS is applied in the hybrid method.
 |
Fig. 4 Temperature ladder evolution for the 15D Gaussian shells in the SAR regime (top) and SMD regime (bottom). In the x-axis is the current iteration. From top to bottom are the temperature ladder evolution, T, the swap acceptance ratio, Tswap, and the SMD. Colours represent each chain, where blue is the coldest (β=1), with temperature increasing towards the red, where the hottest chain is omitted. The vertical dashed black line indicates where the adaptation stops. |
6.4 Number of temperatures
A natural question that arises is how many temperatures are enough. The answer, as one might expect, is that it depends. When doing an APT run, there are two objectives in mind: posterior and evidence estimation. More temperatures might be redundant posterior-wise, not contributing with additional information to the cold chain. At the same time, more temperatures provide a finer grid for the evidence estimation. Nonetheless, it is possible to dabble into this question, by analysing the temperature evolution of the ladder. If the mixing is low, increasing the temperatures will result in a more efficient run. This may be measured by comparing the additional chains computational cost against the efficiency (or kenits) increase. Visualising the likelihood variance as a function of temperature (the TI) can be helpful. A smoothly increasing curve will not be affected as much as a ladder-like curve by decreasing temperatures. This can also be appreciated by the Cν plot. A ladder-like behaviour would be seen as multiple sharp peaks (as in the HD 20794 3K model, see Fig. 6 with a secondary small peak at around β=0.4), whereas a smooth curve is seen as a single smooth peak (as in the 15D shells, see Fig. 5).
Another matter is how the different evidence-estimation algorithms proposed are affected. The 15D shells (with 10 000 sweeps) were re-run with Nβ=6, 8, 12, and 16 (see Table A.3). The TI method by decreasing temperatures presents a linear fall-off with 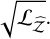 . This result can also be easily derived from Eq. (8), which reveals that the log-evidence error is proportional to
. This result can also be easily derived from Eq. (8), which reveals that the log-evidence error is proportional to 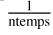 . The TI+ method presents a huge improvement over TI, although still fails to reach the mark in temperature-poor regimes. The SS methods remain extremely accurate even at low Nβ = 6, with Δ𝒵=1.78 and
. The TI+ method presents a huge improvement over TI, although still fails to reach the mark in temperature-poor regimes. The SS methods remain extremely accurate even at low Nβ = 6, with Δ𝒵=1.78 and 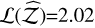 . The geometrical bridge in SS+ yields a small accuracy gain (lower Δ𝒵 for every Nβ), while bringing a small drop in
. The geometrical bridge in SS+ yields a small accuracy gain (lower Δ𝒵 for every Nβ), while bringing a small drop in 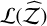 , due to the slight increase in the error estimate.
, due to the slight increase in the error estimate.
 |
Fig. 5 Chain density per temperature range for the SAR and SMD methods in the 15D Gaussian shells. The dashed blue line denotes the maximum of the SAR, with the green one representing the maximum of the SMD. Both lines also denote the regions where the TI or SS algorithms are applied in the hybrid method. |
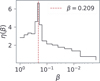 |
Fig. 6 Chain density per temperature range for the HD 20794 3K SAR run. The vertical dashed red line marks the distribution maximum. |
7 Conclusions
We have introduced reddemcee, an APT ensemble sampler that combines three next-level techniques – flexible ladder adaptation, robust evidence estimation, and practical error quantification – into a single, easy-to-deploy package. Three of the five ladder adaptation algorithms are new implementations from this work (SMD, SGG, ETL), reliable alternatives to the most commonly used SAR method, as is demonstrated in our benchmarks (see Section 4). All of these methods converge in a few sweeps and deliver cold-chain mixing efficiencies around an order of magnitude higher than DNS across our tests. In the challenging 15D Gaussian-shell benchmark, reddemcee sustained > 2 ken- its, about 7 times faster than the best DNS configuration, while the SMD ladder proved particularly resilient as dimensionality grew.
We devised three evidence estimators – two original implementations, TI+ and SS+, and a novel hybrid approach – that combine curvature-aware interpolation with bridge sampling. These estimators yield accurate log-evidence and maintain realistic uncertainties even when the number of temperatures is decreased beyond what is optimal.
A real-world application to the HD 20794 RV dataset shows that reddemcee reproduces literature model rankings, recovers planetary parameters with tighter – yet statistically consistent – credible intervals, and supplies evidence uncertainty that closely tracks run-to-run dispersion. Crucially, this performance was obtained without manual ladder tuning: the same hyperparameters were used from no-planet to four-planet models and from 6 to 21 dimensions.
Overall, reddemcee demonstrates that a carefully engineered APT sampler can match, and occasionally surpass, state- of-the-art DNS, both in sampling throughput and in evidence estimation, while retaining the posterior-inference strengths that make MCMC indispensable. Future work will explore on-the-fly convergence diagnostics, further widening the sampler’s applicability to the increasingly complex problems faced in modern astrophysics and beyond.
Acknowledgements
PAPR and JSJ gratefully acknowledge support by FONDE-CYT grant 1240738, from the ANID BASAL project FB210003, and from the CASSACA China-Chile Joint Research Fund through grant CCJRF2205. For the n-d Gaussian shells, Gaussian egg-box, and Rosenbrock function benchmarks parallelisation was not used and computing was limited to single-core for all algorithms. For the exoplanet detection benchmark, parallelisation was used with 24 threads. All the benchmarks were performed on a computer with an AMD Ryzen Threadripper 3990X 64-Core Processor with 128Gb of DDR4 3200Mhz RAM. We thank the anonymous referee for insightful suggestions that enhanced the quality of this manuscript. We are grateful to Fabo Feng and Mikko Tuomi for stimulating early discussions on planet detection. We would also like to thank Dan Foreman-Mackey for the excellent library emcee (Foreman-Mackey et al. 2013), which opened a most exciting new world. Typesetting was carried out in Overleaf (Digital Science UK Ltd. 2025).
References
- Diamond-Lowe, H., Charbonneau, D., Malik, M., Kempton, E. M. R., & Beletsky, Y. 2020, AJ, 160, 188 [NASA ADS] [CrossRef] [Google Scholar]
- Digital Science UK Ltd. 2025, Overleaf [Google Scholar]
- Drummond, A., Nicholls, G., Rodrigo, A., & Solomon, W. 2002, Genetics, 161, 1307 [Google Scholar]
- Earl, D. J., & Deem, M. W. 2005, Phys. Chem. Chem. Phys. (Incorp. Faraday Trans.), 7, 3910 [Google Scholar]
- Feroz, F., & Hobson, M. P. 2008, MNRAS, 384, 449 [NASA ADS] [CrossRef] [Google Scholar]
- Feroz, F., Balan, S. T., & Hobson, M. P. 2011, MNRAS, 415, 3462 [Google Scholar]
- Flegal, J. M., & Jones, G. L. 2008, arXiv e-prints [arXiv:0811.1729] [Google Scholar]
- Ford, E. B., Lystad, V., & Rasio, F. A. 2005, Nature, 434, 873 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2016, J. Open Source Softw., 1, 24 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Fritsch, F. N., & Butland, J. 1984, SIAM J. Sci. Statist. Comput., 5, 300 [Google Scholar]
- Gelman, A., & Meng, X.-L. 1998, Statist. Sci., 13, 163 [Google Scholar]
- Gelman, A., Carlin, J. B., Stern, H. S., & Rubin, D. B. 2004, Bayesian Data Analysis, 2nd edn. (Chapman and Hall/CRC) [Google Scholar]
- Gilks, W. R., Roberts, G. O., & Sahu, S.K. 1998, J. Am. Statist. Assoc., 93, 1045 [Google Scholar]
- Goggans, P. M., & Chi, Y. 2004, in American Institute of Physics Conference Series, 707, Bayesian Inference and Maximum Entropy Methods in Science and Engineering, eds. G. J. Erickson, & Y. Zhai, 59 [Google Scholar]
- Gonzalez, G. 1997, MNRAS, 285, 403 [Google Scholar]
- Goodman, J., & Weare, J. 2010, Commun. App. Math. Comput. Sci., 5, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Gregory, P. C. 2005, ApJ, 631, 1198 [NASA ADS] [CrossRef] [Google Scholar]
- Gronau, Q. F., Sarafoglou, A., Matzke, D., et al. 2017, J. Math. Psychol., 81, 80 [Google Scholar]
- Hansmann, U. H. E. 1997, Chem. Phys. Lett., 281, 140 [Google Scholar]
- Higson, E., Handley, W., Hobson, M., & Lasenby, A. 2019, Statist. Comput., 29, 891 [Google Scholar]
- Hou, F., Goodman, J., Hogg, D. W., Weare, J., & Schwab, C. 2012a, ApJ, 745, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Hou, F., Goodman, J., Hogg, D. W., Weare, J., & Schwab, C. 2012b, ApJ, 745, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, J. S., Díaz, M. R., Kurtovic, N. T., et al. 2020, Nat. Astron., 4, 1148 [Google Scholar]
- Katzgraber, H. G., Trebst, S., Huse, D. A., & Troyer, M. 2006, J. Statist. Mech. Theory Exp., 2006, 03018 [Google Scholar]
- Kofke, D. 2002, jcph, 117, 6911 [Google Scholar]
- Kone, A., & Kofke, D. 2005, J. Chem. Phys., 122, 206101 [Google Scholar]
- Lartillot, N., & Philippe, H. 2006, Syst. Biol., 55, 195 [Google Scholar]
- Marcy, G. W., & Butler, R. P. 2000, PASP, 112, 137 [Google Scholar]
- Maturana-Russel, P., Meyer, R., Veitch, J., & Christensen, N. 2019, Phys. Rev. D, 99, 084006 [Google Scholar]
- Mayor, M., & Queloz, D. 1995, Nature, 378, 355 [Google Scholar]
- Meng, X.-L., & Wong, W. 1996, Statist. Sin., 6, 831 [Google Scholar]
- Miasojedow, B., Moulines, E., & Vihola, M. 2013, J. Computat. Graph. Statist., 22, 649 [Google Scholar]
- Nari, N., Dumusque, X., Hara, N. C., et al. 2025, A&A, 693, A297 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oaks, J. R., Cobb, K. A., Minin, V. N., & Leaché, A. D. 2018, arXiv e-prints [arXiv:1805.04072] [Google Scholar]
- Pagani, F., Wiegand, M., & Nadarajah, S. 2019, arXiv e-prints [arXiv:1903.09556] [Google Scholar]
- Pepe, F., Lovis, C., Ségransan, D., et al. 2011, A&A, 534, A58 [CrossRef] [EDP Sciences] [Google Scholar]
- Predescu, C., Predescu, M., & Ciobanu, C. V. 2004, J. Chem. Phys., 120, 4119 [Google Scholar]
- Rannala, B., & Yang, Z. 1996, J. Mol. Evol., 43, 304 [Google Scholar]
- Rathore, N., Chopra, M., & de Pablo, J. 2005, J. Chem. Phys., 122, 024111 [Google Scholar]
- Roberts, G., & Rosenthal, J. 2007, J. Appl. Probab., 44 [Google Scholar]
- Shenfeld, D. K., Xu, H., Eastwood, M. P., Dror, R. O., & Shaw, D. E. 2009, Phys. Rev. E, 80, 046705 [Google Scholar]
- Skilling, J. 2004, in American Institute of Physics Conference Series, 735, Bayesian Inference and Maximum Entropy Methods in Science and Engineering, eds. R. Fischer, R. Preuss, & U. V. Toussaint, 395 [Google Scholar]
- Speagle, J. S. 2020, MNRAS, 493, 3132 [Google Scholar]
- Sugita, Y., & Okamoto, Y. 1999, Chem. Phys. Lett., 314, 141 [Google Scholar]
- Swendsen, R. H., & Wang, J.-S. 1986, Phys. Rev. Lett., 57, 2607 [CrossRef] [MathSciNet] [PubMed] [Google Scholar]
- van der Sluys, M., Raymond, V., Mandel, I., et al. 2008, Class. Quant. Grav., 25, 184011 [Google Scholar]
- Veitch, J., Raymond, V., Farr, B., et al. 2015, Phys. Rev. D, 91, 042003 [NASA ADS] [CrossRef] [Google Scholar]
- Vines, J. I., Jenkins, J. S., Berdiñas, Z., et al. 2023, MNRAS, 518, 2627 [Google Scholar]
- Vousden, W. D., Farr, W. M., & Mandel, I. 2016, MNRAS, 455, 1919 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, Y.-B., Chen, M.-H., Kuo, L., & Lewis, P. O. 2018, Bayesian Anal., 13, 311 [Google Scholar]
- Xie, W., Lewis, P., Fan, Y., Kuo, L., & Chen, M.-H. 2011, Syst. Biol., 60, 150 [Google Scholar]
Appendix A Gaussian shells
15D Gaussian shells evidence-estimation comparison with the SAR method.
15D Gaussian shells ln 𝒵 estimation with variable burn-in for the SAR method.
15D Gaussian shells ln 𝒵 estimation with variable temperatures for the SAR method.
Appendix B HD 20794
Each dataset, HARPS03, HARPS15, and E19, is nightly binned, then sigma clipped (3σ), and measurements where the error is higher than 3 times the median error are excluded, leaving out 512, 231, and 63 RVs respectively, for a grand total of 806 RVs. Priors were matched to those stated by Nari et al. (2025), with unspecified priors left to an educated guess. For offset a prior ~𝒰(−3, 3) was chosen, and for jitter ~𝒩(0, 5), truncated at [0, 3]. For eccentricity e and longitude of periastron ω, we use the change of variable
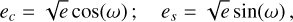 (B.1)
to linearise the circular parameter ω, improving sampler performance, as in Hou et al. (2012b). Point estimates and uncertainties for all parameters are defined as the posterior maxima and the corresponding 1-σ highest-density intervals (HDIs), rather than the more commonly used medians and corresponding 1-σ percentiles, reflecting our methodological preference for mode-based summaries.
(B.1)
to linearise the circular parameter ω, improving sampler performance, as in Hou et al. (2012b). Point estimates and uncertainties for all parameters are defined as the posterior maxima and the corresponding 1-σ highest-density intervals (HDIs), rather than the more commonly used medians and corresponding 1-σ percentiles, reflecting our methodological preference for mode-based summaries.
Both methods had matching estimates for the H0 model (with little variance). This value was chosen as offset for the reference values from the literature. We tried to follow the recipe of executing five runs and selecting the three with highest evidences. But this could not be applied to all models due to inconsistent results.
For the dynesty runs (random-slice sampling, 3 000 live- points), the 1S model consistently found P1 = 18.314 d, K = 0.61 ms−1, with In 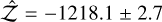 , presenting a 46.1 difference against the H0 model ln
, presenting a 46.1 difference against the H0 model ln 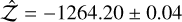 . The 2S run (3 000 live-points) consistently added a signal with P2 = 89.6 d and K2 = 0.44 ms−1 (signal subindex were shifted so P1<P2, and so on), with ln
. The 2S run (3 000 live-points) consistently added a signal with P2 = 89.6 d and K2 = 0.44 ms−1 (signal subindex were shifted so P1<P2, and so on), with ln 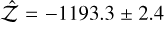 , a difference of 24.9 against 1S.
, a difference of 24.9 against 1S.
An extra sinusoid brought multiple solutions in 3S at P3 = 655, 1 018, and 1 426 d, the former being the solution with the highest maximum likelihood. The number of live-points was gradually increased until this solution was obtained at least three times out of five consecutive runs. At 5 000 live-points this solution was obtained consistently (5 out of 5 times), bringing an evidence difference of 24.2 with the 2S model.
Changing the sinusoids for Keplerians in the 3K model seems to eliminate this problem, since P3 = 655 d appeared consistently amongst runs (3 000 live-points). For consistency, we also did the runs with increasing live-points, but when doing this the algorithm appears to get stuck in lower likelihood peaks more often. With 6 000 live-points we consistently got P3 = 1 378 d, with an evidence 15 lower than P3 = 655 d, and a maximum likelihood 20 lower. The increase in evidence compared to the 3S model (3.1) is tinier than both the reference value and the one obtained with the SAR method.
The 4K model did not converge to a single solution, obtaining 85.5 d, 111 d, 1011 d, or 1420 d as the fourth signal. The best evidence was obtained by the period P4 = 85.54 d, while the best likelihood by P4 = 111.23 d.
By comparing the differences between each model’s best solution, our dyn-rs results match the reference only for Δ𝒵(H0, S 1) and Δ𝒵(S 1, S 2), with diverging results in increasing models by 5.3, 2.6, and −4.2, respectively. This could be explained by the high standard deviation (e.g., for the 4K, 4.6 in the reference and 3.8 in dyn-rs) or to sampler setup differences.
On the other hand, doing the same exercise against the SAR run provides much closer differences to the reference: 0.3, 2.2, −1.5, 1.6, and −0.2, with the highest values corresponding to Δ𝒵(2S, 3S ) and Δ𝒵(3S, 3K), and well within variance.
 |
Fig. B.1 HD 20794 posteriors for the first Keplerian in the 3K SAR run. |
The reddemcee runs used 16 temperatures, 256 walkers, and 5 000 sweeps, increasing by 2 500 extra sweeps for each model, with 17 500 sweeps for the 4K, to facilitate the adaptation stationarity without ‘hand-tuning’ the adaptive parameters.
The 1S model consistently found the P = 18.314 d signal, with an evidence of ln 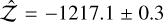 , and a difference of 47.9 with the H0 model. Adding a signal found P2 = 89.66 d consistently, with an evidence improvement of 23.5. The third sinusoid shifted this period slightly to 89.7 d, whilst adding one at P3 = 652.2 d, and improving the evidence by 29.1. Changing the sinusoids to Keplerians brought an improvement of 5.2 evidence-wise, with eccentricities of e1 = 0.057, e2 = 0.026, e3 = 0.467. The top of the posterior samples for the first Kep- lerian can be seen in Fig. B.1, with the last two parameters the aforementioned es and ec in Eq. B.1. Additionally, Fig. B.2 (top) shows a corner plot (scatter plot matrix for multidimensional samples) for the same Keplerian, revealing parameter covariances: P1 and K1 have tight posteriors, with each off-diagonal panel being nearly circular. Both have a little correlation with eccentricity (denoted by their elongation over ec, es). The centre of the ec, es panel indicates a low value for eccentricity. The direction of its isotropic shape defines ω. The phase of periastron passage M0 is coupled to the eccentricity vector, the textbook RV degeneracy. The third signal, with a higher well-defined eccentricity, does not present this degeneracy, as seen in Fig. B.2.
, and a difference of 47.9 with the H0 model. Adding a signal found P2 = 89.66 d consistently, with an evidence improvement of 23.5. The third sinusoid shifted this period slightly to 89.7 d, whilst adding one at P3 = 652.2 d, and improving the evidence by 29.1. Changing the sinusoids to Keplerians brought an improvement of 5.2 evidence-wise, with eccentricities of e1 = 0.057, e2 = 0.026, e3 = 0.467. The top of the posterior samples for the first Kep- lerian can be seen in Fig. B.1, with the last two parameters the aforementioned es and ec in Eq. B.1. Additionally, Fig. B.2 (top) shows a corner plot (scatter plot matrix for multidimensional samples) for the same Keplerian, revealing parameter covariances: P1 and K1 have tight posteriors, with each off-diagonal panel being nearly circular. Both have a little correlation with eccentricity (denoted by their elongation over ec, es). The centre of the ec, es panel indicates a low value for eccentricity. The direction of its isotropic shape defines ω. The phase of periastron passage M0 is coupled to the eccentricity vector, the textbook RV degeneracy. The third signal, with a higher well-defined eccentricity, does not present this degeneracy, as seen in Fig. B.2.
Finally, the 4K model brought both P4~1440 d and ~111 d, with similar evidences and likelihoods.
The step decrease in kenits for the more complex model is attributed to the low walker count. It is also worth noting the difference in both consistency and wall-time in these models. For 3K and 4K the standard deviation in dyn-rs was 2.6 and 3.8 respectively, compared to 0.4 and 0.9 in reddemcee. Furthermore, the average wall-time in dyn-rs was 150.26±32.46, and 112.77±5.2 minutes, whereas in reddemcee it was 57.68±2.57, and 77.21±2.42 minutes. Time-wise, the runs were not only significantly shorter, but also more consistent.
 |
Fig. B.2 HD 20794 corner plot for the first (top) and third (bottom) signals in the 3K model. Figures made with the corner package (Foreman-Mackey 2016). |
Appendix C Evidence estimators
C.1 Geometric-bridge stepping stones
For the temperature ladder 1 = β1 > … > βB ≥ 0, at each βi we have an ensemble of W walkers evolving over T sweeps. For each adjacent pair (βi, βi+1) and for every sweep, we build a symmetric BRIDGE (Meng & Wrong 1996; Gronau et al. 2017) between the two ensembles bridge (Meng & Wong 1996; Gronau et al. 2017) between the two ensembles
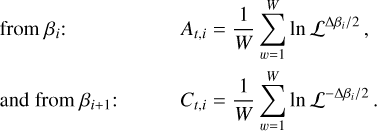 (C.1)
(C.1)
If the ladder is still adapting, we use the per-sweep Δβi,t, otherwise (as in this manuscript) a single averaged Δβi. Then we average over sweeps to get 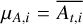 and
and 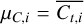 . Each ratio
. Each ratio 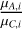 estimates ri via the geometric bridge. Multiplying all these ratios, or adding their logs, gives the log-evidence estimate
estimates ri via the geometric bridge. Multiplying all these ratios, or adding their logs, gives the log-evidence estimate
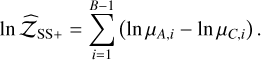 (C.2)
(C.2)
For the sampling error 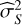 we treat the per-sweep vectors [At; | Ct;] as a correlated time series across sweeps, estimating the long-run covariance with multivariate OBM, and use the delta method for
we treat the per-sweep vectors [At; | Ct;] as a correlated time series across sweeps, estimating the long-run covariance with multivariate OBM, and use the delta method for 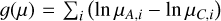 to get
to get ![Mathematical equation: ${\rm{Var}}\left[ {\widehat Z} \right] = \widehat \sigma \mathop s\limits^2 $](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq159.png) (Flegal & Jones 2008; Wang et al. 2018). This method effectively steps along the ladder with a geometric bridge at each step, propagating an autocorrelation-aware uncertainty.
(Flegal & Jones 2008; Wang et al. 2018). This method effectively steps along the ladder with a geometric bridge at each step, propagating an autocorrelation-aware uncertainty.
C.2 Piecewise interpolated thermodynamic integration
For each sweep t = 1,…, T, we take the per-temperature mean log-likelihood 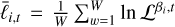 . Now, for each sweep we interpolate the curve
. Now, for each sweep we interpolate the curve ![Mathematical equation: ${{\rm{E}}_\beta }\left[ U \right]\left( \beta \right)$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq161.png) with PCHIP (Fritsch & Butland 1984), and integrate, resulting in a series
with PCHIP (Fritsch & Butland 1984), and integrate, resulting in a series 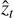 . The time-average of this series is the evidence estimate
. The time-average of this series is the evidence estimate
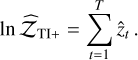 (C.3)
(C.3)
To estimate 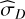 we form a coarser ladder by dropping every other β, recompute the same PCHIP integral to get
we form a coarser ladder by dropping every other β, recompute the same PCHIP integral to get 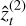 , timeaverage to In
, timeaverage to In 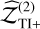 , and set
, and set
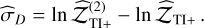 (C.4)
(C.4)
To estimate 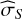 , if the ladder is no longer adapting, we treat
, if the ladder is no longer adapting, we treat 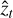 as a correlated univariate time series over the sweeps, estimate its long-run covariance ς with OBM, and set
as a correlated univariate time series over the sweeps, estimate its long-run covariance ς with OBM, and set 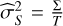 . Otherwise, with a ladder still adapting (under diminishing adaptation), with Nβ the length of the interpolated values, we take the per-sweep trapezoid TI block as
. Otherwise, with a ladder still adapting (under diminishing adaptation), with Nβ the length of the interpolated values, we take the per-sweep trapezoid TI block as
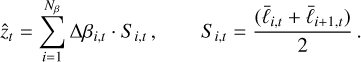 (C.5)
(C.5)
With the St series, we estimate the multivariate long-run covariance ςs with multivariate OBM, and propagate with mean widths 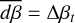 :
:
![Mathematical equation: $\hat \sigma _D^2 = {\rm{Var}}\left[ {{{\hat z}_t}} \right] = {\overline {d\beta } ^ \top }{{\rm{\Sigma }}_S}\overline {d\beta } .$](/articles/aa/full_html/2026/02/aa56609-25/aa56609-25-eq173.png) (C.6)
(C.6)
Note that for the total error, since  and
and 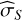 are added in quadrature, they are being treated as independent. For the adaptative case, we need a stationary adaptation settled in the ladder, which should happen under diminishing adaptations after some sweeps have passed, depending on the hyper-parameters on κ(t) (see Eq. 14).
are added in quadrature, they are being treated as independent. For the adaptative case, we need a stationary adaptation settled in the ladder, which should happen under diminishing adaptations after some sweeps have passed, depending on the hyper-parameters on κ(t) (see Eq. 14).
All Tables
15D Gaussian shells ln 𝒵 estimation with variable temperatures for the SAR method.
All Figures
|
Fig. 1 2D Gaussian shells likelihood. Radius r=2 and width w=0.1. Parameter boundaries are imposed as ±6. Likelihood values are coloured from blue (low) to red (high) to facilitate the visualisation of the figure. |
| In the text | |
|
Fig. 2 Gaussian egg-box likelihood, with 16 different modes. Likelihood values are coloured from blue (low) to red (high) to facilitate visualisation. |
| In the text | |
|
Fig. 3 Probability contour of the 2D Rosenbrock function. The inset key shows how the colours relate to the probability. |
| In the text | |
|
Fig. 4 Temperature ladder evolution for the 15D Gaussian shells in the SAR regime (top) and SMD regime (bottom). In the x-axis is the current iteration. From top to bottom are the temperature ladder evolution, T, the swap acceptance ratio, Tswap, and the SMD. Colours represent each chain, where blue is the coldest (β=1), with temperature increasing towards the red, where the hottest chain is omitted. The vertical dashed black line indicates where the adaptation stops. |
| In the text | |
|
Fig. 5 Chain density per temperature range for the SAR and SMD methods in the 15D Gaussian shells. The dashed blue line denotes the maximum of the SAR, with the green one representing the maximum of the SMD. Both lines also denote the regions where the TI or SS algorithms are applied in the hybrid method. |
| In the text | |
|
Fig. 6 Chain density per temperature range for the HD 20794 3K SAR run. The vertical dashed red line marks the distribution maximum. |
| In the text | |
|
Fig. B.1 HD 20794 posteriors for the first Keplerian in the 3K SAR run. |
| In the text | |
|
Fig. B.2 HD 20794 corner plot for the first (top) and third (bottom) signals in the 3K model. Figures made with the corner package (Foreman-Mackey 2016). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.