| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A212 | |
| Number of page(s) | 16 | |
| Section | The Sun and the Heliosphere | |
| DOI | https://doi.org/10.1051/0004-6361/202554265 | |
| Published online | 17 September 2025 | |
Clustering Wind data at 1 AU to contextualize magnetic reconnection in the solar wind
1
KU Leuven, Department of Mathematics, Celestijnenlaan 200b, Leuven 3001, Belgium
2
National Institute for Astrophysics, Astrophysical Observatory of Turin, Via Osservatorio 20, Pino Torinese, 10025 Turin, Italy
3
Laboratory for Atmospheric and Space Physics, University of Colorado, Boulder, CO, USA
4
Institut für Theoretische Physik, Ruhr-Universität Bochum, Universitätstraße 150, 44801 Bochum, Germany
5
Royal Observatory of Belgium, Avenue Circulaire 3, 1180 Brussels, Belgium
6
Dipartimento di Fisica, Università di Torino, via Pietro Giuria 1, 10125 Turin, TO, Italy
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
February
2025
Accepted:
25
July
2025
Abstract
Context. Magnetic reconnection events are frequently observed in the solar wind. Understanding the patterns and structures within the solar wind is crucial to put observed magnetic reconnection events into context, since their occurrence rate and properties are likely influenced by solar wind conditions.
Aims. We employed unsupervised learning techniques such as self-organizing maps (SOM) and K-Means to cluster and interpret solar wind data at 1 AU for an improved understanding of the conditions that lead to magnetic reconnection in the solar wind.
Methods. We collected magnetic field data and proton density, proton temperature, and solar wind speed measurements taken by the Wind spacecraft. After preprocessing the data, we trained a SOM to visualize the high-dimensional data in a lower-dimensional space and applied K-Means clustering to identify distinct clusters within the solar wind data. We then compare the results with the Xu, F., & Borovsky, J. E. (2015, J. Geophys. Res. Space Phys., 120, 70) classification of the solar wind.
Results. Our analysis revealed that the reconnection events are distributed across five different clusters: (a) slow solar wind, (b) compressed slow wind, (c) highly Alfvénic wind, (d) compressed fast wind, and (e) ejecta. Compressed slow and fast wind and ejecta are clusters associated with solar wind transients such as stream interaction regions and interplanetary coronal mass ejections. The majority of the reconnection events are associated with the slow solar wind, followed by the highly Alfvénic wind, compressed slow wind, and compressed fast wind, and a small fraction of the reconnection events are associated with ejecta.
Conclusions. Unsupervised learning approaches with SOM and K-Means lead to physically interpretable solar wind clusters based on their transients and allow for the contextualization of magnetic reconnection exhausts’ occurrence in the solar wind.
Key words: magnetic reconnection / plasmas / Sun: coronal mass ejections (CMEs) / Sun: heliosphere / solar wind
Died in May 28, 2024.
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The Sun constantly emits into interplanetary space the solar wind, a stream of magnetized particles mostly consisting of protons, electrons, and alpha particles. The concept of the solar wind was first introduced by Eddington in 1910 (Eddington 1910) as an explanation for the observed shapes of cometary tails, and its origins were clarified by Parker in 1958 based on theoretical arguments (Parker 1958). First observations by the Luna-1 and Mariner-2 missions quickly followed (Gringauz et al. 1960; Neugebauer & Snyder 1962). Since then a large number of observations and theoretical studies have been made and several missions such as Ulysses (Wenzel et al. 1989), Wind (Ogilvie & Desch 1997), ACE (Advanced Composition Explorer) (Stone et al. 1998), and more recently Parker Solar Probe (PSP) (Fox et al. 2016) and Solar Orbiter (SolO) (Müller et al. 2020) have been launched to probe the solar wind at different distances from the Sun.
The solar wind has traditionally been classified according to the average speed of protons measured at 1 AU (Volker Bothmer 2007) into fast and slow solar wind. The fast wind (v ≳ 500 km/s) generally originates from the coronal holes (Belcher & Davis 1971; Cranmer 2009), i.e., transient coronal regions characterized by less dense and cool plasma, from which the Sun’s magnetic field extends into interplanetary space. The slow solar wind (v ≲ 400 km/s) has many more variable plasma properties (Schwenn 2006) than the fast wind and different candidate solar sources (Abbo et al. 2016).
Recent studies have shown that it is necessary to go beyond the bimodal solar wind model. For instance, Alfvénicity is a characteristic generally attributed to fast wind of coronal hole origin, but recent work has identified highly Alfvénic slow solar wind parcels (D’Amicis & Bruno 2015), and recent PSP observations have shown measurements of generally slow, highly Alfvénic solar wind (Bale et al. 2019; Kasper et al. 2019).
Several investigations have tried to classify solar wind by taking into account different aspects, such as the solar origin. Xu & Borovsky (2015) proposed a four-mode plasma categorization scheme that distinguishes between ejecta, wind of coronal hole origin, sector reversal origin, and streamer belts origin based on three parameters. This classification scheme is the starting point for Camporeale et al. (2017), who added a few additional parameters from a supervised learning approach based on Gaussian Process (GP) for the classification.
At 1 AU we measure both pristine solar wind and the effects of interplanetary transients such as interplanetary coronal mass ejections (ICMEs) and stream interaction regions (SIRs). The ICMEs (Kilpua et al. 2017; Gopalswamy 2016) are macro-scale structures that originate as magnetized plasma clouds ejected from the Sun and are also known as simply coronal mass ejections (CMEs). The SIRs are large-scale plasma structures that result in regions of compression as a fast solar wind overtakes a slow solar wind. A pair of forward and reverse shocks can be produced from this interaction. If the coronal hole source region of the fast wind survives one or more solar rotations, we refer to these SIRs as corotating interaction regions (CIRs) (Heber et al. 1999). These transients and high-speed solar wind streams can result in significant space weather impacts when they interact with the Earth’s magnetosphere (Baker et al. 2018). ICMEs may have particularly strong space weather effects, whereas fast streams and CIRs produce more modest space weather impacts (Manchester et al. 2017).
The solar wind is also affected by smaller-scale phenomena, such as magnetic reconnection (Gosling 2012). Although ICMEs are caused by magnetic reconnection at the solar surface and corona, their passage through interplanetary space causes magnetic reconnection at larger distances from the Sun, in the solar wind (Chian & Muñoz 2011).
Eriksson et al. (2022) have studied the characteristics of magnetic reconnection in multi-scale current sheets in the solar wind. This provided a method of recognizing the occurrence of magnetic reconnection in solar wind in situ observations. With this method, Eriksson et al. (2022) produced a dataset of magnetic reconnection exhausts that took place between July 1, 2004, and December 31, 2014, counting a total of 3374 reconnection exhausts. Heidrich-Meisner & Wimmer-Schweingruber (2018) used K-Means clustering to classify solar wind data from the ACE spacecraft dataset. They showed the importance of the combination of the magnetic field strength and the lower-order moments of the proton velocity distribution function, such as proton density, temperature, and speed, while excluding any ICMEs in their dataset classification. In this work, we apply unsupervised learning techniques to discover patterns in in situ observations of the solar wind at 1 AU, with the objective of finding correspondences between the occurrence of magnetic reconnection and solar wind transients, including ICME transients. The workflow is shown in Figure 1 and it consists of thefollowing steps:
-
Data collection: Retrieve magnetic field data from the MFI instrument (Lepping et al. 1995) and proton density, proton temperature, and solar wind speed data from the 3DP instrument (Lin et al. 1995) on board the Wind spacecraft (Ogilvie & Desch 1997), focusing on one month of data. This step is described in Section 2.
-
Preprocessing: Clean the dataset by removing low-quality data points and applying feature scaling, ensuring that the data are on a comparable scale. This activity is described in Section 2.1.
-
Training SOM: Utilize the self-organizing map (SOM) (Kohonen 2004) to transform time series data into a visual map. This is a technique that has already been used to cluster ACE data (Amaya et al. 2020), magnetospheric simulations (Innocenti et al. 2021), and observations (Edmond et al. 2024), and fully kinetic simulations of tearing and/or plasmoid instabilities (Köhne et al. 2023). The SOM helps visualize high-dimensional data in a lower-dimensional space, making it easier to understand the underlying patterns and structure of the solar wind data. We described SOM training inSection 3.1.
-
Clustering: Apply the K-Means (Lloyd 1982; Macqueen 1967) clustering algorithm to the trained SOM to identify distinct clusters within the solar wind data and determine the optimal number of clusters using the Kneedle algorithm. We describe these steps in Section 3.2.
-
Analysis: Use the reconnection exhausts catalog from Eriksson et al. (2022) to identify the occurrences of magnetic reconnection within the solar wind data and examine the distribution of magnetic reconnection data across the identified clusters. The aim is to understand the relationship of reconnection events with different solar wind conditions. Then, we compare the results with the Xu & Borovsky (2015) classification of the solar wind. We describe this in Section 4.
 |
Fig. 1. Schematic representation of the workflow. From left to right: The dataset was preprocessed by removing low-quality data and applying robust scaling, and then the SOM was trained on the preprocessed dataset. After this, the K-Means algorithm was applied to the SOM’s nodes to identify distinct clusters within the solar wind data. Solar wind data series are colored according to the cluster we identify. |
2. Dataset
We used data from the Wind spacecraft (Ogilvie & Desch 1997); in particular, magnetic field data from the MFI instrument (Lepping et al. 1995) and velocity, proton density, and proton temperature data from the 3DP instrument (Lin et al. 1995). Data were retrieved from the CDAWeb1 Wind dataset using the SunPy Python library (The SunPy Community 2020). The reconnection exhausts’ catalog in Eriksson et al. (2022) covers the period from 2004 to 2014. In our case, we chose the last six months of 2004 (from July 1, 2004, 00:00:00 to December 31, 2004, 23:59:59), corresponding to the descending phase of the XXIII Solar Cycle. We focused on four different physical quantities, with a 3 s cadence: the magnetic field strength, B, measured by the MFI instrument, the proton temperature, Tp, the proton density, Np, and the proton speed, Vp, measured by the 3DP instrument. The initial dataset consists of more than 5 million data points for a total of 181 reconnection exhausts (7556 points). Figure 2 shows the month of July of the initial dataset as an example, with the four features plotted as time series. In red, we highlight the reconnection exhausts from the Eriksson et al. (2022) catalog.
 |
Fig. 2. Proton speed, Vp, magnetic field strength, B, proton density, Np, and proton temperature, Tp, time series for July 2004. In red are the reconnection exhausts. |
2.1. Data cleaning
The Wind data was cleaned by filtering the data gaps and the low-quality data using the data flags from WI_PM_3DP database on the CDAWeb; respectively, “GAP” to remove the gaps (0 is no gap and 1 is a gap) and “VALID” (1 is good-quality data and 0 is low-quality data) to remove the low-quality data. Low-quality data from the MFI instrument was also removed by filtering the 1e−31 values. Whenever there was a data gap or low-quality data in at least one of the parameters, the entire set of corresponding data was removed.
After a visual inspection of the dataset, we noticed that some low-quality data had not been flagged, and the following time intervals had been manually removed: “September 10, 2004, 12:15–13:00,” “October 23, 2004, 04:19–04:20,” and “December 17, 2004, 17:43–17:44.”f All of those time intervals were characterized by sudden nonphysical spikes in one or more parameters (see Figure D.1).
2.2. Features scaling
As is shown in Figure 2, the proton temperature is characterized by a large dynamic range, which can negatively impact the performance of machine learning algorithms. Therefore, we decided to use the logarithm of the proton temperature for our clustering. We remark that the proton temperature is fundamental in distinguishing fast solar wind, which is generally hotter, from slow solar wind, which is generally colder (Marsch et al. 1982; Cranmer 2002). Furthermore, spikes in the proton temperature can be associated with shocks.
Since machine learning algorithms are sensitive to the scale of the input features (Huang et al. 2015; Ozsahin et al. 2022), the second step of the preprocessing phase was the scaling of the features. Scaling of a dataset is a common requirement for many distance-based machine learning estimators. Outliers, i.e., data points significantly out of range with respect to the other points in the dataset, may have a negative impact on the mean and the variance of the dataset. Following Köhne et al. (2023), we used robust scaling to avoid performance reduction and scaling biases due to outliers. Robust scaling (Rousseeuw & Croux 1993) consists of removing the median and scaling the data according to the interquartile range, which in our case is between the first and third quartile.
3. Methodology
3.1. Self-organizing maps
Self-organizing maps (Kohonen 2004) are neural networks that are used in clustering and data visualization, with the aim of producing an ordered and low-dimensional representation of a higher-dimensional dataset. The low-dimensional space generally consists of a structured 2D grid composed of xdim × ydim = K nodes (also called units or neurons). Here, xdim represents the number of columns and ydim the number of rows. Each neuron within this grid possesses a unique position and is linked to a weight vector, 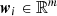 , where m is the number of featuresconsidered.
, where m is the number of featuresconsidered.
To train the SOM, the matrix of weights is initialized. This initialization can be done either randomly or by spanning the weights along the 2D linear subspace of the first two principal components. Then, each data point, x, is randomly picked from the dataset and presented to the network. For each iteration, the following procedure (competition, collaboration, and adaptation) is repeated:
-
Competition (or similarity matching) The SOM nodes competed among themselves to become activated: if
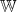 is the set of all the weights in the map, the best matching unit (BMU) of the input data point, x, is identified, by choosing the node whose weight,
is the set of all the weights in the map, the best matching unit (BMU) of the input data point, x, is identified, by choosing the node whose weight, 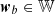 , has a minimum distance (||·||) with respect to x of
, has a minimum distance (||·||) with respect to x of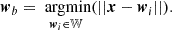 (1)
(1)The BMU is the node that best represents the input data point. The distance between the input data point and the weights can be calculated using different distance metrics, such as the Chebyshev distance, the Euclidean distance, the Mahalanobis distance, the Tanimoto distance, the Manhattan distance, or the vector dot product. In this work, as is suggested in Kohonen (2014), we opted for the Euclidean distance in order to be consistent with the distance metric that was adopted in the K-Means step.
-
Collaboration The identified BMU and its neighboring units in the SOM are activated through a lattice neighborhood function,
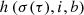 (Eq. (2)). Here σ(τ) represents the iteration-dependent “lattice neighborhood width” (or “neighborhood radius”), usually a monotonically decreasing function that effectively determines the extension of the neighborhood during the training, i is the index of the i-th neuron and b is the BMU index. To obtain a smooth neighborhood function, a Gaussian function is usually selected:
(Eq. (2)). Here σ(τ) represents the iteration-dependent “lattice neighborhood width” (or “neighborhood radius”), usually a monotonically decreasing function that effectively determines the extension of the neighborhood during the training, i is the index of the i-th neuron and b is the BMU index. To obtain a smooth neighborhood function, a Gaussian function is usually selected: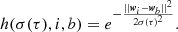 (2)
(2) -
Adaptation For each iteration, the BMU and its neighbors are updated to increase the similarity to the presented sample, x, of the input space. Each weight is updated according to the following rule:
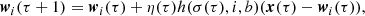 (3)
(3)where i represents the index of the node and b the BMU index. The magnitude of the update depends on the distance of the node, i, from the BMU. Here
![Mathematical equation: $ \eta (\tau ) \in [0;1] $](/articles/aa/full_html/2025/09/aa54265-25/aa54265-25-eq8.gif) is the “learning rate”, which is a decreasing function of the iteration step, τ. The update of the weights depends on the learning rate, η(τ), which controls the magnitude of the update, on the neighborhood function,
is the “learning rate”, which is a decreasing function of the iteration step, τ. The update of the weights depends on the learning rate, η(τ), which controls the magnitude of the update, on the neighborhood function, 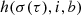 , which controls which and how many weights should be updated, and on the difference,
, which controls which and how many weights should be updated, and on the difference, 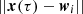 , which shifts the weights toward the input data.
, which shifts the weights toward the input data.
The overall concept is that at the beginning of the training, since the distance between the nodes (weights) and input data is high, i.e., the similarity is low, large updates are needed and a wider number of weights are involved. After several iterations, when the map topology has already partially adapted to that of the input data, minor weight updates are needed and therefore a smaller number of weights is involved in each update, meaning that the updates become more targeted toward improving the numerical similarity of the weight values.
This similarity relation can be expressed in terms of the “quantization error”, QE:
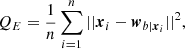 (4)
(4)
where n is the number of points in the dataset, xi the i-th input data, and  the corresponding BMU given xi. It measures the average distance between each of the n entry data points and their BMU, and therefore how similar the map is compared to the input data distribution.
the corresponding BMU given xi. It measures the average distance between each of the n entry data points and their BMU, and therefore how similar the map is compared to the input data distribution.
In this work, we used a CUDA implementation of SOM (CUDA-SOM, Mistri 2020) to speed up the learning process. The discussion and the scaling regarding this tool have already been examined in Köhne et al. (2023).
The CUDA-SOM tool requires the following set of parameters as inputs:
-
Number of rows, xdim, and columns, ydim.
-
The initial learning rate, η0, and the initial neighborhood radius, σ0.
-
Type of decay (exponential or asymptotic) for learning rate and neighborhood radius.
-
Distance metric to use. The options are Euclidean, sum of squares, Manhattan, and Tanimoto.
-
Neighborhood function: Gaussian, Bubble, or Mexican hat.
-
Type of lattice: square or hexagonal.
-
Maximum number of epochs: Tmax.
-
Learning mode: online or batch.
The parameters we chose are shown in Table 1. We explain in Appendix A and Appendix B the reasons for our parameter choices.
CUDA-SOM settings.
3.2. Clustering with K-Means
After the SOM training, we used K-Means on the SOM nodes to obtain a lower number of clusters, which can be used to cluster solar wind time series. The K-Means algorithm (Lloyd 1982; Macqueen 1967) is a partitioning method that aims to minimize the intra-cluster variance and maximize the inter-cluster variance. The algorithm requires as an input the number of clusters, K.
The number of clusters is a crucial parameter, and it can be estimated using the Kneedle algorithm (Satopaa et al. 2011). The algorithm is based on the computation of the second derivative of the intra-cluster variance, ICV(K), with respect to K. The optimal number of clusters is the one that maximizes the second derivative of ICV(K).
The intra-cluster variance is a measure of the homogeneity of the clusters, and it is defined as
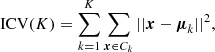 (5)
(5)
where Ck is the k-th cluster and μk is the centroid of the k-th cluster.
To train the K-Means algorithm, we used the KMeans class from the sklearn library (Pedregosa et al. 2011) with“k-means++” initialization, which is a method that chooses the initial centroids in a way that speeds up the convergence of the algorithm.
The results of the clustering of the SOM’s nodes withK-Means are shown in Section 4.2, and the Kneedle method results are shown in Appendix B.
4. Results
4.1. Visualizing the SOM results
The training of the SOM was done on an NVIDIA L40S and took approximately 1.5 hours. The quantization error associated with the trained map is QE = 0.11. The trained SOM is shown in Figure 3; each node in the map is represented by a hexagon. We show the U-matrix on the left and the feature maps corresponding to the four features on the right. The U-matrix represents the distance between the weights of the neurons. It is computed as the average distance between a neuron and its neighbors: a low value of the U-matrix corresponds to a region of the map where neurons are “more similar” to each other, while a high value of the U-matrix corresponds to a region of the map where neurons are “less similar” and more distant from each other. This information can already be used to infer possible clusters in the dataset: low-value regions are likely within clusters, while high values are likely to be the boundaries between clusters.
 |
Fig. 3. (Left) U-matrix representation of the SOM. (Right) Feature maps: proton speed, magnetic field strength, proton density, and logarithm of the proton temperature. In red, we highlight the “reconnection neurons,” i.e., those with which more than four reconnection data points are associated. Here, the SOM weights have been rescaled according to the original dataset. |
We label the so-called “reconnection neurons” in red. Each neuron represents multiple data points of the original dataset: since each data point has been matched with the reconnection exhausts data from Eriksson et al. (2022), it is possible to mark which neuron is the BMU for at least four reconnection data points. We chose four reconnection data points because they correspond to 12 s, which is the median value of the exhaust time duration, shown in Eriksson et al. (2022).
On the right, we show the feature maps, representing the distribution of the features on the map. Here, each hexagon represents a neuron in the SOM, and the color indicates the value of the feature for that neuron. Since the original values for each neuron correspond to the scaled features, to visualize the actual values, the weights have been inversely scaled. We observe that the reconnection data are distributed in different regions of the map, characterized by a different combination of features (i.e., high magnetic field strength, low density, high velocity, medium temperature, and so on), suggesting that the reconnection data belong to different clusters.
4.2. Clustering results
The optimal number of clusters obtained by applying the Kneedle method to SOM’s nodes is K = 5 (see Appendix B). The K-Means clustered map, together with feature maps overplots, is shown in Figure 4. Each node in the map is colored according to the cluster it belongs to.
 |
Fig. 4. Left: Clustered map. Right: Feature maps: proton speed, magnetic field strength, proton density, and proton temperature with overplotted cluster boundaries. In red, we highlight the reconnection neurons. |
It is possible to observe that the reconnection data are distributed in different clusters, confirming the results inferred by the previous inspection of the feature maps.
From the overplots of the clusters’ boundaries on the top of the feature maps (Figure 4, on the right) it is possible to extract some properties of the clusters: in Cluster 1 we observe a low proton speed, low temperature, and average density; in Cluster 2 we observe an enhanced proton speed, and a higher temperature and magnetic field strength compared to Cluster 1; in Cluster 3 we observe a high proton speed, high temperature, and low density; in Cluster 4 we observe a high proton density, low velocity, low temperature, and medium to low magnetic field strength; in Cluster 5 we observe a strong magnetic field, high temperature, and high proton speed.
4.3. Cluster analysis and physical interpretation
Each node of the map can be considered as a local average of data points with similar properties, meaning that different parts of the time series can be mapped onto each neuron. Therefore, it is possible to associate each solar wind data point with one of the five solar wind clusters.
In Figure 5, we plot the month of July 2004 as an example of a clustered time series.
 |
Fig. 5. Plot of the clustered time series for July 2004. Each color corresponds to a cluster identified by the SOM+K-Means method: pink is SSW, cyan is CFW, brown is HAW, blue is CSW, and orange is Ejecta. |
The blue cluster (Cluster 4) is associated with a part of the time series where the proton density is high, the magnetic field strength is increasing, and the solar wind speed is low. We associate this cluster with a compression of the slow solar wind, as it happens in conjunction with the early phase of transient events, especially SIRs, where slow wind is compressed by an incoming fast flow. The pink cluster (Cluster 1) is associated with part of the time series where the proton speed is low, the proton density is high, and the temperature is low. We identify it as slow solar wind. The brown cluster (Cluster 3) is associated with part of the time series where the proton temperature is high, the solar wind speed is high, and the density is low, which is typical in the fast or coronal hole wind. The cyan cluster (Cluster 2) is associated with part of the time series where the proton temperature presents high values and the proton density is higher with respect to Cluster 1 and 3, along with the magnetic field strength, whereas the velocity presents higher values compared to Cluster 4 and 1. This can be associated with a compressed fast wind, which is typical in SIRs and ICMEs’ sheath region. The orange cluster (Cluster 5) is associated with extreme transients in the solar wind where all the features present high values, except for the temperature: we associate this cluster with CME ejecta.
In Figure 6, we plot, at the top, the feature distributions for each cluster, and at the bottom, the average values of each feature for each cluster, which confirms our visual inspection of the time series. Therefore, we decided to assign the following physical interpretation to the clusters:
-
Cluster 1 (Pink): Slow solar wind (SSW).
-
Cluster 2 (Cyan): Compressed fast wind (CFW).
-
Cluster 3 (Brown): Highly Alfvénic wind (HAW).
-
Cluster 4 (Blue): Compressed slow wind (CSW).
-
Cluster 5 (Orange): Ejecta.
The reason we decided to assign the name HAW to the brown cluster is explained in more detail in Section 4.5.
 |
Fig. 6. Top: Feature distribution for each cluster. The x axis represents the feature values, while the y axis represents the number of occurrences of that value in the cluster. Bottom: Average values of each feature for each cluster. The error bars represent the standard deviation of the feature values in each cluster. |
4.4. Reconnection data within the clusters
Now that we have a physical interpretation of the clusters, we can analyze the distribution of the reconnection data across them.
We first performed a visual inspection of the distribution of the reconnection data across the map.
In Figure 7, on the left, we plot the hitmap of the reconnection data on the SOM’s nodes with the clusters boundaries overplotted: for each SOM node, we plot how many reconnection events were detected among the data that have that node as the BMU. On the right, as a comparison, we plot the hitmap for all data, i.e., how many observations are associated with each neuron. It is possible to see that the majority of reconnection events are located in the SSW cluster (pink), followed by the CSW cluster (blue) and the CFW cluster (cyan). The Ejecta cluster (orange) is the one associated with the lowest number of reconnection events. The HAW has the lowest number of activated reconnection neurons, but most of them have a high number of hits. Some reconnection neurons are clustered in a region within this cluster where the velocity is around 450 km/s (Figure D.2, in the yellow box), and the temperature is higher than in the SSW cluster. The hitmap of all data shows that the number of hits is, on average, equally distributed across the map. After the visual inspection, we quantified the distribution of the reconnection data across the clusters. In Table 2 we show the number of reconnection events in each cluster and the relative reconnection content, which is the percentage of reconnection events with respect to the total number of data points in the cluster.
 |
Fig. 7. (Left) Hitmap of the reconnection data on the SOM nodes with the clusters boundaries overplotted: SSW (pink), HAW (brown), CSW (blue), CFW (cyan), and Ejecta (orange). (Right) Hitmap of all data on the SOM nodes. |
Distribution of reconnection events within each cluster obtained with SOM + K-Means.
The table confirms that the majority of the reconnection events (more than 50%) are located in the SSW cluster, followed by the HAW cluster (around 17%), the CSW cluster (around 15%), and the CFW cluster (around 14%). The Ejecta cluster (around 3%) has the lowest percentage of reconnection data. It is noticeable that each cluster has a low relative reconnection content, less than 1%, due to the fact that the total number of reconnection points (7756) is low compared to the size of the initial dataset. However, the clusters with the highest relative reconnection content are the CSW and the Ejecta, followed by SSW, CFW, and HAW.
4.5. The highly Alfvénic wind cluster
The HAW cluster (brown) has proton speed ranging from around 450 km/s to 700 km/s, which is a range that includes low to high solar wind velocities. To further investigate this cluster, we decided to look at its Alfvénicity.
Alfvénicity can be quantified by the correlation coefficient, Cvb, between the fluctuations of the velocity and magnetic field’s components computed using a 30 min running window (D’Amicis et al. 2021), as in:
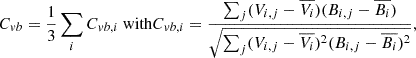 (6)
(6)
where Vi, j and Bi, j are the j-th samples of the velocity and magnetic field i-th component (i = x, y, z), and 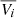 and
and 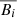 are their mean values over a 30-minute time interval.
are their mean values over a 30-minute time interval.
A value of Cvb close to 1 (−1) indicates that the fluctuations of the velocity and magnetic field are strongly positively (negatively) correlated, while a value close to 0 indicates that they are not correlated. The Alfvénic wind has a high value for the absolute value of Cvb. We computed the average absolute value of the correlation coefficient, Cvb, for each cluster, as is shown in Figure 8. The HAW cluster has a high average absolute value of the correlation coefficient (0.8), indicating that the fluctuations of the velocity and magnetic field are strongly correlated. This suggests that the plasma in this cluster is highly Alfvénic. We see that the CFW cluster is the second cluster with the highest average absolute value of Cvb, followed by the SSW cluster, the CSW cluster, and the Ejecta cluster. The Ejecta cluster has the lowest average absolute value of Cvb, indicating that the fluctuations of the velocity and magnetic field are not correlatedhere.
 |
Fig. 8. Average absolute value of the correlation coefficient, Cvb, for each cluster. The HAW cluster (brown) has a high average absolute value of the correlation coefficient, indicating that the fluctuations of the velocity and magnetic field are strongly correlated (highly Alfvénic wind). |
4.6. Comparison with Xu & Borovsky (2015)
In Xu & Borovsky (2015), the authors provided a solar wind classification based on a different set of parameters. The classification is based on the following parameters: the Alfvén speed, VA, the proton specific entropy, Sp, and the temperature ratio, Texp/Tp, defined as follows:
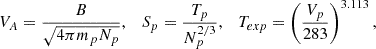 (7)
(7)
where B is the magnetic field strength, mp is the proton mass, Np is the proton density, and Tp is the proton temperature.
The classification is aimed at identifying different solar wind types, based on their origin, using the criteria in Table 3. Ejecta incorporates magnetic clouds and ICMEs, Coronal Hole (CH) is solar wind originating from coronal holes, i.e., fast wind, Streamer Belt (SB) is solar wind originating from the streamer belts, usually associated with slow solar wind, and Sector Reversal (SR) is wind originating from the sector reversal region, corresponding to the helmet streamer regions (see Figure 1 in Xu & Borovsky 2015). We applied the same classification to our dataset and compared the results with our clustering results. The results are shown in Figure 9. On the y axis, we have the clusters identified from our method, while on the x axis, we have the classification from Xu & Borovsky (2015). We then observed how the data from each of “our” clusters would be classified according to Xu & Borovsky (2015) (the sum of each row is 1). We observed that our SSW cluster mainly maps to streamer belt plasma and partially to sector reversal plasma in Xu & Borovsky (2015), as was expected given the possible region of origin of slow solar wind plasmas. Two ejecta clusters correspond well. Our CSW cluster mostly maps to sector reversal plasma and partially to streamer belt plasma. The HAW cluster is mainly composed of coronal hole plasma, as was expected, followed by streamer belt plasma. This may be for two different reasons. The first one, more based on statistics, is that the cadence in our dataset is very high (3 s), while the thresholds obtained in Xu & Borovsky (2015) are based on a lower-cadence dataset (1-hour averages), and this can also explain why we see mismatches in the previous clusters; because the HAW cluster includes not only the “usual” fast, highly Alfvénic solar wind plasma, but also some highly Alfvénic solar wind plasma with velocities around 450 km/s (see Figure 10). The CFW cluster’s composition is the one that captures more attention: according to the Xu & Borovsky (2015) clustering, it is composed of coronal hole plasma, streamer belt plasma, and ejecta plasma. This is partially explained by the conclusions of Xu & Borovsky (2015), in which the authors mention that they noticed a bimodal distribution of their ejecta plasma: one with magnetic-cloud-like patterns of carbon-oxygen ratios, and the other with coronal-hole-like and streamer-belt-like patterns of carbon-oxygen ratios. From Figure 11, it is possible to notice that the identified ejecta plasma by Xu & Borovsky (2015) partially superimposes on our compressed fast wind plasma, which is a wind typically occurring right after a compressed slow wind in an SIR. A typical SIR is characterized by an initial compression of the slow wind, followed by a region of compressed fast wind, which comes before the high-speed stream, as is illustrated in Figure 13 in Belcher & Davis (1971).
Xu & Borovsky (2015) classification criteria.
 |
Fig. 9. Comparison between the solar wind classification from Xu & Borovsky (2015) (on the x axis) and our clustering results (on the y axis). Each row shows the percentages of Xu & Borovsky (2015) classes within the clusters identified by SOM + K-Means. |
 |
Fig. 10. (Top) Comparison between our clustering and the Xu and Borovsky classification for a fast flow during November 2004. The Alfvénicity parameter, |Cvg|, is plotted in black. Our HAW cluster (brown) includes data points classified in Xu & Borovsky (2015) as both CH and SB, but all are characterized by high Alfvénicity. |
 |
Fig. 11. Top: Clustered time series for July 2004. Bottom: Comparison between the Xu & Borovsky (2015) classification and our clustering results. It is noticeable that the Ejecta class in the Xu & Borovsky (2015) classification is also partially superimposed here on our compressed fast wind, which is associated with a SIR. |
We remark that different SIR events may have different signatures, which may result in having only compressed fast wind or compressed solar wind plasma signatures. If we look at the two SIRs in Figure 5, respectively, one SIR on 9–13 July and the other on 18–23 July, we note that the first SIR is characterized by a sequence of both compressed slow and fast plasma, whereas the second one is characterized by only compressed slow plasma. The reason why we see these signatures may need further investigation. It may depend on how the speed of the incoming flow, how compressed the slow wind is, and how the spacecraft trajectory is directed with respect to the incoming SIR. One should not forget that SIRs and ICMEs are 3D structures, and the in situ signatures can differ depending on the trajectory of the spacecraft with respect to the incoming structure.
To further investigate the differences between our clustering results and those from Xu & Borovsky (2015), we analyzed the distribution of reconnection events in the clusters identified following the Xu & Borovsky (2015) classification. The results are shown in Table 4.
Distribution of reconnection events within the solar wind classification from Xu & Borovsky (2015).
Most of the reconnection data are located in the SB cluster (50.86%), followed by the SR cluster (26.65%) and the Ejecta cluster (14.82%). The CH cluster has the lowest percentage of reconnection data (7.66%). This is mostly compatible with our results in Table 2. We see that the reconnection event distribution percentage in the SSW cluster is compatible with that in the SB wind in Table 4. If we sum the reconnection content of our CFW and Ejecta cluster, we get a comparable percentage to the Ejecta plasma in Xu & Borovsky (2015), whereas there are some mismatches with the SR plasma and the CH plasma. The reason for this is partially explained by the result in Figure 9, where we see that the HAW cluster contains a 40% amount of SB plasma, and the CSW cluster has 60% of SR plasma. The relative reconnection content mostly matches what we obtained with our method, with the exception of the HAW cluster, for the reasons we mentioned above.
Overall, the results that we obtain are compatible with the ones in Xu & Borovsky (2015). The mismatches are due to the fact that we aimed for a solar wind clustering highlighting the presence of transients (SIR, CMEs,...) superimposed on the background flow, while Xu & Borovsky (2015) aimed for a solar wind classification based on the solar wind origin. The two approaches are complementary and could potentially be used together to achieve a better understanding of the occurrence of magnetic reconnection in the solar wind.
Coordinated Data Analysis Web https://cdaweb.gsfc.nasa.gov/
References
- Abbo, L., Ofman, L., Antiochos, S. K., et al. 2016, Space Sci. Rev., 201, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Amaya, J., Dupuis, R., Innocenti, M. E., & Lapenta, G. 2020, Front. Astron. Space Sci., 7, 553207 [CrossRef] [Google Scholar]
- Arvai, K. 2020, https://doi.org/10.5281/zenodo.6496267 [Google Scholar]
- Baker, D. N., Erickson, P. J., Fennell, J. F., et al. 2018, Space Sci. Rev., 214, 17 [Google Scholar]
- Bale, S. D., Badman, S. T., Bonnell, J. W., et al. 2019, Nature, 576, 237 [NASA ADS] [CrossRef] [Google Scholar]
- Belcher, J. W., & Davis, Jr., L. 1971, J. Geophys. Res. (1896–1977), 76, 3534 [Google Scholar]
- Bloch, T., Watt, C., Owens, M., McInnes, L., & Macneil, A. R. 2020, Sol. Phys., 295, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Calinski, T., & Harabasz, J. 1974, Commun. Stat., 3, 1 [Google Scholar]
- Camporeale, E., Carè, A., & Borovsky, J. E. 2017, J. Geophys. Res. Space Phys., 122, 910 [Google Scholar]
- Chian, A. C.-L., & Muñoz, P. R. 2011, ApJ, 733, L34 [Google Scholar]
- Cranmer, S. R. 2002, Space Sci. Rev., 101, 229 [Google Scholar]
- Cranmer, S. R. 2009, Liv. Rev. Sol. Phys., 6, 3 [Google Scholar]
- D’Amicis, R., & Bruno, R. 2015, ApJ, 805, 84 [Google Scholar]
- D’Amicis, R., Bruno, R., Panasenco, O., et al. 2021, A&A, 656, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eddington, A. S. 1910, MNRAS, 70, 442 [NASA ADS] [Google Scholar]
- Edmond, J., Raeder, J., Ferdousi, B., Argall, M., & Innocenti, M. E. 2024, J. Geophys. Res. Mach. Learn. Comput., 1, e2024JH000221 [Google Scholar]
- Eriksson, S., Swisdak, M., Weygand, J. M., et al. 2022, ApJ, 933, 181 [NASA ADS] [CrossRef] [Google Scholar]
- Fox, N. J., Velli, M. C., Bale, S. D., et al. 2016, Space Sci. Rev., 204, 7 [Google Scholar]
- Gopalswamy, N. 2016, Geosci. Lett., 3, 1 [Google Scholar]
- Gosling, J. T. 2012, Space Sci. Rev., 172, 187 [Google Scholar]
- Gringauz, K., Bezrokikh, V., Ozerov, V., & Rybchinskii, R. 1960, Sov. Phys. Doklady, 5, 361 [Google Scholar]
- Heber, B., Sanderson, T., & Zhang, M. 1999, Adv. Space Res., 23, 567 [NASA ADS] [Google Scholar]
- Heidrich-Meisner, V., & Wimmer-Schweingruber, R. F. 2018, in Machine Learning Techniques for SpaceWeather, eds. E. Camporeale, S. Wing, & J. R. Johnson, 397 [Google Scholar]
- Huang, J., Li, Y.-F., & Xie, M. 2015, Inf. Software Technol., 67, 108 [Google Scholar]
- Innocenti, M. E., Amaya, J., Raeder, J., et al. 2021, Ann. Geophys., 39, 861 [CrossRef] [Google Scholar]
- Kasper, J. C., Bale, S. D., Belcher, J. W., et al. 2019, Nature, 576, 228 [Google Scholar]
- Kilpua, E., Koskinen, H. E. J., & Pulkkinen, T. I. 2017, Liv. Rev. Sol. Phys., 14, 5 [Google Scholar]
- Köhne, S., Boella, E., & Innocenti, M. 2023, J. Plasma Phys., 89, 895890301 [Google Scholar]
- Kohonen, T. 1990, Proc. IEEE, 78, 1464 [Google Scholar]
- Kohonen, T. 2004, Bio. Cybernet., 43, 59 [Google Scholar]
- Kohonen, T. 2014, MATLAB Implementations and Applications of the Self-Organizing Map [Google Scholar]
- Lepping, R. P., Acũna, M. H., Burlaga, L. F., et al. 1995, Space Sci. Rev., 71, 207 [Google Scholar]
- Lin, R. P., Anderson, K. A., Ashford, S., et al. 1995, Space Sci. Rev., 71, 125 [CrossRef] [Google Scholar]
- Lloyd, S. 1982, IEEE Trans. Inf. Theory, 28, 129 [Google Scholar]
- Macqueen, J. 1967, in Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability/University of California Press [Google Scholar]
- Manchester, W., Kilpua, E. K. J., Liu, Y. D., et al. 2017, Space Sci. Rev., 212, 1159 [Google Scholar]
- Marsch, E., Mühlhäuser, K.-H., Schwenn, R., et al. 1982, J. Geophys. Res. Space Phys., 87, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Mistri, M. 2020, CUDA-SOM: A CUDA implementation of Self-Organizing Maps, gitHub repository, version as of July 20, 2020 https://github.com/mistrello96/CUDA-SOM [Google Scholar]
- Müller, D., St. Cyr, O. C., Zouganelis, I., et al. 2020, A&A, 642, A1 [Google Scholar]
- Neugebauer, M., & Snyder, C. W. 1962, Science, 138, 1095 [Google Scholar]
- Nieves-Chinchilla, T., Vourlidas, A., Raymond, J. C., et al. 2018, Sol. Phys., 293, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Nieves-Chinchilla, T., Jian, L. K., Balmaceda, L., et al. 2019, Sol. Phys., 294, 89 [Google Scholar]
- Ogilvie, K., & Desch, M. 1997, Adv. Space Res., 20, 559 [Google Scholar]
- Ozsahin, D. U., Taiwo Mustapha, M., Mubarak, A. S., Said Ameen, Z., & Uzun, B. 2022, 2022 International Conference on Artificial Intelligence in Everything (AIE), 87 [Google Scholar]
- Parker, E. N. 1958, ApJ, 128, 664 [Google Scholar]
- Pearson, K. 1901, Lond. Edinburgh Dublin Philos. Mag. J. Sci., 2, 559 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Rousseeuw, P. J. 1987, J. Comput. Appl. Math., 20, 53 [Google Scholar]
- Rousseeuw, P. J., & Croux, C. 1993, J. Am. Stat. Assoc., 88, 1273 [Google Scholar]
- Satopaa, V., Albrecht, J., Irwin, D., & Raghavan, B. 2011, 2011 31st International Conference on Distributed Computing Systems Workshops, 166 [Google Scholar]
- Schwenn, R. 2006, Space Sci. Rev., 124, 51 [Google Scholar]
- Stone, E. C., Frandsen, A. M. A., Mewaldt, R. A., et al. 1997, The Advanced Composition Explorer (ACE): Mission Overview, NASA/GSFC and Caltech, launched in 1997, the ACE spacecraft provides near-real-time solar wind data and cosmic ray composition measurements [Google Scholar]
- Stone, E. C., Frandsen, A. M., Mewaldt, R. A., et al. 1998, Space Sci. Rev., 86, 1 [Google Scholar]
- The SunPy Community, Barnes, W. T., Bobra, M. G., et al. 2020, ApJ, 890, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Volker Bothmer, I. A. D. 2007, Space Weather: Physics and Effects (Berlin, Heidelberg: Springer), 635 [Google Scholar]
- Wenzel, K.-P., Marsden, R., Page, D., & Smith, E. 1989, Adv. Space Res., 9, 25 [Google Scholar]
- Xu, F., & Borovsky, J. E. 2015, J. Geophys. Res. Space Phys., 120, 70 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: SOM Parameters
Here we discuss the parameters choice for the SOM training.
Kohonen (1990) suggests the following formula for the number of neurons K in a map:
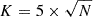 (A.1)
(A.1)
where N is the number of data points in the dataset.
To set the dimension of the map, we have to consider the number of neurons K and the number of rows x and columns y of the map, such that x ⋅ y ≈ K.
To do so, we decide that the ratio between the two dimensions should be the same as the ratio of the two principal components (Pearson 1901) of the dataset:
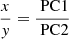 (A.2)
(A.2)
where PC1 and PC2 are the first two principal components’ eigenvalues.
In this work, the decaying function for both neighborhood radius σ and the learning rate η is the following:
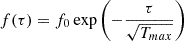 (A.3)
(A.3)
where f0 is the initial value of the parameter, τ is the iteration step and Tmax is the maximum number of iterations.
Tmax is chosen so that toward the end of the training, the neighborhood radius approaches 1, meaning that at the end of the training, the updates are more local and the overall map structure is less impacted by them. Given the initial value of the learning rate η0 and the critical value ηcrit, the upper value number of maximum iterations Tmax is given by:
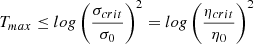 (A.4)
(A.4)
We decide to set the initial learning rate to η0 = 0.01 ⋅ σ0 because we do not want to have large updates mostly affected by large learning rates during the training (see Eq. 3) and a maximum number of epochs Tmax=9.
Appendix B: Comparison with K-Means and Convergence
To better justify our choice of Tmax, we show how classification results are impacted by a different choice of Tmax.
In the body of the manuscript, we use Tmax = 9. Here, we train SOM for 20 epochs. In Figure B.1, it is shown how the hyperparameters and the quantization error (QE) of the SOM is changing according to the epochs, where in red is highlighted the epochs for which, with Tmax=20, the radius goes to 1. It is noticeable that after the radius goes to 1, the improvements on the QE are marginal.
 |
Fig. B.1. Trend of the learning rate, the radius, and the quantization error during the SOM’s training. In red is highlighted the baseline for each quantity when the radius is equal to 1. Green-dashed is the value of the epochs such that the radius first approaches 1. |
After this, we apply K-Means on the data without applying SOM, and compare the results of applying K-Means alone and the clustering results using the SOM that has been used in the main results, and the longer-trained SOM at the stage when the radius is equal to 1 (i=12, where i is the epoch) and at the end of the training (i=19). Figure B.2 shows the comparison between K-Means and SOM + K-Means with the total number of epochs used for the main results (Tmax = 9 epochs) and at the different training stages in the longer training for 12 epochs, 19 epochs. It is noticeable that the comparison gets worse once we look at the last stages of SOM, and that the results with the SOM stopped at epochs equals to 12 and the ones we used in the main results are compatible. We notice that the main differences between applying K-Means alone and the combination of SOM with K-Means are mostly related to the CSW cluster. The CSW cluster is one of the smallest clusters in the dataset (see Figure 6), and we see that in the case of SOM + K-Means, we classify it as SSW. We think that this is a minor issue, and it may be related to the fact that with high cadence, slightly different thresholds may result in slightly different clustering. We see that the biggest clusters, SSW and HAW, are the ones that vary the least.
 |
Fig. B.2. Comparison between K-Means and SOM+K-Means at different stages of the training. From left to right: the SOM that has been used in the main results, long training at epochs equal to 12, and long training at epochs equal to 19. |
B.1. Training with a different number of neurons
To further justify our choice of parameters we decided to perform a training of the SOM with a different number of neurons. We decide to use 70% of the neurons used in the main results, and we rescale each hyperparameter accordingly, with xdim=105, ydim=80, σ0=21, η0=0.21, Tmax=7.
In Figure B.3, on the left, we show the comparison with only applying K-Means on the data and the SOM trained with fewer neurons, and on the right, we show the comparison between the SOM used in the main results and the one trained with fewer neurons. It is noticeable that we have similar results with the ones we obtained by comparing K-Means and SOM + K-Means with the SOM used in the main results. This is confirmed by the comparison between the two SOMs in Figure B.3, on the right, where we have above 93% matching between clusters.
 |
Fig. B.3. (Left) Comparison between K-Means and SOM + K-Means trained with fewer neurons. (Right) Comparison between SOM + K-Means with a SOM with fewer neurons and the SOM that has been used in the main results. |
Appendix C: Finding the optimal number of clusters
C.1. Kneedle Method
The Kneedle method is a technique to find the optimal number of clusters in a dataset. It is based on the computation of the second derivative of the intra-cluster variance as a function of the number of clusters. The intra-cluster variance, or inertia, is defined as the sum of squared distances between each point and the centroid of the cluster to which it has been assigned:
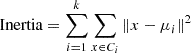 (C.1)
(C.1)
The optimal number of clusters is the one that maximizes the second derivative of the intra-cluster variance.
Here we show the results of the Kneedle method applied to the SOM’s nodes. In this work, we have used the kneed (Arvai 2020) python package to compute the knee of the inertia.
A metric that can be used to evaluate clustering methods is the Calinski-Harabasz index (Calinski & Harabasz 1974). The Calinski-Harabasz index (CH) is defined as the ratio of the sum of inter-cluster dispersion and the sum of intra-cluster dispersion. The index is computed as
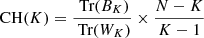 (C.2)
(C.2)
where N is the number of data points, K is the number of clusters, Tr(BK) is the trace of the intra-cluster dispersion matrix and Tr(WK) is the trace of the inter-cluster dispersion matrix, defined as follows:
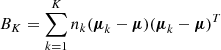 (C.3)
(C.3)
where nk is the number of data points in the k-th cluster, μk is the centroid of the k-th cluster, and μ is the centroid of the dataset. The intra-cluster dispersion matrix is defined as
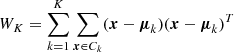 (C.4)
(C.4)
where Ck is the k-th cluster.
Usually, the optimal number of clusters is the one that maximizes the CH index.
The plot of the intra-cluster variance (inertia) as a function of the number of clusters, together with the CH scores inFigure C.1, shows the match between the knee identified by the Kneedle method and the maximum of the CHindex.
 |
Fig. C.1. Plot of the inter-cluster variance (in black) and the Calinski-Harabasz (CH) scores (in blue). The knee (red dashed line) identified with the kneedle method corresponds to the maximum CH score. |
 |
Fig. C.2. Results of the Silhouette analysis of the K-Means clustering of the trained SOM nodes, with different numbers of clusters. Each plot shows the Silhouette scores for each SOM node in each cluster and the average Silhouette score (red dashed). The optimal number of clusters is 5 because all the clusters’ scores are above the average Silhouette score which is greater than the rest of the average scores with different numbers of clusters, excluding the case of K=2, where one cluster (orange) has lower scores than the average and K=3, where two clusters (cyan and orange) are slightly above the average. |
C.2. Silhouette Analysis
Another technique to find the optimal number of clusters is the silhouette analysis. The silhouette score is a measure of how similar an object is to the other data points in its cluster compared to those in other clusters. The silhouette score ranges from -1 to 1, where a value close to 1 indicates that the object is well-matched to its cluster, negative values indicate that an object may have been assigned to the wrong cluster, and values close to 0 indicate that the object is lying close to the decision boundaries between catalog clusters. The silhouette score for a single object i is computed as
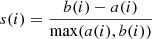 (C.5)
(C.5)
where a(i) is the average distance between i and all other data points in the same cluster, and b(i) is the minimum average distance between i and all other clusters.
The silhouette analysis consists of measuring the silhouette score for each data point and then computing the average silhouette score for each number of clusters. The optimal number of clusters is a compromise between the maximization of the average silhouette score and how much each cluster’s scores are above the average silhouette score.
In Figure C.2, we show the silhouette analysis for the clustering of the SOM’s nodes: the silhouette score for each SOM node and the average silhouette scores are shown. The conditions expressed above are satisfied for K = 5, thus confirming the results obtained with the Kneedle method.
Appendix D: Additional Figures
 |
Fig. D.1. Example of bad quality data window for September 2004. It is noticeable a sudden drop of the velocity at 200 km/s. The other features of the 3DP instrument are affected by the same drop or jumps at the same time. |
 |
Fig. D.2. Detailed picture of the velocity feature map, highlighting in yellow a region of the HAW cluster where the velocity is lower and some of the reconnection neurons are clustered. |
 |
Fig. D.3. (Top) Clustered time series for four ICMEs from Nieves-Chinchilla et al. (2018) (in gray) during July 2004. It is noticeable that the orange cluster is associated with ejecta with a clear signature of a magnetic cloud, whereas the cyan cluster is associated with compressed fast wind and related to events where the magnetic cloud is not clearly defined. For the first three ICMEs, it is noticeable that we have a first phase where the slow wind is compressed (blue), followed by a fast compressed wind, and depending on the event, one has an orange cluster, which is associated with magnetic clouds. The exception is for the last ICME, where a strong shock occurred, and we have no compressed slow wind, but only compressed fast wind. (Bottom) Comparison between Xu & Borovsky (2015) classification. In this case, the Xu and Borovsky classification better matches the ICMEs. |
All Tables
Distribution of reconnection events within each cluster obtained with SOM + K-Means.
Distribution of reconnection events within the solar wind classification from Xu & Borovsky (2015).
All Figures
|
Fig. 1. Schematic representation of the workflow. From left to right: The dataset was preprocessed by removing low-quality data and applying robust scaling, and then the SOM was trained on the preprocessed dataset. After this, the K-Means algorithm was applied to the SOM’s nodes to identify distinct clusters within the solar wind data. Solar wind data series are colored according to the cluster we identify. |
| In the text | |
|
Fig. 2. Proton speed, Vp, magnetic field strength, B, proton density, Np, and proton temperature, Tp, time series for July 2004. In red are the reconnection exhausts. |
| In the text | |
|
Fig. 3. (Left) U-matrix representation of the SOM. (Right) Feature maps: proton speed, magnetic field strength, proton density, and logarithm of the proton temperature. In red, we highlight the “reconnection neurons,” i.e., those with which more than four reconnection data points are associated. Here, the SOM weights have been rescaled according to the original dataset. |
| In the text | |
|
Fig. 4. Left: Clustered map. Right: Feature maps: proton speed, magnetic field strength, proton density, and proton temperature with overplotted cluster boundaries. In red, we highlight the reconnection neurons. |
| In the text | |
|
Fig. 5. Plot of the clustered time series for July 2004. Each color corresponds to a cluster identified by the SOM+K-Means method: pink is SSW, cyan is CFW, brown is HAW, blue is CSW, and orange is Ejecta. |
| In the text | |
|
Fig. 6. Top: Feature distribution for each cluster. The x axis represents the feature values, while the y axis represents the number of occurrences of that value in the cluster. Bottom: Average values of each feature for each cluster. The error bars represent the standard deviation of the feature values in each cluster. |
| In the text | |
|
Fig. 7. (Left) Hitmap of the reconnection data on the SOM nodes with the clusters boundaries overplotted: SSW (pink), HAW (brown), CSW (blue), CFW (cyan), and Ejecta (orange). (Right) Hitmap of all data on the SOM nodes. |
| In the text | |
|
Fig. 8. Average absolute value of the correlation coefficient, Cvb, for each cluster. The HAW cluster (brown) has a high average absolute value of the correlation coefficient, indicating that the fluctuations of the velocity and magnetic field are strongly correlated (highly Alfvénic wind). |
| In the text | |
|
Fig. 9. Comparison between the solar wind classification from Xu & Borovsky (2015) (on the x axis) and our clustering results (on the y axis). Each row shows the percentages of Xu & Borovsky (2015) classes within the clusters identified by SOM + K-Means. |
| In the text | |
|
Fig. 10. (Top) Comparison between our clustering and the Xu and Borovsky classification for a fast flow during November 2004. The Alfvénicity parameter, |Cvg|, is plotted in black. Our HAW cluster (brown) includes data points classified in Xu & Borovsky (2015) as both CH and SB, but all are characterized by high Alfvénicity. |
| In the text | |
|
Fig. 11. Top: Clustered time series for July 2004. Bottom: Comparison between the Xu & Borovsky (2015) classification and our clustering results. It is noticeable that the Ejecta class in the Xu & Borovsky (2015) classification is also partially superimposed here on our compressed fast wind, which is associated with a SIR. |
| In the text | |
|
Fig. B.1. Trend of the learning rate, the radius, and the quantization error during the SOM’s training. In red is highlighted the baseline for each quantity when the radius is equal to 1. Green-dashed is the value of the epochs such that the radius first approaches 1. |
| In the text | |
|
Fig. B.2. Comparison between K-Means and SOM+K-Means at different stages of the training. From left to right: the SOM that has been used in the main results, long training at epochs equal to 12, and long training at epochs equal to 19. |
| In the text | |
|
Fig. B.3. (Left) Comparison between K-Means and SOM + K-Means trained with fewer neurons. (Right) Comparison between SOM + K-Means with a SOM with fewer neurons and the SOM that has been used in the main results. |
| In the text | |
|
Fig. C.1. Plot of the inter-cluster variance (in black) and the Calinski-Harabasz (CH) scores (in blue). The knee (red dashed line) identified with the kneedle method corresponds to the maximum CH score. |
| In the text | |
|
Fig. C.2. Results of the Silhouette analysis of the K-Means clustering of the trained SOM nodes, with different numbers of clusters. Each plot shows the Silhouette scores for each SOM node in each cluster and the average Silhouette score (red dashed). The optimal number of clusters is 5 because all the clusters’ scores are above the average Silhouette score which is greater than the rest of the average scores with different numbers of clusters, excluding the case of K=2, where one cluster (orange) has lower scores than the average and K=3, where two clusters (cyan and orange) are slightly above the average. |
| In the text | |
|
Fig. D.1. Example of bad quality data window for September 2004. It is noticeable a sudden drop of the velocity at 200 km/s. The other features of the 3DP instrument are affected by the same drop or jumps at the same time. |
| In the text | |
|
Fig. D.2. Detailed picture of the velocity feature map, highlighting in yellow a region of the HAW cluster where the velocity is lower and some of the reconnection neurons are clustered. |
| In the text | |
|
Fig. D.3. (Top) Clustered time series for four ICMEs from Nieves-Chinchilla et al. (2018) (in gray) during July 2004. It is noticeable that the orange cluster is associated with ejecta with a clear signature of a magnetic cloud, whereas the cyan cluster is associated with compressed fast wind and related to events where the magnetic cloud is not clearly defined. For the first three ICMEs, it is noticeable that we have a first phase where the slow wind is compressed (blue), followed by a fast compressed wind, and depending on the event, one has an orange cluster, which is associated with magnetic clouds. The exception is for the last ICME, where a strong shock occurred, and we have no compressed slow wind, but only compressed fast wind. (Bottom) Comparison between Xu & Borovsky (2015) classification. In this case, the Xu and Borovsky classification better matches the ICMEs. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.