| Issue |
A&A
Volume 703, November 2025
|
|
|---|---|---|
| Article Number | A95 | |
| Number of page(s) | 9 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202556839 | |
| Published online | 06 November 2025 | |
A photometric classifier for tidal disruption events in Rubin LSST
Institute of Physics of the Czech Academy of Sciences,
Praha,
Czech Republic
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
12
August
2025
Accepted:
3
October
2025
Context. Tidal disruption events (TDEs) are astrophysical phenomena that occur when stars are disrupted by supermassive black holes. The Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST), with its unprecedented depth and cadence, will detect thousands of TDEs, creating the need for robust photometric classifiers capable of efficiently distinguishing these events from other extragalactic transients.
Aims. We developed and validated a machine learning pipeline for photometric TDE identification in LSST-scale datasets. Our classifier is designed to provide high precision and recall, enabling the construction of reliable TDE catalogs for multi-messenger follow-up and statistical studies.
Methods. Using the second Extended LSST Astronomical Time Series Classification Challenge (ELAsTiCC2) dataset, we fit Gaussian processes (GPs) to light curves for feature extraction (e.g., color, rise and fade times, and GP length scales). We then trained and tuned boosted decision-tree models (XGBoost) with a custom scoring function that emphasizes the high-precision recovery of TDEs. Our pipeline was tested on diverse simulations of transient and variable events, including supernovae, active galactic nuclei, and superluminous supernovae.
Results. We achieve high precision (up to 95%) while maintaining competitive recall (about 72%) for TDEs, with minimal contamination from non-TDE classes. Key predictive features include post-peak colors and GP hyperparameters that reflect the characteristic timescales and spectral behaviors of TDEs.
Conclusions. Our photometric classifier provides a practical and scalable approach to identifying TDEs in forthcoming LSST data. By capturing essential color and temporal properties through GP-based feature extraction, it enables the efficient construction of clean TDE candidate samples. Future refinements will incorporate real data and additional features (e.g., photometric redshifts), further enhancing the reliability and scientific impact of this classification framework.
Key words: methods: data analysis / surveys
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Tidal disruption events (TDEs) occur when stars venture close to supermassive black holes (SMBHs) in the center of galaxies, resulting in the disintegration of stars as their self-gravity is overwhelmed by the tidal forces of SMBHs. Consequently, the disrupted stellar debris is flung around the SMBH, and some fraction of it, depending on the type of disruption, remains bound and eventually circularizes to form an accretion disk; the rest escapes the gravitational field of the SMBH (Rees 1988; Evans & Kochanek 1989). The emanating radiation spans the entire electromagnetic spectrum, although there are still ongoing discussions about the exact physical mechanisms involved (see Gezari 2021 for a recent review of TDEs). These cataclysmic events are not only scientifically rich in their own right but also serve as potential accelerators of ultra-high-energy cosmic rays (Piran & Beniamini 2023; Biehl et al. 2018; Farrar & Piran 2014) and sources of high-energy neutrinos (Stein et al. 2021; Yuan et al. 2024; van Velzen et al. 2024). Currently, only around 100 to 150 TDEs have been discovered, primarily in optical surveys, and expanding that sample will be crucial for revealing additional multi-messenger correlations and potentially shedding light on the origins of some ultra-high-energy cosmic rays and high-energy neutrinos.
The Vera C. Rubin Observatory (hereafter Rubin) and its Legacy Survey of Space and Time (LSST) is poised to revolutionize transient astronomy with its unprecedented depth and cadence. Rubin is slated to begin operations and have first light in 20251. It will have a wide-field telescope with an 8.4 meter mirror and six photometric filters. LSST will be a 10-year-long survey, and each year its vast data volume will enable the discovery and monitoring of thousands of TDEs (Bricman & Gomboc 2020), offering a unique opportunity to study their properties and statistical distribution in detail. However, the sheer volume of data and lack of spectroscopy necessitates the development of efficient and accurate classification algorithms to distinguish TDEs from other extragalactic transient events, such as supernovae (SNe) and active galactic nuclei (AGNs).
Many classifiers based on machine learning (ML) algorithms are already in use and play a crucial role in identifying optical transients (Villar et al. 2020; Hosseinzadeh et al. 2020; Sheng et al. 2023). While there are existing ML classifiers designed to categorize TDEs using real Zwicky Transient Facility (ZTF) data and host-galaxy information (Stein et al. 2024; Gomez et al. 2023; Sheng et al. 2023), none have been specifically trained to recognize TDEs using the most recent simulated LSST-like data.
In this paper we introduce a novel photometric classifier specifically tailored to identify TDEs in LSST data using only light-curve information, i.e., without needing spectroscopic confirmation, host-galaxy associations, or redshifts. By leveraging ML techniques on simulated datasets, and using only photometry, our approach aims to significantly improve TDE detection rates and facilitate the construction of robust TDE catalogs for astrophysical and multi-messenger investigations. The code is available on GitHub2. In Sect. 2 we describe the dataset used for our analysis. Section 3 details the light-curve fitting and feature extraction procedures, which is followed by an examination of feature distributions and correlations in Sect. 4. We present our classifier architecture and report its performance metrics in Sect. 5. Finally, Sect. 6 discusses the implications of our results, and Sect. 7 offers concluding remarks.
2 Dataset
In anticipation of the Rubin LSST, several large-scale simulation efforts (for, e.g., CosmoDC2; Korytov et al. 2019) have been initiated to provide realistic light curves for a variety of transient and variable objects. These simulations aim to mirror LSST’s planned cadence, photometric depths, and noise characteristics, thereby allowing researchers to develop and test ML classifiers under conditions that closely approximate future survey data.
One of the most comprehensive such efforts is the Extended LSST Astronomical Time Series Classification Challenge (ELAsTiCC), organized by the LSST Dark Energy Science Collaboration (DESC)3. The primary goal of ELAsTiCC is to create synthetic datasets with accurate astrophysical diversity and realistic observational effects, enabling the community to develop, benchmark, and refine algorithms for transient classification well in advance of LSST operations. Building on the success of the Photometric LSST Astronomical Time-series Classification Challenge (PLAsTiCC; Kessler et al. 2019), ELAsTiCC incorporates updated survey strategies, enhanced modeling of various transient populations, realistic host galaxy associations and probabilistic photometric redshifts.
For this work, we focused on the second release of ELAsTiCC (dubbed ELAsTiCC2), which provides an even more advanced simulation of extragalactic transients. In Sect. 2.1, we outline how we extracted and preprocessed the subset of ELAsTiCC2 data relevant for our TDE classifier, along with the specific transient classes that pose the greatest risk of contaminating a TDE candidate sample.
2.1 ELAsTiCC2
ELAsTiCC2 is a simulation of transients observed by LSST under realistic observing conditions. ELAsTiCC2 uses a more current baseline 3.2 LSST cadence over 3 years, including a rolling cadence in years 2–3 and including deep drilling fields. For ELAsTiCC2, light curves for 4.1 million transient and variable objects were simulated, yielding 62 million detections and 990 million forced photometry points. The ELAsTiCC2 photometry provided is as observed; we did not de-redden the light curves. For deployment on real LSST data, we plan to mitigate Galactic contamination using: (i) a Gaia parallax and/or proper–motion veto; (ii) a nuclear–offset prior once a host is associated; (iii) a Galactic–latitude mask (e.g., exclude |b| ≲ 10°−15°); and (iv) simple variability-timescale rules to suppress rapid stellar variables. In addition, Rubin LSST Data Release 1 (DR1) will provide photometric redshifts and star–galaxy separation scores that can be used as early checks before our Gaussian process+XGBoost model. To train and test our classifier, in addition to the TDEs themselves, we used only the extragalactic models (and subclasses within) that are most likely to be TDE impostors: AGNs, superluminous supernovae (SLSNe), and SNe of various types (Ia, Iax, Ib, Ic, Ic-BL, IIb, and IIn).
Objects before and after quality cuts and the retention fraction.
2.2 TDE simulation and modeling
ELAsTiCC2 employs the Modular Open Source Fitter for Transients (MOSFiT) TDE model to generate realistic light curves. These models are based on hydrodynamical simulations from Guillochon & Ramirez-Ruiz (2013) and Mockler et al. (2019), which simulate the disruption of stars by SMBHs. Using 11 real TDE light curves as a basis, the MOSFiT model parameters were fitted to generate 745 spectral energy distributions. Using these spectral energy distributions, thousands of TDE light curves were created with the SuperNova ANAlysis (SNANA) software (Kessler et al. 2009), ensuring a diverse and comprehensive training set. A more detailed description of the model of sources is given in Kessler et al. (2019) and references therein. The simulated TDEs incorporate known volumetric rates and redshift dependences to reflect the expected distribution in the universe. However, the model is limited by the relatively low number of fitted TDEs, which may result in less accurate representation of diversity and demographics within the TDE population. Notably, newer TDEs found in literature, such as those with double peaks, pre-peak bumps, late-time plateaus, or re-brightening, are not included in the simulated TDE model in ELAsTiCC2.
3 Light-curve fitting and feature extraction
3.1 Light-curve quality cut
To ensure a bare minimum data quality, we required that each light curve have at least three observations in any photometric band with a signal-to-noise ratio greater than 5 and a calibrated flux exceeding 100, corresponding to approximately 22.5 mag. These cuts help filter out noisy and unreliable light curves, thereby enhancing the robustness of the classifier. The initial and quality-cut counts and the population of the remaining sources are shown in Table 1 and Fig. 1, respectively.
3.2 Fitting light curves with Gaussian processes
Gaussian processes (GPs) provide a flexible and probabilistic approach to modeling light curves (see Aigrain & Foreman-Mackey 2023). They are nonparametric and, hence, can be trained also on exotic TDEs (those exhibiting double peaks, prepeak bumps, late-time plateaus, re-brightening, etc.) and other potential subtypes that may not have been discovered yet. By fitting GPs to the photometric data, we can extract features such as variability timescales, color, rise and fade times, and color evolution. These features can then serve as inputs to the classifier, enabling it to distinguish TDEs from other transient phenomena based on their unique photometric signatures. Our implementation of GP follows Boone (2019). We began by fitting the light curves of all object types with GP using the George package (Ambikasaran et al. 2015). After experimenting with several kernels available in George, we settled on a 2D Matérn-3/2 kernel (initialized with 100 days and 6000 Å) for amplitude (flux), time length scale, and wavelength length scale parameters on a perobject basis. While no explicit bounds for the hyperparameters were enforced, we used an optimizer that retries up to 3 times with small perturbations and chooses the best result. This kernel proved effective for fitting TDE-like light curves. We used the central values of each LSST band as effective wavelengths and optimized the fit via the minimize function from scipy, which uses the Broyden–Fletcher–Goldfarb–Shanno optimization algorithm. Using a kernel in both time and wavelength allows the GP to leverage cross-band information to interpolate a light curve even when it is poorly sampled in any given band. An example of a fit is shown in Fig. 2, where the u band has no observation before the peak, yet the GP, using cross-band information, predicts the light curve reasonably well.
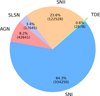 |
Fig. 1 Sample population after the light-curve quality cut. Of the remaining objects, 2878 (0.6%) are TDEs. |
 |
Fig. 2 Example light curve with a GP fit. We show the rise and fade times as well as the pre- and post-peak g − r color within the rise and fade times. |
3.3 Feature extraction
Tidal disruption events in the literature have certain known characteristics that help distinguish them from other transients such as AGNs and SNe. These include their bluer color, minimal color evolution, and longer rise and fade timescales. Hence, we extracted the following features:
Rise and fade timescale: Drop of 1 mag on either side of the GP-estimated g-peak.
Weighted mean color g − r and r − i: Minimum of one observation within rise and fade times for pre- and post-peak color, respectively (using g-peak for g − r, r-peak for r − i).
Weighted color evolution: Slope of a fitted line to at least two observations in g − r and r − i within the rise and fade times, for pre- and post-peak color, respectively.
GP hyperparameters: Amplitude, length scale in time, and length scale in wavelength.
Although all six LSST bands are fit with GP, we focused on the three most frequently observed bands (g, r, and i) for feature extraction. First, to empirically estimate timescales, we identified the g- and r-band peaks based on the GP-estimated maximum flux, then measured the rise and fade timescales in the g band, where brightness decreases by one magnitude (≈40% of the original flux) on either side of the peak. While this approach is conceptually similar to Hammerstein et al. (2023) our implementation relies on GP interpolation rather than fitting a line between just two adjacent points. Choosing 1 magnitude to measure the timescales proved to be a robust and stable method as the part around the peak of the light curve is usually better defined than near the baseline. Second, using the g-peak for g − r and the r-peak for r − i, we computed pre- and post-peak g − r (and r − i) within the corresponding rise and fade times, where at least one observation in either g or r (and r or i) is present. For instance, if there is an observation in g but not r, the GP curve provides an interpolated flux in r. Figure 2 illustrates this scenario, where an observation in r exists near the peak, but none in g; nonetheless, we still determined g − r via the GP prediction. Third, to quantify color evolution, we fit a line to the g − r (and r − i) measurements (requiring at least two points) for both the rise and fade intervals, weighting each data point by its uncertainty. Finally, we extracted the three GP hyperparameters – amplitude, time, and wavelength length scales – leading to a total of 13 features per light curve. The GP fitting procedure and feature extraction is relatively swift in practice and takes about 0.2 seconds per object with parallelization on a 16-core CPU.
3.4 Success rate
Up to this point, we did not discard any objects. After fitting all objects of various types that passed the light-curve quality cut, we calculated the success rate of extracted features, as shown in Fig. 3. As expected, the GP hyperparameters are successfully calculated for all objects. For TDEs, the fade time was computed for nearly all objects, largely because we extended the GP predictions manually after the peak. About 40% of TDEs had all features successfully extracted. For the remaining TDEs, some or all of the features could not be extracted, predominantly pre-peak features and slopes, due to low number of data points (a minimum of two points are needed within the rise and fade timescales, as detailed in Sect. 3.3).
4 Feature distributions and correlations
The extracted features provide strong discriminatory power for classifying TDEs against other extragalactic transients such as SNe, AGNs, and SLSNe. We focused on color metrics (mean post-peak g-r and r-i), color slopes (rate of (g-r) or (r-i) change), and GP hyperparameters LengthScale_Time and LengthScale_Wavelength, along with rise and fade times. This section highlights a few illustrative 2D projections and a correlation matrix. Histograms of all extracted features are given in Appendix A.
Figure 4 shows that TDEs (blue points) have smaller mean post-peak g-r values and lower (g-r) color-evolution rates compared to other transient classes. AGNs (yellow) often cluster around near-zero evolution but vary widely in mean g-r, while SNe (red for SNe I and green for SNe II) are scattered across a broader range of g-r color. The broad clump of SLSNe (purple) indicates more extreme color and evolution values.
In Fig. 5, we plot two key GP hyperparameters: LengthScale_Time and LengthScale_Wavelength. TDEs typically occupy intermediate values for both parameters, aligning with their characteristic timescales and gradual color changes. By contrast, some SN subtypes can display distinctly larger (or smaller) LengthScale_Time due to rapid declines post-peak or faster color evolution. AGNs particularly stand out, as they are known to exhibit high variability both in time and wavelength.
Figure 6 illustrates a color–color diagram, showing the relationship between mean post-peak g-r and r-i, along with marginal distributions projected on the top and right axes. TDEs cluster toward bluer g-r and r-i, while AGNs exhibit extended tails in g-r. SNe I and SNe II partially overlap in color space but deviate distinctly from TDE-like blue colors.
Finally, Fig. 7 presents a correlation matrix for the main features. Key observations include the strong interdependence of color features, reflecting the overall spectral evolution of the transients. Likewise, rise and fade times exhibit moderate correlations with the GP LengthScale_Time, consistent with physically longer timescales leading to broader or slower light-curve variations.
Collectively, these 2D projections and the correlation matrix highlight the photometric diversity among transients, demonstrating how our selected features help separate TDEs from other classes in the parameter space used for classification.
 |
Fig. 3 Success rate of feature extraction for TDEs and non-TDEs. |
 |
Fig. 4 Scatter plot of the mean post-peak g-r (horizontal axis) vs. its rate of change (vertical axis), illustrating how TDEs (blue crosses) tend to cluster around smaller color values and lower color evolution rates, in contrast to other transient classes. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
 |
Fig. 5 2D distribution of the GP hyperparameters LengthScale_Time (vertical axis) vs. LengthScale_Wavelength (horizontal axis), showing how each transient class occupies distinct regions in this parameter space. TDEs (blue crosses) and SLSNe (pink diamonds) typically have moderate LengthScale_Time and LengthScale_Wavelength values, reflecting narrower spectral and temporal variations compared to SNe and AGNs. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
5 Classifier architecture and performance
Having processed the light curves of all object types, we fed the extracted features into a ML classifier, including XGBoost (Chen & Guestrin 2016) and random forest from the scikit-learn Python package (Pedregosa et al. 2011). Since we had enough TDEs (2878 TDEs, 517064 non-TDEs), we could split the dataset evenly into a training set and a test set without the need for data augmentation, even though TDEs constitute only 0.6% of the total. With 1439 TDEs and 258 532 non-TDEs in each set, we trained and test our ML classifier. First, we prepared data for the XGBoost model. Any missing data in our 13 features were replaced with a placeholder (e.g., −999) or the mean across the dataset for a given feature. We find that neither choice significantly impacts the classification. Next, to optimize XGBoost, we defined a hyperparameter search space, outlining reasonable ranges and distributions for key parameters (e.g., number of trees, learning rate, and maximum depth). This search space captures the most influential settings in XGBoost, allowing the model to explore configurations that may enhance performance.
Because achieving high precision (or purity) is central to our science goals (i.e., constructing an optical TDE candidate catalog for statistical studies of correlations with other messengers, such as high-energy neutrinos), we set a target precision of 95%. To integrate this requirement, we implemented a custom scoring function that identifies solutions meeting or exceeding this precision threshold, then selects among them the one yielding the highest recall (or completeness). This encourages the classifier to minimize false positives while recovering as many true positives as possible. We performed the hyperparameter search with stratified k-fold cross-validation and a randomized search approach using RandomizedSearchCV from scikit-learn. Stratified splitting ensures each fold has a similar class distribution, enabling fairer comparisons of different settings. Randomized search accelerates tuning by sampling diverse configurations within the predefined ranges of key parameters, striking a balance between computational efficiency and thoroughness. The resulting hyperparameter values are shown in Table 2.
After identifying the best hyperparameters, we applied the optimized XGBoost model to the test set to generate decision scores for the positive (TDE) class. Inspired by Stein et al. (2024), we converted these decision scores into binary class labels by defining decision thresholds for three scenarios: 80% precision (balanced), 95% precision (high-purity), and 95% recall (high-completeness). Figure 8 shows how precision and recall vary with the threshold.
In the balanced case (at least 80% precision), the classifier recovers 81% (1166) of TDEs while correctly classifying 99.9% (258 242) of non-TDEs, with only 0.1% (291) misclassified as TDEs.
 |
Fig. 6 Scatter plot of mean post-peak g-r (horizontal) vs. mean post-peak r-i (vertical), with 1D distributions (histograms) shown along the top and right axes. TDEs (blue crosses) appear bluer than SNe (orange circles and green squares) and SLSNe (pink diamonds), while AGNs (gray triangles) span a broader range of colors. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
 |
Fig. 7 Correlation matrix of the selected features, indicating pairwise Spearman or Pearson correlation coefficients. Warmer colors correspond to higher positive correlations, while cooler colors indicate negative correlations. Notably, Mean_Color_Post_Peak_gr and Mean_Color_Post_Peak_ri show a strong positive correlation, reflecting common color-evolution behavior in TDEs. |
 |
Fig. 8 Precision and recall as a function of classifier threshold. |
6 Discussion
The results presented in this work highlight both the efficacy and flexibility of our photometric classifier for TDEs. By leveraging GP for feature extraction and XGBoost for classification, we achieved high precision and recall on simulated LSST-like data (ELAsTiCC2). Below, we summarize and discuss the key findings, referencing relevant figures that illustrate our conclusions.
Optimized hyperparameter values for the XGBoost model.
 |
Fig. 9 XGB truth-normalized confusion matrices for different thresholds. True classes are on the vertical axis, and predicted classes on the horizontal axis. |
 |
Fig. 10 Relative importance of extracted features calculated by XGB using the gain type. |
6.1 Feature importance and classifier insights
Figure 10 provides a visual summary of feature importance as measured by the XGBoost gain metric. Several observations stand out:
Color-based features dominate: the post-peak colors (g-r) and (r-i) rank at the top, indicating their strong discriminating power. TDEs are known to remain bluer than SNe or AGNs, particularly in the post-peak phase.
GP hyperparameters are influential: features like LengthScale_Wavelength and LengthScale_Time highlight how characteristic timescales and wavelength behaviors effectively differentiate TDEs from other transients.
Color evolution matters: the slope post peak (g-r)/(r-i) distinguishes TDEs from other transients, as the rate of color change per day is minimal for TDEs, especially after peak.
Time-based features are moderate in rank: While rise time and fade time do contribute, the classifier places more emphasis on color information and the GP length scales.
Amplitude is less critical: brightness alone, without color or temporal information, proves insufficient for robustly distinguishing TDEs from other transients, hence its comparatively lower feature importance.
6.2 Threshold tuning and the precision–recall trade-off
We employed a threshold-based classification approach that allows users to select operating points that match their scientific objectives. Figure 8 shows the precision–recall curve as a function of threshold, while Fig. 9 displays confusion matrices for three specific thresholds:
80% precision: At this threshold (≈0.81), we obtain about 81% recall, correctly identifying a substantial fraction of TDEs while only 0.1% of non-TDEs are misclassified.
95% precision: Increasing the threshold to ≈0.98 yields nearly zero contamination by non-TDEs, albeit at a reduced recall of 71.2%. This high-purity setting is suitable for building a TDE catalog with minimal false positives.
95% recall: By aiming to recover nearly all TDEs (about 95.1%), the classifier admits a false-positive rate of 3.4% among non-TDEs. This is ideal when completeness is paramount, potentially guiding spectroscopic or multiwave-length follow-ups.
6.3 Processing efficiency
Our nonparametric GP framework offers a valuable balance between flexibility and performance. Each object requires only about 0.2 seconds for GP fitting and feature extraction with a 16-core CPU. This translates to ≈27 hours of computing time for ≈0.52 million transients in our ELAsTiCC2 post-quality-cut sample. Such efficiency is critical for handling large-scale surveys like the Rubin LSST, which will detect millions of transient events.
6.4 Generalization to other datasets and further improvements
Although our current results rely on simulated data, validating the approach on real photometric observations from the ZTF is a natural next step (Bhardwaj et al., in prep.). Potential discrepancies in real-world noise levels, survey cadences, and systematic effects may require additional refinements. To deal with false positives such as galactic sources, artifacts, or moving objects, we can implement mitigating filters as described in Sect. 2. Moreover, the future availability of photometric redshifts and improved host-galaxy association in LSST data will allow for further enhancements:
Kernel specialization: different GP kernels (or kernel mixtures) specifically tailored to particular TDE subclasses could significantly improve performance.
Augmented feature set: integrating photometric redshift estimates and host-galaxy properties would likely strengthen the classifier’s ability to discriminate TDEs from lower-redshift SNe or higher-redshift AGNs.
Exotic TDEs: engineering new features or modifying the existing ones for complex or outlier light-curve shapes can make the methodology robust against the diversity of TDE populations.
7 Concluding remarks
In summary, our photometric classifier, underpinned by GP-based feature extraction and boosted decision trees, demonstrates high effectiveness in identifying TDEs across a range of precision and recall targets. Its color-driven feature set provides a powerful tool for distinguishing TDEs from a diverse population of extragalactic transients. Figure 11 compares our methods and results with specialized TDE classifiers previously published. With forthcoming refinements for handling exotic TDE subtypes and real survey conditions, this method is well poised for the next generation of optical transient studies; it will likely play a crucial role in multi-messenger astrophysics and in helping us understand SMBH environments through TDE observations.
 |
Fig. 11 Comparison of this work with dedicated TDE classifiers in the literature. |
Acknowledgements
This work was co-funded by the EU and supported by the Czech Ministry of Education, Youth and Sports (project CZ.02.01.01/00/22_008/0004632 – FORTE). We gratefully acknowledge the support of the Institute of Physics of the Czech Academy of Sciences. Computations were carried out in part on the HPC cluster Phoebe, operated by the Central European Institute of Cosmology (CEICO) at the Institute of Physics of the Czech Academy of Sciences. This research made use of the following software packages: jupyter, numpy, matplotlib, astropy, sklearn, pandas, seaborn, george, python, and xgboost.
References
- Aigrain, S., & Foreman-Mackey, D. 2023, Annu. Rev. Astron. Astrophys., 61, 329 [Google Scholar]
- Ambikasaran, S., Foreman-Mackey, D., Greengard, L., Hogg, D. W., & O’Neil, M. 2015, arXiv e-prints [arXiv:1403.6015] [Google Scholar]
- Biehl, D., Boncioli, D., Lunardini, C., & Winter, W. 2018, Sci. Rep., 8, 10828 [NASA ADS] [CrossRef] [Google Scholar]
- Boone, K. 2019, ApJ, 158, 257 [Google Scholar]
- Bricman, K., & Gomboc, A. 2020, ApJ, 890, 73 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (San Francisco California USA: ACM), 785 [Google Scholar]
- Evans, C. R., & Kochanek, C. S. 1989, ApJ, 346, L13 [Google Scholar]
- Farrar, G. R., & Piran, T. 2014, arXiv e-prints [arXiv:1411.0704] [Google Scholar]
- Gezari, S. 2021, ARA&A, 59, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Gomez, S., Villar, V. A., Berger, E., et al. 2023, ApJ, 949, 113 [Google Scholar]
- Guillochon, J., & Ramirez-Ruiz, E. 2013, ApJ, 767, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Hammerstein, E., van Velzen, S., Gezari, S., et al. 2023, ApJ, 942, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Hosseinzadeh, G., Dauphin, F., Villar, V. A., et al. 2020, ApJ, 905, 93 [Google Scholar]
- Kessler, R., Bernstein, J. P., Cinabro, D., et al. 2009, PASP, 121, 1028 [Google Scholar]
- Kessler, R., Narayan, G., Avelino, A., et al. 2019, PASP, 131, 094501 [NASA ADS] [CrossRef] [Google Scholar]
- Korytov, D., Hearin, A., Kovacs, E., et al. 2019, ApJSS, 245, 26 [Google Scholar]
- Mockler, B., Guillochon, J., & Ramirez-Ruiz, E. 2019, ApJ, 872, 151 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Piran, T., & Beniamini, P. 2023, arXiv e-prints [arXiv:2309.15644] [Google Scholar]
- Rees, M. J. 1988, Nature, 333, 523 [Google Scholar]
- Sheng, X., Nicholl, M., Smith, K. W., et al. 2023, arXiv e-prints [arXiv:2312.04968] [Google Scholar]
- Stein, R., van Velzen, S., Kowalski, M., et al. 2021, Nat. Astron., 5, 510 [NASA ADS] [CrossRef] [Google Scholar]
- Stein, R., Mahabal, A., Reusch, S., et al. 2024, ApJ, 965, L14 [Google Scholar]
- van Velzen, S., Stein, R., Gilfanov, M., et al. 2024, MNRAS, 529, 2559 [CrossRef] [Google Scholar]
- Villar, V. A., Hosseinzadeh, G., Berger, E., et al. 2020, ApJ, 905, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, C., Winter, W., & Lunardini, C. 2024, ApJ, 969, 136 [Google Scholar]
Appendix A Feature distributions
Here we present the distribution histograms of the extracted features in a single-column format. This layout allows a detailed examination of how various photometric quantities, such as color and amplitude, are distributed across different classes of objects. By comparing these distributions, we can identify patterns that differentiate TDEs from other extragalactic transients.
 |
Fig. A.1 The visible peak at mean color 0.0 in all the plots is a direct consequence of the GP fit failing (and all predicted light-curve bands converging to one curve) due to noisy or poor-cadence light curves. |
 |
Fig. A.2 Feature distributions for objects that pass the light-curve quality cut. |
Appendix B Random forest results
In addition to XGBoost, we employed a random forest classifier, included in the scikit-learn package (Pedregosa et al. 2011), to compare performance and feature importance across different ensemble methods. The method is similar to that described for XGBoost, with a focus on growing multiple decision trees while randomly sampling both training instances and features to reduce overfitting.
 |
Fig. B.1 Random forest performance and outcomes. Upper left: Precision–recall curve. Upper right: Feature importance. Bottom: Confusion matrices at various thresholds. |
Optimized hyperparameters for the random forest classifier.
All Tables
All Figures
|
Fig. 1 Sample population after the light-curve quality cut. Of the remaining objects, 2878 (0.6%) are TDEs. |
| In the text | |
|
Fig. 2 Example light curve with a GP fit. We show the rise and fade times as well as the pre- and post-peak g − r color within the rise and fade times. |
| In the text | |
|
Fig. 3 Success rate of feature extraction for TDEs and non-TDEs. |
| In the text | |
|
Fig. 4 Scatter plot of the mean post-peak g-r (horizontal axis) vs. its rate of change (vertical axis), illustrating how TDEs (blue crosses) tend to cluster around smaller color values and lower color evolution rates, in contrast to other transient classes. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
| In the text | |
|
Fig. 5 2D distribution of the GP hyperparameters LengthScale_Time (vertical axis) vs. LengthScale_Wavelength (horizontal axis), showing how each transient class occupies distinct regions in this parameter space. TDEs (blue crosses) and SLSNe (pink diamonds) typically have moderate LengthScale_Time and LengthScale_Wavelength values, reflecting narrower spectral and temporal variations compared to SNe and AGNs. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
| In the text | |
|
Fig. 6 Scatter plot of mean post-peak g-r (horizontal) vs. mean post-peak r-i (vertical), with 1D distributions (histograms) shown along the top and right axes. TDEs (blue crosses) appear bluer than SNe (orange circles and green squares) and SLSNe (pink diamonds), while AGNs (gray triangles) span a broader range of colors. Contours denote the 50%, 80%, and 95% highest-density regions of the per-class 2D kernel density estimate. |
| In the text | |
|
Fig. 7 Correlation matrix of the selected features, indicating pairwise Spearman or Pearson correlation coefficients. Warmer colors correspond to higher positive correlations, while cooler colors indicate negative correlations. Notably, Mean_Color_Post_Peak_gr and Mean_Color_Post_Peak_ri show a strong positive correlation, reflecting common color-evolution behavior in TDEs. |
| In the text | |
|
Fig. 8 Precision and recall as a function of classifier threshold. |
| In the text | |
|
Fig. 9 XGB truth-normalized confusion matrices for different thresholds. True classes are on the vertical axis, and predicted classes on the horizontal axis. |
| In the text | |
|
Fig. 10 Relative importance of extracted features calculated by XGB using the gain type. |
| In the text | |
|
Fig. 11 Comparison of this work with dedicated TDE classifiers in the literature. |
| In the text | |
|
Fig. A.1 The visible peak at mean color 0.0 in all the plots is a direct consequence of the GP fit failing (and all predicted light-curve bands converging to one curve) due to noisy or poor-cadence light curves. |
| In the text | |
|
Fig. A.2 Feature distributions for objects that pass the light-curve quality cut. |
| In the text | |
|
Fig. B.1 Random forest performance and outcomes. Upper left: Precision–recall curve. Upper right: Feature importance. Bottom: Confusion matrices at various thresholds. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.