| Issue |
A&A
Volume 704, December 2025
|
|
|---|---|---|
| Article Number | A70 | |
| Number of page(s) | 17 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202555875 | |
| Published online | 01 December 2025 | |
Unsupervised learning for variability detection with Gaia Data Release 3 photometry
The main sequence–white dwarf valley
1
Department of Astrophysics/IMAPP, Radboud University, P.O. Box 9010 6500 GL Nijmegen, The Netherlands
2
Instituut voor Sterrenkunde, KU Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
3
Astrophysics group, Department of Physics, University of Surrey, Guildford GU2 7XH, United Kingdom
4
Departament de Física Quàntica i Astrofísica, Institut de Ciêncies del Cosmos, Universitat de Barcelona, Martí i Franquès 1, E-08028 Barcelona, Spain
5
Department of Astronomy, University of Cape Town, Private Bag X3, Rondebosch 7701, South Africa
6
South African Astronomical Observatory, P.O. Box 9 Observatory 7935, South Africa
7
The Inter-University Institute for Data Intensive Astronomy, University of Cape Town, Private Bag X3, Rondebosch 7701, South Africa
8
Hamburger Sternwarte, University of Hamburg, Gojenbergsweg 112, 21029 Hamburg, Germany
9
Texas Tech University, Department of Physics & Astronomy, Box 41051 79409 Lubbock, TX, USA
10
Max Planck Institute for Astronomy, Königstuhl 17, 69117 Heidelberg, Germany
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
9
June
2025
Accepted:
26
October
2025
Abstract
Context. The unprecedented volume and quality of data from space- and ground-based telescopes present an opportunity for machine learning to identify new classes of variable stars and peculiar systems that may have been overlooked by traditional methods. The region between the main sequence and white-dwarf sequence in the colour-magnitude diagram (CMD) hosts a variety of astrophysically valuable and poorly characterised objects, including hot subdwarfs, pre-white dwarfs, and interacting binaries.
Aims. Extending prior methodological work, this study investigates the potential of the unsupervised learning approach to scale effectively to larger stellar populations, including objects in crowded fields, and without the need for pre-selected catalogues. Specifically, it focuses on 13 405 sources selected from Gaia DR3 and lying in the selected region of the CMD.
Methods. Our methodology incorporates unsupervised clustering techniques based primarily on statistical features extracted from Gaia DR3 epoch photometry. We used the t-distributed stochastic neighbour embedding algorithm to identify variability classes, their subtypes, and spurious variability induced by instrumental effects. Feature importance was evaluated using SHapley Additive exPlanations values to identify the most influential parameters associated with each cluster.
Results. The clustering results revealed distinct groups, including hot subdwarfs, cataclysmic variables (CVs), eclipsing binaries, and objects in crowded fields, such as those in the Andromeda (M31) field. Several potential stellar subtypes also emerged within these clusters, such as pulsating hot subdwarfs exhibiting pure or hybrid (pressure and/or gravity) modes within the HSD cluster. Magnetic CVs and dwarf novae appeared in the CV cluster. Feature evaluation further enabled the identification of a cluster dominated purely by photometric variability, as well as clusters associated with instrumental effects and crowded fields. Notably, objects previously labelled as RR Lyrae were found in an unexpected region of the CMD, potentially due to either unreliable astrometric measurements (e.g. due to binarity) or alternative evolutionary pathways.
Conclusions. This study emphasises the robustness of the proposed method in finding variable objects in a large region of the Gaia CMD, including variable hot subdwarfs and CVs, while demonstrating its efficiency in detecting variability in extended stellar populations. The proposed unsupervised learning framework demonstrates scalability to large datasets and yields promising results in identifying stellar subclasses.
Key words: methods: data analysis / methods: statistical / techniques: photometric / surveys / subdwarfs / stars: variables: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The advent of large-scale time-domain surveys has revolutionised observational astronomy. Ground- and space-based surveys such as the Palomar Transient Factory (PTF; Law et al. 2009), the Zwicky Transient Facility (ZTF; Bellm et al. 2019), the Gaia mission (Gaia Collaboration 2023), and the Transiting Exoplanet Survey Satellite (TESS; Ricker et al. 2015) have produced large volumes of high-cadence photometric and spectroscopic data. These datasets have enabled not only the discovery of new classes of astrophysical transients and variables, such as fast blue optical transients (Drout et al. 2014) and blue large-amplitude pulsators (BLAPs; Macfarlane et al. 2015; Pietrukowicz et al. 2017), but also the robust statistical characterisation of previously under-represented or poorly understood stellar populations, including hot subdwarfs and pre-white dwarfs (Heber 2016; Geier et al. 2017; Eyer et al. 2023), EL CVn systems (van Roestel et al. 2018), and detached double white dwarf binaries (Burdge et al. 2019, 2020). Additionally, recently developed and forthcoming facilities such as BlackGEM (Groot et al. 2024), the Vera Rubin Observatory’s Legacy Survey of Space and Time (VRO/LSST; Ivezić et al. 2019), and the PLAnetary Transits and Oscillations of Stars (PLATO; Rauer et al. 2025) mission will continue to produce large datasets and thereby increase the probability of discovering new classes of astronomical objects.
In order to efficiently extract scientifically meaningful patterns from these large datasets, the astronomical community has increasingly adopted machine learning (ML) and deep learning (DL) methods. These techniques have become particularly prominent in the automated detection, classification, and clustering of variable stars, supernovae, and other transient phenomena (e.g. Bloom et al. 2012; Villar et al. 2020; Pantoja et al. 2022; Ranaivomanana et al. 2025). Supervised learning methods have been widely used to classify known types of variability, often relying on labelled training sets constructed from light curve morphology or statistical parameters (Debosscher et al. 2007; Blomme et al. 2011; Richards et al. 2011; Aguirre et al. 2019). However, supervised methods are limited by the availability of these training datasets and may fail to identify novel or rare types of variability.
To address this limitation, unsupervised ML approaches, particularly dimensionality reduction and clustering algorithms, are used to reveal hidden structure or patterns, as well as peculiarities in the data without relying on labelled training sets (van der Maaten & Hinton 2008; Jolliffe & Cadima 2016). Among these, t-distributed stochastic neighbour embedding (t-SNE; van der Maaten & Hinton 2008) and the uniform manifold approximation and projection (UMAP; McInnes et al. 2018) have proven powerful for visualising high-dimensional data in a lower-dimensional space, revealing latent structures and relationships that are not immediately obvious in raw data. In astronomy, both algorithms have been applied successfully in a variety of contexts, including gamma-ray burst classification (Jespersen et al. 2020; Zhu et al. 2024), finding white dwarfs’ hidden companions (Pérez-Couto et al. 2025), and the classification of eclipsing binaries (Kochoska et al. 2017).
This work extends our previous study, in which we developed an unsupervised ML framework based on t-SNE for detecting photometric variability in hot subdwarfs observed with Gaia DR3 multi-epoch photometry (Ranaivomanana et al. 2025, hereafter Paper I). In Paper I, our analysis was limited to 1576 objects pre-selected from a catalogue of hot subdwarfs compiled by Culpan et al. (2022). In the present study, we broaden the scope to a more diverse stellar population located in the valley between the main sequence and the white dwarf cooling sequence in the colour-magnitude diagram (CMD). This region encompasses a wide variety of stellar types of interest to the understanding of binary evolutionary pathways, including hot subdwarfs, pre-white dwarfs, cataclysmic variables (CVs), and compact binaries, many of which exhibit variability patterns not easily captured by traditional classification methods. As a large fraction of the objects in this transitional region remain poorly studied, identifying and characterising additional sources is essential for understanding their variability and constraining their evolutionary pathways.
Building upon the work presented in Paper I, the primary aim of this study is to demonstrate that our unsupervised learning framework is scalable to larger stellar populations and that it can potentially recover and separate distinct populations across the region between the main sequence and the white-dwarf sequence, without relying on pre-selected catalogues. In contrast to Paper I, which analysed the pre-selected sample of 1576 hot-subdwarf candidates (Culpan et al. 2022), here we apply the same feature-extraction, dimensionality reduction, and clustering techniques, but to a much broader sample of 13 405 objects. This scalability test is important because it demonstrates the method’s robustness when applied to a larger and more diverse dataset.
Additionally, the focus here is on providing a general overview of variability across the dataset rather than analysing individual objects or assessing the completeness of classification catalogues as was the main subject of Paper I. Particular emphasis is given to the evaluation of the performance of statistical features in characterising the identified clusters.
This paper delivers unsupervised ML classification of the variability of the objects between the main-sequence and the white dwarf sequence, while suggesting key statistical features for variability detection that can be generally applied to any photometric observations. In addition, the study highlights the impact of applying data quality cuts on variability classification. The structure of this paper is as follows: In Sect. 2, we describe the data and methods. The clustering results are presented in Sect. 3, while the analysis of data quality cuts is discussed in Sect. 4. Our conclusion and future prospects are provided in Sect. 5
2. Data and methods
Data were collected using publicly available datasets from Gaia DR3 (Gaia Collaboration 2023). The Gaia mission provides photometric data in three main bands: the broadband G (330−1050 nm), the blue passband BP (330−680 nm), and the red passband RP (640−1050 nm). To prepare our data for ML analysis, we followed a structured workflow that integrates target selection, data extraction, and feature extraction. The following sections describe these steps.
2.1. Target selection
To extract the Gaia objects, we selected all sources within 1 kpc to mostly avoid Galactic extinction and reddening. We also required reliable parallax measurements (parallax_over_error > 5) and the availability of Gaia light curves (has_epoch_photometry=’True’), with at least 25 observations in the Gaia G band (num_selected_g_fov > 24), which we considered as the minimum necessary to detect photometric variability (Ranaivomanana et al. 2025; Morales-Rueda et al. 2006). These requirements were implemented in the Gaia astronomical data query language (ADQL) query form1 when we ran the data extraction (see the appendix for the full ADQL query). The query resulted in 2 080 613 objects, where distances in parsecs (pc) were estimated by a simple 1/parallax estimation to compute the absolute G magnitudes, MG. Using a more sophisticated method for distance determination (Bailer-Jones 2015) yielded very small differences due to the (pre-selected) high-quality parallax measurements. In the diagram, our initial sample was drawn from a region between the main-sequence and white-dwarf sequence, as is indicated by the dashed grey line in the right panel of Fig. 1. This was done by making a free selection in the area between the two sequences using the tool for operations on catalogues and tables (TOPCAT, Taylor 2005) software, while avoiding densely populated areas from both sequences2. Since these objects are further processed and classified by a ML algorithm, we could make a free selection in the CMD without the need to rely on traditional colour-selection criteria. As a result, we obtained 18 085 objects between the main sequence and white dwarf sequence, as is shown by the blue data points in the left panel of Fig. 1.
 |
Fig. 1. Colour-magnitude diagrams, with grey background points representing all selected Gaia DR3 sources within 1 kpc. Left panel: Blue points showing the 18 085 initial targets drawn from the grey background sources within the dash-dotted black polygon. The dashed grey polygon marks the region from which the targets in Paper I were selected. Right panel: Identified stellar classes among the 13 405 final targets within the same dash-dotted black polygon, namely hot subdwarfs from Paper I (orange circles), eclipsing binaries from Gaia classification (blue squares), solar-like rotational modulation stars from Gaia classification (brown stars), CVs from Canbay et al. (2023) catalogue (green triangles), and white dwarfs from the SIMBAD database (purple diamonds), and hot subdwarfs from Culpan et al. (2022) catalogue. The dashed grey polygon indicates the freely selected target region. |
Gaia’s epoch photometry provides light curves for objects in the G, BP, and RP bands, with each transit corresponding to a ∼50 s broad G-band exposure, while BP and RP fluxes are obtained simultaneously from low-resolution prism spectrophotometry (Hodgkin et al. 2021; Riello et al. 2021). Gaia light curves in the three Gaia bands were extracted using the astroquery.Gaia Python package (Ginsburg et al. 2019). The value EPOCH_PHOTOMETRY was specified for the retrieval_type parameter in the package when extracting the light curves. Additionally, a light curve quality flag known as reject_by_variability (Holl et al. 2018) was applied to each light curve to exclude epochs rejected by the Gaia variability pipeline. By extracting the light curves of the 18 085 targets and after applying the quality flag to the light curves, we found 13 405 Gaia light curves with more than 25 observations (Morales-Rueda et al. 2006) in the Gaia G, BP, and RP bands. These light curves serve as our final dataset on which the feature extraction and clustering analysis of the Gaia epoch photometry were based. In the following sections, we preprocessed their Gaia light curves for feature extraction.
2.2. Feature extractions
The first stage in the feature extraction involved running a frequency search algorithm on the 13 405 targets to find the dominant frequency in each of the G-, BP-, and RP-band light curves. The frequency search algorithm described in Ranaivomanana et al. (2023, 2025) was used in this work, with a frequency trial range from zero to 360 day−1. In brief, the frequency search approach consists of computing the Lomb-Scargle periodogram (LSP, Lomb 1976; Scargle 1982) and the Lafler-Kinman statistic (Θ, Clarke 2002; Lafler & Kinman 1965), and determining the dominant frequency in the so-called Ψ-periodogram, defined as 2 * LSP/Θ. The next step was to extract statistical and photometric features from the Ψ-periodogram and the light curves. This was done by following the feature extraction steps described in Ranaivomanana et al. (2025), from which a total of 54 features were obtained from the Gaia summary statistics table3, 6 parameters from the Gaia source database, and a set of 24 computed statistical features extracted from the actual light curves, resulting in a total of 84 light curve features. Since the number of observations in the G, BP, and RP bands (N_G, N_BP, N_RP) are already included in the Gaia summary statistics, we did not include them in this work. Thus, we obtained a set of 81 features as input data for the Gaia light-curve clustering.
After the features were extracted from the epoch photometry, a dimensionality reduction algorithm was applied to visualise these features in a 2D feature space and to use domain knowledge to interpret and validate the clustering results. In this work, dimensionality reduction was performed using the t-SNE algorithm as implemented in the openTSNE Python package (Poličar et al. 2021). Compared to the original implementation (van der Maaten & Hinton 2008), openTSNE offers several advantages in terms of scalability and transferability. More precisely, the openTSNE algorithm is computationally efficient over large datasets, and it also enables the embedding of new data into an existing t-SNE space. The latter is its unique feature compared to similar fast algorithms, such as the fast Fourier transform (FFT)-accelerated interpolation-based t-SNE (FIt-SNE) algorithm (Linderman et al. 2019).
2.3. t-SNE optimisation and clustering
Following the steps outlined in Paper I, and summarised in Fig. A.1, feature pairs with Pearson correlation coefficients greater than 0.95 were considered highly correlated. One feature from each pair was removed, resulting in a final set of 66 features. These features were then normalised to have zero mean and unit standard deviation (z-score normalisation) before optimising the t-SNE hyperparameters, namely perplexity and learning rate. The perplexity parameter reflects the effective number of local neighbours considered during similarity computations in t-SNE, while the learning rate determines the step size used in minimising the t-SNE cost function (see van der Maaten & Hinton 2008 for more details). The learning rate was fixed to ‘auto’ while determining the optimal perplexity, which was varied from 30 to 100 in steps of five. For each perplexity value, a gaussian mixture model (GMM) with ten components (n_components = 10), reflecting the number of identified classes and sub-classes in Sect. 3, was used to cluster the resulting t-SNE embeddings. Given the smooth overlaps in the t-SNE embedding, GMM proved to be the most suitable choice: it explicitly models overlapping distributions and provides soft membership probabilities, which are essential when clusters overlap in feature space. Compared to the density-based spatial clustering of applications with noise (DBSCAN, Ester et al. 1996) algorithm that has been applied in similar contexts (e.g. Kochoska et al. 2017), GMM produced more stable and interpretable cluster boundaries and is therefore the more appropriate method for this work.
Clustering performance was evaluated using the silhouette score (Rousseeuw 1987), which evaluates clustering quality by measuring how well each data point fits within its assigned cluster compared to other clusters. As a result, a perplexity value of 70 yielded the highest silhouette score. Regarding the learning rate, setting it to auto produced the highest score compared to other tested values (ranging from 50 to 1000 in steps of 50). Cluster labels from the GMM were used to compute feature importance scores via a random forest model. To enhance clustering performance, the 66 features were ranked based on their importance scores. Using the optimised perplexity and learning rate values, as well as the ranked features, t-SNE was applied using the top 25 to 65 features. The number of features that produced the highest silhouette score was selected to generate the final clustering result shown in Figs. 2a–c, where 51 features were used. Using five-fold cross-validation, the random forest classifier achieved an average accuracy of 0.89 ± 0.01, indicating it captured meaningful patterns. The resulting feature importance scores (Fig. A.2) thus provide a reliable estimate of each feature’s contribution.
 |
Fig. 2. t-SNE embeddings for the original targets (a–c) and the reduced targets with RUWE < 1.4 (d–f). Panels (b) and (e) show the t-SNE visualisations annotated with known classes from various sources: Gaia classifications (legends in the bottom left), SIMBAD (white dwarfs, labelled as WD_SB), Paper I (Hsd_C0, Hsd_C1, CV_C2), and CVs from the literature (CV_Lit). Panel (c) displays cluster labels derived from a Gaussian mixture model, where clusters are labelled according to known object types rather than numerical identifiers. Panel (f) shows the same cluster labels in panel c for the reduced dataset. The SOS and ML annotations in the legends refer to objects classified from the Gaia SOS and ML pipelines, respectively (see also Fig. 3). |
3. Results
To gain a general understanding of what each cluster represents, the 13 505 targets were cross-matched with catalogues of known objects built in Paper I, including hot subdwarfs (Culpan et al. 2022; Ranaivomanana et al. 2025), CVs (Canbay et al. 2023), and objects listed in the SIMBAD database (Ochsenbein et al. 2000). Thus, 223 known hot subdwarfs and 576 known CVs were identified in addition to 140 white dwarfs from SIMBAD. Note that amongst the hot subdwarfs and CVs were objects identified in Paper I referred to as cluster 0 (Hsd_C0, 70 objects) and cluster 1 (Hsd_C1, 286 objects) for candidate and known hot subdwarfs, and cluster 2 (CV_C2, 98 objects) for CVs. As a reminder from Paper I, objects in cluster 0 exhibit clear periodic variability, whereas those in cluster 1 show weak or unclear variability patterns. Since the targets in this work were limited to objects within 1 kpc, only a subset matched those identified in Paper I.
Furthermore, Gaia DR3 provides variability classifications for approximately nine million variable sources produced by ML classifiers (Rimoldini et al. 2023). The resulting classifications are followed by a dedicated pipeline known as specific object study (SOS) to validate individual classes, except for a few SOS pipelines, such as the SOS module for solar-like rotation modulation stars (Distefano et al. 2023) and short-timescale (period < 1 d) variables (Roelens et al. 2018), with candidate selections independent of the ML results (Rimoldini et al. 2023). Using the classifications published by these pipelines, we identified in our sample objects that were previously labelled, including 167 RR Lyrae stars (Clementini et al. 2023), 2874 eclipsing binaries (Mowlavi et al. 2023), 792 short-timescale variables (Rimoldini et al. 2022), 2552 objects in the Gaia Andromeda photometric survey (GAPS, Evans et al. 2023), and 1029 and 1481 solar-like rotation modulation stars from the Gaia SOS pipeline (Distefano et al. 2023) and Gaia ML classification, respectively.
A CMD of the objects with known classifications is shown in Fig. 1. Eclipsing binaries occupy the region between the main sequence and the white dwarf sequence, while validated rotational modulation stars from the Gaia SOS pipeline are located near the main sequence, at the boundary of the target selection. Note that the rotational modulation candidates were selected from the main-sequence region of the CMD using strict selection criteria (see Fig. 1 in Distefano et al. 2023).
3.1. Dimensionality reduction implementation
3.2. t-SNE embeddings
Figure 2 shows the resulting t-SNE embeddings. In sub-panels 2b and 2e, the location of the above known classes are represented by density contour lines. These contours are drawn from Gaussian kernel density estimates using the seaborn4 Python package with the function seaborn.kdeplot. Note that the objects previously labelled as RR Lyrae stars are present everywhere in the t-SNE embeddings, particularly in the eclipsing binary clusters; therefore, they are not shown in Fig. 2 for a better visualisation. However, they are shown in Fig. A.3 in the appendix and discussed further in Sect. 3.4. The short-timescale variables overlap in the t-SNE embeddings with the clusters with the hot subdwarfs, white dwarfs, and CVs, and therefore they are not also shown in Fig. 2 for clarity purpose. The overlap is due to the fact that this class corresponds to objects with fast variability defined as having periods less than 1 day (Roelens et al. 2018), which overlaps mostly with the range of periodicity in the aforementioned three classes. Apart from variables validated by the SOS pipeline, 3483 short-timescale variable candidates and 1481 solar-like rotation modulation stars from the Gaia ML classification (Rimoldini et al. 2023) were found in our sample. These objects are distributed somewhat distinctively in the t-SNE embeddings as shown in Fig. 2, with a few overlaps with those classified from the SOS pipelines: 40 and 12 objects overlap for the short-timescale variables and rotation modulation stars, respectively.
The cross-matched sources allowed us to validate the clustering results shown in Fig. 2, where each cluster generally represents physically meaningful object class. For hot subdwarfs and CV in particular, the results for Hsd_C0, Hsd_C1, and CV_C2 are consistent with the findings in Paper I, where the three classes are distributed distinctively in the t-SNE embeddings. Of the 70 objects originally in Paper I’s Hsd_C0 set that are present in our sample, 61 (87%) lie in cluster EB1 in the current t-SNE embedding, with only seven objects in the CV cluster and two in the hot subdwarf cluster (hereafter the HSD cluster). Conversely, of the 286 objects from Paper I’s Hsd_C1 set, 282 (98.6%) fall in the HSD cluster here. The Paper I CV candidate set (CV_C2) likewise maps predominantly to the CV cluster in this work. These mappings (Fig. 3) demonstrate that the three main clusters identified in Paper I remain distinct when the analysis is performed on a substantially larger and more diverse dataset (13 405 objects), confirming the stability of our unsupervised method.
 |
Fig. 3. Number of known objects per cluster without a RUWE cut (left) and with the RUWE < 1.4 cut applied (right). The x-axis (Cluster) shows the clusters defined in Figs. 2c and 2f, while the y-axis indicates the object types found in each cluster, as described in Table A.1. |
3.3. Feature evaluation
Now that each cluster in the t-SNE embeddings has been identified, it is important to examine which features contribute to assigning an object to a particular cluster. This analysis is especially useful for understanding why objects of the same type may belong to two or more distinct clusters. To evaluate the contribution of each feature to each cluster, the same approach as in previous sections was followed, using the GMM to predict class labels for a specified number of clusters.
Since the number of identified classes is approximately ten, and some classes span multiple clusters, the GMM was fitted with ten components (n_components = 10). The resulting clustering is shown in Fig. 2c, where the ten clusters were renamed based on the predominant type of objects identified in each cluster (see Fig. 3), rather than using the default numeric labels (e.g. Cluster 0 or Cluster 1). For instance, the cluster containing known hot subdwarfs was renamed ‘HSD’ instead of ‘Cluster 0’. Additionally, object types that appear in multiple clusters (e.g. EB) were given additional labels, such as EB1 and EB2. The number of known objects in each cluster is summarised in Fig. 3, which highlights the most prevalent object types per cluster.
The output labels from the GMM were used to fit a random forest model to estimate feature importance scores. Since the goal here is to obtain importance scores for each individual cluster, SHapley Additive exPlanations (SHAP) values (Lundberg & Lee 2017) were used to quantify the contribution of each feature to the random forest predictions. These values measure how much each feature increases or decreases a prediction relative to the average prediction. A summary plot of the first and second most contributing features for each cluster is shown in Fig. 4. The relevance of these features is further supported by kernel density plots in Fig. A.5, stressing their distribution per cluster. To better understand the detected variability periods within each cluster, the period distributions are shown in Fig. 5, revealing three main distributions centred on timescales of minutes, hours, and days in the Gaia G band. The majority of the clusters (eight out of ten) exhibit short-period distributions on timescales of minutes. While genuine short-timescale variability may be present in these clusters, a significant fraction could result from aliasing effects, as discussed in Roelens et al. (2018). Similarly, the long-period distribution seen in Fig. 5 may largely be attributed to aliasing frequencies, such as the Gaia precession period at 62.97 days (Lebzelter et al. 2023). On the other hand, the narrow peak around a few hours primarily corresponds to genuine variables, including eclipsing binaries, as described in Sect. 3.3.1.
 |
Fig. 4. SHapley Additive exPlanations (SHAP) values for the most important features in predicting each cluster: The top panel shows the highest-ranked feature, and the bottom panel shows the second-most important. SHAP values are expressed in log-odds units. |
 |
Fig. 5. Gaia G-band period distribution per cluster. |
We now focus on investigating feature importances for each object class, especially those that appear in more than one cluster, including eclipsing binaries, solar-like rotational modulation variables, and short-timescale variables. This analysis aims to help identify the distinguishing characteristics between these clusters.
3.3.1. Eclipsing binaries
The distribution of eclipsing binaries from Gaia classification are shown in Fig. 2b, which are labelled as EB1, EB2, and EB3 in Fig. 2c. The SHAP value outputs in Fig. 4 for these clusters indicate that the features p95_100 and n05 are highly important for predicting EB1. The feature p95_100 represents the 95th percentile of the 100 strongest power values in the periodogram, whereas n05 denotes the number of frequencies whose power Ψ exceeds 0.5 in the normalised periodogram. These features are critical for identifying light curves with clear variability, as demonstrated in Paper I. This is supported by visual inspection of objects in cluster EB1, where 1497 out of 1703 objects show unambiguous variability, mostly consisting of eclipsing binaries.
In contrast, cluster EB2 also contains clearly variable objects, with p95_100 and mad_mag_g_fov being the most important features. However, there are only a few of them since EB2 is contaminated by objects with noisy periodograms. This is demonstrated by the number of peaks above 0.5 of the normalised periodogram (n05), where the 10th and 90th percentile of n05 for EB2 are 17 and 452, respectively, while these values are 2 and 40 for EB1, respectively. This suggests a poorly constrained variability for EB2.
Finally, the false alarm probability (FAP) contributes the most to the prediction of EB3, where more than 80% of objects in EB3 have FAP values above 0.6. The variability observed in EB3 is likely associated with aliasing frequencies, indicating less reliable or spurious variability signatures.
3.3.2. Short-timescale variables
This category contains two clusters, namely STS1 (1333 objects) and STS2 (1688 objects). Firstly, the prediction for cluster STS1 is mainly driven by the FAP feature and skewness in the G band (skewness_mag_g_fov). The SHAP values for the two parameters are approximately the same as seen in Fig. 4, suggesting that they have similar impact in the model prediction. Although the majority (80%) of cluster STS1’s FAP values are below 0.1 with a median value of detected periods of 9 min, the FAP values may not reflect the period significance of such high-frequency variables (VanderPlas 2018). Visual inspection shows that the STS1 cluster contains mostly noisy periodograms, most likely due to the sparsity of the Gaia sampling. Further observations would be required to confirm the variability in STS1. Regarding the skewness parameter, about 75% of the objects in STS1 have negative skewness, which may suggest that their variability is likely caused by flaring events if only a few bright events are captured among mostly quiescent observations. However, this could be a result of selection effects since short-timescale variable candidates described in Rimoldini et al. (2023) have a good balance between negative and positive skewness values, where candidates are selected in such a way that −1.4 < skewness_mag_g_fov < 4.
Objects in STS2 are characterised by high re-normalised unit weight error (RUWE, Lindegren 2018) values, where the majority (90%) of the objects have RUWE > 2.6. Compared to the overall population, objects in STS2 have higher parallax error with a median of 0.42 mas, while the median value for all the objects is 0.23 mas (excluding STS2). These objects could present rapid variability candidates in crowded fields or merely unresolved binary systems.
3.3.3. Solar-like rotational modulation
This class of objects is divided into two clusters: solar-like rotational modulation 1 and 2, referred to as ROT1 and ROT2, respectively, as shown in Fig. 2. The ROT1 cluster exhibits a stronger negative skewness in the RP band compared to the G band, with 90% of its members having negative skewness values. These objects exhibit occasional bright outliers in their RP band light curves, most likely due to instrumental artefacts, contributing to the more negatively skewed distribution. Similarly, the kurtosis pattern in the RP band for ROT1 may also result from the bright outliers. On the other hand, ROT2 is characterised by lower Abbe values, with abbe_mag_g_fov centred around 0.5, and a higher number of observations in the G band, with a median of 71 observations compared to 45 for the full sample. The lower Abbe values in ROT2 could indicate light curves with trends, pulsations, or transient events (Mowlavi 2014; Roelens et al. 2018). The increased Gaia sampling for ROT2 is likely a result of the Gaia scanning law (Rimoldini et al. 2023). Additionally, the Gaia SOS rotation modulation selection requires segmentation of long-term, densely sampled time-series data (Distefano et al. 2016, 2023), which contain more observations than are typical for Gaia sources. This selection effect leads to an increased number of identified observations and may also influence the Abbe value.
3.3.4. Hot subdwarfs
The SHAP values for the HSD cluster suggest that the Gaia G-band absolute magnitude and BP−RP colour are the primary features driving their classification. These two parameters are known to characterise hot subdwarfs in the CMD, confirming the robustness of the SHAP value analysis in identifying the most relevant features for each class. Moreover, the HSD cluster is the least contaminated, containing the majority (46 out of 50) of known pulsating hot subdwarfs (Uzundag et al. 2024). This cluster includes promising candidates for identifying pulsating hot subdwarfs through multiple observational campaigns. The variability of all objects in the HSD cluster has been studied in detail by Ranaivomanana et al. (2025), except for ten objects not included in their hot subdwarf training set from Culpan et al. (2022).
Furthermore, a close view of the t-SNE embedding for the HSD cluster reveals two sub-clusters in the left panel of Fig. 6, where pulsating hot subdwarfs from the literature (Baran et al. 2024; Krzesinski & Balona 2022) have been identified. Sub-cluster 0 of the HSD cluster contains pure pressure (p) and gravity (g) mode pulsating hot subdwarfs, while sub-cluster 1 includes both p- and g-mode pulsators, as well as hybrid (p+g) mode pulsators and g-mode pulsators in binary systems. Since the number of objects with known pulsation modes in both sub-clusters is not statistically significant, it is not yet conclusive whether these two sub-clusters represent hybrid and pure pulsators, respectively. We therefore present these as promising indications that merit confirmation with larger samples or targeted spectroscopy, but we do not claim definitive subclass classification here. Additionally, both sub-clusters contain objects with low photometric amplitude variations, with median values of 7 mmag and 8 mmag for sub-cluster 0 and sub-cluster 1, respectively. As is demonstrated in Ranaivomanana et al. (2025), these amplitudes are too small to allow for detection of clear variability in Gaia.
 |
Fig. 6. Close-up view of the t-SNE embeddings for HSD (left panel) and CV (right panel) clusters. Left panel: HSD sub-clusters 0 and 1 represent the cluster HSD in Fig. 2c, where p-mode hot subdwarfs were identified from Baran et al. (2024), while the other modes (g, p+g, g mode + binary) were taken from (Krzesinski & Balona 2022). Right panel: Magnetic CVs (mCVs), non-magnetic CVs (non-mCVs), and dwarf novae (DNs) from Canbay et al. (2023) are shown. |
3.3.5. Cataclysmic variables
Regarding the CV cluster, the stetson_mag_g_fov and the mad_mag_g_fov contribute the most to the prediction of CVs, with Stetson variability index and median absolute deviation median values around 50 (against 3 for the full sample) and 0.28 mag (against 0.04 mag for the full sample), respectively. The values of these two parameters are consistent with the variability nature of CVs, where large-amplitude brightness variations are expected. Moreover, several variants of CVs were observed in the CV cluster, including magnetic CVs (mCVs), non-magnetic CVs (non-mCVs), and dwarf novae (DNs) from Canbay et al. (2023). These sub-classes are highlighted in the second panel of Fig. 6, where mCVs and DNs tend to occupy two sub-clusters. However, non-mCVs are ubiquitous in both sub-clusters.
3.3.6. Objects in the Gaia Andromeda photometric survey
The GAPS sample consists of an early release of epoch photometry of about 1.2 million sources centred on the Andromeda galaxy (M31), with a field radius of 5.5° (Evans et al. 2023). Sources in the GAPS include objects within M31, or the Milky Way that happen to be in the line of sight. As was introduced in Sect. 3, we found 2552 objects to be part of the GAPS survey. Since our initial target selection was limited to objects within 1 kpc, these objects are most likely Galactic objects. Their location in the t-SNE embeddings is shown in Fig. 2b, while the cluster with most known GAPS objects is referred to as GAPS in Fig. 2c. By analysing their SHAP values, these objects are characterised by higher FAP values and low significance of variability (log_sigvar) with median values of 0.2 and 0.35, respectively. These values could indicate weak detection of variability in the GAPS cluster. Since the GAPS survey also largely includes constant stars (Evans et al. 2023), such objects could contribute to the observed low variability significance in this cluster.
3.4. RR Lyrae stars
As was previously mentioned, 167 objects labelled as RR Lyrae stars from the Gaia SOS pipeline (Clementini et al. 2023) were found in our sample. These are located in an unexpected location in the CMD, below the main sequence rather than above it (see Fig. 7). More precisely, they fall within the ranges of GaiaG absolute magnitude 5 < Gabs < 11 and Gaia colour 0 < BP − RP < 2, whereas RR Lyrae stars are typically expected to lie in the approximate range 0 < Gabs < 1 (Garofalo et al. 2022) and 0 < BP − RP < 1 (e.g. Clementini et al. 2023; Lu et al. 2024). Note that applying dust extinction and parallax zero-point offset corrections (Garofalo et al. 2022) has only a minor effect on their positions in the CMD. To understand this misplacement, visual inspections of their light curves were first performed, revealing 67 objects with distinct RR Lyrae-like light curves, while the remaining 100 objects exhibit noisy light curves (e.g. Fig. A.4). Their derived periods and amplitudes from this work are consistent with that of RR Lyrae stars, with a median period and amplitude of 0.47 d and 0.26 mag, respectively. Among the 67 objects, 25 are also classified as RR Lyrae stars in the variable star index (VSX, Watson et al. 2006), excluding VSX classification from Gaia.
 |
Fig. 7. Colour-magnitude diagram of the 67 RR Lyrae stars identified from Gaia classification (blue squares) and the 5/67 objects (red circles) that met RR Lyrae selection criteria described in Iorio & Belokurov (2021). The grey background points representing all selected Gaia DR3 sources within 1 kpc. |
Secondly, the set of 67 objects with verified RR Lyrae-like light curves, amplitudes and periods, were further examined by applying selection criteria described in Iorio & Belokurov (2021) to remove objects with unreliable astrometric measurements and contaminant sources in crowded fields. These criteria are based on the RUWE, the Gaia colour excess factor (phot_bp_rp_excess_factor), and the reddening E(B − V) parameters. As a result of applying all three cuts, only five out of 67 objects remained, while the RUWE criterion alone (RUWE < 1.2) retained 11 out of 67 objects. From their Gaia light curves alone (see Fig. 8), it is not obvious whether these five objects are genuine RR Lyrae stars. Three of them show regular, sinusoidal-like curves and could be eclipsing binary contaminants (e.g. WUMa-type variables), while the other two have periods shorter than expected for RR Lyrae stars and may instead be δ Scuti contaminants (e.g. Fig. 8, sub-panel c) or other types of variables.
 |
Fig. 8. Gaia light curves of five stars labelled as RR Lyrae passing the RR Lyrae selection criteria described in Iorio & Belokurov (2021). (a) Gaia DR3 378807525573579520, (b) Gaia DR3 5086653158769068928, (c) Gaia DR3 5281647899528664320, (d) Gaia DR3 5290302155549350272, (e) Gaia DR3 537040928284437632. |
On the other hand, Fig. 9 shows a sample of five light curves of the objects that did not pass the RR Lyrae selection criteria. These objects exhibit unambiguous RR Lyrae-like (RRab) light curves. However, since these stars were excluded by the three quality cuts, their estimated parallaxes may be systematically biased, and their uncertainties underestimated (e.g. El-Badry 2025). One possible explanation is that these stars are part of unresolved binary systems. This has important implications for alternative RR Lyrae formation channels involving binary evolution (see, e.g. Karczmarek et al. 2017; Bobrick et al. 2024). To date, no RR Lyrae stars have been astrometrically confirmed as binaries (Holl et al. 2023). However, the upcoming Gaia data release DR4 will provide the opportunity to confirm or refute this scenario, both for the 67 RR Lyrae stars identified here and for the RR Lyrae population as a whole (Iorio et al., in prep.). If, instead, the parallax measurements are not significantly affected by astrometric bias, their fainter absolute magnitudes (Gabs > 5 mag) may indicate that these are objects mimicking the RR Lyrae light curve, but with a different intrinsic nature or evolutionary pathway (e.g. Pietrzyński et al. 2012).
 |
Fig. 9. Gaia light curves of five stars labelled as RR Lyrae that did not pass the RR Lyrae selection criteria described in Iorio & Belokurov (2021). (a) Gaia DR3 4107485483951148544, (b) Gaia DR3 4112601610223924480, (c) Gaia DR3 4122378020940824832, (d) Gaia DR3 4161748512969413888, (e) Gaia DR3 4268274211697325312. |
4. Applying data quality cuts
Inspired by the objects that appear as RR Lyrae, and since our initial targets were selected without applying any astrometric quality criteria, except for fractional parallax, we investigate the impact of applying a RUWE cut on the clustering results in this section. Although high RUWE values (e.g. RUWE > 1.4) are potentially indicative of unresolved binary systems, other factors such as crowding and instrumental effects can also contribute to elevated RUWE values (Castro-Ginard et al. 2024). If, instead of our initial unconstrained selection, we apply a cut of RUWE < 1.4, which corresponds to the upper limit of a sky-dependent RUWE threshold (Castro-Ginard et al. 2024), the number of objects in our sample drops to 6443.
This cut significantly affected the number of objects in nearly all clusters, with the exception of the CV and HSD clusters. Notably, the impact was strongest in the second short-timescale variables cluster (STS2), where the number of objects dropped from 1688 to just 34 after applying the RUWE cut. This is consistent with the SHAP value analysis shown in Fig. 4, which indicates that RUWE is a dominant feature for classifying objects in this cluster.
For the cluster containing potential variables (EB1), 833 out of 1703 objects remained after applying the RUWE cut, of which 787 matched with visually confirmed bona fide variables. On the one hand, the RUWE cut improved the purity of the EB1 cluster from approximately 88% (1497/1703 before the cut; see Sect. 3.3.1) to around 95% (787/833 after the cut). On the other hand, it reduced the number of potential variables by nearly 50%.
To evaluate the effect of applying the RUWE cut on the clustering results, the clustering steps described in Sect. 2.3 were repeated using the reduced dataset. Figs. 2d–f show the t-SNE embeddings generated using 46 features. In this new representation, the clusters corresponding to eclipsing binaries, white dwarfs, and hot subdwarfs appear more distinct than in the original embeddings as shown in Figs. 2b and 2e. This improvement could be due to the white dwarf and hot subdwarf classes being previously under-represented relative to the neighbouring eclipsing binary class. As most of the original clusters are now reduced in size due to the RUWE cut, their positions in the new t-SNE projection have shifted slightly, with the short-timescale variable cluster showing the most notable change. Additionally, some contamination is visible across clusters in the new t-SNE embeddings shown in Fig. 2f, where the original cluster labels from Fig. 2c are used. This is because data points that previously had neighbours from the removed data may now be drawn to different nearby points and consequently shifting their location. These observations highlight the sensitivity of t-SNE to sample distribution and emphasise the critical role of sampling in shaping the resulting low-dimensional structures, potentially revealing or obscuring important patterns in the data (van der Maaten & Hinton 2008; Poličar et al. 2021).
5. Conclusion and future prospects
The unsupervised ML framework developed in Paper I was extended in this work to classify Gaia light curves for objects located between the main sequence and the white dwarf sequence. Instead of the 1576 pre-selected targets under scrutiny in Paper I, the current analysis was based on 13 405 objects with at least 25 observations in the Gaia G band located in a much wider region of the Gaia CMD. Following the feature extraction and selection procedures outlined in Paper I, 51 features were selected and used as the basis for the unsupervised clustering using t-SNE. For data treated here, these 51 features yielded better cluster separation in the t-SNE embeddings than the 27 features selected in Paper I.
To assess the integrity of the clusters observed in the t-SNE embeddings and to gain insights into the nature of each cluster, objects with known classifications were overplotted onto the embeddings. This cross-matching helped identify the number of distinct clusters in the t-SNE representation, revealing ten clusters and sub-clusters. This number was used as the input for the GMM to assign objects to their corresponding clusters. The ten clusters were further examined using SHAP values, which highlighted the most important features characterising each cluster. In addition, the clustering analysis was repeated on a reduced dataset of 6443 objects to assess the impact of applying a RUWE cut on the t-SNE clustering and classification results.
Two distinct clusters for known hot subdwarfs and CVs were detected in the t-SNE embeddings, which is consistent with the findings in Paper I. In addition, this analysis helped the identification of a cluster of objects (EB1) with pure photometric variability, including eclipsing binaries, hot subdwarfs, and white dwarfs. Key features for identifying this cluster include the p95_100 and n05 parameters introduced in Paper I. Clusters associated with spurious variability and in crowded fields were also detected (STS1, STS2, GAPS, EB3); these objects typically display slightly different RUWE and FAP distributions.
As for the impact of RUWE filtering on the classification, the results indicate that it can effectively remove spurious or noisy data, revealing under-represented classes, such as white dwarfs and hot subdwarfs. While this cut eliminates many spurious variables, it also discards a significant fraction of potential variables, particularly eclipsing binaries. This is expected, as eclipsing binaries often exhibit high RUWE values, although other factors may also contribute to elevated RUWE. The decision to apply a RUWE cut should therefore be guided by the specific object types of interest. For instance, in the case of hot subdwarfs, a relaxed threshold of RUWE < 7 has been applied by Dawson et al. (2024) to avoid excluding promising candidates.
This work also led to the identification of 67 objects that were classified as RR Lyrae stars in the Gaia SOS pipeline, which exhibit all typical characteristics of RR Lyrae stars, yet are located in an unusual place in the CMD. Analysis of their astrometric parameters and light curves proposed three possible explanations: either their positions in the CMD result from poor astrometric measurements; they represent a different evolutionary channel for RR Lyrae stars; or they represent an evolutionary channel for objects that display features very similar to classical RR Lyrae stars.
The findings of this study suggest several implications. First, the proposed unsupervised ML framework is scalable to large datasets with a rich variety of stellar populations. Second, this approach is not limited to detecting photometric variability; it also aids in identifying instrumental effects and anomalies, which could facilitate faster analysis of large-scale datasets. Third, the results of this study present the possibility of identifying sub classes or intrinsic properties of a given stellar population, such as pulsation modes in hot subdwarfs, based only on statistical parameters. This is particularly valuable for increasing the detection of under-represented classes in population studies. We note that the Gaia classifications and literature-based class labels from literature shown in Fig. 2b are not used as a training set or as ground truth in our analysis. Our embedding (Fig. 2a) is derived in a fully unsupervised manner from light-curve features. The Gaia labels are included only as an external reference to illustrate how broadly defined variability classes are distributed in the embedding. While these classes are known to be imperfect and in some cases biased (see e.g. Rimoldini et al. 2023; Gavras et al. 2023), they remain useful to explore specific Gaia-defined categories in this representation. Since the clustering algorithms used here were designed to embed new data points into existing t-SNE embeddings (Poličar et al. 2021), the framework can accommodate new datasets without the need for retraining. Further research may explore the performance of the proposed ML approach on data from other observations, notably those from ground-based telescopes, such as the BlackGEM telescopes (Groot et al. 2024).
Data availability
The complete version of Table A.2, containing the classifications of the 13 405 targets is available at the CDS via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/704/A70
The TOPCAT expression for the area selection is: isInside(BP–RP, MG, −0.19, 1.96, 1.36, 8.10, 1.91, 9.25, 2.79, 16.07, 1.53, 16.36, −0.22, 9.43, −0.97, 3.02).
Acknowledgments
C.J. acknowledges funding from the Royal Society through the Newton International Fellowship funding scheme (project No. NIF∖R1∖242552). This research was supported by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC 2121 “Quantum Universe” – 390833306. Co-funded by the European Union (ERC, CompactBINARIES, 101078773). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them. The research leading to these results has received funding from the Research Foundation Flanders (FWO) under grant agreement G0A2917N (BlackGEM), as well as from the BELgian federal Science Policy Office (BELSPO) through PRODEX grants for Gaia data exploitation. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/Gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/Gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. PJG is supported by NRF SARChI grant 111692.
References
- Aguirre, C., Pichara, K., & Becker, I. 2019, MNRAS, 482, 5078 [CrossRef] [Google Scholar]
- Bailer-Jones, C. A. L. 2015, PASP, 127, 994 [Google Scholar]
- Baran, A. S., Charpinet, S., Østensen, R. H., et al. 2024, A&A, 686, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, PASP, 131, 018002 [Google Scholar]
- Blomme, J., Sarro, L. M., O’Donovan, F. T., et al. 2011, MNRAS, 418, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Bloom, J. S., Richards, J. W., Nugent, P. E., et al. 2012, PASP, 124, 1175 [Google Scholar]
- Bobrick, A., Iorio, G., Belokurov, V., et al. 2024, MNRAS, 527, 12196 [Google Scholar]
- Burdge, K. B., Fuller, J., Phinney, E. S., et al. 2019, ApJ, 886, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Burdge, K. B., Coughlin, M. W., Fuller, J., et al. 2020, ApJ, 905, L7 [NASA ADS] [CrossRef] [Google Scholar]
- Canbay, R., Bilir, S., Özdönmez, A., & Ak, T. 2023, AJ, 165, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Castro-Ginard, A., Penoyre, Z., Casey, A. R., et al. 2024, A&A, 688, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clarke, D. 2002, A&A, 386, 763 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clementini, G., Ripepi, V., Garofalo, A., et al. 2023, A&A, 674, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Culpan, R., Geier, S., Reindl, N., et al. 2022, A&A, 662, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dawson, H., Geier, S., Heber, U., et al. 2024, A&A, 686, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Debosscher, J., Sarro, L. M., Aerts, C., et al. 2007, A&A, 475, 1159 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Distefano, E., Lanzafame, A. C., Lanza, A. F., Messina, S., & Spada, F. 2016, A&A, 591, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Distefano, E., Lanzafame, A. C., Brugaletta, E., et al. 2023, A&A, 674, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Drout, M. R., Chornock, R., Soderberg, A. M., et al. 2014, ApJ, 794, 23 [Google Scholar]
- El-Badry, K. 2025, Open J. Astrophys., 8, 62 [Google Scholar]
- Ester, M., Kriegel, H. P., Sander, J., & Xu, X. 1996, Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96 (AAAI Press), 226 [Google Scholar]
- Evans, D. W., Eyer, L., Busso, G., et al. 2023, A&A, 674, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eyer, L., Audard, M., Holl, B., et al. 2023, A&A, 674, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garofalo, A., Delgado, H. E., Sarro, L. M., et al. 2022, MNRAS, 513, 788 [NASA ADS] [CrossRef] [Google Scholar]
- Gavras, P., Rimoldini, L., Nienartowicz, K., et al. 2023, A&A, 674, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geier, S., Østensen, R. H., Nemeth, P., et al. 2017, A&A, 600, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ginsburg, A., Sipőcz, B. M., Brasseur, C. E., et al. 2019, AJ, 157, 98 [Google Scholar]
- Groot, P. J., Bloemen, S., Vreeswijk, P. M., et al. 2024, PASP, 136, 115003 [NASA ADS] [CrossRef] [Google Scholar]
- Heber, U. 2016, PASP, 128, 082001 [Google Scholar]
- Hodgkin, S. T., Harrison, D. L., Breedt, E., et al. 2021, A&A, 652, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Holl, B., Audard, M., Nienartowicz, K., et al. 2018, A&A, 618, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Holl, B., Sozzetti, A., Sahlmann, J., et al. 2023, A&A, 674, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Iorio, G., & Belokurov, V. 2021, MNRAS, 502, 5686 [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jespersen, C. K., Severin, J. B., Steinhardt, C. L., et al. 2020, ApJ, 896, L20 [NASA ADS] [CrossRef] [Google Scholar]
- Jolliffe, I. T., & Cadima, J. 2016, Phil. Trans. Roy. Soc. A: Math. Phys. Eng. Sci., 374, 20150202 [Google Scholar]
- Karczmarek, P., Wiktorowicz, G., Iłkiewicz, K., et al. 2017, MNRAS, 466, 2842 [CrossRef] [Google Scholar]
- Kochoska, A., Mowlavi, N., Prša, A., et al. 2017, A&A, 602, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krzesinski, J., & Balona, L. A. 2022, A&A, 663, A45 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lafler, J., & Kinman, T. D. 1965, ApJS, 11, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Law, N. M., Kulkarni, S. R., Dekany, R. G., et al. 2009, PASP, 121, 1395 [NASA ADS] [CrossRef] [Google Scholar]
- Lebzelter, T., Mowlavi, N., Lecoeur-Taibi, I., et al. 2023, A&A, 674, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lindegren, L. 2018, Re-normalising the Astrometric Chi-square in Gaia DR2, GAIA-C3-TN-LU-LL-124 [Google Scholar]
- Linderman, G. C., Rachh, M., Hoskins, J. G., Steinerberger, S., & Kluger, Y. 2019, Nat. Meth., 16, 243 [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [Google Scholar]
- Lu, Y., Mateu, C., & Stanek, K. Z. 2024, ArXiv e-prints [arXiv:2411.02514] [Google Scholar]
- Lundberg, S., & Lee, S. I. 2017, ArXiv e-prints [arXiv:1705.07874] [Google Scholar]
- Macfarlane, S. A., Toma, R., Ramsay, G., et al. 2015, MNRAS, 454, 507 [NASA ADS] [CrossRef] [Google Scholar]
- McInnes, L., Healy, J., & Melville, J. 2018, ArXiv e-prints [arXiv:1802.03426] [Google Scholar]
- Morales-Rueda, L., Groot, P. J., Augusteijn, T., et al. 2006, MNRAS, 371, 1681 [NASA ADS] [CrossRef] [Google Scholar]
- Mowlavi, N. 2014, A&A, 568, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mowlavi, N., Holl, B., Lecoeur-Taïbi, I., et al. 2023, A&A, 674, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pantoja, R., Catelan, M., Pichara, K., & Protopapas, P. 2022, MNRAS, 517, 3660 [Google Scholar]
- Pérez-Couto, X., Manteiga, M., & Villaver, E. 2025, ApJ, 988, 51 [Google Scholar]
- Pietrukowicz, P., Dziembowski, W. A., Latour, M., et al. 2017, Nat. Astron., 1, 0166 [Google Scholar]
- Pietrzyński, G., Thompson, I. B., Gieren, W., et al. 2012, Nature, 484, 75 [CrossRef] [Google Scholar]
- Poličar, P. G., Stražar, M., & Zupan, B. 2021, Mach. Learn., 112, 721 [Google Scholar]
- Ranaivomanana, P., Johnston, C., Groot, P. J., et al. 2023, A&A, 672, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ranaivomanana, P., Uzundag, M., Johnston, C., et al. 2025, A&A, 693, A268 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rauer, H., Aerts, C., Cabrera, J., et al. 2025, Exp. Astron., 59, 26 [Google Scholar]
- Richards, J. W., Starr, D. L., Butler, N. R., et al. 2011, ApJ, 733, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, J. Astron. Telesc. Instrum. Syst., 1, 014003 [Google Scholar]
- Riello, M., De Angeli, F., Evans, D. W., et al. 2021, A&A, 649, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rimoldini, L., Eyer, L., Audard, M., et al. 2022, Gaia DR3 Documentation Chapter 10: Variability, Gaia DR3 Documentation, European Space Agency; Gaia Data Processing and Analysis Consortium. Online at https://gea.esac.esa.int/archive/documentation/GDR3/index.html [Google Scholar]
- Rimoldini, L., Holl, B., Gavras, P., et al. 2023, A&A, 674, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Roelens, M., Eyer, L., Mowlavi, N., et al. 2018, A&A, 620, A197 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rousseeuw, P. J. 1987, J. Comput. Appl. Math., 20, 53 [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Uzundag, M., Krzesinski, J., Pelisoli, I., et al. 2024, A&A, 684, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Maaten, L., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 2579 [Google Scholar]
- van Roestel, J., Kupfer, T., Ruiz-Carmona, R., et al. 2018, MNRAS, 475, 2560 [CrossRef] [Google Scholar]
- VanderPlas, J. T. 2018, ApJS, 236, 16 [Google Scholar]
- Villar, V. A., Hosseinzadeh, G., Berger, E., et al. 2020, ApJ, 905, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Watson, C. L., Henden, A. A., & Price, A. 2006, Soc. Astron. Sci. Annu. Symp., 25, 47 [Google Scholar]
- Zhu, S.-Y., Sun, W.-P., Ma, D.-L., & Zhang, F.-W. 2024, MNRAS, 532, 1434 [Google Scholar]
Appendix A: Additional material
A.1. Gaia ADQL query

A.2. Gaia summary statistic table query

 |
Fig. A.1. Flowchart summarising the dimensionality reduction steps using t-SNE. |
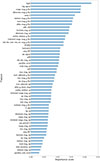 |
Fig. A.2. Random forest feature importance scores for the selected 51 features. |
 |
Fig. A.3. t-SNE embeddings depicting the distribution of RR Lyrae stars classified by Gaia. |
 |
Fig. A.4. Gaia light curves of five stars labelled as RR Lyrae that did not pass the RR Lyrae selection criteria described in Iorio & Belokurov (2021), which exhibit noisy light curves or spurious variability. (a) Gaia DR3 4325299252697361920, (b) Gaia DR3 5850070779543826944, (c) Gaia DR3 6056717633367527552, (d) Gaia DR3 4056072560643550336, (e) Gaia DR3 4042776681999969152. |
Description of the object type labels in Fig. 3.
 |
Fig. A.5. Kernel density estimate (kde) plots for features with high importance scores from SHAP values. |
 |
Fig. A.7. Top ten most important features per cluster. |
List of 13 405 targets with their stellar and variability classifications, along with their t-SNE embeddings.
All Tables
List of 13 405 targets with their stellar and variability classifications, along with their t-SNE embeddings.
All Figures
|
Fig. 1. Colour-magnitude diagrams, with grey background points representing all selected Gaia DR3 sources within 1 kpc. Left panel: Blue points showing the 18 085 initial targets drawn from the grey background sources within the dash-dotted black polygon. The dashed grey polygon marks the region from which the targets in Paper I were selected. Right panel: Identified stellar classes among the 13 405 final targets within the same dash-dotted black polygon, namely hot subdwarfs from Paper I (orange circles), eclipsing binaries from Gaia classification (blue squares), solar-like rotational modulation stars from Gaia classification (brown stars), CVs from Canbay et al. (2023) catalogue (green triangles), and white dwarfs from the SIMBAD database (purple diamonds), and hot subdwarfs from Culpan et al. (2022) catalogue. The dashed grey polygon indicates the freely selected target region. |
| In the text | |
|
Fig. 2. t-SNE embeddings for the original targets (a–c) and the reduced targets with RUWE < 1.4 (d–f). Panels (b) and (e) show the t-SNE visualisations annotated with known classes from various sources: Gaia classifications (legends in the bottom left), SIMBAD (white dwarfs, labelled as WD_SB), Paper I (Hsd_C0, Hsd_C1, CV_C2), and CVs from the literature (CV_Lit). Panel (c) displays cluster labels derived from a Gaussian mixture model, where clusters are labelled according to known object types rather than numerical identifiers. Panel (f) shows the same cluster labels in panel c for the reduced dataset. The SOS and ML annotations in the legends refer to objects classified from the Gaia SOS and ML pipelines, respectively (see also Fig. 3). |
| In the text | |
|
Fig. 3. Number of known objects per cluster without a RUWE cut (left) and with the RUWE < 1.4 cut applied (right). The x-axis (Cluster) shows the clusters defined in Figs. 2c and 2f, while the y-axis indicates the object types found in each cluster, as described in Table A.1. |
| In the text | |
|
Fig. 4. SHapley Additive exPlanations (SHAP) values for the most important features in predicting each cluster: The top panel shows the highest-ranked feature, and the bottom panel shows the second-most important. SHAP values are expressed in log-odds units. |
| In the text | |
|
Fig. 5. Gaia G-band period distribution per cluster. |
| In the text | |
|
Fig. 6. Close-up view of the t-SNE embeddings for HSD (left panel) and CV (right panel) clusters. Left panel: HSD sub-clusters 0 and 1 represent the cluster HSD in Fig. 2c, where p-mode hot subdwarfs were identified from Baran et al. (2024), while the other modes (g, p+g, g mode + binary) were taken from (Krzesinski & Balona 2022). Right panel: Magnetic CVs (mCVs), non-magnetic CVs (non-mCVs), and dwarf novae (DNs) from Canbay et al. (2023) are shown. |
| In the text | |
|
Fig. 7. Colour-magnitude diagram of the 67 RR Lyrae stars identified from Gaia classification (blue squares) and the 5/67 objects (red circles) that met RR Lyrae selection criteria described in Iorio & Belokurov (2021). The grey background points representing all selected Gaia DR3 sources within 1 kpc. |
| In the text | |
|
Fig. 8. Gaia light curves of five stars labelled as RR Lyrae passing the RR Lyrae selection criteria described in Iorio & Belokurov (2021). (a) Gaia DR3 378807525573579520, (b) Gaia DR3 5086653158769068928, (c) Gaia DR3 5281647899528664320, (d) Gaia DR3 5290302155549350272, (e) Gaia DR3 537040928284437632. |
| In the text | |
|
Fig. 9. Gaia light curves of five stars labelled as RR Lyrae that did not pass the RR Lyrae selection criteria described in Iorio & Belokurov (2021). (a) Gaia DR3 4107485483951148544, (b) Gaia DR3 4112601610223924480, (c) Gaia DR3 4122378020940824832, (d) Gaia DR3 4161748512969413888, (e) Gaia DR3 4268274211697325312. |
| In the text | |
|
Fig. A.1. Flowchart summarising the dimensionality reduction steps using t-SNE. |
| In the text | |
|
Fig. A.2. Random forest feature importance scores for the selected 51 features. |
| In the text | |
|
Fig. A.3. t-SNE embeddings depicting the distribution of RR Lyrae stars classified by Gaia. |
| In the text | |
|
Fig. A.4. Gaia light curves of five stars labelled as RR Lyrae that did not pass the RR Lyrae selection criteria described in Iorio & Belokurov (2021), which exhibit noisy light curves or spurious variability. (a) Gaia DR3 4325299252697361920, (b) Gaia DR3 5850070779543826944, (c) Gaia DR3 6056717633367527552, (d) Gaia DR3 4056072560643550336, (e) Gaia DR3 4042776681999969152. |
| In the text | |
|
Fig. A.5. Kernel density estimate (kde) plots for features with high importance scores from SHAP values. |
| In the text | |
 |
Fig. A.6. Colour-magnitude diagram of each cluster shown in Fig. 2c. |
| In the text | |
|
Fig. A.7. Top ten most important features per cluster. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.