| Issue |
A&A
Volume 704, December 2025
|
|
|---|---|---|
| Article Number | A201 | |
| Number of page(s) | 11 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202555898 | |
| Published online | 09 December 2025 | |
Bayesian luminosity function estimation in multi-depth datasets with selection effects: A case study for 3 < z < 5 Lyman α emitters
1
Dipartimento di Fisica “G. Occhialini”, Universitá degli Studi di Milano-Bicocca, Piazza della Scienza 3, 20126 Milano, Italy
2
INAF – Osservatorio Astronomico di Brera, Via Brera 28, I-21021 Milano, Italy
3
INAF – Osservatorio Astronomico di Trieste, Via G. B. Tiepolo 11, I-34143 Trieste, Italy
4
INFN, Sezione di Milano-Bicocca, Piazza della Scienza 3, 20126 Milano, Italy
5
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1, D-85748 Garching bei München, Germany
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
11
June
2025
Accepted:
21
October
2025
Abstract
We present a hierarchical Bayesian framework designed to infer the luminosity function of any class of object by jointly modelling data from multiple surveys with varying depth, completeness, and sky coverage. Our method explicitly accounts for selection effects and measurement uncertainties (e.g. in luminosity) and can be generalized to any extensive quantity, such as mass. We validated the model using mock catalogues; from this we determined that deep data reaching ≳1.5 dex below a characteristic luminosity (L̃★) are essential to reducing biases at the faint end (≲0.1 dex) and that wide-area data help constrain the bright end. As a proof of concept, we considered a combined sample of 1176 Lyman α emitters at redshift 3 < z < 5 drawn from several MUSE surveys, ranging from ultra-deep (≳90 h) and narrow (≲1 arcmin2) fields to shallow (≲5 h) and wide (≳20 arcmin2) fields. With this complete sample, we constrain the luminosity function parameters log(Φ★/Mpc−3) = −2.86−0.17+0.15, log(L★/erg s−1) = 42.72−0.09+0.10, and α = −1.81−0.09+0.09, where the uncertainties represent the 90% credible intervals. These values are in agreement with the results of studies based on gravitational lensing that reach log(L/erg s−1)≈41, although differences in the faint-end slope underscore how systematic errors are starting to dominate. In contrast, wide-area surveys represent the natural extension needed to constrain the brightest Lyman α emitters [log(L/erg s−1)≳43], where statistical uncertainties still dominate.
Key words: methods: data analysis / galaxies: evolution / galaxies: high-redshift / galaxies: luminosity function / mass function
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The luminosity function (LF) is one of the most fundamental statistical descriptors of the properties of a population of astrophysical objects (e.g. Ciardullo et al. 1989; Boyle et al. 2000; Miyaji et al. 2001; Blanton et al. 2003; Kelly & Merloni 2012; Baldry et al. 2012; Ajello et al. 2012; Bouwens et al. 2021). It is largely used in the context of galaxy formation models, providing a census of the evolution – or lack thereof – of galaxy populations across cosmic time. The LF, denoted as Φ(L, z), is defined as the number of sources per unit comoving volume and luminosity interval. Constraining the parameters that shape the LF and characterizing its evolution with redshift are critical steps in studying the changing demographics of galaxies throughout cosmic history (e.g. Richards et al. 2006; Muzzin et al. 2013; Herenz et al. 2019).
A fundamental aspect for an accurate determination and parametrization of the LF, in addition to improved observational techniques and higher-quality datasets, lies in the statistical methodology used to infer its parameters. A robust and flexible formalism is even more critical when catalogues are incomplete due to complex selection functions, which themselves depend on the observational techniques adopted. Different methods have been developed to model the LF and can be broadly categorized into non-parametric and parametric approaches (see Johnston 2011 for a review).
The former includes several binning techniques, most notably the 1/Vmax estimators (Schmidt 1968) and the C− method for deriving the cumulative LF (Lynden-Bell 1971). After binning the sources by luminosity, a procedure that carries the arbitrary choices of bin width and phase, a parametric function – often a Schechter function (Press & Schechter 1974; Schechter 1976) – is typically fitted to the binned data using different optimization techniques. Another parametric approach, known as the maximum likelihood estimator (e.g. Sandage et al. 1979), has the significant advantage of deriving the Schechter function parameters without binning the data, thus preserving the statistical constraining power of the full dataset. However, even this method has limitations and shortcomings: (i) it usually does not directly constrain the LF normalization, but rather only its shape. The normalization is derived by requiring that the expected number of sources matches the number detected in the survey. (ii) It may not properly account for the selection effects introduced by the observations. (iii) It often does not take into account the uncertainties associated with both the luminosities and redshifts of the sources. Finally, (iv) it generally does not allow for the combination of heterogeneous datasets from different surveys with distinct selection functions and sky coverage. Partial attempts to address these limitations include Kelly et al. (2008) for (i), Marshall et al. (1983) and Drake et al. (2017) for (ii), Chen et al. (2003), Kelly et al. (2008), and Mehta et al. (2015) for (iii), and Heyl et al. (1997) for (iv).
In this paper we present a comprehensive analysis strategy that addresses all these limitations at once. Our model is a hierarchical Bayesian framework that we used to estimate the LF parameter; it allows us to combine multiple surveys with an accurate treatment of selection effects and to reconstruct the properties of the parent population, as traced by the observed samples. Specifically, we constructed the likelihood function of the observed data given a set of parameters for an assumed form of the LF, linking the observed quantities to the true, unobservable properties of the sources while explicitly accounting for the survey selection functions. From this, we derived the posterior probability distribution of the LF parameters conditioned on the observed data. We then validated our Bayesian method by generating mock catalogues, both for individual surveys with idealized selection functions and different sky coverage and for combinations of surveys with heterogeneous characteristics.
Although we focus in this work on the problem of estimating the LF of galaxies, we emphasize that this framework is fully general and can be applied to any population of objects described by an observed luminosity, or even generalized to any extensive quantity, such as mass. Furthermore, the model, here explicitly for a Schechter function, can be generalized to any shape by replacing Φ with the desired form.
As a case study, we applied our model to the analysis of high-redshift Lyman α emitters (LAEs), the distribution of which has become a cornerstone in investigations of galaxy formation and evolution, and it traces the large-scale structures in the early Universe (e.g. Ouchi et al. 2020; Leclercq et al. 2020; Fossati et al. 2021; Herrera et al. 2025). The LAE LF has been measured over a wide range of redshifts, from the local Universe up to z ∼ 8, through various observational programmes since their first detections in the late 1990s. Early studies relied primarily on narrow-band (NB) imaging techniques to identify LAEs. Advances in instrumentation at world-class observatories have enabled NB imaging surveys to become an ideal technique for mapping large sky areas, thus providing initial constraints on the bright end of the LF [log(LLyα/erg s−1)≳43]. However, NB imaging studies are limited in terms of depth and the purity of the LAE selection.
These limitations can be overcome by spatially resolved spectroscopic surveys mapping the three-dimensional distribution of LAEs in smaller, but representative, volumes. Thanks to the advent of a new class of integral-field spectrographs, such as the Multi Unit Spectroscopic Explorer (MUSE; Bacon et al. 2010) on the European Southern Observatory’s Very Large Telescope (VLT), it is now possible to perform sensitive and blind searches for emission-line sources in the range 3 ≲ z ≲ 6, enabling a more complete census of spectroscopically confirmed LAEs. During the past decade, several studies with MUSE have constrained the LAE LF down to log(LLyα/erg s−1)≳41.4 (e.g. Drake et al. 2017; Herenz et al. 2019; Fossati et al. 2021). Using the magnification provided by gravitational lensing by massive foreground galaxy clusters, some efforts have also pushed the detection threshold to the very faint end, reaching log(LLyα/erg s−1)≲40 (Thai et al. 2023; de La Vieuville et al. 2019). However, these faint-end constraints of the LF are accompanied by increasing uncertainties due to cosmic variance, small-number statistics, and the dependence on complex lensing models.
In this work we applied our Bayesian model to multiple MUSE surveys, including the two deepest fields currently available: the MUSE Ultra Deep Field (MUDF; Lusso et al. 2019; Fossati et al. 2019) and the MUSE eXtremely Deep Field (MXDF; Bacon et al. 2021, 2023). In addition, we considered the MUSE Analysis of Gas around Galaxies (MAGG; Lofthouse et al. 2020; Fossati et al. 2021) and the MUSE-Wide (MW; Herenz et al. 2019) surveys. From these datasets, we drew a combined sample of 1176 LAEs to constrain the parameters of the Lyα LF over a wide luminosity range (≈2.8 dex) at 3 < z < 5.
The structure of this paper is as follows. Section 2 introduces our hierarchical Bayesian model with the treatment of multiple surveys. Readers interested only in the general formalism will find all relevant information in this section. To validate the method, we used the explicit example of estimating the Lyα LF of LAEs. In Sect. 3 we describe the MUSE datasets and the construction of the observed LAE catalogues, and in Sect. 4 we use mock catalogues that simulate real observational conditions to validate the method. Finally, in Sect. 5 we apply our framework to the real combined MUSE datasets, and we compare our results with the literature. We summarize our conclusions in Sect. 6.
Throughout this paper, we adopt a standard Λ cold dark matter cosmology with Ωm = 0.31 and H0 = 67.7 km s−1 Mpc−1 (Planck Collaboration VI 2020). We use log(⋅) to indicate base-10 logarithms.
2. Hierarchical Bayesian framework for multi-depth surveys
In this section we describe in detail the expanded Bayesian inference formalism we used to model the LF and estimate parameter posteriors, assuming observations characterized by uncertainties on redshift and luminosities and selection biases. This same formalism is discussed by Loredo (2004), Mandel et al. (2019), and Vitale et al. (2022), which we adapted and expanded to our specific case: the study of the LF in multi-depth surveys. The formalism described below applies to multi-dimensional data.
In this Bayesian framework, we considered a population of objects characterized by a set of parameters, θ, that describes their individual properties. Any population of sources characterized by an extensive quantity could be used, but here we chose to make the formalism explicit for the case of galaxies with luminosity and redshift, such that θ = (L, z). The distribution of events within our galaxy population is governed by a set of parameters, λ, such that the number density of objects is given by
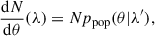 (1)
(1)
where we have separated the parameters λ into the overall normalization factor N (representing the true number of objects in the population, i.e. the number of LAEs in our case) and the subset of parameters λ′ that describes the shape of the population distribution, ppop(θ|λ′).
For galaxies, the LF can be modelled using a Schechter function, parameterized by 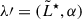 , where
, where 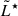 is the characteristic logarithmic luminosity (with typical units of erg s−1), and α is the faint-end slope of the LF,
is the characteristic logarithmic luminosity (with typical units of erg s−1), and α is the faint-end slope of the LF,
![Mathematical equation: $$ \begin{aligned} \Phi (\tilde{L} | \lambda ^{\prime }, \Phi ^\star ) = \ln (10)\Phi ^\star 10^{(\tilde{L}-\tilde{L^\star })(1+\alpha )}\exp {\left[-10^{(\tilde{L}-\tilde{L}^\star )}\right]}, \end{aligned} $$](/articles/aa/full_html/2025/12/aa55898-25/aa55898-25-eq8.gif) (2)
(2)
which denotes the number of sources per comoving volume and per unit log-luminosity, 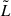 . The parameter Φ★ represents the normalization (usually in Mpc−3), and is related to the total number of LAEs, N, which, by definition, is given by the integral of the LF multiplied by the total comoving volume Vcomtot (see below). Here, we considered an LF that is independent of redshift over the considered interval. In its more general form, however, the LF could vary with redshift and adopt a different functional form.
. The parameter Φ★ represents the normalization (usually in Mpc−3), and is related to the total number of LAEs, N, which, by definition, is given by the integral of the LF multiplied by the total comoving volume Vcomtot (see below). Here, we considered an LF that is independent of redshift over the considered interval. In its more general form, however, the LF could vary with redshift and adopt a different functional form.
The distribution of events in the population is sampled by a set of observations, Nobs, with true parameters {θi}i = 1Nobs. This means that, in reality, we do not know the true value of N, as our survey contains only Nobs galaxies. Because of this, we should also consider N as an additional parameter that needs to be estimated. For each observed galaxy in the population, we obtained an uncertain measurement of its parameters, which is characterized by an associated likelihood function p(θobs|θ) that relates the observed measurements 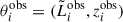 to the true event parameters θi. We assumed a factorized likelihood made of a log-normal distribution for Lobs with standard deviation
to the true event parameters θi. We assumed a factorized likelihood made of a log-normal distribution for Lobs with standard deviation  , and a Dirac δ function for zobs. In symbols, one has
, and a Dirac δ function for zobs. In symbols, one has
 (3)
(3)
The use of a δ function rests on the assumption of a negligible error in the redshift estimate compared to the redshift interval we considered, which is the case with spectroscopically confirmed catalogues.
Crucially, we also had to take the selection effects associated with the observations into account. We could only obtain a sample of galaxies that represents a biased subset of the intrinsic population, as some of them are more challenging or even impossible to detect. Therefore, we had to account for a detection probability Pdet(θ, t), which depends both on the properties of the objects (θ) and on the limiting sensitivity of the survey (a parameter that is not intrinsic to the population). When focusing on flux-based surveys, as in our examples of the LAE LF, we can use the mean exposure time t as a proxy for the survey depth. This probability can be estimated empirically by analysing the noise properties of the survey and performing source injection and recovery experiments (see an example of this implementation in Sect. 3).
In the presence of multiple surveys, Nsurvey, with different mean exposure times tk, we can define a set of selection probabilities {Pdet,k(θ)}k = 1Nsurvey. Empirically, for each survey, we can determine a threshold for the luminosity parameter, corresponding to the luminosity at which the selection function is complete above a certain threshold (for example, 10%), 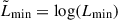 . An associated Ωk, describing the accessible solid angle of the k-th survey, must be specified. Having done so, we are in a position to define a detection statistic that depends solely on the data, making it possible to split the integration domain into two disjoint sets: one corresponding to the data that yield a detection statistic above a predetermined threshold, and its complement (see e.g. Kelly et al. 2008; Taylor & Gerosa 2018; Mandel et al. 2019; Vitale et al. 2022).
. An associated Ωk, describing the accessible solid angle of the k-th survey, must be specified. Having done so, we are in a position to define a detection statistic that depends solely on the data, making it possible to split the integration domain into two disjoint sets: one corresponding to the data that yield a detection statistic above a predetermined threshold, and its complement (see e.g. Kelly et al. 2008; Taylor & Gerosa 2018; Mandel et al. 2019; Vitale et al. 2022).
Our goal is to determine the population properties described by the parameters λ, but we can only rely on a finite and limited set of observations {θiobs} subject to selection biases and measurement uncertainties. Therefore, we compute the posterior probability on λ using Bayes’ theorem
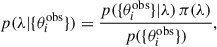 (4)
(4)
where p({θiobs}|λ) is the likelihood of obtaining the observed data given the population parameters, π(λ) is the prior distribution on λ and p({θiobs}) is the evidence.
We follow the bottom-up derivation by Mandel et al. (2019) and assume that each observation is independent. Furthermore, we assume that the generating process of the observed data is an inhomogeneous Poisson process, meaning that the number of galaxies observed in any given region of parameter space (e.g. luminosity and redshift) is a random realization drawn from a Poisson distribution whose expectation value is determined by the underlying function (e.g. LF) that describes the distribution of objects in the population. This statistical model accounts for the discrete nature of galaxy counts (Poisson) and their variation across luminosity and redshift (inhomogeneous), reflecting the expected physical distribution of galaxies in the Universe.
In the following, we refer to each individual survey as the k-th survey, with k = 1, …, Nsurvey, and to each source detected within that survey as ik = 1, …, Nobs, k. When considering the combined sample across all surveys, we denote the ensemble of all observed sources by i = 1, …, Ntot, where we defined 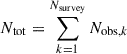 .
.
We then write the likelihood for the k-th survey as
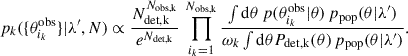 (5)
(5)
The expected number of detections Ndet,k is computed as
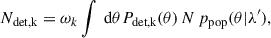 (6)
(6)
where the factor ωk = Ωk/4π accounts for the limited solid angle of the survey. In Eq. (5), by multiplying both the numerator and the denominator inside the product by N, we note that the denominator corresponds exactly to Ndet, k. Bringing this term outside the product results in Ndet, kNobs, k, which cancels with the same factor outside the product.
Considering explicitly our case, Eq. (1) can be expressed as
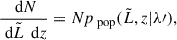 (7)
(7)
where 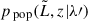 represents the normalized distribution of the galaxy population. By definition, the LF can be expressed as
represents the normalized distribution of the galaxy population. By definition, the LF can be expressed as
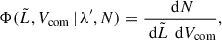 (8)
(8)
i.e. the number of events in the population we expect in the log-luminosity range 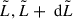 and in the comoving volume range Vcom, Vcom + dVcom. This yields
and in the comoving volume range Vcom, Vcom + dVcom. This yields
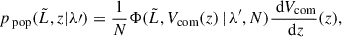 (9)
(9)
where N is, by definition, the total number of sources in the population. In the equations above,
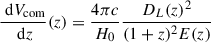 (10)
(10)
is the differential comoving volume, where E(z) contains the cosmology terms, DL(z) is the luminosity distance, c is the speed of light, H0 is the Hubble constant (see Hogg 1999), and we have accounted for the total solid angle 4π. If we assume a simplified version of the LF without explicit dependence on z, as in Eq. (2), we can write 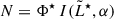 , where we have explicitly factorized Φ★ as a normalization constant (without any z dependence) out of the integral over
, where we have explicitly factorized Φ★ as a normalization constant (without any z dependence) out of the integral over 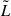 in Eq. (2), with
in Eq. (2), with
![Mathematical equation: $$ \begin{aligned} I(\tilde{L}^\star , \alpha ) = V_\text{com}^\text{tot} \int \text{ d}\tilde{L}\,\ln (10)\,10^{(\tilde{L}-\tilde{L^\star })(1+\alpha )}\exp {\left[-10^{(\tilde{L}-\tilde{L}^\star )}\right]}. \end{aligned} $$](/articles/aa/full_html/2025/12/aa55898-25/aa55898-25-eq26.gif) (11)
(11)
With the simplification we operated on Eq. (5), the likelihood can be written as
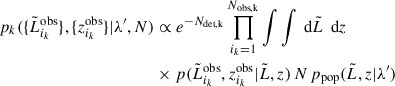 (12)
(12)
with
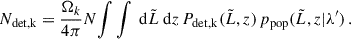 (13)
(13)
Finally, we used the definition in the Eq. (9) and the equivalence between the normalization parameter N and Φ★ described above to express the likelihood in terms of Φ★ instead of N:
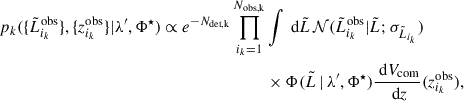 (14)
(14)
where we have also accounted for the Dirac delta in 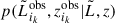 and used
and used
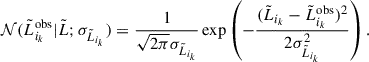 (15)
(15)
The expected number of detected sources in Eq. (13) can be expressed as
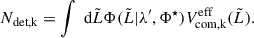 (16)
(16)
Furthermore, 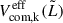 accounts for selection effects and is expressed as
accounts for selection effects and is expressed as
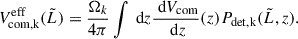 (17)
(17)
It is crucial to note how the selection effects are introduced only in the denominator factor of Eq. (5) (see Loredo 2004) and in the Poissonian term in Eq. (14). Since each survey can be considered independent of the other (they are disjoint in area), the final likelihood can be expressed as the product
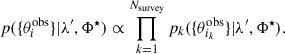 (18)
(18)
We implemented this formalism by using the UltraNest package (Buchner 2021), which is a Python implementation of nested sampling (Skilling 2004). This algorithm efficiently produces posterior samples along with the evidence. As input, the model requires the different catalogues of galaxies from the various surveys, along with the associated selection functions and the area of the sky covered. In our implementation, for the luminosity threshold below which sources are not considered, we adopted the limit at which the selection function reaches 10% completeness, similar to other works in the literature (e.g. de La Vieuville et al. 2019; Fossati et al. 2021). To assess the impact of the chosen threshold, we also applied the model adopting 5% and 20% completeness limits (see Sect. 5).
Having laid out the expanded Bayesian formalism that describes the LF in the presence of multi-depth surveys with uncertainties, we proceeded by validating the method and applying it to a concrete example: the study of the LF for LAEs. In the following section we introduce the main LAE datasets we incorporated in this work. Readers not interested in, or already familiar with, these technical aspects can resume reading from Sect. 4.
3. Observations and sample selection
The LAEs analysed in this paper originate from four different surveys: (i) the MUDF (Lusso et al. 2019; Fossati et al. 2019), (ii) the MXDF (Bacon et al. 2021, 2023), (iii) the MAGG (Lofthouse et al. 2020; Fossati et al. 2021), and (iv) the MW survey (Herenz et al. 2019). The LAE catalogue and the determination of the selection function for the MAGG and MW surveys are presented by Fossati et al. (2021) and Herenz et al. (2019), respectively, and those of the MW survey are publicly available. In this work, we provide a detailed discussion of the construction of the LAE catalogue and the determination of the selection functions for the MUDF survey, and briefly describe the properties of the other samples in the following subsections.
For each dataset, we considered LAEs within the redshift range 3 ≤ z ≤ 5, where the MUSE sensitivity is highest. Applying this selection criterion and the individual luminosity thresholds at which the completeness is 10%, we obtained the final catalogues, which comprise a total of 1176 sources. Their properties are summarized in Table 1.
Main properties of the surveys used in this work.
3.1. The MUDF dataset
The MUDF is a 142-hour VLT/MUSE programme covering an area of approximately 2.1 × 1.9 arcmin2 in a field that hosts two bright quasars at z ≈ 3.22, reaching the highest sensitivity (≳90 h) in the ≈0.55 arcmin2 central region. Details of observations and data reduction are provided by Lusso et al. (2019), Fossati et al. (2019), Tornotti et al. (2025b). In this work, we utilized the full-depth dataset presented by Tornotti et al. (2025b). Specifically, we adopted the final datacube in which the quasar and stars point spread functions and the extended continuum sources have been subtracted using a non-parametric algorithm (e.g. Borisova et al. 2016; Arrigoni Battaia et al. 2019).
The procedure used to detect compact LAEs follows a similar approach to that described in, for example, Lofthouse et al. (2020) and Fossati et al. (2021), and is briefly summarized here. First, we ran the Spectral Highlighting and Identification of Emission (SHINE) code (Fossati & Tornotti 2025), following an approach similar to that by Tornotti et al. (2025a) for the extraction of Lyα extended filamentary emission, but adopting appropriate parameters for compact sources: (i) a signal-to-noise ratio (S/N) threshold per voxel of 3 with spatial Gaussian smoothing kernel of σ = 2 pixels; (ii) a minimum number of 27 connected voxels; (iii) a minimum of 3 spectral channels (i.e. > 3.75 Å) along at least one spatial pixel; and (iv) a group of connected voxels spanning no more than 50 wavelength channels (62.5 Å), to reject residuals from continuum sources.
The candidate line emitters are then classified into two credible levels (1 and 2) based on the integrated signal-to-noise ratio (ISN), corrected for the uncertainty covariance (Lofthouse et al. 2020). Specifically, class 1 includes sources with ISN > 7, ensuring high purity but lower completeness, while class 2 includes sources with 5 < ISN < 7, improving completeness at the expense of purity. To construct a high-purity sample, we consider only class 1 sources hereafter. All candidates are visually inspected by three authors (DT, MF, and MFo) independently. During this process, we also examined the shape of the segmentation map and the extracted spectrum of each emitter to identify possible skyline residuals or other artefacts.
Following this procedure, a total of 212 LAEs have been extracted and confirmed. For each confirmed emitter, the redshift is determined from the peak of the Lyα emission line in the spectrum. In cases where a double-peaked profile is present and no non-resonant line is detected, the red peak is used to assign the redshift. We then estimated the total flux of the Lyα line. LAEs can be decomposed into a bright compact core and a faint, diffuse halo (e.g. Wisotzki et al. 2016; Leclercq et al. 2017). As a result, the flux obtained directly from the segmentation map typically underestimates the total flux, as it misses the faint extended emission in the outskirts of the halos. To this end, we adopted a curve-of-growth (CoG) approach using circular apertures centred on each source (Fossati et al. 2021). We applied this technique to pseudo-NB images, obtained by collapsing the datacube within ±15 Å around the source redshift. The total flux of each object is then defined from the analysis of the cumulative CoG profile. This procedure is performed interactively, by inspecting CoG diagnostic plots to ensure that the measured flux is indeed dominated by the LAE emission. In a few cases, where necessary, we masked artefacts, residuals, or the edges of the field by limiting the apertures or the pseudo-NB accordingly. As a final step, we computed the luminosity from the fluxes using the luminosity distance at the redshift of the LAE within our cosmological model, after correcting for Milky Way dust extinction using the calibrated extinction map by Schlafly & Finkbeiner (2011) and applying the extinction law by Fitzpatrick (1999).
To study the LF of LAEs, we needed to model the selection function of the MUDF, i.e. the probability of detecting a LAE with a given luminosity and redshift in our datacube. To this end, we injected mock sources into the datacube and tested their detectability using the same procedure described above. To better represent the morphological properties of LAEs, we injected observed LAEs (see Herenz et al. 2019; Fossati et al. 2021). Specifically, we selected 11 LAEs with ISN > 25 in the MUDF dataset, spanning the redshift range 3 < z < 5 that is representative of the entire LAE population. For each selected source we extracted a sub-cube of 25 × 25 spatial pixels and 17 spectral pixels (21.25 Å) and normalized the data to the total flux. We used these bright sources as non-parametric and nearly noise-free LAE templates. They were then randomly selected and injected in the real datacube after being rescaled to a random flux value. This approach is the best method for simulating observed LAEs across the full range of fluxes that can be observed in MUSE datacubes. Due to the high ISN, the impact of the residual noise in the sub-cubes used as LAE models is negligible, even when rescaled to high flux levels.
Next, we computed the recovery fraction of the injected sources in bins of redshift and flux. Converting these fluxes into luminosities for each redshift bin yields the final selection function, which is modulated primarily by the MUSE sensitivity and the impact of bright sky emission lines. Since the MUDF exposure map decreases quasi-radially from the central deep region (up to 120 h) towards the edges (≲10 h), we incorporated this spatial dependence into the selection function. During the injection process, we tracked the exposure time at the position of each mock source. In the subsequent analysis, we computed distinct selection functions corresponding to each depth-defined region.
We divided the MUDF field into five regions characterized by exposure times of 91 − 120, 48 − 91, 19 − 48, 10 − 19, and 3 − 10 hours. These bins were chosen to maximize the LAE statistics, reflecting the depth variation within the datacube. In the following, these five regions (named MUDF 1, MUDF 2, MUDF 3, MUDF 4, and MUDF 5) are treated as independent surveys, each characterized by its own selection function. The luminosity at which the selection function reaches 10% completeness is, for each region, log(Lmin/erg s−1) = 41.03, 41.11, 41.29, 41.49 and 41.63.
3.2. The MXDF dataset
The catalogue of line emitters from the MXDF is publicly available and presented in Bacon et al. (2023); hence, we describe only the salient properties here. The MXDF is a 155-hour VLT/MUSE programme covering an area of approximately 2.45 arcmin2, located within the Hubble Ultra Deep Field (HUDF; Beckwith et al. 2006), and reaching high sensitivity (≳90 and up to 140 hours) in the central ≈0.9 arcmin2 region. Details of observations and data reduction are provided by Bacon et al. (2023). These authors have also released an emission line catalogue of all sources in the datacube, from which we selected the LAEs.
To ensure the consistency of the analysis methods in this work, we extracted the candidate LAEs from the continuum-subtracted MXDF cube using the same procedure as done for the MUDF, including the estimate of each candidate’s ISN. We then cross-matched these LAEs with the available MXDF catalogue to obtain a final list of individual sources with ISN > 7. All sources meeting this criterion are already included in the original sample in Bacon et al. (2023). For each source, we estimated the total flux using the same CoG method. We then computed the associated selection function by running similar injection and recovery simulations. Finally, we considered only the ultra-deep region (≳90 h) to derive the final selection function. This area covers nearly twice the ultra-deep region of the MUDF, allowing us to build a sample of LAEs that further constrains the faint end of the LF. The luminosity at which the selection function reaches a completeness of 10% is log(Lmin/erg s−1) = 40.89.
3.3. The MAGG dataset
The MAGG survey is a VLT/MUSE programme targeting 28 quasar fields at z ≈ 3.2–4.5, each observed for a total of approximately 4 hours. Details of the observations and data reduction are provided by Lofthouse et al. (2020), Fossati et al. (2021), along with a description of the extraction and creation of the LAE catalogue and the associated selection function for realistic LAEs. In summary, the strategy adopted for this dataset is consistent with the one described for the MUDF. Since the exposure time of each field is nearly identical, the survey can be treated as a single large-area programme covering ≈26.5 arcmin2, with a selection function reaching 10% completeness at log(Lmin/erg s−1) = 41.69.
3.4. The MW dataset
The MW survey is a VLT/MUSE programme consisting of 24 adjacent 1 × 1 arcmin2 pointings in the CANDELS/Deep region of the GOODS-South field. The total survey area is 22.2 arcmin2, accounting for a 4″ overlap between individual pointings. Details of the observations and data reduction are provided by Herenz et al. (2019), along with the extraction and construction of the LAE catalogue and the associated selection function. Although the extraction process adopts a slightly different methodology, the provided selection function refers to this final catalogue and therefore allows us to include this dataset consistently in our analysis. Furthermore, the luminosity of each source is carefully estimated and corrected to be consistent with a manual CoG analysis adopted in the other datasets, as described in Herenz & Wisotzki (2017). The luminosity at which the selection function reaches 10% completeness is log(Lmin/erg s−1) = 42.13.
4. Testing the Bayesian formalism with mock catalogues
In this section we numerically test the Bayesian model using mock catalogues generated from a given LF, demonstrating that we can recover the input parameters from the synthetic sample. To concretely demonstrate the flexibility of this formalism in working on multi-depth datasets, we performed this test not in general terms, but by specializing to the case of an LF for LAEs in surveys that share the characteristics introduced in the previous section. The outcome of this test is easily generalized to any galaxy survey. To work on this specific case, we implemented the formalism described above, further assuming (in Eq. 4) a uniform prior π in the parameters Φ★, 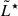 and α in the ranges [10−4, 10−2],[41.5, 43.5] and [ − 2.5, −1]. As output, we obtain the posterior samples for
and α in the ranges [10−4, 10−2],[41.5, 43.5] and [ − 2.5, −1]. As output, we obtain the posterior samples for 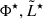 , and α, the three parameters that define the Schechter function (see Eq. 2).
, and α, the three parameters that define the Schechter function (see Eq. 2).
For our test, we constructed three mock catalogues that represent different observational scenarios, considering a selection function that depends only on luminosity, thereby neglecting, at this stage, the wavelength (or redshift) dependence. These three catalogues are defined as follows:
-
A shallow survey (tobs ∼ 5 hr with MUSE) covering a wide area of ∼25 arcmin2 (MAGG-like), with a selection function characterized by a 10% detection threshold at log(Lmin/erg s−1)≈41.7;
-
A deep survey (tobs ∼ 100 hr with MUSE) over an area of ∼0.5 arcmin2 (MUDF 1-like), with a selection function characterized by a 10% detection threshold at log(Lmin/erg s−1)≈41;
-
A combination of the two mock surveys described above.
We also performed an initial test on a complete mock survey with an area 30 times larger than that of the full MUDF, which allowed us to constrain both the faint and bright ends of the LF, in order to verify that the Bayesian model can correctly recover the true parameters.
We assumed that the mock population follows the Schechter LF in Eq. (2), with the parameters inferred for LAEs by Herenz et al. (2019): log(Φ★/Mpc−3) = − 2.71, log(L★/erg s−1) = 42.66, α = −1.84. This choice mimics an LF that is close to a real observed case, but the results of this test are not dependent on the specific parameter values chosen. We sampled the corresponding probability distribution function of the population [Eq. (9)], generating sources with associated redshifts in the range 3 < z < 5 and luminosities satisfying log(L/erg s−1)≥40.5. While we did not introduce measurement errors in the redshift values, we included a relative uncertainty of 10% in the luminosities. We then applied a selection function modelled as a sigmoid,
 (19)
(19)
defined by the inflection point 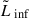 that depends on the mock survey and a fixed slope parameter
that depends on the mock survey and a fixed slope parameter 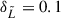 , which simulates the sharp decline in sensitivity observed in the real data. We chose an
, which simulates the sharp decline in sensitivity observed in the real data. We chose an 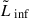 value that reproduces the 10% detection thresholds described above:
value that reproduces the 10% detection thresholds described above: 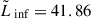 (
(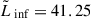 ) for the shallow (deep) survey. Following this procedure, we generated a sample of 1082 (105) LAEs with luminosities log(L/erg s−1)≳41.7 (log(L/erg s−1)≳41) for the shallow (deep) survey.
) for the shallow (deep) survey. Following this procedure, we generated a sample of 1082 (105) LAEs with luminosities log(L/erg s−1)≳41.7 (log(L/erg s−1)≳41) for the shallow (deep) survey.
We applied the formalism to these mock samples and compare in Fig. 1 the true input LF with the median posterior estimates derived from our Bayesian model for each mock survey scenario. In this figure, we also show the non-parametric 1/Vmax LF estimator originally proposed by Schmidt (1968) and later modified to account for redshift- and luminosity-dependent selection functions (Fan et al. 2001; Herenz et al. 2019). Within this formalism, and using the same notation as above, the differential LF for the k-th survey can be approximated in luminosity bins according to the relation
 |
Fig. 1. Results of the Bayesian model applied to mock catalogues for both individual surveys and their combination. This test demonstrates how combining multiple surveys with varying depths helps constrain the LF with reduced statistical uncertainty across a wider dynamical range of luminosities. In the top panel the solid dark blue line indicates the true LF used to generate the mock catalogues. The light blue (magenta) diamonds represent the 1/Vmax estimator of the LF obtained from the MUDF 1- (MAGG)-like survey, along with the median of the posterior samples from the Bayesian model (dashed line) and the corresponding 90% credible interval. The solid black line shows the median when combining the two surveys, with the associated 90% credible interval. Horizontal bars on the diamonds represent the bin widths, while vertical bars are the Poisson errors associated with the 1/Vmax estimator. In the bottom panel the dashed lines (same colours as in the top panel) show the logarithmic difference between the median LF obtained from the Bayesian model and the true LF. The solid lines indicate the 5th and 95th percentiles relative to the true LF. |
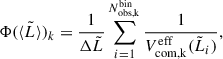 (20)
(20)
where 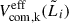 is the effective comoving volume accessible to the i-th galaxy in the k-th survey and in the luminosity bin, accounting for the survey’s selection function (see Eq. 17). Here,
is the effective comoving volume accessible to the i-th galaxy in the k-th survey and in the luminosity bin, accounting for the survey’s selection function (see Eq. 17). Here, 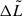 is the width of the luminosity bin, which is set to be 0.35 dex in Fig. 1, while
is the width of the luminosity bin, which is set to be 0.35 dex in Fig. 1, while 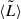 is the average Lyα luminosity within that bin. The associated uncertainty in each bin can be estimated following, for example, Johnston (2011) as
is the average Lyα luminosity within that bin. The associated uncertainty in each bin can be estimated following, for example, Johnston (2011) as
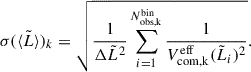 (21)
(21)
The first conclusion we draw from Fig. 1 is that the methodology laid out above faithfully recovers the parameters of the input LF. Indeed, by combining a wide and a deep survey to explore a considerable luminosity range with appropriate statistics, we observe that the recovered LF reproduces the input one. However, inspection of the recovered LF from the combined surveys shows a small discrepancy at the bright end [log(L/erg s−1)≈43]. This is due to residual statistical uncertainty caused by the limited number of luminous LAEs.
It is also instructive to explore the impact that specific surveys have on the recovery of the LF by considering two typical cases that are frequently encountered in observations: a deep, narrow-area survey and a shallow, wide-area survey. We adopted luminosity uncertainties that are consistent with the typical values and the luminosity dependence observed in data. Specifically, we assumed a fractional uncertainty that decreases with increasing luminosity and ranges from 25% for low-luminosity sources to 2% for bright ones. We also estimated the potential error introduced when extrapolating the model beyond the dynamical range covered by the data. We first considered a survey with an area of ≈26 arcmin2 and a 10% completeness luminosity limit of log(Lmin/erg s−1)≈41.5, i.e. approximately 1.2 dex below the input 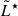 . The method constrains the true LF at the faint end within an uncertainty of ≈0.25 dex, down to a luminosity of log(L/erg s−1)≈41, and with a much smaller uncertainty of ≈0.02 dex up to log(L/erg s−1)≈42.9. Despite the lower statistical uncertainties resulting from the relatively high number of luminous objects in the survey area, the recovered parameters show discrepancies at the level of ≳0.1 − 0.2 dex, due to the lack of sufficient low luminosity galaxies and the increasing luminosity uncertainties affecting those that are detected, which reduce their statistical weight and favour a steeper faint-end slope.
. The method constrains the true LF at the faint end within an uncertainty of ≈0.25 dex, down to a luminosity of log(L/erg s−1)≈41, and with a much smaller uncertainty of ≈0.02 dex up to log(L/erg s−1)≈42.9. Despite the lower statistical uncertainties resulting from the relatively high number of luminous objects in the survey area, the recovered parameters show discrepancies at the level of ≳0.1 − 0.2 dex, due to the lack of sufficient low luminosity galaxies and the increasing luminosity uncertainties affecting those that are detected, which reduce their statistical weight and favour a steeper faint-end slope.
The opposite effect is noticeable when considering an ultra-deep, small-area survey covering ≈0.5 arcmin2 and reaching a 10% completeness luminosity limit of log(Lmin/erg s−1)≈41. In this case, the faint end is recovered with high accuracy, ≲0.01 dex, down to log(L/erg s−1)≲41. However, the ability to constrain the bright end decreases, reaching 0.25 dex at log(L/erg s−1)≈43. This finding highlights that the sheer number of objects at specific low luminosities, rather than the quality of individual datasets, drives the accuracy with which we recover the LF faint-end parameters. Indeed, at the cost of a slightly larger discrepancy on 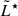 (≈0.1 dex), the number density set by Φ★ and the faint-end slope (α) are still well constrained. Higher statistical errors persist due to the limited number of bright sources in such a small-area survey.
(≈0.1 dex), the number density set by Φ★ and the faint-end slope (α) are still well constrained. Higher statistical errors persist due to the limited number of bright sources in such a small-area survey.
We conclude that, in order to reduce uncertainties in the determination of the LF, it is more effective to carry out a deeper survey reaching a 10% completeness luminosity limit ≳1.5 dex below the true 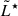 over a small area – enough to obtain only tens of galaxies around
over a small area – enough to obtain only tens of galaxies around 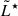 . However, this strategy does not allow us to constrain the bright end of the LF (at log(L/erg s−1)≳43) accurately. A wide-area (≳30 − 35 arcmin2) and shallow survey is required as supplemental input. Our formalism natively allows the combination of various surveys, thus enabling the combination of various datasets effortlessly.
. However, this strategy does not allow us to constrain the bright end of the LF (at log(L/erg s−1)≳43) accurately. A wide-area (≳30 − 35 arcmin2) and shallow survey is required as supplemental input. Our formalism natively allows the combination of various surveys, thus enabling the combination of various datasets effortlessly.
In summary, we have shown that the framework we developed reliably recovers the true LF parameters and provides reliable determinations of the LF in a variety of configurations and survey combinations, fully leveraging the available information.
5. Application to the LF of LAEs at 3 < z < 5
Having validated the method with mock data, we applied our Bayesian framework to the MUSE surveys described in Sect. 3. In parallel, for comparison, we also computed the non-parametric LF using binned estimates with a bin width of  dex for each survey. The binning procedure accounts for the varying luminosity limits of the different surveys, ensuring that no bin includes contributions from surveys whose detection threshold lies within the bin range. This prevents a (possibly severe) underestimation of the number density in the bin that would otherwise require a very large and highly uncertain statistical correction.
dex for each survey. The binning procedure accounts for the varying luminosity limits of the different surveys, ensuring that no bin includes contributions from surveys whose detection threshold lies within the bin range. This prevents a (possibly severe) underestimation of the number density in the bin that would otherwise require a very large and highly uncertain statistical correction.
The LF obtained from applying the Bayesian model to the combined dataset (MXDF+MUDF+MAGG+MW) is shown in the top panel of Fig. 2, together with the non-parametric 1/Vmax estimates from individual surveys and their average, weighted by the number of objects per bin. These 1/Vmax values and their weighted mean lie in proximity to the inferred parametric model and serve as visual guidance for the model performance. Arrows indicate, for each survey, the luminosity limit above which the completeness exceeds 10%. This helps visualize the minimum luminosity covered by each dataset, highlighting their constraining power in the combined model.
 |
Fig. 2. LF obtained from the combination of the four MUSE surveys considered in this study (see Table 1). Top panel: Median LF reconstructed using our Bayesian model applied to the full sample (solid black line), along with the corresponding 90% credible interval. The blue colour-coded diamonds represent the 1/Vmax estimates from each individual survey, with vertical bars indicating the Poisson uncertainties and horizontal bars the bin widths. The dark blue circles show the weighted average of the 1/Vmax points across surveys in each bin. Arrows in the same colour scheme indicate the luminosity limit above which each survey reaches a completeness higher than 10%. For comparison, coloured lines with different line styles display the best-fit Schechter LFs from various studies in the literature (Herenz et al. 2019; Thai et al. 2023). Bottom panel: Statistical uncertainty on the LF as a function of luminosity. The solid black lines show the relative 5th and 95th percentiles of the Bayesian posterior distribution. |
Below log(L/erg s−1)≲40.9, the inferred LF is no longer directly constrained by the data. Conversely, at the high-luminosity end, we cannot define a single cutoff point in the constraining power of the adopted datasets. However, due to the volumes probed by the largest surveys we used (MAGG and MW), the model is no longer constrained by the data at log(L/erg s−1)≳43.4. The bottom panel shows the statistical uncertainty on the LF as a function of luminosity, expressed as the 5th and 95th percentiles of the posterior relative to the best-fit. Uncertainties vary from ≲0.01 dex at log(L/erg s−1)≈42, to ≈0.1 dex at log(L/erg s−1)≈41, and increase to ≳0.15 dex for log(L/erg s−1)≳43, reflecting the lower number of bright sources. These values are consistent with the findings of the mock tests presented above. The apparent offset between the 1/Vmax point in highest-luminosity bin and the Bayesian fit arises from the very low number statistics in that bin (only two sources), which consequently has a limited impact on constraining the LF in the Bayesian model, as also indicated by the larger statistical uncertainty. Additional large volume datasets, can provide stronger constraints on the bright-end of the LF, as further discussed in Sect. 5.1.
The median values and credible intervals of the Schechter function parameters obtained for the overall sample are reported in Table 2. We also assessed the dependence of the results on the adopted completeness threshold, considering the luminosities at which the completeness exceeds 5% and 20%. We applied the model to the redshift range 3 < z < 5 and report the associated number of sources above the new luminosity threshold, along with the median values and credible intervals, in Table 3. The sharp decline in the completeness results in a variation in the luminosity limits of ≈0.04 dex (on average). This does not significantly impact the inferred LF parameters that remain in good agreement with those estimated at a limit 10%. We believe that the initial choice of 10% provides a good balance between extended minimum luminosity and a sufficient number of observed galaxies without the need of excessive completeness corrections.
Schechter function parameters in different redshift bins.
Schechter function parameters when varying the completeness threshold, Cth.
While we assumed a perfectly known 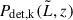 , we assessed the effect of uncertainties on this quantity to the recovery of the LF by generating a set of perturbed realizations of the selection functions shown in Fig. A.1. Specifically, we perturbed the transition region of the sigmoid-like completeness curve along the luminosity axis at fixed redshift, introducing Gaussian variations from a few percent up to several tens of percent. This approach allowed us to test the sensitivity of the Bayesian model in the regime with the steepest variations in
, we assessed the effect of uncertainties on this quantity to the recovery of the LF by generating a set of perturbed realizations of the selection functions shown in Fig. A.1. Specifically, we perturbed the transition region of the sigmoid-like completeness curve along the luminosity axis at fixed redshift, introducing Gaussian variations from a few percent up to several tens of percent. This approach allowed us to test the sensitivity of the Bayesian model in the regime with the steepest variations in 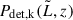 with luminosity and, thus, the one potentially more affected by systematics. We notice that even the strongest perturbations produce only marginal changes in the faint-end slope, within the statistical uncertainties. Our inference is therefore statistically robust against reasonable biases and random uncertainties in the selection functions.
with luminosity and, thus, the one potentially more affected by systematics. We notice that even the strongest perturbations produce only marginal changes in the faint-end slope, within the statistical uncertainties. Our inference is therefore statistically robust against reasonable biases and random uncertainties in the selection functions.
Finally, we split the sample into two redshift bins (3 < z < 4 and 4 < z < 5) to test whether the data imply a redshift evolution of the LF. In Fig. 3, we show the posterior distributions of the parameters inferred from the Bayesian model in the two redshift intervals, along with the full redshift range we explored. The median marginalized values are reported in Table 2. We observe a trend in Φ★, consistent with a decreasing number density of sources towards a higher redshift. There is a weak but not statistically significant increase in 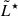 with redshift, in line with the results of Thai et al. (2023) and Drake et al. (2017). Instead, the faint-end slope (α) shows a stronger evolution, ranging from
with redshift, in line with the results of Thai et al. (2023) and Drake et al. (2017). Instead, the faint-end slope (α) shows a stronger evolution, ranging from 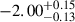 in the 4 < z < 5 bin to
in the 4 < z < 5 bin to 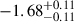 in the 3 < z < 4 bin. At higher redshift, we must note that the credible contours show a degeneracy between α and
in the 3 < z < 4 bin. At higher redshift, we must note that the credible contours show a degeneracy between α and 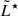 . This arises as a consequence of the smaller number of available objects that can pin down the knee of the LF, allowing for an ambiguity between a shallower LF with a fainter knee or a steeper LF with a brighter
. This arises as a consequence of the smaller number of available objects that can pin down the knee of the LF, allowing for an ambiguity between a shallower LF with a fainter knee or a steeper LF with a brighter 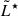 .
.
 |
Fig. 3. Posterior distributions of the LF parameters α, |
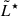
5.1. Discussion and comparison with the literature
We compared our median LF reconstructed from the posterior samples with those from previous studies, some of which are shown as dashed lines in Fig. 2. In particular, we considered the LF estimates of Thai et al. (2023), who leveraged strong gravitational lensing by 17 galaxy clusters to probe the faint end of the LF (log(L/erg s−1)≲41) in the redshift bins 2.9 < z < 4 and 4 < z < 5. Their results show overall agreement with our median LF, although with a steeper faint-end slope (α ≈ −2.00 compared to our median 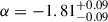 , considering the overall redshift range 3 < z < 5). When comparing the same redshift intervals, we find that our faint-end slope is in agreement within the uncertainties in the 4 < z < 5 range, but is lower by approximately 15% in the 3 < z < 4 bin. Conversely, in the 4 < z < 5 interval, our slope is steeper by about 19%, while in the 3 < z < 4 range it remains higher, but still consistent within 1σ with the values reported by de La Vieuville et al. (2019), a study also exploiting the lensing effect to reach low luminosities (log(L/erg s−1)≲41).
, considering the overall redshift range 3 < z < 5). When comparing the same redshift intervals, we find that our faint-end slope is in agreement within the uncertainties in the 4 < z < 5 range, but is lower by approximately 15% in the 3 < z < 4 bin. Conversely, in the 4 < z < 5 interval, our slope is steeper by about 19%, while in the 3 < z < 4 range it remains higher, but still consistent within 1σ with the values reported by de La Vieuville et al. (2019), a study also exploiting the lensing effect to reach low luminosities (log(L/erg s−1)≲41).
Thai et al. (2023) include all sources with a completeness above 1%, thereby incorporating a larger number of objects that may be more strongly affected by completeness corrections. This is also particularly relevant because magnification models become increasingly uncertain at the lowest luminosities, where sources lie close to the lensing caustic lines and are thus highly sensitive to their precise positions relative to these lines (see Thai et al. (2023) for a detailed discussion). In our analysis, we adopted a more conservative completeness threshold of 10%, which was explicitly incorporated into the Bayesian model used to determine the median LF. Indeed, the total number of expected sources (or the volume density) is treated as a free parameter and is modelled accordingly, taking this threshold into account. Moreover, Thai et al. (2023) reports that applying a 10% completeness cut results in a shallower faint-end slope–particularly in the 3 < z < 4 bin, where they find a value of approximately α ≈ −1.78, which is closer to our estimate. A steeper slope can indeed be expected when a small number of objects carry a very large statistical correction weight. The generally lower values of the faint-end slope reported by de La Vieuville et al. (2019) who applied a 10% completeness threshold can instead be attributed to larger statistical uncertainties due to the smaller sample size, as also discussed in Thai et al. (2023).
We also show in Fig. 2 the best-fit obtained in the work of Herenz et al. (2019), who used the MW data included in our combined fit. Although the luminosity range covered by these data is limited to log(L/erg s−1)≳42.1, and is therefore subject to larger statistical uncertainties, their best-fit is in good agreement with our median LF once combined with the deeper datasets, although we observe a slightly lower 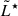 and higher Φ★.
and higher Φ★.
We conclude that, because of the ability offered by our Bayesian framework to combine multiple surveys with varying observational characteristics, we are now in a position to robustly constrain the shape of the LF of 3 < z < 5 LAEs across three dex in luminosity. In particular, the availability of sufficient numbers of deep surveys has now considerably reduced the statistical uncertainties on the faint-end slope. While this is welcome news, comparison with literature values highlights how we are moving towards a regime in which systematic effects – such as those imposed by completeness corrections – start to be relevant. Further improvements in the determination of α should invest in high-quality datasets where purity and completeness are well characterized, rather than increasing sample sizes or pushing to even fainter luminosities1. In contrast, there is an ample margin for improving the statistical significance with which the bright end of the LF is constrained. At high luminosities, the LAE surveys used in this work lack the statistical power to probe the LF where the expected number density is Φ < 10−4 Mpc−3 dex−1. Much larger volumes can be harvested from the MUSE archive, an effort that is currently only limited by the speed with which LAE catalogues can be assembled. Alternatively, wide-area surveys from other instruments (e.g. HETDEX; Hill et al. 2008) can offer interesting datasets that complement the MUSE surveys. With our work, the tool for stitching together various datasets is now available.
6. Summary and conclusions
We have presented a hierarchical Bayesian model to constrain the shape of the LF, accounting for the selection effects of different surveys, such as completeness, luminosity limits, and limited sky coverage. By combining heterogeneous data to fully exploit the constraining power of the wide dynamical range spanned by all diverse available surveys, this approach provides a robust way to determine the parameters of the underlying population of sources, once a functional form (e.g. a Schechter function) is assumed. In addition, the model incorporates measurement uncertainties on the physical properties associated with each source (e.g. luminosity).
While this model is very general and can be applied to describe the distribution of any extensive quantity for a class of astrophysical object, in this work we focused on the case study of establishing the LF of galaxies. In particular, we applied our framework to derive the LF of LAEs using data from four large MUSE surveys, ranging from ultra-deep observations (≳90 h) over small areas (≲1 arcmin2) to shallower exposures (≲5 h) over much larger fields (≳20 arcmin2). When combined, these surveys account for nearly 500 h of MUSE observing time. Before applying the model to real data, we validated its performance using mock catalogues, assessing its ability to recover the input parameters and investigating how statistical uncertainties on the inferred parameters depend on the properties of the input surveys.
We summarize our main conclusions as follows:
-
The hierarchical Bayesian model developed in this work incorporates several novel key points for the estimate of the LF: It enables the combination of multi-depth surveys, each characterized by its own selection effects (see e.g. Mandel et al. 2019). It explicitly treats the normalization factor as a free parameter of the underlying population, accounting for it through a Poisson term in the likelihood, and includes measurement uncertainties on the observed properties (e.g. the galaxies’ luminosity).
-
Tests of the model using mock catalogues of LAEs suggest that it is highly beneficial to extend the observations to luminosities ≳1.5 dex below the characteristic luminosity (
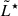 ) even over relatively small areas. These deep observations can be effectively complemented by wide-area but shallower surveys, which help constrain the bright end of the LF.
) even over relatively small areas. These deep observations can be effectively complemented by wide-area but shallower surveys, which help constrain the bright end of the LF. -
Through a population of 1176 LAEs obtained from the combination of the ultra-deep MXDF and MUDF surveys and the large-area MAGG and MW surveys, we studied the LF both in the redshift range 3 < z < 5 and in the redshifts bins 3 < z < 4 and 4 < z < 5. This allowed us to constrain the faint-end slope of the LF with statistical errors ≲0.1 dex at log(L/erg s−1)≈41. Assuming the population of LAEs is described by a Schechter function, the median values along with the 90% credible interval obtained from the one-dimensional marginalized posterior in the redshift range 3 < z < 5 are:
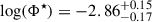 ,
, 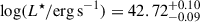 , and
, and 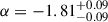 .
. -
The median LF is consistent with previous results of past studies that constrained the faint end (e.g. de La Vieuville et al. 2019; Thai et al. 2023), although our median value of α is ≈10% lower than those obtained by Thai et al. (2023) and ≈6% higher than (see the text for a more detailed discussion de La Vieuville et al. 2019). The steepening of the faint-end slope with redshift, suggested also by de La Vieuville et al. (2019) and Thai et al. (2023), is tentatively confirmed with this sample.
We show that, within our Bayesian framework and by leveraging a large and ultra-deep MUSE sample, it is in principle possible to recover the true LAE LF within ≲0.05 − 0.1 dex, with statistical errors ≲0.1 dex up to log(L/erg s−1)≳43. This is particularly true at the faint end, where we have demonstrated that the model applied to these types of datasets can, in principle, constrain the underlying LF, provided that the sample selection process is not affected by significant biases.
While in this work we focused on MUSE surveys, there are other large-area observational efforts in the literature (e.g. the LAE sample from the HETDEX survey; Hill et al. 2008; Zhang et al. 2021) that can further constrain the bright end of the LF [log(L/erg s−1)≳43], a regime where our current sample still yields estimates that are affected by larger statistical uncertainties, or where deviations from a single Schechter function are possible (Spinoso et al. 2020). In the future, upcoming and proposed instruments like BlueMUSE (Richard et al. 2019) and WST (Mainieri et al. 2024) will expand both the accessible redshift range (down to z ≈ 2) and the depth and number density of the samples, providing tighter constraints on the shape and evolution of the LAE LF. The ability to fully capture uncertainties and selection effects in the model is therefore essential to characterizing the galaxy population when combining data from different observational facilities, and represents a crucial step towards building an accurate picture of galaxy evolution across cosmic time.
Ultra-deep experiments retain values, including the mitigation of cosmic variance from pencil beam surveys and the testing of uncharted regions of parameter space, such as deviations from a single power law or even the existence of a cutoff in the LF.
Acknowledgments
This work is supported by the Italian Ministry for Research and University (MUR) under Grant ‘Progetto Dipartimenti di Eccellenza 2023-2027’ (BiCoQ). D.G. is supported by ERC Starting Grant No. 945155–GWmining, Cariplo Foundation Grant No. 2021-0555, MSCA Fellowship No. 101064542–StochRewind, MSCA Fellowship No. 101149270–ProtoBH, MUR PRIN Grant No. 2022-Z9X4XS, MUR Young Researchers Grant No. SOE2024-0000125 and the ICSC National Research Centre funded by NextGenerationEU.
References
- Ajello, M., Shaw, M. S., Romani, R. W., et al. 2012, ApJ, 751, 108 [NASA ADS] [CrossRef] [Google Scholar]
- Arrigoni Battaia, F., Hennawi, J. F., Prochaska, J. X., et al. 2019, MNRAS, 482, 3162 [NASA ADS] [CrossRef] [Google Scholar]
- Bacon, R., Accardo, M., Adjali, L., et al. 2010, Proc. SPIE, 7735, 773508 [Google Scholar]
- Bacon, R., Mary, D., Garel, T., et al. 2021, A&A, 647, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bacon, R., Brinchmann, J., Conseil, S., et al. 2023, A&A, 670, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baldry, I. K., Driver, S. P., Loveday, J., et al. 2012, MNRAS, 421, 621 [NASA ADS] [Google Scholar]
- Beckwith, S. V. W., Stiavelli, M., Koekemoer, A. M., et al. 2006, ApJ, 132, 1729 [Google Scholar]
- Blanton, M. R., Hogg, D. W., Bahcall, N. A., et al. 2003, ApJ, 592, 819 [Google Scholar]
- Borisova, E., Cantalupo, S., Lilly, S. J., et al. 2016, ApJ, 831, 39 [Google Scholar]
- Bouwens, R. J., Oesch, P. A., Stefanon, M., et al. 2021, ApJ, 162, 47 [Google Scholar]
- Boyle, B. J., Shanks, T., Croom, S. M., et al. 2000, MNRAS, 317, 1014 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J. 2021, J. Open Source Softw., 6, 3001 [CrossRef] [Google Scholar]
- Chen, H.-W., Marzke, R. O., McCarthy, P. J., et al. 2003, ApJ, 586, 745 [Google Scholar]
- Ciardullo, R., Jacoby, G. H., Ford, H. C., & Neill, J. D. 1989, ApJ, 339, 53 [Google Scholar]
- de La Vieuville, G., Bina, D., Pello, R., et al. 2019, A&A, 628, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Drake, A. B., Garel, T., Wisotzki, L., et al. 2017, A&A, 608, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fan, X., Strauss, M. A., Schneider, D. P., et al. 2001, ApJ, 121, 54 [Google Scholar]
- Fitzpatrick, E. L. 1999, PASP, 111, 63 [Google Scholar]
- Fossati, M., & Tornotti, D. 2025, http://dx.doi.org/10.5281/zenodo.14710518 [Google Scholar]
- Fossati, M., Fumagalli, M., Lofthouse, E. K., et al. 2019, MNRAS, 490, 1451 [NASA ADS] [CrossRef] [Google Scholar]
- Fossati, M., Fumagalli, M., Lofthouse, E. K., et al. 2021, MNRAS, 503, 3044 [NASA ADS] [CrossRef] [Google Scholar]
- Herenz, E. C., & Wisotzki, L. 2017, A&A, 602, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Herenz, E. C., Wisotzki, L., Saust, R., et al. 2019, A&A, 621, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Herrera, D., Gawiser, E., Benda, B., et al. 2025, ApJ, 988, L57 [Google Scholar]
- Heyl, J., Colless, M., Ellis, R. S., & Broadhurst, T. 1997, MNRAS, 285, 613 [Google Scholar]
- Hill, G. J., Gebhardt, K., Komatsu, E., et al. 2008, Astron. Soc. Pac. Conf. Ser., 399, 115 [Google Scholar]
- Hogg, D. W. 1999, arXiv e-prints [arXiv:astro-ph/9905116] [Google Scholar]
- Johnston, R. 2011, A&A Rev., 19, 41 [Google Scholar]
- Kelly, B. C., & Merloni, A. 2012, Adv. Astron., 2012, 970858 [CrossRef] [Google Scholar]
- Kelly, B. C., Fan, X., & Vestergaard, M. 2008, ApJ, 682, 874 [NASA ADS] [CrossRef] [Google Scholar]
- Leclercq, F., Bacon, R., Wisotzki, L., et al. 2017, A&A, 608, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leclercq, F., Bacon, R., Verhamme, A., et al. 2020, A&A, 635, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lofthouse, E. K., Fumagalli, M., Fossati, M., et al. 2020, MNRAS, 491, 2057 [NASA ADS] [CrossRef] [Google Scholar]
- Loredo, T. J. 2004, AIP Conf. Proc., 735, 195 [CrossRef] [Google Scholar]
- Lusso, E., Fumagalli, M., Fossati, M., et al. 2019, MNRAS, 485, L62 [NASA ADS] [Google Scholar]
- Lynden-Bell, D. 1971, MNRAS, 155, 95 [Google Scholar]
- Mainieri, V., Anderson, R. I., Brinchmann, J., et al. 2024, arXiv e-prints [arXiv:2403.05398] [Google Scholar]
- Mandel, I., Farr, W. M., & Gair, J. R. 2019, MNRAS, 486, 1086 [Google Scholar]
- Marshall, H. L., Tananbaum, H., Avni, Y., & Zamorani, G. 1983, ApJ, 269, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Mehta, V., Scarlata, C., Colbert, J. W., et al. 2015, ApJ, 811, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Miyaji, T., Hasinger, G., & Schmidt, M. 2001, A&A, 369, 49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Muzzin, A., Marchesini, D., Stefanon, M., et al. 2013, ApJ, 777, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Ono, Y., & Shibuya, T. 2020, ARA&A, 58, 617 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [Google Scholar]
- Richard, J., Bacon, R., Blaizot, J., et al. 2019, arXiv e-prints [arXiv:1906.01657] [Google Scholar]
- Richards, G. T., Strauss, M. A., Fan, X., et al. 2006, ApJ, 131, 2766 [Google Scholar]
- Sandage, A., Tammann, G. A., & Yahil, A. 1979, ApJ, 232, 352 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. 1976, ApJ, 203, 297 [Google Scholar]
- Schlafly, E. F., & Finkbeiner, D. P. 2011, ApJ, 737, 103 [Google Scholar]
- Schmidt, M. 1968, ApJ, 151, 393 [Google Scholar]
- Skilling, J. 2004, AIP Conf. Proc., 735, 395 [Google Scholar]
- Spinoso, D., Orsi, A., López-Sanjuan, C., et al. 2020, A&A, 643, A149 [EDP Sciences] [Google Scholar]
- Taylor, S. R., & Gerosa, D. 2018, Phys. Rev. D, 98, 083017 [NASA ADS] [CrossRef] [Google Scholar]
- Thai, T. T., Tuan-Anh, P., Pello, R., et al. 2023, A&A, 678, A139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tornotti, D., Fumagalli, M., Fossati, M., et al. 2025a, ApJ, 980, L43 [Google Scholar]
- Tornotti, D., Fumagalli, M., Fossati, M., et al. 2025b, Nat. Astron., 9, 577 [Google Scholar]
- Vitale, S., Gerosa, D., Farr, W. M., & Taylor, S. R. 2022, in Handbook of Gravitational Wave Astronomy, eds. C. Bambi, S. Katsanevas, & K. D. Kokkotas, 45 [Google Scholar]
- Wisotzki, L., Bacon, R., Blaizot, J., et al. 2016, A&A, 587, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhang, Y., Ouchi, M., Gebhardt, K., et al. 2021, ApJ, 922, 167 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Selection functions of the surveys
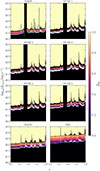 |
Fig. A.1. Selection functions |
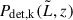
All Tables
All Figures
|
Fig. 1. Results of the Bayesian model applied to mock catalogues for both individual surveys and their combination. This test demonstrates how combining multiple surveys with varying depths helps constrain the LF with reduced statistical uncertainty across a wider dynamical range of luminosities. In the top panel the solid dark blue line indicates the true LF used to generate the mock catalogues. The light blue (magenta) diamonds represent the 1/Vmax estimator of the LF obtained from the MUDF 1- (MAGG)-like survey, along with the median of the posterior samples from the Bayesian model (dashed line) and the corresponding 90% credible interval. The solid black line shows the median when combining the two surveys, with the associated 90% credible interval. Horizontal bars on the diamonds represent the bin widths, while vertical bars are the Poisson errors associated with the 1/Vmax estimator. In the bottom panel the dashed lines (same colours as in the top panel) show the logarithmic difference between the median LF obtained from the Bayesian model and the true LF. The solid lines indicate the 5th and 95th percentiles relative to the true LF. |
| In the text | |
|
Fig. 2. LF obtained from the combination of the four MUSE surveys considered in this study (see Table 1). Top panel: Median LF reconstructed using our Bayesian model applied to the full sample (solid black line), along with the corresponding 90% credible interval. The blue colour-coded diamonds represent the 1/Vmax estimates from each individual survey, with vertical bars indicating the Poisson uncertainties and horizontal bars the bin widths. The dark blue circles show the weighted average of the 1/Vmax points across surveys in each bin. Arrows in the same colour scheme indicate the luminosity limit above which each survey reaches a completeness higher than 10%. For comparison, coloured lines with different line styles display the best-fit Schechter LFs from various studies in the literature (Herenz et al. 2019; Thai et al. 2023). Bottom panel: Statistical uncertainty on the LF as a function of luminosity. The solid black lines show the relative 5th and 95th percentiles of the Bayesian posterior distribution. |
| In the text | |
|
Fig. 3. Posterior distributions of the LF parameters α, |
| In the text | |
|
Fig. A.1. Selection functions |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.