| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A267 | |
| Number of page(s) | 8 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202554742 | |
| Published online | 25 September 2025 | |
Neutron star envelopes with machine learning
A single-hidden-layer neural network application
1
Institute of Space Sciences (ICE, CSIC), Campus UAB,
Carrer de Magrans,
08193
Barcelona,
Spain
2
Institut d’Estudis Espacials de Catalunya (IEEC), Edifici RDIT, Campus UPC,
08860
Castelldefels (Barcelona),
Spain
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
March
2025
Accepted:
1
August
2025
Abstract
Thermal and magneto-thermal simulations are an important tool for advancing understanding of neutron stars, as they allow us to compare models of their internal structure and physical processes against observations constraining macroscopic properties such as the surface temperature. A major challenge in the simulations is in modelling of the outermost layers, known as the envelope, exhibiting a drop of many orders of magnitude in temperature and density in a geometrically thin shell. This is often addressed by constructing a separate envelope model in plane-parallel approximation that produces a relation between the temperature at the bottom of the envelope, Tb, and the surface temperature, Ts. Our aim is to construct a general framework for approximating the Tb−Ts relation that is able to include the dependencies from the strength and orientation of the magnetic field. We used standard prescriptions to calculate a large number of magnetised envelope models to be used as a training sample and employed single-hidden-layer feedforward neural networks as approximators, providing the flexibility, high accuracy, and fast evaluation necessary in neutron star simulations. We explored the optimal network architecture and hyperparameter choices and used a special holdout set designed to avoid overfitting to the structure of the input data. We find that relatively simple neural networks are sufficient for the approximation of the Tb−Ts relation with an accuracy ∼ 3%. The presented workflow can be used in a wide range of problems where simulations are used to construct approximating formulae.
Key words: dense matter / magnetic fields / methods: numerical / methods: statistical / stars: neutron
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Neutron stars (NSs) are ultra-dense remnants of massive stellar cores and are observed as pulsars, thermally emitting compact objects, accreting X-ray binaries, gravitational-wave sources, gamma-ray bursts, and more. As the end points of the evolution of isolated stars with an initial mass 8 ≲M☉ ≲30 (depending on the metallicity) and with more diverse origins in interacting multiples (e.g. accretion induced collapse), they offer unique insights into stellar evolution theory (e.g. Tauris & van den Heuvel 2023). Their extreme density, comparable or even exceeding the nuclear one, and strong magnetic fields ranging from several million to ≍ 1015 G probe physics in regimes unattainable in ground-based laboratories (e.g. Shapiro & Teukolsky 1983).
Many NSs have been detected to emit thermal emission in the soft X-ray band, corresponding to temperatures of ≍ 106 K (e.g. Rigoselli 2024); this can be compared with NS thermal evolution models as a means of accessing the internal structure and reactions occurring in the interior of the star (Tsuruta & Cameron 1966; Page et al. 2004; Potekhin et al. 2015). When modelling the temperature throughout the star, very different scales must be considered. In particular, in the outermost layers, known as the ‘envelope’, temperature and density drop by several orders of magnitude within mere meters (e.g. Haensel et al. 2007), making it problematic to treat them alongside the bulk of the star of ≍ 10 km radius. To this end, envelope models are commonly studied in plane parallel and quasi-stationary approximation (see the comprehensive review by Beznogov et al. 2021).
Most notably, an envelope model is able to provide a Tb−Ts relation, that is, an expression linking the temperature at the bottom of the envelope, Tb, to one at the surface, Ts. This in turn is key to link the observed temperature (Ts) to that controlling the physical processes in the interior (Tb). In particular, when solving numerically the NS thermal evolution equations in realistic, multidimensional setups, these envelope models are employed in order to impose a boundary condition on the surface temperature gradient (e.g. Pons & Viganò 2019). However, this framework presents a practical nuisance: While the 1D parallel model is built using a given a value of Ts as its initial condition (see Section 2.1), the thermal evolution code updates the value of Tb. Hence, having an expression for the Tb−Ts relation is necessary in all cases, as solving a 1D model every time the boundary condition is imposed is not only impractical, but impossible. To this end, a variety of models and relations have been proposed in the literature. The case of a weakly magnetised, heavy element envelope was studied by Gudmundsson et al. (1983), who provided a Tb−Ts relation that is often taken as a reference. For more specific applications, a variety of more refined models taking into account the effect of the magnetic field, neutrino emission, and different chemical compositions are available in the literature (e.g. Potekhin et al. 2003, 2015; Beznogov et al. 2016), typically in the form of ad hoc analytical formulae fitted to the models. However, as an increasing amount of details are included in the models, these expressions can become rather large and complicated to handle, especially if one needs to adapt them to include further effects.
The above information highlights the necessity of a computational framework for generalizing the Tb−Ts relation to consider additional parameters and construct an approximation that is accurate and fast. This is specifically important given the advent of 3D numerical codes (De Grandis et al. 2020; Igoshev et al. 2021; Dehman et al. 2023; Ascenzi et al. 2024) since the Tb−Ts relation is expected to be used at least once per time step for each point on the NS surface.
A promising avenue towards such a framework is the use of artificial neural networks (ANNs) as approximators of the Tb−Ts relation. Firstly, ANNs can accommodate the inclusion of additional inputs without necessitating significant changes to the overall framework. More importantly, even though they can be slow in the training phase, their predictions are fast, involving simple algebraic operations that are highly optimised in modern computational software. The flexibility and efficiency of ANNs have contributed to the widespread adoption of neural networks in astrophysics (see review in Smith & Geach 2023). Initial steps to solve classification (e.g. Odewahn et al. 1992) and regression problems (e.g. Collister & Lahav 2004) were taken as early as the 1990s and 2000s. More complex neural network architectures, such as convolutional neural networks, have been used to obtain morphological classifications of galaxies from images (e.g. Huertas-Company et al. 2015; Domínguez Sánchez et al. 2018) and to provide alternatives to surface brightness profile fitting thousands of times faster than traditional methods (e.g. Tuccillo et al. 2018.) These developments demonstrate how machine learning has evolved from performing relatively simple tasks (e.g. star–galaxy classification) to addressing increasingly complex problems, including constraining physics (e.g. Marino et al. 2024) and employing explainable models to probe the behaviour of astrophysical sources (e.g. Pinciroli Vago et al. 2025).
Multilayer feedforward networks are known to be universal approximators (e.g. Hornik et al. 1989; Cybenko 1989) when given sufficient depth (number of hidden layers) and hidden units (neurons in hidden layers). The exact architecture of the network (number of hidden layers and units) and training configuration (e.g. initialisation, optimisation algorithm, number of epochs) depends on the investigated function and the structure of the training data. Interestingly, even the use of single-hidden-layer feedforward neural networks (SLFNs) can be sufficient for both univariate and multivariate functions (e.g. Cybenko 1989; Guliyev & Ismailov 2018), especially when using a sigmoid activation function. This is particularly appealing for the application at hand, as it not only promises fast tuning and training but also faster predictions.
In this paper, we investigate the ability of SLFNs to approximate Ts as a function of the magnetic field strength and orientation, bottom density and temperature, and chemical composition of the envelope (Section 2). We study the optimal ANN architecture for future expansions of the models and provide trained networks for use by the community1 after having evaluated their approximation accuracy (Section 3). In Section 4, we summarise our findings and show examples of Tb−Ts relations, and we discuss the applicability of our approach to other fields. A direct application of the models and methods developed in this work can be found in De Grandis et al. (2025), where a set of simulations of short-term magneto-thermal evolution in magnetars is presented.
2 Methodology
In this section we describe the physics input and the resulting simulation data. We also present the machine learning workflow towards a model approximating the Tb−Ts relation.
2.1 Physics input
We closely followed the formalism by Potekhin et al. (2007, see also Thorne 1977), which we present here for clarity of exposition. Namely, we describe the structure of the NS envelope, assuming a quasi-stationary state, as the set of equations for the gravitational potential, Φ; local heat flux, Fr; temperature, T; and gravitational mass, m, enclosed in a sphere of radius, r:
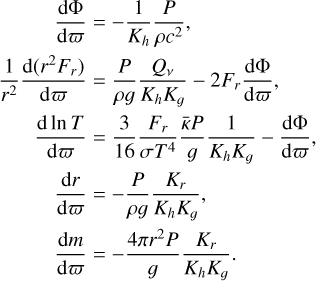 (1)
(1)
Here, ϕ=ln P is the (natural) logarithm of the pressure, P; ρ is the mass density; Qv is the neutrino emissivity; σ is the Stefan-Boltzmann constant; κ̄ is the opacity; and
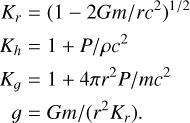 (2)
(2)
These equations must be supplemented with an equation of state connecting the density and pressure P = P(ρ, T, B, Z, A), which in general will also depend on the magnetic field, temperature, and composition (Z and A being the atomic and mass numbers of the plasma). Within the notation used here, the opacity, κ̄, is related to the thermal conductivity of the plasma, κ, as κ̄= 16 σ T3/3 κ ρ, while the conductivity is affected by the magnetic field as
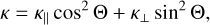 (3)
(3)
where Θ is the angle between the (local) magnetic field and the normal to the surface and κ|, ⊥ are the components of the conductivity tensor related to the heat transport along or across field lines (themselves a function of ρ, B, T, and composition), respectively. The values of this quantity as well as the equation of state P(ρ, B) were obtained through the latest version of the equation of state by Potekhin et al. (2015), which is available online2. We assumed a fixed chemical composition for the envelope, either of pure hydrogen (H) or pure iron (Fe).
This system is completed by the boundary conditions at the surface:
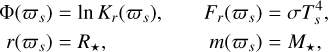 (4)
(4)
where the surface pressure logarithm, ϕs, is determined via the condition κ̄(ϕs) P(ϕs) / g(ϕs)=2 / 3 (Gudmundsson et al. 1983). Therefore, an envelope model is defined once the stellar mass, M*, and radius, R*; surface temperature, Ts; and magnetic field (strength and direction) are defined.
The effect of neutrino emission, represented by the term Qv (which we described following the prescriptions from Yakovlev et al. 2001), is to limit the maximum Ts an envelope can have (Potekhin et al. 2015). In practice, when solving Equations (1), a large neutrino emission translates into a steep rise in the temperature. The cases in which this gradient makes the temperature increase up to unrealistic values (≳ 1010 K) are interpreted as having too large an initial temperature Ts to have a possible physical realisation and are therefore discarded.
We solved the system defined by Equations (1)–(4) as an initial-values problem, with a standard fourth-order Runge-Kutta algorithm employing a step advance in P in a geometric progression with constant 1% increases. The integration proceeds up to an assigned density, ρb, the choice of which depends upon several factors. Namely, the integration should proceed throughout the region in which the steepest thermal gradient in the NS is found, which happens around the sensitivity strip, i.e. the layer where the radiative and electron opacity are comparable and the thermal gradient is largest (Gudmundsson et al. 1983). Typically, this happens at around 106 g cm−3. However, the integration can be extended beyond this in order to remove the low density layers from the domain of (magneto-)thermal codes as much as possible; a customary choice is ρb=1010 g cm−3. This value controls the time resolution of the (magneto-)thermal code itself, which cannot be shorter than the characteristic heat diffusion time across the envelope without breaking the assumption of quasi-stationarity onto which the Tb−Ts relation is built (see the discussion in Beznogov et al. 2021). At ρb=1010 g cm−3, this is ≍ 1 yr, which is adequate in most cooling simulations. However, when treating phenomena unfolding on shorter timescales, a lower value of ρb should be used. In this work, we concentrate on such lower values of ρb since the motivation is to build envelope models applicable to short-term simulations that can support high temperatures (this is most important for tackling outbursts; see De Grandis et al. 2025). In particular, the term Qv increases with density so that models that are to be discarded when studying thick envelopes might still be physical for shallow ones (at which point the region at higher density does not have to be described under the constraint of stationarity).
In the following, we calculate models with two compositions, H and Fe, representing the extreme ends of NS envelope compositions, with other compositions falling between these cases. For simplicity, we assume a standard NS with M*=1.4 M☉, R*= 10 km. Different values of mass and radius can be accounted for, as the Tb−Ts relation scales as the surface gravity 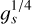 (Gudmundsson et al. 1983), though an extension to account explicitly for this could be easily implemented within our formalism.
(Gudmundsson et al. 1983), though an extension to account explicitly for this could be easily implemented within our formalism.
2.2 Description of the simulation data
Even though we have solved the full set of equations describing the structure of the envelope, in the following we focus on the profile of the temperature as a function of density T(ρ) for a given set of physical parameters of the NS (B, Θ, and Ts). Moreover, in order to build envelope models corresponding to different ρb values, we considered ρb itself as another parameter. Thus the function 𝒯 to be approximated is
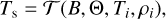 (5)
(5)
where i labels the integration grid. Collecting all simulation outputs gives
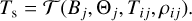 (6)
(6)
Here, j enumerates the simulations, each corresponding to a temperature profile with multiple points (index i).
We ran a set of simulations randomly sampling the parameter space, namely selecting B in the [109, 1015] G range (with a log-uniform distribution), Θ uniformly in [0, π / 2], and Ts log-uniformly in [5 × 105, 5 × 107] K. Overall, our sample is constituted by 4221 profiles for the two compositions, which are shown in Figure 1. Interestingly, a fraction of the curves shows a behaviour quite unlike the others, as they exhibit plateaus (jump in density at the same T) and/or high density surfaces. These behaviours occur when the envelope presents a thermodynamically unstable or solid phase, respectively. These phases are due to the presence of the strong magnetic field, and for the parameter range studied here, they are the most important around B ≍ 1014 G. As an example, Figure 2 shows the equation of state we adopted (Potekhin & Chabrier 2013) for a fixed field and different temperatures, which includes the transition to a thermodynamically unstable phase (P<0) at ρ ≲106 g cm−3. The ‘gap’ in the equation of state is reflected in the density jumps in the envelope temperature profiles.
2.3 Neural network architecture
The input layer consists of four units (xi) corresponding to the four physical parameters in Equation (6). They are the decimal logarithm of the density at the bottom of the envelope, log ρ (in units of [g cm−3]); the decimal logarithm of the corresponding temperature, log T (in units of [K]); and the parameters of the magnetic field log B (in units of [G]) and Θ (in radians).
The architecture is that of a shallow network having one hidden layer, as shown in Figure 3. The hidden layer has n units (the choice of this value is discussed in Sect. 2.5) and is fully connected to the input layer, resulting in 4 n weights wi j and n biases bj. The sigmoid activation function S(x)=(1+e−x)−1 is applied at each hidden unit, hj,
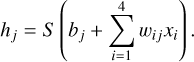 (7)
(7)
The output layer has one unit, corresponding to the target quantity, log Ts, and as it is fully connected to the hidden layer, it has n weights (w′k) and one bias (b′). As in standard regression neural networks, the linear activation function is used at the output (f(x)=x):
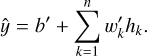 (8)
(8)
Overall, the network contains a small number of trainable variables, 6 n+1.
We used standard prescriptions for the initialisation of the weights (He et al. 2015) and the optimisation method, that is, the AMSGrad variant (Reddi et al. 2018) of the Adam optimiser (Kingma & Ba 2015). For the loss function, we used the mean squared error (MSE) combined with L1 and L2 regularisation terms:
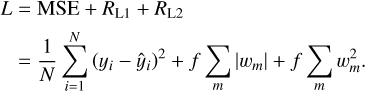 (9)
(9)
Here, yi is the surface temperature of the profile containing the i-th data point, ŷi is the network’s prediction, while wm represent all the weights in the neural network. The regularisation terms, controlled by the hyperparameter f, are aimed at diminishing the effect of the weights, thus reducing the risk of overfitting.
 |
Fig. 1 Profile curves from the NS envelope simulations for the Fe (left panel) and H envelope (right panel). Orange lines indicate the holdout curves used as an alternative test set. In the inset we show a zoom-in illustrating the random assignment of data points to the training (black), validation (green), and test (purple) sets from 90% of the profiles as well as the holdout points (orange) comprised of whole curves (the remaining 10%; see Sect. 2.4 for details). |
 |
Fig. 2 Equation of state by Potekhin & Chabrier (2013) for a strong field and different temperature values in the case of iron composition. The gaps correspond to thermodynamically unstable regions (we note that the high density branches for all temperatures are almost superimposed and indistinguishable from one another). |
2.4 Data subsets and holdout curves
For each envelope model, we used four data sets. First, is the training set, which is the only one used to update the weights of the ANN. Second is the validation set used for the hyperparameter tuning (e.g. number of hidden units; see Sect. 2.5) and for monitoring the validation error during training. The final sets are the test set and holdout curves for the final evaluation of the optimised and fully trained networks. In contrast to the test set, which comprises random points from different profiles, the holdout curves are the collection of all the integration points from a fraction of the simulated profiles. We note that the terms ‘test’ and ‘holdout’ are sometimes used interchangeably in the literature or to refer to different stages (final evaluation or validation). Here, they act as independent sets, which are unseen during training, tuning, or validation, and they are characterised by their different distributions in the feature space (random single points versus complete simulation profiles).
Specifically, we randomly selected 10% of the profiles (see orange lines in Figure 1) as holdout curves. We merged the points of the remaining 90% of the curves and randomly split them into the training (80%), validation (10%), and test (10%) sets (72%, 9%, and 9% of the total data, respectively). The inset in Figure 1 demonstrates the distribution of the different sets in the log ρ – log T feature space, where each sequence of points corresponds to the profile for a different combination of B and Θ. The training (black), validation (green), and test (purple) points are randomly distributed among the majority of the profiles, but the holdout points (orange) form full profiles.
Effectively, the neural networks will learn the profiles of the curves that are represented in the training set. Since the validation and test sets are made up of points from the same curves, there is a risk of overfitting the network to the specific values of B and Θ. The holdout curves serve as a way to test the ability of the final trained network to generalise, approximating 𝒯 for unseen combinations of (B, Θ). In Figure 4, we show the fraction of data as a function of B, Θ, and Ts, demonstrating that the subsets are sampled fairly.
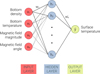 |
Fig. 3 Single-hidden-layer feedforward network architecture used for approximating the surface temperature, Ts. For n hidden units (hj), the total of variables is 6 n+1 (weights in each connection and biases in each unit including the output). |
 |
Fig. 4 Fraction of data in the training (‘train’), validation (‘valid’), test, and holdout sets as a function of the input simulation parameters: magnetic field strength (left panel) and angle (middle panel), and the target variable surface temperature (right panel) for the Fe (cyan) and H (violet) compositions. For better visibility, the fraction of the validation and test sets has been multiplied by three and two, respectively. |
2.5 Hyperparameter tuning
After experimentation with different choices of hyperparameters (e.g. optimisers, weight initialisers), we identified three of them as determining the prediction accuracy, as well as the ranges that will be systematically explored. These are the learning rate, r; the number of units (neurons) in the hidden layer of the SLFN, n; and the regularisation factor, f (see Table 1). We used the KERAS_TUNER v.1.4.6 to perform a grid search on all 45 possible combinations, training the networks up to 100 epochs. Finally, we used the mean absolute error calculated on the validation set (eval) to measure the performance of the models, on which we later based our final choice.
2.6 Training setup and early stopping
We used tensorflow v. 2.15.0 for Python to compile the two SLFNs corresponding to the Fe and H envelope. We adopted the optimal hyperparameters (see Sect. 2.5) and the same settings (e.g. optimiser, initialisation) as in the tuning phase.
Despite the small number of trainable variables (103−4 depending on the optimal number of units) with respect to the data (∼ 7 × 106) and the use of regularisation, there is always a risk of overfitting. Moreover, it is quite possible that a small number of epochs is required for the task at hand, rendering prolonged training unnecessary. To address both issues, we used early stopping with patience to 30 epochs while monitoring the validation loss function. This means that during the training phase, the loss was calculated using the validation data that was not included in the learning process. If there was no improvement for 30 consecutive epochs, hinting at reaching the best performance, or overfitting, then the training stopped. Since during these 30 epochs the model may have been slightly overfitted to the training data, we restored the weights of the best performing snapshot of the network (30 epochs before the end).
Because of the use of early stopping, the final model depends on the random choice of the validation set. More importantly, the choice of restoring the weights results in a model with overrated performance if it is evaluated on the validation set. Therefore, we used the test set and holdout curves, which played no role in the construction of the model (learning or early stopping), to obtain an unbiased assessment of the performance on unseen data.
Hyperparameters considered during the tuning phase.
3 Results
3.1 Tuning
In our investigation, since we are considering the two extreme cases of chemical composition, we expected them to be able to inform us about the best neural network architectures and scales for the estimation of Ts in further models with different compositions or physical assumptions. For this reason, we combined the findings of the two grid searches. Furthermore, this increases the performance statistical size and reduces the risk of selecting hyperparameters due to statistical fluctuations in the performance metrics (e.g. mean absolute error).
Notably, for the H-envelope, the five best performing models out of the 45 trials had similar mean absolute errors (0.020-0.022) and corresponded to r = 0.01, f = 10−6, and they all had different numbers of units (512, 4096, 256, 2048, 1024 in order of decreasing performance). We obtained similar results with the Fe-envelope models. The best performing models (mean absolute error between 0.015 and 0.19) had f = 10−6, with the majority having r = 0.01, and the models had a varying number of units.
In Figure 5, we show the distributions (with pink violin plots) of the validation mean absolute error of the trials as a function of the f, r and n (from left to right panel). As one can see in the f panel, the best results are obtained for f = 10−6. For this reason, in the panels of r and n, we also plot the subset of the trials with f = 10−6 (green violin plots). We observed that out of these models, the best performing ones had r = 0.01. Consequently, in the last panel, we show the distribution of these models (f = 10−6 and r = 0.01; blue violins), where we find that the best performance is obtained for 256, 2048, and 4096 units. This hints at the possibility that regularisation simplified the networks and resulted in a similar ‘effective’ number of units.
Since the performance is similar when using different numbers of hidden units (possibly because of statistical fluctuations), we considered additional criteria for our final choice on this hyperparameter. A small number of units (e.g. 256) gives lower flexibility to the networks in case of more complex data for different compositions. On the other hand, a large n would increase the computational complexity for predictions (feed-forward propagation). For this reason, we selected the intermediate value of n = 2048. The hyperparameters we eventually adopted are highlighted in bold in Table 1.
 |
Fig. 5 Distribution of the validation mean absolute errors of the models trained during the hyperparameter tuning. Left panel: dependence on the regularisation factor (pink), with f = 10−6 indicated as the optimal value. Middle panel: dependence on the learning rate (pink). The distribution highlights the trials with the optimal f value (green) and indicates optimal performance for r = 0.01. Right panel: dependence on the number of units (pink). The distribution highlights the trials with the optimal f (green) and r values (blue). The green violin plots focus on the models with the best performing regularisation factor, f = 106, while the blue ones also focus on those with the best performing learning rate, r = 0.01. |
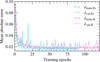 |
Fig. 6 Improvement of the mean absolute error during the training of the SLFNs for the Fe (cyan) and H-envelope (violet) composition models, calculated on the training (dashed lines) and validation sets (solid lines). For illustrative purposes, the curves have been smoothed using a Savitzky-Golay filter with a window length equal to two. |
 |
Fig. 7 Distribution of the prediction errors, r = y−ŷ, of the final models for Fe (upper part) and H (lower part) in the different sets (from top to bottom): training (‘train’), validation (‘val’), test (‘test’), and holdout curves (‘hold’). The standard deviation of the prediction errors (σ), their mean value (r̄ i.e. the mean bias of the predictions), and mean absolute values (ē; i.e. the mean absolute error) are shown in the tails of the violin plots. |
 |
Fig. 8 Tb−Ts relations for different densities, ρb (see annotated coloured text, in g cm−3), and three magnetic field strengths (see titles) for the Fe envelope. The band corresponds to different values of the magnetic angle, Θ (lower values of Ts for the same Tb correspond to larger angles, i.e. more magnetic insulation). Using the same colours, we show all the points (circles) in the training dataset that correspond to similar magnetic field strengths and densities (difference smaller than 0.05 dex), demonstrating the success of the model in learning the Tb−Ts relation. The relations obtained by Gudmundsson et al. (1983) (dotted black line) and Potekhin et al. (2015) (hatched band) for ρb=1010 g cm−3 are also plotted for comparison. |
 |
Fig. 9 Same as Figure 8 but for the H envelope. The hatched band in this case is the model from Potekhin et al. (2003). |
3.2 Training and evaluation of performance
In Figure 6, we show the training and validation mean absolute errors during the training of the two networks. The different number of epochs for the Fe (cyan) and H (violet) networks is a result of early stopping. We note that there is no sign of overfitting, and the models quickly converged after a few tens of epochs.
Even with optimal average performance, it is important to ensure that the predictions are not systematically biased or skewed. To test this, we calculated the prediction errors (or residuals), ri=yi−ŷi, and their absolute values, ei=|ri|, for all four sets (training, validation, test, and holdout). The violin plots of the errors are shown in Figure 7, marking the minimum and maximum values, their scatter (σ), mean value (r̄), and the mean absolute error (ē).
The mean values of the prediction errors for both envelopes and all sets are ≲0.0025 dex, which is significantly smaller than the scatter (≲0.02 dex), indicating that the predictions are not biased. The test and holdout mean absolute errors of the Fe model is ∼ 0.012 dex, indicating a relative error smaller than 3% in Ts. For the H model, the mean absolute error is ∼ 0.015 dex, resulting in a relative error of ∼ 3.5% in Ts.
4 Discussion
The present work showcases the step-by-step construction of an approximator of the Tb−Ts relation that is directly applicable to numerical codes for NS evolution. The same recipe can be followed by studies adopting different models of NS envelopes without further extensive exploration of the hyperparameter space.
In Figures 8 and 9, we show the predictions of the Fe and H envelope, respectively, for different magnetic field strengths and inclinations and bottom densities. We also overplot (circles) the training data that correspond to the respective field values (with a tolerance of 0.05 dex absolute difference since the training data correspond to simulations with randomly sampled magnetic field strengths). We find that the model predictions follow the distribution of the points, and despite the small number of points, the bands are smooth, indicating that the network has learned the trends in the Tb−Ts relation. The overall trends are also compatible with the fits found in the literature and computed for ρb=1010 g cm−3. We did not extend our curves up to this density value because those with a high Ts would have been rendered unphysical by neutrino emission (which is not necessarily the case when those layers are treated outside of the plane-parallel approximation). Nevertheless, we checked that in the cases in which such ρb could be reached our models follow the existing Tb−Ts relation fits from the literature well within their error.
We find that a small neural network having 2048 neurons (units) in a single hidden layer is sufficient for reaching an accuracy of <0.015 dex(<3.5%) in the case of the Fe and H envelopes. The use of the sigmoid activation function avoids artefacts and numerical instabilities in simulations and is compatible with numerical solvers requiring smooth functions. The result is a fast and infinitely differentiable approximator that can be loaded in modern computational frameworks (e.g. in Python) or even manually built with ease to interact with pre-existing codes (e.g. in Fortran). In particular, we implemented our model in the Fortran code by Pons & Viganò (2019), finding a limited impact on performance (total runtime increased by 1−5%) with respect to the use of analytical expressions from the literature (specifically, the one proposed in Potekhin et al. 2015, valid only for a single ρb) on a standard laptop running on an Intel i7 processor.
The weak dependence of the mean absolute error on the number of units in the hidden layer indicates that the two models are relatively simple: Many of the weights are close to zero, and a small number of neurons are activated. Consequently, different models with wider parameter ranges or additional functional dependence on other NS properties may be accommodated with the same adopted hyperparameter values.
Shallow-learning approaches with neural networks are not new in astrophysics (e.g. Silva et al. 2011), but to our knowledge this is the first study applying them in data that represent ‘evolution tracks’, as well as considering an additional test dataset (holdout curves) to detect potential overfitting due to the ordered structured of the training data. Similar networks and holdout curve sets can be used in other disciplines where fast approximations are desired involving evolution in space or time, such as stellar or planetary structure; single, binary, or triple population synthesis; metallicity-dependent star-formation histories of galaxies. The code of the presented framework is provided in a public GitHub repository3, and we have included instructions as well as the ready-for-use trained models.
Acknowledgements
KK is supported an ICE Fellowship under the program Unidad de Excelencia Maria de Maeztu (CEX2020-001058-M). KK, DDG and NR are supported by the Catalan grant SGR2021-01269 (PI: Graber/Rea), DDG by a Juan de la Cierva fellowship (JDC2023-052264-I), and DDG and NR are also supported by the European Research Council (ERC) via the Consolidator Grant ‘MAGNESIA’ (No. 817661) and the Proof of Concept 'DeepSpacePulse' (No. 101189496).
References
- Ascenzi, S., Viganò, D., Dehman, C., et al. 2024, MNRAS, 533, 201 [NASA ADS] [CrossRef] [Google Scholar]
- Beznogov, M. V., Potekhin, A. Y., & Yakovlev, D. G., 2016, MNRAS, 459, 1569 [Google Scholar]
- Beznogov, M. V., Potekhin, A. Y., & Yakovlev, D. G., 2021, Phys. Rep., 919, 1 [CrossRef] [Google Scholar]
- Collister, A. A., & Lahav, O., 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Cybenko, G. V., 1989, Math. Control Signals Syst., 2, 303 [CrossRef] [Google Scholar]
- De Grandis, D., Turolla, R., Wood, T. S., et al. 2020, ApJ, 903, 40 [NASA ADS] [CrossRef] [Google Scholar]
- De Grandis, D., Rea, N., Kovlakas, K., et al. 2025, A&A, 701, A229 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dehman, C., Viganò, D., Pons, J. A., & Rea, N., 2023, MNRAS, 518, 1222 [Google Scholar]
- Domínguez Sánchez, H., Huertas-Company, M., Bernardi, M., Tuccillo, D., & Fischer, J. L. 2018, MNRAS, 476, 3661 [Google Scholar]
- Gudmundsson, E. H., Pethick, C. J., & Epstein, R. I., 1983, ApJ, 272, 286 [CrossRef] [Google Scholar]
- Guliyev, N. J., & Ismailov, V. E., 2018, Neural Networks, 98, 296 [Google Scholar]
- Haensel, P., Potekhin, A. Y., & Yakovlev, D. G., 2007, Neutron Stars 1 : Equation of State and Structure, 326 [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J., 2015, in 2015 IEEE International Conference on Computer Vision (ICCV), 1026 [Google Scholar]
- Hornik, K., Stinchcombe, M., & White, H., 1989, Neural Networks, 2, 359 [CrossRef] [Google Scholar]
- Huertas-Company, M., Gravet, R., Cabrera-Vives, G., et al. 2015, ApJS, 221, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Igoshev, A. P., Hollerbach, R., Wood, T., & Gourgouliatos, K. N., 2021, Nat. Astron., 5, 145 [Google Scholar]
- Kingma, D. P., & Ba, J., 2015, in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings, eds. Y. Bengio, & Y. LeCun [Google Scholar]
- Marino, A., Dehman, C., Kovlakas, K., et al. 2024, Nat. Astron., 8, 1020 [Google Scholar]
- Odewahn, S. C., Stockwell, E. B., Pennington, R. L., Humphreys, R. M., & Zumach, W. A., 1992, AJ, 103, 318 [NASA ADS] [CrossRef] [Google Scholar]
- Page, D., Lattimer, J. M., Prakash, M., & Steiner, A. W., 2004, ApJS, 155, 623 [NASA ADS] [CrossRef] [Google Scholar]
- Pinciroli Vago, N. O., Amato, R., Imbrogno, M., et al. 2025, A&A, 701, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pons, J. A., & Viganò, D., 2019, Liv. Rev. Computat. Astrophys., 5, 3 [Google Scholar]
- Potekhin, A. Y., & Chabrier, G., 2013, A&A, 550, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Potekhin, A. Y., Yakovlev, D. G., Chabrier, G., & Gnedin, O. Y., 2003, ApJ, 594, 404 [Google Scholar]
- Potekhin, A. Y., Chabrier, G., & Yakovlev, D. G., 2007, Ap&SS, 308, 353 [Google Scholar]
- Potekhin, A. Y., Pons, J. A., & Page, D., 2015, Space Sci. Rev., 191, 239 [Google Scholar]
- Reddi, S. J., Kale, S., & Kumar, S., 2018, arXiv e-prints [arXiv:1904.09237] [Google Scholar]
- Rigoselli, M., 2024, in Multifrequency Behaviour of High Energy Cosmic Sources XIV, 55 [Google Scholar]
- Shapiro, S. L., & Teukolsky, S. A., 1983, Black holes, white dwarfs and neutron stars. The physics of compact objects [Google Scholar]
- Silva, L., Schurer, A., Granato, G. L., et al. 2011, MNRAS, 410, 2043 [NASA ADS] [Google Scholar]
- Smith, M. J., & Geach, J. E., 2023, Roy. Soc. Open Sci., 10, 221454 [NASA ADS] [CrossRef] [Google Scholar]
- Tauris, T. M., & van den Heuvel, E. P. J., 2023, Physics of Binary Star Evolution. From Stars to X-ray Binaries and Gravitational Wave Sources [Google Scholar]
- Thorne, K. S., 1977, ApJ, 212, 825 [NASA ADS] [CrossRef] [Google Scholar]
- Tsuruta, S., & Cameron, A. G. W., 1966, Can. J. Phys., 44, 1863 [Google Scholar]
- Tuccillo, D., Huertas-Company, M., Decencière, E., et al. 2018, MNRAS, 475, 894 [NASA ADS] [CrossRef] [Google Scholar]
- Yakovlev, D. G., Kaminker, A. D., Gnedin, O. Y., & Haensel, P., 2001, Phys. Rep., 354, 1 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Profile curves from the NS envelope simulations for the Fe (left panel) and H envelope (right panel). Orange lines indicate the holdout curves used as an alternative test set. In the inset we show a zoom-in illustrating the random assignment of data points to the training (black), validation (green), and test (purple) sets from 90% of the profiles as well as the holdout points (orange) comprised of whole curves (the remaining 10%; see Sect. 2.4 for details). |
| In the text | |
|
Fig. 2 Equation of state by Potekhin & Chabrier (2013) for a strong field and different temperature values in the case of iron composition. The gaps correspond to thermodynamically unstable regions (we note that the high density branches for all temperatures are almost superimposed and indistinguishable from one another). |
| In the text | |
|
Fig. 3 Single-hidden-layer feedforward network architecture used for approximating the surface temperature, Ts. For n hidden units (hj), the total of variables is 6 n+1 (weights in each connection and biases in each unit including the output). |
| In the text | |
|
Fig. 4 Fraction of data in the training (‘train’), validation (‘valid’), test, and holdout sets as a function of the input simulation parameters: magnetic field strength (left panel) and angle (middle panel), and the target variable surface temperature (right panel) for the Fe (cyan) and H (violet) compositions. For better visibility, the fraction of the validation and test sets has been multiplied by three and two, respectively. |
| In the text | |
|
Fig. 5 Distribution of the validation mean absolute errors of the models trained during the hyperparameter tuning. Left panel: dependence on the regularisation factor (pink), with f = 10−6 indicated as the optimal value. Middle panel: dependence on the learning rate (pink). The distribution highlights the trials with the optimal f value (green) and indicates optimal performance for r = 0.01. Right panel: dependence on the number of units (pink). The distribution highlights the trials with the optimal f (green) and r values (blue). The green violin plots focus on the models with the best performing regularisation factor, f = 106, while the blue ones also focus on those with the best performing learning rate, r = 0.01. |
| In the text | |
|
Fig. 6 Improvement of the mean absolute error during the training of the SLFNs for the Fe (cyan) and H-envelope (violet) composition models, calculated on the training (dashed lines) and validation sets (solid lines). For illustrative purposes, the curves have been smoothed using a Savitzky-Golay filter with a window length equal to two. |
| In the text | |
|
Fig. 7 Distribution of the prediction errors, r = y−ŷ, of the final models for Fe (upper part) and H (lower part) in the different sets (from top to bottom): training (‘train’), validation (‘val’), test (‘test’), and holdout curves (‘hold’). The standard deviation of the prediction errors (σ), their mean value (r̄ i.e. the mean bias of the predictions), and mean absolute values (ē; i.e. the mean absolute error) are shown in the tails of the violin plots. |
| In the text | |
|
Fig. 8 Tb−Ts relations for different densities, ρb (see annotated coloured text, in g cm−3), and three magnetic field strengths (see titles) for the Fe envelope. The band corresponds to different values of the magnetic angle, Θ (lower values of Ts for the same Tb correspond to larger angles, i.e. more magnetic insulation). Using the same colours, we show all the points (circles) in the training dataset that correspond to similar magnetic field strengths and densities (difference smaller than 0.05 dex), demonstrating the success of the model in learning the Tb−Ts relation. The relations obtained by Gudmundsson et al. (1983) (dotted black line) and Potekhin et al. (2015) (hatched band) for ρb=1010 g cm−3 are also plotted for comparison. |
| In the text | |
|
Fig. 9 Same as Figure 8 but for the H envelope. The hatched band in this case is the model from Potekhin et al. (2003). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.