| Issue |
A&A
Volume 700, August 2025
|
|
|---|---|---|
| Article Number | A30 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202554450 | |
| Published online | 29 July 2025 | |
NIKA2 Cosmological Legacy Survey
Blind detection of galaxy clusters in the COSMOS field via the Sunyaev-Zel’dovich effect
1
Univ. Grenoble Alpes, CNRS, Grenoble INP, LPSC-IN2P3, 53, avenue des Martyrs, 38000 Grenoble, France
2
Univ. Grenoble Alpes, CNRS, IPAG, 38000 Grenoble, France
3
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange, France
4
School of Physics and Astronomy, Cardiff University, Queen’s Buildings, The Parade, Cardiff CF24 3AA, UK
5
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM, F-91191 Gif-sur-Yvette, France
6
Institut de Radioastronomie Millimétrique (IRAM), Avenida Divina Pastora 7, Local 20, E-18012 Granada, Spain
7
Instituto de Astrofísica de Canarias, C/Vía Láctea s/n, E-38205 La Laguna, Tenerife, Spain
8
Universidad de La Laguna, Departamento de Astrofísica, E-38206 La Laguna, Tenerife, Spain
9
Aix Marseille Univ, CNRS, CNES, LAM (Laboratoire d’Astrophysique de Marseille), Marseille, France
10
Institut Néel, CNRS, Université Grenoble Alpes, France
11
Institut de Radioastronomie Millimétrique (IRAM), 300 rue de la Piscine, 38400 Saint-Martin-d’Hères, France
12
Université de Strasbourg, CNRS, Observatoire astronomique de Strasbourg, UMR 7550, 67000 Strasbourg, France
13
Astronomy Centre, Department of Physics and Astronomy, University of Sussex, Brighton BN1 9QH, UK
14
Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 5, I-00185 Roma, Italy
15
Institute for Research in Fundamental Sciences (IPM), School of Astronomy, Tehran, Iran
16
Centro de Astrobiología (CSIC-INTA), Torrejón de Ardoz, 28850 Madrid, Spain
17
National Observatory of Athens, Institute for Astronomy, Astrophysics, Space Applications and Remote Sensing, Ioannou Metaxa and Vasileos Pavlou, GR-15236 Athens, Greece
18
Department of Astrophysics, Astronomy & Mechanics, Faculty of Physics, University of Athens, Panepistimiopolis, GR-15784 Zografos, Athens, Greece
19
High Energy Physics Division, Argonne National Laboratory, 9700 South Cass Avenue, Lemont, IL 60439, USA
20
LERMA, Observatoire de Paris, PSL Research University, CNRS, Sorbonne Université, UPMC, 75014 Paris, France
21
Institute of Space Sciences (ICE), CSIC, Campus UAB, Carrer de Can Magrans s/n, E-08193 Barcelona, Spain
22
ICREA, Pg. Lluís Companys 23, Barcelona, Spain
23
Université Paris-Saclay, CEA, Département de Physique des Particules, 91191 Gif-sur-Yvette, France
24
IRAP, CNRS, Université de Toulouse, CNES, UT3-UPS (Toulouse), France
25
Dipartimento di Fisica, Università di Roma ‘Tor Vergata’, Via della Ricerca Scientifica 1, I-00133 Roma, Italy
26
School of Physics and Astronomy, University of Leeds, Leeds LS2 9JT, UK
27
Institut d’Astrophysique de Paris, CNRS (UMR7095), 98 bis boulevard Arago, 75014 Paris, France
28
University of Lyon, UCB Lyon 1, CNRS/IN2P3, IP2I, 69622 Villeurbanne, France
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
10
March
2025
Accepted:
2
June
2025
Abstract
Clusters of galaxies, formed in the latest stages of structure formation, are unique cosmological probes. With the advent of large CMB surveys like those from the Planck satellite, the ACT and SPT telescopes, we now have access to a large number of galaxy clusters detected at millimeter wavelengths via the thermal Sunyaev-Zel’dovich (tSZ) effect. Nevertheless, it is interesting to complement them with high-angular-resolution (tens of arcseconds) observations to target the lowest-mass and highest-redshift clusters. This is the case of observations with the NIKA2 camera, which is installed on the IRAM 30-m telescope in Pico Veleta, Spain. We used the existing 150 GHz (2 mm) data from the NIKA2 Cosmological Legacy Survey (N2CLS) Large Program to blindly search for galaxy clusters in the well-known COSMOS field, across a 877 arcmin2 region centered on (RA, Dec)J2000 = (10h00m28.81s, +02d17m30.44s). We first developed a dedicated data reduction pipeline to construct NIKA2 maps at 2 mm. We then used a matched-filter algorithm to extract cluster candidates assuming a universal pressure profile to model the expected cluster tSZ signal. We computed the purity and completeness of the sample by applying the previous algorithm to simulated maps of the sky signal in the COSMOS field, including tSZ contribution, point sources and instrumental noise. We find a total of 16 cluster candidates at S/N > 4, from which eight have either an optical or X-ray cluster (or group of galaxies) counterpart. This is the first blind detection of clusters of galaxies at mm wavelengths at 18″ angular resolution. For candidates with available redshift estimates, we derived their mass by modeling the cluster tSZ signal with a universal pressure profile via a MCMC analysis. From this analysis, we confirm that NIKA2 and the IRAM 30-m telescope should be sensitive to low-mass clusters at intermediate and high redshift, complementing current and planned large tSZ-based cluster surveys.
Key words: galaxies: clusters: general / cosmology: observations / large-scale structure of Universe
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Clusters of galaxies are formed in the latest stages of structure formation and are unique cosmological probes to study structure formation and its evolution (Voit 2005; Allen et al. 2011). In particular, cluster number counts as a function of mass and redshift are sensitive to the universe matter content and root-mean-square (rms) fluctuations via the Ωm and σ8 cosmological parameters (see Planck Collaboration XXVII 2016). Clusters are intricate systems comprising dark matter, galaxies, and hot-ionized gas known as the intracluster medium (ICM), making them observable across multiple wavelengths of the electromagnetic spectrum. Catalogs of clusters of galaxies have thus been built by surveys at different wavelengths, primarily in the optical and infrared (Abell 1958; Wen et al. 2012, 2018; Bleem et al. 2015a; Oguri et al. 2018; Gonzalez et al. 2019), through the detection of galaxy overdensities, but also in X-ray (Gioia et al. 1990; Mehrtens et al. 2012; Adami et al. 2018; Klein et al. 2019) via the bremsstrahlung emission of hot electrons in the ICM. Furthermore, the last decade has seen a major advance in the study of clusters at millimeter wavelengths (Planck Collaboration XXVII 2016; Hilton et al. 2021; Bleem et al. 2024) via the Sunyaev-Zel’dovich effect (SZ, Sunyaev & Zeldovich 1972).
The thermal Sunyaev-Zel’dovich (tSZ) effect, resulting from the inverse Compton scattering of cosmic microwave background (CMB) photons by hot-thermal electrons in the ICM, is a powerful tool for detecting high-redshift clusters. Unlike other observables, it is not impacted by cosmological dimming, with the cluster’s size being the only limiting factor. Furthermore, the cluster size is related to the cluster mass as clusters are expected to be self-similar objects (Arnaud et al. 2010; Allen et al. 2011). Therefore, we expect low-mass, high-redshift objects to be small in size but detectable via the tSZ effect.
The first successful targeted measurements of the tSZ effect were obtained in the 1970s (Pariiskii 1973; Gull & Northover 1976), with the first blind detection of tSZ clusters following three decades later (Staniszewski et al. 2009). Current blind cluster catalogs of order 103–104 clusters have been obtained using instruments dedicated to CMB observations – the Planck satellite (Planck Collaboration VIII 2011; Planck Collaboration XXIX 2014; Planck Collaboration XXXII 2015; Planck Collaboration XXVII 2016), the ground-based South Pole Telescopes (SPT, Williamson et al. 2011; Bleem et al. 2015b, 2020, 2024; Kornoelje et al. 2025), and the Atacama Cosmology Telescope (ACT, Marriage et al. 2011; Hasselfield et al. 2013; Hilton et al. 2018, 2021). However, they have relatively poor angular resolutions: 5 arcmin for Planck, and about 1 arcmin for SPT and ACT. As a consequence, there is a need for high-angular-resolution instruments (tens of arcseconds) in order to map the tSZ signal for high-redshift and/or low-mass clusters of galaxies, which are expected to be of great cosmological interest (see for example Tinker et al. 2008). In this respect, observations of the tSZ effect with the NIKA2 camera are particularly interesting.
The New IRAM KID Array (NIKA2, Bourrion et al. 2016; Calvo et al. 2016; Adam et al. 2018) is a dual-band millimeter camera consisting of three arrays of kinetic inductance detectors (KIDs) installed at the IRAM 30-m telescope in Granada, Spain. NIKA2 operates at 150 (2 mm) and 260 GHz (1.2 mm), where the tSZ signal is strongly negative and slightly positive, respectively. NIKA2 has a field of view of 6.5′ and offers a high angular resolution of 17.6″ at 2 mm and 11.1″ at 1.2 mm (for a full review of the performance of the instrument see Perotto et al. 2020). As part of the NIKA2 guaranteed time, the NIKA2 Cosmological Legacy Survey (N2CLS) acquired 300 hours of observations distributed between the GOODS-N and COSMOS fields (Bing et al. 2023; Ponthieu et al. 2025). The main goal of the survey is to study dust-obscured galaxies up to very high redshift, but thanks to the depth and very high angular resolution of the observations, the detection of galaxy clusters via the tSZ effect is also possible. The N2CLS catalog of dusty star-forming galaxies will be published in Béthermin et al. (in prep.).
Here we focus on the COSMOS field (Scoville et al. 2007; Laigle et al. 2016; Weaver et al. 2022), where the NIKA2 observations cover a larger area and a large number of ancillary data sets are available. This part of the sky is particularly well adapted for this project as it is widely visible, and also uncontaminated by bright X-ray, UV, and radio sources as well as massive tSZ clusters. The field has been thoroughly observed by both space and ground-based experiments such as the XMM-Newton, HST, Chandra, Spitzer, Herschel, Keck, Subaru, ESO-VLT, and CFHTLS telescopes (see Scoville et al. 2007). This wealth of data enabled the assembly of cluster catalogs in COSMOS, such as the ALHAMBRA catalog (Ascaso et al. 2015), the CES catalog (Söchting et al. 2012), the HIROCS survey (Zatloukal et al. 2007), and other studies (Bellagamba et al. 2011). Clusters have also been detected in this region by larger surveys like the SDSS (Wen et al. 2012), DESI (Zou et al. 2021), XMM (Mehrtens et al. 2012), CFHTLS (Adami et al. 2010), KiDS (Lesci et al. 2022), and Subaru Weak-Lensing (Miyazaki et al. 2007) surveys. However, at the time of writing this article, there are no detections of SZ clusters in the NIKA2 COSMOS field. The new N2CLS data are thus quite promising, as we are able to match any cluster candidate with the available catalogs and identify optical or X-ray counterparts.
In this paper, we present the blind detection of clusters via the SZ effect with the NIKA2 camera in the COSMOS field. The paper is structured as follows. In Section 2, we present the data used and the data reduction pipeline. Section 3 describes the blind cluster detection algorithm and the cluster sample identification process. In Section 4, we discuss the simulation framework used to characterize our sample. Finally, Sections 5 and 6 present the candidate clusters compared to other multiwavelength cluster catalogs and their properties. We summarize and draw conclusions in Section 7.
Throughout this article, we assume a flat ΛCDM cosmology model (e.g., Planck Collaboration VI 2020) with Ωm = 0.31, ΩΛ = 0.69, and Hubble constant H0 = 67.7 km s−1 Mpc−1. All masses are expressed using the quantity M500, which represents the mass contained within a radius R500, where the average density equals 500 times the critical density at the cluster redshift.
2. The NIKA2 maps of COSMOS
2.1. Observations
The N2CLS data set of the COSMOS field corresponds to a total of 195 hours of observations carried out from October 2017 to January 2023. Two groups of 27.0′×34.7′ and 35.0′×28.0′ raster scans, centered on (RA, Dec)J2000 = (10h00m28.81s, +02d17m30.44s), were executed for a total area of ∼1400 arcmin2. The two groups of scans were performed with a speed of 60 ″/s at position angles of 0 and 90 degrees in the RA–Dec coordinate system of the telescope (Bing et al. 2023). In this paper, we concentrate on the 2 mm data, where the signal-to-noise ratio (S/N) for the tSZ signal is larger. The 1.2 mm data were only used for robustness tests and are not discussed in this paper.
2.2. Data reduction pipeline
The raw NIKA2 data per detector array were reduced using the data reduction pipeline described in Ponthieu et al. (2025). It is an evolution of that of Perotto et al. (2020) and is optimized for the detection of faint and small angular size objects. We here summarize its main steps. The raw time-ordered information (TOI) data were first calibrated following the baseline procedure outlined in Perotto et al. (2020). We first transformed the NIKA2 raw data into KID resonance frequency shift (Calvo et al. 2016), and then Uranus was used as a primary calibrator accounting for line-of-sight opacity absorption. Furthermore, the TOIs were corrected from detector correlated atmospheric and electronic noise using a decorrelation procedure. For each 45s subscan, we fitted the TOI of each detector, k, to the following model:
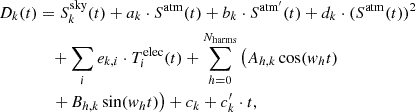 (1)
(1)
where 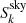 is the astronomical signal at the position observed by detector k. Satm is a template of the atmospheric signal built from all detectors of a given array, and Satm′ its time derivative to account for gradients across the array. The square of the atmospheric model was also added to account for possible nonlinearities of a given KID. To account for electronic noise, we used off-resonance measurements (see Catalano et al. 2014). Off-resonance measurements are sampled as the detector signal and come from reading tone frequencies set apart from any KID resonance. As the electronic noise is strongly correlated between detectors and the off-resonance measurements, the electronic noise templates, Tielec, were constructed by coadding all off-resonances that belong to the same electronic box i. The harmonic term consists of a series of cosine and sine terms with Nharms = 8, which for a 27 second subscan is equivalent to a high-pass filtering above 1/3 Hz. The final terms ck + c′k ⋅ t allow a linear baseline, where t is the time. For each KID k, a single linear regression was performed per subscan, to determine the coefficients ak, bk, ck, c′k, dk, ek, i, Ah, k, and Bh, k, once the templates Satm, Satm′, and Tielec were computed.
is the astronomical signal at the position observed by detector k. Satm is a template of the atmospheric signal built from all detectors of a given array, and Satm′ its time derivative to account for gradients across the array. The square of the atmospheric model was also added to account for possible nonlinearities of a given KID. To account for electronic noise, we used off-resonance measurements (see Catalano et al. 2014). Off-resonance measurements are sampled as the detector signal and come from reading tone frequencies set apart from any KID resonance. As the electronic noise is strongly correlated between detectors and the off-resonance measurements, the electronic noise templates, Tielec, were constructed by coadding all off-resonances that belong to the same electronic box i. The harmonic term consists of a series of cosine and sine terms with Nharms = 8, which for a 27 second subscan is equivalent to a high-pass filtering above 1/3 Hz. The final terms ck + c′k ⋅ t allow a linear baseline, where t is the time. For each KID k, a single linear regression was performed per subscan, to determine the coefficients ak, bk, ck, c′k, dk, ek, i, Ah, k, and Bh, k, once the templates Satm, Satm′, and Tielec were computed.
We observed some residuals in maps that are projected in Nasmyth coordinates, with striping corresponding to the electronic box orientation at 1.2 mm. We decided to correct for this pattern with one template per array.
The cleaned TOIs were then projected on a grid and coadded with weights depending on their noise level, using an inverse variance weighting scheme, to produce the final maps per array. The decorrelation method needs to be performed iteratively because the sky signal can impact the procedure. By subtracting from Sksky the high S/N point source signal from the previous iteration, we can improve the quality of the final maps. We have found that only few iterations are needed for this process toconverge.
The processing parameters (basically the high-pass filtering) were tuned to optimize the detection of point and compact sources, but the filtering is mild enough to allow slightly extended sources to be detected, in particular the SZ effect of compact clusters or groups. We found that the decorrelation procedure induces a filtering at large scales on the final maps (due to the final harmonic term) that we need to take into account in our analysis (see Sect. 3.2). We ran a white noise simulation through the pipeline and computed the transfer function as the ratio between the power spectra of the input white noise map and of the pipeline output. The transfer function is shown in Fig. 1 as a function of the inverse of the angular scale, k. We observe significant filtering for k < 0.5 arcmin−1.
 |
Fig. 1. Transfer function as a function of angular scale for the pipeline used to construct the NIKA2 2 mm COSMOS maps discussed in this paper. The shaded gray regions represent the NIKA2 FoV (left) and instrumental beam (right). |
2.3. Final sky maps
The final 2 mm map was constructed combining the signal from all available observation scans for the final iteration step of the pipeline. In addition, null maps, or jackknife (JK, McIntosh 2016) maps, were constructed by alternately multiplying scan pairs by +1, –1 and coadding them. This effectively subtracts the astrophysical signal to obtain realistic noise maps. These noise maps are used in our cluster detection algorithm presented in Sect. 3.
We decided to limit our analysis to the region inside the black line shown in Fig. 2, discarding the very noisy edges of the map. We chose a region of 877 arcmin2 where the noise is below 1.2 times the median noise value over the full map.
 |
Fig. 2. S/N map of the matched-filtered 2 mm COSMOS map. Positive S/N values corresponding to cluster candidates are shown in blue, matching the colors in Figs. 7 and A.1, as expected for tSZ emission. The angular size of the applied matched filter is equal to the size of the NIKA2 beam at 2 mm (18.5″). The black contour shows the high-quality region discussed in Sect. 2.3. Cluster candidates are highlighted in black squares. Sixteen candidates are detected above a S/N threshold of 4 (see Sect. 3.3). |
In Bing et al. (2023), the same COSMOS data were reduced using the PIIC software (Zylka 2013), and optimized for positive point sources detection. We thus have access to two final sky maps, one produced by PIIC, and one produced using the pipeline described in Sect. 2.2. In the following, we use the map produced with the IDL pipeline described above, which is better adapted for the detection of extended negative signal. Furthermore, we extensively used simulations (see Sect. 4) that required full access to the code, which was more difficult to achieve with the PIIC software.
The 2 mm signal map will be published in a forthcoming publication (Carvajal et al., in prep.). Here we present only zoom-in maps of patches around cluster candidates (see Sect. 6 and Appendix A).
3. Cluster detection
3.1. tSZ signal modeling
The tSZ cluster contribution to the NIKA2 2 mm maps can be modeled as
 (2)
(2)
where x is the spatial dependency and 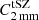 accounts for the tSZ spectrum in Jy/beam units for the 2 mm NIKA2 band (see Ruppin et al. 2018; Kéruzoré et al. 2020; Muñoz-Echeverría et al. 2023). The Compton parameter, y is given by the integration along the line of sight, l, of the cluster electron pressure profile Pe:
accounts for the tSZ spectrum in Jy/beam units for the 2 mm NIKA2 band (see Ruppin et al. 2018; Kéruzoré et al. 2020; Muñoz-Echeverría et al. 2023). The Compton parameter, y is given by the integration along the line of sight, l, of the cluster electron pressure profile Pe:
 (3)
(3)
where σT, me, and c are the Thomson cross-section, the electron rest mass, and the speed of light.
In the following, we assume spherically symmetric clusters and the universal pressure profile (UPP) model defined in Arnaud et al. (2010) as
![Mathematical equation: $$ \begin{aligned} P_e(r)&= 1.65 \times 10^{-3}\,h(z)^{8/3}\,\left[\frac{M_{500}}{3\times 10^{14}\,h_{70}^{-1}\,M_{\odot }}\right]^{2/3+0.12}\nonumber \\&\quad \times p(x) \, h_{70}^2 \, \mathrm keV\,cm^{-3} , \end{aligned} $$](/articles/aa/full_html/2025/08/aa54450-25/aa54450-25-eq6.gif) (4)
(4)
where 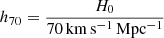 , h(z) the dimensionless Hubble parameter, and p(x) is the generalized Navarro-Frenk-White (gNFW) model proposed by Nagai et al. (2007):
, h(z) the dimensionless Hubble parameter, and p(x) is the generalized Navarro-Frenk-White (gNFW) model proposed by Nagai et al. (2007):
![Mathematical equation: $$ \begin{aligned} p(x) = \frac{P_0}{(c_{500}x)^\gamma \, [1 + (c_{500}x)^\alpha ]^{(\beta -\gamma )/\alpha }}, \end{aligned} $$](/articles/aa/full_html/2025/08/aa54450-25/aa54450-25-eq8.gif) (5)
(5)
with P0 a normalization constant, γ and β the inner and outer slopes of the profile, respectively,  the concentration where rs is the transition radius between the inner and outer regimes of the profile, α the slope of the transition, and
the concentration where rs is the transition radius between the inner and outer regimes of the profile, α the slope of the transition, and 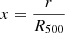 a normalized radius. We considered as free parameters of the model only the cluster redshift, z, and the mass M500. The rest of the parameters were fixed to the values derived in Arnaud et al. (2010):
a normalized radius. We considered as free parameters of the model only the cluster redshift, z, and the mass M500. The rest of the parameters were fixed to the values derived in Arnaud et al. (2010):
![Mathematical equation: $$ \begin{aligned}[P_0, c_{500}, \gamma , \alpha , \beta ] = [8.403 \, h_{70}^{-3/2}, 1.177, 0.3081, 1.0510, 5.4905]. \end{aligned} $$](/articles/aa/full_html/2025/08/aa54450-25/aa54450-25-eq11.gif)
We also assume the following scaling relation between the integrated cluster mass and the integrated Compton parameter at R500:
![Mathematical equation: $$ \begin{aligned} Y_{500} = 2.925\times 10^{-5} I(1) \, h(z)^{2/3} \left[\frac{M_{500}}{3\times 10^{14}\,h_{70}^{-1}\,M_{\odot }}\right]^{5/3+0.12} \, h_{70}^{-1} \, \mathrm{Mpc^2} , \end{aligned} $$](/articles/aa/full_html/2025/08/aa54450-25/aa54450-25-eq12.gif) (6)
(6)
where I(1) = 0.6145, and define the angular size of the cluster as
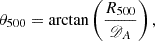 (7)
(7)
where 𝒟A is the angular diameter distance.
The pressure model was integrated along the line of sight and projected on a two-dimensional (2D) grid to obtain a Compton parameter map, y(θ). We converted it to surface brightness (see Eq. (2)) using the  value discussed in Ruppin et al. (2018). We convolved the model map with the NIKA2 2 mm beam and corrected by the transfer function computed in Sect. 2.2 to account for the filtering at large angular scales.
value discussed in Ruppin et al. (2018). We convolved the model map with the NIKA2 2 mm beam and corrected by the transfer function computed in Sect. 2.2 to account for the filtering at large angular scales.
3.2. Matched-filtering
We searched for galaxy cluster candidates in the N2CLS data using a matched-filter technique (Herranz et al. 2002; Melin et al. 2006), to optimally extract the tSZ signal from the map. This method has been used by previous large SZ surveys (see Sect. 1) to blindly detect galaxy clusters, without prior knowledge on their positions. As general spatial features of clusters and the spectral characteristics of the tSZ signal are well known, it is possible to build a source filter that maximizes the cluster signal after filtering. This filter can be applied to a set of multifrequency maps or to a single map. In this analysis, we only used the 2 mm data, as the tSZ signal is expected to be well below the noise in the 1.2 mm map, and the contamination due to point sources, mainly dusty galaxies, is too high. The signal contained in a single frequency map can be described as I(x) = f ⋅ S(x)+N(x) where f accounts for the tSZ spectral distortion at 2 mm, S(x) the spatial template of galaxy clusters and N(x) the noise map. To extract the signal at maximum significance, Haehnelt & Tegmark (1996) have shown that the optimal filter is expressed as Ψ = [τT C−1 τ]−1 τ C−1 with τ being the Fourier transform of the spatial template S convolved with the pipeline’s transfer function (see Sect. 2.2), and C the noise power spectrumC= diag(|N(k)|2).
We used the PyMF Python package described in Erler et al. (2019) as our matched-filter algorithm. For the spatial template S we used the tSZ model presented above and given by Eq. (2). To cover a wide range of possible cluster angular sizes, we produced a set of 15 cluster templates, with typical angular sizes θ500 ∈ [18.5″, 185″]. For simplicity, we kept the redshift constant and varied the cluster’s mass to obtain different cluster sizes. The SZ cluster templates were obtained using the minot Python package (Adam et al. 2020).
 |
Fig. 3. Pixel negative S/N distribution in the match-filtered N2CLS 2 mm signal map (blue) and null map (red). The high negative S/N tail is due to point sources. The hatched gray area shows a small positive S/N tail up to S/N ∼ 5, indicating strong negative signal in the 2 mm signal map, as expected for the SZ sources. |
Galaxy cluster candidates, sorted by decreasing S/N, with S/N > 4.
3.3. Identification of cluster candidates
Using the method detailed in Sect. 3.2, we obtained a set of match-filtered maps where the tSZ signal is enhanced. Using the find_peak routine in the photutils package (Bradley et al. 2023), we identified cluster candidates as peaks above a S/N threshold of 4 in the match-filtered maps. The extraction box size was set to 9 pixels, to only extract one candidate per beam. When a candidate was detected in multiple filtered maps, its center position and S/N were taken from the map where the detection had the highest S/N value.
During the match-filtering process, we also carefully masked bright positive point sources in the map. Indeed, the filtering of these sources can produce ringing artifacts with negative signal, and thus impact cluster detection. Fig. 2 shows, as an example, one of the S/N maps, filtered to optimally extract objects with θ500 = 18.5″. The cluster’s S/N is positive, as the negative sign of the tSZ signal at 2 mm has already been accounted for in the filter. Positive peaks in this map, highlighted in black, can be identified as cluster candidates. To validate the significance of the S/N estimates, we also applied the matched-filtering technique to the null maps (see Sect. 3.4). Fig. 3 shows the pixel S/N distribution for both the match-filtered data and null maps. For the null map (red), we obtain a Gaussian-like distribution consistent with the noise distribution in the data. For the filtered data (blue), we clearly observe a large negative S/N tail corresponding to point sources in the original map. We also observe a positive tail, which corresponds to the clustercandidates.
As presented in Table 1, we detect 16 cluster candidates in the low noise area defined in Sect. 2.3. The mean S/N of our candidate sample is S/N ∼ 4.51, with detections spanning from a S/N of 4–5.31. Fig. A.1 shows a cutout of the 2 mm signal map around each of the cluster candidates. In this case, they appear as compact negative objects in the map, due to the filtering of the signal at large angular scales.
 |
Fig. 4. (Left) Completeness as a function of the mass, M500, for different redshift ranges. We reach 80% completeness at all redshift for M500 > 2 × 1014 M⊙. (Right) Purity as a function of S/N for different redshift ranges. The purity rises quickly with S/N and reaches 60% at S/N ∼ 5. |
3.4. Random detection rate
To estimate the expected number of random detections in the survey area, we generated 1000 noise-only maps without any tSZ signal, and ran the detection algorithm. We find an average of 2.36 random detections above a S/N of 4 per null map. We thus expect an overall purity of 85% for our sample, excluding point source effect. The overall purity increases to 93% above a S/N of 4.2, where we only expect ∼1 random detection. A more detailed assessment of the purity using tSZ simulations is given in Sect. 4.
4. Cluster detection characterization via simulations
4.1. Cluster detection on simulations
To characterize our cluster detection algorithm, we used a set of realistic simulations of the COSMOS field. We first produced 1000 large mock cluster catalogs. We estimated the expected number of clusters in the area considered in our analysis (877 arcmin2), by integrating the Tinker et al. (2008) mass function in bins of redshift (0 < z < 3) and mass (2 × 1013 M⊙ < M500 < 3 × 1015 M⊙). For each catalog, we drew the number of clusters from a Poisson distribution, assigned to each cluster a mass and redshift drawn from the mass function, and a random position in the survey area. To model the cluster signal, we used the model presented in Sect. 3.1. To this thermal SZ map, we added residual atmospheric and instrumental noise by using the null maps described in Sect. 2.
Finally, we added a sky model, the simulated infrared dusty extragalactic sky (SIDES, Béthermin et al. 2017, 2022). SIDES includes galaxy clustering, and produces a catalog of galaxies with a large set of physical parameters. We used the SIDES light cone from the Uchuu simulation (Ishiyama et al. 2021; Gkogkou et al. 2023). Contributions from radio sources and the spatial correlation between simulated components were not taken into account. For each simulated cluster catalog, we produced 104 simulated maps using independent tiles from the SIDES sky model. This prevented any overlapping of bright point sources and massive clusters from impacting the completeness and purity of the sample (see Sects. 4.2 and 4.3).
We estimated the CMB anisotropies contribution to the NIKA2 2 mm map. We note that measurements of the CMB power spectrum,  , at the very high ℓ multipoles sampled by NIKA2 (ℓ > 104) are not available. Furthermore, theoretical models become inaccurate at such small angular scales. Thus, we fitted a power law to the current Planck best-fit CMB power spectrum and extrapolated it to very large ℓ multipoles. Finally, we computed the expected CMB rms signal as
, at the very high ℓ multipoles sampled by NIKA2 (ℓ > 104) are not available. Furthermore, theoretical models become inaccurate at such small angular scales. Thus, we fitted a power law to the current Planck best-fit CMB power spectrum and extrapolated it to very large ℓ multipoles. Finally, we computed the expected CMB rms signal as
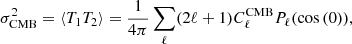 (8)
(8)
where Pℓ are the Legendre polynomials. We find that, accounting for the pipeline transfer function, the CMB induced noise is negligible at the scales probed in this analysis. Thus, it is not accounted for in the following.
We first ran the detection algorithm presented in Sect. 3.2 on the full set of simulated maps, using a 2D Gaussian as template, to detect very bright positive sources in the maps (above S/N = 10). The filtering of these bright sources could produce ringing artifacts with negative signal and impact cluster detection. The detected bright sources were fitted with a 2D Gaussian and subtracted from the simulations. We then convolved these simulated maps with the NIKA2 beam and corrected by the pipeline’s transfer function shown in Fig. 1. The bright sources were added back after filtering. This method was also used in the data reduction pipeline described in Sect. 2.2. Using the transfer function directly is a good compromise, as processing all simulated maps through the pipeline is very long and computationally expensive. There are no big differences between the two processes, as bright sources have been subtracted before filtering.
We then ran the detection algorithm on the simulated maps using the cluster template presented in Sect. 3.1. We identified S/N peaks with S/N > 4 in the resulting match-filtered maps. The position and S/N of each cluster candidate were stored in an output catalog. We defined the matching radius to 20″ – the size of the NIKA2 beam slightly extended for uncertainties as in previous studies (see e.g., Planck Collaboration XXVII 2016). We first matched each input cluster with the closest detection in the output catalog using the astropy function match_to_catalog_sky. Then, we matched the output catalog with the input catalog. We note that we require two-way matches for the following studies. If there were multiple associated input clusters with a single output cluster in a radius the size of the NIKA2 beam around the detection, we chose the best matching cluster based on two criteria: the Y500 value and the cluster-detection separation. This prevented detections from being matched with very faint clusters, which can introduce biases on the sample’s completeness (see Sect. 4.2). From the results, we computed the average number of detections. Taking the median across simulations, we find an average of 26 ± 5 detections for S/N > 4. This is within two Poisson errors from what we have found on the NIKA2 COSMOS data as shown in Sect. 3.3. Therefore, it is compatible with the distribution found from the simulations.
4.2. Completeness
The completeness of a survey is a crucial information to characterize the sample and the performance of the detection algorithm. We define it as the fraction of true cluster detected with respect to the clusters in the input mock catalog,

 |
Fig. 5. Color-coded completeness defined as the probability for a cluster of mass M500 and redshift z to be detected. The number of true clusters detected with respect to the total number of simulated clusters is given for each bin in mass and redshift. |
In Fig. 5 we present, color-coded, the completeness in bins of mass and redshift for the NIKA2 sample as derived from the simulations described above. We observe, as expected, that the detection algorithm performance is limited at low mass and low redshift, for which clusters are faint and extended and thus filtered out by the pipeline transfer function. (see Sect. 2.2). However, at higher redshift, z > 1, we reach a completeness above 80% for M500 > 2 × 1014 M⊙. As the redshift increases, we can effectively detect clusters with lower and lower masses, down to M500 ∼ 1 × 1014 M⊙ at z ∼ 1.5. This is also what we observe in the left panel of Fig. 4, which shows the completeness as a function of M500 for different redshift ranges. The whole sample is complete, C > 80%, for M500 > 2 × 1014 M⊙ in all redshift ranges. We expect to detect most clusters above this mass threshold in the survey area.
These results highlight the interest of high-resolution instruments to target the detection via the tSZ effect of high-redshift and low-mass clusters, which are not accessible with more traditional CMB experiments. We stress also that the limit in cluster mass is mainly imposed by the depth of the survey, which in the case of the COSMOS field was not optimized for clusterdetection.
4.3. Purity
Another key information that we can draw from the simulations is the purity, which we define as the percentage of true detections in the sample

We show in Fig. 4 the purity of the sample as a function of the S/N for different redshift ranges. We find that the purity increases significantly with redshift. For z > 1 the purity is above 70% (90%) for S/N > 5 (>6). From the simulations and the results presented in Sect. 3.4, we have observed that the purity of the sample is much better if point sources are not included in the simulations. Sect. 3.4 describes a best case scenario where the detection is noise limited. Adding point sources shifts the map’s zero-level and introduces ringing artifacts after filtering.
5. Cluster candidates’ validation
We performed an extensive validation of the cluster candidates presented in Sect. 3.3 using existing datasets and archives.
5.1. Cross-matching in NED, SIMBAD and VizieR databases
We searched for known clusters around our candidates in the NED1 and SIMBAD2 databases, where most of the detected clusters are cataloged. We adopted a search radius of 20 arcsecond around each candidate for both databases. In SIMBAD, we only queried objects listed as galaxy clusters or group of galaxies. For NED, after querying all objects in the vicinity of the candidates, we only considered objects listed as a cluster or group of galaxies for the matching. We also performed a systematic query in the VizieR3 database to avoid missing any association with recent cluster catalogs (e.g., DESI, Zou et al. 2021). Our candidates were matched with VizieR catalogs classified as ’Clusters of galaxies’.
We find that, from our sample of 16 cluster candidates, eight are matched with a known cluster. From those, seven were identified in the SIMBAD and NED databases, and one in VizieR. For each cluster candidate, the name of the closest counterpart, the distance to it, and its redshift are given in Table 1. The median redshift of the sample is z ∼ 0.74, with two candidates at high redshift, z > 0.9. We have no match with already detected tSZ clusters from traditional large CMB surveys when querying the SZMC database4. We have seven matches in optical and NIR cluster catalogs like the ALHAMBRA (Ascaso et al. 2015), BMH (Bellagamba et al. 2011), DESI (Zou et al. 2021), COSMOS 10k (Scoville et al. 2007), COSMOS Wall (Iovino et al. 2016), and SCC (Söchting et al. 2012) catalogs. One candidate matches with an X-ray detected cluster in the XMMXCS catalog (Finoguenov et al. 2007). We notice that the highest S/N cluster candidate, NK2-CL J100045.8+020514.3, does not match any known cluster, making it an interesting prospect for follow-up observations. Fig. 6 shows an example optical image of the candidate NK2-CL J100004.4+021148.4, which has an optical counterpart at z = 0.94.
 |
Fig. 6. Hyper Suprime-Cam (HSC) gri image of NK2-CL J100004.4+021148.4. The image is 200″ on a side, with north at the top and east at the left. The contours in white show S/N levels in the match-filtered map from Fig. 2, starting at 2σ and spaced by 1σ. The green contours show the unfiltered tSZ cluster model, as seen in the third panel of Fig. 7. |
To quantify the impact of random associations between our cluster candidates and clusters in the literature, we used our cross-matching procedure described in Sect. 5.1 on our detected simulated clusters from Sect. 4. We find that 24.6% of them are matched with a cluster in the literature, compared to 50% in our observed sample. We find that ∼0.28% are randomly matched with an X-ray cluster, compared to 6.5% for our sample. The SCC catalog (Söchting et al. 2012) has a lot of entries, and thus a non negligible 6.9% chance to match at random. In our sample, 19% are matched with a cluster in the SCC catalog. We tested other matching radii, but found that this one gives the best ratio between true and randomassociations.
5.2. Spectroscopic and photometric redshift catalogs
To complete the database search, we also had access to a semi-public spectroscopic redshift catalog (Khostovan et al. 2025) and a public photometric catalog (Weaver et al. 2022). For both catalogs, we searched for all objects labeled as galaxies, with an available redshift measurement, within a radius of 1 arcmin around each cluster candidate. This search radius is consistent with the average θ500 value we have found for the NIKA2 candidates (see Sect. 6.1 and Table 1). For each of the NIKA2 cluster candidates, we show histograms of spectroscopic (blue) and photometric (red) galaxy redshifts in Fig. B.1. When available, redshift estimates of the cluster candidates are shown as a dashed black line. We observe that in some cases – see for example panels (b), (g), (m), and (p) – the candidates’ redshift estimates are found at the peak of the galaxy redshift distribution. Furthermore, we observe that for some of the unmatched NIKA2 cluster candidates, well-defined redshift peaks are found at relatively high redshift. In some cases, we find multiple well-defined peaks, suggesting a superposition of a low and a high-redshift cluster. A more detailed analysis of these redshift distributions is out of the scope of this paper.
6. Properties of cluster candidates
6.1. Integrated tSZ emission
In order to characterize the tSZ contribution in each cluster candidate, we performed an MCMC analysis by fitting the millimeter emission in the cluster candidate cutout maps (see Appendix A) to the spherical model of the tSZ emission presented in Sect. 4.1. We considered a Gaussian likelihood function as in Muñoz-Echeverría et al. (2023), with the cluster redshift, z, and mass M500 as free parameters. We used flat priors similar to the redshift and mass limits presented in Sect. 3.1. For the cluster candidates with known counterparts, we considered a Gaussian prior on the redshift, based on the values and uncertainties from the literature. We used the emcee package (Foreman-Mackey et al. 2013) to run the MCMC analysis. The convergence of the chains was checked using the  test of Gelman & Rubin (1992). The mass and redshift posterior distributions were then converted to relevant cluster quantities, the integrated tSZ flux Y500 and the cluster’s angular size θ500, using Eqs. (6) and (7).
test of Gelman & Rubin (1992). The mass and redshift posterior distributions were then converted to relevant cluster quantities, the integrated tSZ flux Y500 and the cluster’s angular size θ500, using Eqs. (6) and (7).
 |
Fig. 7. Results of the fit of 200″ × 200″ cutouts of the NIKA2 COSMOS 2 mm map centered on two cluster candidates. NK2-CL J100004.4+021148.4 (top) has a known redshift z = 0.94. In contrast, for NK2-CL J100045.8+020514.3 (bottom) we found no counterpart. The left map corresponds to the 1.2 mm map centered on the cluster candidate. Then, from left to right, we show the 2 mm cutout map for the cluster candidate, the best-fit tSZ model, and residuals. For visualization purposes, the maps have been smoothed with a Gaussian 2D kernel of 6″ and 10″ for the 1.2 mm and 2 mm maps, respectively. The effective FWHM for the 1.2 mm and 2 mm maps is represented as a black disk in the bottom left corner. The white contours have the same scaling as in Fig. 6. We observe that the tSZ effect at the cluster position is negative in the 2 mm band, and not observed at the 1.2 mm band, as expected. |
 |
Fig. 8. θ500–Y500 68% confidence values, for each cluster candidate in the NIKA2 sample. Matched and unmatched candidates (see Sect. 5) are depicted in red and blue, respectively. The redshift of matched counterparts is illustrated with the red colorbar. |
 |
Fig. 9. (Left) NIKA2 matched cluster sample in the mass-redshift plane. Cluster samples from other blind tSZ surveys such as PSZ2 (Planck Collaboration XXVII 2016), ACT DR5 (Hilton et al. 2021), SPT-ECS (Bleem et al. 2020), SPTpol (Huang et al. 2020), and SPT-SZ (Bocquet et al. 2019) are shown for comparison. The 20%, 50%, and 80% completeness contours are shown as solid, dashed, and dotted red lines, respectively. (Right) Cluster surface density as a function of cluster mass. We see that a dedicated NIKA2 survey would complement the currently available tSZ cluster catalogs quite well. |
As an illustration, we present in Fig. 7 examples of the results of the fitting procedure at the map level for two cluster candidates. NK2-CL J100004.4+021148.4 (top) has a known redshift z = 0.94, which is used in the MCMC analysis via a Gaussian prior as discussed before. By contrast, for NK2-CL J100045.8+020514.3 (bottom) we found no counterpart. On the left, we present the 1.2 mm map centered on the cluster candidate, which is dominated by dusty point sources and has negligible tSZ contribution. Then, from left to right we present the NIKA2 2 mm cutout map, the best-fit model, and residuals. We observe that the model is a good fit to the data, and the residual maps are consistent with the local noise level, including point sources. We also notice that the latter are much fainter at 2 mm (as expected for dusty sources), and do not significantly affect the fit.
We show in Fig. 8 the estimated tSZ signal and angular size of each cluster candidate in the Y500 − θ500 plane. The 68% confidence values for Y500 and θ500 and uncertainties can be found in Table 1. Posterior likelihood distributions in the Y500 − θ500 plane are shown in Fig. C.1, presented in Appendix C. We observe that cluster candidates for which a cluster counterpart has been identified, and thus a redshift estimate obtained, present much smaller scatter than unmatched candidates. A tighter redshift prior provides better constraints, as seen from the uncertainties given in Table 1. However, at low redshift, where candidates are expected to have a large angular size, constraining their tSZ flux, mass, and size becomes challenging because much of the signal is filtered out (e.g., candidate NK2-CL J100011.9+021256.5, which has a counterpart at z = 0.24).
6.2. Cluster candidate mass estimates
As discussed above, for matched cluster candidates we can use strong priors on the cluster redshift and then obtain reliable mass estimates from the MCMC analysis presented in Sect. 6.1. We stress that these mass estimates are only valid within the context of the assumed model (see Sect. 3.1), but are still very useful to understand the detection performance and capabilities of NIKA2. The left panel of Fig. 9 shows the mass-redshift distribution for our matched sample and several other large SZ surveys. We also show the 20%, 50%, and 80% completeness of our NIKA2 survey (see Sect. 4) contours as solid, dashed, and dotted red lines. The mass 68% confidence values and uncertainties are also presented in Table 1. We see that our completeness contours are steeper at high redshifts compared to other surveys, as expected from NIKA2’s compact beam. This is because the tSZ flux of distant (and compact) clusters is less affected by beam dilution, making it more sensitive to fainter, lower-mass clusters.
The median mass of the NIKA2 cluster candidate sample is  . Overall, confirmed NIKA2 detections correspond to intermediate and high-redshift, low-mass clusters, probing a region in the mass-redshift plane where clusters are not detected by other millimeter instruments and surveys. As the COSMOS region was selected for being relatively empty, we do not expect to find high-mass clusters. We observe that a dedicated NIKA2 cluster survey would significantly extend current tSZ cluster surveys toward low-mass and high-redshift clusters, as shown in the right panel of Fig. 9.
. Overall, confirmed NIKA2 detections correspond to intermediate and high-redshift, low-mass clusters, probing a region in the mass-redshift plane where clusters are not detected by other millimeter instruments and surveys. As the COSMOS region was selected for being relatively empty, we do not expect to find high-mass clusters. We observe that a dedicated NIKA2 cluster survey would significantly extend current tSZ cluster surveys toward low-mass and high-redshift clusters, as shown in the right panel of Fig. 9.
7. Summary and conclusion
The detection of low-mass, high-redshift galaxy clusters is challenging due to their compact nature, but they provide great insights into deviations from self-similarity at lower cluster masses (Pop et al. 2022), and the formation of large-scale structures.
In this work, we have presented the first blind detection of galaxy clusters at mm wavelength via the tSZ effect at high angular resolution (18.5″) using the NIKA2 camera. We used the existing 195 hours of NIKA2 2 mm data of the COSMOS field, which is part of the N2CLS Large Program. We constructed an adapted 2 mm map of the region and then applied matched-filtering techniques to optimally extract the tSZ signal and identify cluster candidates.
The NIKA2 sample consists of 16 cluster candidates with S/N > 4. Using realistic simulations of the dataset and of the clusters signal, we estimated the completeness and purity of the sample. Purity reaches 60% for S/N > 5. Completeness is above 80% for cluster masses M500 > 2 × 1014 M⊙. For eight of the cluster candidates, we found a counterpart by searching the SIMBAD, NED, or VizieR databases. Out of these eight clusters, seven are matched with optical and infrared clusters, and one with an X-ray cluster. The median redshift of the sample is z ∼ 0.74, with values ranging from 0.24 < z < 1.42, with two detections at high redshift z > 0.9.
We used available photometric and spectroscopic redshift catalogs to complete the previous search. For most of the matched candidates, their redshift estimates match with a peak in the galaxies redshift distribution. Some unmatched candidates also show a well-defined peak at intermediate or high redshift.
The integrated tSZ emission Y500 and angular size θ500 of each cluster candidate were estimated using the universal pressure profile and scaling relations from Arnaud et al. (2010). For the eight cluster candidates with redshift estimates, we derived reliable mass estimates. The median mass of the sample is M500 = 1.54 × 1014 M⊙, spanning from 1.0 to 3.1 × 1014 M⊙ at intermediate to high redshift.
It was then highlighted that the NIKA2 camera enables the detection of high-redshift and low-mass clusters thanks to its very high angular resolution and sensitivity. It is thus possible to explore a region in the mass-redshift plane that is not covered by current large cluster surveys based on tSZ. At sub 20 arcsec scales, the CMB contribution is negligible (see Sect. 4.1) and dusty galaxies can be resolved on a finer scale than the SZ signal (Bing et al. 2023; Ponthieu et al. 2025). This allows us to use single band match-filtering instead of a more standard multifrequency approach in CMB experiments. However, the latter would help reduce possible residual radio source contamination. By contrast, we also notice reduced S/N compared to larger and deeper CMB surveys. This is consistent with the fact that, in general, very large millimeter telescopes typically have a FoV of only a few tens of arcmins and are not designed for survey-mode observations.
Data availability
Table 1 is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/700/A30
The N2CLS final maps and catalogs are available online on the survey’s home page: https://data.lam.fr/n2cls/home
Acknowledgments
We thank Anna Niemiec for useful discussions on optical data images. This work is based on observations carried out under project numbers 192-16 with the IRAM 30m telescope. IRAM is supported by INSU/CNRS (France), MPG (Germany) and IGN (Spain). We would like to thank the IRAM staff for their support during the observation campaigns. The NIKA2 dilution cryostat has been designed and built at the Institut Néel. In particular, we acknowledge the crucial contribution of the Cryogenics Group, and in particular Gregory Garde, Henri Rodenas, Jean-Paul Leggeri, Philippe Camus. This work has been partially funded by the Foundation Nanoscience Grenoble and the LabEx FOCUS ANR-11-LABX-0013. This work is supported by the French National Research Agency under the contracts “MKIDS”, “NIKA” and ANR-15-CE31-0017 and in the framework of the “Investissements d’avenir” program (ANR-15-IDEX-02). This work has been supported by the GIS KIDs. This work has benefited from the support of the European Research Council Advanced Grant ORISTARS under the European Union’s Seventh Framework Programme (Grant Agreement no. 291294). A. R. acknowledges financial support from the Italian Ministry of University and Research - Project Proposal CIR01_00010. R. A. acknowledges support from the Programme National Cosmology et Galaxies (PNCG) of CNRS/INSU with INP and IN2P3, co-funded by CEA and CNES. R. A. was supported by the French government through the France 2030 investment plan managed by the National Research Agency (ANR), as part of the Initiative of Excellence of Université Côte d’Azur under reference number ANR-15-IDEX-01. M.M.E. acknowledges the support of the French Agence Nationale de la Recherche (ANR), under grant ANR-22-CE31-0010. M.D.P. acknowledges PRIN-MIUR grant 20228B938N “Mass and selection biases of galaxy clusters: a multi-probe approach” funded by the European Union Next generation EU, Mission 4 Component 1 CUP C53D2300092 0006. A. Maury acknowledges support the funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant agreement No. 101098309 – PEBBLES). This work made use of Astropy, a community-developed core Python package and an ecosystem of tools and resources for astronomy (Astropy Collaboration 2013, 2018, 2022). This research made use of Photutils, an Astropy package for detection and photometry of astronomical sources (Bradley et al. 2023).
References
- Abell, G. O. 1958, ApJS, 3, 211 [NASA ADS] [CrossRef] [Google Scholar]
- Adam, R., Adane, A., Ade, P. A. R., et al. 2018, A&A, 609, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adam, R., Goksu, H., Leingärtner-Goth, A., et al. 2020, A&A, 644, A70 [EDP Sciences] [Google Scholar]
- Adami, C., Durret, F., Benoist, C., et al. 2010, A&A, 509, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adami, C., Giles, P., Koulouridis, E., et al. 2018, A&A, 620, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Arnaud, M., Pratt, G. W., Piffaretti, R., et al. 2010, A&A, 517, A92 [CrossRef] [EDP Sciences] [Google Scholar]
- Ascaso, B., Benítez, N., Fernández-Soto, A., et al. 2015, MNRAS, 452, 549 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Bellagamba, F., Maturi, M., Hamana, T., et al. 2011, MNRAS, 413, 1145 [NASA ADS] [CrossRef] [Google Scholar]
- Béthermin, M., Wu, H.-Y., Lagache, G., et al. 2017, A&A, 607, A89 [Google Scholar]
- Béthermin, M., Gkogkou, A., Van Cuyck, M., et al. 2022, A&A, 667, A156 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bing, L., Béthermin, M., Lagache, G., et al. 2023, A&A, 677, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bleem, L. E., Stalder, B., Brodwin, M., et al. 2015a, ApJS, 216, 20 [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015b, ApJS, 216, 27 [Google Scholar]
- Bleem, L. E., Bocquet, S., Stalder, B., et al. 2020, ApJS, 247, 25 [Google Scholar]
- Bleem, L. E., Klein, M., Abbot, T. M. C., et al. 2024, Open J. Astrophys., 7, 13 [CrossRef] [Google Scholar]
- Bocquet, S., Dietrich, J. P., Schrabback, T., et al. 2019, ApJ, 878, 55 [Google Scholar]
- Bourrion, O., Benoit, A., Bouly, J., et al. 2016, JINST, 11, P11001 [Google Scholar]
- Bradley, L., Sipőcz, B., Robitaille, T., et al. 2023, https://doi.org/10.5281/zenodo.7946442 [Google Scholar]
- Calvo, M., Benoît, A., Catalano, A., et al. 2016, J. Low Temp. Phys., 184, 816 [CrossRef] [Google Scholar]
- Catalano, A., Calvo, M., Ponthieu, N., et al. 2014, A&A, 569, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Erler, J., Ramos-Ceja, M. E., Basu, K., & Bertoldi, F. 2019, MNRAS, 484, 1988 [Google Scholar]
- Finoguenov, A., Guzzo, L., Hasinger, G., et al. 2007, ApJS, 172, 182 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Stat. Sci., 7, 457 [Google Scholar]
- Gioia, I. M., Maccacaro, T., Schild, R. E., et al. 1990, ApJS, 72, 567 [NASA ADS] [CrossRef] [Google Scholar]
- Gkogkou, A., Béthermin, M., Lagache, G., et al. 2023, A&A, 670, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gonzalez, A. H., Gettings, D. P., Brodwin, M., et al. 2019, ApJS, 240, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Gull, S. F., & Northover, K. J. E. 1976, Nature, 263, 572 [Google Scholar]
- Haehnelt, M. G., & Tegmark, M. 1996, MNRAS, 279, 545 [Google Scholar]
- Hasselfield, M., Hilton, M., Marriage, T. A., et al. 2013, JCAP, 2013, 008 [Google Scholar]
- Herranz, D., Sanz, J. L., Hobson, M. P., et al. 2002, MNRAS, 336, 1057 [Google Scholar]
- Hilton, M., Hasselfield, M., Sifón, C., et al. 2018, ApJS, 235, 20 [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Huang, N., Bleem, L. E., Stalder, B., et al. 2020, AJ, 159, 110 [Google Scholar]
- Iovino, A., Petropoulou, V., Scodeggio, M., et al. 2016, A&A, 592, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ishiyama, T., Prada, F., Klypin, A. A., et al. 2021, MNRAS, 506, 4210 [NASA ADS] [CrossRef] [Google Scholar]
- Kéruzoré, F., Mayet, F., Pratt, G. W., et al. 2020, A&A, 644, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Khostovan, A. A., Kartaltepe, J. S., Salvato, M., et al. 2025, ApJ, submitted [arXiv:2503.00120] [Google Scholar]
- Klein, M., Grandis, S., Mohr, J. J., et al. 2019, MNRAS, 488, 739 [Google Scholar]
- Knobel, C., Lilly, S. J., Iovino, A., et al. 2009, ApJ, 697, 1842 [NASA ADS] [CrossRef] [Google Scholar]
- Kornoelje, K., Bleem, L. E., Rykoff, E. S., et al. 2025, ApJ, submitted [arXiv:2503.17271] [Google Scholar]
- Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24 [Google Scholar]
- Lesci, G. F., Nanni, L., Marulli, F., et al. 2022, A&A, 665, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marriage, T. A., Acquaviva, V., Ade, P. A. R., et al. 2011, ApJ, 737, 61 [Google Scholar]
- McIntosh, A. 2016, arXiv e-prints [arXiv:1606.00497] [Google Scholar]
- Mehrtens, N., Romer, A. K., Hilton, M., et al. 2012, MNRAS, 423, 1024 [NASA ADS] [CrossRef] [Google Scholar]
- Melin, J. B., Bartlett, J. G., & Delabrouille, J. 2006, A&A, 459, 341 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miyazaki, S., Hamana, T., Ellis, R. S., et al. 2007, ApJ, 669, 714 [NASA ADS] [CrossRef] [Google Scholar]
- Muñoz-Echeverría, M., Macías-Pérez, J. F., Pratt, G. W., et al. 2023, A&A, 671, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nagai, D., Kravtsov, A. V., & Vikhlinin, A. 2007, ApJ, 668, 1 [Google Scholar]
- Oguri, M., Lin, Y.-T., Lin, S.-C., et al. 2018, PASJ, 70, S20 [NASA ADS] [Google Scholar]
- Pariiskii, Y. N. 1973, Soviet Ast., 16, 1048 [Google Scholar]
- Perotto, L., Ponthieu, N., Macías-Pérez, J. F., et al. 2020, A&A, 637, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VIII. 2011, A&A, 536, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIX. 2014, A&A, 571, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXXII. 2015, A&A, 581, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ponthieu, N., Désert, F.-X., Beelen, A., et al. 2025, A&A, submitted [Google Scholar]
- Pop, A. R., Hernquist, L., Nagai, D., et al. 2022, MNRAS, submitted [arXiv:2205.11528] [Google Scholar]
- Ruppin, F., Mayet, F., Pratt, G. W., et al. 2018, A&A, 615, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Söchting, I. K., Coldwell, G. V., Clowes, R. G., Campusano, L. E., & Graham, M. J. 2012, MNRAS, 423, 2436 [Google Scholar]
- Staniszewski, Z., Ade, P. A. R., Aird, K. A., et al. 2009, ApJ, 701, 32 [CrossRef] [Google Scholar]
- Sunyaev, R. A., & Zeldovich, Y. B. 1972, Comm. Astrophys. Space Phys., 4, 173 [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Voit, G. M. 2005, Rev. Mod. Phys., 77, 207 [Google Scholar]
- Weaver, J. R., Kauffmann, O. B., Ilbert, O., et al. 2022, ApJS, 258, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Wen, Z. L., Han, J. L., & Liu, F. S. 2012, ApJS, 199, 34 [Google Scholar]
- Wen, Z. L., Han, J. L., & Yang, F. 2018, MNRAS, 475, 343 [Google Scholar]
- Williamson, R., Benson, B. A., High, F. W., et al. 2011, ApJ, 738, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Zatloukal, M., Röser, H. J., Wolf, C., Hippelein, H., & Falter, S. 2007, A&A, 474, L5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zou, H., Gao, J., Xu, X., et al. 2021, ApJS, 253, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Zylka, R. 2013, Astrophysics Source Code Library [record ascl:1303.011] [Google Scholar]
Appendix A: Cluster candidate sample
We present in Fig. A.1 zoom-in views of the COSMOS NIKA2 2 mm map centered at the location of each of the cluster candidates in Table 1. We can distinguish negative signal in the center of each of the maps, as expected for the tSZ effect in a cluster of galaxies. We can also observe some positive point sources corresponding to those discussed in detail in Bing et al. (2023).
 |
Fig. A.1. 200″ × 200″ cutouts of the NIKA2 COSMOS 2 mm map around each cluster candidate. The center of the candidate (red star) shows clear negative signal. Clusters found in the literature are shown as black triangles. For each candidate, we show as white contours the S/N levels in the matched-filtered map where its detection S/N is maximum (see Sect. 3.3). The contours start at ±2σ and are spaced by ±1σ. The maps have been smoothed with a 10″ gaussian kernel for display purposes. |
 |
Fig. A.1. continued. |
Appendix B: Photometric and spectroscopic redshift histograms
In this section, we present the photometric and spectroscopic redshift on patches of 1 arcmin radius centered at the position of the NIKA2 cluster candidates. For NIKA2 cluster candidates with redshift estimates in the literature, the value is represented as a vertical dashed line.
 |
Fig. B.1. Normalized spectroscopic (blue) and photometric (red) redshift counts within a 1 arcmin radius around each cluster candidate. The total number of galaxies, N, within this radius is indicated in the legend of the figure for each redshift type. The number of galaxies per redshift bin is obtained by multiplying N by the normalized counts. If the NIKA2 cluster candidate has a redshift estimate (see Table 1), its redshift is represented by a black dashed line. |
 |
Fig. B.1. continued. |
Appendix C: Results of the MCMC analysis
We show the main results of the fitting procedure for all cluster candidates presented in Sect. 6.1. We present the posterior likelihood distribution in the θ500 − Y500 plane.
 |
Fig. C.1. Corner plot of the θ500 − Y500 posterior maximum likelihood distribution for each of the cluster candidate. A more detailed description of the fitting procedure can be found in Sect. 6.1. The 68% confidence values and uncertainties are given in the figure. We see that the posterior distributions are much better constrained for cluster candidates with a redshift estimate, as expected from the tighter redshift prior. |
 |
Fig. C.1. continued. |
All Tables
All Figures
|
Fig. 1. Transfer function as a function of angular scale for the pipeline used to construct the NIKA2 2 mm COSMOS maps discussed in this paper. The shaded gray regions represent the NIKA2 FoV (left) and instrumental beam (right). |
| In the text | |
|
Fig. 2. S/N map of the matched-filtered 2 mm COSMOS map. Positive S/N values corresponding to cluster candidates are shown in blue, matching the colors in Figs. 7 and A.1, as expected for tSZ emission. The angular size of the applied matched filter is equal to the size of the NIKA2 beam at 2 mm (18.5″). The black contour shows the high-quality region discussed in Sect. 2.3. Cluster candidates are highlighted in black squares. Sixteen candidates are detected above a S/N threshold of 4 (see Sect. 3.3). |
| In the text | |
|
Fig. 3. Pixel negative S/N distribution in the match-filtered N2CLS 2 mm signal map (blue) and null map (red). The high negative S/N tail is due to point sources. The hatched gray area shows a small positive S/N tail up to S/N ∼ 5, indicating strong negative signal in the 2 mm signal map, as expected for the SZ sources. |
| In the text | |
|
Fig. 4. (Left) Completeness as a function of the mass, M500, for different redshift ranges. We reach 80% completeness at all redshift for M500 > 2 × 1014 M⊙. (Right) Purity as a function of S/N for different redshift ranges. The purity rises quickly with S/N and reaches 60% at S/N ∼ 5. |
| In the text | |
|
Fig. 5. Color-coded completeness defined as the probability for a cluster of mass M500 and redshift z to be detected. The number of true clusters detected with respect to the total number of simulated clusters is given for each bin in mass and redshift. |
| In the text | |
|
Fig. 6. Hyper Suprime-Cam (HSC) gri image of NK2-CL J100004.4+021148.4. The image is 200″ on a side, with north at the top and east at the left. The contours in white show S/N levels in the match-filtered map from Fig. 2, starting at 2σ and spaced by 1σ. The green contours show the unfiltered tSZ cluster model, as seen in the third panel of Fig. 7. |
| In the text | |
|
Fig. 7. Results of the fit of 200″ × 200″ cutouts of the NIKA2 COSMOS 2 mm map centered on two cluster candidates. NK2-CL J100004.4+021148.4 (top) has a known redshift z = 0.94. In contrast, for NK2-CL J100045.8+020514.3 (bottom) we found no counterpart. The left map corresponds to the 1.2 mm map centered on the cluster candidate. Then, from left to right, we show the 2 mm cutout map for the cluster candidate, the best-fit tSZ model, and residuals. For visualization purposes, the maps have been smoothed with a Gaussian 2D kernel of 6″ and 10″ for the 1.2 mm and 2 mm maps, respectively. The effective FWHM for the 1.2 mm and 2 mm maps is represented as a black disk in the bottom left corner. The white contours have the same scaling as in Fig. 6. We observe that the tSZ effect at the cluster position is negative in the 2 mm band, and not observed at the 1.2 mm band, as expected. |
| In the text | |
|
Fig. 8. θ500–Y500 68% confidence values, for each cluster candidate in the NIKA2 sample. Matched and unmatched candidates (see Sect. 5) are depicted in red and blue, respectively. The redshift of matched counterparts is illustrated with the red colorbar. |
| In the text | |
|
Fig. 9. (Left) NIKA2 matched cluster sample in the mass-redshift plane. Cluster samples from other blind tSZ surveys such as PSZ2 (Planck Collaboration XXVII 2016), ACT DR5 (Hilton et al. 2021), SPT-ECS (Bleem et al. 2020), SPTpol (Huang et al. 2020), and SPT-SZ (Bocquet et al. 2019) are shown for comparison. The 20%, 50%, and 80% completeness contours are shown as solid, dashed, and dotted red lines, respectively. (Right) Cluster surface density as a function of cluster mass. We see that a dedicated NIKA2 survey would complement the currently available tSZ cluster catalogs quite well. |
| In the text | |
|
Fig. A.1. 200″ × 200″ cutouts of the NIKA2 COSMOS 2 mm map around each cluster candidate. The center of the candidate (red star) shows clear negative signal. Clusters found in the literature are shown as black triangles. For each candidate, we show as white contours the S/N levels in the matched-filtered map where its detection S/N is maximum (see Sect. 3.3). The contours start at ±2σ and are spaced by ±1σ. The maps have been smoothed with a 10″ gaussian kernel for display purposes. |
| In the text | |
|
Fig. A.1. continued. |
| In the text | |
|
Fig. B.1. Normalized spectroscopic (blue) and photometric (red) redshift counts within a 1 arcmin radius around each cluster candidate. The total number of galaxies, N, within this radius is indicated in the legend of the figure for each redshift type. The number of galaxies per redshift bin is obtained by multiplying N by the normalized counts. If the NIKA2 cluster candidate has a redshift estimate (see Table 1), its redshift is represented by a black dashed line. |
| In the text | |
|
Fig. B.1. continued. |
| In the text | |
|
Fig. C.1. Corner plot of the θ500 − Y500 posterior maximum likelihood distribution for each of the cluster candidate. A more detailed description of the fitting procedure can be found in Sect. 6.1. The 68% confidence values and uncertainties are given in the figure. We see that the posterior distributions are much better constrained for cluster candidates with a redshift estimate, as expected from the tighter redshift prior. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.