| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A45 | |
| Number of page(s) | 15 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202555295 | |
| Published online | 02 September 2025 | |
Active galactic nuclei with massive black holes have closer galactic neighbors
k-nearest-neighbor statistics of an unbiased sample at z ∼ 0.03
1
Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, 452 Lomita Mall, Stanford, CA 94305, USA
2
Leibniz-Institut fur Astrophysik Potsdam (AIP), An der Sternwarte 16, D-14482 Potsdam, Germany
3
George P. and Cynthia Woods Mitchell Institute for Fundamental Physics and Astronomy, Texas A&M University, College Station, TX 77845, USA
4
Leiden Observatory, PO Box 9513 2300 RA Leiden, The Netherlands
5
Eureka Scientific, 2452 Delmer Street Suite 100, Oakland, CA 94602-3017, USA
6
Instituto de Astrofísica, Facultad de Física, Pontificia Universidad Católica de Chile, Campus San Joaquín, Av. Vicuña Mackenna 4860, Macul, Santiago 7820436, Chile
7
Korea Astronomy and Space Science Institute, 776, Daedeokdae-ro, Yuseong-gu, Daejeon 34055, Republic of Korea
8
Yale Center for Astronomy & Astrophysics and Department of Physics, Yale University, P.O. Box 208120 New Haven, CT 06520-8120, USA
9
Núcleo de Astronomía de la Facultad de Ingeniería, Universidad Diego Portales, Av. Ejército Libertador 441, Santiago, Chile
10
Kavli Institute for Astronomy and Astrophysics, Peking University, Beijing 100871, PR China
11
Dipartimento di Matematica e Fisica, Università degli Studi Roma Tre, Via della Vasca Navale 84, I-00146 Roma, Italy
12
INAF – Osservatorio Astronomico di Roma, Via Frascati 33, 00040 Monteporzio Catone, Italy
13
Departamento de Física, Universidad Técnica Federico Santa María, Vicuña Mackenna, 3939 San Joaquín, Santiago de Chile, Chile
14
INAF – Osservatorio Astrofisico di Arcetri, Largo Enrico Fermi 5, I-50125 Firenze, Italy
15
Dipartimento di Matematica e Fisica, Università di Roma 3, Via della Vasca Navale, 84, 00146 Roma, RM, Italy
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
April
2025
Accepted:
25
June
2025
Abstract
Context. The large-scale environments of active galactic nuclei (AGNs) reveal important information on the growth and evolution of supermassive black holes (SMBHs). Previous AGN clustering measurements using two-point correlation functions have hinted that AGNs with massive black holes preferentially reside in denser cosmic regions than AGNs with less massive SMBHs. At the same time, little to no dependence on the accretion rate has been found; however, the significance of such trends has been limited.
Aims. Here, we present kth-nearest-neighbor (kNN) statistics of 2MASS galaxies around AGNs from the Swift/BAT AGN Spectroscopic survey. These statistics have been shown to contribute additional higher order clustering information on the cosmic density field.
Methods. By calculating the distances to the nearest seven galaxy neighbors in angular separation to each AGN within two redshift ranges (0.01 < z < 0.03 and 0.03 < z < 0.06), we compared their cumulative distribution functions to that of a randomly distributed sample to demonstrate the sensitivity of this method to the clustering of AGNs. We also split the AGNs into bins of bolometric luminosity, black hole mass, and Eddington ratio (while controlling for redshift) to search for trends between kNN statistics and fundamental AGN properties.
Results. We find that AGNs with massive SMBHs have significantly closer neighbors than AGNs with less massive SMBHs (at the 99.98% confidence level), especially in our lower redshift range. We find less significant trends with luminosity or Eddington ratio. By comparing our results to empirical SMBH-galaxy-halo models implemented in N-body simulations, we show that small-scale kNN trends with black hole mass may go beyond stellar mass dependencies.
Conclusions. This suggests that massive SMBHs in the local universe reside in more massive dark matter halos and denser regions of the cosmic web, which may indicate that environment is important for the growth of SMBHs, bolstering prior conclusions based on correlation functions.
Key words: galaxies: active / galaxies: halos / quasars: supermassive black holes / large-scale structure of Universe
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Supermassive black holes (SMBHs) are ubiquitously found at the centers of massive galaxies. Phases of their mass growth occur when they actively accrete matter, which we observe as active galactic nuclei (AGNs). Studies of nearby galaxies and AGNs over the last few decades have shown that there are a number of correlations between SMBHs and the properties of their host galaxies, thereby suggesting that their growth and evolution are linked in some way (e.g., Kormendy & Ho 2013). At the same time, galaxy properties (e.g., mass, morphology, star formation rate, and size) have been found to correlate with their larger scale dark matter (DM) halo environments, indicating that environment and the dark matter gravitational potential wells impact how galaxies evolve over cosmic time (e.g., Coil et al. 2017; Behroozi et al. 2019; Ghosh et al. 2024). Still, it remains unclear which physical processes drive the growth and coevolution between SMBHs, galaxies, and their DM halos, as well as the role of the larger-scale environment. Characterizing the trends between SMBHs and their host dark matter halos can provide clues to these processes.
The spatial clustering of AGNs probes the large-scale environments of growing SMBHs. Two point statistics are a well-established method of measuring clustering and have provided clues for the link between AGN and large-scale structure across a range of spatial scales. For example, detected AGNs seem to reside in halos that have masses characteristic of galaxy group environments (e.g., Cappelluti et al. 2012). Additionally, there seems to be little or no dependence between the AGN clustering amplitude and luminosity (Krumpe et al. 2012; Allevato et al. 2011; Powell et al. 2020), which would imply that the accretion rate does not depend strongly on the extragalactic environment. However, previous studies from X-ray surveys have shown that there may be trends with black hole mass (MBH); AGNs with more massive SMBHs are typically found to be more clustered than less massive SMBHs (Shirasaki et al. 2016; Powell et al. 2018, 2022; Krumpe et al. 2015, 2023). However, the relatively low number densities of AGN samples have so far limited the significance of such trends. An additional complication is the many AGN selection methods that each have their own biases against the underlying population of accreting SMBHs; AGN clustering has been found to strongly depend on the selection method (e.g., Mendez et al. 2016; Powell et al. 2024). Previous studies have also explored potential clustering differences between obscured and unobscured AGNs, often finding conflicting results (e.g., Powell et al. 2018; DiPompeo et al. 2017; Viitanen et al. 2021); selection biases are likely causing some of the inconsistencies. Additional sources of uncertainties and degeneracies are the conversion between the large-scale clustering amplitude and halo mass (DeGraf & Sijacki 2017; Oogi et al. 2020; Aird & Coil 2021), as well as the question of whether or not underlying host galaxy population is the main driver of AGN clustering (Mendez et al. 2016; Allevato et al. 2019; Krishnan et al. 2020; Powell et al. 2022).
The Swift/BAT Spectroscopic Survey1 is one of the largest and most unbiased samples of local AGNs (z < 0.1; BASS DR2; Koss et al. 2017, 2022a). Its hard X-ray selection (14−195 keV) is sensitive to unobscured and obscured sources (nearly unbiased to obscuring column densities up to NH = 1024 cm−2; e.g., Ricci et al. 2015; Ananna et al. 2022), while the abundance of the multiwavelength follow-up, including optical spectroscopy and soft X-ray observations (Ricci et al. 2017), has allowed for the characterization of the vast majority of BASS AGNs. The survey also overlaps with the Two Micron All- Sky Survey (2MASS) galaxy survey (Huchra et al. 2012), enabling powerful AGN-galaxy cross-correlation measurements that boost clustering statistics (Koss et al. 2010; Cappelluti et al. 2010; Powell et al. 2018). Previous AGN clustering measurements with this sample via the two-point correlation function have found hints that AGNs with more massive SMBHs are more strongly clustered than AGNs with less massive SMBHs on scales of the one-halo term (e.g., < 1 h−1 Mpc; Powell et al. 2022). While the differences were only at a level of 2.3σ, it was shown in Powell et al. (2022) that such trends can constrain the underlying relationship between the SMBH mass and the host dark matter halo mass, which would provide a powerful benchmark for SMBH growth implemented in hydrodynamic simulations. Therefore, characterizing AGN clustering trends at a higher significance would be an invaluable constraint for AGN fueling and feedback processes. While AGN two-point correlation function measurements will improve over time with future larger surveys like Euclid and eROSITA/SDSS-V/4MOST, we can alternatively use additional probes of the cosmic density field of the current samples to better understand the AGN-halo connection.
k-nearest neighbor (kNN) cumulative distribution functions have proven to be a powerful complementary probe of galaxy clustering (e.g., Banerjee & Abel 2020; Wang et al. 2022). The kNN statistics comprise the distributions of distances between a set of points and their kth nearest-neighbors, where many different values of k are explored. With sufficient values of k, these statistics are sensitive to higher order correlation functions on nonlinear physical scales, whereas two-point functions are not (Yuan et al. 2023). This provides additional information on the clustering statistics of galaxies. While kNN statistics have been primarily applied to galaxy and galaxy clusters (e.g., Banerjee & Abel 2020; Wang et al. 2022; Yuan et al. 2023), this method has not yet been fully explored with AGN samples for studying the SMBH-halo connection.
Previous studies of galactic neighbors around AGN have typically used only one to three values for k, for instance, calculating only the first or fifth nearest neighbor distances, which have limited the full potential of such statistics (e.g., Silverman et al. 2009; Perez & Coldwell 2022). Additionally, trends with the fundamental AGN parameters (e.g., mass and accretion rate) have been unexplored with kNN statistics, especially using a large and unbiased sample.
Here, we aim to measure the kNN statistics for the BASS DR2 hard X-ray-selected AGN sample to investigate trends between the fundamental AGN properties and large-scale structure. We measured the angular distances to the first seven neighbors to characterize their environments on small (< 1 h−1 Mpc) and larger (1 − 4 h−1 Mpc) scales in two redshift bins. We tested whether or not there are significant trends with luminosity, black hole mass, and Eddington ratio. We also briefly examined the trends with the obscuring column density to eliminate possible degeneracies in black hole mass differences. The paper is organized as follows. We first describe the AGNs and galaxy samples used in our analyses (Sect. 2), including selection criteria and estimations of black hole masses and luminosities. Next, we explain the methodology of kNN statistics, how we applied it to our data, and the metrics we used to verify our results (Sect. 3). In Sect. 4, we present the findings of our kNN analysis for black hole mass, luminosity, and accretion rate. In Sect. 5, we compare our results to simple empirical models implemented in an N-body simulation. In Sects. 6 and 7, we discuss our results and summarize our findings.
2. Data
2.1. X-ray-selected AGN Sample
The AGN sample is taken from the second data release of the Swift/BAT AGN Spectroscopic Survey (BASS DR2; Koss et al. 2022a,b), which is drawn from the 70-month catalog of detections from the hard X-ray BAT detector aboard the Neil Gehrels Swift observatory (Baumgartner et al. 2013; sensitive from 14 − 195 keV). Excluding beamed and lensed AGN (Marcotulli et al. 2022), the full sample comprises 858 AGN. We selected objects within the redshift range 0.01 < z < 0.06 outside of the galactic plane (|b|> 8°), totaling 419 AGNs.
Optical spectroscopy was obtained for each AGN, enabling secure spectroscopic redshift measurements and black hole mass estimates for 98% of the sample. For the Type 1 AGNs with broad (> 1000 km s−1) emission lines, black hole masses were calculated via the full width at half maximum (FWHM) of Hα, Hβ, Mg II, and/or C IV (Mejía-Restrepo et al. 2022). For Type 2 AGN without broad Balmer lines, bulge velocity dispersions (σ*) were measured by the absorption features in the optical spectra (the Ca H+K, Mg I, and/or the Ca II triplet); the MBH − σ* from Kormendy & Ho (2013) was assumed for MBH (Koss et al. 2022a). Of the 419 AGNs, 412 have black hole mass measurements: 225 from stellar velocity dispersion measurements, 157 from broad line measurements and 30 from the literature via reverberation mapping or dynamical measurements. For this analysis, we use the best MBH measurement available for each AGN. However, a bias has been found between the two main MBH measurement techniques, based on comparing Type 1 MBH estimates obtained with σ* to their broad line measurements (Caglar et al. 2020, 2023). We therefore repeated our analysis using consistently measured MBH values and ensured that this bias is not significantly impacting our main results, which we present in Appendix C.
In addition to optical spectroscopy, each AGN was followed up with soft X-ray observations by Swift, Chandra, and/or XMM-Newton. This has enabled robust measurements of the absorbed column densities (NH) and the intrinsic X-ray luminosities (Ricci et al. 2017). Column densities range from the unabsorbed to Compton-thick level (log NH = 25 [cm−2]). The bolometric luminosities were estimated based on the intrinsic ultra-hard luminosities (L14 − 195) via Lbol = 8 × L14 − 195.
In this work, we calculate the nearest-neighbor statistics in bins of luminosity (Lbol), black hole mass (MBH), and Eddington ratio (λEdd ≡ Lbol/LEdd, where LEdd is the Eddington luminosity). We matched the redshift distributions for each binning scheme, so that the same cosmic volumes were probed and the projection effects were the same for each bin. This was done via the following methodology: we first divided the sample into six equally spaced redshift intervals from z = 0.01 to z = 0.06; then, within each redshift interval, AGNs were further subdivided based on the AGN parameter (Lbol, MBH, or λEdd) into three tertiles. The upper bin was defined as the upper 33% tertile; the lower bin was defined as the lower 33% tertile. We deliberately chose to exclude the middle tertile to minimize overlap and potential contamination in each bin due to measurement uncertainties. For black hole mass estimates, for example, uncertainties range from 0.3 to 0.5 dex (e.g., Koss et al. 2022b; Mejía-Restrepo et al. 2022). The number of AGNs in each subsample is given in Table 1, along with the median redshifts, luminosities, black hole masses, and Eddington ratios. We additionally defined two redshift ranges to perform a tomographic analysis and probe projected spatial scales from 0.1 to 4 h−1 Mpc: 0.01 < z < 0.03 and 0.03 < z < 0.06. We show the distributions of each parameter versus redshift for each parameter bin in Fig. 1.
 |
Fig. 1. AGN parameters (luminosity, black hole mass, and Eddington ratio) vs. redshift for the BASS AGN sample used in our kNN analysis. We categorized the parameter bins into large (sky blue) and small (orange) subsamples to have similar redshift distributions. For each plot, the top histogram shows the redshift distribution of the two bins and the rightward histogram shows the parameter distribution. Luminosity bins are shown at the top, black hole mass bins are in the middle, and Eddington ratio bins are at the bottom. We show the typical parameter uncertainties in the bottom right. |
Median parameter values of the BASS AGN subsamples for which we perform the kNN measurements.
2.2. Galaxy sample
The tracer galaxy sample was taken from the 2MASS Redshift Survey (2MRS; Huchra et al. 2012), which includes over 40k near-infrared-selected galaxies with Ks < 11.75 and spectroscopic redshifts. They cover nearly the full sky (excluding the galactic plane (|b|> 8°). We selected 36 584 in the same redshift range as the AGN sample: 0.01 < z < 0.06. We excluded from the catalog the counterparts of the BASS AGN (within 3″), so that the first nearest-neighbors are separate galaxies and not the BASS AGN themselves. Figure 2 shows the redshift distribution of the 2MASS galaxies compared to the BASS AGNs.
 |
Fig. 2. Redshift distributions of the full AGN sample (blue) and the galaxy catalog (black). The redshift separating our two redshift ranges (0.03) is shown by the dotted line. |
Due to the shallow flux limit of 2MRS, the galaxy number density decreases by 88% between our two redshift ranges. Therefore, each redshift range is sensitive to different environments and spatial scales; at lower z, the survey is more complete and so galaxy neighbors trace more diverse regions of the cosmic web. The higher redshift range is limited to the brightest galaxies, so the neighbor distances are typically larger and the galaxies are less likely to probe the more typical field environments. We show the effect of the flux limit on kNN distances using a volume-limited AGN sample in Appendix A. As a result of this flux limit, we expect less significant AGN kNN trends in the higher-z range due to poorer statistics and less diverse environments probed. We emphasize that since the primary focus of this work is on the relative differences in the clustering signal between AGN subsamples within the same redshift range, this flux limit does not bias the trends with AGN properties. For each comparison, the subsamples (each controlled for redshift) are cross-correlated with the same galaxy samples.
3. k-nearest-neighbor calculation
The kNN statistics refer to cumulative probability distributions of the distances between a set of query points (either a random sample in the volume or a real galaxy sample) and their nearest galaxy neighbors. It is sensitive to all orders of the correlation function (Banerjee & Abel 2020) and it is especially powerful on small, non-linear scales. While the original approach utilizes a random sample of query points, useful for probing underdense regions and testing cosmology (Banerjee & Abel 2020; Wang et al. 2022), the “data-data” approach instead uses the galaxy sample itself as query points; therefore, it is more sensitive to the overdense regions of the cosmic web (Yuan et al. 2023). For the first time, we have performed a cross-correlation between X-ray AGNs and galaxies to calculate the AGN-galaxy kNN.
Following Yuan et al. (2023), Banerjee & Abel (2020, 2022), we measured the angular distances from each BASS AGNs in our sample to their kth nearest 2MRS galaxy neighbor, where k ranges from 1 to 7. By collecting these distances for each AGN in this range of k values, we constructed empirical cumulative distribution functions (CDFs). These CDFs correspond to the probabilities that AGN have their kth nearest galaxy neighbor within a given angular distance. The distances to the AGN neighbors were calculated using the Balltree algorithm from the sklearn Python package. A histogram of the distances using the specified bins was computed for each neighbor, aggregating via a cumulative sum to obtain the CDF.
We sampled the CDFs with several values of angular separations. In this study, we chose to use six total angular bins to construct the CDFs for the full AGN sample and five total bins when splitting the sample by a given parameter. These numbers were chosen as a balance between having sufficient samplings to generate a CDF and avoiding having too many that would increase noise and lead to possible singularity in the covariance matrix. Since the CDFs are normalized such that the largest bin is always one, we exclude it from the analysis. For the full sample of AGNs, this corresponds to having 35 degrees of freedom (five per neighbor). For the other subsamples based on mass, luminosity, or Eddington ratio, we have 28 degrees of freedom (four per neighbor). As discussed in Sect. 3.1, these choices were made to minimize noise and maintain numerical stability in the covariance matrix. Previous work has also shown that the covariance matrix is most reliable for CDF probabilities between 0.1 and 0.9 (Yuan et al. 2023) and so, the angular bins were chosen so that the respective probabilities roughly fell in this range. To maintain this condition across increasing neighbors, the angular samplings were linearly shifted by 0.15° for each neighbor. For the first neighbor, the bins were linearly sampled between 0.1 and 1°.
3.1. Covariance matrix estimation
The uncertainties of the kNN CDFs and the covariances were calculated via jackknife resampling. The survey was partitioned into 49 sky regions, with each patch containing approximately the same number of AGNs and galaxies. The choice of 49 regions was made based on a balance between having sufficiently large regions and having enough samples to approximate a normal distribution to measure the uncertainties. Furthermore, we varied the number of jackknifes, M, from 52 to 92 to ensure that the covariance matrix, and more importantly, the chi-squared value calculated from it, remained relatively stable and was not sensitive to the number of jackknife samples. Across various measurements, we observed that the covariance matrix remained stable for M > 49, and we found that the chi-squared values derived from it were not significantly changed by increasing M past this mark.
The covariance matrix was calculated as follows:
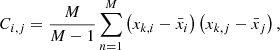
where M is the number of jackknife samples (49), xk, i is the measurement in the ith angular bin-neighbor pair and nth jackknife sample, and 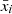 is the mean across all jackknifes for the ith angular bin-neighbor pair. Here, i and j span all possible combinations of angular bins and neighbors, treating each bin-neighbor pair as a distinct data point. Therefore, i and j run from 1 to Nk × Nθ, where Nk is the number of neighbors probed, and Nθ is the number of angular samplings per neighbor. The errors on xi are the square roots of the diagonal of this matrix:
is the mean across all jackknifes for the ith angular bin-neighbor pair. Here, i and j span all possible combinations of angular bins and neighbors, treating each bin-neighbor pair as a distinct data point. Therefore, i and j run from 1 to Nk × Nθ, where Nk is the number of neighbors probed, and Nθ is the number of angular samplings per neighbor. The errors on xi are the square roots of the diagonal of this matrix: 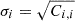 .
.
To ensure the stability and reliability of our measurements, we confirmed that inverting C twice returned our original covariance matrix within floating point error. We also calculated the condition number of each covariance matrix, ensuring it is real and of reasonable magnitude. An exceedingly large condition number would indicate significant noise and instability in the inverse matrix, leading to unreliable chi-squared measurements.
As discussed earlier, four angular samplings per neighbor were chosen (28 degrees of freedom). This number of angular samplings is chosen to sufficiently sample the CDFs, while ensuring that the number of independent elements in the covariance matrix was smaller than the number of jackknifes. Specifically, we have 28 independent elements, sufficiently smaller than our number of jackknifes (49), ensuring statistical reliability.
3.2. Correlated chi-squared calculation
We aim to compare kNN measurements of two subsamples of AGN, binned either by MBH, λEdd, or Lbol, to investigate whether or not the two subsamples are clustered consistently. To estimate the significance of the differences, we calculated the correlated chi-squared between kNN outputs for two samples using their covariance matrices, calculated as follows:
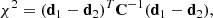
where d1 and d2 are the vectors containing the kNN outputs for each subsample, and C−1 is the inverse of the combined covariance matrix (the sum of the two individual matrices).
We empirically determined the null chi-squared distribution by randomly splitting the AGN sample into subsamples with the same number of AGN (68) as in the average of each defined parameter bin (Lbol, MBH, λEdd). The chi-squared values between the kNN statistics of the subsamples were calculated for each split. This was done 1000 times for each redshift range to characterize the distributions of chi-squared values for random splits, which we used to estimate the significance of our calculated chi-squared values. Differences between the kNN CDFs of examples of randomly split subsamples are shown in Appendix B.
3.3. Random AGN generation
We calculated the kNN statistics for the full sample of AGN compared to a randomly distributed sample to show the excess probability of close galactic neighbors associated with AGN clustering.
We followed the method of Powell et al. (2022) to generate randoms that consider the BASS survey sensitivity map. First, we randomly assigned RA and Dec over the sphere of the sky, excluding the galactic plane (|b|> 8°). Then, we assigned fluxes to each random point following the log N−log S of the survey. We then disregarded the random values whose fluxes were below the survey sensitivities at their angular positions. Finally, redshifts were randomly assigned to the remaining randoms, drawn from the smoothed redshift distribution of the data. The random catalog was constructed to have the ∼10× the number of objects as the AGN. The errors for the random kNN CDF’s were calculated via the standard deviation of 25 random sample realizations.
4. BASS kNN results
4.1. Full AGN sample versus randoms
Figure 3 presents the cumulative distribution functions (CDFs) of the neighbor distances for the full AGN catalog and the randomly generated points for nearest neighbors. The AGN catalog has higher probabilities of having its galaxy neighbors within a given angular distance compared to the random sample for each kth neighbor. This shows that AGN are significantly more clustered than the random points, which is expected since AGNs tend to reside in more massive galaxies (Powell et al. 2018).
 |
Fig. 3. Top panels: CDFs of nearest galaxy angular separations for the AGNs (solid lines) compared to randomly generated points (dashed lines) within two redshift ranges: 0.01 < z < 0.03 (left) and 0.03 < z < 0.06 (right). Each color corresponds to a kth nearest neighbor, from the first nearest (k = 1; purple) to the seventh nearest (k = 7; yellow). For clarity, the fourth and sixth neighbors are excluded. Bottom panels: Random kNN CDF subtracted from the AGN CDF, showing the excess probabilities for AGN to have close galactic neighbors. |
Also shown in Fig. 3 is the difference between the AGN kNN CDF and that of the random catalog, which shows the excess probabilities for the neighbor separations around the AGN. The curves peak at different angular separations in both redshift ranges, showing how each neighbor is sensitive to different physical scales. We note that the absolute CDF values depend strongly on the 2MRS flux limit, the impact of which is demonstrated in Appendix A for each redshift range; however, our results are concerned with the relative CDF differences in each redshift range, rather than the absolute values.
4.2. Trends with luminosity
We first searched for trends between the AGNs extragalactic environments with their bolometric luminosities, as estimated by their hard X-ray emission. In Fig. 4, we show the kNN Cumulative Distribution Functions for the first seven neighbors for both luminosity bins in each redshift range, as well as the differences between the high-Lbol and low-Lbol CDFs. We find that the higher luminosity bin has, in general, closer galactic neighbors than the low-Lbol bin, as indicated by the higher amplitudes of their CDFs. This is especially the case in the lower-z range on small scales for the first and second nearest neighbor (k = 1 and k = 2), with the differences becoming less significant for higher k neighbors. The less-significant trends in the higher-redshift bin are likely due to the sparser galaxy sample, as well as the smaller difference in luminosity between the bright and faint subsamples within this redshift range (as shown in Fig. 1). It should also be noted that the lower luminosity bin in this higher-z range is similar to the high-luminosity bin in the lower-z sample due to the strong trend between luminosity and redshift in the BASS sample. We calculated a correlated chi-squared of 51.21 between the subsamples for the low redshift range and 39.47 for the high redshift range (28 degrees of freedom each).
 |
Fig. 4. kNN CDFs of the two luminosity bins across the low redshift range (left) and higher redshift range (right). The solid lines represent the high luminosity bin and the dashed lines represent the low luminosity bin. The measurements for each galactic neighbor are marked with a different color, and the differences between the high- and low-Lbol CDFs are shown in the bottom panels. |
Bolometric luminosity is a product of two fundamental AGN properties, namely black hole mass and Eddington ratio. Therefore, we next investigate trends between the AGN kNN statistics and those properties to determine whether or not the subtle environmental trends with luminosity are due to more significant trends with either MBH or λEdd.
4.3. Trends with black hole mass
Figure 5 presents the CDFs for our two black hole mass bins for the nearest 7 neighbors. The results are again shown for both redshift ranges. In the case of the lower redshift range (0.01 < z < 0.03), the high-mass bin has higher probabilities of having closer neighbors within a given angular distance than the lower black hole mass bin for all values of k. The differences appear to be most significant for first three galactic neighbors (k = 1, 2, and 3), which corresponds to scales between 0.25 and 0.75 h−1 Mpc (assuming the median redshift of the sample). However, differences are still seen for larger ks that correspond to scales of ∼1.75 h−1 Mpc. The χ2 difference between the two mass bins is 99.57 (with 28 degrees of freedom).
 |
Fig. 5. kNN CDFs of the two black hole mass bins for the low redshift range (left) and higher redshift range (right). The solid lines correspond to the high-BH mass AGN and the dashed lines represent the low-BH mass subsample. The color scheme is the same as in Fig. 4, and the differences between the high- and low-MBH CDFs are shown in the bottom panels. |
For the higher redshift range, AGN with more massive SMBHs are still seen to have closer nearest neighbors (k = 1), although the differences are again less significant than at lower-z. As previously discussed, the weaker significance is likely due to the fact that the 2MASS galaxies become less complete at z > 0.03. Additionally, the scales associated with these first-neighbor angular distances at this redshift range are larger; at ∼1 h−1 Mpc, no longer probing scales of the one-halo term. Therefore, if the environmental differences between high- and low-mass SMBHs are primarily on scales of the one-halo term (as found in Powell et al. 2022), we would expect weaker trends in this higher-z range. For k = 5, 6, and 7, we see little or no significant differences between the two MBH CDFs. However, the high-mass bin does seem to have closer neighbors for k = 1 − 4, corresponding to scales roughly from 1 − 3 h−1 Mpc. The χ2 difference between the two mass bins for all k values in this higher redshift range is 55.86.
The closer neighbors for the high-mass bin correspond to more massive SMBHs being more clustered than less massive SMBHs. This is the case in both redshift bins and was also found using samples with consistently measured MBH (i.e., using only σ*-derived values or using only broad line measurements), shown in Appendix C. It is also consistent with what is found with the correlation function for this sample, as measured in Powell et al. (2022). However, the kNN difference is more significant than what was found with the 2-point function (3.8σ compared to 2.3σ; see Sect. 4.5), showing that kNN statistics have additional information that may better probe small-scale clustering than the correlation function.
4.4. Trends with Eddington Ratio
Finally, we show the kNN CDFs for the two bins of Eddington ratio in Fig. 6. For both redshift ranges, the trends are opposite to what was seen for the BH mass bins; the low-Eddington AGN have slightly closer neighbors than the high-Eddington AGN, especially for lower values of k. However, the differences between the λEdd bins are less significant than when binning by BH mass; we calculate χ2 = 50.82 for the lower-z range, and χ2 = 35.05 for the higher-z range. The differences lie mostly within the estimated uncertainties. We note that the kNN differences are not very sensitive to the bin sizes; defining the bins as being more widely separated from each other (such that there is less contamination in each due to the larger uncertainties on λEdd) results in the same conclusions.
 |
Fig. 6. kNN CDFs of the two Eddington ratio bins for the low redshift range (left) and higher redshift range (right). The solid lines correspond to the high-λEdd AGN and the dashed lines represent the low-λEdd subsample. The color scheme is the same as in Figs. 4 and 5, and the differences between the high- and low-λEdd CDFs are shown in the bottom panels. |
Because the trends are opposite of those found for Lbol, and since 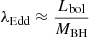 , the differences in the λEdd bins are most likely driven by black hole mass rather than accretion rate. Additionally, these findings are further evidence that the trends in luminosity were driven by black hole mass and not by Eddington ratio, since the differences in λEdd-binned kNN CDFs go in the opposite direction. We discuss this further in Sect. 6.
, the differences in the λEdd bins are most likely driven by black hole mass rather than accretion rate. Additionally, these findings are further evidence that the trends in luminosity were driven by black hole mass and not by Eddington ratio, since the differences in λEdd-binned kNN CDFs go in the opposite direction. We discuss this further in Sect. 6.
4.5. Trend significances
The comparison of the χ2 values for each parameter binning with the empirically-measured null χ2 distribution is shown in Fig. 7 for both redshift ranges. The chi-squared of the lower-zMBH bins is in the 99.98th percentile of random splits, corresponding to a 3.6-σ clustering difference. The luminosity and Eddington ratio bins, on the other hand, are in the 91st percentile. For the higher-z range, the mass binning chi-squared is in the 94th percentile of the higher-z null distribution, while it is 74th and 64th for the luminosity and Eddington ratio bins, respectively. Combining the two redshift ranges results in p values of 8.06 × 10−5 for the mass trends, and p values of 0.05 and 0.08 for the luminosity and Eddington ratio trends, respectively.
 |
Fig. 7. Comparison of our chi-squared values for each binning configuration (red lines) with the null distribution (blue histograms). The latter was obtained by randomly splitting the AGN sample into two subsamples the size of each parameter bin and comparing them. The results for our lower redshift range are shown on top, and the higher-z on the bottom. |
To summarize, while there are < 2σ differences in the nearest neighbor statistics of AGN binned by luminosity and Eddington ratio, kNN differences are much more significant when binning by black hole mass. This may indicate that the extragalactic environment was important for earlier supermassive black hole growth, while being less important for the instantaneous accretion rate.
To further investigate these trends, we looked at the kNN statistics versus the Eddington ratio while controlling for black hole mass and redshift, as well as kNN versus the black hole mass while controlling for Eddington ratio and redshift. We did this for the low redshift bin, where the statistics were better and where the trends were more significant. For each subsampling, we show the distributions of redshift, black hole mass, and Eddington ratio in Figs. 8 (two bins of Eddington ratio) and 9 (two bins of black hole mass). We also show the differences in the nearest-neighbor statistics in these figures, which indicate that differences are again greater for the two MBH bins rather than for the λEdd bins.
 |
Fig. 8. kNN statistics vs. Eddington ratio, controlled for redshift and black hole mass. Top: distributions of redshift, MBH, and λEdd are shown for each bin (high-λEdd in light blue, low-λEdd in dark blue). Bottom: kNN CDF differences between the high-λEdd and low-λEdd bin for the first 7 neighbors. |
 |
Fig. 9. kNN statistics vs. black hole mass, controlled for redshift and Eddington ratio. Top: distributions of redshift, MBH, and λEdd are shown for each bin (high-MBH in light blue, low-MBH in dark blue). Bottom: kNN CDF differences between the high-MBH and low-MBH bin for the first 7 neighbors. |
Additionally, since previous results have found that AGN clustering depends on obscuring column density (Krumpe et al. 2018; Powell et al. 2018), we also examined possible kNN trends with NH while controlling for redshift and black hole mass. We found minimal differences in the kNN statistics as seen in Fig. 10. The independence of clustering with respect to obscuration indicates that observed black hole mass trends are not biased by trends with obscuration. To test whether these results come from the well-known tight correlation between halo mass (Mh) and stellar mass (which MBH is correlated with) or from an additional MBH − Mh connection, we compared our results to toy models implemented into an N-body simulation, detailed in the following section.
 |
Fig. 10. kNN statistics vs. obscuration, controlled for redshift and black hole mass. Top: distributions of redshift, MBH, and NH are shown for each bin (high-NH in light blue, low-NH in dark blue). Bottom: kNN CDF differences between the high-NH and low-NH bin for the first 7 neighbors. |
5. Interpreting kNN MBH trends via N-body mocks
By measuring the nearest-neighbor statistics of AGN in bins of luminosity, black hole mass, and accretion rate, we found that AGN clustering depends most strongly on MBH, while trends with Eddington ratio were less significant. This is especially true in our low-redshift range and it indicates that environment is more related to the cumulative mass growth of the black hole rather than to the instantaneous accretion rate, with the latter being more influenced by internal processes. To interpret the kNN dependence on MBH, we compared the measurements to forward-modeled kNN statistics from N-body simulations, where standard scaling relations were assumed between SMBH mass, galaxy stellar mass, and (sub)halo virial mass.
It has been well-established that SMBH mass correlates with stellar mass (e.g., Kormendy & Ho 2013; Reines & Volonteri 2015; Shankar et al. 2016). While the local relation’s slope, normalization, and scatter are not precisely known due to measurement uncertainties and selection biases, they have been constrained using various samples and techniques. At the same time, the local stellar mass-(sub)halo mass relation (SMHMR) has also been constrained via abundance matching, and the scatter on that relation has also been found to be relatively small at ∼0.2 dex (e.g., Behroozi et al. 2010; Moster et al. 2013). Since more massive galaxies and halos cluster more strongly and have closer neighbors, we test whether the MBHkNN trends are due to these already-established relations, or whether an additional SMBH-halo correlation is required. Evidence of such a correlation between SMBH mass and halo mass has been reported in several previous works (Marasco et al. 2021; Powell et al. 2022; Shankar et al. 2025).
We followed the method in Powell et al. (2022, 2024) to populate mock black holes and galaxies within halo catalogs from a snapshot N-body simulation. For this analysis, we used the Unit simulation (Chuang et al. 2019), which is a 1 h−1 Gpc volume box with a 1.2 × 109 particle mass that assumed Planck cosmology (Planck Collaboration XIII 2016). We used the halo catalog from the a = 0.97810 snapshot and the Rockstar halo finder (Behroozi et al. 2013).
As in Powell et al. (2022), we compared two models: model 1, in which the SMBH mass is assigned purely based on galaxy stellar mass (M*), following a power-law mean relation with log-normal scatter; and model 2, which includes the same MBH − M* relation as Model 1, but additionally incorporates a correlation between MBH and peak host halo virial mass (Mvir) at fixed M*. In the latter case, MBH is tightly correlated with halo mass.
5.1. Mock generation
Here, we summarize the steps to populate the halo catalog with mock SMBHs and galaxies (additional details can be found in Powell et al. 2022, 2024). We also describe our method of selecting the mock data for the kNN calculation.
-
Each halo and subhalo2 with a virial mass Mvir > 5 × 1010 h−1 M⊙ in the halo catalog was assumed to have a mock galaxy at its center. We assigned the stellar masses based on the SMHMR from Behroozi et al. (2010), which includes a log-normal scatter of 0.2 dex on the mean relation.
-
We populated each mock galaxy with a mock SMBH with a mass assigned according to either model 1 or model 2. In both cases, a powerlaw relation between MBH and M* was assumed in the form of log MBH = norm + slope × log10(M*/1011 M⊙), with a uniform lognormal scatter. The results were compared for three different sets of parameters for this relation. In the case of model 2, we used the conditional_abunmatch function from halotools to assign a value for MBH so that, for fixed stellar mass, there was a 1−1 relation between MBH and peak virial (sub)halo mass. This resulted in a tighter overall relationship between the black hole mass and halo mass.
-
We then transformed the coordinates such that the observer was at the center of the simulation box. Using the 3D positions and line-of-sight velocities of the host (sub)halos, we selected the mock SMBHs with ‘redshifts’ between 0.01 and 0.03 to match the data. We then downsampled these mocks to create two black hole mass bins, each with the same distribution of MBH as the data bins. To achieve this, we divided the smoothed data MBH histogram with that of the mocks and then normalized and interpolated it to define the completeness curve (f) as a function of MBH. We then randomly assigned each mock SMBH a number between 0 and 1; if the number was below the f value for its mass, we kept the mock in the sample; otherwise, we masked it. This was done for both large and small MBH bins. The resulting mass distributions of the mocks and data are shown in Fig. 11 for both mass bins.
 |
Fig. 11. Normalized distributions of SMBH mass for each MBH bin (orange and blue for the small and large bin, respectively) for the data (filled histograms) and mocks (step histograms). The mocks were chosen to match the smoothed BASS distributions. |
For each model, we assumed three different parameterizations for the MBH − M* relation based on results from the literature: Reines & Volonteri (2015) (norm = 7.45, slope = 1.05, scatter = 0.3), Shankar et al. (2016) (norm = 7.574, slope = 1.946, scatter = 0.32), and Powell et al. (2022) (norm = 7.91, slope = 0.93, scatter = 0.35).
The mock kNN calculation requires a mock sample of galaxies with the same number density and environments as the 2MASS galaxies. To make the mock galaxy sample, we once again followed the method in Powell et al. (2022), in which mock galaxies were assigned K-band luminosities based on abundance matching using the K-band luminosity function from Jones et al. (2006). This method has been shown to reproduce the autocorrelation function of the 2MRS galaxies (Powell et al. 2018, 2022). However, instead of downsampling this mock catalog to match the total luminosity distribution of the data, as was done for the 2-point correlation function measurement, we divided the mocks into six redshift bins from 0.01 < z < 0.03 (again defining the center of the simulation box as the observer). We then matched the luminosity distribution of the data in each z-bin. This was done to better simulate the flux-limited 2MASS survey, where the luminosity and number density strongly depend on redshift. We verified that the number of mock galaxies in each redshift bin were similar to the data.
5.2. Mock kNN calculation and results
With the mock AGN and mock galaxy sample, we used the same method described in Sect. 3 to calculate the CDFs for the first seven neighbors. We also used the same angular bins as previously described.
The differences between the high- and low-mass CDFs for each model and for the different MBH − M* parameterizations are plotted in Fig. 12 for the first four neighbors since those had the largest differences. As expected, the differences between the two MBH bins are higher for model 2, in which black hole mass is strongly correlated with halo mass. However, the trends also depend on the specific MBH − M* relation assumed. The trends with MBH are stronger for the Reines & Volonteri (2015) parameterization, which assumes a slightly smaller scatter (0.3 dex) than the other two (0.32 and 0.35 dex).
 |
Fig. 12. Differences between the high-mass and low-mass CDFs for the first 4 neighbors. The BASS measurements (black data points) are compared to two toy models: model 1 (blue), which assumes standard MBH − M* and M* − Mhalo relations, and model 2 (orange), which additionally includes a MBH − Mhalo correlation at fixed M*. Different line styles correspond to different assumptions for the MBH − M* relation. |
We find that for the first two neighbors, model 2 better reproduces the angular distance differences than model 1. However, this is not necessarily the case for further neighbors (i.e., higher values of k). This is consistent with results from the correlation function, where model 2 displays a better fit to the AGN clustering for each BH mass bin, but only on scales of the one-halo term (< 1 h−1 Mpc; Powell et al. 2022).
To summarize, the differences in the nearest-neighbor statistics between large and small-mass SMBHs seem to go beyond just correlations with stellar mass on small scales. However, while the toy model assuming a MBH − Mhalo correlation at fixed stellar mass was able to reproduce those differences well when implemented in N-body simulations, it did worse on larger scales (corresponding to higher k values). This may indicate that more sophisticated models are required to reproduce the full clustering trends. Alternatively, secondary parameters beyond mass may drive the AGN clustering statistics.
6. Discussion
In this work, we calculated the kNN statistics of the local BASS DR2 sample, performing a cross-correlation between AGN and 2MRS galaxies by calculating angular distances between the AGN and their first seven galactic neighbors. We found significant differences among the neighbor statistics for two redshift-controlled bins of black hole mass, especially in our lower redshift range (0.01−0.03). The AGNs with massive SMBHs were found to have closer galactic neighbors, with the differences being strongest on the angular scales corresponding to the one-halo term. These findings align with previous results obtained using the two-point correlation function using a similar AGN sample (Powell et al. 2022) as well as other samples (Krumpe et al. 2015, 2023) demonstrating that X-ray selected AGN with massive SMBHs are more clustered than less massive SMBHs.
In addition, we found less significant trends between kNN statistics and the Eddington ratio or luminosity. While the more luminous AGNs tended to have closer galactic neighbors, we show that this is likely due to the MBH dependence, rather than any trends between the environment and accretion rate. This is in agreement with previous works on X-ray AGNs at higher redshifts, which found no relation between AGN activity and environment based on the distances to their 5th, 10th, or 20th neighbors (Silverman et al. 2009) or based on the smoothed overdensity of galaxies (Yang et al. 2018). Optically identified AGN in dwarf galaxies also showed no trends between AGN fraction and environment calculated from the 5th nearest-neighbor distances (Siudek et al. 2023). These findings also agree with previous AGN clustering studies that have found minimal trends (or none altogether) between the amplitude of the AGN correlation function and luminosity and/or Eddington ratio (Allevato et al. 2011; Krumpe et al. 2012); Krumpe:2015; (Powell et al. 2020).
Hydrodynamic simulations have predicted AGN activity (and therefore Eddington ratio) should be enhanced in dense environments due to galaxy interactions, as indicated by the distances to the nearest neighbors (Bhowmick et al. 2020; Kristensen et al. 2021; Singh et al. 2023). Indeed, an excess of mergers and dual AGN have been found in the BASS sample (Koss et al. 2010, 2011, 2012; Koss et al. 2018). However, the AGNs triggered by interactions represent a minority of AGNs in the simulations and observations and so, the predicted clustering excesses may be smaller than the current level of observational statistics so far probed. Future surveys like Euclid will be able to better elucidate the role of environment in triggering AGN, and how it changes over cosmic time.
Some previous studies have found hints suggesting that X-ray obscured AGN may be more clustered than unobscured AGN (e.g., Krumpe et al. 2018; Powell et al. 2018; Koutoulidis et al. 2018), while others have shown they cluster consistently (Viitanen et al. 2021). However, such trends may be partially explained by selection effects; that is, obscured AGN typically need to be intrinsically brighter in order to be detected in a given (soft) X-ray survey. Because more luminous AGN tend to host larger SMBHs, there could be a degeneracy between obscuration, luminosity, and black hole mass that contributes to the observed clustering trends found in other samples. Our analysis found no significant difference in kNN statistics between obscured and unobscured AGN when controlling for black hole mass and redshift. This may indicate that the previously found clustering differences between obscured and unobscured AGN are impacted (or driven) by the black hole mass dependence.
The trend that more massive SMBHs tend to have closer neighbors has implications for our understanding of SMBH growth. By implementing simple models into a snapshot N-body simulation that assumes empirical relationships between the masses of SMBHs, galaxies, and (sub)halos, we found that the kNN trends with MBH depended both on the input MBH − M* relation, as well as the correlation between MBH and Mhalo at fixed M*. While neither model assumed (model 1 with no additional MBH − Mhalo correlation and model 2 with a one-to-one MBH − Mhalo relation at fixed M*) could fully reproduce trends in the data, model 2 was preferred on small scales (i.e., k = 1, 2) while Model 1 was preferred on larger scales (k > 4). Better clustering statistics, as well as a better constraint on the MBH − M* scatter, are required to distinguish between these models and to infer the MBH − Mhalo connection.
A tight relationship between the SMBH mass and halo mass has been suggested in previous studies using dynamical black hole and halo mass measurements of individual nearby galaxies (Ferrarese 2002; Marasco et al. 2021). Such a correlation between SMBH mass and their host halos may suggest that local density plays a role in SMBH growth of SMBHs during earlier epochs. Denser cosmic regions may facilitate more rapid growth of SMBH earlier in cosmic time, via the availability of more gas or more frequent galaxy interactions. This is consistent with some hydrodynamic simulations that show environmental AGN triggering is more enhanced at higher redshifts (e.g., Bhowmick et al. 2020). Similarly, it may imply that the galaxies with more massive SMBHs have undergone a recent merger that rapidly increased their SMBH mass, as those galaxies tend to have closer neighbors. Alternatively, a direct MBH − Mhalo correlation could suggest that AGN feedback is relevant on halo scales. It has been suggested that the total amount of kinetic feedback and halo mass together regulate the growth of the SMBH and galaxy. This picture has been motivated by several observations (Chen et al. 2020; Marasco et al. 2021) and seen in hydrodynamic simulations as well (Bower et al. 2017; Li et al. 2024). Better probes of the MBH − Mhalo relation for various galaxy types and at several cosmic epochs will allow for this scenario to be further tested.
7. Summary and conclusions
In this work, we calculated the nearest-neighbor statistics of AGN from the hard-X-ray selected BASS DR2 sample using galaxies from the 2MASS redshift survey. We searched for clustering trends with luminosity, black hole mass, and accretion rate by splitting the AGN sample into several bins, and by computing angular distances to the first seven galactic neighbors in two redshift ranges. Our main conclusions are as follows:
-
Massive SMBHs have a higher probability of having closer neighbors than less massive SMBHs (at the 99.98% confidence level). This is especially significant in the lower redshift bin (0.01 < z < 0.03) and on smaller scales of the one-halo term.
-
Luminous AGNs tend to have closer neighbors than less-luminous AGNs; however, we found that these differences were primarily driven by trends with MBH and not the accretion rate. We found no significant kNN differences between AGNs with a high and low Eddington ratio when controlling for MBH and z.
-
The MBHkNN differences are more significant than those found with correlation function, showing that kNN statistics provide additional and complementary information on the surrounding cosmic density field.
-
Toy models implemented into N-body simulations suggest that clustering differences with MBH on small scales may go beyond those attributed to correlations with the stellar mass.
Large spectroscopic samples of AGNs and galaxies will soon be provided by surveys such as Euclid and eROSITA/SDSS-V/4MOST. Measuring the kNN statistics of these samples will enable us to robustly probe the SMBH-halo connection, as well as the environmental dependence of AGN activity across several cosmic epochs. This will provide powerful constraints on AGN fueling and feedback over time.
A subhalo is a dark matter halo that resides within the virial radius of a larger halo.
Acknowledgments
We acknowledge the work done by the Swift/BAT team to make this project possible. This paper is part of the Swift BAT AGN Spectroscopic Survey. KO acknowledges support from the Korea Astronomy and Space Science Institute under the R&D program (Project No. 2025-1-831-01), supervised by the Korea AeroSpace Administration, and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (RS-2025-00553982). IMC acknowledges support from ANID programme FONDECYT Postdoctorado 3230653. MS acknowledges financial support from the Italian Ministry for University and Research, through the grant PNRR-M4C2- I1.1-PRIN 2022-PE9-SEAWIND: Super-Eddington Accretion: Wind, INflow and Disk-F53D23001250006-NextGenerationEU.
References
- Aird, J., & Coil, A. L. 2021, MNRAS, 502, 5962 [NASA ADS] [CrossRef] [Google Scholar]
- Allevato, V., Finoguenov, A., Cappelluti, N., et al. 2011, ApJ, 736, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Allevato, V., Viitanen, A., Finoguenov, A., et al. 2019, A&A, 632, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ananna, T. T., Weigel, A. K., Trakhtenbrot, B., et al. 2022, ApJS, 261, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Banerjee, A., & Abel, T. 2020, MNRAS, 500, 5479 [NASA ADS] [CrossRef] [Google Scholar]
- Banerjee, A., & Abel, T. 2022, MNRAS, 519, 4856 [Google Scholar]
- Baumgartner, W. H., Tueller, J., Markwardt, C. B., et al. 2013, ApJS, 207, 19 [Google Scholar]
- Behroozi, P. S., Conroy, C., & Wechsler, R. H. 2010, ApJ, 717, 379 [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P., Wechsler, R. H., Hearin, A. P., & Conroy, C. 2019, MNRAS, 488, 3143 [NASA ADS] [CrossRef] [Google Scholar]
- Bhowmick, A. K., Blecha, L., & Thomas, J. 2020, ApJ, 904, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Bower, R. G., Schaye, J., Frenk, C. S., et al. 2017, MNRAS, 465, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Caglar, T., Burtscher, L., Brandl, B., et al. 2020, A&A, 634, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caglar, T., Koss, M. J., Burtscher, L., et al. 2023, ApJ, 956, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Cappelluti, N., Ajello, M., Burlon, D., et al. 2010, ApJ, 716, L209 [NASA ADS] [CrossRef] [Google Scholar]
- Cappelluti, N., Allevato, V., & Finoguenov, A. 2012, Adv. Astron., 2012, 853701 [Google Scholar]
- Chen, Z., Faber, S. M., Koo, D. C., et al. 2020, ApJ, 897, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Chuang, C.-H., Yepes, G., Kitaura, F.-S., et al. 2019, MNRAS, 487, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Coil, A. L., Mendez, A. J., Eisenstein, D. J., & Moustakas, J. 2017, ApJ, 838, 87 [Google Scholar]
- DeGraf, C., & Sijacki, D. 2017, MNRAS, 466, 3331 [NASA ADS] [CrossRef] [Google Scholar]
- DiPompeo, M. A., Hickox, R. C., Eftekharzadeh, S., & Myers, A. D. 2017, MNRAS, 469, 4630 [NASA ADS] [CrossRef] [Google Scholar]
- Ferrarese, L. 2002, ApJ, 578, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ghosh, A., Urry, C. M., Powell, M. C., et al. 2024, ApJ, 971, 142 [Google Scholar]
- Huchra, J. P., Macri, L. M., Masters, K. L., et al. 2012, ApJS, 199, 26 [Google Scholar]
- Jones, D. H., Peterson, B. A., Colless, M., & Saunders, W. 2006, MNRAS, 369, 25 [Google Scholar]
- Kormendy, J., & Ho, L. C. 2013, ARA&A, 51, 511 [Google Scholar]
- Koss, M., Mushotzky, R., Veilleux, S., & Winter, L. 2010, ApJ, 716, L125 [Google Scholar]
- Koss, M., Mushotzky, R., Veilleux, S., et al. 2011, ApJ, 739, 57 [Google Scholar]
- Koss, M., Mushotzky, R., Treister, E., et al. 2012, ApJ, 746, L22 [Google Scholar]
- Koss, M., Trakhtenbrot, B., Ricci, C., et al. 2017, ApJ, 850, 74 [Google Scholar]
- Koss, M. J., Blecha, L., Bernhard, P., et al. 2018, Nature, 563, 214 [Google Scholar]
- Koss, M. J., Ricci, C., Trakhtenbrot, B., et al. 2022a, ApJS, 261, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Koss, M. J., Trakhtenbrot, B., Ricci, C., et al. 2022b, ApJS, 261, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Koutoulidis, L., Georgantopoulos, I., Mountrichas, G., et al. 2018, MNRAS, 481, 3063 [NASA ADS] [CrossRef] [Google Scholar]
- Krishnan, C., Almaini, O., Hatch, N. A., et al. 2020, MNRAS, 494, 1693 [NASA ADS] [CrossRef] [Google Scholar]
- Kristensen, M. T., Pimbblet, K. A., Gibson, B. K., Penny, S. J., & Koudmani, S. 2021, ApJ, 922, 127 [Google Scholar]
- Krumpe, M., Miyaji, T., Coil, A. L., & Aceves, H. 2012, ApJ, 746, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Husemann, B., et al. 2015, ApJ, 815, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Coil, A. L., & Aceves, H. 2018, MNRAS, 474, 1773 [CrossRef] [Google Scholar]
- Krumpe, M., Miyaji, T., Georgakakis, A., et al. 2023, ApJ, 952, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Li, H., Chen, Y., Wang, H., & Mo, H. 2024, ArXiv e-prints [arXiv:2409.06208] [Google Scholar]
- Marasco, A., Cresci, G., Posti, L., et al. 2021, MNRAS, 507, 4274 [NASA ADS] [CrossRef] [Google Scholar]
- Marcotulli, L., Ajello, M., Urry, C. M., et al. 2022, ApJ, 940, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Mejía-Restrepo, J. E., Trakhtenbrot, B., Koss, M. J., et al. 2022, ApJS, 261, 5 [CrossRef] [Google Scholar]
- Mendez, A. J., Coil, A. L., Aird, J., et al. 2016, ApJ, 821, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Moster, B. P., Naab, T., & White, S. D. M. 2013, MNRAS, 428, 3121 [Google Scholar]
- Oogi, T., Shirakata, H., Nagashima, M., et al. 2020, MNRAS, 497, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Perez, N. R., & Coldwell, G. 2022, MNRAS, 513, 5344 [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Powell, M. C., Cappelluti, N., Urry, C. M., et al. 2018, ApJ, 858, 110 [Google Scholar]
- Powell, M. C., Urry, C. M., Cappelluti, N., et al. 2020, ApJ, 891, 41 [CrossRef] [Google Scholar]
- Powell, M. C., Allen, S. W., Caglar, T., et al. 2022, ApJ, 938, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Powell, M. C., Krumpe, M., Coil, A., & Miyaji, T. 2024, A&A, 686, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reines, A. E., & Volonteri, M. 2015, ApJ, 813, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Ricci, C., Ueda, Y., Koss, M. J., et al. 2015, ApJ, 815, L13 [Google Scholar]
- Ricci, C., Trakhtenbrot, B., Koss, M. J., et al. 2017, ApJS, 233, 17 [Google Scholar]
- Shankar, F., Bernardi, M., Sheth, R. K., et al. 2016, MNRAS, 460, 3119 [NASA ADS] [CrossRef] [Google Scholar]
- Shankar, F., Bernardi, M., Roberts, D., et al. 2025, MNRAS, 541, 2070 [Google Scholar]
- Shirasaki, Y., Komiya, Y., Ohishi, M., & Mizumoto, Y. 2016, PASJ, 68, 23 [Google Scholar]
- Silverman, J. D., Kovac, K., Knobel, C., et al. 2009, ApJ, 695, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Singh, A., Park, C., Choi, E., et al. 2023, ApJ, 953, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Siudek, M., Mezcua, M., & Krywult, J. 2023, MNRAS, 518, 724 [Google Scholar]
- Viitanen, A., Allevato, V., Finoguenov, A., Shankar, F., & Marsden, C. 2021, MNRAS, 507, 6148 [Google Scholar]
- Wang, Y., Banerjee, A., & Abel, T. 2022, MNRAS, 514, 3828 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Brandt, W. N., Darvish, B., et al. 2018, MNRAS, 480, 1022 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Zamora, A., & Abel, T. 2023, MNRAS, 522, 3935 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Effects of flux-limited 2MRS galaxy sample on kNN distances
The 2MRS galaxy sample used in this study is flux-limited, which introduces certain effects on the kNN distance measurements. Specifically, as the redshift increases, the survey completeness becomes increasingly limited to only the most luminous (and massive) galaxies, resulting in a lower overall number density. There are ∼20k galaxies in the low-z range (0.01 < z < 0.03) versus ∼17k in the higher-z range (0.03 < z < 0.06), corresponding to a∼88% decrease in spatial density.
To show the difference of the kNN distances for each redshift range due only to the 2MRS flux limit, we select a volume-limited sample of AGN (log LX > 44.5 [erg/s]) and compute the angular distances to the first 7 neighbors. Figure A.1 shows that AGN in the lower redshift range tend to have systematically closer neighbors than those in the higher redshift range. This supports the idea that, due to the 2MRS flux limit, the two redshift ranges analyzed in this study (0.01 < z < 0.03 and 0.03 < z < 0.06) effectively probe different physical scales. In the lower redshift range, the higher number density of galaxies allows for kNN measurements on smaller angular scales, while the higher redshift range, with its sparser galaxy sample, extends the neighbor distances to larger scales.
 |
Fig. A.1. Cumulative distribution functions (CDFs) of the kNN distances for a volume-limited AGN sample in the low-redshift range (0.01 < z < 0.03, dashed lines) and higher-redshift range (0.03 < z < 0.06, solid lines). The top plot shows the CDFs as a function of angular distance, while the bottom plot shows the corresponding physical projected separation assuming the average redshift of each z−bin. AGN in the lower redshift range have closer galactic neighbors than AGN in the higher redshift range due to the 2MRS flux limit. |
Appendix B: Random subsample splits
As discussed in Sect. 3, we split the low-redshift sample (0.01 < z < 0.03) into multiple random subsamples to ensure that observed trends were not driven by sample variance. Each subsample contained 68 AGN, roughly the number in each parameter bin of our main analysis. We show in Fig. B.1 10 examples of the kNN differences between the random subsamples. These differences are not significant, and notably smaller than those calculated for the parameter bins.
 |
Fig. B.1. kNN CDF differences vs. the angular scale of randomly-selected subsamples of the low-redshift BASS AGN (0.01 < z < 0.03). Each subsample contains 68 AGN to roughly match the number in each bin of AGN property. |
Appendix C: kNN Statistics using consistently measured MBH
The BASS sample uses several mass measurement techniques due to both Type 1 and Type 2 AGN included in the sample. While broad line measurements available from Type 1 spectra are typically preferred over those estimated from velocity dispersion, Caglar et al. (2023) found that extinction can bias these measurements by a significant margin. Additionally, the Kormendy & Ho (2013)MBH − σ* relation used to infer MBH in the Type 2 AGN has been found to be too steep for this sample based on Type 1 velocity dispersion measurements (Caglar et al. 2023).
To test whether these biases affect our kNN results, we repeat the measurements using the sample of BASS Type1 and Type 2 AGN with σ* measurements. We define MBH and Eddington ratio bins by the values obtained from the velocity dispersions using the MBH − σ* as measured for this sample in (Caglar et al. 2020) and the same method as described in Sect. 2. In doing so, a consistent measure of MBH is used. Figure C.1 shows the kNN trends with MBH and λEdd using these alternative values. The kNN differences are consistent with those found in Sect. 4 from Figs. 5 and 6.
 |
Fig. C.1. kNN CDFs as a function of black hole mass (top) and Eddington ratio (bottom), using values derived from stellar velocity dispersion measurements (Caglar et al. 2023). Left plots show results for AGN in the low-redshift range, and right panels show the higher redshift range. The color scheme is the same as in Figs. 4, 5 and 6, and differences are again shown in the bottom panels. |
Finally, we measured the trends using only Type 1 AGN with broad line MBH and again found consistent results, shown in Fig. C.2. Despite the measurements being noisier due to the smaller sample, the massive black holes still have significantly closer neighbors than the less massive bin. We conclude that mass measurement biases are not causing the kNN trends we observed in this work.
 |
Fig. C.2. kNN CDFs as a function of black hole mass (top) and Eddington ratio (bottom), using values derived from the Hα or Hβ broad lines. Left plots show results for AGN in the low-redshift range, and right panels show the higher redshift range. The color scheme is the same as in Figs. 4, 5 and 6, and differences are again shown in the bottom panels. |
All Tables
Median parameter values of the BASS AGN subsamples for which we perform the kNN measurements.
All Figures
|
Fig. 1. AGN parameters (luminosity, black hole mass, and Eddington ratio) vs. redshift for the BASS AGN sample used in our kNN analysis. We categorized the parameter bins into large (sky blue) and small (orange) subsamples to have similar redshift distributions. For each plot, the top histogram shows the redshift distribution of the two bins and the rightward histogram shows the parameter distribution. Luminosity bins are shown at the top, black hole mass bins are in the middle, and Eddington ratio bins are at the bottom. We show the typical parameter uncertainties in the bottom right. |
| In the text | |
|
Fig. 2. Redshift distributions of the full AGN sample (blue) and the galaxy catalog (black). The redshift separating our two redshift ranges (0.03) is shown by the dotted line. |
| In the text | |
|
Fig. 3. Top panels: CDFs of nearest galaxy angular separations for the AGNs (solid lines) compared to randomly generated points (dashed lines) within two redshift ranges: 0.01 < z < 0.03 (left) and 0.03 < z < 0.06 (right). Each color corresponds to a kth nearest neighbor, from the first nearest (k = 1; purple) to the seventh nearest (k = 7; yellow). For clarity, the fourth and sixth neighbors are excluded. Bottom panels: Random kNN CDF subtracted from the AGN CDF, showing the excess probabilities for AGN to have close galactic neighbors. |
| In the text | |
|
Fig. 4. kNN CDFs of the two luminosity bins across the low redshift range (left) and higher redshift range (right). The solid lines represent the high luminosity bin and the dashed lines represent the low luminosity bin. The measurements for each galactic neighbor are marked with a different color, and the differences between the high- and low-Lbol CDFs are shown in the bottom panels. |
| In the text | |
|
Fig. 5. kNN CDFs of the two black hole mass bins for the low redshift range (left) and higher redshift range (right). The solid lines correspond to the high-BH mass AGN and the dashed lines represent the low-BH mass subsample. The color scheme is the same as in Fig. 4, and the differences between the high- and low-MBH CDFs are shown in the bottom panels. |
| In the text | |
|
Fig. 6. kNN CDFs of the two Eddington ratio bins for the low redshift range (left) and higher redshift range (right). The solid lines correspond to the high-λEdd AGN and the dashed lines represent the low-λEdd subsample. The color scheme is the same as in Figs. 4 and 5, and the differences between the high- and low-λEdd CDFs are shown in the bottom panels. |
| In the text | |
|
Fig. 7. Comparison of our chi-squared values for each binning configuration (red lines) with the null distribution (blue histograms). The latter was obtained by randomly splitting the AGN sample into two subsamples the size of each parameter bin and comparing them. The results for our lower redshift range are shown on top, and the higher-z on the bottom. |
| In the text | |
|
Fig. 8. kNN statistics vs. Eddington ratio, controlled for redshift and black hole mass. Top: distributions of redshift, MBH, and λEdd are shown for each bin (high-λEdd in light blue, low-λEdd in dark blue). Bottom: kNN CDF differences between the high-λEdd and low-λEdd bin for the first 7 neighbors. |
| In the text | |
|
Fig. 9. kNN statistics vs. black hole mass, controlled for redshift and Eddington ratio. Top: distributions of redshift, MBH, and λEdd are shown for each bin (high-MBH in light blue, low-MBH in dark blue). Bottom: kNN CDF differences between the high-MBH and low-MBH bin for the first 7 neighbors. |
| In the text | |
|
Fig. 10. kNN statistics vs. obscuration, controlled for redshift and black hole mass. Top: distributions of redshift, MBH, and NH are shown for each bin (high-NH in light blue, low-NH in dark blue). Bottom: kNN CDF differences between the high-NH and low-NH bin for the first 7 neighbors. |
| In the text | |
|
Fig. 11. Normalized distributions of SMBH mass for each MBH bin (orange and blue for the small and large bin, respectively) for the data (filled histograms) and mocks (step histograms). The mocks were chosen to match the smoothed BASS distributions. |
| In the text | |
|
Fig. 12. Differences between the high-mass and low-mass CDFs for the first 4 neighbors. The BASS measurements (black data points) are compared to two toy models: model 1 (blue), which assumes standard MBH − M* and M* − Mhalo relations, and model 2 (orange), which additionally includes a MBH − Mhalo correlation at fixed M*. Different line styles correspond to different assumptions for the MBH − M* relation. |
| In the text | |
|
Fig. A.1. Cumulative distribution functions (CDFs) of the kNN distances for a volume-limited AGN sample in the low-redshift range (0.01 < z < 0.03, dashed lines) and higher-redshift range (0.03 < z < 0.06, solid lines). The top plot shows the CDFs as a function of angular distance, while the bottom plot shows the corresponding physical projected separation assuming the average redshift of each z−bin. AGN in the lower redshift range have closer galactic neighbors than AGN in the higher redshift range due to the 2MRS flux limit. |
| In the text | |
|
Fig. B.1. kNN CDF differences vs. the angular scale of randomly-selected subsamples of the low-redshift BASS AGN (0.01 < z < 0.03). Each subsample contains 68 AGN to roughly match the number in each bin of AGN property. |
| In the text | |
|
Fig. C.1. kNN CDFs as a function of black hole mass (top) and Eddington ratio (bottom), using values derived from stellar velocity dispersion measurements (Caglar et al. 2023). Left plots show results for AGN in the low-redshift range, and right panels show the higher redshift range. The color scheme is the same as in Figs. 4, 5 and 6, and differences are again shown in the bottom panels. |
| In the text | |
|
Fig. C.2. kNN CDFs as a function of black hole mass (top) and Eddington ratio (bottom), using values derived from the Hα or Hβ broad lines. Left plots show results for AGN in the low-redshift range, and right panels show the higher redshift range. The color scheme is the same as in Figs. 4, 5 and 6, and differences are again shown in the bottom panels. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.