| Issue |
A&A
Volume 705, January 2026
|
|
|---|---|---|
| Article Number | A213 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202554530 | |
| Published online | 26 January 2026 | |
NIKA2 Cosmological Legacy Survey. First measurement of the confusion noise at the IRAM 30 m telescope
1
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange Nice, France
2
School of Physics and Astronomy, Cardiff University Queen’s Buildings The Parade Cardiff CF24 3AA, UK
3
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM 91191 Gif-sur-Yvette, France
4
Institut de Radioastronomie Millimétrique (IRAM), Avenida Divina Pastora 7 Local 20 E-18012 Granada, Spain
5
Aix Marseille Univ, CNRS, CNES, LAM (Laboratoire d’Astrophysique de Marseille) Marseille, France
6
Institut Néel, CNRS, Université Grenoble Alpes Grenoble, France
7
Université de Strasbourg, CNRS, Observatoire astronomique de Strasbourg, UMR 7550 67000 Strasbourg, France
8
Astronomy Centre, Department of Physics and Astronomy, University of Sussex Brighton BN1 9QH, UK
9
Institut de RadioAstronomie Millimétrique (IRAM) Grenoble, France
10
Univ. Grenoble Alpes, CNRS, Grenoble INP, LPSC-IN2P3, 53 avenue des Martyrs 38000 Grenoble, France
11
Dipartimento di Fisica, Sapienza Università di Roma Piazzale Aldo Moro 5 I-00185 Roma, Italy
12
Univ. Grenoble Alpes, CNRS, IPAG 38000 Grenoble, France
13
Institute for Research in Fundamental Sciences (IPM), School of Astronomy Tehran, Iran
14
Centro de Astrobiología (CSIC-INTA), Torrejón de Ardoz 28850 Madrid, Spain
15
National Observatory of Athens, Institute for Astronomy, Astrophysics, Space Applications and Remote Sensing, Ioannou Metaxa and Vasileos Pavlou GR-15236 Athens, Greece
16
Department of Astrophysics, Astronomy & Mechanics, Faculty of Physics, University of Athens Panepistimiopolis GR-15784 Zografos Athens, Greece
17
High Energy Physics Division, Argonne National Laboratory 9700 South Cass Avenue Lemont IL 60439, USA
18
LERMA, Observatoire de Paris, PSL Research University, CNRS, Sorbonne Université, UPMC 75014 Paris, France
19
Institute of Space Sciences (ICE), CSIC, Campus UAB Carrer de Can Magrans s/n E-08193 Barcelona, Spain
20
ICREA Pg. Lluís Companys 23 Barcelona, Spain
21
IRAP, CNRS, Université de Toulouse, CNES, UT3-UPS (Toulouse), France
22
Dipartimento di Fisica, Università di Roma ‘Tor Vergata’ Via della Ricerca Scientifica 1 I-00133 Roma, Italy
23
School of Physics and Astronomy, University of Leeds Leeds LS2 9JT, UK
24
Institut d’Astrophysique de Paris, CNRS (UMR7095) 98 bis boulevard Arago 75014 Paris, France
25
University of Lyon, UCB Lyon 1, CNRS/IN2P3, IP2I 69622 Villeurbanne, France
★ Corresponding author.
Received:
14
March
2025
Accepted:
17
June
2025
Abstract
The NIKA2 Cosmological Legacy Survey (N2CLS) is a large programme using the NIKA2 dual-band camera on the IRAM 30 m telescope. Its goal is to improve our understanding of the physics of distant Dusty Star Forming Galaxies (DSFGs) by carrying out deep surveys of two fields, GOODS-North and COSMOS. This work is focussed on GOODS-North, which was observed for 78.2 hours, simultaneously at 1.2 and 2 mm, with a field of view of ∼240 arcmin2. With such a deep integration, we were able to measure, for the first time, the confusion noise limits at the 30 m telescope using the best sampled ∼62 arcmin2 and masking sources with a flux greater than 0.54 or 0.17 mJy at 1.2 or 2 mm, respectively. We found a confusion noise of 139.1−19.2+15.9±11.9 μJy/beam at 1.2 mm and 38.6−13.1+9.6±3.7 μJy/beam at 2 mm (the first uncertainty is statistical, the second is the cosmic variance). In this region, this corresponds to half the instrumental noise. To derive these estimates, we devised a novel estimator, referred to as the cross variance, which also enabled us to estimate the correlated confusion noise between the two bands. Thus, we obtained a result of 49.6−24.8+15.9±6.4 μJy/beam. These values are consistent with the state of the art Simulated Infrared Dusty Extragalactic Sky (SIDES) model.
Key words: galaxies: abundances / galaxies: evolution / galaxies: high-redshift / infrared: diffuse background / infrared: galaxies
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
In the far-infrared (FIR) to radio domains, single-dish surveys face a fundamental limitation in sensitivity and photometric accuracy due to fluctuations in the background surface brightness. In surveys of so called cosmological fields (i.e. free from Galactic contamination, the dominant source of background fluctuations is unresolved extragalactic point sources, which contribute to confusion noise in both the radio (Condon 1974) and IR domains (Kiss et al. 2001; Lagache et al. 2003; Dole et al. 2004). This confusion noise establishes the fundamental sensitivity limit for single-dish surveys, particularly for blind detection and accurate flux measurements of point sources.
The angular resolution of a single-dish telescope directly depends on the observed wavelength, limiting its ability to resolve individual sources at longer wavelengths. For example, the Spitzer Space Telescope’s 85 cm mirror (Werner et al. 2004) resolved over 80% of the galaxies contributing to the total emission at 24 μm (Papovich et al. 2004), but only 23% at 70 μm and 7% at 160 μm (Dole et al. 2004). Similarly, the Herschel Space Observatory (Pilbratt et al. 2010), with its larger 3.5 m mirror, was able to resolve 58% and 74% of the sources at 100 μm and 160 μm, respectively, but only 25% at 250 μm (Berta et al. 2011; Oliver et al. 2010). To overcome these resolution limitations, innovative techniques have been developed, such as stacking analyses of known galaxy populations (Dole et al. 2006; Béthermin et al. 2012; Viero et al. 2013a) and analyses based on the probability of deflection to study unresolved source fluctuations (Glenn et al. 2010; Berta et al. 2011; Béthermin et al. 2012; Viero et al. 2013b). Additionally, studying the anisotropies of the cosmic infrared background (CIB) offers valuable insights into large-scale distribution and clustering of dusty star-forming galaxies, as well as the properties of the CIB itself (Lagache et al. 2000; Amblard et al. 2011; Planck Collaboration XVIII 2011; Viero et al. 2013b; Planck Collaboration XXX 2014). This helps achieve an effective approach to constrain the evolution of galaxy populations and cosmic star formation processes.
Following the initial theoretical studies of confusion noise in the radio domain (Condon 1974), its first empirical assessment was made in a 4 GHz radio survey using a half-difference technique to separate instrumental noise from observed noise (Ledden et al. 1980). This methodology has been extended to the FIR and submillimetre (submm) range, where confusion levels attributed to extragalactic sources and galactic cirrus fluctuations have been predicted (Helou & Beichman 1990; Hacking & Soifer 1991; Gautier et al. 1992). In the FIR domain, confusion noise was measured with ISOPHOT data (Kiss et al. 2001), which revealed fluctuations from extragalactic sources. Confusion noise, which represents the ultimate sensitivity limit for source detection, has become a critical parameter for assessing the performance of extragalactic deep fields. For the Spitzer Space Telescope, studies of confusion noise were undertaken to optimise deep IR surveys, particularly in regions with high source densities (Kiss et al. 2005). Observations from the MIPS instrument at 24 μm quantified confusion limits imposed by the high density of faint unresolved sources (Dole et al. 2003), influencing the design of deep field surveys (Dole et al. 2004). Measurements at longer wavelengths, such as 70 μm and 160 μm, revealed the combined role of extragalactic fluctuations and Galactic cirrus in setting confusion limits, providing a means for reliable source detection amidst the noise background (Frayer et al. 2006; Papovich et al. 2004).
In the submm range, confusion noise also determines the depth of the survey. This was first addressed by Blain et al. (1998), who highlighted the impact of confusion noise from faint, dusty galaxies on single-dish observations. The problem was further explored with SCUBA at the JCMT, where confusion from unresolved sources set the practical sensitivity limits for wide-field surveys (Hughes et al. 1998; Barger et al. 1998; Eales et al. 1999). More recently, observations with SCUBA-2 refined the understanding of submm confusion, particularly at 850 μm. Geach et al. (2017) measured the confusion noise at 0.42 mJy, highlighting the critical role of clustering in shaping the background fluctuations and limiting source extraction. The Herschel Multi-tiered Extragalactic Survey (HerMES) provided a detailed assessment of confusion noise using SPIRE, quantifying detection limits at 250, 350, and 500 μm (Nguyen et al. 2010). Follow-up analyses of Herschel data deepened our understanding of confusion noise contributions from clustered dusty galaxies and Galactic cirrus, aiding in the optimisation of survey strategies and robust source extraction (Lagache et al. 2003; Negrello et al. 2004; Nguyen et al. 2010). These studies have proven instrumental in improving our ability to characterise the faint submm galaxy population, which dominates the cosmic IR background.
Different methods are commonly used to estimate the level of confusion noise, especially in the radio, FIR, and submm bands. One category of methods is based on galaxy number count models. A widely used approach calculates the number of sources per beam based on the source count distribution, dN/dS (Dole et al. 2003). These methods estimate the confusion noise as the flux density variance induced by unresolved sources within the telescope beam. The flux cut-off threshold can be defined by a photometric criterion, such as a signal-to-noise ratio (S/N) threshold, or a source density criterion that assumes a uniform spatial distribution of sources (Takeuchi et al. 2001). While effective in sparse source environments, this approach becomes less reliable in clustered fields where source correlations amplify background fluctuations, rendering the uniformity assumption invalid.
Another type of method is data-driven and derives the confusion noise directly from the map noise measurements. In this approach, the confusion noise (σc) is derived as the asymptotic limit of the map noise (σm) as a function of observation time. The relation σm2 = σi2 + σc2 is used, where σi represents the instrumental noise, which decreases with time as t−0.5 (Nguyen et al. 2010; Geach et al. 2017). This technique has the advantage that it does not rely on assumptions about the underlying source distribution. However, it is sensitive to systematic effects in the instrument or data reduction processes that may not diminish with longer observing times, potentially biasing the estimated confusion limit.
These methods highlight a trade-off between model-based and empirical approaches. While number count models make use of well-understood theoretical frameworks, they falter in complex fields with clustered sources. Conversely, empirical methods offer robustness to such clustering but are vulnerable to systematic errors, highlighting the need for careful cross-validation between methods in confusion-limited surveys.
NIKA2 is the current IRAM camera for measuring the millimetre continuum emission of astrophysical objects at the 30 m telescope (Pico Veleta, Spain). It is described in detail, together with its performance in Perotto et al. (2020). In short, it is a dual-band camera whose detectors are kinetic inductance detectors (KID) (Monfardini et al. 2010). The bands, which are observed simultaneously, are centred at 260 and 150 GHz (1.2 and 2 mm, respectively). There are three focal planes (arrays of detectors), two operating at 260 GHz and consisting of 1140 KIDs each, as well as one operating at 150 GHz with 616 KIDs. About 90 and 84% of these detectors are effectively used for observations. The photometric bandwidths are 49 and 40 GHz. The main beams have FWHMs of 11.1 and 17.6 arcsec (at 1.2 and 2 mm), and the field of view (FOV) is of 6.5 arcmin in diameter. This large field of view combined with point source sensitivities of 30 and 9 mJy.s1/2 provides mapping speeds of 111 and 1388 arcmin2 mJy−2 h−1 at 1.2 and 2 mm respectively, an order of magnitude better than the previous generation photometric instruments at the 30 m (Perotto et al. 2020). Although it is not used in this work, linear polarisation measurements can be made with the 1.2 mm channel. NIKA2 has been available to the community since 2017. In return for its efforts to design, fund, install, and characterise the instrument, the NIKA2 collaboration1 has been granted 1300 h of guaranteed time of observation that have been divided into five large programmes. This paper is one of those presenting the results of the NIKA2 Cosmological Legacy Survey (N2CLS), which consists of a deep integration of two extragalactic fields with many available ancillary data: GOODS-North and COSMOS.
This paper is organised as follows. In Sect. 2, we present the GOODS-North field and our observations. In Sect. 3, we describe the data processing that has been devised to produce the scientific maps. Sect. 4 presents the confusion noise estimator that we have built, the obtained measurements and their validation. In Sect. 5, we discuss the physical interpretation of the measured confusion. We present our summary and conclusions in Sect. 6.
2. Observing the GOODS-North field
GOODS-North is one of the two fields of the NIKA2 Large programme “NIKA2 Cosmological Legacy Survey” (N2CLS). An introduction to this IRAM 30 m Large Programme and a first analysis of its observations in terms of deep cosmological number counts have been proposed in Bing et al. (2023). For the sake of clarity, we recall here the main features of our observations that are relevant to this work.
From October 2017 to March 2021, across 12 NIKA2 runs (i.e. one or two consecutive weeks of observations), we have observed GOODS-North 749 times. In the following, we will refer to each of these observations as a ‘scan’. The observed region is a rectangle of 12′×6.3′ centred on RA = 12:36:55.03 and Dec = 62:14:37.59. Each of these raster scans is a collection of ‘subscans’ that encompass a straight trajectory of the telescope, that are parallel to each other and that are separated by 20″. A scan has its subscans oriented at 40 or −50° in (RA, Dec) so that we cover exactly the same region each time, but with alternating orthogonal directions. This was decided in anticipation of robustness tests (see Sect. 4.3). The scanning strategy on GOODS-North was designed to reach sensitivities comparable to the predicted confusion at 1.2 and 2 mm, respectively, estimated from simulations to be about 140 and 40 μJy/beam (Béthermin et al. 2017), in less than 100 h of observations. Each scan lasted about 7 and 8 mn.
During these 4.5 years of observations, some scans have suffered from poorer atmospheric conditions or instrumental instabilities. Thus, we rejected the ones that proved to be more of a liability than an asset. Our main criterion was the final average noise of an individual scan map compared to that of all the other scans. For this work, to reduce the noise in the data, we used an improved version of the pipeline described in Perotto et al. (2020), which has been used in previous papers published by our collaboration2 (see Sect. 3.1). Although it is similar in its basic principles as far as noise reduction is concerned, this method also differs from the one used in Bing et al. (2023). Indeed, the need for extensive end-to-end simulations dedicated to this work was more conveniently achieved with the NIKA2 collaboration pipeline. Our methods have different exclusion criteria when it comes to selecting scans. In this work, we ended up using 668 scans, both at 1.2 and 2 mm, thereby giving 78.2 h of observation on the field. As for the opacities, the mean values are 0.25 and 0.15, with minima of 0.1 and 0.07, and maxima of 0.5 and 0.3 at 1.2 and 2 mm, respectively.
3. Data reduction
In this section, we present our data reduction pipeline. We retained the Planck idiom and refer indifferently to timelines or time-ordered information (TOI) for the data streams recorded by the detectors over time.
3.1. From raw to calibrated data
Most of the low-level processing that goes from the raw data to the calibrated data is the same as that described in detail in Perotto et al. (2020). Here, we present only the modifications that are relevant to this work. In particular, we have used a novel method to monitor the KID resonance frequency shifts and convert them into a TOI that is proportional to the incident flux. This method, described in detail in Appendix C, improves on the previous one in terms of the numerical integration, which improves the residuals from the atmosphere and low frequency electronic noise. Our data model has also changed. In Perotto et al. (2020), for each detector, we estimated a single composite mode of atmosphere and electronic noise from the other detectors that are most correlated with it. This composite mode was computed while taking into account a bright source mask and both can be improved by an iterative scheme. While this method has proven effective for all the other science objectives of NIKA2, the level of integration is so much deeper in this work that it proved insufficient and led us to explicitly separate the atmosphere and several different ‘modes’ of the sky noise and the electronic noise. We explored several approaches based on more sophisticated instrument models. The main idea was to use the distribution of detectors per electronic box and their analogue sub-bandpasses to derive educated models of the noise modes. Although promising, this idea did not meet our expectations. The output maps were indeed very clean, but the transfer function (see Sect. 4.2) was smaller than 50%. This led to too much uncertainty in the actual blind detection of the bright sources to be masked and to a large and more uncertain correction in the final quoted values of the confusion.
In the end, we limited ourselves to one mode per acquisition electronics box. This mode, however, is not built up from the KID TOIs, but from measures of the same feedlines where there are no KID resonances. This is the analog of dark or blind detectors in other instruments and we refer to them as ‘tones’. There are approximately 140 such measures available for each of arrays 1 and 3 (both at 1.2 mm) and 18 for array 2 (at 2 mm). This relatively low number is a limitation for our 2 mm channel. The same circle method is used for these off-resonance tones as for the standard KIDs to derive a frequency variation. Empirically, we have found that the signal that is orthogonal to the circle frequency variation (see Appendix C) is not useful for the decorrelation, so we used only the tangential on-circle variations, in the same way as for KIDs. Therefore, we here modelled the TOI of detector k as
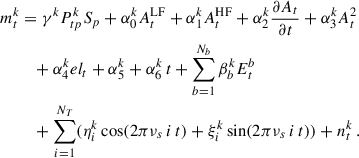 (1)
(1)
In Eq. (1), t is time, Ptp is the pointing matrix, and Sp is the sky brightness map in pixel, p. Here, At is the atmosphere as seen by all the KIDs, decomposed into its low frequency part: AtLF below 0.5 Hz and its high frequency part: AtHF = At − AtLF. To the first order, all KIDs see the same atmospheric signal, since its origin is in the near field of the telescope. Then, elt is the elevation of the telescope and Etb is the series of noise components derived from off-resonance tones, which are partially correlated with a range of different detectors depending on their common readout electronic box, b. Then, ntk is the individual KID Gaussian white noise. We also included the time derivative of the atmosphere, 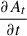 , as a proxy for second-order variations of the atmospheric contribution across the FOV, for possible residual non-linearity with the At2 term and a time linear drift, α5k + α6k t. Finally, on a subscan basis, we also defined harmonic modes to filter out low-frequency residual noise. To filter short and long subscans equally, we set the effective number of trigonometric modes per subscan, so that the highest subtracted frequency was 0.2 Hz. In practice, this added NT = 4 modes (2 cosine and 2 sine functions) for each of the 10 s subscans (6 × 12 arcmin case) or 6 modes for each of the 17 s subscans (12 × 6 arcmin case). Here, γk is the absolute calibration, known from specific observations (see Perotto et al. 2020) on Uranus and skydips, while the αk, βk, ηk, and ξk coefficients are determined during the processing, as described in the next subsection. The actual implementation of this model goes along with the map making presented in the next section.
, as a proxy for second-order variations of the atmospheric contribution across the FOV, for possible residual non-linearity with the At2 term and a time linear drift, α5k + α6k t. Finally, on a subscan basis, we also defined harmonic modes to filter out low-frequency residual noise. To filter short and long subscans equally, we set the effective number of trigonometric modes per subscan, so that the highest subtracted frequency was 0.2 Hz. In practice, this added NT = 4 modes (2 cosine and 2 sine functions) for each of the 10 s subscans (6 × 12 arcmin case) or 6 modes for each of the 17 s subscans (12 × 6 arcmin case). Here, γk is the absolute calibration, known from specific observations (see Perotto et al. 2020) on Uranus and skydips, while the αk, βk, ηk, and ξk coefficients are determined during the processing, as described in the next subsection. The actual implementation of this model goes along with the map making presented in the next section.
3.2. Noise reduction and map making
In all of this work, we built maps at a resolution of 4 arcsec, so that it is less than a third of the main beam FWHM of the instrument, as the standard proxy for Nyquist’s criterion. Our data reduction scheme is then:
-
For each time, t, the median of the simultaneous samples of all the KIDs in the same array is computed. The median ensures robustness against possible outliers due to possible bright sources or anomalies that are seen by only a few KIDs at the same time, compared to the ∼1000 KIDs of the array. We internally iterate once on the mode production by eliminating KIDs that do not correlate with this initial mode (e.g. due to a bad tuning) and take the average of all selected KID TOIs.
-
This mean mode is dominated by the atmosphere and can therefore be used as an estimate of At. Its derivative ∂A/∂t is derived after a 0.5 s smoothing.
-
One noise mode per acquisition box Etb is built with the average signal of the off-resonance tones of this box.
-
Each KID timeline, mtk, is simultaneously linearly regressed against the atmosphere modes, the noise modes, and the trigonometric functions to estimate all the coupling coefficients αk, βik, ηjk, and ξjk. This regression is performed on a subscan basis to better account for the variability of the KID coupling to the different electronic modes. We also note that all electronic box modes are used altogether in the fit for each KID, and not just the box mode of that KID. This is to cope with the mixing of the electronic modes when At and ∂A/∂t are generated using all KIDs of the same array.
-
A few percent of the KIDs show a poor fit to this model and are excluded at this stage.
-
For each remaining KID, the estimated atmosphere and noise contributions are subtracted, leaving only γkPtpkSp + ntk in Eq. (1).
-
Once all the KID timelines from a scan have been processed in this way, they can be projected onto a map. To do this, we use a standard nearest grid point average and apply a weight to each data sample. This weight is the inverse of the variance of the KID timeline during the subscan to which the data sample belongs. For the record, we note a slight overall excess of variance during the first two seconds of each subscan and we down-weight the corresponding data samples accordingly.
-
Low-level residuals can be seen in maps in Nasmyth coordinates, with a striping oriented in the same way as the electronic boxes. We decided to correct for this pattern with one template per array and per subscan.
Each scan was reduced according to this scheme and we obtained a map per scan. We then co-added all these scan maps to produce the final map, using inverse noise per pixel weighting. This process is based on the implicit assumption that the signal is zero or at least negligible compared to the parasitic components. To improve the final map, we iterated this process. We performed a point source detection on the map and kept only the brightest ones that appear at a SNR greater than 10. We built a model map that is just the sum of these bright point sources modelled as constant-width 2D Gaussian. At the start of the next iteration, we de-projected this model map into point source TOIs, which we then subtracted from the KID TOIs. In this way, the final map was no longer affected by the filtering residuals of the bright sources. In practice, we proceeded more progressively. At each iteration, iter, we actually subtracted (1 − 0.2iter) times the source model map built at the previous iteration to mitigate the effect of errors on this map at the very first iterations. This process was iterated until convergence was achieved, with residual peaks on the difference between successive iterations at less than 10 μJy. In practice, three processing iterations were sufficient, the first one assuming a vanishing point-source model map. Figure 1 presents our final maps, together with the contours of the region used to derive the confusion (cf. Sect. 4). The noise map was derived in two steps. As described in step 7 of our data processing, each sample was projected onto the final map with a known weight. Straightforward algebra allowed us to derive the total noise per pixel on the final map. However, we note that the distribution of the S/N per map pixel did not follow the expected normalised Gaussian, probably due to some residual correlation in the noise. We concluded that our TOI noise propagation underestimated the effective noise on the map. To correct for this, we needed to multiply our noise maps by typically 1.6 and 1.3 at 1.2 and 2 mm, respectively.
 |
Fig. 1. Maps of GOODS-North used in this work (left 1.2 mm, right 2 mm). The black contours define the region (i.e. mask) that we use to compute the confusion. |
4. Measuring the confusion
The confusion, σc, is defined as the square root of the variance of the measured brightness, S (i.e. including the point spread function; PSF or beam of the instrument) when bright sources above a certain flux are masked out and in the limit of zero instrumental noise or (equivalently) infinite integration time (Condon 1974; Nguyen et al. 2010; Béthermin et al. 2024) as follows:
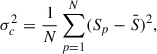 (2)
(2)
where Sp is the signal at pixel, p, and 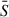 is the average brightness of the map. With this definition, the confusion depends on both the angular resolution of the instrument and the arbitrary flux cut of bright sources. In practice, maps are affected by the data processing and contaminated by instrumental noise so that Eq. (2) cannot be readily implemented. In the next subsection, we present our estimator of σc. Our final results and a discussion on their robustness are summarised in Sect. 4.3.
is the average brightness of the map. With this definition, the confusion depends on both the angular resolution of the instrument and the arbitrary flux cut of bright sources. In practice, maps are affected by the data processing and contaminated by instrumental noise so that Eq. (2) cannot be readily implemented. In the next subsection, we present our estimator of σc. Our final results and a discussion on their robustness are summarised in Sect. 4.3.
4.1. The cross-variance estimator
To define the sky area over which we calculate the confusion, we have to make a trade-off between the size of the patch and the homogeneity of the noise. To this end, we chose to restrict to pixels with a number of samples greater than two times the median number of hits per pixel on the full map for both bands. We built on the results of Bing et al. (2023) and masked sources that are confidently detected above a minimum S/N of 4.6 and correspond to fluxes greater than ∼0.54 and ∼0.17 mJy at 1.2 and 2 mm, respectively. We took the locations of these sources and mask all pixels within a radius of 19 arcsec at 1.2 mm and 27.8 arcsec at 2 mm. This leaves us with 64.7 and 62.1 arcmin2 at 1.2 mm and 2 mm (see Fig. 1). The masks were independently derived at 1.2 and 2 mm.
Implementing Eq. (2) directly on the data leads to an estimate of 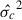 that is biased. In fact, the measured value in each pixel, Ap, is the sum of the signal, Sp, and the noise ap, so the two variances add up. Furthermore, the signal has been affected by the data processing. In our case, where we are interested in a single number, the effect of the processing (i.e. the transfer function) can be represented by a single factor, f. In the limit of zero noise on the maps, replacing Sp by Ap in Eq. (2) gives f2σc2. The derivation of f is detailed in Sect. 4.2 and is based on simulations. We went on to determine how we could estimate the variance of the noise, σa2. We considered several possibilities.
that is biased. In fact, the measured value in each pixel, Ap, is the sum of the signal, Sp, and the noise ap, so the two variances add up. Furthermore, the signal has been affected by the data processing. In our case, where we are interested in a single number, the effect of the processing (i.e. the transfer function) can be represented by a single factor, f. In the limit of zero noise on the maps, replacing Sp by Ap in Eq. (2) gives f2σc2. The derivation of f is detailed in Sect. 4.2 and is based on simulations. We went on to determine how we could estimate the variance of the noise, σa2. We considered several possibilities.
First, we could use a null map produced by combining the 668 scans with alternating positive and negative weights. This would cancel out the astronomical signal, while leaving the noise properties unchanged. Applying Eq. (2) to this map would directly give σa2. In practice, the noise on the null map actually appears to be less than the noise on the map. Indeed, when we computed the histogram of the S/N, with the noise derived from the null map, its width is rather 1.2 than 1. We attribute this to residual noise in the data maps that is difficult to estimate precisely and that may bias our estimate of σc. Nevertheless, if we computed 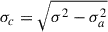 using this method, we would find σc ≃ 145 and 34 μJy/beam at 1.2 and 2 mm, respectively. These values are in good agreement with our final results.
using this method, we would find σc ≃ 145 and 34 μJy/beam at 1.2 and 2 mm, respectively. These values are in good agreement with our final results.
Second, we could use an approach such as the one proposed in Nguyen et al. (2010) and monitor the measured noise as a function of the integration time. Unlike them, we did not have enough integration time to do this analysis pixel per pixel, but we could generalise their approach to a sub-area of our map, accumulating scans, calculating the variance of the map pixels as we went along, and then fit its decrease as a linear function of the inverse of the integration time. The noise variance would decrease as 1/t and the confusion would be the remaining constant term in the fit3. We found that this does not solve the previous problem and comes with other difficulties, such as the determination of the (strongly correlated) uncertainties of each measurement of σ2(t) and the determination of the out-of-atmosphere equivalent integration time. Both of these factors impact the derived value of the confusion and its associated uncertainty. The former can be addressed by Monte-Carlo simulations, but the latter is poorly defined in the context of a non-uniform survey and is affected by uncertainties in the opacity as well as the overall absolute calibration; this can vary between different runs, depending on the number and quality of absolute calibration scans that could be performed. In Fig. 2, we still show the decrease of the variance of the map versus the integration time, but this is for illustrative purpose only. As such, the solid black line follows t−1/2, which was fitted for integration times smaller than 20 000 s and it does not take the correlation between the error bars into account. For reference, completing this exercise yields σc≃ 142 and 49 μJy/beam at 1.2 and 2 mm, respectively. Given the actual significance of our detection (see below), the observed excess is real and dominated by the confusion and the agreement between this method and our final one is not surprising. However, the caveats we mention here have prevented us from using this estimator to derive our final results.
 |
Fig. 2. Variance of the N2CLS maps vs. the out of atmosphere integration time on a region in the center equivalent to one NIKA2 field of view (6.5 arcmin diameter). To determine these data points, we simply take the variance of the unmasked pixels (see Fig. 1) in the central area. For each NIKA2 band, the lower plot shows the residuals compared to the t−1/2 instrumental noise integration that is fitted here for times of integration smaller than 20 000 s. The error bars are the square roots of the diagonal elements of the covariance matrix of the measures (Fig. A.2), derived from 100 Monte-Carlo simulations of map-based realistic noise (per scan). There is a clear excess of signal at high integration time due to the confusion, but as explained in the main text, this plot is for illustrative purposes only and is not used to derive our final results. |
To improve on all these aspects, we developed a third approach based on the general idea of cross-correlations (e.g. Tristram et al. 2005). Instead of combining all the scans into a single map, we combined them into a set of independent maps (1 for each of the 12 observation runs). This gives us 66 pairs of different maps of the same sky (excluding auto-correlations) and for each pair (Ai, Bi), we can compute the cross-variance, as defined by:
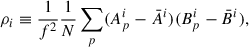 (3)
(3)
where i is the pair index. Since the maps Ai and Bi are independent, the statistical expectation of ρi for unmasked pixels is directly σc2 (see Eqs. (A.4) and (A.11)), without any bias. Indeed, since maps Ai and Bi were not coadded before computing the variance of the sum, their noise components did not add up in quadrature as in the previous two estimators. Finally, ρi makes no assumption about the uniformity of the integration time per pixel and is therefore immune to inhomogeneities in the sky coverage. To make the best use of all the available data, we computed the cross-variance of all the possible pairs and determine their full covariance matrix, X (see Appendix A for details). With these two in hand, we were able to compute the likelihoods of the confusion at 1.2 mm, 2 mm, and even the cross-confusion 1.2 × 2 mm:
![Mathematical equation: $$ \begin{aligned} \mathcal{L} \propto \exp {[-(\rho _i-\sigma _c^2)X_{ij}^{-1}(\rho _j-\sigma _c^2)]}\,. \end{aligned} $$](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq11.gif) (4)
(4)
We relied on these likelihoods to derive final values and their associated confidence intervals. Our final results are discussed in Sect 4.3.
4.2. Determining the transfer function
To determine the transfer function factor, f, we relied on the state-of-the-art SIDES-UCHUU simulations (Béthermin et al. 2017, 2022; Gkogkou et al. 2023). We applied the NIKA2 bandpass and point spread function to the SIDES-UCHUU cube to create a simulated sky, simp, as it would be observed by NIKA2. We then ran our exact scan strategy and KID selection over this map, for each scan, to build simulated signal timelines, simtk, for each KID, k. These simulated timelines can then be added to our real data timelines. To be immune to the true astronomical signal in our data, before adding the simulated timeline, we multiplied our data timelines by −1 for every second pair of scans (to account for both scan orientations), so that the true signal is cancelled out in the final map, leaving only the simulated component. This is the best possible simulation to characterise our pipeline, as it deals with the true atmosphere and electronic noise rather than approximations. The magnitude of the simulated timelines is smaller than these two components by a factor of more than 1000, so it does not bias their derivation. We then reduced these composite timelines in exactly the same way as the data and project them onto a map, Mp = simpprocessed + Np, where Np is the noise. Basically, to determine f, we need to measure the rms of simpprocessed and divide it by the variance of the input noiseless simulated map, simp. A first way to proceed is to process the data timelines with exactly the same mask and alternating sign weights, but without adding simtk. This gives Np which can be subtracted from Mp to get simpprocessed. A second way is to do the same whole process as on the data, namely making maps per runs, calculating their cross-variance and deriving the estimated final confusion as the value that maximises their likelihood. The ratio of this value to the standard deviation of the input map, simp, on the same area gives an estimate of f. As described in Sect. 2, our observations consist of two sets of scans with orthogonal directions and different subscan lengths. This results in slightly different effective filtering between these two types of scans, so we computed a transfer function, f, per direction and we corrected accordingly. We discuss this in more detail in Sect. 4.3. We checked the robustness of our estimates of f by varying the mask definition criteria (size and masked sources) and by scaling the SIDES simulations by factors ranging from 1 to 3. The scaling improves or degrades the S/N of the output signal, while remaining negligible compared to the true noise of the data. Finally, we used the f factors derived from simulations scaled by a factor 3, as they provide a better dispersion due to their higher S/N. We estimated f on 274 simulations and the two methods agree on average by 1%. The statistical uncertainty on the average of f is also about 1%, so we take this as our final uncertainty on f.
The dispersion of σc as estimated from these 27 end-to-end simulations (including the detection of bright sources and masks) also provides an estimate of the cosmic variance associated with our measurement. We find about 12, 4, and 6 μJy/beam at 1.2, 2, and 1.2 × 2 mm, respectively (exact values are given in Table 1).
Confusion noise estimates and uncertainty budget.
4.3. Results
The 12 observation runs give us 66 cross-variance measurements, which are given in Fig. A.1 in the particular case of 1.2 mm. The likelihoods of the confusion at both wavelengths are shown in Fig. 3 as estimated on different subsets of our data. ‘Half 1’ denotes the ensemble of 334 of our scans that are oriented at 40°, ‘Half 2’ is the 334 at −50°. To check for consistency, we compute the confusion either exclusively on each half of the scans, on ‘all’ the scans combined or exclusively by crossing one half with the other. As mentioned in the previous section, we computed an effective transfer function, f, and corrected for it independently in each case. Indeed, this f factor relates to the variance of the signal and is implicitly azimuthally symmetric, whereas our filtering is mostly per subscan and is therefore directional. This particular feature prevents us from deriving f based on the combined directions taken from f coming from each direction. As shown in Fig. 3, all estimates are compatible within 1σ. Using the values derived from all the scans (as they have the highest S/N), we obtained the confusion estimates shown in Table 1; namely, 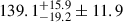 ,
, 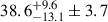 and
and 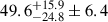 μJy/beam at 1.2, 2 and 1.2 × 2 mm, respectively. The first set of error bars refers to the instrumental noise and the second to the cosmic variance. These are clear measures at a significance of 7σ at 1.2 mm and 3σ at 2 mm, but only a 2σ evidence at 1.2 × 2 mm. An overall absolute calibration uncertainty has to be considered. It affects the quoted value and its statistical error bars, but not the cosmic variance. This uncertainty has three main components. Firstly, there is the statistical variability of the measurement under various observation conditions from the ground, which was determined to be 5% during the NIKA2 commissioning. Secondly, there is uncertainty regarding the exact flux of our calibration source Uranus. As reported in Perotto et al. (2020), this uncertainty is about 5%. Taking all these uncertainties into account and adopting a conservative approach, we estimated an overall uncertainty of 10% in our absolute calibration.
μJy/beam at 1.2, 2 and 1.2 × 2 mm, respectively. The first set of error bars refers to the instrumental noise and the second to the cosmic variance. These are clear measures at a significance of 7σ at 1.2 mm and 3σ at 2 mm, but only a 2σ evidence at 1.2 × 2 mm. An overall absolute calibration uncertainty has to be considered. It affects the quoted value and its statistical error bars, but not the cosmic variance. This uncertainty has three main components. Firstly, there is the statistical variability of the measurement under various observation conditions from the ground, which was determined to be 5% during the NIKA2 commissioning. Secondly, there is uncertainty regarding the exact flux of our calibration source Uranus. As reported in Perotto et al. (2020), this uncertainty is about 5%. Taking all these uncertainties into account and adopting a conservative approach, we estimated an overall uncertainty of 10% in our absolute calibration.
 |
Fig. 3. Likelihoods (normalised to their maximum) of the confusion at 1 mm, 2 mm, and the cross-confusion 1 × 2 mm for different subsets of our data. The central points and their 1-σ equivalent error bars are shown for convenience and have arbitrary ordinates. ‘Half 1’ refers to scans oriented at 40°. ‘Half 2’ refers to scans oriented at −50°. ‘All’ refers to the total sum of the two. |
To check the consistency of our final values, we used the SIDES simulations and the bright source masks derived from our end-to-end simulations and calculated the expected confusion levels. We find 156, 49, and 84 μJy/beam at 1.2, 2, and 1.2 × 2 mm. If we compare this to our measures taken at face value, at 1.2 and 2 mm, our results are compatible with SIDES at 1σ (stat), even without considering the uncertainty onabsolute calibration or the cosmic variance. Our measurement of the 1.2 × 2 mm confusion is 1.4σ (stat) lower than the value expected from SIDES. Given the 10% uncertainty on our absolute calibration, if we allow it to increase by this factor, our results at 1.2 and 2 mm become 153 ± 21 and 43 ± 14. This shows an even better agreement with the prediction of SIDES. Our measurement at 1.2 × 2 mm becomes 55 ± 28 μJy/beam, which is now 1.04σ (stat) of the 84 μJy/beam expected from SIDES. This last compatibility can be further improved if we assume that our field has a low intrinsic confusion within one cosmic standard deviation (Table 1). This would actually also improve the agreement at 2 mm, but slightly degrade that at 1.2 mm, although keeping it within 1σ (stat). Overall, this comparison shows a good agreement between our results and the predictions of SIDES at 1.2 and 2 mm, but a marginally lower than expected value at1.2 × 2 mm.
The consistency of our results can be assessed in another way. Using Eq. (6), we can see that σc2 = rσc1θ2/θ1.2 and σc1 × 2 = (2r)1/2σc1θ2/(θ12 + θ22)1/2, where θ is the instrumental beam FWHM and r is a constant that can be derived from the SIDES confusions and is 0.21. Applying this to the measured value of the confusion at 1.2 mm and considering only the statistical uncertainty, we would expect σc2 ≃ 44 ± 6 and σc1 × 2 = 75 ± 10 μJy/beam. Both of these values are compatible with our measures and their associated error bars, although, again, the measured value at 1.2 × 2 mm appears slightly lower than the predicted one.
Finally, we compare these estimates with the instrumental noise in the final maps. On the central region of our maps equivalent to one NIKA2 field of view (a disk of 6.5 arcmin diameter) and still masking bright sources, we find total variances of map pixels of about 2.8 × 105 and 4.5 × 104 (μJy/beam)2. Subtracting our estimates of confusion (139 and 39 μJy/beam) according to Eq. (B.5), we can derive the residual noise contribution per beam to be 218 and 60 μJy/beam at 1.2 and 2 mm, respectively. It means that the measured confusions are 0.64 and 0.65 times the residual noise in our final maps. These noise estimates agree within 25% with those obtained by Bing et al. (2023) (170 and 48 μJy/beam) with a data reduction optimised for point source detection; thus, it filters out more of the undetected sources that generate the confusion.
This was achieved after about 80 hours of observation of about 64 arcmin2, that is, approximately 11 hours per field of view of 33.2 arcmin2. These numbers provide with another cross-check when we use them to derive an approximate value of the instrumental sensitivity, also known as the Noise Equivalent Flux Density (NEFD). A thorough assessment of this sensitivity and its uncertainty with these data is beyond the scope of this paper. Still we note that taking the average encountered opacities and elevations (Sect. 2), we obtain effective out-of-atmosphere NEFDs of 32 and 10 mJy/beam at 1.2 and 2 mm, respectively. Although these values are only approximate, they are in good agreement with those presented in Perotto et al. (2020) and comfort our results.
5. Sources responsible for the confusion
The confusion is caused by all galaxies with flux below the detection limit Slim. However, depending on the exact shape of the number counts, the confusion noise can be dominated by sources with different flux regimes. In this section, we use the SIDES simulation (Béthermin et al. 2017) to predict the contribution of the different flux densities to the confusion, and compare it with the contribution to the CIB, expressed as
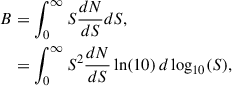 (5)
(5)
where 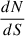 is the differential number counts. The factor
is the differential number counts. The factor 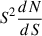 thus directly gives the relative contribution of a logarithmic flux density interval to the background.
thus directly gives the relative contribution of a logarithmic flux density interval to the background.
In the absence of clustering, the confusion noise is expressed as
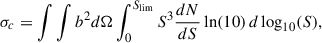 (6)
(6)
where b is the beam function. Similar to the background case, the term 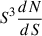 gives the contribution of the logarithmic flux density intervals to the fluctuations. As shown in Béthermin et al. (2017), the clustering tends to broaden the pixel flux distribution and thus increases the confusion. However, even for Herschel/SPIRE at 500 μm with its 36 arcsec beam, the effect is of the order of 15%. We can therefore reasonably neglect it in the case of NIKA2, which has a beam area four times smaller.
gives the contribution of the logarithmic flux density intervals to the fluctuations. As shown in Béthermin et al. (2017), the clustering tends to broaden the pixel flux distribution and thus increases the confusion. However, even for Herschel/SPIRE at 500 μm with its 36 arcsec beam, the effect is of the order of 15%. We can therefore reasonably neglect it in the case of NIKA2, which has a beam area four times smaller.
In Fig. 4, we show the relative contribution to the background (blue) and the confusion (red) as a function of the flux density. Only sources below the detection limit contribute to the confusion and the grey area indicates the region where they are masked and therefore do not contribute. The curves are calculated from the number counts derived from the SIDES simulation. At both 1.2 mm and 2 mm, the maximum of the red curve is in the masked regime and decreases strongly with decreasing flux density. The sources just below the detection limit are therefore the ones that produce most of the confusion we measure. The contribution to the background peaks at fainter flux densities, which are below the detection limit. However, we note that at 1.2 mm, this peak is just below the detection limit. At this wavelength, the flux density regime that dominates both the background and the confusion is therefore the same.
 |
Fig. 4. Relative contribution to the background (blue curve) and to the fluctuations causing the confusion (red curve) as a function of the flux density derived with the SIDES simulation at 1.2 mm (left) and 2 mm (right) (see Sect. 5). The same quantities derived from the source counts measurements in GOODS-N by Bing et al. (2023) are shown as blue circles and red squares, respectively. The difference between the prediction of galaxy counts from SIDES and the source counts from N2CLS is well understood and caused by the blending of galaxies into the NIKA2 beam (see the analysis in Bing et al. 2023). The grey area shows the flux density regime where the sources are masked and do not contribute to the confusion. |
The agreement of the confusion noise from SIDES and N2CLS is an important validation of SIDES in the flux regime corresponding to the peak of the contribution to the background and, thus, to the obscured star formation budget. At 2 mm, the peak is below the detection limit by a factor of ∼3. Therefore, we are mainly probing galaxies that are slightly brighter than those that make up the bulk of the background.
6. Conclusion
From October 2017 to March 2021, we observed the GOODS-North field. We were able to accumulate 78.2 h of observations on about 240 arcmin2. By masking the sources that we confidently detected in a previous work (Bing et al. 2023), whose flux is greater than 0.54 or 0.17 mJy at 1.2 and 2 mm, and by restricting ourselves to the 62 arcmin2 of our best sampled observations, we were able to derive the first estimates of the confusion ever obtained at the IRAM 30 m telescope. We measured 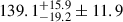 μJy/beam at 1.2 mm, where the first set of error bars is due to noise and the second one due to the cosmic variance. At 2 mm, we measured
μJy/beam at 1.2 mm, where the first set of error bars is due to noise and the second one due to the cosmic variance. At 2 mm, we measured 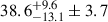 μJy/beam. To derive these estimates, we developed a new estimator, referred to as the cross-variance. This estimate is less sensitive to residual noise on the maps and also allows us to measure the contribution to the confusion that is correlated between 1.2 and 2 mm. In this case of cross-band confusion, we only found evidence at the level of a 2σ:
μJy/beam. To derive these estimates, we developed a new estimator, referred to as the cross-variance. This estimate is less sensitive to residual noise on the maps and also allows us to measure the contribution to the confusion that is correlated between 1.2 and 2 mm. In this case of cross-band confusion, we only found evidence at the level of a 2σ: 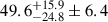 μJy/beam. All these results are close to those expected from the independently developed SIDES simulations (Béthermin et al. 2017, 2022; Gkogkou et al. 2023). This agreement consolidates both our estimates and the model in the flux regime below the detection limit of N2CLS. Since the confusion is caused by a wide range of fluxes, we cannot formally exclude another scenario where the number counts would have a steeper slope than SIDES near the detection limit, but with a higher number of sources with very faint flux densities. However, many such faint galaxies would be required and this would contradict findings that state that low-mass galaxies tend to have lower dust attenuation and, thus, lower FIR emissions (e.g. Heinis et al. 2014; Fudamoto et al. 2020).
μJy/beam. All these results are close to those expected from the independently developed SIDES simulations (Béthermin et al. 2017, 2022; Gkogkou et al. 2023). This agreement consolidates both our estimates and the model in the flux regime below the detection limit of N2CLS. Since the confusion is caused by a wide range of fluxes, we cannot formally exclude another scenario where the number counts would have a steeper slope than SIDES near the detection limit, but with a higher number of sources with very faint flux densities. However, many such faint galaxies would be required and this would contradict findings that state that low-mass galaxies tend to have lower dust attenuation and, thus, lower FIR emissions (e.g. Heinis et al. 2014; Fudamoto et al. 2020).
Acknowledgments
We acknowledge financial support from the “Programme National de Cosmologie and Galaxies” (PNCG) funded by CNRS/INSU-IN2P3-INP, CEA and CNES, France, from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (project CONCERTO, grant agreement No 788212) and from the Excellence Initiative of Aix-Marseille University-A*Midex, a French “Investissements d’Avenir” programme. This work is based on observations carried out under project numbers 192-16 with the IRAM 30 m telescope. IRAM is supported by INSU/CNRS (France), MPG (Germany) and IGN (Spain). We would like to thank the IRAM staff for their support during the observation campaigns. The NIKA2 dilution cryostat has been designed and built at the Institut Néel. In particular, we acknowledge the crucial contribution of the Cryogenics Group, and in particular Gregory Garde, Henri Rodenas, Jean-Paul Leggeri, Philippe Camus. This work has been partially funded by the Foundation Nanoscience Grenoble and the LabEx FOCUS ANR-11-LABX-0013. This work is supported by the French National Research Agency under the contracts “MKIDS”, “NIKA” and ANR-15-CE31-0017 and in the framework of the “Investissements d’avenir” program (ANR-15-IDEX-02). This work has been sup- ported by the GIS KIDs. This work has benefited from the support of the European Research Council Advanced Grant ORISTARS under the European Union’s Seventh Framework Programme (Grant Agreement no. 291294). A. R. acknowledges financial support from the Italian Ministry of University and Research – Project Proposal CIR01_00010. M. M. E. acknowledges the support of the French Agence Nationale de la Recherche (ANR), under grant ANR-22-CE31-0010. R. A. acknowledges support from the Programme National Cosmology et Galaxies (PNCG) of CNRS/INSU with INP and IN2P3, co-funded by CEA and CNES. R. A. was supported by the French government through the France 2030 investment plan managed by the National Research Agency (ANR), as part of the Initiative of Excellence of Université Côte d’Azur under reference number ANR-15-IDEX-01.
References
- Amblard, A., Cooray, A., Serra, P., et al. 2011, Nature, 470, 510 [NASA ADS] [CrossRef] [Google Scholar]
- Barger, A. J., Cowie, L. L., Sanders, D. B., et al. 1998, Nature, 394, 248 [Google Scholar]
- Berta, S., Magnelli, B., Nordon, R., et al. 2011, A&A, 532, A49 [CrossRef] [EDP Sciences] [Google Scholar]
- Béthermin, M., Le Floc’h, E., Ilbert, O., et al. 2012, A&A, 542, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Béthermin, M., Wu, H.-Y., Lagache, G., et al. 2017, A&A, 607, A89 [Google Scholar]
- Béthermin, M., Gkogkou, A., Van Cuyck, M., et al. 2022, A&A, 667, A156 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Béthermin, M., Bolatto, A. D., Boulanger, F., et al. 2024, A&A, 692, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bing, L., Béthermin, M., Lagache, G., et al. 2023, A&A, 677, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blain, A. W., Ivison, R. J., & Smail, I. 1998, MNRAS, 296, L29 [Google Scholar]
- Calvo, M., Roesch, M., Désert, F. X., et al. 2013, A&A, 551, L12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Catalano, A., Calvo, M., Ponthieu, N., et al. 2014, A&A, 569, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Condon, J. J. 1974, ApJ, 188, 279 [Google Scholar]
- Dole, H., Lagache, G., & Puget, J. 2003, ApJ, 585, 617 [NASA ADS] [CrossRef] [Google Scholar]
- Dole, H., Rieke, G. H., Lagache, G., et al. 2004, ApJS, 154, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Dole, H., Lagache, G., Puget, J., et al. 2006, A&A, 451, 417 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eales, S., Lilly, S., Gear, W., et al. 1999, ApJ, 515, 518 [NASA ADS] [CrossRef] [Google Scholar]
- Frayer, D. T., Huynh, M. T., Chary, R., et al. 2006, ApJ, 647, L9 [Google Scholar]
- Fudamoto, Y., Oesch, P. A., Faisst, A., et al. 2020, A&A, 643, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gautier, T. N., I., Boulanger, F., Perault, M., & Puget, J. L. 1992, AJ, 103, 1313 [NASA ADS] [CrossRef] [Google Scholar]
- Geach, J. E., Dunlop, J. S., Halpern, M., et al. 2017, MNRAS, 465, 1789 [Google Scholar]
- Gkogkou, A., Béthermin, M., Lagache, G., et al. 2023, A&A, 670, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Glenn, J., Conley, A., Béthermin, M., et al. 2010, MNRAS, 409, 109 [Google Scholar]
- Grabovskij, G. J., Swenson, L. J., Buisson, O., et al. 2008, Appl. Phys. Lett., 93, 134102 [Google Scholar]
- Hacking, P. B., & Soifer, B. T. 1991, ApJ, 367, L49 [Google Scholar]
- Heinis, S., Buat, V., Béthermin, M., et al. 2014, MNRAS, 437, 1268 [Google Scholar]
- Helou, G., & Beichman, C. A. 1990, Liege Int. Astrophys. Colloq., 29, 117 [Google Scholar]
- Hughes, D. H., Serjeant, S., Dunlop, J., et al. 1998, Nature, 394, 241 [Google Scholar]
- Kiss, C., Ábrahám, P., Klaas, U., Juvela, M., & Lemke, D. 2001, A&A, 379, 1161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kiss, C., Klaas, U., & Lemke, D. 2005, A&A, 430, 343 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lagache, G., Haffner, L. M., Reynolds, R. J., & Tufte, S. L. 2000, A&A, 354, 247 [Google Scholar]
- Lagache, G., Dole, H., & Puget, J. L. 2003, MNRAS, 338, 555 [Google Scholar]
- Ledden, J. E., Broderick, J. J., Condon, J. J., & Brown, R. L. 1980, AJ, 85, 780 [NASA ADS] [CrossRef] [Google Scholar]
- Monfardini, A., Swenson, L. J., Bideaud, A., et al. 2010, A&A, 521, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Monfardini, A., Adam, R., Adane, A., et al. 2014, J. Low Temp. Phys., 176, 787 [NASA ADS] [CrossRef] [Google Scholar]
- Negrello, M., Magliocchetti, M., Moscardini, L., et al. 2004, MNRAS, 352, 493 [Google Scholar]
- Nguyen, H. T., Schulz, B., Levenson, L., et al. 2010, A&A, 518, L5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oliver, S. J., Wang, L., Smith, A. J., et al. 2010, A&A, 518, L21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Papovich, C., Dole, H., Egami, E., et al. 2004, ApJS, 154, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Perotto, L., Ponthieu, N., Macías-Pérez, J. F., et al. 2020, A&A, 637, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pilbratt, G. L., Riedinger, J. R., Passvogel, T., et al. 2010, A&A, 518, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XVIII. 2011, A&A, 536, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXX. 2014, A&A, 571, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Takeuchi, T. T., Kawabe, R., Kohno, K., et al. 2001, PASP, 113, 586 [Google Scholar]
- Tristram, M., Macías-Pérez, J. F., Renault, C., & Santos, D. 2005, MNRAS, 358, 833 [Google Scholar]
- Viero, M. P., Moncelsi, L., Quadri, R. F., et al. 2013a, ApJ, 779, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Viero, M. P., Wang, L., Zemcov, M., et al. 2013b, ApJ, 772, 77 [Google Scholar]
- Werner, M. W., Roellig, T. L., Low, F. J., et al. 2004, ApJS, 154, 1 [NASA ADS] [CrossRef] [Google Scholar]
To be more specific, this integration time is meant as out of the atmosphere. It is the actual wall clock observation time corrected for elevation and opacity, and as such, is different at 1.2 and 2 mm. See Sect. 10.2.1 in Perotto et al. (2020).
The SIDES maps used in this work were more conveniently grouped by 9. As the agreement between the two derivations and the dispersion was satisfactory, there was no need to run further (rather long) end-to-end simulations.
Appendix A: Estimation of the confusion via the cross-variance
To motivate the definition of our estimator, we start with the simple case where the signal projected onto maps is unaffected by the data processing and the noise in the map pixels is Gaussian, white, and independent per run. We then return to these hypotheses.
We consider two different runs of observations. The combination of all scans for the first gives the map A, the combination of all scans for the second gives the map B. In the following, capital letters denote map raw values and p and q denote pixel indices. Let Sp be the sky signal at pixel p, so for map A we have Ap = Sp + ap, where ap is the noise of map A. We assume that masking bright sources leaves us with N unmasked pixels. Finally, we use an over bar to denote the spatial average of the sky signal over all these pixels:
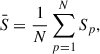
With such conventions, the confusion at 1 or 2 mm is expressed as
 (A.1)
(A.1)
We generalise this definition to the cross-band confusion when A is a 1 mm map and B a 2 mm map.
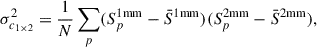 (A.2)
(A.2)
Under the hypotheses of pure signal and ideal noise, we define the ideal cross-variance estimator as
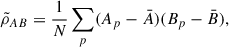 (A.3)
(A.3)
We show that its statistical expectancy is indeed σc2 via
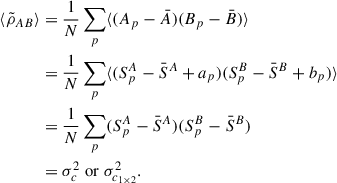 (A.4)
(A.4)
Next, we can compute the covariance of this estimator. By definition, taking four maps, A, B, C, and D, the covariance matrix of 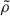 is expressed as
is expressed as
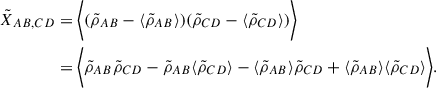 (A.5)
(A.5)
We define 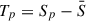 for convenience and use Kronecker’s symbol δ, which is equal to 1 when its indices are equal, zero otherwise. The first of the four terms in Eq. (A.5) is expressed as
for convenience and use Kronecker’s symbol δ, which is equal to 1 when its indices are equal, zero otherwise. The first of the four terms in Eq. (A.5) is expressed as
![Mathematical equation: $$ \begin{aligned} \langle \tilde{\rho }_{AB}\tilde{\rho }_{CD}\rangle&= \frac{1}{N^2} \biggl < \sum _{p,q} (A_p-\bar{A})(B_p-\bar{B}) (C_q-\bar{C})(D_q-\bar{D}) \biggr > \nonumber \\&= \frac{1}{N^2} \biggl < \sum _{p,q} (S^A_p-\bar{S}^A+a_p)(S^B_p-\bar{S}^B+b_p)\nonumber \\&(S^C_q-\bar{S}^C+c_q)(S^D_q-\bar{S}^D+d_q) \biggr > \nonumber \\&= \frac{1}{N^2} \biggl < \sum _{p,q} (T^A_p+a_p)(T^B_p+b_p)(T^C_q+c_q)(T^D_q+d_q) \biggr > \nonumber \\&= \frac{1}{N^2} \biggl < \sum _{p,q} \left(T^A_pT^B_p + T^A_p b_p + T^B_p a_p +a_pb_p\right)\nonumber \\&\left(T^C_q T^D_q + T^C_q d_q + T^D_q c_q + c_qd_q\right)\biggr > \nonumber \\&= \frac{1}{N^2} \sum _{p,q} \delta _{pq}\left[ T^A_pT^B_pT^C_q T^D_q + \right. \nonumber \\&(T^A_pT^C_q\delta _{BD} + T^A_pT^D_q\delta _{BC})\sigma ^2_{B_p} + \nonumber \\&(T^B_pT^C_q\delta _{AD}+T^B_pT^D_q\delta _{AC})\sigma ^2_{A_p}+ \nonumber \\&\left. (\delta _{AD}\delta _{BC} + \delta _{AC}\delta _{BD})\sigma ^2_{A_p}\sigma ^2_{B_p}\right]\,. \end{aligned} $$](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq37.gif) (A.6)
(A.6)
In the previous equation, σAp2 for instance, denotes the variance of the noise ap in pixel p of map A. It is derived at the map making stage when all scans are co-added (Sect. 3.2) and will be responsible for the statistical uncertainty on the determination of the confusion.
Assuming for now that A, B, C, and D are all maps of the same band, then Eq. (A.6) becomes:
![Mathematical equation: $$ \begin{aligned} \langle \tilde{\rho }_{AB}\tilde{\rho }_{CD}\rangle&= \frac{1}{N^2} \sum _{pq} \delta _{pq}\left[ T_p^2T_q^2 \right. \nonumber \\&+ T_p^2\left[(\delta _{BD} + \delta _{BC})\sigma ^2_{B_p} + (\delta _{AD}+\delta _{AC})\sigma ^2_{A_p}\right]\nonumber \\&+(\delta _{AD}\delta _{BC} + \delta _{AC}\delta _{BD})\sigma ^2_{A_p}\sigma ^2_{B_p} \end{aligned} $$](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq38.gif) (A.7)
(A.7)
The other terms involved in Eq. (A.5) are
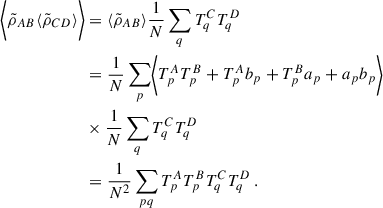 (A.8)
(A.8)
The same goes for the last two terms:
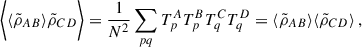
hence,
![Mathematical equation: $$ \begin{aligned} \tilde{X}^{1\times 1 \;\mathrm{or}\; 2\times 2}_{AB,CD}&= \frac{1}{N^2}\sum _p T_p^2\left[(\delta _{AC}+\delta _{AD})\sigma _{A_p}^2 + (\delta _{BC}+\delta _{BD})\sigma _{B_p}^2\right]\nonumber \\&+ (\delta _{AC}\delta _{BD} + \delta _{AD}\delta _{BC})\sigma _{A_p}^2\sigma _{B_p}^2\,. \end{aligned} $$](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq41.gif) (A.9)
(A.9)
In the specific case of the cross-band confusion, because we take maps from different runs and bands, if A and C refer to maps at 1 mm and B and D to maps at 2 mm, then eq. (A.9) simplifies further into
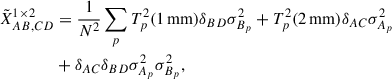 (A.10)
(A.10)
We note that in each case, the covariance matrix involves terms like Tp2, that is to say the pure underlying signal, that we actually don’t know in real data. In practice, we replace this term by the expected confusion squared σc2. Because it is in any case much smaller than the noise per pixel, the uncertainty on its exact value has a negligible impact on the derivation of the covariance matrix and subsequently that of the final error bar.
In a more realistic case, the data are inevitably affected by the data processing. It is common to loosely refer to the overall effect as "filtering". In this work, where we determine a single scalar term, we model the impact of the filtering by a multiplicative factor f on the confusion, smaller than 1, that needs to be determined. Thus, our cross-variance estimator and its covariance become:
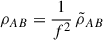 (A.11)
(A.11)
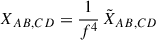 (A.12)
(A.12)
In this work, the timeline processing proceeds per subscan, and they have different orientations on the sky (cf. Sect. 2). As discussed in Sect. 4.2, this leads to different values of f. Filtering also affects the noise. In general, filtering mostly affects low frequency components and therefore has less effect on the statistical noise than on the signal. The 1/f2 correction in the definition of XAB, CD is therefore somewhat conservative in terms of statistical uncertainty.
Figure A.1 shows the 66 cross-variance estimates at 1.2 mm, and Fig. A.2 shows their associated covariance matrix.
 |
Fig. A.1. Estimates of the cross-variance at 1.2 mm for all pairs of independent observation runs in (μJy/beam)2. Error bars are the square root of the diagonal elements of the covariance matrix of ρi shown on Fig. A.2. The dashed line marks zero and the solid line is the combined cross-variance (see Eq. (A.14)). |
 |
Fig. A.2. Covariance matrix of the 66 cross-variance estimates. Each pixel of this image is an element of this 66 × 66 matrix, and its value is given by the color bar. The color scale is saturated on purpose to display the off-diagonal terms. The top plot shows the diagonal elements of the matrix. The blocks, dots and lines that appear in the matrix reflect the correlations when the same map is used in Eq. (A.9). |
Although we prefer to use likelihoods to derive our estimates of confusion and their associated confidence intervals, we here provide a direct way to estimate the overall cross-variance for the sake of completeness. We have checked that in the high-S/N case of 1.2 mm, the following derivation matches the maximum likelihood value given in the text.
We can gather all our cross-variance estimates in a single vector {ρi}i and relabel the covariance matrix Xij terms accordingly. The optimal way to combine ρi derives from the minimisation of the log likelihood
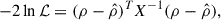 (A.13)
(A.13)
thus,
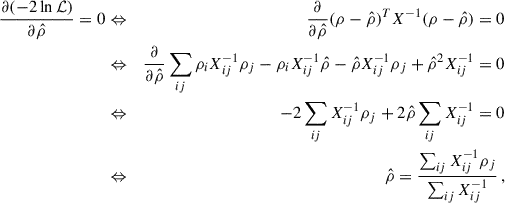 (A.14)
(A.14)
and the final uncertainty of 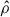 reads
reads
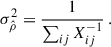 (A.15)
(A.15)
Appendix B: Note on photometry and conventions
The NIKA2 maps used in this work are calibrated in mJy/beam, and the absolute calibration is performed following Perotto et al. (2020). In this convention, a point source of flux ϕ would show up on the map mp as a Gaussian with an amplitude equal to ϕ, i.e. mp = ϕgp, with gp normalised such that their maximum is 1. In the limit of no noise and if the source falls exactly at the center of a map pixel, one could just read the value of this pixel to determine the flux. In practice, a weighted average of the pixel values mp is required, and a simple estimator of the flux of the source is:
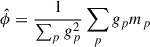 (B.1)
(B.1)
Under the assumption that the noise per pixel σp is independent, the variance of this estimator is expressed as
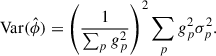 (B.2)
(B.2)
Thus, under the assumption of uniform noise per pixel σ, the uncertainty on the flux of the source is simply:
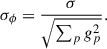 (B.3)
(B.3)
We can now relate the instrumental noise per beam to the overall variance of the unmasked pixels of our maps. Let us use the same notation as in the text to denote the value of a pixel Ap, its signal content Sp and its noise ap, then:
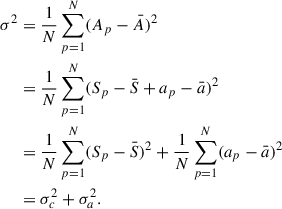 (B.4)
(B.4)
According to Eq. (B.3), the instrumental noise per beam is now expressed as
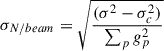 (B.5)
(B.5)
Computing σ2 on our final maps and using the values of the confusion derived in Sect 4.3, i.e. 139 and 39 μJy/beam, we thus find σN/beam = 218 and 60 μJy/beam at 1.2 and 2 mm, respectively.
Appendix C: The KID Möbius circle calibration method
In a nutshell, a KID is monitored by its response to two excitation signals, one in phase I and the other one in quadrature Q. The KID tone, set at frequency f is modulated by a known Δf frequency shift, every half millisecond, that induces variations of these excitation signals by those measured quantities dI and dQ (Catalano et al. 2014). Calvo et al. (2013) have shown different methods to use these quantities to monitor the variations of the resonance frequency f0 of a KID when it collects photons, and how to relate them to the incoming power. We here present yet another method, that proves to be more robust against numerical integration. It relies on 1D (instead of 2D) polynomial fit. It is also easier to implement in algorithmic terms. The idea is to find how to project I, Q and dI, dQ onto an axis in a way that is as linear as possible with frequency, itself shown to be linear with optical power (Monfardini et al. 2014). This is provided by the Möbius transform.
We study the expected physical Z = I + jQ complex dependency of a KID with frequency. Grabovskij et al. (2008) have shown that
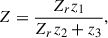 (C.1)
(C.1)
where z1, z2 and z3 are constant complexes, and 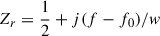 where f0 and w are real values in Hz. The location of Z is on a circle, at least approximately when near the resonance (see Fig. C.2.2 and the subsection below on Circle Fit). The inverse of Z is a circle, but we can transform it to have an infinite radius circle i.e. a line, which can be expected to be linearised with the KID frequency. To simplify the solution of this inversion, we proceed in two steps. The first step is to scale, translate, rotate and reverse the initial circle so that it is identical to the reference circle defined as a
where f0 and w are real values in Hz. The location of Z is on a circle, at least approximately when near the resonance (see Fig. C.2.2 and the subsection below on Circle Fit). The inverse of Z is a circle, but we can transform it to have an infinite radius circle i.e. a line, which can be expected to be linearised with the KID frequency. To simplify the solution of this inversion, we proceed in two steps. The first step is to scale, translate, rotate and reverse the initial circle so that it is identical to the reference circle defined as a 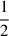 radius, and
radius, and 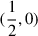 centre, in the complex plane, as defined by:
centre, in the complex plane, as defined by:
![Mathematical equation: $$ Z_{ref}=\frac{1}{2}+\frac{1}{2}[\cos \phi +j\sin \phi ]=\cos \frac{\phi }{2}\exp j\frac{\phi }{2}. $$](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq58.gif)
The second step consists in inverting that reference circle (the Möbius transform), as 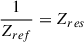 with
with
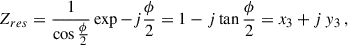
and 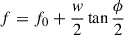 . The imaginary part of the inversion of the reference circle is just linearly dependent on the frequency, to first order. To calibrate this dependency (because the linearity is only approximate) we must rely on the dI, and dQ measurements (see the subsection below on 1D polynomial fit).
. The imaginary part of the inversion of the reference circle is just linearly dependent on the frequency, to first order. To calibrate this dependency (because the linearity is only approximate) we must rely on the dI, and dQ measurements (see the subsection below on 1D polynomial fit).
Circle fit
The first step is best achieved with a circle fit to the data samples5. Then, if r is the radius of the circle and xc, yc its centre and 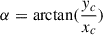 , the complex Z becomes Znorm with
, the complex Z becomes Znorm with ![Mathematical equation: $ I_{norm}=-\frac{1}{2r}[(I-x_{c})\cos\alpha+(Q-y_{c})\sin\alpha]+\frac{1}{2} $](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq63.gif) , and
, and ![Mathematical equation: $ Q_{norm}=\frac{1}{2r}[-(I-x_{c})\sin\alpha+(Q-y_{c})\cos\alpha] $](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq64.gif) . This is shown in Fig. C.1.1 where the top-left plot shows Z and the top-right plot shows Znorm. This figure is made with a simple simulation using Eq. (C.1) and including some noise. The bottom-left plot shows the inverse of Znorm. The data points lie mostly along the imaginary line of abscissa unity and of ordinate y3. The transform from mostly circular data on a plane to a one dimensional data stream is a particular case of Möbius transforms. They preserve angles, and this property is used in the following to propagate the calibration from the circle to the imaginary line.
. This is shown in Fig. C.1.1 where the top-left plot shows Z and the top-right plot shows Znorm. This figure is made with a simple simulation using Eq. (C.1) and including some noise. The bottom-left plot shows the inverse of Znorm. The data points lie mostly along the imaginary line of abscissa unity and of ordinate y3. The transform from mostly circular data on a plane to a one dimensional data stream is a particular case of Möbius transforms. They preserve angles, and this property is used in the following to propagate the calibration from the circle to the imaginary line.
 |
Fig. C.1. Illustration of our use of a Möbius transform to derive the total power measured by a KID on a simulation. Top-left: black diamonds are individual I, Q points on a circle (blue curve). Top-right: normalised circle transformation of the points into the reference circle coordinates. The resonance is reached at (1,0). Bottom-left: Complex inverse of the points in the previous complex plane (the Möbius transform). Bottom-right: 1D polynomial fit (blue curve) to the derivative data points corresponding to dI, dQ normalised, inverted and selected on the imaginary axis. |
1D polynomial fit
We need to calibrate y3 which is nearly proportional to f − f0. The modulation technique gives us this calibration via the derivative function. Let us call dI, and dQ, the measured variations of the signal with a modulation of frequency of Δf. The normalised variations are ![Mathematical equation: $ dI_{norm}=-\frac{1}{2r}[dI\cos\alpha+dQ\sin\alpha] $](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq65.gif) , and
, and ![Mathematical equation: $ dQ_{norm}=\frac{1}{2r}[-dI\sin\alpha+dQ\cos\alpha] $](/articles/aa/full_html/2026/01/aa54530-25/aa54530-25-eq66.gif) . The derivative of the inverse complex is
. The derivative of the inverse complex is 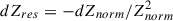 . We then take the imaginary part of dy3 and use it to calibrate y3 in this way: we fit
. We then take the imaginary part of dy3 and use it to calibrate y3 in this way: we fit 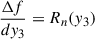 where Rn is a polynomial of degree n (see bottom-right panel of Fig. C.1.1) which is easy to integrate into Pn + 1 (with Ṗn+1 = Rn). We then obtain the relative frequency of the KID from y3 only with f − f0 = Pn + 1(y3) which is plotted in Fig. C.2.2 along with the residual of the fit.
where Rn is a polynomial of degree n (see bottom-right panel of Fig. C.1.1) which is easy to integrate into Pn + 1 (with Ṗn+1 = Rn). We then obtain the relative frequency of the KID from y3 only with f − f0 = Pn + 1(y3) which is plotted in Fig. C.2.2 along with the residual of the fit.
 |
Fig. C.2. Comparison between the KID simulation and the 1D polynomial retrieval. Relative KID frequency as a function of the phase ϕ in the circle, as deduced from the 1D polynomial fit (grey curve) and from the initial simulation (red dashed curve). The small wiggly horizontal black line represents the residual frequency (grey curve minus red curve) multiplied by a factor ten for visibility, as a function of the same phase. |
The method is robust if the polynomial fit is weighted. Indeed, the noise on the derivative measurement (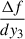 ) increases as the phase changes (see the bottom-right panel of Fig. C.1.1 where the flaring away from the zero phase is apparent). The noise is proportional to the noise in dy3 divided by
) increases as the phase changes (see the bottom-right panel of Fig. C.1.1 where the flaring away from the zero phase is apparent). The noise is proportional to the noise in dy3 divided by 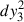 . The noise in dy3 is not constant. It can be shown that it is inversely proportional to the distance of the current I, Q point to the point in the circle which is opposite to the resonance point. This noise model can also be used to show that the noise on the recovered frequency is flaring as we go away from the resonance. To a good approximation, the rms noise is proportional to
. The noise in dy3 is not constant. It can be shown that it is inversely proportional to the distance of the current I, Q point to the point in the circle which is opposite to the resonance point. This noise model can also be used to show that the noise on the recovered frequency is flaring as we go away from the resonance. To a good approximation, the rms noise is proportional to 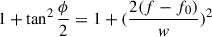 . Hence, although a KID is a linear device, its noise depends on the distance of the measuring tone frequency to the resonance frequency.
. Hence, although a KID is a linear device, its noise depends on the distance of the measuring tone frequency to the resonance frequency.
This Möbius Circle calibration method is better at accounting for the quick variations of dI, dQ and as such, is even more linear than previous methods. Another benefit of the method is that the sky noise, mostly due to water vapour fluctuations in the first kilometres of the atmosphere, is calibrated more accurately between KIDs, on the long time scales, whereas other methods have a random drift 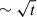 . Here, the global circle method ensures that the measured KID frequency is unique for a given point in the [I, Q] plane. The atmospheric common mode can thus be removed with less residual noise.
. Here, the global circle method ensures that the measured KID frequency is unique for a given point in the [I, Q] plane. The atmospheric common mode can thus be removed with less residual noise.
All Tables
All Figures
|
Fig. 1. Maps of GOODS-North used in this work (left 1.2 mm, right 2 mm). The black contours define the region (i.e. mask) that we use to compute the confusion. |
| In the text | |
|
Fig. 2. Variance of the N2CLS maps vs. the out of atmosphere integration time on a region in the center equivalent to one NIKA2 field of view (6.5 arcmin diameter). To determine these data points, we simply take the variance of the unmasked pixels (see Fig. 1) in the central area. For each NIKA2 band, the lower plot shows the residuals compared to the t−1/2 instrumental noise integration that is fitted here for times of integration smaller than 20 000 s. The error bars are the square roots of the diagonal elements of the covariance matrix of the measures (Fig. A.2), derived from 100 Monte-Carlo simulations of map-based realistic noise (per scan). There is a clear excess of signal at high integration time due to the confusion, but as explained in the main text, this plot is for illustrative purposes only and is not used to derive our final results. |
| In the text | |
|
Fig. 3. Likelihoods (normalised to their maximum) of the confusion at 1 mm, 2 mm, and the cross-confusion 1 × 2 mm for different subsets of our data. The central points and their 1-σ equivalent error bars are shown for convenience and have arbitrary ordinates. ‘Half 1’ refers to scans oriented at 40°. ‘Half 2’ refers to scans oriented at −50°. ‘All’ refers to the total sum of the two. |
| In the text | |
|
Fig. 4. Relative contribution to the background (blue curve) and to the fluctuations causing the confusion (red curve) as a function of the flux density derived with the SIDES simulation at 1.2 mm (left) and 2 mm (right) (see Sect. 5). The same quantities derived from the source counts measurements in GOODS-N by Bing et al. (2023) are shown as blue circles and red squares, respectively. The difference between the prediction of galaxy counts from SIDES and the source counts from N2CLS is well understood and caused by the blending of galaxies into the NIKA2 beam (see the analysis in Bing et al. 2023). The grey area shows the flux density regime where the sources are masked and do not contribute to the confusion. |
| In the text | |
|
Fig. A.1. Estimates of the cross-variance at 1.2 mm for all pairs of independent observation runs in (μJy/beam)2. Error bars are the square root of the diagonal elements of the covariance matrix of ρi shown on Fig. A.2. The dashed line marks zero and the solid line is the combined cross-variance (see Eq. (A.14)). |
| In the text | |
|
Fig. A.2. Covariance matrix of the 66 cross-variance estimates. Each pixel of this image is an element of this 66 × 66 matrix, and its value is given by the color bar. The color scale is saturated on purpose to display the off-diagonal terms. The top plot shows the diagonal elements of the matrix. The blocks, dots and lines that appear in the matrix reflect the correlations when the same map is used in Eq. (A.9). |
| In the text | |
|
Fig. C.1. Illustration of our use of a Möbius transform to derive the total power measured by a KID on a simulation. Top-left: black diamonds are individual I, Q points on a circle (blue curve). Top-right: normalised circle transformation of the points into the reference circle coordinates. The resonance is reached at (1,0). Bottom-left: Complex inverse of the points in the previous complex plane (the Möbius transform). Bottom-right: 1D polynomial fit (blue curve) to the derivative data points corresponding to dI, dQ normalised, inverted and selected on the imaginary axis. |
| In the text | |
|
Fig. C.2. Comparison between the KID simulation and the 1D polynomial retrieval. Relative KID frequency as a function of the phase ϕ in the circle, as deduced from the 1D polynomial fit (grey curve) and from the initial simulation (red dashed curve). The small wiggly horizontal black line represents the residual frequency (grey curve minus red curve) multiplied by a factor ten for visibility, as a function of the same phase. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.