| Issue |
A&A
Volume 706, February 2026
|
|
|---|---|---|
| Article Number | A201 | |
| Number of page(s) | 17 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202556710 | |
| Published online | 13 February 2026 | |
A normalizing flow approach for the inference of star cluster properties from unresolved broadband photometry
I. Comparison to spectral energy distribution fitting
1
Universität Heidelberg, Zentrum für Astronomie, Institut für Theoretische Astrophysik,
Albert-Ueberle-Straße 2,
69120
Heidelberg,
Germany
2
Universität Heidelberg, Interdisziplinäres Zentrum für Wissenschaftliches Rechnen,
INF 225,
69120
Heidelberg,
Germany
3
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange,
06000,
Nice,
France
4
Instituto de Astronomía, Universidad Nacional Autónoma de México,
Unidad Académica en Ensenada, Km 103 Carr. Tijuana–Ensenada,
Ensenada,
B.C., C.P.
22860,
Mexico
5
INAF – Arcetri Astrophysical Observatory,
Largo E. Fermi 5,
I-50125,
Florence,
Italy
6
Department of Physics and Astronomy, University of Wyoming,
Laramie,
WY
82071,
USA
7
Research School of Astronomy and Astrophysics, Australian National University,
Canberra,
ACT 2611,
Australia
8
Department of Physics and Astronomy, The Johns Hopkins University,
Baltimore,
MD
21218,
USA
9
Space Telescope Science Institute,
Baltimore,
MD,
USA
10
Sub-department of Astrophysics, Department of Physics, University of Oxford,
Keble Road,
Oxford
OX1 3RH,
UK
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
1
August
2025
Accepted:
2
December
2025
Abstract
Context. Estimating properties of star clusters from unresolved broadband photometry is a challenging problem that is classically tackled using spectral energy distribution (SED) fitting methods that are based on simple stellar population models. However, grid-based methods suffer from computational limitations. Because of their exponential scaling, they can become intractable when the number of inference parameters grows. In addition, nuisance parameters in the model can make the computation of the likelihood function intractable. These limitations can be overcome by modern generative deep learning methods that offer flexible and powerful tools for modeling high-dimensional posterior distributions and fast inference from learned data.
Aims. We present a normalizing flow approach for the inference of cluster age, mass, and reddening parameters from Hubble Space Telescope broadband photometry. In particular, we explore our network’s behavior when dealing with an inference problem that has been analyzed in previous works.
Methods. We used the SED modeling code CIGALE to create a dataset of synthetic photometric observations for 5 × 106 mock star clusters. Subsequently, this dataset was used to train a coupling-based flow in the form of a conditional invertible neural network to predict posterior probability distributions for cluster age, mass, and reddening from photometric observations.
Results. We predicted cluster parameters for the Physics at High Angular resolution in Nearby GalaxieS (PHANGS) Data Release 3 catalog. To evaluate the capabilities of the network, we compared our results to the publicly available PHANGS estimates and found that the estimates agree reasonably well.
Conclusions. We demonstrate that normalizing flow methods can be a viable tool for the inference of cluster parameters, and argue that this approach is especially useful when nuisance parameters make the computation of the likelihood intractable and in scenarios that require efficient density estimation.
Key words: methods: data analysis / methods: statistical / techniques: photometric / catalogs / galaxies: star clusters: general
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Star clusters form a link between the small-scale physics of star formation and stellar evolution and the large-scale physics of galactic environments and galaxy evolution. Young open clusters can inform us about the most recent star formation history of the host galaxy, while old globular clusters encode information about early galactic evolution. In light of this, there has been an effort to characterize the main parameters (i.e., age and mass) of galactic and extragalactic star clusters (e.g., Fall et al. 2005; Chandar et al. 2016; Gontcharov et al. 2019; Turner et al. 2021).
High-resolution surveys of nearby galaxies (d < 25 Mpc) that retrieve UV-to-optical broadband photometry, like the Legacy ExtraGalactic Ultraviolet Survey (LEGUS; Calzetti et al. 2015) and Physics at High Angular resolution in Nearby GalaxieS (PHANGS) Hubble Space Telescope (HST; Lee et al. 2022, 2023) surveys, enable the detection and classification of thousands of clusters per galaxy. However, at these distances, the stellar populations that constitute the clusters can typically not be resolved to the degree that is necessary for the construction of color-magnitude diagrams. Consequently, age and mass estimates are based on the integrated photometry of the clusters. By fitting the observed photometry to a grid of model photometry (under the assumption of an appropriate noise model), maximum-likelihood estimates (MLEs) of cluster parameters can be retrieved (see, e.g., Turner et al. 2021). Alternatively, the likelihood function can be multiplied by a suitable prior probability density to find the posterior distribution of cluster parameters (thus opting for Bayesian analysis). In the simplest case, the model photometry is calculated from a spectral energy distribution (SED) modeling code that assumes that the members of the cluster population have the same age and follow the initial mass function (IMF; i.e., a simple stellar population). In addition, dust attenuation can have a substantial effect on the UV and optical broadband fluxes and needs to be included to generate realistic SED models. In principle, there is a wide range of additional effects that can be included in the model (nebular emissions, stochastic IMF sampling for low-mass clusters, etc.) to create ever more realistic SEDs with the tradeoff of a higher computational cost.
In this work, we focus on the SED modeling code CIGALE (Code Investigating GALaxy Emission; Burgarella et al. 2005; Noll et al. 2009; Boquien et al. 2019), which is capable of producing mock star cluster photometry. Using a training set based on simulated CIGALE photometry, we attempted to model the Bayesian posterior probability distributions of the star cluster parameters with a deep learning approach based on the conditional invertible neural network (cINN) proposed by Ardizzone et al. (2019). This specific network has already seen applications in image processing (Ardizzone et al. 2019), medicine (Nölke et al. 2021; Denker et al. 2021), and astronomy (Ksoll et al. 2020; Kang et al. 2022; Haldemann et al. 2023; Bister et al. 2023; Kang et al. 2023; Kang et al. 2023; Eisert et al. 2023; Ksoll et al. 2024) and is based on the general framework of normalizing flows. We give a more detailed description of the method in Sect. 2.1.
The CIGALE forward model is computationally inexpensive and can be used to directly compute the posterior probability distributions over a sufficiently dense grid via Bayes’ theorem (Turner et al. 2021). For the simplest case, no neural network approach is needed to solve the cluster inference problem. However, the complexity of the forward model can drastically increase with the addition of nuisance parameters in the model. With nuisance parameters, we specifically mean quantities that we neither observe nor predict but whose stochasticity or uncertainty can nevertheless influence the result. For example, stochasticity in the distribution of stellar masses can have a large effect on the SED for low-mass clusters (<104 M⊙; da Silva et al. 2012; Orozco-Duarte et al. 2022) and is consequently of crucial importance when estimating the properties of clusters with few stars. In general, there can be many such nuisance parameters in the model. Take, as an example, the RV parameter of the Cardelli et al. (1989) dust attenuation law. We might want to account for the fact that we do not know the true value of the RV parameter with certainty (as suggested by the observed RV variability in the Milky Way; Zhang et al. 2023b). A more honest model might account for the uncertainty by assuming that RV follows some distribution: RV ~ p(RV) (deploying a probabilistic interpretation of RV in line with Bayesian reasoning). Since we do not observe RV directly and do not aim to predict it, it will effectively constitute a nuisance parameter of our model, similar to the stochasticity of the IMF. Of course, any other model parameter can, in principle, be treated in the same way.
This poses computational problems to the classic grid-based approaches that are ubiquitously used to retrieve cluster ages and masses. Formally, we can understand this by considering the likelihood function when we have a set of n nuisance parameters ![Mathematical equation: $\[\boldsymbol{\theta}^*=\left(\theta_1^*, \ldots, \theta_n^*\right)^T\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq1.png) :
:
![Mathematical equation: $\[p(\mathbf{x} \mid \boldsymbol{\theta})=\int p\left(\mathbf{x}, \boldsymbol{\theta}^* \mid \boldsymbol{\theta}\right) d \boldsymbol{\theta}^*=\int p\left(\mathbf{x} \mid \boldsymbol{\theta}, \boldsymbol{\theta}^*\right) \cdot p\left(\boldsymbol{\theta}^* \mid \boldsymbol{\theta}\right) d \boldsymbol{\theta}^*,\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq2.png) (1)
(1)
where θ denotes the cluster parameters and x the photometric observations. Usually, the function p(x | θ, θ*) is tractable but needs to be averaged over all combinations of ![Mathematical equation: $\[\boldsymbol{\theta}^{*}=\left(\theta_{1}^{*}, \ldots, \theta_{n}^{*}\right)^{T}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq3.png) . Adding a new grid dimension for every nuisance parameter quickly becomes intractable due to the “curse of dimensionality.” Alternatively, one can retrieve the likelihood as a Monte Carlo estimate:
. Adding a new grid dimension for every nuisance parameter quickly becomes intractable due to the “curse of dimensionality.” Alternatively, one can retrieve the likelihood as a Monte Carlo estimate:
![Mathematical equation: $\[p(\mathbf{x} \mid \boldsymbol{\theta})=\mathbb{E}_{\boldsymbol{\theta}^* \sim p\left(\boldsymbol{\theta}^* \mid \boldsymbol{\theta}\right)}\left[p\left(\mathbf{x} \mid \boldsymbol{\theta}, \boldsymbol{\theta}^*\right)\right] \approx \frac{1}{M} \sum_{i=1}^M p\left(\mathbf{x} \mid \boldsymbol{\theta}, \boldsymbol{\theta}_i^*\right).\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq4.png) (2)
(2)
However, even this can be intractable if the variance of p(x | θ, θ*) is sufficiently large, since the variance of the sample mean is given by Varθ* (p(x | θ, θ*))/M. In these cases, so-called likelihood-free approaches (sometimes referred to as simulation-based inference) are a natural choice since they do not rely on an explicit calculation of the likelihood (see, e.g., Cranmer et al. 2020). Instead, they require only the ability to generate output samples with the forward model. Normalizing flow approaches like the cINN can be trained in a likelihood-free manner and are therefore ideal candidates for these kinds of problems. In addition, the computational cost of normalizing flows is amortized. This means that an initial high computational cost (training, hyperparameter search, etc.) is compensated for by a low computational cost during inference. For example, in the context of galaxy parameter estimation, Hahn & Melchior (2022) reduced the inference time per galaxy from 10–100 CPU hr to ~ 1s. This property is especially useful when forward models become more complex (i.e., computationally expensive) and the number of inferences becomes large (e.g., when cluster catalogs become more extensive) and constitutes a particular advantage over the classical Markov chain Monte Carlo (MCMC) approach, which requires a re-simulation for every inference. We give a more detailed discussion of the computational advantages and disadvantages in Sect. 4.
In recent years, normalizing flows have seen applications in a wide range of astronomical inference problems. Examples include stellar parameter estimation (Zhang et al. 2023a; Candebat et al. 2024), exoplanetary atmospheric retrieval (Vasist et al. 2023), and the inference of galaxy properties (Khullar et al. 2022). Conceptually, our work is perhaps most similar to Hahn & Melchior (2022), who used masked autoregressive flows in conjunction with an SED modeling code to infer galaxy properties from broadband photometry.
To introduce normalizing flows for the inference of star cluster properties, we based our approach on a CIGALE model with a fully sampled IMF, a small number of photometric filters (five HST filters), and only three inference parameters (age, mass, and color excess (EB–V), hereafter reddening). We wanted to explore the behavior of the cINN in this simplified setting before applying it to the more general and complex problem (i.e., models with nuisance parameters and a possibly larger number of photometric filters and inference parameters), which will be the focus of a follow-up paper. This allowed us to evaluate the performance of the network without additional confounding variables and enabled comparisons with previous works based on the standard approach of SED forward modeling and fitting. Specifically, we replicated the CIGALE setup of Turner et al. (2021) and compared our estimates to theirs. We want to stress that in this simplified setting, the normalizing flow approach is not necessary since posterior densities can be calculated directly over a relatively fine parameter grid.
We discuss the general normalizing flow approach, the cINN architecture, and the training procedure in Sect. 2.1. Sections 2.2 and 2.3 describe the synthetic data (used for training) and the catalog of real cluster photometry (used for the comparison with Turner et al. 2021). In Sect. 3 we present various tests and evaluations on a held-out test set from the synthetic dataset (Sect. 3.1) and the real observations (Sect. 3.2). Finally, Sect. 4 provides a discussion of the advantages and disadvantages of the normalizing flow approach and compares it to other commonly used inference methods. The main results of our work are summarized in Sect. 5.
2 Methods
2.1 Normalizing flows and the cINN architecture
Normalizing flows form a class of generative models that can be used to directly compute the probability density of the underlying dataset (Kobyzev et al. 2021). This is in contrast to other methods like generative adversarial networks (Goodfellow et al. 2014) or variational autoencoders (Kingma & Welling 2013), which typically cannot be used to directly estimate densities. This is achieved by constructing an expressive mapping fϕ that transforms a well-behaved base distribution (commonly a multivariate standard normal) into the target distribution (i.e., the distribution of the training set): fϕ(Z) ≈ Θ, where Θ denotes the target variables and ϕ the collection of free parameters of f (e.g., the weights and biases of a neural network). In our case, Θ refers to the cluster parameters for which we want to model the posterior probability density. The variables Z ~ 𝒩(0, 𝕀) are commonly called “latent variables.” Usually, Z does not have a direct physical meaning. Under the condition that fϕ is invertible and differentiable, the density of fϕ(Z) can be calculated from the density of the latent variables via the change-of-variables formula:
![Mathematical equation: $\[p_{f_\boldsymbol{\phi}(\mathbf{Z})}(\boldsymbol{\theta})=\frac{p_{\mathbf{Z}}\left(f_{\boldsymbol{\phi}}^{-1}(\boldsymbol{\theta})\right)}{\left|\operatorname{det} J_{f_\boldsymbol{\phi}}\left(f_{\boldsymbol{\phi}}^{-1}(\boldsymbol{\theta})\right)\right|},\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq5.png) (3)
(3)
where Jfϕ denotes the Jacobi matrix of fϕ. The network parameters ϕ can then be retrieved by maximum-likelihood estimation – or equivalently by minimizing the Kullback–Leibler divergence DKL(pΘ ∥ pfϕ(Z) (see, e.g., Papamakarios et al. 2021) – which leads to a negative log-likelihood function of the form
![Mathematical equation: $\[-\log L(\boldsymbol{\phi}) \propto \frac{1}{N} \sum_{i=1}^N\left(\frac{\left\|f_{\boldsymbol{\phi}}^{-1}\left(\boldsymbol{\theta}_i\right)\right\|^2}{2}+\log \left|\operatorname{det} J_{f_{\boldsymbol{\phi}}}\left(f_{\boldsymbol{\phi}}^{-1}\left(\boldsymbol{\theta}_i\right)\right)\right|\right),\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq6.png) (4)
(4)
where L(ϕ) denotes the likelihood function relative to some training set {θ1, . . ., θN}.
Once the network is trained, it can be used for both density estimation (using Eq. (3)) and sampling. To generate samples of the target distribution, one simply draws samples from the latent variable distribution z1, . . ., zk ~ 𝒩(0,𝕀) and transforms them to the target space fϕ(z1), . . ., fϕ(zk). Note that sampling requires the evaluation of the forward direction of the network, while density estimation requires the backward direction.
In practice, one is usually not interested in modeling a single probability density distribution but an entire family of conditional probability density distributions. In that case, fϕ will have an additional input x (i.e., fϕ(θ; x)) that denotes the variables over which the probability distribution is conditioned (in our case the cluster photometry).
For the mapping fϕ, we used the cINN architecture of Ardizzone et al. (2019), which is based on the composition of invertible coupling blocks that have a tractable determinant of the Jacobian. For an input vector θj (in the j-th network layer), the coupling blocks split the vector into two sub-vectors ![Mathematical equation: $\[\boldsymbol{\theta}_{j}=\left\{\boldsymbol{\theta}_{j}^{(1)}, \boldsymbol{\theta}_{j}^{(2)}\right\}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq9.png) and perform the transformation
and perform the transformation
![Mathematical equation: $\[\boldsymbol{\theta}_{j+1}^{(1)}=\boldsymbol{\theta}_j^{(1)} \odot \exp \left(s_1\left(\boldsymbol{\theta}_j^{(2)}, \mathbf{x}\right)\right) \oplus t_1\left(\boldsymbol{\theta}_j^{(2)}, \mathbf{x}\right)\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq10.png) (5)
(5)
![Mathematical equation: $\[\boldsymbol{\theta}_{j+1}^{(2)}=\boldsymbol{\theta}_j^{(2)} \odot \exp \left(s_2\left(\boldsymbol{\theta}_{j+1}^{(1)}, \mathbf{x}\right)\right) \oplus t_2\left(\boldsymbol{\theta}_{j+1}^{(1)}, \mathbf{x}\right)\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq11.png) (6)
(6)
![Mathematical equation: $\[\boldsymbol{\theta}_{j+1}=\left\{\boldsymbol{\theta}_{j+1}^{(1)}, \boldsymbol{\theta}_{j+1}^{(2)}\right\},\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq12.png) (7)
(7)
where ⊙ and ⊕ denote the component-wise multiplication and addition. The mappings s1, s2, t1, and t2 are realized by fully connected multilayer neural networks. We can visualize this mapping in a flowchart (see Fig. 1), from which it is apparent that the coupling block transformation is indeed invertible. For further details on the expressibility and the Jacobian matrix of coupling-based architectures, we refer to Dinh et al. (2017). In actuality, the four subnetworks – s1, s2, t1, and t2 – are combined to two subnetworks – s1/t1 and s2/t2 – that produce both the multiplicative and additive output inside the coupling block. With the successive composition of these coupling blocks, we can create highly expressive mappings. To further increase the expressibility, the output vector components are permuted before they are passed to the next coupling block. These permutations are randomly initialized but fixed during training and testing, i.e., there is the same permutation for every run.
To minimize the negative log-likelihood, – log L(ϕ), during training, we used the gradient descent based Adam optimizer (Kingma & Ba 2014) and an additional regularization term ![Mathematical equation: $\[\eta \cdot\|\boldsymbol{\phi}\|_{2}^{2}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq13.png) to prevent overfitting. To optimize the hyperparameters of the network, we used the HYPERBAND algorithm, as proposed by Li et al. (2018). A full list of hyperparameters is given in Appendix A. The network is implemented through the PyTorch-based (Paszke et al. 2019) Framework for easily Invertible Architectures (FrEIA; Ardizzone et al. 2018–2022).
to prevent overfitting. To optimize the hyperparameters of the network, we used the HYPERBAND algorithm, as proposed by Li et al. (2018). A full list of hyperparameters is given in Appendix A. The network is implemented through the PyTorch-based (Paszke et al. 2019) Framework for easily Invertible Architectures (FrEIA; Ardizzone et al. 2018–2022).
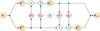 |
Fig. 1 Flowchart of single coupling block (representing Eqs. (5), (6), and (7)) taken from Walter (2023). The input vector, θj, is split into two sub-vectors, |
![Mathematical equation: $\[\boldsymbol{\theta}_{j}^{(1)}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq7.png)
![Mathematical equation: $\[\boldsymbol{\theta}_{j}^{(2)}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq8.png)
2.2 Synthetic data
To generate the synthetic training set, we used the PHANGS branch of the CIGALE GitLab repository1 and reproduced the configuration setup of Turner et al. (2021). In this setup, the simple stellar population spectra are based on the Bruzual & Charlot (2003) model and the star formation history is modeled as an instantaneous burst. To account for dust, the SED is reddened by a Milky Way extinction screen using the Cardelli et al. (1989) law. Nebular emissions of young clusters are not accounted for.
For the synthetic photometry, we considered the five HST WFC3-UVIS filters used in the PHANGS survey, namely F275W (near-UV), F336W (U), F438W (B), F555W (V), and F814W (I), ranging from the UV to the near-infrared. In this wavelength range, dust emission is practically absent and therefore neglected.
We assumed a prior distribution of cluster parameters that is log-uniform for age (t) and initial mass (m0), and uniform for reddening (EB–V), i.e., log10 t ~ 𝒰, log10 m0 ~ 𝒰 and EB–V ~ 𝒰. The parameters are assumed to be independent in the prior with parameter ranges 1 Myr < t < 13750 Myr, 102 M⊙ < m0 < 108 M⊙ and 0 mag < EB–V < 1.5 mag. This implies that the prior is jointly uniform over the parameters log10 t, log10 m0 and EB–V. We note that this distribution is not physically motivated. Instead, it has the advantage of allowing us to easily compare our maximum a posteriori (MAP) estimates with the PHANGS MLEs. Under the assumption of a uniform prior, the two estimates must be equivalent:
![Mathematical equation: $\[p(\boldsymbol{\theta})=\mathcal{U}(\boldsymbol{\theta}) \Longrightarrow p(\boldsymbol{\theta} \mid \mathbf{x}) \propto p(\mathbf{x} \mid \boldsymbol{\theta}) \Longrightarrow \text { MAP }=\text { MLE. }\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq14.png) (8)
(8)
Note also that these priors do not replicate the priors that Turner et al. (2021) use in their Bayesian analysis. Therefore, we only replicated their MLEs and not their Bayesian estimates.
From this distribution, we sampled ≈5 × 106 mock star clusters, for which we simulated broadband photometry with CIGALE. From these, ≈105 example clusters are held out as a test set and an additional ≈105 are held out as a validation set for the hyperparameter search.
Our CIGALE setup is limited to an age resolution of 1 Myr. We find that the network learns to reproduce this grid structure, which results in undesirable peaks in the posterior at the positions of the grid points. This also leads to computational problems for the flow model, since the probability density at these points is essentially infinite. To alleviate this, we added a uniform noise to the age grid so that the probability mass at these points is distributed over the entire valid range: t′ = t + ϵ, with ϵ ~ 𝒰[−0.5,0.5]. This prevents the network from overfitting on the parameter grid.
By default, CIGALE generates photometry normalized to a reference distance of d0 = 10 pc (for redshift z = 0). We wanted the network to be able to generate parameter estimates for a range of distances. Thus, for every photometric value in the synthetic dataset, we randomly sampled a distance d ~ 𝒰[1 Mpc, 30 Mpc] and corrected the photometric fluxes via f′ = f · (d0/d)2. The parameter d is then cast as an additional conditioning input.
To account for measurement uncertainties, we added random noise to the photometry: for every mock cluster photometry f, we sampled a relative error r ~ 𝒰[0, 0.5] (i.e., a maximum relative error of 50%), from which we retrieved an uncertainty σ = f · r. We then generated a noisy observation by sampling from a log-normal distribution with mean f and standard deviation σ, i.e., f* ~ ℒ𝒩(f, σ) (this is equivalent to a normally distributed noise in magnitude space). The observed relative error r* = σ/f* is saved and passed to the network as an additional conditioning input. That way, the cINN learns how a wide range of measurement uncertainties affect the photometry. Note that we deviated from Turner et al. (2021) here, who assumed a normally distributed noise on the fluxes. This is mainly motivated by a technical issue that we encounter when training the network. We find the best results when the fluxes are logarithmically scaled before passing them to the network. Naturally, this is only possible if the fluxes are strictly positive. A log-normal noise model guarantees exactly that. Normally distributed noise will generally lead to negative flux values in the training set. Of course, it is possible to shift the resulting distribution to positive values and apply a log-transformation afterward. However, we found that the resulting preprocessing led to poorer overall performance. Using a positively truncated normal distribution is also possible, but results in a distribution with a systematically lower standard deviation. This can be corrected by rescaling the distribution, but again leads to a noise model that is not equivalent to the approach of Turner et al. (2021). Finally, we settled on the log-normal noise model, since it provided the easiest treatment of the flux uncertainties. Figure 2 shows the distribution of relative flux uncertainties in the cluster catalog for the five photometric bands, as well as the resulting noise models for the median and maximum relative flux uncertainties. At median relative flux uncertainty, the log-normal noise model is practically indistinguishable from the normal noise model. Only for the highest relative uncertainties can we see substantial deviations in the near-UV and U band. As we will see, this can lead to considerable deviations in the parameter estimates for the clusters with the highest relative flux uncertainties. For the vast majority of clusters, however, the log-normal noise model is effectively equivalent to the normal noise model.
Since the generated fluxes span many orders of magnitudes, it is useful to represent them in log-space before passing them to the network. Overall, this results in three predicted parameters (log10 t, log10 m and EB–V) and eleven conditioning inputs (![Mathematical equation: $\[\log~ f_{\mathrm{F} 275 \mathrm{~W}}^{*}, ~\log~ f_{\mathrm{F} 336 \mathrm{~W}}^{*}, ~\log~ f_{\mathrm{F} 438 \mathrm{~W}}^{*} ~\log~ f_{\mathrm{F} 555 \mathrm{~W}}^{*}, ~\log~ f_{\mathrm{F} 814 \mathrm{~W}}^{*}, r_{\mathrm{F} 275 \mathrm{~W}}^{*}, r_{\mathrm{F336W}}^{*}, r_{\mathrm{F438W}}^{*}, r_{\mathrm{F555W}}^{*}, r_{\mathrm{F814W}}^{*}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq15.png) , and d).
, and d).
A technical difficulty arises from the fact that the prior distribution enforces sharp bounds on the parameter values. We found that it is difficult for the cINN to transform the standard normal distribution into a sharply bounded posterior distribution, which resulted in the network generating values outside the boundaries of the training set (e.g., negative EB–V values). This problem can be solved by an additional data preprocessing step that bijectively maps a bounded support onto ℝ (consequently the inverse will always be within the bounds). If Θ is a uniformly distributed random variable with support [a, b], i.e., Θ ~ 𝒰[a, b], then we have (Θ – a)/(b – a) ~ 𝒰[0,1] and consequently
![Mathematical equation: $\[\Phi^{-1}\left(\frac{\Theta-a}{b-a}\right) \sim \mathcal{N}(0,1),\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq16.png) (9)
(9)
where ![Mathematical equation: $\[\Phi(u)=\frac{1}{2} \cdot(1+\operatorname{erf}~(u / \sqrt{2}))\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq17.png) denotes the cumulative distribution function of the standard normal distribution. We used this invertible mapping component-wise on log10 t, log10 m, and EB–V to enforce the strict bounds of the prior.
denotes the cumulative distribution function of the standard normal distribution. We used this invertible mapping component-wise on log10 t, log10 m, and EB–V to enforce the strict bounds of the prior.
The generation of the synthetic dataset and training of the neural network were performed on the Compute Servers of the Interdisciplinary Center for Scientific Computing2 (IWR) in Heidelberg. For the CIGALE simulation runs, we used four 12-Core AMD Opteron 6176SE 2.3 GHz processors (≈11 h) and for the network training two 2 × 14-Core Intel Xeon Gold 6132 processors in conjunction with an Nvidia Titan Xp graphics card, taking ≈1.5–3 h for a single full training run (depending on the size of the network).
 |
Fig. 2 Top row: histograms of relative flux uncertainties in the PHANGS cluster catalog. The dotted vertical lines denote the median relative flux uncertainties, and the dashed lines denote the maximum relative flux uncertainties. Middle row: comparison of the normal noise model and the log-normal noise model for median relative flux uncertainties. Bottom row: comparison of the normal noise model and the log-normal noise model for maximum relative flux uncertainties. |
2.3 Observed data
The observed photometry is taken from the PHANGS Data Release 3 catalog (Catalog Release 1; Lee et al. 2022; Thilker et al. 2022), which are publicly available at the Mikulski Archive for Space Telescopes (MAST)3. These catalogs contain photometry for clusters in five galaxies (NGC 1433, NGC 1559, NGC 1566, NGC 3351, and NGC 3627) as well as MLEs for age, mass, and reddening based on CIGALEs fitting procedure. Note that by now, a cluster catalog over the full PHANGS-HST galaxy sample (38 galaxies) is available (Maschmann et al. 2024).
PHANGS provides catalogs of both human- and machine-classified clusters that are distinguished into Class 1 (symmetric, centrally concentrated, radial profile extended relative to point source) and Class 2 (asymmetric, centrally concentrated, radial profile extended relative to point source) type clusters. We included both Class 1 and Class 2 type clusters in our analysis but limited ourselves to the human-classified catalogs, which contain 2638 clusters in total. To simplify the evaluation with the cINN, we only kept those clusters that have information in all five photometric bands, reducing the total dataset size by 7.5% to 2439. In order to replicate the approach of Turner et al. (2021), the galaxy distances were taken from LEGUS (Calzetti et al. 2015) and uncertainties in the distances were neglected. Note, however, that better distance estimates are available (Anand et al. 2021). Finally, to fully replicate the approach of Turner et al. (2021), we added an additional 5% systematic error to the flux uncertainties:
![Mathematical equation: $\[r^{* \prime}=\sqrt{r^{* 2}+0.05^2}.\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq18.png) (10)
(10)
3 Results
3.1 Tests on synthetic data
Before we applied the network to the real-world photometry of the PHANGS catalog, we investigated its behavior on the synthetic test set. In contrast to the real-world photometry, the synthetic dataset contains the ground truth values for the cluster parameter. This allowed us to perform calibration checks on the synthetic data that we cannot perform on the PHANGS catalog (for which ground truth parameter values are unavailable). A popular diagnostic tool for assessing the quality of Bayesian inference algorithms is simulation-based calibration (SBC; Talts et al. 2018). The SBC method proceeds as follows: consider a set of simulated test parameters and observations {(θ1, x1), . . ., (θm, xm)} (i.e., a synthetic dataset that is not part of the training set of the network). For every test observation xi, generate a number of posterior samples using the generative model: ![Mathematical equation: $\[\boldsymbol{\theta}_{i, 1}^{\prime}, \ldots, \boldsymbol{\theta}_{i, n}^{\prime} \sim p_{\text {cINN }}\left(\boldsymbol{\theta} \mid \mathbf{x}_{i}\right)\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq19.png) . Now let T(θ) be any statistic of the parameters (θ). Talts et al. (2018) show that the rank of T(θi) in
. Now let T(θ) be any statistic of the parameters (θ). Talts et al. (2018) show that the rank of T(θi) in ![Mathematical equation: $\[\left\{T\left(\boldsymbol{\theta}_{i, 1}^{\prime}\right), \ldots, T\left(\boldsymbol{\theta}_{i, n}^{\prime}\right)\right\}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq20.png) must be uniformly distributed if the generative model reproduces the correct posterior distributions (i.e., pcINN(θ | x) = p(θ | x)). Deviations from uniformity are therefore an indication of modeling errors. Note that the reverse implication is generally not true (i.e., one may have completely wrong posteriors that nevertheless produce a perfectly uniform distribution over the ranks of some statistic T). We performed SBC with two sets of statistics. The first set is given by T1(θ) = t, T2(θ) = m and T3(θ) = EB–V. Deviations from uniformity for these statistics indicate issues with the marginal posterior distributions. The second set of statistics will characterize the relationships between pairs of parameters: T4(θ) = (log t) · (log m), T5(θ) = (log m) · EB–V and T6(θ) = (log t) · EB–V. Here, deviations from uniformity may indicate problems in the network’s modeling of the posterior covariances. The two sets of statistics are therefore complementary.
must be uniformly distributed if the generative model reproduces the correct posterior distributions (i.e., pcINN(θ | x) = p(θ | x)). Deviations from uniformity are therefore an indication of modeling errors. Note that the reverse implication is generally not true (i.e., one may have completely wrong posteriors that nevertheless produce a perfectly uniform distribution over the ranks of some statistic T). We performed SBC with two sets of statistics. The first set is given by T1(θ) = t, T2(θ) = m and T3(θ) = EB–V. Deviations from uniformity for these statistics indicate issues with the marginal posterior distributions. The second set of statistics will characterize the relationships between pairs of parameters: T4(θ) = (log t) · (log m), T5(θ) = (log m) · EB–V and T6(θ) = (log t) · EB–V. Here, deviations from uniformity may indicate problems in the network’s modeling of the posterior covariances. The two sets of statistics are therefore complementary.
Figure 3 (left column) shows the corresponding SBC rank histograms. As we can see, the rank distributions are roughly uniform. To emphasize deviations at small and large ranks, Talts et al. (2018) suggest pairing the rank histograms with plots of the empirical cumulative distribution function (ECDF). In Fig. 3 (right column), we show the differences between the rank ECDF and the uniform cumulative distribution function together with the 0.01–0.99 quantile range (gray area) that we would expect under perfect uniformity (assuming a binomial distribution for the values of the ECDF). The fact that the curves lie (partially) outside of the gray area, suggests a nonuniformity in the rank distribution. We can use the shape of the curves to get a rough idea of the type of failure. For example, the statistic T2 shows a slight over-concentration at low and high ranks (except for very high ranks, where we have an under-concentration) indicating that the marginal mass distributions are, on average, slightly too narrow. The statistic T3 shows an ECDF difference plot that is mostly above the expected range. This suggests that the network is, on average, overestimating the cluster reddening. The same pattern is seen in the ECDF difference plots for T5 and T6. This may indicate that the network is generating covariances between mass and reddening, as well as age and reddening, that are somewhat larger than the covariances in the test set. However, an alternative interpretation is simply that the overestimates in EB–V produce somewhat larger values in the product statistics. This is supported by the fact that the overestimation does not occur for the statistic T4 (which does not use the reddening).
 |
Fig. 3 Results of SBC analysis over the entire test set (≈105 parameter–observation pairs). We generated a hundred posterior samples for every element in the test set. Left column: rank histograms for the proposed statistics. Horizontal dashed lines correspond to the ±1σ range under the assumption of uniformity. Right column: difference between rank ECDF and uniform cumulative distribution function. The gray area highlights the expected 0.01–0.99 quantile range of the ECDF difference under the assumption of uniformity. |
3.2 Tests on PHANGS catalog
3.2.1 Posterior predictive checks
Unlike the synthetic data, the real-world photometry of the PHANGS catalog does not provide us with ground truth parameter values. This means that the SBC approach of Sect. 3.1 cannot be applied to the dataset of real-world photometry. In this case, a common approach is given by posterior predictive checks (PPCs; Rubin 1984; Gelman et al. 1996): suppose {x1, . . ., xm} is a set of observations. For every observation xi, we generated samples of the posterior from the generative model: ![Mathematical equation: $\[\boldsymbol{\theta}_{i, 1}^{\prime}, \ldots, \boldsymbol{\theta}_{i, n}^{\prime} \sim p_{\text {cINN }}\left(\boldsymbol{\theta} \mid \mathbf{x}_{i}\right)\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq21.png) . Then we re-simulated these parameters to generate corresponding synthetic observations:
. Then we re-simulated these parameters to generate corresponding synthetic observations: ![Mathematical equation: $\[\mathbf{x}_{i, j}^{\prime} \sim p\left(\mathbf{x} \mid \boldsymbol{\theta}_{i, j}\right)\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq22.png) . The resulting distribution is commonly referred to as the posterior predictive distribution of xi. We could then compare the posterior predictive distribution with the initial observation. On average, the posterior predictive distribution should not deviate strongly from the true observation. Figure 4 (left column) shows a comparison between the mean posterior predictive photometry and the initial PHANGS photometry for the five photometric bands. As we can see, the mean of the re-simulated photometry tends to be close to the ground truth. In Fig. 4, (right column) we show the rank of the PHANGS photometry within the posterior predictive distribution. Note that high and low ranks tend to be underrepresented, while mid-range ranks tend to be overrepresented. This suggests that the PHANGS photometry tends to lie well within the posterior predictive distribution. Note that we do not expect a uniform distribution of ranks in our PPC analysis. In fact, p-values of posterior predictive distributions are known to be “stochastically less variable,” i.e., more concentrated toward mid-range ranks (see Sect. 6.3 of Gelman et al. 2013).
. The resulting distribution is commonly referred to as the posterior predictive distribution of xi. We could then compare the posterior predictive distribution with the initial observation. On average, the posterior predictive distribution should not deviate strongly from the true observation. Figure 4 (left column) shows a comparison between the mean posterior predictive photometry and the initial PHANGS photometry for the five photometric bands. As we can see, the mean of the re-simulated photometry tends to be close to the ground truth. In Fig. 4, (right column) we show the rank of the PHANGS photometry within the posterior predictive distribution. Note that high and low ranks tend to be underrepresented, while mid-range ranks tend to be overrepresented. This suggests that the PHANGS photometry tends to lie well within the posterior predictive distribution. Note that we do not expect a uniform distribution of ranks in our PPC analysis. In fact, p-values of posterior predictive distributions are known to be “stochastically less variable,” i.e., more concentrated toward mid-range ranks (see Sect. 6.3 of Gelman et al. 2013).
3.2.2 Example cases
The absence of nuisance parameters in the model makes the computation of the likelihood tractable. This allows us to compute the posteriors directly. In this section we compare the cINN generated posteriors with the ground truth posteriors that we get from direct computation via Bayes’ theorem. To that end, we chose four example clusters that we used for a density comparison and that are presented in Fig. 5. We chose these examples to cover a wide cluster age range. In addition, we highlight the cINN MAP estimates (triangle) and the PHANGS MLEs (cross) in the plots.
Looking at Example I (very young), we see that the posterior distribution shows noticeable artifacts in the age versus mass histogram. These artifacts are a consequence of the fact that our CIGALE version was limited to a discrete age grid with a resolution of 1 Myr. Since the cINN is trained on the CIGALE forward model, it inherits the 1 Myr discretization, which results in grid artifacts. In log-space, this becomes noticeable in the low-age regime, where the logarithm strongly stretches the parameter space.
Example II (young) shows a clearly multimodal distribution. Notice how a difference in mode selection leads to a large discrepancy between our MAP estimate and the PHANGS estimate. Example III (intermediate age) shows a similar multi-modality. However, here, the high-age mode is much more pronounced than the low-age mode. Consequently, the two estimates coincide well. A comprehensive comparison of cINN MAP estimates and PHANGS MLEs is given in Sect. 3.2.3.
Finally, Example IV (old) shows a typical high-age posterior distribution that we included for completeness. We note, however, that the example posteriors presented in this paper cover only a small fraction of the diversity of distributions that we encounter.
 |
Fig. 4 Results of PPC analysis. Posterior predictive distributions with 500 samples each were generated for all clusters in the PHANGS catalog. Left column: comparison of the mean predictive photometry and the initial photometry. Right column: rank distribution of the initial photometry within the posterior predictive distribution. Horizontal dashed lines correspond to the ±1σ range under the assumption of uniformity. |
3.2.3 Recovering PHANGS estimates
Since our SED modeling setup is identical to Turner et al. (2021) and our prior is uniform, the cINN MAP estimates should correspond to the PHANGS MLEs (see Eq. (8)). It therefore makes sense to investigate these estimates for possible deviations.
To find the MAP values of the joint posterior distributions, we used the sampling capabilities of the cINN to generate 104 samples per posterior. We found that in some cases the result can strongly depend on the choice of MAP estimator. For the final evaluation, we settled on the mean shift estimator (Fukunaga & Hostetler 1975). The related algorithm is mode-seeking in nature and can be used to find additional (non-MAP) modes of the posterior. For every posterior, we determined up to three modes of the multidimensional joint distribution.
Figure 6 (top) shows a direct comparison between cINN MAP estimates and PHANGS MLEs for NGC 1433 (Fig. B.1 shows the same comparison for all galaxies). We find that all galaxies show similar patterns of deviation. Interestingly, the age plots show a sword-like shape. Turner et al. (2021) find an analogous sword-like pattern when they investigate how small errors in photometry affect age, mass, and reddening estimates on a sample of NGC 3351 clusters (see Sect. 3.2 and Fig. 2 of Turner et al. 2021). They report that these deviations are mostly a result of bimodalities in the underlying probability distribution functions. Likewise, we find that the large deviations around 10 Myr are mostly a result of multimodal posterior distributions. To further emphasize that the residuals are mostly a result of differing mode selection, we compared the PHANGS estimates with the peaks of the additional modes that occur in the posteriors. Figure 6 (bottom) plots the posterior modes that are closest to the PHANGS estimates against the PHANGS estimates, resulting in drastically reduced residuals (comparisons for all galaxies can be found in Fig. B.2). Generally, we find that large residuals tend to be associated with broader posterior distributions (see Fig. B.3). This again illustrates that deviations between our MAP estimates and the PHANGS MLEs occur mainly for observations that put fewer constraints on the parameters. In Table 1 we summarize inlier statistics that quantify how often the PHANGS estimates are contained within the cINN marginal posteriors and, conversely, how often the cINN point estimates are contained in the 1σ-regions of the PHANGS estimates.
To test the quality of the generated posterior samples, we used CIGALE to re-simulate the corresponding photometry for the retrieved cluster parameters. Ideally, the re-simulated photometry should be contained within the error range of the initial observations. Figure 7 shows the re-simulated SEDs of the four example clusters introduced in Sect. 3.2.3. Visually, it appears that the re-simulated SEDs of examples I, II, III, and IV are well within the ±3σ-range of the initial observation for both cINN and PHANGS estimates. To quantify the residuals, it is useful to calculate the (reduced) χ2−deviations between re-simulated photometry and ground truth observations:
![Mathematical equation: $\[\chi^2=\frac{1}{\nu} \cdot \sum_i\left(\frac{f_i^{\mathrm{resim}}-f_i}{\sigma_i}\right)^2,\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq23.png) (11)
(11)
where ν corresponds to the degrees of freedom. Figure 8 shows the χ2−deviations of re-simulated MAP estimates for the entire PHANGS catalog. Primarily, these plots indicate that the cINN MAP estimates exhibit larger χ2−deviations than the PHANGS MLEs. This is expected since the PHANGS estimates are based on a minimum χ2 fit (and are hence optimized to minimize the χ2−deviation between observation and re-simulation). The cINN, on the other hand, finds these estimates only in a very indirect way by modeling the entire probability density function (by minimizing the KL-divergence between the model posterior and target posterior) and determining the MAP estimates as a byproduct. Nevertheless, we find that these values are acceptable.
 |
Fig. 5 2D and 1D density plots of example posteriors. Top rows: marginal 1D density for the cINN posterior (gray histogram) and ground truth (dashed black line). Middle rows: 2D density of the cINN generated posterior (104 samples per posterior). Bottom rows: contour plot of ground truth densities calculated over a parameter grid. Note that we use the same color maps in the second and third rows (although the colorbars show different ranges). The yellow markers indicate positions of cINN MAP estimates (triangle) and PHANGS MLEs (cross). Continued. |
3.2.4 Outliers and the effect of a log-normal noise model
Figure 6 illustrates that a small number of clusters show large deviations even when we compare the closest mode of the cINN posterior with the CIGALE MLE. As it turns out, this is mostly an artifact of the differing noise models. As an example, take the cluster with ID 724 in NGC 1433. Figure 9 shows the posterior that the cINN generates for this cluster. As we can see, the CIGALE MLE is fully outside the support of the posterior. We mark the position of the cluster in Fig. 6 with an arrow. Clearly, this is the largest outlier in NGC 1433. At the same time, it is the only cluster in NGC 1433 that has relative flux uncertainties above 40% in both UV bands. In fact, we find that all the other major outliers are also associated with large UV band uncertainties. In Fig. 6 we mark every cluster in blue that has a relative flux uncertainty larger than 40% in at least one UV band. Figure 2 (bottom row) makes it apparent why the UV bands are of particular importance here. They tend to have much larger relative flux uncertainties and are therefore the only bands for which the log-normal noise model deviates strongly from the normal noise model. This shows that for some cases, the noise model assumptions can have a large impact on the cluster parameter estimates.
4 Discussion
The aim of this paper is to explore the network’s behavior on a simplified cluster inference problem and to establish that the cINN can produce accurate estimates of cluster age, mass, and reddening from broadband photometric observations. Our analysis shows that this is the case, both for synthetic and real-world photometry. Furthermore, the ability to model the full joint posterior distribution enables accurate uncertainty estimation and can be used as a basis for further statistical analysis (e.g., via the calculation of correlations, moments, quantiles, or entropy related quantities).
In the following, we further justify our normalizing flow approach by detailing some computational and statistical aspects of this inference method.
 |
Fig. 6 Comparison of cINN posterior modes and PHANGS MLEs for all (filtered) NGC 1433 clusters. Top panels: cINN MAP modes as determined by the mean-shift estimator. Error bars show the 16%- and 84%-quantiles of the marginalized posteriors. The yellow markers indicate the positions of the four example clusters. Bottom panels: comparison with the posterior modes that were closest to the PHANGS MLE (for every posterior, a maximum of three modes were determined). For better visibility, we omitted the error bars. The blue dots mark clusters that have relative flux uncertainties larger than 40% in at least one UV band, as discussed in Sect. 3.2.4. The arrow shows the position of the largest outlier. Comparisons for all galaxies are provided in Appendix B. |
Inlier percentages for cINN and PHANGS estimates.
4.1 Sampling and density estimation
When modeling the posterior distribution, we would like to perform two similar but distinct tasks. On the one hand, we want the ability to sample from the underlying probability distribution θ1, . . ., θn ~ p(θ | x). This enables, for example, the efficient computation of the moments of the posterior via ![Mathematical equation: $\[m_{k}=\mathbb{E}\left[\boldsymbol{\Theta}^{k}\right] \approx \frac{1}{n} \sum_{i} \boldsymbol{\theta}_{i}^{k}\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq28.png) . On the other hand, it is often interesting to assess the density of the posterior. For instance, if we want to estimate the entropy (and related quantities like KL-divergence or Mutual Information) of the posterior distribution, we need a model for the density of the posterior. In fact, combining sampling capabilities with density estimation capabilities can lead to a Monte Carlo-based estimator of the differential entropy:
. On the other hand, it is often interesting to assess the density of the posterior. For instance, if we want to estimate the entropy (and related quantities like KL-divergence or Mutual Information) of the posterior distribution, we need a model for the density of the posterior. In fact, combining sampling capabilities with density estimation capabilities can lead to a Monte Carlo-based estimator of the differential entropy: ![Mathematical equation: $\[h(\boldsymbol{\Theta} \mid \mathbf{X}=\mathbf{x})= \int p(\boldsymbol{\theta} \mid \mathbf{x}) \cdot \log~ p(\boldsymbol{\theta} \mid \mathbf{x}) d \boldsymbol{\theta} \approx \frac{1}{n} {\sum}_{i} ~\log~ p(\boldsymbol{\theta}_{i} \mid \mathbf{x})\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq29.png) . In general, sampling and density estimation provide different advantages and can enable the application of different methods.
. In general, sampling and density estimation provide different advantages and can enable the application of different methods.
Normalizing flows differentiate themselves from other methods (e.g., variational autoencoders or generative adversarial networks) by providing the capability for both efficient sampling and density estimation. The former can be achieved by first sampling the latent variable distribution and then applying the forward pass of the network, i.e., fϕ(z) with z ~ pZ. Conversely, for density estimation, we used the Jacobi determinant in conjunction with the backward pass: ![Mathematical equation: $\[p_{\boldsymbol{\Theta}}(\boldsymbol{\theta}) \approx p_{\mathbf{Z}}(f_{\boldsymbol{\phi}}^{-1}(\boldsymbol{\theta})) /|\operatorname{det}~ J_{f_{\boldsymbol{\phi}}}(f_{\boldsymbol{\phi}}^{-1}(\boldsymbol{\theta}))|\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq30.png) . Note that different normalizing flow architectures provide different efficiencies when it comes to forward and backward pass. For example, masked autoregressive flows provide an efficient backward pass and thereby efficient density estimation, but have a computationally expensive forward pass, especially for high-dimensional data (Papamakarios et al. 2017). Coupling-based architectures (like the cINN) on the other hand, have a symmetric computational cost for forward and backward pass. This makes them ideal for situations in which both sampling and density estimation are of interest. This, however, comes at the cost of a lower expressibility per flow layer (Papamakarios et al. 2021, Sect. 3.1.2).
. Note that different normalizing flow architectures provide different efficiencies when it comes to forward and backward pass. For example, masked autoregressive flows provide an efficient backward pass and thereby efficient density estimation, but have a computationally expensive forward pass, especially for high-dimensional data (Papamakarios et al. 2017). Coupling-based architectures (like the cINN) on the other hand, have a symmetric computational cost for forward and backward pass. This makes them ideal for situations in which both sampling and density estimation are of interest. This, however, comes at the cost of a lower expressibility per flow layer (Papamakarios et al. 2021, Sect. 3.1.2).
4.2 Comparison to Markov chain Monte Carlo
A popular inference method that provides sampling capabilities is the Metropolis–Hastings algorithm, which constitutes an MCMC method. In fact, Serra et al. (2011) have successfully used the Metropolis-Hastings algorithm to infer galaxy properties with CIGALE (using an older version of the code as described in Noll et al. 2009). They emphasize that the computational cost of a grid-based approach scales exponentially with the number of inferred parameters and is therefore costly compared to the Metropolis-Hastings approach.
To our knowledge, there are no formal mathematical results pertaining to the scaling of the computational cost of normalizing flow methods when applied to high-dimensional data. However, numerous empirical results show that popular flow architectures can model high-dimensional distributions. For example, Kobyzev et al. (2021, Sect. 4) provide a summary of log-likelihood scores for common flow architectures on high-dimensional (D = 6, 8, 21, 43, 63) tabular datasets and high-dimensional (D = 784, 3072, 12288) image datasets.
In this work, the number of inference parameters was low (D = 3). However, in future works we may increase this number (e.g., by additionally inferring metallicity and other insightful parameters). The scaling of the computational cost is therefore of practical interest. The considerations above show that it is unclear how the normalizing flow approach compares to classical MCMC approaches in this regard.
Another crucial aspect relates to the tractability of the likelihood function. The classical Metropolis-Hastings algorithm (as applied to Bayesian inference) generates samples of the posterior by drawing from a Markov process with transition probability
![Mathematical equation: $\[A\left(\boldsymbol{\theta}_i, \boldsymbol{\theta}^{\prime}\right)=\min \left(1, \frac{p\left(\mathbf{x} \mid \boldsymbol{\theta}^{\prime}\right) \cdot p\left(\boldsymbol{\theta}^{\prime}\right) \cdot q\left(\boldsymbol{\theta}_i \mid \boldsymbol{\theta}^{\prime}\right)}{p\left(\mathbf{x} \mid \boldsymbol{\theta}_i\right) \cdot p\left(\boldsymbol{\theta}_i\right) \cdot q\left(\boldsymbol{\theta}^{\prime} \mid \boldsymbol{\theta}_i\right)}\right),\]$](/articles/aa/full_html/2026/02/aa56710-25/aa56710-25-eq31.png) (12)
(12)
where q(θi | θ′) denotes the proposal distribution of the current state θi and proposed state θ′. Calculating the transition probability requires the tractability of the likelihood p(x | θ). As discussed in Sect. 1, we believe that the inclusion of additional nuisance parameters can lead to an expensive or intractable likelihood function. This can make the classical Metropolis-Hastings algorithm (and other likelihood-based MCMC methods) infeasible. Normalizing flow methods are trained in a likelihood-free manner and therefore require only a data generation process (i.e., a simulation). In particular, they do not require the explicit calculation of the likelihood. This makes them ideal tools for likelihood-free inference.
In Sect. 1, we note that normalizing flows constitute an amortized approach to Bayesian inference. This means that a high initial computational cost (i.e., training) is compensated by a smaller computational cost during inference. Therefore, amortization becomes useful when the number of inferences and computational cost per simulation become sufficiently large. MCMC methods, on the other hand, require re-simulations for every inference. This can make normalizing flow approaches significantly cheaper for scenarios with many inferences (see, e.g., Hahn & Melchior 2022).
Finally, we should mention that adaptations to the classical MCMC method have led to amortized and likelihood-free MCMC approaches. For example, surrogate models can amortize the simulation cost (e.g., Himes et al. 2022) and “amortized ratio estimators” can be used to extend MCMC methods to likelihood-free scenarios (Hermans et al. 2020). The field of MCMC methods is large, and a discussion of these techniques would exceed the scope of this paper.
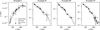 |
Fig. 7 Simulated SEDs for the example clusters (cINN MAP and PHANGS MLE). The horizontal dashed lines indicate the broadband fluxes for the five HST filters. The black dots and error bars show the ground truth photometry and ± 3σ range as found in the PHANGS catalog. |
 |
Fig. 8 Comparison of reduced χ2 deviations for the cINN MAP estimates and the PHANGS MLEs. Top panel: histograms of the log10(χ2) distributions. Bottom panel: PHANGS MLE deviations versus the cINN MAP deviations. The differences are somewhat exaggerated by the logarithmic color scale. Yellow markers indicate the log10(χ2) values of the example clusters. |
 |
Fig. 9 Posterior distribution generated by the cINN for the outlier cluster (marked with an arrow) in Fig. 6. Triangles show positions of the posterior modes; the yellow triangle denotes the MAP value and cyan triangles denote the second and third mode. The yellow cross shows the position of the CIGALE MLE. The numerical values of the parameter estimates are shown in the top right. |
5 Summary
We used the SED modeling code CIGALE to generate a training set of 5 × 106 sets of cluster parameters (age, mass, and reddening) and photometric fluxes (F275W, F336W, F438W, F555W, and F814W). This dataset was used to train a cINN with the goal of modeling the posterior distribution of the cluster parameters conditioned on the observed photometry.
After the training phase of the cINN, we performed various tests to ascertain the performance of the network. In our SBC analysis on the synthetic dataset, we find a reasonably uniform rank distribution over six selected statistics, with some deviations from uniformity that become apparent in the ECDF difference plots. In addition, we performed PPCs on the realworld photometry. Here, we find that the mean of the posterior predictive distribution aligns well with the initial photometry and that the corresponding rank distributions behave as expected. When we compare the cINN MAP estimates with the PHANGS MLEs, we find that deviations with respect to the Turner et al. (2021) estimates are mostly a result of differing mode selection, except for some outlier cases that are caused by different noise model assumptions. To assess the quality of our estimates, we re-simulated our MAP estimates and found that the cINN produced larger χ2 deviations compared to the PHANGS MLEs.
Overall, we find that the cINN generates decent approximations of the cluster posterior distributions. However, we must keep an important caveat in mind. If the goal is solely to generate parameter estimates with a model that uses a fully realized IMF and no additional model nuisance parameters (i.e., a case in which the grid-based approach is very efficient), then we cannot expect to gain much from the normalizing flow approach. In fact, this work shows that the cINN produces consistently worse MLEs compared to traditional grid-based fitting. However, the cINN will allow us to model posterior distributions in scenarios that are intractable to classic grid-based approaches. Here, we are referring in particular to models that incorporate multiple nuisance parameters and add additional inference parameters, which will be the focus of our follow-up paper.
Acknowledgements
DW, VFK, and RSK acknowledge financial support from the European Research Council via the ERC Synergy Grant “ECOGAL” (project ID 855130), from the German Excellence Strategy via the Heidelberg Cluster of Excellence (EXC 2181 – 390900948) “STRUCTURES”, and from the German Ministry for Economic Affairs and Climate Action in project “MAINN” (funding ID 50OO2206). The team at Heidelberg University is also grateful for computing resources provided by the Ministry of Science, Research and the Arts (MWK) of the State of Baden-Württemberg through bwHPC and the German Science Foundation (DFG) through grants INST 35/1134-1 FUGG and 35/1597-1 FUGG, and also for data storage at SDS@hd funded through grants INST 35/1314-1 FUGG and INST 35/1503-1 FUGG. MB acknowledges support by the ANID BASAL project FB210003. This work was supported by the French government through the France 2030 investment plan managed by the National Research Agency (ANR), as part of the Initiative of Excellence of Université Côte d’Azur under reference No. ANR-15-IDEX-01. This research was funded, in whole or in part, by the French National Research Agency (ANR), grant ANR-24-CE92-0044 (project STARCLUSTERS). We thank the German Science Foundation DFG for financial support in the project STARCLUSTERS (funding ID KL 1358/22-1 and SCHI 536/13-1). KG is supported by the Australian Research Council through the Discovery Early Career Researcher Award (DECRA) Fellowship (project number DE220100766) funded by the Australian Government.
References
- Anand, G. S., Lee, J. C., Van Dyk, S. D., et al. 2021, MNRAS, 501, 3621 [Google Scholar]
- Ardizzone, L., Bungert, T., Draxler, F., et al. 2018 and 2022, Framework for Easily Invertible Architectures (FrEIA) [Google Scholar]
- Ardizzone, L., Lüth, C., Kruse, J., Rother, C., & Köthe, U. 2019, arXiv e-prints [arXiv:1907.02392] [Google Scholar]
- Bister, T., Erdmann, M., Köthe, U., & Schulte, J. 2023, J. Phys.: Conf. Ser., 2438, 012094 [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Burgarella, D., Buat, V., & Iglesias-Páramo, J. 2005, MNRAS, 360, 1413 [NASA ADS] [CrossRef] [Google Scholar]
- Calzetti, D., Lee, J. C., Sabbi, E., et al. 2015, AJ, 149, 51 [Google Scholar]
- Candebat, N., Sacco, G. G., Magrini, L., et al. 2024, A&A, 692, A228 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, ApJ, 345, 245 [Google Scholar]
- Chandar, R., Whitmore, B. C., Dinino, D., et al. 2016, ApJ, 824, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Cranmer, K., Brehmer, J., & Louppe, G. 2020, PNAS, 117, 30055 [NASA ADS] [CrossRef] [Google Scholar]
- da Silva, R. L., Fumagalli, M., & Krumholz, M. 2012, ApJ, 745, 145 [CrossRef] [Google Scholar]
- Denker, A., Schmidt, M., Leuschner, J., & Maass, P. 2021, J. Imaging, 7. 243 [Google Scholar]
- Dinh, L., Sohl-Dickstein, J., & Bengio, S. 2017, in International Conference on Learning Representations [Google Scholar]
- Eisert, L., Pillepich, A., Nelson, D., et al. 2023, MNRAS, 519, 2199 [Google Scholar]
- Fall, S. M., Chandar, R., & Whitmore, B. C. 2005, ApJ, 631, L133 [NASA ADS] [CrossRef] [Google Scholar]
- Fukunaga, K., & Hostetler, L. 1975, IEEE Trans. Inform. Theory, 21, 32 [CrossRef] [Google Scholar]
- Gelman, A., Meng, X.-L., & Stern, H. 1996, Statist. Sin., 6, 733 [Google Scholar]
- Gelman, A., Carlin, J. B., Stern, H. S., et al. 2013, Bayesian Data Analysis, 3rd edn., Chapman & Hall/CRC Texts in Statistical Science Series (CRC) [Google Scholar]
- Gontcharov, G. A., Mosenkov, A. V., & Khovritchev, M. Y. 2019, MNRAS, 483, 4949 [NASA ADS] [CrossRef] [Google Scholar]
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., et al. 2014, in Advances in Neural Information Processing Systems, 27, eds. Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, & K. Weinberger (Curran Associates, Inc.) [Google Scholar]
- Hahn, C., & Melchior, P. 2022, ApJ, 938, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Haldemann, J., Ksoll, V., Walter, D., et al. 2023, A&A, 672, A180 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hermans, J., Begy, V., & Louppe, G. 2020, in Proceedings of Machine Learning Research, 119, Proceedings of the 37th International Conference on Machine Learning, eds. H. D. III, & A. Singh (PMLR), 4239 [Google Scholar]
- Himes, M. D., Harrington, J., Cobb, A. D., et al. 2022, Planet. Sci. J., 3, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Pellegrini, E. W., Ardizzone, L., et al. 2022, MNRAS, 512, 617 [CrossRef] [Google Scholar]
- Kang, D. E., Klessen, R. S., Ksoll, V. F., et al. 2023, MNRAS, 520, 4981 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Ksoll, V. F., Itrich, D., et al. 2023, A&A, 674, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Khullar, G., Nord, B., Ćiprijanović, A., Poh, J., & Xu, F. 2022, Mach. Learn.: Sci. Technol., 3, 04LT04 [Google Scholar]
- Kingma, D. P., & Welling, M. 2013, arXiv e-prints [arXiv:1312.6114] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kobyzev, I., Prince, S. J., & Brubaker, M. A. 2021, IEEE Trans. Pattern Anal. Mach. Intell., 43, 3964 [NASA ADS] [CrossRef] [Google Scholar]
- Ksoll, V. F., Reissl, S., Klessen, R. S., et al. 2024, A&A, 683, A246 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ksoll, V. F., Ardizzone, L., Klessen, R., et al. 2020, MNRAS, 499, 5447 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, J. C., Whitmore, B. C., Thilker, D. A., et al. 2022, ApJS, 258, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, J. C., Sandstrom, K. M., Leroy, A. K., et al. 2023, ApJ, 944, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., & Talwalkar, A. 2018, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Maschmann, D., Lee, J. C., Thilker, D. A., et al. 2024, ApJS, 273, 14 [Google Scholar]
- Nölke, J.-H., Adler, T., Gröhl, J., et al. 2021, in Bildverarbeitung für die Medizin 2021, eds. C. Palm, T. M. Deserno, H. Handels, A. Maier, K. Maier-Hein, & T. Tolxdorff (Wiesbaden: Springer Fachmedien Wiesbaden), 330 [Google Scholar]
- Noll, S., Burgarella, D., Giovannoli, E., et al. 2009, A&A, 507, 1793 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Orozco-Duarte, R., Wofford, A., Vidal-García, A., et al. 2022, MNRAS, 509, 522 [Google Scholar]
- Papamakarios, G., Pavlakou, T., & Murray, I. 2017, in Advances in Neural Information Processing Systems, 30, eds. I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Curran Associates, Inc.) [Google Scholar]
- Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., & Lakshminarayanan, B. 2021, J. Mach. Learn. Res., 22, 1 [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems, 32, eds. H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, & R. Garnett (Curran Associates, Inc.) [Google Scholar]
- Rubin, D. B. 1984, Ann. Statist., 12, 1151 [CrossRef] [Google Scholar]
- Serra, P., Amblard, A., Temi, P., et al. 2011, ApJ, 740, 22 [Google Scholar]
- Talts, S., Betancourt, M., Simpson, D., Vehtari, A., & Gelman, A. 2018, arXiv e-prints [arXiv:1804.06788] [Google Scholar]
- Thilker, D. A., Whitmore, B. C., Lee, J. C., et al. 2022, MNRAS, 509, 4094 [Google Scholar]
- Turner, J. A., Dale, D. A., Lee, J. C., et al. 2021, MNRAS, 502, 1366 [NASA ADS] [CrossRef] [Google Scholar]
- Vasist, M., Rozet, F., Absil, O., et al. 2023, A&A, 672, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Walter, D. 2023, Inferring Properties of Star Clusters from Unresolved Broadband Photometry with a Flow-Based Generative Model, master’s thesis, unpublished [Google Scholar]
- Zhang, K., Jayasinghe, T., & Bloom, J. 2023a, in Machine Learning for Astrophysics, 39 [Google Scholar]
- Zhang, R., Yuan, H., & Chen, B. 2023b, ApJS, 269, 6 [NASA ADS] [CrossRef] [Google Scholar]
https://gitlab.lam.fr/cigale/cigale/-/tree/PHANGS?ref_type=heads; git commit hash: 9dd1827ae3fc67a1d412153309d924650abf110f; last accessed: May 2025.
https://typo.iwr.uni-heidelberg.de/services/facilities/compute-server.html (last accessed: Nov 2025).
https://archive.stsci.edu/hlsp/phangs/phangs-cat (last accessed: Nov 2025).
Appendix A Network parameters
Network architecture and training parameters.
Appendix B Supplementary plots
 |
Fig. B.3 Deviations between cINN MAP estimates and PHANGS MLEs plotted against the posterior width (as quantified by the distance between 16% and 84% quantile) for the entire cluster catalog. The yellow and blue lines indicate the median, 5% and 95% quantiles of the deviations. |
All Tables
All Figures
|
Fig. 1 Flowchart of single coupling block (representing Eqs. (5), (6), and (7)) taken from Walter (2023). The input vector, θj, is split into two sub-vectors, |
| In the text | |
|
Fig. 2 Top row: histograms of relative flux uncertainties in the PHANGS cluster catalog. The dotted vertical lines denote the median relative flux uncertainties, and the dashed lines denote the maximum relative flux uncertainties. Middle row: comparison of the normal noise model and the log-normal noise model for median relative flux uncertainties. Bottom row: comparison of the normal noise model and the log-normal noise model for maximum relative flux uncertainties. |
| In the text | |
|
Fig. 3 Results of SBC analysis over the entire test set (≈105 parameter–observation pairs). We generated a hundred posterior samples for every element in the test set. Left column: rank histograms for the proposed statistics. Horizontal dashed lines correspond to the ±1σ range under the assumption of uniformity. Right column: difference between rank ECDF and uniform cumulative distribution function. The gray area highlights the expected 0.01–0.99 quantile range of the ECDF difference under the assumption of uniformity. |
| In the text | |
|
Fig. 4 Results of PPC analysis. Posterior predictive distributions with 500 samples each were generated for all clusters in the PHANGS catalog. Left column: comparison of the mean predictive photometry and the initial photometry. Right column: rank distribution of the initial photometry within the posterior predictive distribution. Horizontal dashed lines correspond to the ±1σ range under the assumption of uniformity. |
| In the text | |
|
Fig. 5 2D and 1D density plots of example posteriors. Top rows: marginal 1D density for the cINN posterior (gray histogram) and ground truth (dashed black line). Middle rows: 2D density of the cINN generated posterior (104 samples per posterior). Bottom rows: contour plot of ground truth densities calculated over a parameter grid. Note that we use the same color maps in the second and third rows (although the colorbars show different ranges). The yellow markers indicate positions of cINN MAP estimates (triangle) and PHANGS MLEs (cross). Continued. |
| In the text | |
|
Fig. 6 Comparison of cINN posterior modes and PHANGS MLEs for all (filtered) NGC 1433 clusters. Top panels: cINN MAP modes as determined by the mean-shift estimator. Error bars show the 16%- and 84%-quantiles of the marginalized posteriors. The yellow markers indicate the positions of the four example clusters. Bottom panels: comparison with the posterior modes that were closest to the PHANGS MLE (for every posterior, a maximum of three modes were determined). For better visibility, we omitted the error bars. The blue dots mark clusters that have relative flux uncertainties larger than 40% in at least one UV band, as discussed in Sect. 3.2.4. The arrow shows the position of the largest outlier. Comparisons for all galaxies are provided in Appendix B. |
| In the text | |
|
Fig. 7 Simulated SEDs for the example clusters (cINN MAP and PHANGS MLE). The horizontal dashed lines indicate the broadband fluxes for the five HST filters. The black dots and error bars show the ground truth photometry and ± 3σ range as found in the PHANGS catalog. |
| In the text | |
|
Fig. 8 Comparison of reduced χ2 deviations for the cINN MAP estimates and the PHANGS MLEs. Top panel: histograms of the log10(χ2) distributions. Bottom panel: PHANGS MLE deviations versus the cINN MAP deviations. The differences are somewhat exaggerated by the logarithmic color scale. Yellow markers indicate the log10(χ2) values of the example clusters. |
| In the text | |
|
Fig. 9 Posterior distribution generated by the cINN for the outlier cluster (marked with an arrow) in Fig. 6. Triangles show positions of the posterior modes; the yellow triangle denotes the MAP value and cyan triangles denote the second and third mode. The yellow cross shows the position of the CIGALE MLE. The numerical values of the parameter estimates are shown in the top right. |
| In the text | |
 |
Fig. B.1 Same as Fig. 6 (top) but including all galaxies from the PHANGS catalog. |
| In the text | |
 |
Fig. B.2 Same as Fig. 6 (bottom) but including all galaxies from the PHANGS catalog. |
| In the text | |
|
Fig. B.3 Deviations between cINN MAP estimates and PHANGS MLEs plotted against the posterior width (as quantified by the distance between 16% and 84% quantile) for the entire cluster catalog. The yellow and blue lines indicate the median, 5% and 95% quantiles of the deviations. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.