| Issue |
A&A
Volume 708, April 2026
|
|
|---|---|---|
| Article Number | A64 | |
| Number of page(s) | 14 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202556354 | |
| Published online | 26 March 2026 | |
An automated activity classification tool for optical galaxy spectra
1
Physics Department, and Institute of Theoretical and Computational Physics, University of Crete, 71003 Heraklion, Greece
2
Institute of Astrophysics, Foundation for Research and Technology-Hellas, 71110 Heraklion, Greece
3
Center for Astrophysics | Harvard & Smithsonian, 60 Garden St., Cambridge, MA 02138, USA
4
Astronomical Institute, Academy of Sciences, Boční II 1401, CZ-14131 Prague, Czech Republic
5
ALMA Sistemi Srl, Guidonia, Rome 00012, Italy
6
Quantum Innovation Pc, Chania 73100, Greece
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
10
July
2025
Accepted:
23
February
2026
Abstract
Context. Reliable and versatile galaxy activity diagnostic tools are indispensable for comprehending the physical processes that drive galaxy evolution. Traditional methodologies frequently necessitate extensive preprocessing, such as starlight subtraction and emission-line deblending (e.g., Hα and [N II]), which can introduce substantial biases and uncertainties due to their model-dependent nature. Additionally, numerous diagnostics omit the inclusion of dormant (passive) galaxies.
Aims. This work aims to develop a reliable, automated, and efficient diagnostic tool capable of distinguishing among star-forming galaxies, active galactic nuclei (AGNs), low-ionization nuclear emission-line regions (LINERs), composite and passive galaxies under one unified scheme.
Methods. We developed a diagnostic tool based on a support vector machine trained on ground-truth data originating from optical emission-line ratios and color selection criteria. Building upon previous literature findings and exploring various combinations of discriminatory feature schemes, we identified the equivalent widths (EWs) of Hβ, [O III] λ5007, and Hα+[N II] λλ6548,84 as key discriminatory features. Additionally, galaxies classified as AGNs can be distinguished as broad- or narrow-line AGNs by measuring the full quarter at the half-maximum of the Hα and [N II] complex.
Results. Employing machine-learning algorithms and three EWs directly measured from the galaxy’s optical spectrum, we have developed a diagnostic tool that encompasses all potential activities of galaxies while simultaneously achieving high-performance scores across all of them. Our diagnostic achieves overall accuracy of ∼83% and recall of ∼79% for star-forming galaxies, ∼94% for AGN, ∼85% for LINERs, ∼77% for composite galaxies, and ∼96% for passive galaxies.
Conclusions. Our diagnostic tool offers significant improvements over the existing galaxy activity diagnostics as it can be applied to large numbers of spectra, eliminates the need for preprocessing (i.e., starlight subtraction or flux calibration) and spectral-line deblending, encompasses all activity classes under one unified scheme, and offers the ability to distinguish between the two main types of AGN. In addition, the omission of starlight subtraction was not found to significantly reduce the diagnostic’s performance. Furthermore, the narrow wavelength range required for its application enables its use over a wide range of redshifts, making it highly relevant to activity studies of high-redshift galaxies.
Key words: galaxies: active / galaxies: formation / galaxies: Seyfert / galaxies: statistics
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The characterization of a galaxy’s activity is of great significance for many areas of extragalactic astrophysics, yet it often presents challenges due to the intricate interplay of several astrophysical processes involved. Galaxies exhibit a diverse range of activities, from quiescent (passive) ones characterized by minimal to absent star formation, to active ones marked by intense starburst activity or accretion onto their or supermassive black hole. Furthermore, high-coverage sky surveys such as the Sloan Digital Sky Survey (SDSS; York et al. 2000) or The Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST; Cui et al. 2012) routinely produce substantial datasets of galaxies, providing valuable insights into galaxy populations and their properties but also posing challenges for traditional data analysis methods. This underscores the need for a high-accuracy automated activity classification tool that could be applied to large number of galaxy samples and include a wide range of galaxy activities.
The optical part of a galaxy’s spectrum holds a wealth of information pertinent to its activity. Thus, many diagnostic methods have been developed over the years trying to classify galaxy activity using emission lines such as the Hα, Hβ, [O III] λ5007, [N II] λ6584, [S II] λλ6717,6731, and [O I] λ6300 (hereafter BPT diagrams; e.g., Baldwin et al. 1981; Veilleux & Osterbrock 1987; Kewley et al. 2001; Kauffmann et al. 2003; Schawinski et al. 2007), with the most widely used being the [O III]/Hβ versus [N II]/Hα. The success of these lines can be attributed to the fact that they are sensitive to ionizing photons of different energy levels and hence continua of different hardness (Kewley et al. 2019). However, estimating the flux for an emission line requires line profile fitting, which can be model-dependent, particularly for blended lines (e.g., [N II] and Hα) that may have multiple components. In addition, active galactic nuclei (AGNs) can be classified as broad-line AGNs (Seyfert 1) and narrow-line AGNs depending on the presence of broad permitted emission lines. In particular, true Seyfert 1 AGNs (as opposed to intermediate types such as 1.9−1.1) are typically characterized by Hα full with at half maximum (FWHM) ≳ 1000 km s−1 (e.g., Greene & Ho 2005), while many studies adopt a more conservative threshold of FWHM ≳ 2000 km s−1 (e.g., Osterbrock & Pogge 1985; Veron-Cetty & Veron 2000). Objects with a FWHM in the range of ∼500−2000 km s−1 are usually classified as narrow-line Seyfert 1 galaxies (e.g., Zhou et al. 2006). For the traditional diagnostics, only the narrow-line components are used, further emphasizing the need for line profile fitting.
Furthermore, the accurate flux estimation requires starlight subtraction, which can introduce biases resulting from the assumptions about the underlying stellar populations. Although line fluxes measured in starlight-subtracted spectra are generally robust (e.g., Maragkoudakis et al. 2014), the starlight subtraction process introduces uncertainties that are hard to quantify and in the case of spectra with strong AGN continuum may bias the results since it only accounts for the stellar component. Lastly, emission-line diagnostics often exclude objects with weak or absent activity (i.e., passive galaxies) from these diagnostics. In order to remedy this limitation, diagnostics utilizing the equivalent width (EW) of the Hα line have been proposed (Cid Fernandes et al. 2010). However, these diagrams still rely on the line flux of Hα and [N II] λ6584 requiring profile fitting and starlight subtraction.
In this paper, motivated by the results presented in Daoutis et al. (2025), we propose an automated diagnostic tool for galaxy activity. In contrast to the aforementioned work, our approach focuses on automating the activity characterization of galaxies by using spectra without the need for starlight subtraction. In addition, while that work demonstrated remarkable success in the identification and decomposition of galaxy activity, it uses the D4000 index break (Balogh et al. 1999). This may hinder its application to low-quality spectra, as the blue portion of the spectrum can be challenging to measure reliably. Furthermore, in our diagnostic we included all classes including broad-line AGNs and the narrow-line ones considered in the traditional diagnostics. Specifically, we encompassed five distinct activity classes: star-forming, AGN, LINER, composite, and passive; and we utilized three features: the EWs of [O III], Hβ, and the combined Hα + [N II] λλ6548,84. These features are measured directly on the observed spectra, eliminating the need for starlight subtraction and deblending of the [N II] doublet and the Hα line. Another advantage of this method is that since it is based on the EW of all the considered lines it is not sensitive to extinction effects and does not require flux calibration, making it particularly useful for multi-fiber spectra.
This paper is organized as follows. In Section 2, we introduce the galaxy sample and the methods employed to obtain the ground-truth labels for the activity classification of the various classes. In Section 3, the development of the diagnostic is described in detail, as well as the process for identifying broad- and narrow-line AGNs. Additionally, we present the algorithm employed and the metrics utilized to assess its performance. In Section 4, we present the results and the diagnostic’s performance in classifying and identifying the AGN subclasses. In Section 5, we present the outcomes of a diagnostic applied to spectra of different spectral resolutions or signal-to-noise ratios. We discuss methods for assessing the classification reliability and the influence of the stellar continuum on the classification of and AGNs, particularly in the case of low AGN-fraction contribution. Finally, the overall conclusions are presented in Section 6.
2. Data sample
2.1. The galaxy sample
Our galaxy sample is primarily drawn from the SDSS. The SDSS has revolutionized the study of galaxies by providing high-quality optical spectra for millions of galaxies across a wide range of environments and redshifts. SDSS spectra are uniformly processed, ensuring consistency across the dataset, and they cover a large portion of the sky, making them ideal for statistical studies of galaxy evolution. They cover the 3800−9200 Å spectral range, encompassing all the diagnostically important optical lines with a resolving power ranging from R ∼ 1500 at 3800 Å to R ∼ 2500 at 9000 Å for the original SDSS-I/II/III spectrographs. The Baryon Oscillation Spectroscopic Survey (BOSS) and the extended BOSS (eBOSS) survey used in SDSS-IV extend the wavelength coverage to 3600−10 400 Å with a resolution of R ∼ 1300 at 3600 Å and R ∼ 2500 at 10 400 Å. We used the same galaxy sample introduced in Daoutis et al. (2025), which was built by combining spectroscopic data from the MPA-JHU DR8 (Kauffmann et al. 2003; Brinchmann et al. 2004; Tremonti et al. 2004) release of the SDSS and ultraviolet photometry from the GALEX survey, via the GSWLC catalog (Salim et al. 2016). Since our analysis in this project differs from that of Daoutis et al. (2025), we applied small modifications to these criteria to tailor the sample to better the needs of this project.
2.2. Galaxy-activity classification
In order to define our new diagnostic, we needed a sample with reliable activity classifications for all the activity types we considered in this project. These were used to delineate the locus of each activity class in the parameter space defined by the spectral features we consider in our diagnostic.
Galaxies that show prominent emission lines, namely star-forming galaxies, AGN, LINER, and composite galaxies, were selected by implementing the Soft Data-Driven Allocation (SoDDA; Stampoulis et al. 2019) classifier, a four-dimensional diagnostic based jointly on the emission-line ratios of log10([N II]/Hα), log10([S II]/Hα), log10([O I]/Hα), and log10([O III]/Hβ). This method presents a significant advantage in comparison to the commonly used two-dimensional emission-line ratio diagnostics since it simultaneously considers all four crucial features preventing contradictory classifications. The emission-line fluxes were acquired from the MPA-JHU catalog, which provides deblended, starlight-subtracted line measurements for SDSS spectra obtained up to the SDSS DR7. The sample of passive galaxies was defined using the NUV − r against the absolute magnitude in the SDSS r-band (Mr) color-magnitude diagram, which was found to be the most reliable criterion with almost no contamination from green-valley galaxies (Haines et al. 2008).
2.3. Characterization of AGN subclasses
Following our activity characterization of galaxies, we partitioned the AGNs identified with the SoDDA diagnostic (Sect. 2.2) into two subclasses: broad-line (Type 1; BL AGN) and narrow-line (Type 2; NL AGN) AGNs based on their SDSS classification. We characterized any galaxy classified as AGN by SoDDA that has (“SUBCLASS” = “BROADLINE” or “AGN BROADLINE”) SDSS a designation as a BL AGN. These are objects of non-stellar spectra with emission lines detected at the 10σ level that have velocity dispersions of the Balmer emission lines exceeding 200 km s−1 at the 5σ level (or FWHM of ∼470 km s−1).
2.4. Final sample
For all active galaxies, we adopted the quality criteria imposed by Daoutis et al. (2025) based on the signal-to-noise ratio (S/N > 5) of the emission lines of [O III], [N II], [O I], [S II], Hα, and Hβ. This ensured the quality of the classification labels based on the SoDDA diagnostic. In addition, we removed any galaxy where the MPA-JHU pipeline failed to provide reliable line measurements (RELIABLE = 0 flag).
For the passive galaxies, all S/N based quality criteria imposed by Daoutis et al. (2025) are retained. However, we eliminated any galaxy that is classified as star-forming, an AGN, a LINER, or composite from the sample of passive galaxies, thus excluding any one with the diagnostic emission lines that have S/N > 5. Galaxies that exhibit emission lines at lower confidence are included in our sample in order not to be biased against excitation by old stellar populations or very weak AGNs.
For all galaxies that satisfy the aforementioned criteria, we downloaded their optical spectra from the DR8 SDSS1. The final sample composition per class is presented in Table 1.
Composition of the final sample for each galaxy class.
2.5. Feature selection
Following the results presented in Daoutis et al. (2025) and motivated by previous works using the EW of Hα as a diagnostic feature (Cid Fernandes et al. 2010), we adopted the EWs of the spectral lines of Hβ, [O III], and Hα + [N II] as diagnostic indicators (see Fig. 1). Utilizing EWs instead of spectral line fluxes offers two key advantages: it allows for the inclusion of galaxies with very faint or nonexistent emission lines, e.g., passive galaxies, and it is reddening-insensitive.
 |
Fig. 1. Distributions of EW of the three spectral lines [O III] (top), of the [N II] doublet and Hα (middle), and of Hβ (bottom), used as determining features for the development of our new diagnostic for the activity classes of star-forming (SF), AGN, LINER, composite, and passive galaxies. All measurements were performed on non-starlight-subtracted SDSS spectra. We adhered to the same conventions as the SDSS, wherein negative EW correspond to emission. |
While the labels for the spectral classification of the emission-line galaxies are based on the starlight-subtracted line measurements and the SoDDA diagnostic, in our diagnostic we measured the EWs directly from the reduced SDSS spectra processed by the SDSS pipeline without performing any starlight subtraction. This is because our goal is to develop a diagnostic applicable to spectra requiring minimal processing. We adhered to the convention established by the SDSS, which assigns negative EW values to emission lines. Furthermore, we measured the combined EW of the [N II] doublet and Hα, which eliminated the need for profile fitting and deblending; this can be model-dependent, especially in galaxies with broad-line components. In summary, our feature scheme consists of the EWs of Hβ, [O III] λ5007, and Hα + [N II] λλ6548,84.
The wavelength ranges of these spectral bands are defined around the central wavelength of the relevant spectral lines. Their wavelength ranges are 80 Å for the Hα + [N II] blend and 30 Å for the [O III] and Hβ. In Table 2, we report the centers of each targeted feature, their wavelength span, and the range of the continuum on either side of each spectral window. The estimation of the continuum was performed from a 10 Å wide region on either side of each spectral line, using all points and their corresponding uncertainties and fitting a linear model using the weighted least-squares method. This model was then used for the estimation of the continuum at each wavelength point in each spectral-line band of interest for the calculation of its EW (see Appendix C, Eq. C.2). A linear model provides a good approximation to the local continuum due to the short wavelength range and the absence of significant changes in the continuum shape. These bandwidths are sufficiently broad to encompass the full profile of each emission line, even in low-resolution spectra, yet narrow enough to ensure that the linear approximation of the continuum remains valid within the EW measurement range and to avoid contamination from neighboring spectral lines (e.g., confusion between [O III] λ4959 and [O III] λ5007). At the SDSS resolution, the line band is narrow enough that the adjacent continuum region remains uncontaminated by the emission line itself, provided the line has a FWHM up to ∼10 Å (less than 0.1% leakage of line flux to the continuum), corresponding to velocities of up to ∼700 km s−1 for the Hβ (∼900 km s−1 for Hα and [N II]). For slightly higher contamination levels of 5%, these velocities are twice as large.
Spectral features, central wavelengths, wavelength ranges, and continuum ranges used for the calculation of the EWs.
3. Developing the diagnostic tool
3.1. The algorithm
Machine-learning algorithms are highly effective tools fr identifying intricate relationships and patterns within data sets that are challenging to discern using conventional methods. Their application spans numerous scientific fields, tackling a diverse array of challenges. For example, in the field of astrophysics, these algorithms have been employed for several purposes. They have been utilized in tasks such as stellar classification (e.g., Kyritsis et al. 2022; Maravelias et al. 2022). Similarly, they have been employed for galaxy classification utilizing the BPT diagram (e.g., Stampoulis et al. 2019).
For this work, we adopted the support vector machine (SVM; Cortes & Vapnik 1995) algorithm. SVMs are versatile and powerful tools for classification, regression, and outlier detection, and they are especially effective in high-dimensional spaces. They can handle nonlinear relationships through kernels while offering flexibility and efficiency, making them suitable for a wide range of applications.
SVMs function by identifying the optimal hyperplane that separates the locus of the different classes in the considered multidimensional space. They achieve this by focusing on the data points closest to the hyperplane, known as support vectors, which uniquely determine the separation boundary. For nonlinearly separable classes, SVMs employ kernel functions to transform the data into a higher dimensional space where a linear separation is possible, making them extremely efficient. Preliminary testing showed that, for our data, these properties made it more robust than the other alternatives we explored, namely the random forest method and its variants, leading us to adopt SVM as the algorithm of choice.
3.2. Implementation
We employed the Python 3 scikit-learn (Pedregosa et al. 2011) implementation of the SVM algorithm and, specifically, the support vector classification (SVC; i.e., SVM for classification tasks). For the training process, the algorithm is provided with three discriminatory features: the EWs of Hβ, [O III] λ5007, and Hα + [N II] λλ6548,84 (see Sect. 2.5), along with the activity class of each galaxy considered, which serves as the ground truth. In total, we considered five activity classes: star-forming (SF), AGN, LINER, composite, and passive.
As the development of a robust classifier requires high-quality data, we utilized the final sample described in Sect. 2.4. Subsequently, these data were partitioned into two subsamples, one of which serves as the training set, while the other constitutes the test set in a 70%/30% ratio, respectively. The training set was exclusively used for the training process, while the test set was reserved for evaluating the performance of the algorithm.
Our training dataset comprises classes that are represented by varying numbers of objects, resulting in a significant imbalance. This can lead to biases toward the majority class, thereby impeding the diagnostic’s performance for the under-represented classes. We enforced balancing by assigning class-specific weights to the penalty term within the optimization function, namely through the class_weight parameter. This adjustment increased the cost associated with misclassifying samples from the minority class, thereby promoting the definition of more balanced decision boundaries.
The discriminatory features were standardized prior to their use for training the algorithm. The standardization of input features is crucial for training an SVM, as the algorithm is sensitive to the scale of the features as it relies on distance-based computations. In other words, features with larger ranges can disproportionately influence the model, resulting in biased decision boundaries. In this study, the StandardScaler() from scikit-learn was used as the normalization method to transform each feature, ensuring that it had a mean of zero and a standard deviation of one. Furthermore, the SVM hyperparameters were optimized through a random search, as described in Appendix A.
3.3. Performance metrics
The confusion matrix serves as the main tool for assessing the performance of classification models. It presents the correctly classified objects (primary diagonal elements) and the misclassified instances (off-diagonal elements), simultaneously providing insights into the class distributions. From this matrix, we derived the following metrics, which we used to evaluate the efficacy and performance of our diagnostic tool. Accuracy measures the proportion of correct classifications across all instances, although it may be misleading in imbalanced datasets such as ours. Recall, or sensitivity, focuses on the proportion of actual positives correctly identified by the model. The F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics. For the definitions and equations of these metrics, we refer the reader to Table 2 in Daoutis et al. (2023).
3.4. Predicted probabilities
Knowing the probability of an object belonging to each of the considered classes offers a more insightful perspective on the model’s decision-making process, and it allows the assessment of the classification robustness.
SVMs are not inherently probabilistic models. Their primary objective is to identify a hyperplane that maximizes the boundary between classes, rather than estimating class probabilities. However, the SVM algorithm provided by scikit-learn includes a probability estimation through Platt scaling (Platt 2000). This approach entails fitting a logistic regression model to the decision function scores. By mapping the distance from the decision boundary to probabilities, we can obtain class likelihoods. In general this, is done by looking at the density of the objects according to their (true) type in the multiclass feature space considered.
This is, however, not sufficient, since those probabilities are model-dependent and not strictly related to the sample’s demographics. A correction to this can be performed via the calibration curves, which assess the reliability of the predicted probabilities by comparing them to the corresponding true observed frequencies. To construct a calibration curve, the predicted probabilities are partitioned into bins, usually employing equal widths (i.e., an equal number of objects per bin). Then, for each bin, the mean predicted probability is computed along with the actual proportion of positive instances (observed frequency). These values are subsequently plotted against each other, with the x-axis representing the mean predicted probabilities and the y-axis indicating the corresponding observed frequencies. A perfectly calibrated model will generate a diagonal line, where predicted probabilities align with observed frequencies. Deviations from this line indicate miscalibration, such as overconfidence or underconfidence in the predictions. If the calibration curves indicate a miscalibrated classifier – i.e., if predicted probabilities deviate from true outcome frequencies – then post hoc calibration techniques such as Platt scaling or isotonic regression should be applied to a separate validation set to improve probabilistic reliability. This step ensures that the classifier’s output probabilities can be meaningfully interpreted as confidence estimates. Figure 2 presents the calculated calibration curves for each class implemented with our diagnostic tool. These curves indicate that our diagnostic outputs predict probabilities that closely align with the actual appearance frequency of each class in the feature space for almost all classes, with minimal deviations; this is especially true for AGN and star-forming galaxies. The only deviations observed appear to be limited to the classes of LINERs and composites, but only within a narrow range at the midpoint of the predicted probabilities, which can be attributed to the inherently complex nature of these mixed-activity classes (Daoutis et al. 2023, 2025). This analysis suggests that the output probabilities of our diagnostic are calibrated, ensuring that the model outputs probabilities that are well aligned with the true frequency of classes in the feature space. This makes it suitable for applications where confidence estimates or probabilistic thresholds are required, which is what we are interested in here.
 |
Fig. 2. Calibration curves for the predicted probabilities of each activity class. This plot illustrates the relationship between the predicted probabilities (derived from our diagnostic) and the actual frequency of an activity class appearing among the remaining classes in the feature space. The dashed line represents an idealized classifier with perfect calibration. We observe that for star-forming (SF) and AGN galaxies, the predicted probabilities closely align with the observed frequencies. Passive galaxies exhibit a greater deviation from the dashed line compared to the previous two classes. Notably, LINER galaxies and passive galaxies demonstrate more pronounced deviations, which is consistent with their intricate nature. |
3.5. Distinguishing between broad- and narrow-line AGNs
After defining our primary tool used to classify galaxies as one of five activity types, we explored its extension to indicatively separate broad-line and narrow-line AGNs. We achieved this by employing a two-step process. The first step is the five-class classifier described in the previous sections. This is followed by a separate one applied to the galaxies confirmed as AGNs in the first step. This way, the primary classifier can be readily applied even to low-quality spectra, where accurately measuring the width of spectral lines may be challenging. The classifier for the broad-line and narrow-line AGNs, which is more sensitive to the spectral resolution and the S/N, will not interfere with the main activity classification results.
The secondary classifier only uses one discriminatory feature to provide information about the width of the Hα emission line. For this feature, we used the full width at quarter maximum (FWQM) of the Hα + [N II] blend, which is the distance (in Å) between two points on either side of the Hα + [N II], where the flux is found to be 1/4 of its maximum. The FWQM offered better performance than the FWHM since it better probes the wings of the line instead of its core. For the training of the secondary classifier, we collected all AGN galaxies classified as broad-line and narrow-line ones, as described in Sect. 2.3. The algorithm employed, the training, and the performance evaluation procedures were identical to those followed for the definition of the principal diagnostic tool (see Sect. 3). Furthermore, to mitigate any potential biases, we utilized exactly the same AGNs from the training sample (see Sect. 3.2) of the principal classifier to train the secondary classifier. In other words, the ground-truth labels used to train and test the performance of the secondary classifier were derived by dividing the AGNs in the training and test sets of the primary classifier into broad- and narrow-line AGNs, respectively.
4. Results
4.1. Performance evaluation
To evaluate the performance of our model, we employed the k-fold cross-validation method. This technique involves partitioning the entire dataset into k distinct subsamples (in our case, we chose k = 10). In each iteration, k-1 subsamples (folds) were utilized for training, while the remainder serves as the evaluation set. This process was repeated k times, ensuring that each fold acts as the test set on an equal timescale. By employing this approach, we obtained a reliable assessment of the model’s accuracy. This yielded a mean accuracy across the folds of 83 ± 1%, indicating a high level of accuracy and robustness of our classifier.
Table 3 presents the performance scores for each activity class, indicating near-perfect scores throughout. The high recall values for all classes demonstrate the classifier’s ability to accurately identify almost all galaxies within each category, underscoring its exceptional completeness. Specifically, we observe that AGN and passive galaxies have almost perfect recall scores, with the star-forming and LINER galaxies following with very good scores. Composite galaxies, on the other hand, exhibit lower recall scores compared to the other classes, which is generally anticipated due to their nature in that they share similarities with AGNs (Ferland & Netzer 1983; Halpern & Steiner 1983; Stasińska 1984) and star-forming galaxies. Their spectra are also consistent with excitation from old stellar populations sharing some similarities with LINERs (Binette et al. 1994; Stasińska et al. 2008; Papaderos et al. 2013). Indeed, examining the confusion matrix (Fig. 3), we see that the primary mixing occurs between star-forming and composite galaxies. Notably, 12.3% of composite galaxies were misclassified as star-forming galaxies, while 16.6% of the star-forming galaxies were erroneously identified as composite ones. Furthermore, we find that mixing between composite and LINER galaxies resulted in 10.4% of composite galaxies being misclassified as LINERs, while 10.1% of LINERs were incorrectly identified as composite galaxies. This behavior is anticipated, as it is widely recognized that composite and LINER galaxies can be powered by old stellar populations, resulting in mixing between these populations (Stasińska et al. 2008; Cid Fernandes et al. 2010; Singh et al. 2013; Daoutis et al. 2025) or shocks that produce LINER-like line ratios (Heckman 1980; Dopita & Sutherland 1995; Byler et al. 2020; Daoutis et al. 2025).
 |
Fig. 3. Confusion matrix summarizing the performance of our new diagnostic tool on the test set (Sect. 3.2) of our final sample (Sect. 2.4). We see that almost all objects are found on the primary diagonal indicative of a high-performance classifier. There are a few objects in the off-diagonal elements (misclassifications), indicating mild mixing between the composite and star-forming (SF) and composite and LINER classes. This is expected, as these classes share common characteristics. |
4.2. Performance on broad- and narrow-line AGNs
To evaluate the efficiency of the secondary scheme for the classification of broad- and narrow-line AGNs, we used the same metrics as presented in Sect. 3.3. We find that this scheme is effective in the two subclasses of AGNs, with recall rates for broad- and narrow-line AGNs of 91.0% and 90.0%, respectively (Table 4). The primary diagonal in this table represents the recall rate, while the off-diagonal elements of this table correspond to the misclassified objects. The number of objects is indicated in parentheses. The k-fold cross-validation method is not applicable because the total number of objects is not sufficient to derive reliable statistics.
Confusion matrix for broad- and narrow-line AGN classification.
The results presented in Table 4 demonstrate the nearly perfect efficiency of the secondary classification tool in distinguishing between broad-line and narrow-line AGNs. To further validate the above results, we visually inspected the spectra of galaxies classified by our diagnostic as broad-line and narrow-line AGNs. Our classification aligns with the spectral characteristics observed for these.
5. Discussion
In the previous sections, we present a new method for activity classification of galaxies based on the EW of the Hβ, [O III] λ5007, and Hα + [N II] λλ6548,84 lines. This method can characterize active galaxies of different types as well as passive galaxies, while it does not require starlight subtraction or even calibrated spectra, facilitating its application to large datasets.
5.1. Classification confidence
The confidence of the classification results depends on the intrinsic precision of the classifier (discussed in Sect. 4.1), on the uncertainty of the data used (in our case the EW of the diagnostic lines), and the intrinsic mixing of the considered classes (Daoutis et al. 2023).
In order to asses the sensitivity of the classification on the measurement uncertainties affecting the EWs, we repeated the procedure described in Sect. 2.5 on multiple realizations of the spectral lines of interest, based on modeling. In particular, we modeled each spectral point of the spectral line and adjacent continuum as a Gaussian distribution, with the measured flux as the mean and its 1σ uncertainty (provided by the SDSS) as the standard deviation. Utilizing this methodology, we generated a number of spectra (including the spectral line and adjacent continuum regions) from which we measured the EWs of each feature. Subsequently, we applied our classification method to each of these sets of EW measurements for each object. This process generates a distribution of classifications. Objects with low uncertainty in their spectra are anticipated to be consistently classified as belonging to a specific class. Conversely, spectra with poor quality are expected to exhibit a wide range of EW measurements, leading to frequent changes in classification across different runs, especially if they are located close to the boundary of the loci of the different classes.
An alternative method for assessing the reliability of the classification is to examine the probability of an galaxy belonging to each of the considered classes (Sect. 3.4). In order to account for the uncertainty of this probability stemming from the measurement uncertainties, we examined the distribution of the predicted probabilities obtained from multiple runs of the diagnostic on simulated spectra, as described in the previous paragraph. In practice, we calculated the mean and the standard deviation of the predicted probabilities for each source to belong to each of the considered classes. Consequently, galaxies with confident classifications will exhibit a high probability of belonging to a single class, while probabilities for the other classes will be low. Additionally, the standard deviation of the predicted probabilities will be low.
Figure 4 shows two examples of the classification procedure accounting for measurement errors, as outlined in the preceding paragraphs. We considered two galaxies exhibiting similar standard deviations in their EWs across all features, and we show the distribution of (a) the predicted classes and (b) the probability for each class. The top row shows a classification with high confidence, where the majority of the classifications (left panel) are confined to a single class. The distributions of predicted probabilities (right panel) are dominated by this class, exhibiting low standard deviation. This galaxy was identified as being near the center of its class distribution within the feature space. Conversely, the bottom row illustrates a classification with lower confidence, where the source is sorted into multiple classes, although one dominates (left panel). The distribution of predicted probabilities (right panel) covers multiple classes, resulting in higher standard deviations (shown by the error bars on the predicted probabilities) and ambiguous classification. This galaxy lies near the intersection of multiple classes in the feature space, meaning that its classification is sensitive to small perturbations of its EW within the associated uncertainties. As a result, when the EW values are varied within their errors, the galaxy may cross decision boundaries and transition into the locus of neighboring classes.
 |
Fig. 4. Two examples of classification output generated by our diagnostic, demonstrating a confident classification (top row) and a less confident classification (bottom row). Both galaxies have the same standard deviation (measurement error) in their EWs across all features. The output left (blue) histograms show the resulting classifications based on Monte Carlo sampling the EW of the spectral features within their uncertainties, while the right (green) histograms show the corresponding probability for the different classes. The error bars represent the standard deviation of the predicted probabilities for each class. The classification result for the galaxy depicted in the top row indicates a reliable classification, whereas the galaxy in the bottom row exhibits ambiguous results. |
However, these probabilities should be treated with caution since they are very sensitive to the location of each galaxy in the feature space with respect to the boundary between classes. This problem becomes particularly important for objetcs near the boundaries and in the case of under-represented classes. Therefore, while the distribution of the predicted probabilities can provide insights into classification uncertainty, they cannot be used as a robust indicator. Instead, we regard the distribution of the predicted classes as a more robust indicator of the classification confidence accounting for both measurement uncertainties and the intrinsic uncertainty of the classifier.
5.2. Application to the HECATE catalog
The Heraklion Extragalactic Catalog (HECATE; Kovlakas et al. 2021; Kyritsis et al. 2025) is a comprehensive catalog that provides detailed information for 204 733 galaxies up to 200 Mpc. It is based on the HyperLEDA catalog and incorporates additional data from various extragalactic and photometric sources. The catalog offers comprehensive information, including positions, morphological information, multiband photometry, distances, star-formation rates, stellar masses, gas-phase metallicities, and nuclear classifications. Activity classification for such a sample is important to estimate activity demographics, studies of the starburst and AGN connection, characterization of sources in wide-area multiwavelength surveys, and transient events (e.g., tidal disruption events). Here, we utilized the revised HECATE catalog (HECATEv2; Kyritsis et al. 2025). This version of HECATE includes spectroscopic classifications for 53 291 galaxies based on spectral-line measurements available in the SDSS JHU-MPA DR8 catalog. These classifications are based on the diagnostic of Stampoulis et al. (2019). However, the number of galaxies with available spectra in SDSS has increased dramatically since DR8. As an application of this new method, we obtained all available spectra from SDSS for the galaxies in the HECATE catalog from DR17.
The SDSS spectra were obtained from DR17 using the astroquery Python package based on a cone search of 10 arcsec around the galaxy coordinates. In total, we obtained spectra for 89 628 galaxies. We retained all spectra with reliable redshift measurements (i.e., ZWARNING=0), resulting in 88 514 spectra. Subsequently, our diagnostic was applied in all of these galaxies, and we performed two actions. First, we compared our classification results against the classification provided in the HECATE catalog, which were obtained using the SoDDA classifier (see Sect. 2.2). To achieve this, we adhered to all the quality criteria (S/N > 5 in all the aforementioned emission lines) that ensure reliable classification labels for the SoDDA diagnostic, which resulted in 23 710 galaxies with highly reliable flux measurements in the Hα, Hβ, [O III], [O I], [N II], and [S II] lines. The results of this comparison are presented in Table 5. These results are comparable to the performance metrics presented in Fig. 3, suggesting that the classifier operates with high reliability.
Comparison between the SoDDA diagnostic (ground truth) and our spectral classifier.
The second action is to implement our diagnostic for all galaxies in the HECATE catalog that have SDSS DR17 spectra (with ZWARNING=0), irrespective of whether they have classification labels from SoDDA. This enabled us to increase the population statistics per activity class of the HECATE catalog based on spectroscopic classifications from 26% to 43%, include passive galaxies, and also identify broad- and narrow-line galaxies that are currently not characterized. We find that out of the 88 514 galaxies in HECATE, 26 393 (29.8%) are star-forming, 7024 (7.9%) AGN, 16 721 (18.9%) LINER, 16 075 (18.2%) composite, and 22 301 (25.2%) passive galaxies. AGNs are further subdivided into 6800 narrow (96.8%) and 224 broad-line (3.2%) AGNs. These statistics are summarized in Fig. 5. These classifications will be publicly available in a later release of the HECATE catalog.
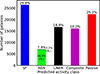 |
Fig. 5. Distribution of activity classes derived from the implementation of our diagnostic on the HECATE catalog galaxies using SDSS DR17 spectra. Any galaxy classified as an AGN by our diagnostic is subsequently characterized as a broad-line (BL) or narrow-line (NL) AGN. |
We proceeded by comparing the population statistics derived above (based on the spectra from DR17) for the galaxies in the HECATE catalog with those estimated from Ho et al. (1997), which is regarded as a representative sample of galaxies in the local Universe. To improve the accuracy of the classifications of the Ho et al. (1997) sample, we applied the SoDDA diagnostic (Stampoulis et al. 2019), which incorporates three emission-line ratios ([O III]/Hβ, [N II]/Hα, and [S II]/Hα) simultaneously (the classifications available in the original publication are based on the original version of the BPT diagnostics), to their emission-line measurements. Our analysis shows that the population statistics are broadly consistent, exhibiting only a 2−5% deviation across all activity classes.
5.3. Application to low-resolution spectra
Our diagnostic was designed to be versatile and flexible so that it could be applied to spectra of different resolutions than the ones used for its training (i.e., SDSS). We note that the resolution affects the classifier in two ways: (a) leakage of the emission lines into the continuum bands in poor-resolution spectra affects the main activity classification since it results in underestimation of the EW; (b) it affects the FWQM of the Hα+[N II] blend that is used for the classification of AGNs as narrow-line and broad-line galaxies. In order to minimize the leakage of the line flux into the continuum (even in the case of galaxies with broad lines; Sect. 2.5), the continuum was defined to be at least 40 Å on either side from the center of the line band for the Hα+[N II] and 15 Å for Hβ and the [O III].
In order to test our diagnostic’s performance on lower resolution and S/N spectra, we first performed a simulation study for its application to spectra similar to those from the six-degree field survey (6dF; Jones et al. 2004, 2009), and then we analyzed actual 6dF spectra. The 6dF galaxy survey, conducted using the 6dF spectrograph, is one of the most comprehensive surveys in the southern sky covering over 17 000 square degrees and providing spectra for over 125 000 galaxies in the 4000−7500 Å range with a resolution of 5−8 Å.
We wanted to ascertain whether our EW measuring bands might result in flux leakage to the adjacent continuum in low resolution spectra. We applied our diagnostic to the galaxies from our test set of SDSS spectra (Sect. 2) after convolving them to match the resolution of the 6dF spectra. More specifically, given that the resolution of the 6dF and the SDSS spectra at an average wavelength is FWHM6dF = 6 Å and FWHMSDSS = 2.4 Å, the convolution kernel is FWHMkernel = FWHM6dF2–FWHMSDSS2 = 5.6 Å. Subsequently, the EWs of all features in the test set were measured using the same bands (see Table 2). We find that the performance (recall score) using the smoothed spectra remained relatively unchanged across all classes (recall scores changed ±1−2% on average) with respect to the original SDSS spectra shown in Fig. 3. This indicates that the line fluxes are well contained within the defined measurement bands outlined in Sect. 2.5 and that our diagnostic can be applied to lower resolution spectra without any modifications.
Next, we applied our method to actual 6dF spectra, which serve as real-world examples of spectra exhibiting significantly lower quality and resolution compared to those from the SDSS. In addition, the 6dF spectra are provided in uncalibrated photon counts and lack absolute flux calibration. Flux calibration of these spectra presents challenges due to calibration issues associated with instrumental and observational challenges that affect spectral quality (e.g., Proctor et al. 2008). This in turn results in unreliable starlight subtraction, making the use of EW a good alternative.
In order to perform this exercise, we applied our diagnostic to all objects that are common to both SDSS and 6dF. Cross-matching our final sample (Sect. 2.4) with the 6dF survey yields 1093 common objects. Then, we measured the EWs for all discriminatory features from the 6dF rest-frame spectra. Table 6 presents the performance of our diagnostic when implemented on the 6dF spectra. For this comparison, we considered the classification from SoDDA (Sect. 2.2) as ground truth. We observe a reduction in performance, which is expected due to generally poorer quality of the 6dF spectra. Furthermore, we find that when we exclude objects with comparable predicted probabilities of belonging to more than one class, indicating unreliable classifications (Sect. 5.1), the fraction of correct classifications reaches 60%. However, it is important to note that the number of available objects used for this test is too small to achieve reliable statistics. Although there is a reduction in performance due to the lower quality of the 6dF spectra, the diagnostic remains a robust method for classifying galaxy spectra across various surveys considering the intrinsic limitations of each one.
Comparison between classifications based on measurements performed on the 6dF and corresponding SDSS spectra.
Based on the results of the simulation study, the reduced performance cannot only be attributed to differences in the SDSS and 6dF spectral resolution. In addition, the fibers used to obtain the 6dF spectra have a size of 6.7 arcsec (in comparison to ∼3 arcsec for SDSS), also leading to aperture effects. Aperture bias poses a challenge because it dictates the balance of nuclear versus host-galaxy light in a spectrum. While we might expect larger apertures to simply dilute AGN signatures, Maragkoudakis et al. (2014) showed that the reality is far more complex, often driven by the inclusion of circumnuclear star-forming regions, which have a wide range of relative emission line strengths depending on the age and the metallicity of their stellar populations. This unpredictability means that we cannot simply assume a systematic trend across the sample, requiring the assessment of aperture effects on a case-by-case basis.
Spectra obtained from the 6dF survey have previously been employed to classify galaxy activity using the BPT diagnostics (Zaw et al. 2019). In that study, two catalogs of galaxies were provided: one containing optically identified AGN (based on BPT diagnostics; 3365 objects) and the other containing galaxies that do not exhibit AGN activity (6787 objects), which were then separated into objects showing emission lines (3837) and non-emission-line objects (2950).
We applied our method to the set of galaxies with classifications from Zaw et al. (2019). We retrieved the spectra for these two galaxy catalogs from the 6dF2 using their celestial coordinates. Then, we classified these spectra using our diagnostic. Based on our diagnostic from the AGN sample reported in Zaw et al. (2019), we identified 265 (7.9%) as AGN, 598 (17.8%) as star-forming galaxies, 770 (22.9%) as LINER, 1052 (31.3%) as composite, and 680 (20.2%) as passive galaxies. The results for the galaxies showing emission lines from the non-AGN catalog are as follows: 635 (16.5%) star-forming galaxies, 30 (0.8%) AGN, 606 (15.8%) LINER, 713 (18.6%) composite, and 1853 (48.3%) passive galaxies. The results for the galaxies with no presence of emission lines from the non-AGN catalog are as follows: 43 (1.5%) star-forming, 8 (0.3%) AGN, 259 (8.8%) LINER, 144 (4.9%) composite, and 2496 (84.6%) passive. For the AGN sample of galaxies from Zaw et al. (2019), we identify 7.9% of the galaxies as actual AGNs. Also, the LINER and composite galaxies, this fraction reaches 54%. However, it should be noted that measuring emission line ratios from the 6dF spectra is prone to several biases due to poor spectral resolution and the lack of flux calibration which affects the starlight subtraction and of course the measurement of the emission lines themselves. In addition to these effects, these discrepancies may stem from the low quality of the 6dF spectra and the flux calibration that suffers from various artifacts, as previously discussed, and which affects the measurement of absolute line fluxes. These factors hinder the accurate measurement of emission-line fluxes, making the classifications from Zaw et al. (2019) unreliable.
5.4. The effect of the stellar continuum
One potential limitation of our method is that it does not require the removal of the stellar component of galaxy spectra (starlight subtraction). In general, starlight subtraction is used to measure the intrinsic flux of emission lines, especially those that are buried in strong stellar absorption features, which may lead to the underestimation of their intensity. However, starlight subtraction also presents significant challenges. One major drawback is the over- or under-subtraction of the starlight resulting in potential contamination or residuals, which can lead to inaccuracies in derived quantities if not carefully handled (see, Maragkoudakis et al. 2014, for a discussion on the sensitivity of line measurements on the starlight subtraction process). Furthermore, assumptions about the stellar populations, such as the initial mass function or the adoption of particular stellar libraries can introduce uncertainties (Conroy et al. 2009). In addition, in the case of AGNs, starlight subtraction may give wrong estimates for the emission-line fluxes since it models the AGN continuum as stellar continuum affecting the stellar absorption lines and hence the estimated intrinsic flux of the emission lines of interest. This is particularly important for identifying low-luminosity AGNs, especially in early type galaxies where the absorption lines may be masked by the stellar component (Colina et al. 2002; Cardoso et al. 2017).
Our diagnostic tool avoids these biases, as it eliminates the need for starlight subtraction from the spectra. However, this presents another challenge: the suppression of characteristic spectral features that may be concealed within a dominant stellar continuum, resulting in low-luminosity AGNs being misclassified (e.g., as composite galaxies or even passive ones).
To quantify the impact of the stellar continuum on the classification of star-forming and AGN galaxies, we applied the diagnostic to simulated spectra of composite galaxies with a known AGN contribution. First, we selected galaxies with the same apparent g-band magnitude from each of our final samples (Sect. 2.4) of star-forming, AGN, and passive galaxies. The g band used here was derived from the SDSS 3″ fiber (fiberMag), which corresponds to the nucleus of a galaxy. In addition, this ensures consistency with the spectroscopic aperture used for the ground-truth classification (SoDDA), minimizing aperture-related effects. The AGNs utilized for this analysis have a median luminosity of the Hα line LHα ≈ 1041 erg s−1, which is generally regarded as a moderate luminosity for an AGN, making it ideal for low-luminosity AGNs. Then, composite galaxy spectra were created by combining randomly drawn spectra of star-forming, AGN, and passive galaxies. This way, we considered both types of composite spectra: AGN + passive and AGN + star-forming. In total, in this exercise, we used spectra from 460 star-forming, 42 AGN, and 153 passive galaxies with 18.50 < mg < 18.55 (AB mag), ensuring spectra of similar quality. In order to simulate different AGN contributions, we kept the AGN spectrum as it was and multiplied the other (star-forming or passive, depending on the analysis) spectrum by a constant c. Then, the AGN contribution (in g-band continuum) to the composite (total) spectrum was calculated as 1/(1 + c), and we selected appropriate values for c to simulate AGN fractional contributions of 1, 5, 10, 25, 50, 75, and 100%. In total, 20 composite spectra for each AGN contribution fraction were produced by randomly drawing spectra from each of the considered types (AGN, passive, star-forming). The resulting composite spectra were then classified with our diagnostic tool, and we calculated the average and standard deviations of the predictions of each composite spectrum in order to sort them according to our classification scheme.
Figure 6 presents the average predictions (classification frequency) per activity class for the composite spectra of AGN and passive galaxies as a function of the AGN’s fractional contribution in the nuclear (3″) g-band continuum. This is relevant for AGNs in elliptical galaxies or galaxy bulges. This plot illustrates that even without removing the stellar component our diagnostic is able to identify passive galaxies hosting AGNs with contributions as low as 25% in the g band. For lower AGN contribution (below 25% to 10%), our composite spectra are classified as LINERs, with AGNs being the second-ranking class.
 |
Fig. 6. Classification frequencies of composite spectrum (derived from combining AGN and passive spectra, with respect to the classes considered in our diagnostic scheme) as a function of AGN fractional contribution to the total nuclear (3″) continuum in the SDSS g band. We observe a transition from passive to LINER and then to AGN galaxy classification when the AGN contribution to the nuclear flux in the SDSS g band reaches approximately 10% and 25%, respectively, indicating that our diagnostic is sensitive to AGN contributions in passive galaxies as low as 10% in the g band. The curves depict the average predictions of each class for 20 randomly generated composite spectra, while the shaded areas represent the standard deviation of the classification frequencies. |
In Fig. 7, we present the same analysis, but for composite spectra of AGN and star-forming galaxies. The primary objective of this exercise was to assess the diagnostic’s sensitivity in scenarios where star formation is present alongside weak AGN emission. This could result in misclassifications of weak AGNs as star-forming galaxies, which would contaminate our classifications for star-forming galaxies and lead to the omission of AGNs. We see that the identification of an AGN in the composite spectra of AGN + star-forming is possible when the AGN contribution in the nuclear g-band continuum exceeds ∼40%. However, when we consider the contribution of the AGN in the Hα luminosity to the total composite spectrum (red line and right y-axis of Fig. 7), we can detect AGNs at the 30% contribution level. This is a good score considering the fact that the AGN spectra used in the construction of the composite spectra also include their host galaxy’s star-forming component, which has a non-negligible contribution given the moderate AGN Hα luminosities of ∼1041 erg s−1. This star-forming component and the “host-galaxy” component both contribute to the dilution of the AGN emission, especially in the case of the Hα + [N II] lines. From the same figure, we also see that composite spectra classified as star-forming spectra with a classification frequency exceeding ∼60% are indeed dominated by star formation, with little AGN contribution (i.e., the AGN fraction in the g-band continuum is below ∼25%, and even lower in the Hα flux). Similarly, galaxies with a classification frequency higher than 50% are AGN-dominated. Additionally, we observe that as the AGN fraction increases in the composite spectra of AGN and star-forming galaxies, the second most likely class is that of composite galaxies. At the transition point, where the AGN fraction is approximately 30%, this classification frequency competes with both AGN and star-forming galaxy classifications. This outcome is expected, as composite galaxies can result from moderate-luminosity AGNs within galaxies that exhibit substantial star formation.
 |
Fig. 7. Similar analysis to in Fig. 6, but for composite spectra combining star-forming and AGN spectra. The dashed red line depicts the logarithm of the AGN’s Hα luminosity ratio to the total Hα luminosity of the composite spectra. Although the transition from star-forming to AGN galaxy occurs when the AGN’s fractional contribution to the nuclear SDSS g-band continuum approaches ∼40%, the corresponding Hα fractional contribution is ∼30. |
5.5. Sensitivity to flux calibration
Accurate flux calibration is a fundamental prerequisite for reliability when measuring emission-line fluxes and performing starlight subtraction. In certain instances, flux calibration can be challenging due to the instrument or survey design. Our diagnostic overcomes this difficulty since it uses EWs, which make it insensitive to the absolute flux or even spectrograph sensitivity calibration. To evaluate the sensitivity of our diagnostic to flux calibration effects and its applicability in such situations, we conducted the following test. We multiplied the SDSS spectra from the test set (Sect. 2.4) with (a) polynomial functions up to the fifth degree, or (b) sine functions. This approach was designed to simulate systematics that could occur in cases of problematic flux/sensitivity calibration. Then, we applied our diagnostic (Sect. 3) to these transformed spectra. The performance scores across all classes remained unchanged (recall scores changed by ±1−2% on average) as a result of the relatively narrow spectral windows used for measuring the EWs of the spectral lines (see Sect. 2.5) and the fact that we used EWs instead of line fluxes. Because of the narrow range of the continuum and line bands, the linear function for the calculation of the continuum under a spectral line is a good approximation. For more details about the specifics of this exercise, please refer to Appendix B.
5.6. Distinguishing broad-line AGNs from other sources of line broadening
In Sect. 3.5, we introduced an additional classification step to indicatively identify broad-line AGNs using only the FWQM of Hα + [N II]. Although this approach is highly effective (see Sect. 4.2), it may include broad-line galaxies resulting from shocks or outflows rather than from a classical broad-line region. The two types of broadening can be distinguished by comparing the width of the Balmer and the forbidden lines, since in a genuine broad-line AGN only the Balmer lines are broad (see, e.g., Kouroumpatzakis & Svoboda 2025).
To test this we considered the FWQM Hα to [O III] line ratio. We used the Hα line for its higher S/N and weaker stellar absorption relative to Hβ. While the [N II] lines may result in artificially larger FWQM, we find that this is not the case since there is a strong linear correlation between the Hα/[O III] ratios of FWQM and their line-width (σ) ratios. Figure 8 compares the Hα/[O III] FWQM ratio distributions for broad-line and narrow-line AGNs. We see that the vast majority of narrow-line AGNs have FWQM ratios under ∼1.5 (with a median value of ∼1.25), while the vast majority of broad-line AGNs have higher ratios. We find that the broad-line AGNs with FWQM ratios of ∼1.25 have median FWHMs for both the Hα and the [O III] line of ∼850 km s−1, which is consistent with line broadening driven by shocks or outflows rather than a classical broad-line region. However, broad-line AGNs with FWQM ratios > 1.25 are consistent with the definition of a broad-line AGN (median FWHM of Hα ≳ 1000 km s−1 and narrower [O III] with ≲300 km s−1). Thus, a criterion of the FWQM ratio of Hα to [O III] of < 1.75 is effective in separating bona fide broad-line AGNs from shocks/outflows.
 |
Fig. 8. Histogram of FWQM Hα to [O III] λ5007 Å line ratio for the star-forming, broad-line, and narrow-line AGNs in the training sample (blue, red, and green lines, respectively). We see that the distributions for the narrow-line AGNs and star-forming galaxies are almost identical, while the broad-line AGNs extend to a much larger FWQM ratio, with only a small fraction in the region of the star-forming galaxies or narrow-line AGNs. We also show the very-broad-line galaxies (QSO-like spectra) classified as AGNs (solid black line) and star-forming galaxies (dashed black line). We see that the majority of the QSO-like galaxies classified as star-forming galaxies have much larger FWQM ratios than bona fide star-forming galaxies, allowing us to use the FWQM ratio as a metric to correctly classify them. |
To further investigate how our diagnostic handles genuine cases of broad-line AGNs with lines much broader than the ∼470 km s−1 limit used for the definition of our sample (Section 2.3), we used quasi-stellar objects (QSOs) to perform the following exercise. We selected a local sample (z < 0.1) of good-quality (ZWARNING=0 and snMedian3 > 10) QSOs from SDSS ("SUBCLASS"="QSO") to apply our diagnostic. We find that 65% of the QSOs are classified as AGN, 27% as star-forming, and 8% as composite galaxies. The misclassification of star-forming galaxies is due to our bands being too narrow to fully encompass these very broad Balmer lines. This effect can be remedied by imposing a threshold based on the FWQM ratio (> 1.75) of the Hα to [O III] lines as above, since the broad-line galaxies will have much higher ratios than the star-forming galaxies (Fig. 8).
6. Conclusions
In this work, we introduced a new activity diagnostic tool that includes all possible types of galaxy activity under one unified classification scheme utilizing only the EW of the Hβ, [O III] λ5007, and the Hα + [N II] λλ6548,84 spectral lines. Our diagnostic method offers significant improvements over similar studies that employ EW as a classification tool (e.g., Cid Fernandes et al. 2010). It entirely eliminates the need for measuring emission-line fluxes and introduces a more comprehensive activity classification framework, which notably includes the often-overlooked category of passive galaxies. Our results are summarized as follows.
-
Our new diagnostic tool introduces a classification scheme that categorizes galaxies into five main activity classes: star-forming galaxies, AGN, LINER, composite galaxies, and passive galaxies under one unified scheme. Notably, our diagnostic tool achieves near-perfect scores across all classes.
-
AGN galaxies with high-resolution spectra can be further classified into two subclasses: broad- and narrow-line AGNs, both of which exhibit high completeness with only one feature (i.e., the FWQM of the Hα + [N II] blend).
-
A significant advantage of our diagnostic is its direct applicability to uncalibrated optical spectra, thereby eliminating the need for flux calibration, removal of the stellar component, and fitting or deblending of the spectral-line profiles. The latter is particularly important in the case of the Hα and [N II] doublet lines, an often challenging and model-dependent process. Moreover, it is largely insensitive to reddening effects, ensuring reliable classification even for spectra affected by significant dust attenuation.
-
Genuine broad-line AGNs and broad-line galaxies due to outflows or shocks can be discriminated based on the comparison of the FWQM of the Hα and the [O III] λ5007 lines, a feature that is included in our pipeline.
-
AGNs hosted in passive galaxies with an AGN contribution greater than ∼25% in the g-band continuum are recovered even without starlight subtraction. Similarly, AGN situated within star-forming galaxies can be reliably identified when their nuclear g-band contribution is as low as ∼40%.
-
The narrow spectral range window (4864−6584 Å) of our diagnostic, its high completeness, and its independence from the resolution of the spectrograph makes our diagnostic extremely versatile and enables the classification of high-redshift galaxies such as those observed with the James Webb Space Telescope (JWST) and the Dark Energy Spectroscopic Instrument (DESI; DESI Collaboration 2016), making it an invaluable tool for studying galaxy activity across the Universe.
Data availability
The code, including detailed documentation and usage instructions, is publicly available via a GitHub repository4.
Acknowledgments
We thank the anonymous referee for their insightful suggestions that helped to clarify and strengthen this work. CD and EK acknowledge support from the Public Investments Program through a Matching Funds grant to the IA-FORTH. The research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP/2007-2013)/ERC Grant Agreement n. 617001, the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie RISE action, Grant Agreement n. 873089 (ASTROSTAT-II), and the Smithsonian Astrophysical Observatory Predoctoral Program with funding under the NASA grant 80NSSC21K0078. KK acknowledges support by the institutional project RVO:67985815 and by the INTER-COST LUC24023 project of the INTER-EXCELLENCE II programme of the Czech Ministry of Education, Youth and Sports. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High Performance Computing at the University of Utah. The SDSS website is www.sdss.org. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics | Harvard & Smithsonian, the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University.
References
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [Google Scholar]
- Balogh, M. L., Morris, S. L., Yee, H. K. C., Carlberg, R. G., & Ellingson, E. 1999, ApJ, 527, 54 [Google Scholar]
- Binette, L., Magris, C. G., Stasińska, G., & Bruzual, A. G. 1994, A&A, 292, 13 [NASA ADS] [Google Scholar]
- Brinchmann, J., Charlot, S., White, S. D. M., et al. 2004, MNRAS, 351, 1151 [Google Scholar]
- Byler, N., Kewley, L. J., Rigby, J. R., et al. 2020, ApJ, 893, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Cardoso, L. S. M., Gomes, J. M., & Papaderos, P. 2017, A&A, 604, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cid Fernandes, R., Stasińska, G., Schlickmann, M. S., et al. 2010, MNRAS, 403, 1036 [Google Scholar]
- Colina, L., Gonzalez Delgado, R., Mas-Hesse, J. M., & Leitherer, C. 2002, ApJ, 579, 545 [NASA ADS] [CrossRef] [Google Scholar]
- Conroy, C., Gunn, J. E., & White, M. 2009, ApJ, 699, 486 [Google Scholar]
- Cortes, C., & Vapnik, V. 1995, Mach. Learn., 20, 273 [Google Scholar]
- Cui, X.-Q., Zhao, Y.-H., Chu, Y.-Q., et al. 2012, RAA, 12, 1197 [NASA ADS] [Google Scholar]
- Daoutis, C., Kyritsis, E., Kouroumpatzakis, K., & Zezas, A. 2023, A&A, 679, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Daoutis, C., Zezas, A., Kyritsis, E., Kouroumpatzakis, K., & Bonfini, P. 2025, A&A, 693, A95 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, arXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Dopita, M. A., & Sutherland, R. S. 1995, ApJ, 455, 468 [Google Scholar]
- Ferland, G. J., & Netzer, H. 1983, ApJ, 264, 105 [NASA ADS] [CrossRef] [Google Scholar]
- Greene, J. E., & Ho, L. C. 2005, ApJ, 630, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Haines, C. P., Gargiulo, A., & Merluzzi, P. 2008, MNRAS, 385, 1201 [NASA ADS] [CrossRef] [Google Scholar]
- Halpern, J. P., & Steiner, J. E. 1983, ApJ, 269, L37 [CrossRef] [Google Scholar]
- Heckman, T. M. 1980, A&A, 87, 152 [Google Scholar]
- Ho, L. C., Filippenko, A. V., & Sargent, W. L. W. 1997, ApJ, 487, 568 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, D. H., Saunders, W., Colless, M., et al. 2004, MNRAS, 355, 747 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, D. H., Read, M. A., Saunders, W., et al. 2009, MNRAS, 399, 683 [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Kewley, L. J., Dopita, M. A., Sutherland, R. S., Heisler, C. A., & Trevena, J. 2001, ApJ, 556, 121 [Google Scholar]
- Kewley, L. J., Nicholls, D. C., & Sutherland, R. S. 2019, ARA&A, 57, 511 [Google Scholar]
- Kouroumpatzakis, K., & Svoboda, J. 2025, A&A, 696, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kovlakas, K., Zezas, A., Andrews, J. J., et al. 2021, MNRAS, 506, 1896 [NASA ADS] [CrossRef] [Google Scholar]
- Kyritsis, E., Maravelias, G., Zezas, A., et al. 2022, A&A, 657, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kyritsis, E., Zezas, A., Kovlakas, K., et al. 2025, MNRAS, submitted [Google Scholar]
- Maragkoudakis, A., Zezas, A., Ashby, M. L. N., & Willner, S. P. 2014, MNRAS, 441, 2296 [NASA ADS] [CrossRef] [Google Scholar]
- Maravelias, G., Bonanos, A. Z., Tramper, F., et al. 2022, A&A, 666, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Osterbrock, D. E., & Pogge, R. W. 1985, ApJ, 297, 166 [Google Scholar]
- Papaderos, P., Gomes, J. M., Vílchez, J. M., et al. 2013, A&A, 555, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Platt, J. 2000, Adv. Large Margin Classif., 10 [Google Scholar]
- Proctor, R. N., Lah, P., Forbes, D. A., Colless, M., & Couch, W. 2008, MNRAS, 386, 1781 [Google Scholar]
- Salim, S., Lee, J. C., Janowiecki, S., et al. 2016, ApJS, 227, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Schawinski, K., Thomas, D., Sarzi, M., et al. 2007, MNRAS, 382, 1415 [Google Scholar]
- Singh, R., van de Ven, G., Jahnke, K., et al. 2013, A&A, 558, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stampoulis, V., van Dyk, D. A., Kashyap, V. L., & Zezas, A. 2019, MNRAS, 485, 1085 [NASA ADS] [CrossRef] [Google Scholar]
- Stasińska, G. 1984, A&A, 135, 341 [NASA ADS] [Google Scholar]
- Stasińska, G., Vale Asari, N., Cid Fernandes, R., et al. 2008, MNRAS, 391, L29 [NASA ADS] [Google Scholar]
- Tremonti, C. A., Heckman, T. M., Kauffmann, G., et al. 2004, ApJ, 613, 898 [Google Scholar]
- Veilleux, S., & Osterbrock, D. E. 1987, ApJS, 63, 295 [Google Scholar]
- Veron-Cetty, M. P., & Veron, P. 2000, VizieR Online Data Catalog: VII/215 [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zaw, I., Chen, Y.-P., & Farrar, G. R. 2019, ApJ, 872, 134 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, H., Wang, T., Yuan, W., et al. 2006, ApJS, 166, 128 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Optimization of the SVM hyperparameters
An SVM model is specified by at least three significant hyperparameters: the ”tolerance” C (regulating the allowed mis-classifications), the kernel type (for the calculation of the dot product in the transformed feature space), and the kernel hyperparameters themselves (i.e., the constants in the kernel’s functional form). In any implementation, these come with default values, but in practice they need to be optimized for the data at hand.
In the pursuit of optimizing parameters for machine learning models such as SVM, randomized search emerges as a robust alternative to conventional to static methods like grid search. Randomized search is a methodology that explores a predetermined number of random combinations of the parameters. This approach facilitates the efficient identification of optimal parameters by better exploring the parameter space and surpassing exhaustive search techniques in terms of computational efficiency.
This process begins by defining parameter distributions for each hyperparameter, enabling random selection and evaluation of candidates from the parameter space. Unlike grid search, which assesses all possible combinations, randomized search evaluates a random subset. After identifying potential value ranges for each hyperparameter, multiple random parameter sets are generated, each used to train the model. Performance metrics such as accuracy, recall, or F1-score are computed, and the set with the best performance is chosen as the optimal configuration.
Hyperparameter distribution for the primary diagnostic tool based on the SVM algorithm.
Appendix B: Insensitivity to flux calibration
Flux calibration is a critical step in the processing of optical spectra, directly impacting the accuracy of emission line flux measurements in galaxies. It involves correcting the raw observed spectra for the instrumental response and atmospheric transmission, thereby translating counts or relative fluxes. Without proper flux calibration, systematic biases may be introduced in the derived emission line fluxes, particularly when comparing lines across different wavelength regions (e.g., Hβ and Hα), which can lead to significant errors in key diagnostics such as dust attenuation, gas-phase metallicity, and star formation rates. Even moderate calibration errors can propagate non-linearly into derived quantities, especially in line ratio diagnostics that rely on lines widely spaced in wavelength. Therefore, careful attention to flux calibration procedures, is indispensable for robust emission line analyses and the physical interpretation of galaxy spectra.
EWs offer a robust alternative to absolute flux measurements in cases where flux calibration is uncertain or unreliable. By construction, the EW of an emission line is the ratio of the line flux to the adjacent continuum flux density, making it a quantity that is inherently insensitive to multiplicative calibration errors that affect both the line and continuum equally. When the wavelength range is short and the continuum can be approximated with a linear function the EWs remain relatively stable even when the absolute spectral shape or throughput is poorly characterized.
Consequently, we assess the sensitivity of our diagnostic in instances where the flux calibration may have been executed inadequately. To accomplish this, we employed the full set (see Sect. 2) of spectra from the test and convolved them with a fifth-degree polynomial. Subsequently, we repeated the EW measurements of our discriminating features on these transformed spectra. Then, our diagnostic was applied to the EWs measured from the transformed spectra. We found that all the performance metrics (e.g., recall and accuracy) remained unchanged across all classes (recall scores changed ±1-2% on average). The above analysis was repeated but the test set spectra were convolved with a sine function to simulate a scenario where the flux calibration generates periodic patterns on the spectra. Once again, we obtained similar results. Figure B.1 shows an example of a SDSS spectrum after it has been convolved with the fifth-degree polynomial (top) and the sine function (bottom).
 |
Fig. B.1. Examples of spectra used to assess the impact of erroneous flux calibration. The orange spectrum indicates the original spectrum, while the blue spectra show the same spectrum convolved with a fifth order polynomial (top) and a sine function (bottom). Notably, both convolved spectra were accurately classified by our diagnostic, yielding the same classification as when utilizing the original SDSS spectra. |
Appendix C: Measuring EWs
To measure the EWs of the targeted features (see Table 2), each spectrum was first corrected for redshift using spectroscopic redshifts reported in the SDSS. We then defined fixed spectral windows centered on the target lines-such as Hβ, [O III], and the Hα + [N II] λλ6548,84 blend avoiding contamination from neighboring lines. For each spectral feature, the local continuum was estimated by fitting a line to adjacent line-free regions starting from the edges of the spectral windows used for the spectral features (see Table 2) by fitting a straight line on the flux density as a function of wavelength using the data from the blue and red continuum bands for each line. The equation for estimating the continuum is the following:
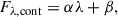 (C.1)
(C.1)
where the α is the slope and is β the intercept. All EWs was calculated as:
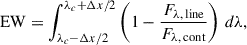 (C.2)
(C.2)
where λc and Δx are the central wavelength and the wavelength span of the spectral feature respectively (see Table 2), Fλ, line is the flux density of the spectrum at each target spectral line, and Fλ, cont is the fitted continuum (equation C.1) under the corresponding spectral line based on the fit to the continuum bands. Emission lines result in negative EWs by this convention (in accordance with SDSS). For the Hα + [N II] λλ6548,84 blend, no Gaussian fitting was performed to deblend and estimate the individual contributions of each component. Instead, the combined EW is measured as a single spectral feature. Figure C.1 illustrates an example SDSS spectrum, where the spectral lines of interest have been annotated along with the spectral range (see Table 2) utilized for calculating the EW.
 |
Fig. C.1. Flux density versus wavelength for an example SDSS spectrum (black) to show the location of our discriminating features along with their respective wavelength ranges (Table 2). The central wavelengths of the targeted features are indicated by red dashed lines, and the shaded gray areas represent the ranges for the EW calculation of each spectral feature. The purple shaded areas n the either side of each band show the areas used to estimate the continuum for the liner fit. |
All Tables
Spectral features, central wavelengths, wavelength ranges, and continuum ranges used for the calculation of the EWs.
Comparison between the SoDDA diagnostic (ground truth) and our spectral classifier.
Comparison between classifications based on measurements performed on the 6dF and corresponding SDSS spectra.
Hyperparameter distribution for the primary diagnostic tool based on the SVM algorithm.
All Figures
|
Fig. 1. Distributions of EW of the three spectral lines [O III] (top), of the [N II] doublet and Hα (middle), and of Hβ (bottom), used as determining features for the development of our new diagnostic for the activity classes of star-forming (SF), AGN, LINER, composite, and passive galaxies. All measurements were performed on non-starlight-subtracted SDSS spectra. We adhered to the same conventions as the SDSS, wherein negative EW correspond to emission. |
| In the text | |
|
Fig. 2. Calibration curves for the predicted probabilities of each activity class. This plot illustrates the relationship between the predicted probabilities (derived from our diagnostic) and the actual frequency of an activity class appearing among the remaining classes in the feature space. The dashed line represents an idealized classifier with perfect calibration. We observe that for star-forming (SF) and AGN galaxies, the predicted probabilities closely align with the observed frequencies. Passive galaxies exhibit a greater deviation from the dashed line compared to the previous two classes. Notably, LINER galaxies and passive galaxies demonstrate more pronounced deviations, which is consistent with their intricate nature. |
| In the text | |
|
Fig. 3. Confusion matrix summarizing the performance of our new diagnostic tool on the test set (Sect. 3.2) of our final sample (Sect. 2.4). We see that almost all objects are found on the primary diagonal indicative of a high-performance classifier. There are a few objects in the off-diagonal elements (misclassifications), indicating mild mixing between the composite and star-forming (SF) and composite and LINER classes. This is expected, as these classes share common characteristics. |
| In the text | |
|
Fig. 4. Two examples of classification output generated by our diagnostic, demonstrating a confident classification (top row) and a less confident classification (bottom row). Both galaxies have the same standard deviation (measurement error) in their EWs across all features. The output left (blue) histograms show the resulting classifications based on Monte Carlo sampling the EW of the spectral features within their uncertainties, while the right (green) histograms show the corresponding probability for the different classes. The error bars represent the standard deviation of the predicted probabilities for each class. The classification result for the galaxy depicted in the top row indicates a reliable classification, whereas the galaxy in the bottom row exhibits ambiguous results. |
| In the text | |
|
Fig. 5. Distribution of activity classes derived from the implementation of our diagnostic on the HECATE catalog galaxies using SDSS DR17 spectra. Any galaxy classified as an AGN by our diagnostic is subsequently characterized as a broad-line (BL) or narrow-line (NL) AGN. |
| In the text | |
|
Fig. 6. Classification frequencies of composite spectrum (derived from combining AGN and passive spectra, with respect to the classes considered in our diagnostic scheme) as a function of AGN fractional contribution to the total nuclear (3″) continuum in the SDSS g band. We observe a transition from passive to LINER and then to AGN galaxy classification when the AGN contribution to the nuclear flux in the SDSS g band reaches approximately 10% and 25%, respectively, indicating that our diagnostic is sensitive to AGN contributions in passive galaxies as low as 10% in the g band. The curves depict the average predictions of each class for 20 randomly generated composite spectra, while the shaded areas represent the standard deviation of the classification frequencies. |
| In the text | |
|
Fig. 7. Similar analysis to in Fig. 6, but for composite spectra combining star-forming and AGN spectra. The dashed red line depicts the logarithm of the AGN’s Hα luminosity ratio to the total Hα luminosity of the composite spectra. Although the transition from star-forming to AGN galaxy occurs when the AGN’s fractional contribution to the nuclear SDSS g-band continuum approaches ∼40%, the corresponding Hα fractional contribution is ∼30. |
| In the text | |
|
Fig. 8. Histogram of FWQM Hα to [O III] λ5007 Å line ratio for the star-forming, broad-line, and narrow-line AGNs in the training sample (blue, red, and green lines, respectively). We see that the distributions for the narrow-line AGNs and star-forming galaxies are almost identical, while the broad-line AGNs extend to a much larger FWQM ratio, with only a small fraction in the region of the star-forming galaxies or narrow-line AGNs. We also show the very-broad-line galaxies (QSO-like spectra) classified as AGNs (solid black line) and star-forming galaxies (dashed black line). We see that the majority of the QSO-like galaxies classified as star-forming galaxies have much larger FWQM ratios than bona fide star-forming galaxies, allowing us to use the FWQM ratio as a metric to correctly classify them. |
| In the text | |
|
Fig. B.1. Examples of spectra used to assess the impact of erroneous flux calibration. The orange spectrum indicates the original spectrum, while the blue spectra show the same spectrum convolved with a fifth order polynomial (top) and a sine function (bottom). Notably, both convolved spectra were accurately classified by our diagnostic, yielding the same classification as when utilizing the original SDSS spectra. |
| In the text | |
|
Fig. C.1. Flux density versus wavelength for an example SDSS spectrum (black) to show the location of our discriminating features along with their respective wavelength ranges (Table 2). The central wavelengths of the targeted features are indicated by red dashed lines, and the shaded gray areas represent the ranges for the EW calculation of each spectral feature. The purple shaded areas n the either side of each band show the areas used to estimate the continuum for the liner fit. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.