| Issue |
A&A
Volume 703, November 2025
|
|
|---|---|---|
| Article Number | A59 | |
| Number of page(s) | 17 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202556530 | |
| Published online | 05 November 2025 | |
A highly accurate drag solver for multi-fluid dust and gas hydrodynamics on GPUs
1
ENS de Lyon, CRAL UMR5574, Université Claude Bernard Lyon 1,
CNRS, Lyon 69007,
France
2
Institut Universitaire de France,
France
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
21
July
2025
Accepted:
11
September
2025
Abstract
Context. Exascale supercomputing unleashes the potential for simulations of astrophysical systems with unprecedented resolution. Taking full advantage of this computing power requires the development of new algorithms and numerical methods that are GPU friendly and scalable. In the context of multi-fluid dust-gas dynamics, we propose a highly accurate algorithm that is specifically designed for GPUs.
Aims. We developed a multi-fluid gas-dust algorithm capable of computing friction terms on GPU architectures to machine precision, with the constraint for the drag-time step to remain a fraction of the global hydrodynamic time step for computational efficiency in practice.
Methods. We present a scaling-and-squaring algorithm tailored to modern architectures for computing the exponential of the drag matrix, enabling high accuracy in friction calculations across relevant astrophysical regimes. The algorithm was validated through the Dustybox, Dustywaye, and Dustyshock tests.
Results. The algorithm was implemented and tested in two multi-GPU codes with different architectures and GPU programming models: Dyablo, an adaptive mesh refinement code based on the Kokkos library, and Shamrock, a multi-method code based on Sycl. On current architectures, the friction computation remains acceptable for both codes (below the typical hydro time step) up to 16 species, enabling a further implementation of growth and fragmentation. This algorithm might be applied to other physical processes, such as radiative transfer or chemistry.
Key words: hydrodynamics / methods: numerical / dust, extinction
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The tiny dust grains originating from the interstellar medium play a crucial role in its evolution at all scales (e.g. Draine 2003; Draine et al. 2007). They are dynamically coupled to the gas via a drag term and can thus exchange momentum and affect the gas dynamics. They act as charge reservoirs, allowing them to interact with the local magnetic field. They also interact with radiation, which affects the light that reaches Earth, and they play a key role in the local thermal balance by significantly contributing to opacity. Additionally, they regulate local chemistry and serve as fundamental building blocks for the formation of planetary embryos. Consequently, to achieve quantitative accuracy, numerical simulations of structure formation increasingly incorporate the most realistic models for dust processing (e.g. the discussions by Bai & Stone 2010; Laibe & Price 2012b; Lombart & Laibe 2021; Moseley & Teyssier 2025).
A major challenge arises from the fact that, locally, dust distributions can vary significantly, particularly in terms of size, which ranges from submicron scales to millimeter-sized particles, as seen in protoplanetary disks (e.g. Bae et al. 2023; Lesur et al. 2023a). This variability is referred to as the polydisperse distribution of dust. This polydispersity adds complexity to the evolution of the system by generating dynamics that do not appear when all grains are of a single size (Bai & Stone 2010; Laibe & Price 2014). For instance, in a protoplanetary disk, larger grains tend to drift inward, which in turn induces a radial outward drift of the gas as a result of feedback effects (Dipierro et al. 2018). This outward gas motion then carries along part of the dust distribution. The consequences of this polydispersity can be critical by favouring or preventing the development of instabilities that are necessary to concentrate dust and form the first planetary embryos (e.g. Krapp et al. 2019; Paardekooper et al. 2020; Krapp et al. 2020; Paardekooper et al. 2021; Wu et al. 2024; Cañas et al. 2024; Paardekooper & Aly 2025a,b; Matthijsse et al. 2025). Last but not least, the dust grain size distribution evolves during the formation of a star and planets via coagulation and fragmentation processes. The latter are regulated by the coupling of the dust grains with the gas and the magnetic fields, for which the dust grain size is key (e.g., Guillet et al. 2020; Lombart & Laibe 2021). In these scenarios, the behaviour of the gas-dust mixture is highly sensitive to the nature and distribution of the dust grains. Precise and rigorous numerical modelling is required to accurately capture these effects.
Numerically, addressing the polydispersity of strong constraints in hydrodynamic solvers presents several challenges (e.g. Bai & Stone 2010; Hutchison et al. 2018; Benítez-Llambay et al. 2019; Mentiplay et al. 2020). On one hand, increasing the number of fields required to evolve in order to simulate mixtures with different dust sizes imposes significant constraints on the computation time, memory access, and data management. In this regard, the solution lies in algorithmic and software advancements. In particular, the advent of exascale computing offers the possibility of overcoming some of these challenges, albeit at the cost of significantly higher energy and environmental demands (e.g. Wibking & Krumholz 2022; Grete et al. 2023; Lesur et al. 2023b; David-Cléris et al. 2025). On the other hand, intense friction regimes associated with small grains impose strict constraints on time-integration schemes. One way to circumvent this difficulty is to reformulate the gas-grain mixture equations in a limit where its evolution can be treated as an equivalent diffusive process (Hutchison et al. 2018; Lebreuilly et al. 2019; Mentiplay et al. 2020). This method is particularly effective when all grains are well coupled with the gas, but it becomes inadequate when part of the distribution is not (e.g. Tricco et al. 2017; Commerçon et al. 2023). Another approach involves using unconditionally stable implicit numerical schemes (Bai & Stone 2010; Benítez-Llambay et al. 2019; Krapp & Benítez-Llambay 2020; Huang & Bai 2022; Krapp et al. 2024). These schemes typically require significantly more computational resources than explicit schemes, however, and they often lead to a trade-off in accuracy for the sake of practical feasibility. This is contrary to the goal of a high-precision numerical treatment that is necessary for accurately simulating complex physical processes. For these reasons, we aim to design a dust algorithm compatible with new multi-GPU architectures. By properly handling the friction matrix decomposition, we ensure maximum precision of the drag calculation without significantly impacting the overall computation time.
The manuscript is organised as follows. Section 2 presents the equations and the most recent description for dust- and gas-mixture hydrodynamics and introduces our novel exponential solver. In Sect. 3 we test our method with respect to other drag solvers in different regimes using standard gas- and dust-dynamics test. We also assess and discuss its performance on GPUs. Section 4 concludes the paper.
2 Numerical method
2.1 Equations of the evolution of a dust and gas mixture
We considered an astrophysical dust-gas mixture and modelled N pressure-less dust fluids. Each dust fluid i was coupled to the gas via a drag term parametrised by Ts,i, the stopping time of the i th dust species. In most astrophysical conditions, the mean free path of the gas exceeds the size of the grain by far. In this case, the grain stopping time of dust species i is given by Epstein (1924)
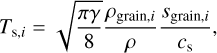 (1)
where γ is the adiabatic index of the gas, cs is the sound speed of the gas, and Sgrain, i and ρgrain, i are the radius and intrinsic density of the grain. This intrinsic grain density is different from the dust density ρd (see below).
(1)
where γ is the adiabatic index of the gas, cs is the sound speed of the gas, and Sgrain, i and ρgrain, i are the radius and intrinsic density of the grain. This intrinsic grain density is different from the dust density ρd (see below).
Conservation of momentum was ensured by the backreaction term onto the gas momentum. The equations of evolution for the mixture are given by
![Mathematical equation: $\frac{\partial \rho_{\mathrm{g}}}{\partial t}+\nabla \cdot\left[\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}\right]=0$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq2.png) (2)
(2)
![Mathematical equation: $\frac{\partial\left(\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}\right)}{\partial t}+\nabla \cdot\left[\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}} \otimes \boldsymbol{v}_{\mathrm{g}}+P_{\mathrm{g}} \mathrm{I}\right]-\rho_{\mathrm{g}} \boldsymbol{f}_{\mathrm{g}}=\sum_{i=1}^{N} \rho_{\mathrm{d}, i} \frac{\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}}{T_{\mathrm{s}, i}}$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq3.png) (3)
(3)
![Mathematical equation: $ \begin{align*} \frac{\partial E_{\mathrm{g}}}{\partial t}+\nabla \cdot\left[\left(E_{\mathrm{g}}+P_{\mathrm{g}}\right) \boldsymbol{v}_{\mathrm{g}}\right]-\rho_{\mathrm{g}} \boldsymbol{f}_{\mathrm{g}} \cdot \boldsymbol{v}_{\mathrm{g}} & =\sum_{i=1}^{N} \rho_{\mathrm{d}, i} \frac{\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}}{T_{\mathrm{s}, i}} \cdot \boldsymbol{v}_{\mathrm{g}} \\ & +w \sum_{i=1}^{N} \rho_{\mathrm{d}, i} \frac{\left(\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}\right)^{2}}{T_{\mathrm{s}, i}} \end{align*} $](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq4.png) (4)
(4)
![Mathematical equation: $\frac{\partial \rho_{\mathrm{d}, i}}{\partial t}+\nabla \cdot\left[\rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i}\right]=0,$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq5.png) (5)
(5)
![Mathematical equation: $\frac{\partial\left(\rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i}\right)}{\partial t}+\nabla \cdot\left[\rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i} \otimes \boldsymbol{v}_{\mathrm{d}, i}\right]-\rho_{\mathrm{d}, i} \boldsymbol{f}_{\mathrm{d}, i}=\rho_{\mathrm{d}, i} \frac{\boldsymbol{v}_{\mathrm{g}}-\boldsymbol{v}_{\mathrm{d}, i}}{T_{\mathrm{s}, i}},$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq6.png) (6)
where ρg, vg, Pg, and Eg denote the gas density, the gas velocity and gas pressure, and the total gas energy
(6)
where ρg, vg, Pg, and Eg denote the gas density, the gas velocity and gas pressure, and the total gas energy 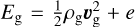 , respectively, with e=Pg(γ−1) the gas internal energy. The densities and velocities of the dust fluid i are denoted ρd,i and vd, i, respectively. I is the matrix identity. The external forces specific to each phase are denoted fg and fd, i. w is a control variable that parametrises frictional heating: w=0 turns the frictional heating off, and w=1 means that the entire dissipation is deposited into the gas. Eqs. (2)–(6) can be written in the following compact form:
, respectively, with e=Pg(γ−1) the gas internal energy. The densities and velocities of the dust fluid i are denoted ρd,i and vd, i, respectively. I is the matrix identity. The external forces specific to each phase are denoted fg and fd, i. w is a control variable that parametrises frictional heating: w=0 turns the frictional heating off, and w=1 means that the entire dissipation is deposited into the gas. Eqs. (2)–(6) can be written in the following compact form:
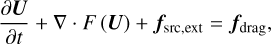 (7)
where
(7)
where
![Mathematical equation: $\boldsymbol{U} \equiv\left[\rho_{\mathrm{g}}, \rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}, E_{\mathrm{g}}, \rho_{\mathrm{d}, i}, \rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i}\right],$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq9.png) (8)
(8)
![Mathematical equation: $F(\boldsymbol{U}) \equiv\left[\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}, \rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}} \otimes \boldsymbol{v}_{\mathrm{g}}+P_{\mathrm{g}} \boldsymbol{I},\left(E_{\mathrm{g}}+P_{\mathrm{g}}\right) \boldsymbol{v}_{\mathrm{g}}, \rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i}, \rho_{\mathrm{d}, i} \boldsymbol{v}_{\mathrm{d}, i} \otimes \boldsymbol{v}_{\mathrm{d}, i}\right],$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq10.png) (9)
(9)
![Mathematical equation: $\boldsymbol{f}_{\text {src,ext}} \equiv\left[0, \rho_{\mathrm{g}} \boldsymbol{f}_{\mathrm{g}}, \rho_{\mathrm{g}} \boldsymbol{f}_{\mathrm{g}} \cdot \boldsymbol{v}_{\mathrm{g}}, 0, \rho_{\mathrm{d}, i} \boldsymbol{f}_{\mathrm{d}, i}\right],$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq11.png) (10)
and
(10)
and
![Mathematical equation: $ \begin{align*} \boldsymbol{f}_{\mathrm{drag}} \equiv\left[0, \sum_{i=1}^{N} \rho_{\mathrm{d}, i}\right. & \frac{\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}}{T_{\mathrm{s}, i}}, \sum_{i=1}^{N} \rho_{\mathrm{d}, i} \frac{\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}}{T_{\mathrm{d}, i}} \cdot \boldsymbol{v}_{\mathrm{g}} \\ & \left.+w \sum_{i=1}^{N} \rho_{\mathrm{d}, i} \frac{\left(\boldsymbol{v}_{\mathrm{d}, i}-\boldsymbol{v}_{\mathrm{g}}\right)^{2}}{T_{\mathrm{s}, i}}, 0, \rho_{\mathrm{d}, i} \frac{\boldsymbol{v}_{\mathrm{g}}-\boldsymbol{v}_{\mathrm{d}, i}}{T_{\mathrm{s}, i}}\right]. \end{align*} $](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq12.png) (11)
(11)
In Eqs. (7)-(11), U denotes the state vector of conservative variables, and F(U) is a rank-2 tensor, the rows of which are the fluxes of each component of U. fsrc,ext and fdrag denote external source terms and drag source terms.
2.2 Review of current dust-gas integrators
Equation (7) is usually solved by splitting the time step to separately integrate the transport term, the source terms, and the drag terms. Gas and dust are treated in a similar way, except for the energy equation. Drag integration requires solving the following equation:
![Mathematical equation: $\frac{\partial \tilde{\boldsymbol{U}}}{\partial t}=\left[\begin{array}{c}-\sum_{i=1}^{N} \alpha_{i}\left(\epsilon_{i} \boldsymbol{M}_{\mathrm{g}}-\boldsymbol{M}_{\mathrm{d}, i}\right) \\ \alpha_{1}\left(\epsilon_{1} \boldsymbol{M}_{\mathrm{g}}-\boldsymbol{M}_{\mathrm{d}, 1}\right) \\ \alpha_{2}\left(\epsilon_{2} \boldsymbol{M}_{\mathrm{g}}-\boldsymbol{M}_{\mathrm{d}, 2}\right) \\ \vdots \\ \alpha_{N}\left(\epsilon_{N} \boldsymbol{M}_{\mathrm{g}}-\boldsymbol{M}_{\mathrm{d}, N}\right)\end{array}\right] \equiv \tilde{\boldsymbol{f}}_{\text {drag}},$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq13.png) (12)
where
(12)
where
![Mathematical equation: $\tilde{\boldsymbol{U}} \equiv\left[\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}, \rho_{\mathrm{d}, 1} \boldsymbol{v}_{\mathrm{d}, 1}, \ldots, \rho_{\mathrm{d}, N} \boldsymbol{v}_{\mathrm{d}, N}\right]^{T}=\left[\boldsymbol{M}_{\mathrm{g}}, \boldsymbol{M}_{\mathrm{d}, 1}, \ldots, \boldsymbol{M}_{\mathrm{d}, N}\right]^{T},$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq14.png) (13)
(13)
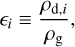 (14)
and
(14)
and
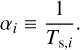 (15)
(15)
Assuming linear drag terms, Eq. (12) can be set in the form of a system of first-order ordinary differential equations,
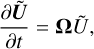 (16)
where Ω is the (N+1) x(N+1) sparse matrix, defined by
(16)
where Ω is the (N+1) x(N+1) sparse matrix, defined by
![Mathematical equation: $\boldsymbol{\Omega} \equiv\left[\begin{array}{ccccc}-\sum_{i=1}^{N} \epsilon_{i} \alpha_{i} & \alpha_{1} & \alpha_{2} & \ldots & \alpha_{N} \\ \epsilon_{1} \alpha_{1} & -\alpha_{1} & 0 & \ldots & 0 \\ \epsilon_{2} \alpha_{2} & 0 & -\alpha_{2} & \ldots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \epsilon_{N} \alpha_{N} & 0 & 0 & \ldots & -\alpha_{N}\end{array}\right].$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq18.png) (17)
(17)
Several methods have been proposed to solve Eq. (16). Benítez-Llambay et al. (2019) and Krapp & Benítez-Llambay (2020) proposed a fully implicit first-order method that involves a similar sparse matrix that can be inverted analytically with the complexity of O(N). Huang & Bai (2022) proposed several second-order methods that are explicit or implicit, where the implicit schemes involve dense matrices that are computationally expensive to invert. The diagonally implicit Runge-Kutta (DIRK) method of Krapp et al. (2024) combines the advantages of the first- and second-order fully implicit methods.
2.3 Exponential solver
2.3.1 Series methods for the matrix exponential
We chose to use the analytical solution of Eq. (16),
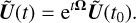 (18)
to build an implicit solver that preserves the accuracy of the scheme. The key difficulty was to maintain reasonable computational costs. Several algorithms have been proposed for the computation of the matrix exponential (Moler & Van Loan 2003). For a given matrix A, the naive approach consists of performing a Taylor expansion in the truncation order m according to
(18)
to build an implicit solver that preserves the accuracy of the scheme. The key difficulty was to maintain reasonable computational costs. Several algorithms have been proposed for the computation of the matrix exponential (Moler & Van Loan 2003). For a given matrix A, the naive approach consists of performing a Taylor expansion in the truncation order m according to
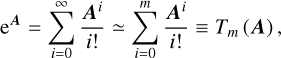 (19)
which is usually not accurate enough because it entails truncation errors (both arithmetic and series truncation) and round-off errors (Moler & Van Loan 2003). An alternative method consists of using the (p, q) Padé approximant of eA, defined by
(19)
which is usually not accurate enough because it entails truncation errors (both arithmetic and series truncation) and round-off errors (Moler & Van Loan 2003). An alternative method consists of using the (p, q) Padé approximant of eA, defined by
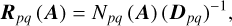 (20)
where
(20)
where
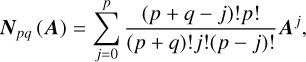 (21)
and
(21)
and
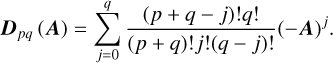 (22)
(22)
This approximation holds when Dp q(A) is not singular. This property is a priori not satisfied for all pairs (p, q). The Taylor series of order m is just a (m, 0) Padé approximant. This method provides a much better approximation for a given order than the Taylor series (see Table 1 in Moler & Van Loan 2003). The Padé approximation is also limited by its own truncation and round-off errors, however. Both algorithms can be used when ‖A‖<1 (Sastre et al. 2015).
2.3.2 Scaling and squaring method
The most widely used method for computing the matrix exponential is the so-called scaling and squaring method (Al-Mohy & Higham 2010). The method relies on the following identity:
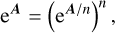 (23)
where n is a non-negative integer. It consists of computing an approximation for the exponential of the scaled matrix eA/n, and then squaring the result n times to have the approximation of eA. The scaling step is performed with a Padé or Taylor approximation, which requires that ‖A‖ is sufficiently small (i.e. ‖A‖<1) to control round-off errors.
(23)
where n is a non-negative integer. It consists of computing an approximation for the exponential of the scaled matrix eA/n, and then squaring the result n times to have the approximation of eA. The scaling step is performed with a Padé or Taylor approximation, which requires that ‖A‖ is sufficiently small (i.e. ‖A‖<1) to control round-off errors.
The scaling step is commonly performed using a Padé approximation to achieve double precision in the institute of electrical and electronics engineers (IEEE) 754 standard at lowest computational cost (Skaflestad & Wright 2009; Al-Mohy & Higham 2009; Higham 2009). This requires a matrix inversion, as shown by Eq. (20). It is possible to achieve almost similar precision without paying the cost of this matrix inversion by the Taylor series, however (Ruiz et al. 2016). The scale factor s is defined as
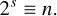 (24)
(24)
Importantly, Fasi & Higham (2019) extended these methods for arbitrary precision, which is of prime interest for our drag algorithm because the aim is to achieve the required accuracy at minimum computational cost.
Sastre et al. (2015) proposed a modified version of the Taylor-based scaling and squaring algorithm. The first modification is relative to the choice of parameters 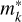 (optimal Taylor polynomial order), k* (optimal matrix product required for the Taylor polynomial evaluation), and s* (optimal squaring parameter), such that the total number of matrix products k*+s* is smaller than or equal to the number for the standard Taylor evaluation. The second modification they proposed is to neglect high-order terms of the Taylor polynomials when for the given unit round-off u the accuracy of the final result is not affected.
(optimal Taylor polynomial order), k* (optimal matrix product required for the Taylor polynomial evaluation), and s* (optimal squaring parameter), such that the total number of matrix products k*+s* is smaller than or equal to the number for the standard Taylor evaluation. The second modification they proposed is to neglect high-order terms of the Taylor polynomials when for the given unit round-off u the accuracy of the final result is not affected.
With these two modifications, they proposed four new Taylor-based scaling and squaring algorithms. Although two of the algorithms they proposed gave a comparable error to the expm routine of MATLAB (matrix exponential routine of MATLAB based on a Padé-approximation), however, we need to point out that all their algorithms are memory-bound. The reason is the need of storing a sequence of the matrix power {A, A2, \ldots, Aq}, with q a given integer known at runtime. The memory required to store the sequence of matrices for every cell in our simulation renders this method unfeasible on both GPUs and CPUs. In Sastre et al. (2015), the Taylor algorithm consisted of two parts:
A Paterson-Stockmeyer coefficient evaluation (see ALGORITHM PS-COEFF in Sastre et al. 2015), and
a Horner-Paterson-Stockmeyer evaluation of the order- m Taylor polynomial (see ALGORITHM HPS-EVAL in Sastre et al. 2015).
We merged the two algorithms to reduce the memory footprint. The algorithmic details are presented in Appendix B.
2.4 Implementation in Dyablo and Shamrock
The different drag solvers we described above are all implemented in the codes Dyablo (Delorme et al. 2025) and Shamrock (David-Cléris et al. 2025). These are two multi-GPU codes for astrophysical hydrodynamics simulations with the aim of targeting exascale supercomputers. They are both written in C++ (currently, C++17) and use MPI for the domain decomposition. For the shared memory parallelism, Dyablo uses Kokkos (Trott et al. 2022), and Shamrock uses Sycl (Group 2021). Dyablo supports Eulerian AMR grid-based method. Shamrock supports both Lagrangian smoothed particle hydrodynamics (SPH) and Eulerian adaptive-mesh-refinement(AMR) grid-based methods.
As pointed out in Sect. 2.2, Eq. (7)–(11) was solved by the splitting technique. To evolve Un from time t=tn to a new value Un+1 at t=tn+1, we first solved
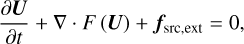 (25)
with U(tn)=Un as initial condition, to obtain an intermediate state value Ūn+1. Then, using Ūn+1 as initial condition, we solved
(25)
with U(tn)=Un as initial condition, to obtain an intermediate state value Ūn+1. Then, using Ūn+1 as initial condition, we solved
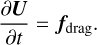 (26)
(26)
We integrated Eq. (25) using a second-order Godunov method, whereas Eq. (26) was solved by one of the different drag solvers we described in Sect. 2.2.
3 Tests and performance
In this section, we present the numerical tests we performed to validate the method. We also present a performance analysis of our exponential drag solver within both Dyablo and Shamrock.
3.1 DUSTYBOX test
In this first test, we focused on the accuracy and the robustness of our matrix exponential solver alone (i.e. without the hydrodynamical solver step). The 1D dust-gas collisions test (Benítez-Llambay et al. 2019) is a derivative of the DUSTYBOX test (Laibe & Price 2011), which consists of a system of gas and an arbitrary number of dust fluids with constant stopping times. The system evolves only under the momentum exchange between gas and dust fluids. In other words, we integrated Eq. (16) for a given initial condition Ũ0. Benítez-Llambay et al. (2019) showed that the velocity of all fluids (gas and dust) is expected to converge to an asymptotic steady-state velocity (the velocity of the centre of mass), given by
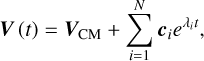 (27)
where VCM is the velocity of the centre of mass, defined as
(27)
where VCM is the velocity of the centre of mass, defined as
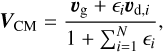 (28)
and λi<0 is obtained by solving the eigenvalue problem,
(28)
and λi<0 is obtained by solving the eigenvalue problem,
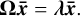 (29)
The associate vector ci is then obtained by expressing the initial conditions into the eigenvectors.
(29)
The associate vector ci is then obtained by expressing the initial conditions into the eigenvectors.
We performed tests B (stiff case with short stopping times) and C (stiff case with high dust-to-gas ratios) described by Huang & Bai (2022) for our EXP1 and different drag solvers of reference. In Table 1 we recall the initial conditions, the eigenvalues, and the coefficients for the analytical solution we used.
Figure 1 shows the evolution of velocities for Collisions tests B and C at a fixed time step of 0.005 and 0.05, respectively, for our EXP integrator (and others, presented in Sect. 2.2). In both cases, the numerical velocity converges to the asymptotic steady-state velocity, and it matches the analytical solution well.
To quantify how well our matrix exponential solver performed in comparison with the drag solvers used in the literature, we performed a convergence analysis in time where the error was obtained following Eq.(40) of Krapp et al. (2024),
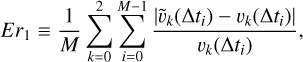 (30)
with v and ṽ denoting exact and numerical quantities, respectively. Here, Δ ti is the time step, M is the number of time steps during numerical integration, and k=0, 1, 2 is the index for the gas and dust fluids. Starting at Δ t=10−4(10−3) for test B (for test C), we doubled the time step until we reached a final time of tfinal=10−1 (2) for test B and (test C). Here and in the remainder of the paper, we refer to RK1 as the first-order implicit drag solver, to RK2 as the second-order implicit Runge-Kutta solver, to MDIRK- and MDIRK+ as the versions of the multi-fluid second-order diagonally implicit Runge-Kutta solver, and to EXP as the exponential solver.
(30)
with v and ṽ denoting exact and numerical quantities, respectively. Here, Δ ti is the time step, M is the number of time steps during numerical integration, and k=0, 1, 2 is the index for the gas and dust fluids. Starting at Δ t=10−4(10−3) for test B (for test C), we doubled the time step until we reached a final time of tfinal=10−1 (2) for test B and (test C). Here and in the remainder of the paper, we refer to RK1 as the first-order implicit drag solver, to RK2 as the second-order implicit Runge-Kutta solver, to MDIRK- and MDIRK+ as the versions of the multi-fluid second-order diagonally implicit Runge-Kutta solver, and to EXP as the exponential solver.
Figure 2 shows the evolution of error E r 1 as a function of the time step Δ ti. The RK1 and MDIRK+ solvers are first order, and the RK2 and MDIRK- solvers are second order. On the other hand, the error of the EXP matrix exponential solver remains almost constant around 10−8, regardless of Δ t. This property arises because the choice of the optimal Taylor polynomial order 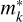 and the optimal squaring parameter was made such that the forward error was smaller than the unit round-off u (we set its value to u=2−53). This indicates that the EXP method is not affected by truncation errors and provides an accurate solution for the drag even at large time steps.
and the optimal squaring parameter was made such that the forward error was smaller than the unit round-off u (we set its value to u=2−53). This indicates that the EXP method is not affected by truncation errors and provides an accurate solution for the drag even at large time steps.
To test the robustness of the matrix exponential solver, we also performed a collision test with 20 dust fluids. The stopping time Ts,i was uniformly spaced in log scale between Ts, min=10−3 and Ts,max=10. The dust-to-gas ratios were given by
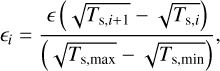 (31)
such that
(31)
such that 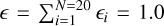 . Figure 3 shows the evolution of the gas and each of the 20 fluid velocities. Even in stiff regimes (short stopping times), the matrix exponential solver still performed well and provided errors of ∼ 10−7 for all dust fluids. Suppose for the RK1 scheme that E r1 ∝ Δ t and the simulation time denotes
. Figure 3 shows the evolution of the gas and each of the 20 fluid velocities. Even in stiff regimes (short stopping times), the matrix exponential solver still performed well and provided errors of ∼ 10−7 for all dust fluids. Suppose for the RK1 scheme that E r1 ∝ Δ t and the simulation time denotes 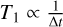 , then to achieve an error of ∼ 10−7, the RK1 scheme requires ∼ 104(∼ 55) more time on a Collisions test with two (20) dust fluids.
, then to achieve an error of ∼ 10−7, the RK1 scheme requires ∼ 104(∼ 55) more time on a Collisions test with two (20) dust fluids.
Initial conditions (left), eigenvalues, and coefficients for the analytical solution of the collision tests (right).
 |
Fig. 1 Collisions test. Evolution of the gas and dust velocities (from top to bottom) for tests B and C (left and right columns, respectively). The dot-dashed black line represents the analytical solution. The other lines compare the numerical solutions obtained with the EXP integrator (orange) with other integrators, namely the first-order implicit RK1 (blue), the second-order fully implicit RK2 (purple), the MDIRK method with |

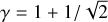
 |
Fig. 2 Collisions tests B (left) and C (right). The evolution of error E r1 is defined by Eq. (30) for the EXP (orange) and other integrators: RK1 (blue), RK2 (purple), MKDIRK- (green), and MKDIRK+ (red). |
3.2 DUSTYWAVE test
The Dustywave test consisted in following the evolution of linear sound waves in a mixture of gas and dust. Because the dust phase is assumed to be pressure-less, it cannot support sound waves. The gas sound wave propagates with a modified sound speed in the mixture, however, because of gas pressure and momentum exchange. This test served as a benchmark for the coupling between the transport and drag steps by solving Eqs. (2)-(6). The analytical solution for one gas and one dust fluid was proposed by Laibe & Price (2012a) and was extended to an arbitrary number of dust fluids by Laibe & Price (2014).
We reproduced the 1D test for one gas fluid with one and four dust fluids. The setup consisted of an isothermal sound wave (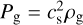 , with cs=1) in a periodic box of size L=1 and zero background velocity. The perturbation equation writes
, with cs=1) in a periodic box of size L=1 and zero background velocity. The perturbation equation writes
![Mathematical equation: $\delta f=A[\operatorname{Re}(\delta \hat{f}) \cos (k x)-\operatorname{Im}(\delta \hat{f}) \sin (k x)],$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq41.png) (32)
with A a small amplitude to ensure linearity (10−4 cs and
(32)
with A a small amplitude to ensure linearity (10−4 cs and 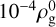 for velocity and density perturbations), and with the wavenumber
for velocity and density perturbations), and with the wavenumber 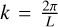 . The test was performed on a uniform grid of Ncells= 1283.
. The test was performed on a uniform grid of Ncells= 1283.
The initial background densities, perturbation amplitudes, and stopping were taken from Table 2 of Benítez-Llambay et al. (2019).
Figure 4 shows the evolution of the normalised velocities 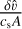 and densities
and densities 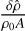 for two and five dust fluids, respectively. The numerical solutions recover the analytical solutions well (a few 0.1−1%), which indicates a good coupling of the drag solver and the transport step. We additionally studied the convergence in space of the scheme (transport and drag together) by comparing the results with the RK1 solver, using a small time step Δ t=10−4 such that the influence of the time error was minimised. For the transport step, we used a second-order MUSCL-Hancock scheme with the Minmod slope limiter. To compute the error, we used Eq. (46) from Krapp et al. (2024) as follows:
for two and five dust fluids, respectively. The numerical solutions recover the analytical solutions well (a few 0.1−1%), which indicates a good coupling of the drag solver and the transport step. We additionally studied the convergence in space of the scheme (transport and drag together) by comparing the results with the RK1 solver, using a small time step Δ t=10−4 such that the influence of the time error was minimised. For the transport step, we used a second-order MUSCL-Hancock scheme with the Minmod slope limiter. To compute the error, we used Eq. (46) from Krapp et al. (2024) as follows:
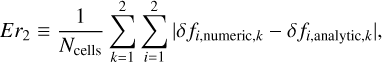 (33)
with k and i the indices of the fluid and the fields (velocity and density), respectively. The lower left panel of Fig. 4 shows that the scheme has second-order accuracy in space, which is consistent with the order of the transport scheme we used. As the resolution increases, the EXP solver gives a better accuracy than the RK1 solver by a moderate factor.
(33)
with k and i the indices of the fluid and the fields (velocity and density), respectively. The lower left panel of Fig. 4 shows that the scheme has second-order accuracy in space, which is consistent with the order of the transport scheme we used. As the resolution increases, the EXP solver gives a better accuracy than the RK1 solver by a moderate factor.
 |
Fig. 3 Evolution of the gas and dust velocities for a Collisions test with 20 dust fluids obtained with the EXP solver and compared to the analytical solution given by Eq. (27) (dashed black lines). For the first five dust species, their stopping time is short, such that they are strongly coupled to the gas. We therefore chose to plot the first and the fifth species. In addition to the 6th dust species, we chose to skip every second fluid from the 10th to the 20th dust species. |
 |
Fig. 4 Dustywave test. Evolution of normalised densities (upper panels) and velocities (lower panels) for one (left panel) and four dust fluids (right panel). The dashed black lines correspond to the analytical solution. The other markers and colours represent the numerical results obtained with the EXP algorithm. We additionally plot the L1 error given by Eq. (33) for the one-dust fluid case as an inset in the bottom left panel using a fixed time step of Δ t=10−4 for EXP and RK1. |
3.3 DUSTYSHOCK test
The dust-gas mixture shock test is a canonical benchmarking problem to test the robustness and accuracy of numerical codes for dusty gas. The steady-state J-type shock solution (when the shock speed exceeds the signal speed) in the case of a one-dust fluid, proposed by Lehmann & Wardle (2018), was extended to an arbitrary number of dust fluids by Benítez-Llambay et al. (2019). The left state is given by
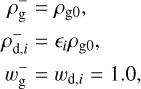 (34)
and the asymptotic right states are given by
(34)
and the asymptotic right states are given by
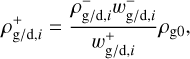 (35)
where wg/d, i=vg/d, i/vs, vs is the shock velocity, and ℳ=vs/cs is the Mach number. Following the same setup as in Sect. 3.3.2 from Benítez-Llambay et al. (2019), we performed the two-fluid and five-fluid tests. We list the initial conditions for the two-fluid and four-fluid tests below,
(35)
where wg/d, i=vg/d, i/vs, vs is the shock velocity, and ℳ=vs/cs is the Mach number. Following the same setup as in Sect. 3.3.2 from Benítez-Llambay et al. (2019), we performed the two-fluid and five-fluid tests. We list the initial conditions for the two-fluid and four-fluid tests below,
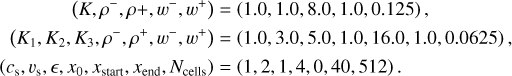 (36)
x0 is the initial jump position, and we used the zero-gradient boundary condition. We used an HLLE Riemann solver for the gas and the upwind solver of Huang & Bai (2022) for the dust. We used the van Leer slope limiter.
(36)
x0 is the initial jump position, and we used the zero-gradient boundary condition. We used an HLLE Riemann solver for the gas and the upwind solver of Huang & Bai (2022) for the dust. We used the van Leer slope limiter.
Figure 5 shows the normalised velocities and densities for gas and for one- (first two panels) and three- (last two panels) dust fluids at t=500.
The good agreement between the analytical and numerical solutions (∼ 0.1−1%) shows that our drag solver is correctly coupled to the transport step in a challenging regime.
3.4 Performance
We report the performance of our EXP algorithm on GPUs by performing the Dustywave test with various numbers of dust fluids. Following the same procedure as in Sect. (3.2), we generated uniform stopping times, computed the dust-to-gas ratio with Eq. (31), solved the dispersion relation, and computed the associated eigenvectors (see Eq. (45)–(48) in Benítez-Llambay et al. 2019). The tests were performed on a NVIDIA DGX station with four A100 GPUs and an AMD 7742 CPU (64 cores, 2.25−3.4 GHz). By default, we used Ncells=643 and integrated until t=2. Profiling consisted in measuring the execution time of the relevant kernels using the tools Nsight compute and Nsight system of the NVIDIA Nsight developer tools suit. Although absolute performance is expected to improve with future hardware advancements and potential optimisation strategies, these tests provide useful estimates of the current tractability of the EXP algorithm to astrophysical simulations.
In the Dyablo code, the matrices required for the Taylor evaluation step are handled with the Kokkos array. These are static arrays, which implies that the code must be recompiled whenever the number of dust fluids changes. Because each cell needs to solve the drag equation, the cells of the overall grid are divided into blocks. Within each block, a parallel_for execution policy is applied in conjunction with a RangePolicy with a length equal to the block size, which allows each cell to integrate the drag equation. In the Shamrock code, the matrices are handled using mdspan, which are dynamic arrays that allow adjusting the number of dust fluids at runtime without recompilation. Within Shamrock, we experimented with two implementation strategies. In the first implementation, mdspan arrays were attached to the device or global memory, and we used a basic data-parallel kernel. In the second implementation, we used ND-Range data-parallel kernels, where the number of work-items2 per work-group3 is computed with respect to the size of the shared memory available on the device and the number of dust fluids. In this case, mdspan arrays were directly attached to the local memory of the work-group.
Figure 6 shows the time per cell (top panels) and the relative cost of the drag kernels per time step (bottom panels) for both codes as function of the number of dust fluids N for a resolution of Ncells=643. For reference, the computational cost of the RK1 solver scales as O(N), as expected, regardless of the implementation. For the EXP solver, the computational cost within Dyablo initially scales as O(N2) up to 8 fluids and then becomes dominated by matrix-matrix operations. This results in a time complexity of O(N3). Within Shamrock, the local memory implementation of the EXP solver offers a slight performance improvement over the global memory implementation for small numbers of fluids (e.g. a factor of 10 for N=4). As the number of fluids and thus the matrix sizes increases, the size of the work-groups decreases. Hence, the local and global memory implementations both have nearly identical execution times. One possible path for improvement might be to use hierarchical dataparallel kernel in which a work-group will compute the matrix exponential instead of assigning this task to a single thread, as is currently done. Furthermore, within Dyablo, the EXP solver takes 55% of the overall time steps for up to 16 fluids, while with Shamrock, the drag time step with the same number of fluids is about the same as the hydro time step in both implementations. For instance, for up to 8 fluids, the EXP solver in Dyablo takes less than 8%, whereas the local memory version in Shamrock is slightly lower than 50%.
Additionally, we analysed the effect of the resolution on the measured performances. Figure 7 shows the time per cell (top panels) and the relative cost of the drag solver per time step (bottom panels) as a function of the number of dust fluids for Ncells=2563 (left panels) and Ncells=643 (right panels) cells (Dyablo code). We observe the same performance profile as for Ncells=643, where for EXP, we have a time complexity of 𝒪(N2) and ℴO(N3) for N ≤ 8 and N ≥ 9, respectively. The computational cost with N=8(∼eq 9.7 × 10−9 s) multiplied by about 4.5 when moving to N=9(∼eq 4.4 × 10−8 s) clearly shows the change in order in the time complexity. With the Nsight Compute profiler, both kernels have a large number of registers (the fastest memory storage area with a streaming multiprocessor) per thread, 256 each. There are 0.18 and 0.09 eligible warps (groups of threads that are scheduled together and are executed in parallel) per cycle for N=8 and N=9 fluids, respectively, on average, however. For each warp, the latency (the amount of time wasted doing nothing) is 12.20 and 25.02 cycles on average between two consecutive executed instructions for 8 and 9 fluids, respectively. This shows that the actual implementation of the exponential solver is over using registers per thread, and as a result, it causes a low occupancy (a measure of the efficiency of the GPU computing resources). We provide the performances for the RK1 solver, which relies on an analytical prescription, for reference.
The above analyses suggest optimisation paths to make the EXP algorithm more competitive. A reduced pressure on the registers might lead to a better occupancy. Using several threads (e.g. a thread block) by matrix operation instead of a single thread, as is done currently, is worth considering. This might be done, for example, by using hierarchical parallelism. Finally, future GPUs with larger bandwidth and shared memory capacity (notably for the implementation in local memory) are also expected to reduce the latency of the algorithm.
 |
Fig. 5 Dustyshock test. Normalised velocities (first and third panels for one- and three-dust fluid(s), respectively) and density (second and fourth panels for one- and three-dust fluid(s), respectively). The dashed lines show the analytical solutions, and the circle markers show the numerical results we obtained with the EXP algorithm. With the EXP solver, the shock is captured within one to two cells. |
 |
Fig. 6 Performance of the EXP drag solver as function of the number of fluids (gas and dust fluids) on one A100 GPU obtained with an implementation with a moderate level of optimisation in the Dyablo (left) and the Shamrock (right) codes. We provide the results obtained with the RK1 algorithm for comparison. The tests with Dyablo used static arrays and global memory. The tests with Shamrock used dynamical arrays and either the local (EXP-LOC) or the global (EXP-GLB) memory. For 8-16 dust fluids, the computational cost of the drag step is ∼ 10−100% of the hydro step, which makes it usable for astrophysical applications. |
 |
Fig. 7 Performances of the EXP drag solver on a Dustywave test performed on a A100 GPU using Dyablo for Ncells=643 (left) and Ncells=2563 cells for 1 to 15 dust fluids, respectively. The top panels show the time per cell for the drag step. The bottom panels show the relative cost of the drag step with respect to the total time step (hydro+drag) per time step. |
4 Conclusion
We have presented and studied the EXP algorithm that we designed to compute the momentum exchange for dust-gas polydisperse mixtures very accurately on GPU architectures. The algorithm is based on a Taylor-based scaling and squaring matrix exponential computation. It was implemented in two different codes, namely Dyablo and Shamrock, using standard moderate optimisation strategies, and it was benchmarked on standard drag-dominated and hydro-dominated tests. The performance measurements showed that the cost of the drag time step does not significantly affect the code performance for up to ∼ 8−16 dust fluids.
The method is therefore suitable for astrophysical simulations even with growth and fragmentation as long as high-order solvers are used (Lombart & Laibe 2021; Lombart et al. 2022, 2024). The algorithm can also be applied for linear or linearised source terms, such as in radiative transfer and chemistry.
Data availability
The Dyablo code and the relevant sources are publicly distributed on Github (https://github.com/Dyablo-HPC/Dyablo). The Shamrock code and the relevant sources are publicly distributed on Github under the open source CeCILL v2.1 license (https://github.com/Shamrock-code/Shamrock).
Acknowledgements
We thank T. David--Cléris, A. Durocher, M. Delorme, G. Lesur, U. Lebreuilly, G. Verrier, P. Hennebelle, F. Lovascio for useful comments and discussions, P. Huang for helping with the RK2 test, E. Quemener and the Centre Blaise Pascal de Simulation et de Modélisation Numérique for support on the benchmarks, the ENS de Lyon for partly funding the DGX Nvidia Workstation and the electric costs associated with local simulations. We acknowledge support from the WP 5.1 MHD@Exascale (ANR-22-EXOR-0015) of the Programme et équipements prioritaires de recherche (PEPR) Origins (PI: A. Morbidelli). The SHAMROCK code follows the developments of the WP 5.1 of PEPR Origins. We acknowledge funding from the ERC CoG project PODCAST No. 864965. BC also acknowledges the funding from program ANR-20-CE49-0006 (ANR DISKBUILD) and funding from the European High Performance Computing Joint Undertaking (JU) under grant agreement No. 101093441, supported by contributions from multiple member states, including ANR (ANR-23-EHPC-0007-02). We thank the referee whose comments, questions and suggestions help to improve the quality of the paper.
Appendix A Drag integrators
To solve for Eqs. (7)–(11), we first integrated the transport and the source terms between the steps (n) and 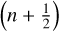 . We then solved for
. We then solved for
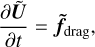 (A.1)
where
(A.1)
where
![Mathematical equation: $\tilde{\boldsymbol{U}} \equiv\left[\rho_{\mathrm{g}} \boldsymbol{v}_{\mathrm{g}}, \rho_{\mathrm{d}, 1} \boldsymbol{v}_{\mathrm{d}, 1}, \ldots, \rho_{\mathrm{d}, N} \boldsymbol{v}_{\mathrm{d}, N}\right]^{T}=\left[\boldsymbol{M}_{\mathrm{g}}, \boldsymbol{M}_{\mathrm{d}, 1}, \ldots, \boldsymbol{M}_{\mathrm{d}, N}\right]^{T},$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq52.png) (A.2)
and f̃drag is defined by Eq. (12), between steps
(A.2)
and f̃drag is defined by Eq. (12), between steps 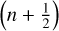 and (n+1). For IMEX (Implicit-Explicit)-like schemes, momenta terms should be modified accordingly for consistency. In the following, we review the different algorithms used to solve Eqs. (A.1)–(A.2).
and (n+1). For IMEX (Implicit-Explicit)-like schemes, momenta terms should be modified accordingly for consistency. In the following, we review the different algorithms used to solve Eqs. (A.1)–(A.2).
Appendix A.1 General first-order implicit RK1
Denoting Δ Ũ=Ũ(n+1)−Ũ(n), and integrating Eq. (A.1) from t=tn to t=tn+1 provides the first-order implicit RK1 method and
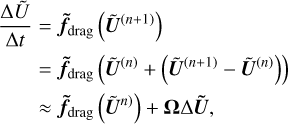 (A.3)
where the Jacobian matrix Ω is given by Eq. (17). Corrections for IMEX-like schemes are taken into account by replacing f̃drag in Eq. (A.1) by f̃ given by
(A.3)
where the Jacobian matrix Ω is given by Eq. (17). Corrections for IMEX-like schemes are taken into account by replacing f̃drag in Eq. (A.1) by f̃ given by
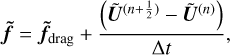 (A.4)
where Ũ(n), Ũ(n+½) denote the momenta vectors before and after the hydrodynamic steps respectively. As such, one solves for
(A.4)
where Ũ(n), Ũ(n+½) denote the momenta vectors before and after the hydrodynamic steps respectively. As such, one solves for
![Mathematical equation: $\tilde{\boldsymbol{U}}^{(n+1)}-\tilde{\boldsymbol{U}}^{(n)}=(\boldsymbol{I}-\Delta t \boldsymbol{\Omega})^{-1}\left[\Delta t \tilde{\boldsymbol{f}}_{\text {drag}}\left(\tilde{\boldsymbol{U}}^{(n)}\right)+\left(\tilde{\boldsymbol{U}}^{\left(n+\frac{1}{2}\right)}-\tilde{\boldsymbol{U}}^{(n)}\right)\right].$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq56.png) (A.5)
(A.5)
For N dust fluids, Eq. (A.5) can be solved using direct methods with a time complexity of O(N3) such as PLU decomposition. This algorithm was used by Benítez-Llambay et al. (2019), only for testing purposes.
Appendix A.2 Implicit RK1 with analytical solution
A more effective alternative of complexity O(N) consists of using an analytical solution of the sparse matrix Eq. (A.5). For a given vector b=(b0, b1, …, bN), we aim to find the vector q=(q0, q1, …, qN) such that
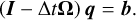 (A.6)
With some algebra
(A.6)
With some algebra
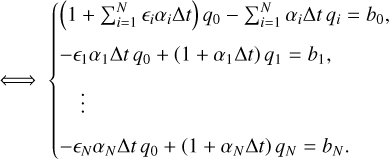 (A.7)
(A.7)
From lines 2−(N+1) of Eq. (A.7) we have for i=1, …, N
![Mathematical equation: $q_{i}=\frac{1}{\left(1+\alpha_{i} \Delta t\right)}\left[b_{i}+\left(\epsilon_{i} \alpha_{i} \Delta t\right) q_{0}\right].$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq59.png) (A.8)
Replacing Eq. (A.8) back into the first line of Eq. (A.7) gives
(A.8)
Replacing Eq. (A.8) back into the first line of Eq. (A.7) gives
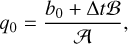 (A.9)
with
(A.9)
with 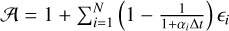 and
and 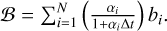 .
.
Appendix A.3 Second-order implicit RK2
The second-order implicit RK2 drag solver proposed by Huang & Bai (2022) is consistent with the two-stage second-order Total Variation Diminishing (TVD) Runge-Kutta scheme of Gottlieb & Shu (1998). The first stage of the drag integration step consists of a first-order implicit RK1. The second stage of the drag integration step is described as follows
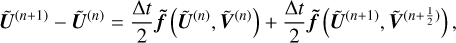 (A.10)
where
(A.10)
where
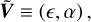 (A.11)
with ε=[ε1, ·s, εn] and α=[α1, ·s, αn].
(A.11)
with ε=[ε1, ·s, εn] and α=[α1, ·s, αn].
From a Taylor expansion in ‖Ω‖ Δ t, we have
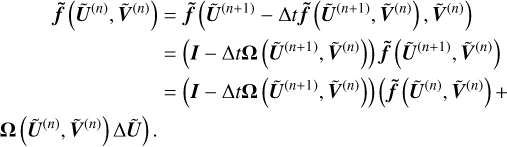 (A.12)
Similarly,
(A.12)
Similarly,
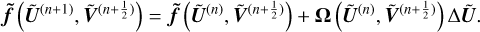 (A.13)
(A.13)
Replacing Eqs. (A.12)–(A.13) into Eq. (A.10) gives
![Mathematical equation: $ \begin{array}{r} \Delta \tilde{\boldsymbol{U}}=\frac{\Delta t}{2} \boldsymbol{\Lambda}^{-1}\left[\tilde{\boldsymbol{f}}\left(\tilde{\boldsymbol{U}}^{(n)}, \tilde{\boldsymbol{V}}^{\left(n+\frac{1}{2}\right)}\right)+\left(\boldsymbol{I}-\Delta t \boldsymbol{\Omega}\left(\tilde{\boldsymbol{U}}^{(n+1)}, \tilde{\boldsymbol{V}}^{(n)}\right)\right)\right.\\ \left.\tilde{\boldsymbol{f}}\left(\tilde{\boldsymbol{U}}^{(n)}, \tilde{\boldsymbol{V}}^{(n)}\right)\right] \end{array} $](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq67.png) (A.14)
where
(A.14)
where
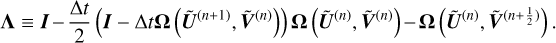 (A.15)
The inverse of Λ is obtained by a PLU decomposition.
(A.15)
The inverse of Λ is obtained by a PLU decomposition.
Appendix A.4 Second-order diagonally implicit Runge-Kutta MDIRK
As an alternative to operator splitting, Krapp et al. (2024) suggest combining the explicit and implicit terms in a single time step when integrating from a step n to a step n+1, as
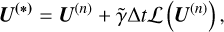 (A.16)
(A.16)
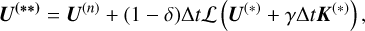 (A.17)
(A.17)
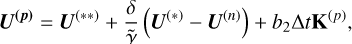 (A.18)
(A.18)
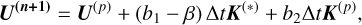 (A.19)
where
(A.19)
where
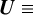 (A.20)
is defined for both gas and dust. The operator
(A.20)
is defined for both gas and dust. The operator
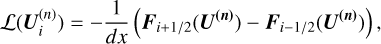 (A.21)
corresponds to the transport step. It returns flux divergence as described by Eq. (A.21) and
(A.21)
corresponds to the transport step. It returns flux divergence as described by Eq. (A.21) and 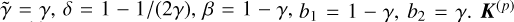 and K(*) are obtained by solving the system
and K(*) are obtained by solving the system
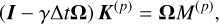 (A.22)
(A.22)
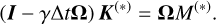 (A.23)
where
(A.23)
where
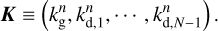 (A.24)
(A.24)
The resolution of Eqs. (A.22)–(A.24) can be performed analytically, similarly to Appendix A.2.
Appendix B Modified Taylor-based scaling and squaring algorithm
We explain the different steps involved in the modified Taylor-based scaling and squaring algorithm of Sastre et al. (2015) described in Sect. 2.3.1.
Appendix B.1 Backward error analysis
The choice of polynomial order m and the scale factor s is based on a backward error analysis, given by the following theorem (Sastre et al. 2015).
Theorem 1. Let the matrix exponential Taylor approximation Tm(A) of a given matrix A as defined by Eq. (19), satisfy
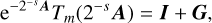 (B.1)
with ‖G‖<1. Then
(B.1)
with ‖G‖<1. Then
![Mathematical equation: $\left[T_{m}\left(2^{-s} \boldsymbol{A}\right)\right]^{2 s}=\mathrm{e}^{\boldsymbol{A}+\boldsymbol{E}},$](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq80.png) (B.2)
where E commutes with A and
(B.2)
where E commutes with A and
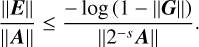 (B.3)
(B.3)
The residue E quantifies the error between the exact exponential of the matrix and its numerical approximation. To improve the estimate, one should minimize the right-hand side of Eq. (B.3). This term can be expressed as a function of θ ≡ ‖2−s A‖. For this purpose, define the function
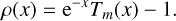 (B.4)
One has
(B.4)
One has
![Mathematical equation: $ \begin{align*} \rho(x) & =-\mathrm{e}^{-x}\left[\mathrm{e}^{x}-T_{m}(x)\right] \\ & =-\mathrm{e}^{-x}\left(\sum_{j \geq m+1} \frac{x^{j}}{j!}\right) \\ & =\left(\sum_{j \geq 0} \frac{(-1) x^{j}}{j!}\right)\left(\sum_{j \geq m+1} \frac{x^{j}}{j!}\right)\\ & =\sum_{j \geq m+1} c_{j} x^{j} \end{align*} $](/articles/aa/full_html/2025/11/aa56530-25/aa56530-25-eq83.png) (B.5)
From Eq. (B.1),
(B.5)
From Eq. (B.1),
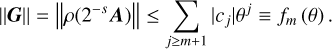 (B.6)
(B.6)
Combining Eqs. (B.3) and (B.3) gives the bound
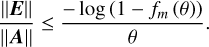 (B.7)
Using a zero-finder tool (symbolic Math Toolbox of MATLAB), we determined the highest value of θ ≡‖2−s A‖ for a range of m such that the bound is at most equal to u=2−53 (the unit round-off in IEEE double precision arithmetic).
(B.7)
Using a zero-finder tool (symbolic Math Toolbox of MATLAB), we determined the highest value of θ ≡‖2−s A‖ for a range of m such that the bound is at most equal to u=2−53 (the unit round-off in IEEE double precision arithmetic).
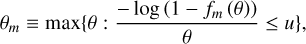 (B.8)
u=2−53 being the unit round-off in IEEE double precision arithmetic. One can take another value depending on the desired accuracy : 2−11, 2−24, 2−113 and 2−237 for half, single, quadruple and octuple precision arithmetic respectively.
(B.8)
u=2−53 being the unit round-off in IEEE double precision arithmetic. One can take another value depending on the desired accuracy : 2−11, 2−24, 2−113 and 2−237 for half, single, quadruple and octuple precision arithmetic respectively.
Appendix B.2 Numerical cost
In the evaluation step, the matrix Tm(2−s A) is calculated from Eq. (B.1). The matrix polynomial is computed with the Horner-Paterson-Stockmeyer method to minimize the number of matrix products involved (Higham 2005). In the rest of the paper we used
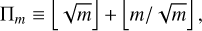 (B.9)
the optimal number of matrix multiplications in the scaling phase with a Taylor approximation of order m, where ⌊ x⌋ denotes the integer part of the real number x. One defines the scaling factor s by
(B.9)
the optimal number of matrix multiplications in the scaling phase with a Taylor approximation of order m, where ⌊ x⌋ denotes the integer part of the real number x. One defines the scaling factor s by
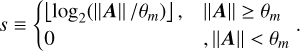 (B.10)
(B.10)
The total cost in terms of matrix multiplications to compute the order- m Taylor-based matrix exponential approximant is (Higham 2005)
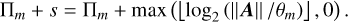 (B.11)
The optimal truncate order of the Taylor polynomial is the one that minimizes the quantity Πm+s. For ‖A‖ ≥ θm, the optimal m is such that Γm=Πm−log2(θm) is the minimum cost, since ‖A‖ does not depend on m.
(B.11)
The optimal truncate order of the Taylor polynomial is the one that minimizes the quantity Πm+s. For ‖A‖ ≥ θm, the optimal m is such that Γm=Πm−log2(θm) is the minimum cost, since ‖A‖ does not depend on m.
Precomputed parameters for Taylor-based scaling and squaring algorithm for u=2−53. In each row from left to right we have respectively the number of matrix product in the scaling phase k, the Taylor series polynomial order mk, the Horner-Paterson-Stockmeyer parameters qk and rk, and the number of matrix product Πmk.
Appendix B.3 First modification for choosing m and s
For a maximum number K of matrix product in the scaling step, we are looking for k* (optimal number of matrix product), m* (optimal Taylor polynomial order associated with k*) and s* (optimal scale factor). The total cost is then k*+s*.
The algorithm 1 presents the different strategy to choose the optimal order m* and the optimal scale factor s*. The algorithm 1 with option 0 is the standard algorithm to choose m* and s*. The first modification proposed by Sastre et al. is to reduce the total cost (k*+s*) in some cases (option 1 and option 2 in algorithm 1). Option 1 involves decreasing the number of matrix products by one, while option 2 involves the cost of additional squaring to select k*<K so that the overall cost is less than one given by option 1.
The high number of branching logic in this algorithm is subject to a high rate of branch divergence on GPUs. So, we rewrote algorithm 1 for option 2 to reduce the number of if-else statements, and then reduce branch divergence. The pseudo-code for the new algorithm is presented in algorithm. 2.
Appendix B.4 Second modification
To evaluate the matrix polynomial of m order in Eq. (19), the Paterson-Stockmeyer method (Paterson & Stockmeyer 1973) consists of choosing an integer q<m and writing the matrix polynomial as a polynomial of degree 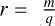 in Aq, such that
in Aq, such that
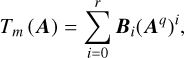 (B.12)
where Bi, i=0, …, r are matrix polynomials of degrees q
(B.12)
where Bi, i=0, …, r are matrix polynomials of degrees q
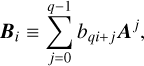 (B.13)
and
(B.13)
and
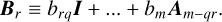 (B.14)
(B.14)
The algorithm 3 presents the procedure for evaluating the Paterson-Stockmeyer coefficients r{Bk}.
Evaluating the matrix polynomial from Eq. (B.12) using the Paterson-Stockmeyer algorithm in combination with the Horner
input : option :=0, 1, or 2;
K maximum number of matrix multiplications allowed in scaling phase;
{mk} and {θmk} from table B.1
output : k*, m*, and s*.
:
m*=mK
k*=K
ŝ}=⌈log2(‖A‖/θmK)⌉ if (‖A‖ ≤ θmK) then
s*=0 ; ŝ=0
for (k=1: K) do
if (‖A‖ ≤ θmk) then
m*=mk
k*=k
break
end
end
if option =2 then
if (k ≥ 8 and ‖A‖ ≤ 2 θmk−2) then
k*=k-2
m*=mk*
s*=1;
else if (k=9 and ‖A‖ ≤ 4 θmk−3) then
k*=k−3
m*=mk
s*=2
end
else
ŝ=⌊log2(‖A‖/θmK)⌋
s*=ŝ
if option >0 then
if K ≥ 7 and 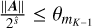 then
then
k*=K-1
m*=mk*
else if option = 2 then
if K ≥ 8 and 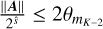 then
then
k*=K-2
m*=mk*
s*=ŝ+1
else if K=9 and 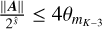 then
then
k*=K-3
m*=mk*
s*=ŝ+2
end
end
technique reduces the number of matrix products (Higham 2005). It is called the Horner-Paterson-Stockmeyer method. Equation (B.14) shows that when q divides m, one has Br=bm I. The values of q are given in the third column of table B.1. And mk+1=mk+qk. Thus, a reduction of the number of matrix products by 1 reduces the order of the Taylor polynomial by qk. Based on this remark, when the inequality
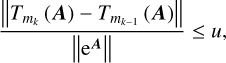 (B.15)
holds, Sastre et al. proposed to neglect the q highest terms in Tmk(A). This condition is verified by performing a numerical
(B.15)
holds, Sastre et al. proposed to neglect the q highest terms in Tmk(A). This condition is verified by performing a numerical
input : K maximum number of matrix multiplications allowed in scaling phase;
{mk} and {θmk} from table B.1
output : k*, m*, and s*.
:
m*=mK
k*=K
ŝ=⌈max (log2(‖A‖/θmK), 0)⌉
s*=0
cond = FALSE
for (k=1: K) and NOT cond do
cond =‖A‖ ≤ min (θmk, θmK)
m*=cond * mk+(1-cond) * m*
k*= cond * k+(1− cond) * k*
end
k̂=min (k, K)
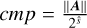
v1=[(k̂ ≥ 7) and (cmp ≤ θmk̂−1)]
v2=[(k̂ ≥ 8) and (c m p ≤ 2 * θmk̂−2)] * 2
v3=[(k̂ ≥ 9) and (c m p ≤ 4 * θmk̂−3)] * 3
v=max (v 1, v 2, v 3)
if v=v1 then
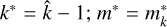
else if v=v2 then
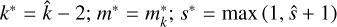
else if v=v3 then
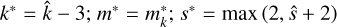
input : q ; r;
{Aj=Aj}, j=1: q;
bi=(1)i/i!, i=0: q r;
output : {Bi}, i=0: r−1
:
for k=0: r−1 do
Bk=0
for j=1: q do
Bk=Bk+bq k+j Aj
end
end
test, which consists of checking if the inequality
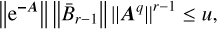 (B.16)
is satisfied. To do so, one estimates a bound for ‖e−A‖ according to
(B.16)
is satisfied. To do so, one estimates a bound for ‖e−A‖ according to
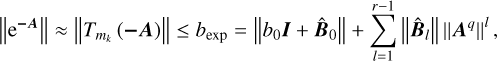 (B.17)
where
(B.17)
where 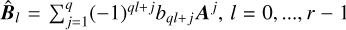 . The condition given by Eq. (B.16) can therefore be replaced in practice by
. The condition given by Eq. (B.16) can therefore be replaced in practice by
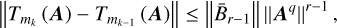 (B.18)
from Eq. (B.16). The numerical procedure to get bexp the bound of ‖e−A‖ is detailed in algorithm 8.
(B.18)
from Eq. (B.16). The numerical procedure to get bexp the bound of ‖e−A‖ is detailed in algorithm 8.
input : q ; r;
{Aj=Aj}, j=1: q;
bi=(−1)i/i!, i=0: q r.
output : bexp
:
compute {B̂l}, l=0: r−1 → Algo 2
bexp=‖B̂r-1‖
for l=r−1:−1: 2 do
bexp=‖B̂r−1‖+‖Aq‖ × bexp
end
bexp=‖b0 I+B̂0‖+‖Aq‖ × bexp
Algorithm 5 presents the Horner-Paterson-Stockmeyer procedure to evaluate the Taylor polynomial or order m during the scaling phase with the bound performance test to reduce the number of matrix products.
input : q ; r;
{Aj=Aj}, j=1: q;
bi=(1)i/i!, i=0: q r;
{B̄l}, l=0: r−1;
u.
output : F=Tm(A)
:
F=B̄r−1
for j=r−1:−1:1 do
if (bexp‖F‖‖Aq‖j ≤ u) then
F=B̄j−1
else
F=B̄j−1+Aq × F
end
end
F=F+b0 I
Together, the two modifications are resumed in the algorithm 6.
As mentioned in Sect. 2.3.2, algorithm 9 shows the new algorithm we proposed, which combines algorithms 3 and 5 (without bound tests) together.
input : A, K, u
output : An approximation of e(A)
:
Select optimal order of Taylor polynomial m* and
optimal scaling factor s*. → Algorithm 1
Perform Taylor polynomial evaluation for the scaled
matrix A/2s. → Algorithm 5
3 Perform the appropriate number of squaring steps.
input : 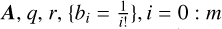
output : 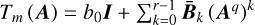 .
.
:
F=0
for k=r−1:−1:0 do
B̄k=0
I:= identity matrix
for j=1: q do
I=A × I →(I:=Aj)
B̄k=B̄k+bq * k+j I →(I:=Aj)
end
cond =(k ≥ 1)
F=(1− cond) *(B̄k+F)+ cond *(B̄k+F) × I
→(I:=Aq)
end
F=F+b0 I → I:= identity matrix
input : q ; r;
A ; bi=(−1)i/i!, i=0: q r.
output : bexp
:
bexp=0
B̂=0
for l=r−1:−1: 0 do
B̂=0
I:= identity matrix
for j=1: q do
I=A × I →(I:=Aj)
B̂=B̂+bq * k+j I →(I:=Aj)
end
cond = (k ≥ 1)
bexp= cond *(‖B̂‖+bexp) ×‖I‖+(1− cond) * bexp
end
bexp=bexp+‖b0 I+B̂‖ →(B̂:=B̂0)
input : 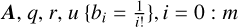
output : 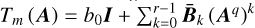 .
.
:
F=0
for k=r−1:−1: 0 do
B̄k=0
I:= identity matrix
for j=1: q do
I=A × I →(I:=Aj)
B̄k=B̄k+bq * k+j I →(I:=Aj)
end
cond1=(k ≥ 1)
cond2=(bexp *‖B̄‖ *‖I‖k) ≤ u
F=(1-cond1) *(B̄k+F)+cond1(1-cond2)*
(B̄k+F) × I
end
F=F+b0 I → I:= identity matrix
References
- Al-Mohy, A., & Higham, N., 2009, SIAM J. Matrix Anal. Appl., 31 [Google Scholar]
- Al-Mohy, A. H., & Higham, N. J., 2010, SIAM J. Matrix Anal. Appl., 31, 970 [CrossRef] [Google Scholar]
- Bae, J., Isella, A., Zhu, Z., et al. 2023, in Astronomical Society of the Pacific Conference Series, 534, Protostars and Planets VII, eds. S. Inutsuka, Y. Aikawa, T. Muto, K. Tomida, & M. Tamura, 423 [Google Scholar]
- Bai, X.-N., & Stone, J. M., 2010, ApJS, 190, 297 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez-Llambay, P., Krapp, L., & Pessah, M. E., 2019, ApJS, 241, 25 [Google Scholar]
- Cañas, M. H., Lyra, W., Carrera, D., et al. 2024, Planet. Sci. J., 5, 55 [CrossRef] [Google Scholar]
- Commerçon, B., Lebreuilly, U., Price, D. J., et al. 2023, A&A, 671, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- David-Cléris, T., Laibe, G., & Lapeyre, Y., 2025, MNRAS, 539, 1 [Google Scholar]
- Delorme, M., Durocher, A., Sacha Brun, A., et al. 2025, in Journal of Physics Conference Series, 2997, 012014 [Google Scholar]
- Dipierro, G., Laibe, G., Alexander, R., & Hutchison, M., 2018, MNRAS, 479, 4187 [NASA ADS] [CrossRef] [Google Scholar]
- Draine, B. T., 2003, ARA&A, 41, 241 [NASA ADS] [CrossRef] [Google Scholar]
- Draine, B. T., Dale, D. A., Bendo, G., et al. 2007, ApJ, 663, 866 [NASA ADS] [CrossRef] [Google Scholar]
- Epstein, P. S., 1924, Phys. Rev., 23, 710 [Google Scholar]
- Fasi, M., & Higham, N. J., 2019, SIAM J. Matrix Anal. Appl., 40, 1233 [Google Scholar]
- Gottlieb, S., & Shu, C. W., 1998, Math. Computat., 67, 73 [Google Scholar]
- Grete, P., Dolence, J. C., Miller, J. M., et al. 2023, Parthenon: Portable blockstructured adaptive mesh refinement framework, Astrophysics Source Code Library [record ascl:2306.026] [Google Scholar]
- Group, K., 2021, SYCL 2020 Specification, https://www.khronos.org/registry/SYCL/specs/sycl-2020/html/sycl-2020.html, revision 10 [Google Scholar]
- Guillet, V., Hennebelle, P., Pineau des Forêts, G.,, et al. 2020, A&A, 643, A17 [EDP Sciences] [Google Scholar]
- Higham, N. J., 2005, SIAM J. Matrix Anal. Appl., 26, 1179 [Google Scholar]
- Higham, N. J., 2009, SIAM Rev., 51, 747 [Google Scholar]
- Huang, P., & Bai, X.-N., 2022, ApJSS, 262, 11 [Google Scholar]
- Hutchison, M., Price, D. J., & Laibe, G., 2018, MNRAS, 476, 2186 [Google Scholar]
- Krapp, L., & Benítez-Llambay, P., 2020, RNAAS, 4, 198 [NASA ADS] [Google Scholar]
- Krapp, L., Benítez-Llambay, P., Gressel, O., & Pessah, M. E., 2019, ApJ, 878, L30 [Google Scholar]
- Krapp, L., Youdin, A. N., Kratter, K. M., & Benítez-Llambay, P., 2020, MNRAS, 497, 2715 [NASA ADS] [CrossRef] [Google Scholar]
- Krapp, L., Garrido-Deutelmoser, J., Benítez-Llambay, P., & Kratter, K. M., 2024, ApJS, 271, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Laibe, G., & Price, D. J., 2011, MNRAS, 418, 1491 [NASA ADS] [CrossRef] [Google Scholar]
- Laibe, G., & Price, D. J., 2012a, MNRAS, 420, 2345 [NASA ADS] [CrossRef] [Google Scholar]
- Laibe, G., & Price, D. J., 2012b, MNRAS, 420, 2365 [Google Scholar]
- Laibe, G., & Price, D. J., 2014, MNRAS, 444, 1940 [Google Scholar]
- Lebreuilly, U., Commerçon, B., & Laibe, G., 2019, A&A, 626, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lehmann, A., & Wardle, M., 2018, MNRAS, 476, 3185 [Google Scholar]
- Lesur, G., Flock, M., Ercolano, B., et al. 2023a, in Astronomical Society of the Pacific Conference Series, 534, Protostars and Planets VII, eds. S. Inutsuka, Y. Aikawa, T. Muto, K. Tomida, & M. Tamura, 465 [Google Scholar]
- Lesur, G. R. J., Baghdadi, S., Wafflard-Fernandez, G., et al. 2023b, A&A, 677, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lombart, M., & Laibe, G., 2021, MNRAS, 501, 4298 [Google Scholar]
- Lombart, M., Hutchison, M., & Lee, Y.-N., 2022, MNRAS, 517, 2012 [CrossRef] [Google Scholar]
- Lombart, M., Bréhier, C.-E., Hutchison, M., & Lee, Y.-N., 2024, MNRAS, 533, 4410 [CrossRef] [Google Scholar]
- Matthijsse, J., Aly, H., & Paardekooper, S.-J., 2025, A&A, 695, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mentiplay, D., Price, D. J., Pinte, C., & Laibe, G., 2020, MNRAS, 499, 3806 [Google Scholar]
- Moler, C., & Van Loan, C., 2003, SIAM Rev., 45, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Moseley, E. R., & Teyssier, R., 2025, MNRAS, 542, 1011 [Google Scholar]
- Paardekooper, S.-J., & Aly, H. 2025a, A&A, 696, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paardekooper, S.-J., & Aly, H. 2025b, A&A, 697, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paardekooper, S.-J., McNally, C. P., & Lovascio, F., 2020, MNRAS, 499, 4223 [CrossRef] [Google Scholar]
- Paardekooper, S.-J., McNally, C. P., & Lovascio, F., 2021, MNRAS, 502, 1579 [NASA ADS] [CrossRef] [Google Scholar]
- Paterson, M. S., & Stockmeyer, L. J., 1973, SIAM J. Comput., 2, 60 [Google Scholar]
- Ruiz, P., Sastre, J., Ibáñez, J., & Defez, E., 2016, J. Computat. Appl. Math., 291, 370 [Google Scholar]
- Sastre, J., Ibánez, J., Defez, E., & Ruiz, P., 2015, SIAM J. Sci. Comput., 37, A439 [Google Scholar]
- Skaflestad, B., & Wright, W., 2009, Appl. Numer. Math., 59, 783 [Google Scholar]
- Tricco, T. S., Price, D. J., & Laibe, G., 2017, MNRAS, 471, L52 [Google Scholar]
- Trott, C. R., Lebrun-Grandié, D., Arndt, D., et al. 2022, IEEE Trans. Parallel Distrib. Syst., 33, 805 [CrossRef] [Google Scholar]
- Wibking, B. D., & Krumholz, M. R., 2022, MNRAS, 512, 1430 [Google Scholar]
- Wu, Y., Lin, M.-K., Cui, C., et al., 2024, ApJ, 962, 173 [Google Scholar]
For the EXP integrator, we used the scaling and squaring method to compute eΔ t/Ω for each cell, where Ω is given by Eq. (17).
In sycl, a work-item is the smallest unit of execution on a GPU compute unit. It is the equivalent of the CUDA thread.
In sycl, a work-group is a set of work-items in the thread hierarchy that are scheduled together. It is the equivalent of warp with the CUDA programming model or wavefront for AMD GPU. The former's size is user-defined, while a warp or wavefront has a fixed size depending on the GPU architecture.
All Tables
Initial conditions (left), eigenvalues, and coefficients for the analytical solution of the collision tests (right).
Precomputed parameters for Taylor-based scaling and squaring algorithm for u=2−53. In each row from left to right we have respectively the number of matrix product in the scaling phase k, the Taylor series polynomial order mk, the Horner-Paterson-Stockmeyer parameters qk and rk, and the number of matrix product Πmk.
All Figures
|
Fig. 1 Collisions test. Evolution of the gas and dust velocities (from top to bottom) for tests B and C (left and right columns, respectively). The dot-dashed black line represents the analytical solution. The other lines compare the numerical solutions obtained with the EXP integrator (orange) with other integrators, namely the first-order implicit RK1 (blue), the second-order fully implicit RK2 (purple), the MDIRK method with |
| In the text | |
|
Fig. 2 Collisions tests B (left) and C (right). The evolution of error E r1 is defined by Eq. (30) for the EXP (orange) and other integrators: RK1 (blue), RK2 (purple), MKDIRK- (green), and MKDIRK+ (red). |
| In the text | |
|
Fig. 3 Evolution of the gas and dust velocities for a Collisions test with 20 dust fluids obtained with the EXP solver and compared to the analytical solution given by Eq. (27) (dashed black lines). For the first five dust species, their stopping time is short, such that they are strongly coupled to the gas. We therefore chose to plot the first and the fifth species. In addition to the 6th dust species, we chose to skip every second fluid from the 10th to the 20th dust species. |
| In the text | |
|
Fig. 4 Dustywave test. Evolution of normalised densities (upper panels) and velocities (lower panels) for one (left panel) and four dust fluids (right panel). The dashed black lines correspond to the analytical solution. The other markers and colours represent the numerical results obtained with the EXP algorithm. We additionally plot the L1 error given by Eq. (33) for the one-dust fluid case as an inset in the bottom left panel using a fixed time step of Δ t=10−4 for EXP and RK1. |
| In the text | |
|
Fig. 5 Dustyshock test. Normalised velocities (first and third panels for one- and three-dust fluid(s), respectively) and density (second and fourth panels for one- and three-dust fluid(s), respectively). The dashed lines show the analytical solutions, and the circle markers show the numerical results we obtained with the EXP algorithm. With the EXP solver, the shock is captured within one to two cells. |
| In the text | |
|
Fig. 6 Performance of the EXP drag solver as function of the number of fluids (gas and dust fluids) on one A100 GPU obtained with an implementation with a moderate level of optimisation in the Dyablo (left) and the Shamrock (right) codes. We provide the results obtained with the RK1 algorithm for comparison. The tests with Dyablo used static arrays and global memory. The tests with Shamrock used dynamical arrays and either the local (EXP-LOC) or the global (EXP-GLB) memory. For 8-16 dust fluids, the computational cost of the drag step is ∼ 10−100% of the hydro step, which makes it usable for astrophysical applications. |
| In the text | |
|
Fig. 7 Performances of the EXP drag solver on a Dustywave test performed on a A100 GPU using Dyablo for Ncells=643 (left) and Ncells=2563 cells for 1 to 15 dust fluids, respectively. The top panels show the time per cell for the drag step. The bottom panels show the relative cost of the drag step with respect to the total time step (hydro+drag) per time step. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.