| Issue |
A&A
Volume 704, December 2025
|
|
|---|---|---|
| Article Number | A61 | |
| Number of page(s) | 20 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202556583 | |
| Published online | 03 December 2025 | |
Playing CHESS with stars
I. Search for similar stars in large spectroscopic datasets★
1
Nicolaus Copernicus Astronomical Center, Polish Academy of Sciences,
ul. Bartycka 18,
00-716
Warsaw,
Poland
2
Instituto de Astrofísica, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna
4860,
Santiago,
Chile
3
Centro de Astro-Ingeniería, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna
4860,
Santiago,
Chile
★★ Corresponding authors: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
24
July
2025
Accepted:
5
September
2025
Abstract
Context. Massive amounts of spectroscopic data obtained by stellar surveys are feeding an ongoing revolution in our knowledge of stellar and Galactic astrophysics. Analysing these datasets to extract the best possible astrophysical parameters on short timescales is a considerable challenge.
Aims. The differential analysis method is known to return the most precise results in the spectroscopic analyses of F-, G-, and K-type stars; however, it can only be applied to stars with similar parameters. Our goal is to present a procedure that significantly simplifies the identification of spectra from stars with similar atmospheric parameters within extensive spectral datasets. This approach allows for a quick application of differential analyses in these samples, thereby enhancing the precision of the results.
Methods. We used projection maps created by the t-SNE dimensionality reduction algorithm applied directly to the spectra using pixels as dimensions. To test the method, we used more than 7300 high-resolution UVES spectra of about 3000 stars in the field of view towards open and globular clusters. As our reference, we used 1244 spectra of 274 stars with well-determined and high-quality atmospheric parameters.
Results. We calibrated a spectral similarity metric that allowed us to identify stars in a t-SNE projection map with parameters that differed by ±200 K, ±0.3 dex, along with ±0.2 dex in effective temperatures, surface gravities, and metallicities, respectively. We achieved completeness between 74–98% and typical purity between 39–54% in this selection. With these data in hand, we have the ability to fully enable the detection of stars with similar spectra for a successful differential analysis. In this work, we apply this method to evaluate the accuracy and precision of four atmospheric parameter catalogues, identifying regions of the parameter space where the spectral analysis methods need improvement.
Key words: surveys / stars : fundamental parameters / stars : late-type
Based on data obtained from the ESO Science Archive Facility.
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Stellar spectra encode information on properties such as detailed surface chemical abundances, rotation, magnetic activity, and mass accretion or loss. Having access to such valuable data for large samples of stars of different ages formed across a wide variety of environments is essential to clarifying the origins of the elements, along with the formation and evolution of planets and stars. In addition, these datasets help improve our understanding of the complexities involved in the formation and evolution of the Milky Way.
Recognising this need for extensive spectroscopic data, several large stellar spectroscopic surveys have been designed and they are now feeding an ongoing revolution in stellar and Galactic astrophysics. Examples include the Gaia-ESO Survey (GES, Gilmore et al. 2022; Randich et al. 2022), the Galactic Archaeology with HERMES Survey (GALAH, De Silva et al. 2015), the Large Sky Area Multi-Object Fibre Spectroscopic Telescope (LAMOST, Zhao et al. 2012; Liu et al. 2020), and the Apache Point Observatory Galactic Evolution Experiment (APOGEE, Majewski et al. 2017). In the near future, projects such as the 4-metre Multi-Object Spectroscopic Telescope (4MOST, de Jong et al. 2019) and the WHT Enhanced Area Velocity Explorer (WEAVE, Jin et al. 2024) will further expand previous efforts in unprecedented ways.
With spectra available for tens of millions of stars, the challenge shifts to efficiently analysing the data on short timescales while maintaining the high quality of the results. This can only be attempted by automatic routines and pipelines (e.g. Recio-Blanco et al. 2006; Magrini et al. 2013; García Pérez et al. 2016; Hanke et al. 2018; Tabernero et al. 2022; Li et al. 2024, to note a few). The most common analysis approach involves radiative transfer calculations based on model atmospheres to fit either the equivalent widths or the profiles of spectral lines. A related, albeit alternative approach involves the matching or interpolation among a grid of template spectra (which can be of observational or synthetic origin).
More recently, data-driven approaches have been used to determine stellar parameters and abundances from large datasets. In a first phase, these methods use an input training grid of spectra to learn the complex relations between so-called labels (stellar parameters and abundances in this case) and the input data. After training, the algorithms can apply what has been learnt to infer the labels of the new data (see e.g. Ness et al. 2015; Fabbro et al. 2018; Leung & Bovy 2019; Ting et al. 2019; Xiang et al. 2019; Guiglion et al. 2020; O’Briain et al. 2021; Li et al. 2022; Nepal et al. 2023; Candebat et al. 2024; Sizemore et al. 2024). These data-driven methods are fast and can reach a very high level of precision. However, creating a high-quality training sample still requires the use of more traditional methods.
Among the different implementations of the traditional approach to spectroscopic analysis, the differential method produces the most precise results (see e.g. Bedell et al. 2014; Nissen & Gustafsson 2018). Radiative transfer analyses may suffer systematic errors coming from typical assumptions, such as reducing physical processes to one-dimensional (1D) problems, using the local thermodynamic equilibrium (LTE) approximation, and adopting a simplified treatment of convection (see e.g. Kupka & Muthsam 2017; Joyce & Tayar 2023; Lind & Amarsi 2024, for reviews on these topics). In a differential analysis, stars of similar atmospheric parameters are analysed with respect to each other. In such a comparison, the systematic errors are assumed to be the same and to cancel out. In this case, the differences in parameters and abundances are determined with a very high precision (below 0.01 dex for abundances, see e.g. Bedell et al. 2014), particularly when the data have been obtained at a high resolution and have a high signal-to-noise ratio (S/N).
However, the accuracy of the results is harder to establish. The fundamental determination of effective temperatures (Teff) and surface gravities (log g) is possible with minimum assumptions, if independent measurements of the stellar bolometric flux, angular diameter, distance, and mass are available (e.g. Boyajian et al. 2013; Creevey et al. 2015; Kiman et al. 2024; Soubiran et al. 2024; Pinsonneault et al. 2025). Metallicities and abundances, on the other hand, need to be inferred from modelling; with the exception of the Solar System, where meteorites can be used for independent (but not assumption-free) measurements (Alexander 2019; Lodders 2021). An accurate determination of stellar parameters is also possible with state-of-the-art three-dimensional (3D) model atmospheres, as demonstrated, for example, in Giribaldi et al. (2021, 2023).
Finally, it is worth mentioning that the variety of approaches, method implementations, codes, physical assumptions, and even somewhat subjective decisions (such as continuum placement) lead to significant discrepancies among the results obtained for the same stars in different works (Lebzelter et al. 2012; Smiljanic et al. 2014; Hinkel et al. 2016; Jofré et al. 2017; Jönsson et al. 2018; Brucalassi et al. 2022). Systematic biases between surveys remain a concern (see e.g. Soubiran et al. 2022; Hegedűs et al. 2023; Van der Swaelmen et al. 2024). Moreover, since the vast majority of the spectra obtained in surveys is of low resolution, the validation of their analysis in a comparison with observations of higher resolution is important (Karinkuzhi et al. 2021; Sandford et al. 2023).
Amid the variety of surveys, spectral databases, and analysis methods, it is a concern that the most extensive, high-quality information are extracted from each spectrum. With this motivation, we are developing a new pipeline called CHEmical Survey analysis System (CHESS), which is aimed at deriving precise, accurate, and complete chemical information from large samples of spectra of F-, G-, and K-type stars. It uses the differential analysis method for a high level of precision and a set of reference stars to anchor the parameter scale with high accuracy.
To identify similar stars for differential analyses, CHESS uses unsupervised machine learning for a similarity analysis using the spectra. In this paper, we describe and validate the steps and results of this similarity analysis. We also show that this step can be useful for a blind test of large survey results. Future articles in this series will discuss the results of the spectral analysis using CHESS in a variety of science cases. This paper is divided as follows. In Sect. 2, we present the spectroscopic data and the preliminary processing steps. The methodology applied for the similarity analysis is discussed in Sect. 3. We present and discuss the results in Sect. 4 and summarise our conclusions in Sect. 5.
2 Data and preliminary data processing
This work uses spectroscopic data publicly available at the Science Archive Facility (SAF, Romaniello et al. 2023) of the Euro-pean Southern Observatory (ESO). The spectra were obtained with the Ultraviolet and Visual Echelle Spectrograph (UVES, Dekker et al. 2000) at the Very Large Telescope, Paranal Observatory, Chile. We focussed on the spectra of FGK-type stars observed in the direction of open and globular clusters. Stars in clusters are very useful for testing methods to determine astrophysical parameters (e.g. Holtzman et al. 2015; Pancino et al. 2017; Anders et al. 2022). Moreover, focussing on cluster stars maximises the chances of including similar stars in the sample.
2.1 Sample of stars in clusters
As reference for globular cluster coordinates, we used the 2010 edition of the ‘Catalog of parameters for Milky Way globular clusters’ originally compiled by Harris (1996), which contains 157 globular clusters in the Milky Way. For open clusters, the catalogue from Hunt & Reffert (2023, 2024) was used, which provides a list of 5647 groups of stars identified as open clusters from an analysis of sources in Data Release 3 (DR3) of Gaia (Gaia Collaboration 2023b).
We performed a cone search at the SAF with a diameter of 20 arcmin centred in the coordinates of each cluster. All the spectra of sources in this area were downloaded; however, we note that membership information was not considered for selection. The selection was restricted to spectra with a resolution of R ≥ 20 000 and excluded those with a signal-to-noise ratio of S/N < 10 (for the current selection; for future analyses, a higher S/N threshold will be preferred). In total, we downloaded 2557 processed slit UVES spectra from stars in the field of 50 globular clusters and 8262 from stars in the field of 371 open clusters. We note here that several of the collected spectra are data from GES, which has observed stars in several open clusters (Bragaglia et al. 2022). This makes the parameters from GES very useful for testing our method of finding similar stars.
2.2 Cross-matching with catalogues and databases
Properly identifying the object to which a spectrum belongs is paramount to search for complementary data (such as photometry, astrometry, or asteroseismology) and investigate the properties of cluster members at a later stage, as well as for general legacy purposes. Therefore, we devoted considerable effort to identifying the stars to which our spectra are linked.
Catalogue cross-matching was challenging. One complication was that the format and content of some keywords in the header of the FITS files were found to be different depending on when the observations were taken. In addition, some observations only list pointing coordinates, which indicate the direction in the sky targeted by the telescope (and are affected by the telescope system uncertainties). Differences between such coordinates and the real object positions complicate the process of star identification, particularly in crowded fields.
Furthermore, object names are frequently non-informative; real examples are Tar_1 or star53. Even in cases where the name is meaningful, it is not necessarily given as an interpretable string that can be used to query a service like the Set of Identifi-cations, Measurements, and Bibliography for Astronomical Data (SIMBAD, Wenger et al. 2000). One example is the object name EGGEN-45: knowing the cluster around the target, it was possible to search SIMBAD for Cl* IC 4651 EGG 45, which returned an entry with very similar coordinates and confirmed the match.
All of these points limit how findable and reusable the data are. The ever-increasing volume of data from current and future instrumentation requires steps to make data mining as straightforward as possible. Therefore, we urge observatories and data archives to use standardised practices for recording object coordinates and identifiers, thus ensuring the long-term usage and legacy of their datasets. To overcome these obstacles, we implemented rules to automate stellar identification using a dedicated PYTHON script. However, many cases still required manual intervention. Even then, there were cases where proper identification of a spectrum was not feasible. In the following subsections, we detailed the steps in the object identification workflow (summarised in Fig. 1).
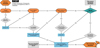 |
Fig. 1 Object identification workflow for discovering the source ID of each spectrum. The steps for crossmatching with SIMBAD and with the Gaia DR3 catalogue are depicted in detail. |
2.2.1 Cross-match with SIMBAD
The script queries SIMBAD to retrieve each star’s correct identifier and coordinates (RA, DEC). The steps are listed below.
If present, the keywords ESO TEL TARG ALPHA and ESO TEL TARG DELTA are used for a cone search in SIMBAD with a radius of 2 arcsec. These coordinates tend to be very accurate. We proceeded differently depending on the results, based on the two following cases:
if more than one source is detected, the correct identification cannot be established unless it refers to a GES object and a Gaia DR3 ID;
in the case of a single source identification, the pointing coordinates (RA, DEC) are checked to confirm whether the source coordinates are in agreement with those in SIMBAD (within 20 arcsec).
If the source identification is uncertain in the previous step, the keyword OBJECT is checked and passed directly to SIM-BAD, unless it is a GES spectrum; in that case, the name is set to start with ‘GES J’. If an exact match is found, we verify the pointing coordinates against SIMBAD to confirm the match and detect typos in the object name.
For unidentified objects in the previous steps, we performed a final search using the header’s object name. We excluded names with fewer than five characters or purely numeric values. For the remaining cases, we added asterisk wildcards (*) between letters and numbers and at both ends of the name. This search used a 30 arcsec radius around the pointing coordinates and required complete character matches with the header name. If a single source match is found, it was accepted as the correct identification.
If the spectrum being analysed was still unidentified following the aforementioned steps, we attempted a manual identification. For example, by performing a systematic literature search to find publications that used the original data and provided a list of targets. This process was occasionally unsuccessful when the relevant source catalogues were unpublished or inaccessible.
For stars matched to an entry in SIMBAD, we included a check of the fields Object type and Spectral type. The goal was to exclude sources that are not of our interest. The following categories were excluded from the sample:
Object types1: Ae*, Be*, Cl*, HXB, HS*, HS?, Mi*, No*, Or*, PN, PN?, QSO, Sy1, TT*, WD*, WR*, Y*O, Y*?, a2*, and pA*;
Spectral types: B, O, WC, WN, and WR.
Of the 10 819 spectra, we initially downloaded, we excluded 76 based on object names that clearly indicated that they are a completely different class of objects (e.g. white dwarfs or pulsars). From the remaining spectra, we were able to identify with high confidence 10 343. From these, we excluded all spectra with the spectral types mentioned above. On the other hand, for the analysis we retained the spectra that met our S/N and resolution criteria, even if they had not been successfully identified. After applying these criteria, the final sample used in our analysis consists of 7 182 spectra.
2.2.2 Cross-match with Gaia DR3
Having completed the SIMBAD cross-match, we proceeded to carry out a cross-identification with the Gaia DR3 catalogue, through a cone search of 2 arcsec. This is useful as another check of the SIMBAD coordinates, since we can confirm whether the Gaia ID found in SIMBAD is the same as the one directly found in Gaia. Of the 7182 spectra retained for analysis, we obtained coordinates for 6743. Among those, 5 997 spectra were successfully matched with Gaia. We found a total of 24 spectra (from five different objects) with mismatched Gaia IDs. The remaining stars did not have a Gaia DR3 ID that matches their entry in SIMBAD.
2.2.3 Cross-match with external catalogues
Following the identification of the stars within our sample, we subsequently obtained the available stellar parameters from various sources in the literature, as follows: (i) the catalogue of stellar parameters obtained by Andrae et al. (2023, hereafter GaiaXGBoost) using the XGBOOST algorithm for 175 million stars from Gaia DR3; (ii) the StarHorse 2 catalogue by Anders et al. (2022, hereafter StarHorse2), based on the isochrone fitting code created by Queiroz et al. (2018); (iii) the Gaia-ESO spectroscopic survey with parameters for almost 7 000 stars observed with the UVES instrument (Hourihane et al. 2023; Worley et al. 2024, hereafter GES); (iv) the 220 million Gaia XP sources analysed by Zhang et al. (2023) with a data-driven model trained on the LAMOST stellar parameters (Li & Lin 2023, hereafter XP-LAMOST). These catalogues cover most of our sample and we were able to use them to check the consistency of the results of our analysis.
2.3 Reference stars
As briefly mentioned in Sect. 1, the CHESS methodology relies on a set of reference stars that we assumed to have accurate stellar parameters. In total, we collected 1244 spectra from 274 reference stars with different values of S/N and wavelength coverage. The distribution of these stars in the Kiel diagram can be seen in Fig. 2. The selected reference stars include:
The Sun: we included two twilight spectra observed with FLAMES-UVES by GES, the FLAMES-UVES solar spectrum made available by ESO2, also from observations of the twilight sky, and a spectrum of reflected solar light on Ganymede observed with the High Accuracy Radial velocity Planet Searcher (HARPS; Mayor et al. 2003) instrument3. The latter is the only non-UVES spectrum included in the current analysis and is used only for testing purposes.
TITANS I (Giribaldi et al. 2021): comprises 165 UVES spectra from 34 stars. Part I of the TITANS is a sample of 41 metal-poor dwarf and subgiants ([Fe/H] ≤ −1.0 dex) with atmospheric parameters derived with high accuracy (maximum errors in Teff of ± 50 K, for log g , the typical error is ≤0.04 dex and for [Fe/H] the dispersion is ± 0.05 dex).
TITANS II (Giribaldi et al. 2023): comprises 164 UVES spectra from 32 stars. Part II of the TITANS presents a sample of 47 metal-poor red giants, some of which are carbon-enhanced metal-poor (CEMP) stars ([Fe/H] ≤ − 0.8 dex). The estimated errors are: ∼50 K for Teff; ± 0.15 dex for log g; and ± 0.09 dex for [Fe/H].
GES K2 stars (Worley et al. 2020): 81 UVES spectra of 44 stars. This is a sample of 90 red giants whose analysis combined spectroscopy from the Gaia-ESO Survey with asteroseismic constraints from the K2 mission (Howell et al. 2014). The estimated errors are: ∼85 K for Teff; ∼0.02 dex for log g; and ∼0.12 dex for [Fe/H].
GES set of hot and cool reference stars (Tables 5 and 6 in Pancino et al. 2017): 274 UVES spectra from 16 stars. Pancino et al. (2017) extended the GES list of reference stars with 17 well-studied OBAM-type stars. Although these are not the types of stars analysed here, they were added to help in distinguishing any such kind of star that may have been included in our target sample unknowingly.
Gaia FGK benchmark stars (Soubiran et al. 2024): 252 UVES spectra of 37 stars. The Gaia benchmark stars are a sample of 192 FGK-type stars with Teff and log g derived from fundamental methods, independent of spectroscopy, using angular diameter, bolometric fluxes, and parallaxes. The uncertainties in these parameters are usually below 2%. The metallicity values come from the literature.
Gaia ‘golden sample’ (Gaia Collaboration 2023a): 304 UVES spectra from 110 stars. As part of Gaia DR3, six samples of stars with high-quality stellar parameters were provided. The parameters of these samples were validated in detail, using both Gaia data and literature results. We focus here on the subsample of FGKM-type stars.
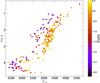 |
Fig. 2 Kiel diagram, colour-coded by metallicity, showing the stellar parameters of the reference stars used in this work. The O- and B-type stars are not shown to facilitate the visualisation. |
2.4 Data homogenisation
Before comparing the spectra, we performed the homogenisation of the data, which entails correcting for the Doppler shift induced by the stellar radial velocities, normalising the flux scale, and setting all data to the same resolution and binning. If this is not done, the differences in such characteristics dominate the comparison between the spectra, as the pixels would not correspond to the same wavelength interval and the relative fluxes can vary a lot depending on exposure time and target brightness.
Originally, the spectral resolution in our sample ranged from 20 000 to ∼110 000. Since there were very few spectra with R< 30 000 (63), we excluded them from further analysis. Therefore, we degraded the data to R = 30 000. For rebinning, we chose the maximum value of the sample, a pixel size of 0.0043 nm. Both steps were performed using ISPEC (Blanco-Cuaresma et al. 2014; Blanco-Cuaresma 2019).
For the continuum normalisation, we used SUPPNET, a neural network software for stellar spectrum normalisation4, developed by Różaźski et al. (2022). At this step, we decided to focus on the wavelength range between 400 and 700 nm. This choice was made to avoid the crowded regions in the blue region and the contamination by telluric lines in the red wavelengths.
We used cross-correlation against a set of 12 synthetic spectra templates (see Table 1) to compute the relative radial velocity and correct the observed data to a rest-frame wavelength solution. Synthetic spectra were calculated using the code TUR-BOSPECTRUM (Plez 2012) in the 300–900 nm range, with steps of 0.0015 nm, and a resolution of R = 30 000 at 450 nm. We used the atomic and molecular line list compiled and tested by Giribaldi & Smiljanic (2023).
The cross-correlation was run against each template in the grid. We discarded extreme values that deviate from the median by at least ten times the median absolute deviation (MAD). We adopted the radial velocity estimate with the smallest error, which was computed by ISPEC following Zucker (2003). This procedure ensured the selection of the template most compatible with the observed spectrum, the one exhibiting the highest peak in the cross-correlation functions.
Stellar parameter of the templates used in the radial velocity determination.
3 Similarity analysis
The similarity analysis is the step that identifies stars with similar atmospheric parameters before the detailed spectroscopic analysis. Our aim is to create a method that directly uses the comparison of stellar spectra to select targets for a successful differential analysis. Specifically, our objective is to identify stars with parameters that differ by ±200 K in Teff, ±0.3 dex in log g, and ±0.2 dex in [Fe/H], from those of a selected reference star. We recall that the use case for this method is in the context of large spectroscopic surveys dealing with several thousands to millions of spectra of stars with still unknown atmospheric parameters. Below, we detail the steps required to identify similar stars.
3.1 Dimensionality reduction
We used the unsupervised machine learning algorithm known as t-distributed Stochastic Neighbour Embedding (t-SNE, van der Maaten & Hinton 2008). This algorithm has been used before in support of spectroscopic analyses. Matijevič et al. (2017) were the first to use t-SNE for that purpose as part of a method to identify candidate metal-poor stars observed by RAVE (The Radial Velocity Experiment, Steinmetz et al. 2020). Similarly, Traven et al. (2017) applied t-SNE to GALAH spectra, producing a two-dimensional map that facilitated semi-automated spectral classification and the identification of peculiar or problematic spectra.
The algorithm projects high-dimensional data onto lower dimensions, while striving to preserve the global structure of those data. In this process, t-SNE tries to conserve the ‘neighbourhood’ of the data points. Thus, data points that are nearby in high-dimensional space should maintain their proximity in lower-dimensional projections, with neighbours being more alike than distant points. A key hyperparameter of t-SNE is the perplexity, which controls the number of neighbours around each data point when the lower-dimensional space is built. It controls the balance between preserving the local and global structure of the data distribution. A low perplexity value creates tightly grouped clusters in the projected space, allowing the algorithm to separate data points with subtle differences. In contrast, a higher perplexity helps to uncover broader structures in the data.
In our case, the high-dimensional data are the homogenised spectra of different types of stars. Each spectrum is a point in a multidimensional space with pixels as dimensions and their flux as coordinates. Within this space, data points representing similar spectra cluster together. With the t-SNE, we wanted to create a projection map of these data in two dimensions (2D). However, our spectra are not uniformly distributed in terms of their wavelength ranges (Fig. 3). This hindered the use of the entire range or even a single selected range with t-SNE; therefore, we had to select several short spectral regions that we could apply the similarity analysis to. Our goal was to select a small number of regions, making sure that each region covered as many spectra as possible and that, altogether, the regions would encompass all spectra contained in the sample. At the same time, we made sure to include some selected features sensitive to different stellar parameters (e.g. the Hα line or the Mg triplet at 517 nm). The final selected spectral regions (named ‘R1’ to ‘R6’) are listed in Table 2 and highlighted in Fig. 3. Some of the sample spectra were found to contain pixels with missing values in the selected regions that cannot be used in the analysis. For small gaps of ≤5 consecutive pixels, we employed a cubic-spline interpolation. For larger gaps, the corresponding pixels were excluded from the analysis.
We used the Python scikit-learn package (Pedregosa et al. 2011) for t-SNE, testing both the exact and Barnes-Hut methods. The exact method took about 30 minutes per spectral region, while the Barnes-Hut method reduced this to 5 minutes (on a computer with a 12-core processor). Since our dataset is relatively small (see Table 2), we opted for the exact method to maximise accuracy.
An example of a projection map, obtained using the spectral region R2, is shown in Fig. 4. Depending on the spectral region used, the morphologies of the maps are different but their overall characteristics are the same (see the additional maps in Appendix B): the main separation of the points is between groups of giant stars (marked as groups B and C in Fig. 4) and dwarfs (groups A and H in Fig. 4). Within the groups of dwarfs, we see a gradient of Teff. Within the groups of giants, there is a gradient of [Fe/H]. These observations already hint that, while all three atmospheric parameters influence the distribution of stars in the projection map, the variations in Teff and [Fe/H] values are most significant. The additional groups in the plot are better discussed in Sect. 4. Given that our sample has many spectra from different types of stars, we can see some imbalance in how different groups appear in the projected space. To address this, we decided to apply t-SNE twice. First, we used the full dataset and a high-perplexity value to divide the main groups (e.g. dwarfs, giants, and metal-poor stars). Then, we ran t-SNE on one of the groups identified before, with slightly lower perplexity, to further separate subgroups of similar spectra.
 |
Fig. 3 Wavelength range of each of the >7000 spectra in our sample, limited to the interval between 400–700 nm. Each spectra is represented as a horizontal line. The shaded regions (R1 to R6) indicate the selected regions to be analysed. Some of the empty spaces correspond to artifacts in the spectra or regions of telluric lines that were masked. |
Spectral regions (enumerated from R1 to R6) used for the similarity analysis.
3.2 Defining the similarity among stars
In the t-SNE projection maps, similar stars are grouped together. However, the projection is obtained in a non-linear manner and the distances between points do not carry direct physical meaning. Points equally spaced in different map regions may not be equally similar. For the same reason, densities on the map are hard to interpret. However, the projections (exemplified in Fig. 4) show clear separation and ordering of the points in terms of atmospheric parameters, with similar stars expected to be neighbours. Our goal is to define a metric for selecting a sample of neighbouring stars that satisfies our similarity criterion with high completeness. To define that metric, we start from a reference star and identify stars in the sample with parameters within ±200 K in Teff, ±0.3 dex in log g, and ±0.2 dex in [Fe/H]. We can then examine how the difference in parameters relates to the distance in the projection map (see Fig. 5 for an example).
As seen in Fig. 5, stars with similar catalogue parameters do not necessarily cluster at the closest distances. This is caused by several factors in addition to the differences in atmospheric parameters. The main aspect for the neighbourhood is the similarity in the spectra. Variations in chemical abundances, uncertainties in the parameters, and noise in the spectra can all affect the t-SNE distance distribution. In particular, biases in the parameters can be significant (as seen in Fig. 5), as the methods applied to the reference stars and the neighbouring stars are not the same. These biases can cause stars with tentatively similar parameters to appear far from the reference star in the projection map because the spectra are actually different.
For our purpose, it is important to note that a region surrounding a reference star, containing objects similar to it, can be defined. Once this is understood, one can naively conclude that the distribution of distances around all reference stars can be used to define a typical distance value to select stars with parameters within ±200 K in Teff, ±0.3 dex in log g, and ±0.2 dex in [Fe/H]. However, that is not the case because distances can vary significantly with position in the projection map and because the t-SNE algorithm has a stochastic component that creates different projection maps in repeated runs. The distances between points change, preventing the selection of the same sub-sample.
As a second step, we examined how direct spectral differences correlate with t-SNE distances. For that, we defined a simple similarity score, Si, which combines the median and a measurement of the dispersion of the absolute differences between the spectra of a sample star and the reference star,
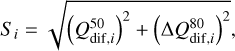 (1)
(1)
In Eq. (1), 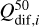 is the 50th quantile (median) and
is the 50th quantile (median) and 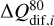 represents the interquantile range between the 90th and the 10th quantiles. We adopted
represents the interquantile range between the 90th and the 10th quantiles. We adopted 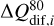 as the dispersion measurement as it is more sensitive to outliers that trace small spectral differences. Such differences can be important for the determination of similarity. For this computation, we mask the wavelength regions where the normalised flux of the reference spectrum exceeds a value of 0.90. This excludes continuum regions and weak spectral lines, ensuring that Si is computed only on more informative parts of the spectra. This is important for metal-poor stars, where large continuum regions could misleadingly suggest higher spectral similarity. An example of the comparison between Si and the t-SNE distances is shown in Fig. 6.
as the dispersion measurement as it is more sensitive to outliers that trace small spectral differences. Such differences can be important for the determination of similarity. For this computation, we mask the wavelength regions where the normalised flux of the reference spectrum exceeds a value of 0.90. This excludes continuum regions and weak spectral lines, ensuring that Si is computed only on more informative parts of the spectra. This is important for metal-poor stars, where large continuum regions could misleadingly suggest higher spectral similarity. An example of the comparison between Si and the t-SNE distances is shown in Fig. 6.
We tested several choices for the similarity metric: median absolute deviation (MAD), coefficient of determination (R2), Euclidean distances combined with a radial basis function (RBF) kernel similarity, cosine similarity, and combinations of these. Both MAD and R2 failed to provide a consistent threshold for most reference spectra. The RBF was too sensitive to outliers and required fine-tuning of the bandwidth parameter. Cosine similarity, while good at capturing overall structures, ignored subtle effects such as differences in line broadening. Combining metrics added complexity without clear benefits, so we chose the simpler option that works reliably in most cases.
Figure 6 shows that stars with atmospheric parameters within the thresholds have a narrow distribution of Si values. However, within the same range of Si values we also find stars that are not similar to the reference in terms of their parameters. This indicates that a combination of median and dispersion is too basic of a metric to capture spectral differences, emphasising the need for t-SNE in the analysis. Importantly, Fig. 6 shows that restricting the problem to the sub-sample of stars that t-SNE places nearby to the reference object, the distribution of Si values can be used to select a close to complete sample of similar stars.
Figures 5 and 6 display the comparisons between the parameters, spectra, and t-SNE distances for the case of one reference star. To generalise the comparison, we extended the investigation to the whole sample of reference stars. We first determined the distribution of distances for the stars with similar parameters (as in Fig. 5) taking the 75th percentile to represent each distribution. This value was adopted to limit the region used to calculate the distribution of the Si values (as in Fig. 6). To compare all the distributions of Si values, we show histograms of their 25th, 50th, 75th, and 90th percentiles in Fig. 7. Each histogram is narrow, with a clear peak and some outliers (probably driven by biased parameters). The exception is the 90th percentile, which is broader and is the one most sensitive to stars with problems in their parameters. Figure 7 clearly shows that all distributions are very similar. This implies that we can define a typical shape for the Si distributions that will be useful to select the most similar stars around all reference objects on the t-SNE map.
The discussion above is primarily focussed on the R2 spectral region. Similar figures for other regions are included in Appendix C. The exception is region R1 (425.1–451.0 nm), which could not be analysed because the stars in this region lack parameters from the GES catalogue. Similar conclusions as above were obtained when analysing the other regions, with the exception of region R3 (516.5–519.0 nm). For R3, the histograms show large dispersions, making it difficult to select a representative shape for the distribution of Si values around the reference stars. This is likely due to its small wavelength coverage, which may limit its sensitiveness to variations in stellar parameters.
 |
Fig. 4 t-SNE projection map of the region R2 colour-coded by the atmospheric parameters from the GES catalogue, Teff (left), log g (centre), and [Fe/H] (right). The axes do not have direct physical meaning as they are not linear combinations of the original data; they are simply indicative of relative neighbourhood of the data points in these projections. |
 |
Fig. 5 Distribution of distances in the t-SNE projection for stars with similar atmospheric parameters to the Sun, using the GES catalogue for the sample and spectral region R2. The absolute values of the differences in Teff, log g, and [Fe/H] are shown in the left, centre, and right panels, respectively. In each panel, the red horizontal line indicates the adopted parameter thresholds; green points represent the similar spectra which fulfil all three of the parameter thresholds, and the green vertical dashed line marks the 75th percentile of their distances from the reference. |
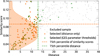 |
Fig. 6 Distribution of similarity score values of the sample surrounding the Sun. The lower the similarity score, the more similar is the stellar spectrum to the solar spectrum. The green points have the same meaning as in Fig. 5. Orange points are all the stars within the 75th percentile of distances defined in Fig. 5. The orange horizontal dashed line indicates the 75th percentile of the distribution of similarity scores. Note that the total range of similarity scores is much larger; the figure shows only nearby stars. |
 |
Fig. 7 Each subplot shows a histogram of similarity scores thresholds obtained (as shown in Fig. 6) for the references in the region R2, but computed using different percentiles (25th, 50th, 75th, and 90th). The red curve represents a smoothed distribution obtained using a Gaussian kernel density estimation (KDE). |
3.3 Procedure for the blind search of similar stars
Previously, we relied on known stellar parameters to assess similar spectra around a reference object. However, what we need as part of CHESS is a method that uses only the metric Si to blindly identify similar spectra. The core idea is that the distribution of Si values in the nearby spectra should mirror the representative distributions found in the previous discussion. To do that, we again decided to characterise the distribution of Si values around reference stars by the value of its 75th percentile. Surrounding stars are added to the distribution until that percentile reaches a threshold value, Sthresh. In the following, we describe the method that we have established for this blind search. The determination of the Sthresh value is discussed in Section 3.4.
As we mentioned earlier, to address class imbalance, we apply t-SNE in two stages. First, we run t-SNE on the full dataset to identify the major groups (shown in Fig. 4). Then, we perform a second iteration of t-SNE separately on each of these groups. This two-step approach allows us to better capture the local structure within each subgroup and avoid interference from the full sample. The following method was then applied to the projection maps generated in this second iteration.
Neighbourhood threshold: Similar stars are searched in the neighbourhood of a given spectra in the t-SNE map. To define what a reasonable neighbourhood threshold is, for each star in the projection map, we calculated the distance to its nearest neighbour (NN). The maximum of such a distribution is affected by some isolated points on the map. As the final threshold, we adopt twice the 95th percentile of the distribution. This ensures that the majority of points in the projection map have a neighbour closer than the threshold.
Initial candidate selection: For each reference spectra, we select up to 15 sample stars within the neighbourhood threshold. This number of stars was chosen to ensure some statistical robustness when calculating the percentiles of the similarity scores even in the presence of potential outliers.
Similarity evaluation: The similarity scores of the initial candidates are computed. The 75th percentile of the distribution of similarity scores is compared to the adopted metric:
if there are no spectra within the neighbourhood threshold, the reference spectrum is no longer analysed;
if the 75th percentile does not exceed the adopted metric value, Sthresh, we continue to add candidates as described in the next step;
if Sthresh is exceeded, no similar spectrum is assigned to the reference.
Distance sorting: For the remaining sample, we sort the spectra by the sum of the Euclidean distances to the reference and to the nearest spectrum already included in the candidate list. This approach ensures that the selection of next candidates grows organically in the neighbourhood of the previous objects, minimising the effect of small spatial gaps while also taking into account the overall structure of the projection.
Candidate list expansion: the next candidate is added from the sorted list if: (i) it lies within the neighbourhood threshold of at least one previously accepted spectrum, and (ii) its inclusion does not cause the 75th percentile of similarity scores to exceed the adopted metric.
Stopping criteria: the addition of new candidates is stopped if: (i) the 75th percentile of similarity scores exceeds Sthresh; or (ii) the median of the similarity scores of the last 15 stars added to the list exceeds S thresh. This secondary criterion is needed when the sample becomes too large and the addition of new stars has little influence on the distribution.
3.4 Selecting the similarity score threshold
Following the method explained above, we assess the completeness and purity of the selection for different values of S thresh using the following definitions,
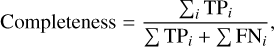 (2)
(2)
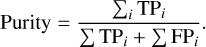 (3)
(3)
Here, for the spectrum of each reference star, i, the true positives (TP) are the spectra that should have been selected (in terms of their atmospheric parameters) and were correctly included; the false negatives (FN) are the spectra that should have been selected but are missed by the method; and the false positives (FP) are the spectra that are incorrectly included in the selection. By summing these quantities over all reference stars, we obtain global values of completeness and purity for the sample analysed in a given spectral region.
Figure 8 shows how the completeness and purity of the blind selection of similar stars vary for different Sthresh values. As expected, there is a trade-off between completeness and purity. For low values of Sthresh, the purity is higher at the cost of a very low completeness. On the other hand, for higher values of Sthresh (meaning broader distributions of Si values around each reference star), higher completeness is achieved at the cost of low purity. We can use the F-score as a metric to find the optimal value of Sthresh in this problem. The F-score is defined as
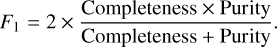 (4)
(4)
The maximum value of F-score occurs at Sthresh = 0.106. This value represents the optimal compromise between completeness and purity for a global selection over all reference stars in the t-SNE map. This is the value that we can adopt when implementing this method in the CHESS pipeline. Moreover, we found that in the remaining regions, the maximum F-score consistently yields similar Sthresh values centred around 0.090 (except for regon R3, where the method cannot be calibrated). However, we note that the above considerations are based on atmospheric parameters from external catalogues, GES in particular.
To double check these conclusions, we decided to analyse some of the spectra and investigate how well the selection indeed identified similar stars. Only five reference stars were used in this exercise, selected in different regions of the parameter space. For the analysis, we actually selected stars in a region beyond what would be chosen by the above method. The goal was to understand whether the selection stopped at an appropriate time or if it should have proceeded further. The line-by-line differential analysis was performed using the q2 code (Ramírez et al. 2014). The Fe I and Fe II lines were selected from the GES line list (Heiter et al. 2021). The equivalent widths were measured with the REvIEW code (McKenzie et al. 2022). The selected reference stars and the completeness and purity results are summarised in Table 3. We can see that when our own parameters are used to evaluate the performance of the blind method, a higher completeness is obtained. This suggests that the method is effective at selecting the stars we wanted to identify. Purity seems to be at a similar level overall, although in two cases, it changed significantly. We plan to better evaluate the reasons for this in future works.
These changes in purity may appear from biases between the stellar parameters in the external catalogue used for comparison and those adopted for the reference star. Thus, the purity value found in the comparison with the tabulated data is not real and is corrected after our analysis. Additionally, low purity can occur in sparsely populated regions of the parameter space. For example, in our current sample, extremely metal-poor stars are not numerous. They cluster together in a region of the t-SNE map, although their parameters are not truly similar (but their spectra are more similar among themselves than to the rest of the sample). As a result, selections around a reference star in this region may be contaminated, leading to low purity. At this point, to illustrate the differences, we show comparisons of similar spectra based on parameters of GES and our own analysis in Fig. 9. This comparison reinforces that our method is obtaining a very clean sample of similar spectra.
 |
Fig. 8 Completeness (blue), purity (orange), and F-score (black) as a function of the Sthresh used to select spectra. The smoothed F-score curve (purple) is used to select its maximum value (red dashed line) representing the best trade-off between completeness and purity. |
4 Discussion
4.1 A deeper look at the t-SNE projection maps
Projection maps done using the different spectral regions exhibit similar characteristics. Therefore, we focus on the map obtained using the R2 region (see Fig. 4) for this discussion, where the details of the t-SNE projection are most visible. All maps show a clear separation between dwarf and giant stars. In addition, there are a few smaller, but well-distinguished groups.
The sections marked as A and H in Fig. 4 contain dwarf stars, roughly those with log g > 3.0. They are distributed according to a clear temperature gradient. The solar-like stars are found in section A while hotter stars (types O and B) occupy section H.
Section B includes giants with [Fe/H ] ≳ −1.0. An apparent gradient in metallicity is identified, with values decreasing toward the direction of section C. There are also some secondary effects related to Teff and log g. In particular, the brightest giants of low Teff seem to group in the same corner as the giants of high metallicity. These stars are projected together probably because both low Teff and high [Fe/H] values create strong spectral lines.
Section C includes low-metallicity giants with [Fe/H] ≲ −1.0. A metallicity gradient appears to be the main factor that causes the dispersion of the points. In the bottom tail of this section there is a concentration of the most metal-poor stars with [Fe/H] ≤ −2.0. Because there are only a few of them, t-SNE interpreted that they exhibit similarities amongst themselves than they would in comparison to other stars. Section D contains a series of metal-rich dwarfs that the algorithm detached from the steps described in Section A. They all correspond to stars from NGC 6253, an open cluster observed by GES. We found these spectra to be affected by a series of artefacts in the form of spikes that were probably caused by failures in the data reduction pipeline, which was enough for the algorithm to isolate them. Section D describes the ability of t-SNE to automatically detect anomalies within an otherwise homogeneous sample.
Section E presents an unexpected group of stars that appear in maps using all the selected wavelength regions. These objects were found to be variable stars, mostly Cepheids. The combination of relatively high Teff values for their relatively low log g values sets them apart from all other sample stars.
Section F is dominated by stars in globular clusters (therefore usually metal poor) that are at the same time on the cool (Teff ≤ 4000–4200 K) and bright (log g ≤ 1.0–1.2) sides of the sample. It seems to include a mixture of stars close to the tip of the red giant branch (RGB) and in the asymptotic giant branch (AGB). In the projection maps, they should be expected closer to the top left corner of Section C, which includes metal-poor giants. Their actual positioning, close to the section of metal-rich giants, is thus somewhat surprising. It may be related to the strengthening of molecular lines because of the low Teff values. Alternatively, they could have some extreme chemical composition, being part of population II stars in globular clusters. These stars will be further investigated in future stages of the project, by obtaining their detailed chemical abundances.
Section G contains a mixture of spectra from subgiants (log g ≥ 3.3–3.5) that are extremely hot (Teff ≥ 30 000 K) or metal-poor ([Fe/H] ≤ –1.1). It is almost entirely populated by reference spectra of these types. Both types of spectra feature very few spectral lines. In the R2 region, most of their similarity comes from similar Hβ profiles. As a result, the t-SNE algorithm groups them closely together on the map. Additionally, our sample includes relatively few such stars, which further limits their separation in the projection.
Comparison of completeness using GES and q2 parameters.
 |
Fig. 9 Comparison of similar spectra to a reference spectrum of the Sun (red line), obtained in two different ways: using the GES catalogue as reference (top panel) and the selected sample using our methodology (bottom panel). Both panels display the corresponding normalized spectra for the region R2 with different colours to show the different spectra. |
 |
Fig. 10 Violin plots showing the comparison between the stellar parameters of stars with spectra similar to the Sun in four catalogues.The red dashed line indicates the reference value of the parameter and the yellow coloured area is the region within 200 K in Teff(top panel), 0.3 dex in log g(mid panel), and 0.2 dex in [Fe/H] (bottom panel) from the solar parameters. |
4.2 Testing large catalogues of stellar parameters
In the context of a spectroscopic survey, one alternative use of our method of identifying similar spectra is to test the consistency of the results. When applying our method, stars with similar spectra should have similar atmospheric parameters, at least within the thresholds of 200 K in Teff, 0.3 dex in log g, and 0.2 dex in [Fe/H]. Furthermore, comparison with reference stars can identify particularly problematic regions of the parameter space where analysis methods do not deliver accurate parameters.
Using the blind method to identify spectra similar to reference stars, we can test the catalogues introduced in 2.2.3. For each reference spectra, we calculated the bias and the interquar-tile range (IQR) of the parameters. The bias is the absolute deviation between the median value of a given stellar parameter and the corresponding value for the reference spectra. The IQR provides a measure of the dispersion of the values in a specific region of the parameter space. Figure 10 illustrates the case for a solar spectrum. Although the method does not select pure samples, as discussed before, Fig. 10 shows how the bias and dispersion change between catalogues. With such a diagnosis, it is possible to quickly select cases for detailed investigation with the aim of identifying the factors that limit the quality of the results.
Figure 11 illustrates the overall comparison. Ideally, a highquality catalogue should have both high accuracy and high precision, namely, a low bias and low IQR within the limits that the method can provide. In general, the biases behave similarly in all four catalogues. The values look particularly worrying for Teff around 5500 K and for log g typical of subgiants (log g ∼ 3.5) and bright giants (log g < 2.0). In this case, we cannot exclude problems in the adopted reference values. For metallicities, the biases increase for metal-poor stars with [Fe/H] < −2.5 and metal-rich giants with [Fe/H] >+0.3.
The plots of IQR ranges in Fig. 11 show where each catalogue has issues related to precision, that is, where parameters of stars with similar spectra tend to be different. Unlike the bias case, the precision evaluation is independent of the reference values. Regimes where the catalogues have a low precision level include cool stars (Teff < 4000 K), bright giants (log g < 1.5), and metal-poor stars (in particular for StarHorse2 and XP-LAMOST, already below [Fe/H] < −0.5). The bias and IQR values are tabulated in Appendix A.
 |
Fig. 11 Comparison of four large catalogues of stellar parameters. Spectra similar to the reference stars were selected using our blind method. The median biases of these samples are plotted as a function of the parameters of the reference stars on the top row. The bottom row shows the median interquartile range (IQR) as a function of the parameters. Low IQR indicates a high level of precision and low bias indicates a high level of accuracy. |
5 Conclusions
This work is the first in a series of papers related to the CHESS pipeline and our project to analyse the UVES spectra of FGK-type stars with high precision and high accuracy. For that purpose, the pipeline will rely on the differential analysis method using a series of reference stars that have accurate parameters distributed over the parameter space. In this paper, we present and discuss our method for finding similar stars based purely on their spectra. The performance of the method was tested and calibrated using catalogues of atmospheric parameters available in the literature. Our main findings can be summarised as follows:
Identifying the correct astrophysical sources that correspond to each UVES spectrum proved to be a significant challenge due to inconsistencies in the metadata of the files. As a result, we strongly recommend that observatories and data archives implement standardised formats for recording object coordinates and identifiers in a way that can ensure the long-term utility of their datasets;
We used the dimensionality-reduction algorithm t-SNE to create 2D projection maps of our sample using their spectra as the multi-dimensional data. We tested the method using six spectral regions and found that the morphologies of the maps are different, but their overall characteristics are the same. Giants and dwarfs are well separated, with dwarfs distributed according to a gradient of temperature and giants according to a gradient of metallicities. Smaller groups of stars can also be identified, including a group of Cepheids, one of bright giants, and one of peculiar globular cluster stars;
To mitigate the class imbalance when identifying similar stars, we applied t-SNE in two steps: the first iteration separated the main groups of interest in our sample (giants, dwarfs, and metal-poor stars) and the second iteration was applied within these groups, using a smaller value for the perplexity, to create tighter groups in the projected space;
Using the GES catalogue of stellar parameters, we calibrated a metric focussed on spectra similarities that allows the identification of similar spectra surrounding a given reference in the projection map. The stars identified in this way have parameters within 200 K in Teff, 0.3 dex in log g, and 0.2 dex in [Fe/H]. The similarity threshold can be adjusted depending on the balance between completeness and purity needed in the selection;
Tests using our own differential analysis showed that with our choice of spectral metric, we were able to achieve completeness between 74–98% and typical purity between 39–54% (with one case of very low purity, around 8%);
Our method can also be used to test the precision and accuracy of large catalogues of stellar parameters. When testing GES, XP-LAMOST, GaiaXGBoost, and StarHorse2, we found a generally strong and rather worrying bias in the log g values for subgiants (log g∼ 3.5) and for stars with Teff ∼ 5500 K. However, we cannot exclude the fact that the issue lies with the choice of reference stars. The biases are also large for cool stars (Teff< 4000 K) and for metal-poor stars ([Fe/H] < –0.5);
We found the level of precision characterising these cata logues to decrease for cool stars (Teff < 4000 K), bright giants (log g < 1.5), and metal-poor stars (in particular, for StarHorse2 and XP-LAMOST, already below [Fe/H] < −0.5).
This type of analysis, aimed at identifying similar stars, is a crucial step in the CHESS pipeline. It will enable efficient selection of target stars for precise differential analyses in future works.
Acknowledgements
We thank the referee for the fast and constructive report. J. E. Martínez Fernández, S. Özdemir, and R. Smiljanic acknowledge support from the National Science Centre, Poland, project 2019/34/E/ST9/00133. MLLD acknowledges Agencia Nacional de Investigación y Desarollo (ANID), Chile, Fondecyt Postdoctorado Folio 3240344. MLLD also acknowledges ANID Basal Project FB210003. Based on data obtained from the ESO Science Archive Facility with DOI: https://doi.eso.org/10.18727/archive/50 (Percheron & Hanuschik 2020). This research has made use of: NASA’s Astrophysics Data System Bibliographic Services; the SIMBAD database, operated at CDS, Strasbourg, France; the VizieR catalogue access tool, CDS, Strasbourg, France. The original description of the VizieR service was published in Ochsenbein et al. (2000). This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
References
- Alexander, C. M. O. 2019, Geochim. Cosmochim. Acta, 254, 277 [CrossRef] [Google Scholar]
- Anders, F., Khalatyan, A., Queiroz, A. B. A., et al. 2022, A&A, 658, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andrae, R., Rix, H.-W., & Chandra, V. 2023, ApJS, 267, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Bedell, M., Meléndez, J., Bean, J. L., et al. 2014, ApJ, 795, 23 [Google Scholar]
- Blanco-Cuaresma, S. 2019, MNRAS, 486, 2075 [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., & Jofré, P. 2014, A&A, 569, A111 [CrossRef] [EDP Sciences] [Google Scholar]
- Boyajian, T. S., von Braun, K., van Belle, G., et al. 2013, ApJ, 771, 40 [Google Scholar]
- Bragaglia, A., Alfaro, E. J., Flaccomio, E., et al. 2022, A&A, 659, A200 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brucalassi, A., Tsantaki, M., Magrini, L., et al. 2022, Exp. Astron., 53, 511 [CrossRef] [Google Scholar]
- Candebat, N., Sacco, G. G., Magrini, L., et al. 2024, A&A, 692, A228 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Creevey, O. L., Thévenin, F., Berio, P., et al. 2015, A&A, 575, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [Google Scholar]
- Dekker, H., D’Odorico, S., Kaufer, A., Delabre, B., & Kotzlowski, H. 2000, SPIE Conf. Ser., 4008, 534 [Google Scholar]
- Fabbro, S., Venn, K. A., O’Briain, T., et al. 2018, MNRAS, 475, 2978 [Google Scholar]
- Gaia Collaboration (Creevey, O. L., et al.) 2023a, A&A, 674, A39 [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023b, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Allende Prieto, C., Holtzman, J. A., et al. 2016, AJ, 151, 144 [Google Scholar]
- Gilmore, G., Randich, S., Worley, C. C., et al. 2022, A&A, 666, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giribaldi, R. E., & Smiljanic, R. 2023, Exp. Astron., 55, 117 [NASA ADS] [CrossRef] [Google Scholar]
- Giribaldi, R. E., da Silva, A. R., Smiljanic, R., & Cornejo Espinoza, D. 2021, A&A, 650, A194 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giribaldi, R. E., Van Eck, S., Merle, T., et al. 2023, A&A, 679, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guiglion, G., Matijevič, G., Queiroz, A. B. A., et al. 2020, A&A, 644, A168 [EDP Sciences] [Google Scholar]
- Hanke, M., Hansen, C. J., Koch, A., & Grebel, E. K. 2018, A&A, 619, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, W. E. 1996, AJ, 112, 1487 [Google Scholar]
- Hegedűs, V., Mészáros, S., Jofré, P., et al. 2023, A&A, 670, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heiter, U., Lind, K., Bergemann, M., et al. 2021, A&A, 645, A106 [EDP Sciences] [Google Scholar]
- Hinkel, N. R., Young, P. A., Pagano, M. D., et al. 2016, ApJS, 226, 4 [CrossRef] [Google Scholar]
- Holtzman, J. A., Shetrone, M., Johnson, J. A., et al. 2015, AJ, 150, 148 [Google Scholar]
- Hourihane, A., François, P., Worley, C. C., et al. 2023, A&A, 676, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Howell, S. B., Sobeck, C., Haas, M., et al. 2014, PASP, 126, 398 [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunt, E. L., & Reffert, S. 2024, A&A, 686, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jin, S., Trager, S. C., Dalton, G. B., et al. 2024, MNRAS, 530, 2688 [NASA ADS] [CrossRef] [Google Scholar]
- Jofré, P., Heiter, U., Worley, C. C., et al. 2017, A&A, 601, A38 [Google Scholar]
- Jönsson, H., Allende Prieto, C., Holtzman, J. A., et al. 2018, AJ, 156, 126 [Google Scholar]
- Joyce, M., & Tayar, J. 2023, Galaxies, 11, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Karinkuzhi, D., Van Eck, S., Jorissen, A., et al. 2021, A&A, 654, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kiman, R., Brandt, T. D., Faherty, J. K., & Popinchalk, M. 2024, AJ, 168, 126 [Google Scholar]
- Kupka, F., & Muthsam, H. J. 2017, Liv. Rev. Computat. Astrophys., 3, 1 [Google Scholar]
- Lebzelter, T., Heiter, U., Abia, C., et al. 2012, A&A, 547, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Li, X., & Lin, B. 2023, MNRAS, 521, 6354 [NASA ADS] [CrossRef] [Google Scholar]
- Li, Z., Zhao, G., Chen, Y., Liang, X., & Zhao, J. 2022, MNRAS, 517, 4875 [NASA ADS] [CrossRef] [Google Scholar]
- Li, C.-q., Shi, J.-r., Yan, H.-l., et al. 2024, ApJS, 273, 18 [Google Scholar]
- Lind, K., & Amarsi, A. M. 2024, ARA&A, 62, 475 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, C., Fu, J., Shi, J., et al. 2020, arXiv e-prints [arXiv:2005.07210] [Google Scholar]
- Lodders, K. 2021, Space Sci. Rev., 217, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Magrini, L., Randich, S., Friel, E., et al. 2013, A&A, 558, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Matijevič, G., Chiappini, C., Grebel, E. K., et al. 2017, A&A, 603, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mayor, M., Pepe, F., Queloz, D., et al. 2003, The Messenger, 114, 20 [NASA ADS] [Google Scholar]
- McKenzie, M., Yong, D., Marino, A. F., et al. 2022, MNRAS, 516, 3515 [NASA ADS] [CrossRef] [Google Scholar]
- Nepal, S., Guiglion, G., de Jong, R. S., et al. 2023, A&A, 671, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H. W., Ho, A. Y. Q., & Zasowski, G. 2015, ApJ, 808, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Nissen, P. E., & Gustafsson, B. 2018, A&A Rev., 26, 6 [NASA ADS] [CrossRef] [Google Scholar]
- O’Briain, T., Ting, Y.-S., Fabbro, S., et al. 2021, ApJ, 906, 130 [CrossRef] [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pancino, E., Lardo, C., Altavilla, G., et al. 2017, A&A, 598, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Percheron, I., & Hanuschik, R. 2020, UVES reduced data obtained by standard ESO pipeline processing [Google Scholar]
- Pinsonneault, M. H., Zinn, J. C., Tayar, J., et al. 2025, ApJS, 276, 69 [NASA ADS] [CrossRef] [Google Scholar]
- Plez, B. 2012, Turbospectrum: Code for spectral synthesis, Astrophysics Source Code Library [record ascl:1205.004] [Google Scholar]
- Queiroz, A. B. A., Anders, F., Santiago, B. X., et al. 2018, MNRAS, 476, 2556 [Google Scholar]
- Ramírez, I., Meléndez, J., Bean, J., et al. 2014, A&A, 572, A48 [Google Scholar]
- Randich, S., Gilmore, G., Magrini, L., et al. 2022, A&A, 666, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Recio-Blanco, A., Bijaoui, A., & de Laverny, P. 2006, MNRAS, 370, 141 [Google Scholar]
- Romaniello, M., Arnaboldi, M., Barbieri, M., et al. 2023, The Messenger, 191, 29 [NASA ADS] [Google Scholar]
- Różńnski, T., Niemczura, E., Lemiesz, J., Posiłek, N., & Różńnski, P. 2022, A&A, 659, A199 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sandford, N. R., Weisz, D. R., & Ting, Y.-S. 2023, ApJS, 267, 18 [Google Scholar]
- Sizemore, L., Llanes, D., Kounkel, M., et al. 2024, AJ, 167, 173 [Google Scholar]
- Smiljanic, R., Korn, A. J., Bergemann, M., et al. 2014, A&A, 570, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soubiran, C., Brouillet, N., & Casamiquela, L. 2022, A&A, 663, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soubiran, C., Creevey, O. L., Lagarde, N., et al. 2024, A&A, 682, A145 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steinmetz, M., Matijevič, G., Enke, H., et al. 2020, AJ, 160, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Tabernero, H. M., Marfil, E., Montes, D., & González Hernández, J. I. 2022, A&A, 657, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Traven, G., Matijevič, G., Zwitter, T., et al. 2017, ApJS, 228, 24 [NASA ADS] [CrossRef] [Google Scholar]
- van der Maaten, L., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 2579 [Google Scholar]
- Van der Swaelmen, M., Viscasillas Vázquez, C., Magrini, L., et al. 2024, A&A, 690, A276 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Worley, C. C., Jofré, P., Rendle, B., et al. 2020, A&A, 643, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Worley, C. C., Smiljanic, R., Magrini, L., et al. 2024, A&A, 684, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Xiang, M., Ting, Y.-S., Rix, H.-W., et al. 2019, ApJS, 245, 34 [Google Scholar]
- Zhang, X., Green, G. M., & Rix, H.-W. 2023, MNRAS, 524, 1855 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, G., Zhao, Y.-H., Chu, Y.-Q., Jing, Y.-P., & Deng, L.-C. 2012, Res. Astron. Astrophys., 12, 723 [NASA ADS] [CrossRef] [Google Scholar]
- Zucker, S. 2003, MNRAS, 342, 1291 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A Catalogue comparison summary table
Appendix B Projection maps for all the spectral regions with data from all the catalogues
 |
Fig. B.1 Projection maps for the region R2 coloured with the atmospheric parameters of four different catalogues. |
 |
Fig. B.2 Projection maps for the region R3 coloured with the atmospheric parameters of four different catalogues. |
 |
Fig. B.3 Projection maps for the region R4 coloured with the atmospheric parameters of four different catalogues. |
 |
Fig. B.4 Projection maps for the region R5 coloured with the atmospheric parameters of four different catalogues. |
 |
Fig. B.5 Projection maps for the region R6 coloured with the atmospheric parameters of four different catalogues. |
Appendix C Histograms of Sthresh for all regions and all catalogues
 |
Fig. C.1 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the GES catalogue. |
 |
Fig. C.2 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the XGBoost catalogue. |
 |
Fig. C.3 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the StarHorse2 catalogue. |
 |
Fig. C.4 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the XP-LAMOST catalogue. |
All Tables
All Figures
|
Fig. 1 Object identification workflow for discovering the source ID of each spectrum. The steps for crossmatching with SIMBAD and with the Gaia DR3 catalogue are depicted in detail. |
| In the text | |
|
Fig. 2 Kiel diagram, colour-coded by metallicity, showing the stellar parameters of the reference stars used in this work. The O- and B-type stars are not shown to facilitate the visualisation. |
| In the text | |
|
Fig. 3 Wavelength range of each of the >7000 spectra in our sample, limited to the interval between 400–700 nm. Each spectra is represented as a horizontal line. The shaded regions (R1 to R6) indicate the selected regions to be analysed. Some of the empty spaces correspond to artifacts in the spectra or regions of telluric lines that were masked. |
| In the text | |
|
Fig. 4 t-SNE projection map of the region R2 colour-coded by the atmospheric parameters from the GES catalogue, Teff (left), log g (centre), and [Fe/H] (right). The axes do not have direct physical meaning as they are not linear combinations of the original data; they are simply indicative of relative neighbourhood of the data points in these projections. |
| In the text | |
|
Fig. 5 Distribution of distances in the t-SNE projection for stars with similar atmospheric parameters to the Sun, using the GES catalogue for the sample and spectral region R2. The absolute values of the differences in Teff, log g, and [Fe/H] are shown in the left, centre, and right panels, respectively. In each panel, the red horizontal line indicates the adopted parameter thresholds; green points represent the similar spectra which fulfil all three of the parameter thresholds, and the green vertical dashed line marks the 75th percentile of their distances from the reference. |
| In the text | |
|
Fig. 6 Distribution of similarity score values of the sample surrounding the Sun. The lower the similarity score, the more similar is the stellar spectrum to the solar spectrum. The green points have the same meaning as in Fig. 5. Orange points are all the stars within the 75th percentile of distances defined in Fig. 5. The orange horizontal dashed line indicates the 75th percentile of the distribution of similarity scores. Note that the total range of similarity scores is much larger; the figure shows only nearby stars. |
| In the text | |
|
Fig. 7 Each subplot shows a histogram of similarity scores thresholds obtained (as shown in Fig. 6) for the references in the region R2, but computed using different percentiles (25th, 50th, 75th, and 90th). The red curve represents a smoothed distribution obtained using a Gaussian kernel density estimation (KDE). |
| In the text | |
|
Fig. 8 Completeness (blue), purity (orange), and F-score (black) as a function of the Sthresh used to select spectra. The smoothed F-score curve (purple) is used to select its maximum value (red dashed line) representing the best trade-off between completeness and purity. |
| In the text | |
|
Fig. 9 Comparison of similar spectra to a reference spectrum of the Sun (red line), obtained in two different ways: using the GES catalogue as reference (top panel) and the selected sample using our methodology (bottom panel). Both panels display the corresponding normalized spectra for the region R2 with different colours to show the different spectra. |
| In the text | |
|
Fig. 10 Violin plots showing the comparison between the stellar parameters of stars with spectra similar to the Sun in four catalogues.The red dashed line indicates the reference value of the parameter and the yellow coloured area is the region within 200 K in Teff(top panel), 0.3 dex in log g(mid panel), and 0.2 dex in [Fe/H] (bottom panel) from the solar parameters. |
| In the text | |
|
Fig. 11 Comparison of four large catalogues of stellar parameters. Spectra similar to the reference stars were selected using our blind method. The median biases of these samples are plotted as a function of the parameters of the reference stars on the top row. The bottom row shows the median interquartile range (IQR) as a function of the parameters. Low IQR indicates a high level of precision and low bias indicates a high level of accuracy. |
| In the text | |
|
Fig. B.1 Projection maps for the region R2 coloured with the atmospheric parameters of four different catalogues. |
| In the text | |
|
Fig. B.2 Projection maps for the region R3 coloured with the atmospheric parameters of four different catalogues. |
| In the text | |
|
Fig. B.3 Projection maps for the region R4 coloured with the atmospheric parameters of four different catalogues. |
| In the text | |
|
Fig. B.4 Projection maps for the region R5 coloured with the atmospheric parameters of four different catalogues. |
| In the text | |
|
Fig. B.5 Projection maps for the region R6 coloured with the atmospheric parameters of four different catalogues. |
| In the text | |
|
Fig. C.1 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the GES catalogue. |
| In the text | |
|
Fig. C.2 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the XGBoost catalogue. |
| In the text | |
|
Fig. C.3 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the StarHorse2 catalogue. |
| In the text | |
|
Fig. C.4 Histogram of the percentiles (25th, 50th, 75th, and 90th) of similarity scores for all spectral regions using the XP-LAMOST catalogue. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.