| Issue |
A&A
Volume 706, February 2026
|
|
|---|---|---|
| Article Number | A334 | |
| Number of page(s) | 19 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202556830 | |
| Published online | 17 February 2026 | |
The SRG/eROSITA all-sky survey: The morphologies of clusters of galaxies
II. The intrinsic distributions of morphological parameters
1
Max-Planck-Institut für extraterrestrische Physik Gießenbachstraße 1 85748 Garching, Germany
2
INAF, Osservatorio di Astrofisica e Scienza dello Spazio via Piero Gobetti 93/3 40129 Bologna, Italy
3
IRAP, CNRS, UPS, CNES 14 Avenue Edouard Belin 31400 Toulouse, France
4
Univ. Grenoble Alpes, CNRS, Grenoble INP, LPSC-IN2P3, 53 Avenue des Martyrs 38000 Grenoble, France
5
Institute for Frontiers in Astronomy and Astrophysics, Beijing Normal University Beijing 102206, China
6
Argelander-Institut für Astronomie (AIfA), Universität Bonn Auf dem Hügel 71 53121 Bonn, Germany
★ Corresponding author.
Received:
12
August
2025
Accepted:
30
December
2025
Abstract
X-ray-selected surveys of clusters of galaxies have been reported to contain more regular cool core clusters compared to samples selected using the Sunyaev-Zel’dovich (SZ) effect. Morphology population studies on X-ray-selected clusters will be biased without taking into account selection, as cool cores are more easily detected at low redshifts, but can be mistaken for point sources at high redshifts. eROSITA, aboard Spectrum Roentgen Gamma (SRG), found over 12 000 optically identified clusters of galaxies in its first survey, eRASS1. Taking account of the selection function obtained from simulations, using a Bayesian framework we obtained the intrinsic distribution of morphological parameters, including the concentration, central density, cuspiness, ellipticity, and slosh. We constructed scaling relations for the parameters as a function of redshift and luminosity, and studied their distribution within redshift or luminosity bins. We find that the concentration in a scaled aperture evolves positively with luminosity, similarly to the central scaled density, and negatively with redshift. When using a fixed aperture, its evolution with luminosity is lower, but also dependent on the choice of cluster centre. The mean cluster ellipticity does not significantly evolve with redshift or luminosity. eRASS1 clusters show indications of higher concentrations compared to SZ-selected objects, even after taking the X-ray selection into account. This suggests that if our selection function model is correct, SZ-selected clusters may also suffer from morphological selection effects. We compared different models for the parameter distribution in bins of redshift and luminosity. The distribution of concentration and ellipticity is generally consistent with a normal one, but other parameters such as the central density and cuspiness strongly favour more complex distributions. However, modelling of all clusters as a single population generally shows a preference for non-normal distributions.
Key words: galaxies: clusters: intracluster medium / X-rays: galaxies: clusters
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open access funding provided by Max Planck Society.
1. Introduction
The morphology of galaxy clusters is a useful probe for understanding their dynamical state. As clusters form from the hierarchical merger of galaxies, groups, and clusters (e.g. Springel et al. 2005), the cluster dynamical state is tied to their evolutionary history and is important for understanding how this hierarchical growth occurs (e.g. Evrard et al. 1993; Wong & Taylor 2012). Dynamical state can affect many aspects of clusters, including thermodynamic properties (e.g. Valdarnini & Sarazin 2021) and metallicities (e.g. Lovisari & Reiprich 2019). It also affects cluster mass measurements, a key quantity for studying cluster populations (e.g. Pratt et al. 2019). For example, dynamical state affects hydrostatic measurements, where the cluster is assumed to be in hydrostatic equilibrium (e.g. Biffi et al. 2016), cluster galaxy kinematics, which can be affected by mergers (e.g. Takizawa et al. 2010), and X-ray scaling relations, where luminosity in particular can be affected by the central gas density (e.g. Edge & Stewart 1991).
The morphology of clusters can be characterised by a number of different parameters, including concentration (Santos et al. 2008), central density (e.g. Lovisari et al. 2017), power ratios (Buote & Tsai 1995), centroid shifts (e.g. Böhringer et al. 2010), ellipticity (e.g. Ghirardini et al. 2022), photon asymmetry (Nurgaliev et al. 2013), Gini coefficient (Lotz et al. 2004), and cuspiness (Vikhlinin et al. 2007). These parameters are sensitive to different aspects of a cluster’s morphology. For example, the concentration, central density, and Gini coefficient are indicators of a cool core. Power ratios, centroid shifts, and photon asymmetry are sensitive to asymmetries in the 2D shape.
The extended ROentgen Survey with an Imaging Telescope Array (eROSITA; Predehl et al. 2021) aboard the Spectrum Roentgen Gamma (SRG) observatory (Sunyaev et al. 2021) is an instrument designed to survey the X-ray sky. The resulting catalogue of sources in the western Galactic hemisphere from its first sky survey was published in Merloni et al. (2024). From these sources, Bulbul et al. (2024), hereafter B24, created a catalogue of over 12 000 optically identified (Kluge et al. 2024) clusters of galaxies. In Sanders et al. (2025), hereafter Paper I, we studied the morphology of these clusters by measuring morphological parameters, including those listed above. Where possible, these parameters, including the concentration, central density, cuspiness, and ellipticity, were measured using a forward-modelling technique, where the instrumental point spread function (PSF) and the sky background can be accounted for. For measurements that are sensitive to the exact location of the cluster, we measured both an X-ray-peak-centred quantity and one where the cluster position is included in the model. Paper I also measures new forward-modelled parameters including slosh, which measures how asymmetric a cluster is, and multipole magnitudes, which are similar to power ratios.
Here, we build upon the work in Paper I to model the intrinsic distributions of morphological parameters, taking into account the selection effects present in the survey. For example, in Paper I we describe how more concentrated clusters are more easily detected at low redshifts, as flatter objects can be mistaken for background variation, while the opposite is true at the highest redshifts, where peaked clusters can be misidentified as point sources. To measure the true distribution, we fitted a model in which selection effects are properly included within a Bayesian framework.
Section 2 describes the selection function model. The cluster subsamples and morphological parameters we analysed are discussed in Section 3. The scaling relation model and results are given in Section 4.1. We describe models using complex non-normal distributions in Section 5. Section 6 discusses our results and our conclusions are given in Section 7.
In this paper log refers to log10, while ln refers to loge. Uncertainties are at the 1σ confidence level unless otherwise specified. We assumed a cosmology with H0 = 70 km s−1 Mpc−1, Ωm = 0.3, and ΩΛ = 0.7. When computing the halo mass function, we assumed σ8 = 0.8159.
2. Modelling of selection functions
Studying the intrinsic properties of the distribution of a parameter requires a selection function accounting for that parameter. The standard selection functions for eROSITA clusters (Clerc et al. 2024) marginalise over the distribution of morphology included in the simulations of Comparat et al. (2020), including variation in ellipticity and realistic input profiles. The selection function is also computed including a morphological parameter EM0, which is the average emission measure within 0.025R500 and is related to the central density. However, as we investigated different morphological parameters which are not trivially converted to EM0, and these parameters can affect detection in different ways, it was necessary to make further simulations of clusters where these parameters were measured, and build models of the selection function from the results.
The simulations described in Paper I did not exactly match the detection procedure used in the eROSITA catalogue because the ermldet detection software (Brunner et al. 2022) was used in imaging mode, rather than photon mode. We improved our simulations to instead produce event lists so that the detection software could use photon mode, as tests showed differences in the obtained ℒext values, affecting the cuts in selection. The simulations are described in Appendix A and the selection function model in Appendix B.
3. Fitted subsamples and parameters
We took our input cluster sample from the eROSITA cosmology sample (B24), which already applies a cut to the cluster extension likelihood, ℒext > 6, and redshift, resulting in a purer set of objects. This likelihood was measured for each object with the detection likelihood (ℒdet) by ermldet. From this sample we chose a brighter subsample, to avoid sources with large uncertainties on their morphological parameters and to avoid bias caused by preferential detection of steeply peaked cluster with high concentrations (Paper I). We note, however, that we used the redshift BEST_Z from the catalogue rather than the photometric redshift, unlike what was done for the cosmology analysis. Other information taken from the catalogue were the cluster initial fit positions, redshifts, L500, and R500.
Rather than use ℒdet to select brighter objects, we instead cut using the number of counts in an 800 kpc aperture, which is less affected by cluster concentration (See section 6.2 and figures 10 and 11 in Paper I). At our 50 count cut, 68% of the complete sample have 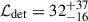 , well above the minimum value of 5, while the corresponding range of
, well above the minimum value of 5, while the corresponding range of 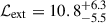 , which is less significantly above the threshold of 6 for the cosmology sample. Taking the cosmology subsample and a minimum of 50 counts, so as not to be strongly affected by the standard initial ℒdet threshold, results in a subsample of 2789 clusters (Table 1). We also made a second subsample for consistency checks with a cut of 100 counts.
, which is less significantly above the threshold of 6 for the cosmology sample. Taking the cosmology subsample and a minimum of 50 counts, so as not to be strongly affected by the standard initial ℒdet threshold, results in a subsample of 2789 clusters (Table 1). We also made a second subsample for consistency checks with a cut of 100 counts.
Subsamples from the first eROSITA all sky survey (eRASS1).
In Paper I we measured a large number of parameters for each cluster. We also described the various biases in measuring the parameters and showed that there are large systematic errors for all the non-forward-modelled parameters, which vary with redshift and luminosity. Rather than examine the intrinsic distributions for all these parameters, we restricted ourselves to the forward-modelled parameters listed in Table 2. For reasons of space we do not show the results for M1 − M4 in all cases. The forward-modelled parameters were obtained through MBProj2D Markov chain Monte Carlo (MCMC) analyses (B24; Paper I), which allowed us to obtain the covariance between parameter values and luminosity. The exception to these are the parameters ϵ, H and M1 − M4, where we took the luminosity and morphology chains from separate runs and assumed them independent. This was done because a luminosity within a particular radius cannot easily be extracted using MBProj2D if the cluster is not circular. At the minimum 50 count threshold, median uncertainties are around 0.23 on the concentrations. They are 0.77, 0.55, 0.25, and 0.17 for ns, 0, ns, 0*, n50, and n50*, respectively. For α, α*, α50, and α50*, they are 1.1, 0.9, 0.9, and 0.7, respectively. For ϵ the uncertainty is 0.36 and for H, 0.31.
Summary of parameters.
4. Morphology scaling relations
4.1. Model
We studied how the morphological parameters evolve with redshift and luminosity. Our procedure followed that described by Bahar et al. (2022), where we parametrised the parameters as a scaling relation with luminosity and redshift. Additionally, here we also allowed the distribution width to vary. We restricted ourselves to redshift and luminosity evolution as these are closely connected to observables and to keep the number of analyses manageable. Despite the large scatter between the scaling of cluster luminosity and mass (e.g. Pratt et al. 2009), our results for luminosity scaling should offer insight into the scaling with mass. We constrained the scaling relation parameters, taking into account the uncertainty and covariance between luminosity and parameter value of each cluster, the likelihood for a cluster to be detected given those parameters (the selection function), and the luminosity distribution of clusters at each redshift.
We assumed that a property of a cluster, Y (e.g. concentration), is related to another quantity X (here X, for consistency with Bahar et al. (2022), is always log L500 and is in units of log erg s−1 in the rest frame 0.2-2.3 keV band) and redshift by
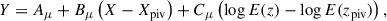 (1)
(1)
where the redshift evolution is E(z) = H(z)/H0, Xpiv is the X-ray luminosity pivot value, 44, and zpiv is the pivot redshift, 0.3 (which is close to the sample mean). The scaling relation is described by parameters Aμ, Bμ, and Cμ. We assumed that the distribution about this relation has a normal distribution with width given by a similar scaling relation
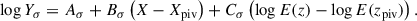 (2)
(2)
By using log Yσ we avoided negative widths, but we also imposed a minimum value on log Yσ of −1.5, to prevent unnaturally narrow distributions. Therefore, we allowed the width and mean of the distribution to vary with both redshift and luminosity. We normalised the probability density functions (PDFs) to ensure that the integral was unity within the integration ranges of our analysis. Integration was done by summing over a fixed grid, using 100 bins between X = 42 and 46. In the Y dimension, we used 200 bins over ranges −2 ≤ c80 − 800 ≤ 0, and −2 ≤ c500 ≤ 0. We used 500 bins over ranges −7 ≤ n50 ≤ 0, −2.0 ≤ ns ≤ 2.5, −4 ≤ α ≤ 2, and −4 ≤ α50 ≤ 2. For H, ϵ, and M1 to M4 we used 100 bins between 0 and 1. To study the impact of allowing a change in scatter, we also repeated the analysis fixing Bσ and Cσ to be 0.
The joint probability of the measured values 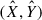 for the observables X and Y is given by
for the observables X and Y is given by
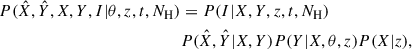 (3)
(3)
where P(I|X, Y, z, t, NH) is the selection function (calculated from the fitted model in Appendix B), 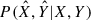 is the measurement uncertainty on the X and Y, and P(Y|X, θ, z) was calculated from the scaling relation and its width (parameters θ).
is the measurement uncertainty on the X and Y, and P(Y|X, θ, z) was calculated from the scaling relation and its width (parameters θ).
The cosmological distribution of the observable X was accounted for using
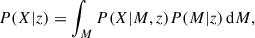 (4)
(4)
where P(X|M, z) was calculated from the Chiu et al. (2022) luminosity-mass scaling relation (their equation 67 and its measured width) and P(M|z) was calculated from the Tinker et al. (2008) mass function.
To calculate the likelihood for a single cluster we marginalised over the nuisance variables (X, Y), to give
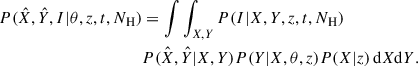 (5)
(5)
To account for the cluster being detected given observables Xi and Yi we used Bayes theorem, giving the likelihood for cluster i
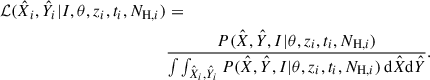 (6)
(6)
The total log likelihood was then computed by summing the log likelihood for all the clusters in the sample.
While we followed the method of Bahar et al. (2022), there were some differences in our analysis. Our selection function also accounted for the morphological parameter being studied (except for the 2D shape parameters, like ellipticity). We allowed the width of the scaling relation to vary both with redshift and luminosity. The joint measurement uncertainties on the morphological parameter and luminosity were calculated from the MCMC chains, and binned using our integration grid to produce 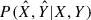 .
.
4.2. Results
4.2.1. Fits and posterior probability distributions
We ran the analysis for the scaling relations of several parameters with X-ray luminosity, the concentration (c80 − 800 and c500), inner density (n50 and ns, 0) and inner density slope (α50 and α), for both the fit and peak centred versions. We also did the same analysis for the ellipticity (ϵ) and slosh (H). To demonstrate the fit to the data, we show in Fig. 1 the average maximum likelihood scaling relation combined with the selection function and mass function for the clusters, ln⟨P(I|X, Y, z, t, NH)P(Y|X, θ, z)P(X|z)⟩, and the average selection function, ⟨P(I|X, Y, z, t, NH)⟩, compared to data points for the concentration, c500, and scaled central density, ns, 0. The best fitting model appears to be a reasonable fit to the data points. The analysis was also repeated assuming no evolution in width (Bσ = Cσ = 0) and for the 100 count minimum subsample.
 |
Fig. 1. Clusters with > 50 counts plotted on PDFs combining the maximum likelihood scaling relation, selection function, and mass function. The clusters in four redshift bins are shown, plotting the concentration, c500 (left), and scaled density, ns, 0 (right). The images show the average maximum likelihood scaling relation combined with the selection function and mass function for the clusters in the redshift ranges, with the solid contour lines at difference levels of −2, −4, −6, −8, and −10 from the maximum. The dashed contour lines show the average selection function, at levels of 0.05, 0.2, 0.4, 0.6, 0.8, and 0.95. |
Figure 2 shows the posterior probability contours for the evolution of the mean and its width, for both the standard and peak-centred versions of the parameters. Tables of the values and corner plots of the other posterior parameter distributions are found in Appendix C. To better understand the likely systematic uncertainties, it is useful to compare the results for the two different cluster centres, for the analysis with fixed distribution widths, and for the smaller 100 count subsample.
 |
Fig. 2. Evolution of mean and width for several parameters. Left: confidence contours for the evolution of μ, with the results using the cluster fit positions shown as solid lines and the peak-centred cluster results shown as dashed lines. Right: confidence contours of the evolution of σ. The contours contain 39.3, 67.5, 86.4, and 95% of the MCMC samples. See Appendix C for corner plots of the other parameters. |
4.2.2. Concentration
The concentration at scaled radius, c500, has a value at the pivot point of −0.68, while it is −0.62 for c500*. The model gives positive scaling with X-ray luminosity, where Bμ ∼ 0.2, while there is significant scaling with redshift, with Cμ ∼ −0.6. The width of the distribution prefers negative redshift evolution, if our selection function and measurements are accurate, although its luminosity evolution appears statistically insignificant. There is reasonably good agreement between the c500 and c500* results for the models with and without width evolution, and also the sample with 100 count objects, with c500* having a larger Aμ and smaller Aσ than c500.
For fixed radius concentration, c80 − 800* prefers a pivot value of the mean around 0.1 dex larger than c80 − 800. The analysis did not find convincing evidence for its evolution. The peak centred c80 − 800* is consistent with no luminosity evolution of the mean, while c80 − 800 is consistent with no redshift evolution of it. Any luminosity evolution is smaller than that of c500. The evolution of the width appears mildly significant with negative redshift.
4.2.3. Central density
The central density at scaled radius, ns, 0, shows rather good consistency between its evolutionary parameters for the different analyses, with its Bμ ∼ 0.2 being very similar to that of c500. There is no evidence for mean redshift evolution. The width, however, prefers a positive evolution with luminosity and a negative evolution with redshift, both for ns, 0 and ns, 0*. In contrast, for n50 the model prefers a luminosity evolution which is twice that ns, 0 (Bμ ∼ 0.45), with also positive redshift evolution. The width of the distribution, if allowed to evolve, again prefers to increase with luminosity and decrease with redshift.
4.2.4. Cuspiness
The two cuspiness parameters α and α50 show very similar results. These parameters evolve negatively with luminosity, in contrast with the other parameters. They also show rather strong positive redshift evolution. As for n50, the width of the distribution evolves positively with luminosity and negatively with redshift. We note, however, that the central slope is a more difficult quantity to measure than the density or concentration and is more likely affected by the modelling procedure.
4.2.5. Ellipticity and slosh
The ellipticity scaling relation shows a mean of 0.77, with no evidence for evolution with luminosity or redshift. This mean value is very close to the median ellipticity found in a set of simulations and XMM-Newton observations (Campitiello et al. 2022). The width, however, shows negative evolution with luminosity and positive evolution with redshift, although its uncertainties are large. The slosh parameter prefers a slightly negative or zero mean, although this is affected by the prior of the parameter. Its evolution is consistent with zero in both luminosity and redshift.
5. More complex distributions
The above scaling relation analysis assumed that the distribution of a parameter is normal at each redshift and luminosity. We could have introduced more complex distributions in an evolutionary analysis, but their interpretation becomes complex. Therefore, to investigate more complex distributions, we examined clusters in bins of luminosity and redshift and assumed that the parameter distributions are constant within these bins.
In this analysis we used four different distributions, a normal distribution, a skew normal distribution, a dual normal, and an interpolated model. Priors of the parameters are listed in Table 3. The normal distribution model has the mean (μ) and width (σ) as free parameters. The skew normal distribution has an additional parameter for the skew, K. The dual normal distribution consists of two normal components. In addition to their means and widths, the components have relative weights f and 1 − f, where f is a free parameter between 0 and 1.
Priors used for fitting distributions in redshift and luminosity bins.
For the interpolated model, we chose a set of six or eight parameter values which are equally separated in parameter space. The log distribution normalisations at these values were free parameters. Points at intermediate values were calculated using cubic spline interpolation in log space. The overall distribution was normalised to create a PDF. As some parameters are only allowed to be in a given range, we renormalised the PDFs for these parameters and made them 0 outside this range (e.g. 0 to 1 for ϵ and H and −2 to 0 for c500 and c80 − 800, with the same integration grid as in Section 4.1).
The objects studied were in five bins of luminosity and five bins of redshift, fitting the objects in the cosmology sample with more than 50 counts (Table 1). We derived posterior probability distributions and the Bayesian evidence using the UltraNest1 package (Buchner 2021). The detailed resulting parameter distributions can be found in Appendix D.
The standard method for doing model comparison in the Bayesian framework is to compute a Bayes factor, K = P(D|Ma)/P(D|Mb) = Za/Zb, given data, D, and the two models to compare, Ma and Mb. The marginal likelihood for the model, the ‘evidence’ Z, is difficult to compute using MCMC sampling or directly, but can be calculated using nested sampling. In Fig. 3 we show the Bayes factor between the models in the bins of redshift and luminosity for the concentration, central density, cuspiness, ellipticity, slosh, and multipole magnitudes, for both the average centred and peak centred results. The comparison is between each model and the best model with the largest evidence for that particular bin. In order to be able to plot using a log scale, we inverted the scale and plotted 1 − ln(Z/Zbest), so that the best model is shown as 1 and those with less evidence have higher values. Included in the plot are typically used thresholds for changes in evidence, which can be used for ruling out models. For example if a point lies above the line for ‘Strong evidence’, then it has little evidence supporting it, while points which lie below the line for ‘Substantial evidence’ have similar levels of evidence to the best model.
 |
Fig. 3. Comparison of model distributions in bins of redshift and luminosity. We show the difference in Bayesian evidence (the Bayes factor) between each model and the model with the greatest Bayesian evidence, where the models with the greatest evidence are plotted at lower values and the best model has a value of 1. We show typical thresholds for Bayes factors from Kass & Raftery (1995). |
Model comparison using Bayes factors favour simpler models with fewer parameters. However, the chosen priors can strongly affect the results. Here we use non-informative priors to use the data to constrain the average value of the parameter, and given that we do not have any advance knowledge of their distribution shape. There is risk that diluting the parameter space with a too broad non-informative prior may over penalise models, and so we emphasise that our comparisons are between the models combined with their priors.
Examining the concentration distributions, we find that a normal distribution is statistically acceptable in most of the redshift and luminosity bins. Exceptions include the highest luminosity and redshift bins for c500 or 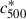 , which prefer dual normal or interpolated models, and for a couple of bins for c80 − 800, although these are not seen for c80 − 800*.
, which prefer dual normal or interpolated models, and for a couple of bins for c80 − 800, although these are not seen for c80 − 800*.
For the scaled density, ns, 0, a normal distribution is often not acceptable, except for high luminosity and redshift ns, 0* bins. Instead, a mixture of interpolated, skew and dual models are preferred. A very similar picture is also seen for n50, with the similar pattern in the same bins. Examining the model distributions (Appendix D), the models appear asymmetric with a sharper edge to one side of the distribution and a narrower core, than a normal distribution would prefer. Typically tails are seen to higher densities in the redshift bins and lower densities in the luminosity bins. For all these density parameters, the peak position evolves with luminosity, similarly to the scaling relation results, while for n50 evolution with redshift is also visible.
The cuspiness parameters, α and α50, show similar results to each other. Almost none of the bins find the normal model acceptable. The distributions (Appendix D) with a fitted cluster centre (α and α50) show two peaks, while those using the cluster peak (α* and α50*) instead show a skewed distribution, although the differences are not obvious in Fig. 3.
The ellipticity does not generally prefer any particular model for the distribution, although the normal distribution is roughly acceptable for most of the bins, although the skew or interpolated model is often better. For slosh, an interpolated model is preferred for in most bins. The picture for M1 to M4 is more complex, although a normal distribution is acceptable for many bins. For M3 and M4 an interpolated model is favoured.
One can also use the assumption that the distributions are the same for the whole sample, with no evolution with redshift or luminosity. Figure 4 compares the Bayes factors of the resulting models for each parameters and shows their PDFs. Concentrations c500 and c500* both prefer complex interpolated models, with two peaks and heavily disfavour a normal distribution, while the evidence for complex distributions is weaker for c80 − 800 and c80 − 800*. The density parameters prefer interpolated or dual-normal models, and disfavour normal models. The central slope parameters also are inconsistent with normal models, preferring dual normal or skewed models, with less evidence for a secondary peak if using the cluster peak centre. Both ellipticity and slosh prefer an interpolated model over a normal model, while the multipole magnitudes are consistent with normal distributions.
 |
Fig. 4. Comparison of different distribution models for the whole sample. Left panel: model comparison, as in Fig. 3, for each parameter, assuming that the clusters have a single distribution. Models with greater evidence have lower values. Right panels: PDFs of each parameter, for each of the model types, coloured as in the left panel. The shaded regions contain 68.27% of the samples. |
6. Discussion
6.1. Comparison with other samples
In Fig. 5 we compare the results for our analysis of eRASS1 clusters with our analysis of 83 clusters from the SZ (Sunyaev-Zel’dovich) effect selected South Pole telescope (SPT) sample observed by Chandra. In addition, we show the distributions for 120 clusters from the Planck early SZ (ESZ) sample, measured using XMM-Newton data by Lovisari et al. (2017). The cluster models used to fit the Chandra data are the same as for our eRASS1 analysis, although the typical exposure times are much longer for the Chandra data and the spatial resolution of the telescope is much better. For this analysis of the radial properties, the centre of the cluster was fixed at the peak of the emission, as in Sanders et al. (2018). The Chandra analysis is discussed further in Paper I. We note that for this analysis the masses and radii for the SPT clusters were taken from the SPT-data (Bleem et al. 2015), rather than derived from the Chandra data. For the XMM-Newton observed clusters we used Planck radii and masses to convert their physical density at 0.02R500 to ns, 0, as in Paper I.
 |
Fig. 5. Comparison of eRASS1 probability densities compared to SPT- and Planck-selected samples. The distribution of the parameters for the Chandra-SPT sample is plotted as a histogram, with the median value indicated by a dashed line. The Planck values are for ESZ clusters from Lovisari et al. (2017). The model distribution for the eRASS1 clusters in the high luminosity bin is plotted (log LX = 44.3 − 45.6, fitted using interpolated model). For those parameters where we fitted a scaling relation (Appendix C), we computed matched PDFs given the redshift and luminosities of the SPT and Planck samples. The distributions of parameter values for the bright 300 count cluster eRASS1 subset are also plotted. |
For the eROSITA data we plot the interpolated model distributions in our highest luminosity bin from the analysis in Section 5, which is roughly the luminosity range of the SPT sample. As the Chandra and XMM-Newton measurements are fixed to the cluster peak, we show the peak based measurements for eROSITA. We also include a direct histogram of the values for the subsample of eRASS1 clusters with more than 300 counts. For those parameters where we fitted scaling relations, we compute eRASS1 effective matched PDFs for the SPT and Planck samples, given our scaling relations and the individual X-ray luminosities and redshifts of the SPT and Planck ESZ clusters, where ESZ cluster luminosities were scaled from the values in Lovisari et al. (2020). Planck clusters typically lie at lower redshift than SPT clusters and have a different luminosity or mass distribution, leading to differences between the PDFs.
In Paper I we compare the distribution of parameters in different eRASS1 subsamples with SPT and Planck, finding that the eRASS1 clusters are more concentrated. The result here is similar to that found for the raw concentration distributions, even though the effect of selection is accounted for. For c500, the difference between the eRASS1 SPT-matched PDF and the SPT median is around 0.23, or 70% more flux on average in the inner aperture for eRASS1 objects compared to SPT. The difference between eRASS1 Planck-matched PDF and Planck median is around 0.25, or 78% more flux inside 0.1R500. We note, however, that there are differences between the concentrations measured for the same clusters. In Paper I we find that the median measurements for c500 are 0.1 dex larger for eRASS1 compared to values from Chandra for SPT clusters and XMM-Newton for Planck clusters. Reasons for the differences can include different point source masking and unresolved point sources, cluster radii, cluster backgrounds, PSF calibration, and the larger eROSITA field of view. This accounts for around half the difference, giving concentrations larger by 0.13 − 0.15 in eRASS1 compared to the SZ-selected objects after this is subtracted (around 35–41% more flux).
Despite the differences seen in the concentration, we see very little difference between the peak central density, ns, 0*, for eRASS1 and the SZ samples. The peak scaling relation density lies almost exactly at the same value as the Planck cluster value. eRASS1 clusters are found to have around 15% lower fluxes than Chandra and XMM (B24; Migkas et al. 2024), although the effect of this on the density should be small (∼0.03 dex). The difference between SPT clusters and eRASS1 clusters is larger for the density at fixed radius, showing a difference of 0.2 dex higher densities at 50 kpc. Although the central density shows reasonable agreement at scaled radius, if the density slope or cuspiness is compared to SZ-cluster measurements, we find values around 0.5 larger for eRASS1 clusters.
The eRASS1 clusters seem to be more concentrated than the SZ samples, despite modelling selection effects on the underlying population. Similarly, the clusters are more steeply peaked in the X-ray band, but in contrast the scaled central densities are consistent. Explanations for the difference in concentration may be that we are either looking at intrinsically different cluster populations, our selection function modelling is inaccurate, or there are differences in observational effects for the samples.
We measured the properties for the sample as a whole assuming a selection function. The SPT and Planck clusters were not selected in the X-ray waveband, and so should not have a bias towards a cool core. However, we note that both these SPT and Planck selected samples are not pure SZ-selected samples, as not all objects above some detection threshold were X-ray observed, which could potentially bias their results. In addition, for Planck, we used the subsample where R500 fits within the XMM field of view, containing 120 out of 189 SZ-selected objects. SZ samples may also be affected by different selection on properties connected to morphology. For example, if they preferentially detect unrelaxed or irregular systems, this could lead to them being less concentrated. Andrade-Santos et al. (2017) find a lower fraction of cool core objects in a Planck SZ selected sample compared to an X-ray flux selected sample. Rossetti et al. (2017) find a similar result, comparing Planck SZ selected and X-ray-selected samples. Lovisari et al. (2017) confirm that a Planck-selected sample tend to be more morphologically disturbed compared to X-ray-selected surveys. It is claimed that the matched filter technique used to detect clusters in SZ surveys is independent of cluster astrophysics (e.g. Melin et al. 2005). However, simulations of Planck data find clusters with steeper pressure profiles produce more complete samples compared to a standard gNFW set of profiles (Gallo et al. 2024). There are differences in the Planck selection found for different ellipticities, although this effect is relatively small except for objects with large angular size. Cluster mergers may produce shocks, which result in pressure jumps, to which SZ selection might be more sensitive than X-ray selection (e.g. Ruan et al. 2013), similar to the effect of cool cores in X-ray selection. Simulations predict that the scatter in the SZ Y − M relation is caused by dynamical state (e.g. Battaglia et al. 2012).
It may be that our selection function is not valid and we are not correcting for the observational effects properly. If profiles of the models generated for the selection are very different to real clusters, or their 2D shape is sufficiently different, this could change their detection efficiency. We also repeated the analysis of the distribution in bins of redshift and concentration, following Section 5, but assuming that the selection function is unity. In the case of the Gaussian model, the average Gaussian distribution mean in each bin of redshift or luminosity changes by 0.05 or less, for both 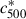 and
and 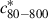 . We also separately fitted the evolution of > 50 and > 100 count subsamples in Section 4.1, finding results which were reasonably similar, despite having different selection functions. Therefore, we would have to make large changes to the selection function to change the results significantly.
. We also separately fitted the evolution of > 50 and > 100 count subsamples in Section 4.1, finding results which were reasonably similar, despite having different selection functions. Therefore, we would have to make large changes to the selection function to change the results significantly.
The density profiles measurements could also be biased in some way, for example, if clusters have profiles sufficiently different from the fitted functional form, or if the priors are affecting the result. However, the > 300 count subsample shows a similar result, which should be much less affected by priors. For the faintest clusters, the choice of the X-ray peak as the cluster centre could also bias the concentrations upwards due to Poisson fluctuations.
If there is a substantial fraction of contaminating non-clusters, such as active galactic nuclei (AGNs), these will likely have high concentrations and bias the distribution. Contaminating AGNs could also affect a subset of the objects by artificially increasing their concentration values, although the cosmology sample has a purity of 95% (B24). We restricted our distribution analysis to the cosmology sample, further selecting clusters with more than 50 counts, which increased the median extension likelihood from 12.0 to 19.3 and likely increased the purity beyond 95%. The substantial fraction of high concentration objects cannot be purely due to contamination if < 5% of clusters are not real. We also still see similarly high concentration values for our > 300 count subsample which should be purer than than the full sample and less affected by unresolved AGNs.
However, we see differences between the same set of clusters observed by eROSITA and XMM-Newton or Chandra, where eRASS1 c500 concentrations are around 0.1 dex larger (Paper I). If the cause of this difference is more important for the population of clusters less represented in SPT or Planck surveys, this could give rise to the 0.1–0.2 dex further differences between the whole populations. For example, if high concentration objects had their concentrations strongly boosted by AGN contamination, this could give rise to such a difference.
As noted in Paper I, the 2D shapes of clusters are rather similar in the eRASS1 and SPT samples. The median SPT ellipticity value (0.79) lies extremely close to the one from eRASS1, with the eFEDS distribution being similar. The distribution of slosh and M1 to M4 are are also rather similar between the samples. There we find that X-ray-selected clusters have a rather similar 2D shape to SPT-selected clusters. This is somewhat surprising as it might be expected that X-ray surveys detect more cool-core, and therefore more regular clusters in terms of 2D shape, compared to SZ surveys (e.g. Maughan et al. 2012). We note, in contrast, that Nurgaliev et al. (2017) finds no difference between X-ray and SZ-selected samples, which may be because its 400d X-ray sample (Burenin et al. 2007) does not have a pure X-ray flux selection. In addition, the Planck clusters have high values of ϵ, meaning that they are much rounder than eRASS1 and SPT. This is likely due to measurement differences, as the matched sample of eRASS1 and Planck clusters (Paper I) show the XMM results have significantly higher values of ϵ than our eRASS1 analysis. This could be because the XMM results are sensitive to a different part of the cluster, or the measurement is affected by the much larger number of counts. The eRASS1 multipole magnitude high count distributions and fitted models look rather similar to the distributions for the SPT clusters, although the SPT fits prefer values closer to zero for M3 and M4. This multipole magnitude comparison is less clear as the statistical measurement uncertainties are large and the parameters cover a limited range of values.
6.2. Cluster position
As noted previously (e.g. Sanders et al. 2018), the choice of centre of a cluster has a large impact on some parameters such as the central density. We tried two methods in this analysis – fitting the cluster position in the analysis and forcing a peak position. However, we note that our position of the peak is determined from a smoothed map, which can be dependent on the data quality and smoothing scale (which is a fixed angular scale and is therefore redshift dependent). We find that using the peak positions increases the average concentrations by 0.063 and 0.010 for c500 and c80 − 800, respectively, from the evolutionary analysis. In Paper I, figure 18, we show that there is increased bias in the measured parameters for objects with low number of counts when using peak compared to average positions. For example, for a 50 count cluster, our minimum here, the peak measured concentrations can be biased upwards by 0.04 − 0.05 dex, while the position fitted concentrations have little bias. Therefore, 2/3 to 1/2 of the measured difference could be due to this bias, as many of the clusters are close to the 50 count limit, although there may be a real differences caused by non-symmetric clusters. Similarly, using the peak position increases the inner slopes by 0.12. The central density, n50, increases by 0.037 and ns, 0 by 0.046, much of which is likely due to the centre bias. Future analyses using deeper eROSITA surveys will be able to test in more detail the differences between choice of centre as we will have larger samples with more counts.
6.3. Evolution of the inner gas properties
Our modelling of the scaling relations allows us to determine the evolution of several of our cluster parameters, under the assumption that they have normal distributions, their evolution can be modelled by a scaling relation, our selection functions properly model the selection of real clusters, and that the assumed cosmology is correct. One of the most interesting cluster morphological properties is concentration, as it is easy to measure and sensitive to cool cores.
On average 16–20% of the cluster luminosity is emitted from the inner 80 kpc (depending on how the cluster centre is defined), and 21–24% is emitted from the inner 0.1R500. The evolution of the concentration using a fixed aperture (c80 − 800 and c80 − 800*) shows differences depending on how the cluster centre is chosen, suggesting that we do not measure significant evolution due to systematic uncertainties. Alternatively, the peak position might be intrinsically better for measuring the properties of a cool core, although one must be aware of bias (Section 6.2). A lack of evolution is in contrast to the picture that cool core clusters have generally higher luminosities (e.g. Edge & Stewart 1991; Pratt et al. 2009; Hudson et al. 2010; Mittal et al. 2011). However, the concentration in a scaled aperture, c500 and c500*, both show positive luminosity evolution, in agreement with the picture of cool cores having higher luminosities. We also find some evidence for lower redshift clusters having larger c500. The evolution in the widths of the concentration distribution is relatively small.
The weaker luminosity evolution of c80 − 800 compared to c500 may be due to cool cores evolving more similarly with clusters if measured in a fixed physical aperture. McDonald et al. (2017) previously examined a sample of massive cool core objects, finding that the average over-density profile did not evolve in redshift. However, we are not looking at cool cores in particular, but the whole cluster population. When looking at the evolution of cool cores, the peak-centred quantities c500* and c80 − 800* are likely more robust, as the other parameters could be affected by the shape of the surrounding ICM. However, peak-centred parameters have additional bias in fainter clusters (Section 6.2).
Examining the central density, we find that the physical gas density at a physical radius of 50 kpc (n50 and n50*) evolves strongly positively with luminosity. The scaled density (ns, 0 and ns, 0*), which accounts for self-similar evolution, shows luminosity evolution similar to c500 and no redshift evolution. These are consistent with the picture that cool core clusters have denser cores and are more luminous. The width of the distributions increases with luminosity and decreases with redshift.
The central density slope or cuspiness, α and α50, show negative luminosity evolution, but positive redshift evolution. The widths of their distributions decrease with increasing redshift and increase with luminosity. The slope parameters do not appear to evolve in a similar way to the central density, suggesting a change in the shape of profiles. The negative evolution with luminosity may suggest that more massive clusters have a more active merger history. Another possibility is that the non-normal distribution (Section 5) distorts the evolutionary parameters.
6.4. Evolution of the 2D shape
Our simulations suggest that the 2D cluster shape (e.g. ellipticity or slosh) does not significantly affect the detection of clusters for reasonable distortions (Paper I). In bins of redshift and luminosity ellipticities are clustered around values of 0.8 (Appendix D). The slosh parameter, H, distribution peaks at values of 0.1 − 0.2. The evolution analysis shows the mean ellipticity is around 0.78, with no significant evolution with redshift or luminosity. However, the width of the distribution shows negative evolution with luminosity (i.e. more luminous clusters have a narrower ellipticity range), but the width of the distribution increases with redshift. Therefore, there appear to be more extreme objects at lower luminosities (i.e. lower masses) and higher redshifts.
Similarly, our slosh parameter, designed to measure asymmetries similar to a sloshing cold front, has a peak towards zero slosh in the evolution analysis. It also shows little evidence for a shift in peak with redshift and luminosity. Similar to ellipticity, the width of the distribution does reduce with increasing luminosity and increases with redshift.
The lack of evolution in these parameters is suggestive that the average cluster over redshift and luminosity has a similar rate of high morphological disturbance. The width of the distribution reduces with increased redshift and luminosity, however. Although we did not find a strong effect of 2D shape on selection itself, if it is correlated with other parameters such as concentration, we may be missing very concentrated but spherical objects, or non-concentrated highly disturbed objects. This effect of correlation between parameters and the selection should be less important for the profile-based parameters, as the profiles were generated based on a model obtained from real cluster profiles.
6.5. Single or multiple populations
One often studied topic is whether the cluster population consists of a single continuous population of objects or whether there are different subpopulations of objects leading to bimodal distributions (e.g. Pratt et al. 2010; Santos et al. 2010; Hudson et al. 2010; Sanders et al. 2018; Ghirardini et al. 2022; Riva et al. 2024). Whether one sees a single population of objects or sees bimodality can also depend on the parameter space being examined. There is a large multidimensional space of possible cluster properties, where clusters can look alike if viewed along certain projections, but they might not if looked at in other ways. For example, the presence of a cool core may not be a useful indicator of whether there is a merger taking place (e.g. Hudson et al. 2010; Lovisari et al. 2017). Bimodality is usually assessed by examining the distribution of a particular quantity to see whether more than one normal component is necessary.
It has been known for a long time that a large fraction of X-ray-selected galaxy clusters have mean radiative cooling times which are relatively short in their centres (e.g. Bauer et al. 2005), which are known as cool core clusters. These objects are seen as having steeply peaked surface brightness profiles compared to the flatter profiles in other systems. Cool core clusters also show evidence for multiphase material in their centres and evidence for AGN feedback (e.g. Fabian 2012).
However, it is not clear whether there is a simple continuum between cool core and non-cool core clusters, or if they are distinct populations. Strong cool core objects are characterised by a very concentrated X-ray surface brightness profile, low central mean radiative cooling time (or low entropy), reductions in temperature in the very central region, and often the X-ray peak and brightest cluster galaxy being at the same location. Several of the morphological parameters we have measured are directly sensitive to the presence of a cool core (e.g. concentration, inner density slope, and central density). Hudson et al. (2010) examined the detailed profiles of their sample of nearby bright galaxy clusters and found, examining histograms of properties, that they could be split into three subsets: strong cool core, weak cool core, and non-cool core. Pratt et al. (2010) found that the central entropy in the REXCESS sample showed either a bimodal or skewed distribution. Sanders et al. (2018) examined the distribution of entropy in the SPT sample of galaxy clusters observed by Chandra, finding evidence for a bimodal distribution of the central entropy.
Other authors, however, have not found evidence for bimodality (or trimodality) in their clusters. Santos et al. (2010) examined the concentration distribution of different samples, finding no evidence for bimodality. Ghirardini et al. (2022) studied the distributions of morphological parameters for the eFEDS sample of clusters observed by eROSITA, finding no evidence for bimodality. Riva et al. (2024) examined the central entropy distribution in the CHEX-MATE cluster sample, finding no evidence for bimodality.
We examined the distribution for some forward-modelled parameters in bins of redshift and luminosity in Section 5. We do not find find a single model distribution which best describes all the parameter distributions. For the ellipticity, its distribution is consistent with normal in most bins, although interpolated or skew models are preferred in a couple of bins. In contrast, interpolated models are usually preferred for H, with a peak preferred in the 0.1 − 0.2 range and a tail to higher values. For the multipole magnitude parameters, M1 to M4, we find that in many bins the normal model is adequate to describe the data.
For the concentration, normal distributions are statistically reasonable, except that there are particular bins of redshift of luminosity which strongly prefer other models, such as the highest redshift and luminosity bins for c500 and c500*. However, in some of the bins (Appendix D) the interpolated model is suggestive of peaks at similar values, although the statistical evidence in each bin is not strong.
The central density parameters show no clear model which best describes the distribution in each bin, although the normal distribution is heavily disfavoured for many of them. The distribution plots show tails in some of the bins, typically to higher densities in the redshift bins and to lower densities in the luminosity bins. Comparing the peak-centred versions of the parameters to the fit-centred ones, we do not see a clear differences, although the normal distribution is favoured in more of the luminosity bins for the peak centred values.
The inner density slope, or cuspiness, parameters strongly disfavour normal models and prefer interpolated or skewed models. For the fit-centred versions of the parameters, α and α50, the interpolated models show a bimodal structure with peaks at similar positions in all the luminosity and redshift bins. This bimodal structure disappears when using the peak centred versions of the clusters, α* and α50*, suggesting it could be induced by a population of clusters where the X-ray peak is not at the fit position.
If we model the distributions of the parameters assuming that they are the same for the whole sample, the evidence for non-normal distributions is significantly stronger. This is seen for the central density and slope parameters, the scaled concentration, and even for the ellipticity. However, evolution of parameters could also cause these non-normal distributions.
Therefore, we find evidence for significant non-Gaussian or non-skew-normal distributions in some of our parameters, in particular the central density and inner slope. The exceptions are the concentration and some of the 2D shape parameters (ϵ and M1 to M4). The preferred model, however, will be dependent on the data quality and we see stronger evidence for non-normal distributions by examining the whole cluster sample. Deeper eROSITA surveys will contain many more objects with a higher data quality than the current dataset.
When forward modelling in a cosmological analysis, the selection function should account for morphological variation. In Clerc et al. (2024), the standard selection function marginalises over morphology, based on an input distribution of cluster profiles, although there is a version of the selection parametrised on EM0, a concentration-like quantity. If there were significant non-normal distributions of morphological parameters not present in the input profiles, this could potentially bias the selection model. The most important morphological parameter for selection is the concentration, where we find normal distribution models are reasonable in individual redshift and luminosity bins, although the combined distribution prefers more complexity. In addition, the redshift or luminosity evolution of concentration is relatively small or moderate. The near normal concentration distribution is helpful for modelling the selection function. To test this further, one could also include a parametrisation for concentration in the selection function and the cosmology forward model.
7. Conclusions
We investigated the intrinsic distributions and evolution of some of the morphological parameters of clusters detected in the eROSITA eRASS1 sky survey; we used a Bayesian framework and took the selection of clusters in the survey into account. Using this technique and assuming that the parameters are described by a scaling relation with redshift and luminosity and are distributed normally, we constrained the parameters of their evolution.
The concentration measured in a scaled aperture evolves positively with luminosity, as expected if cool core clusters are more luminous than non-cool core systems, and negatively with redshift, which implies that low redshift clusters are more concentrated. The scaled central density evolves similarly with luminosity as concentration does, but does not significantly evolve in redshift. The density at a fixed physical radius has a much stronger evolution with luminosity. The concentration in a fixed aperture has a reduced evolution with luminosity, although its evolution depends on how the centre of the cluster is chosen. If the cluster peak is used as the cluster centre, its luminosity evolution is consistent with zero. The negative luminosity and positive redshift evolution of the central slope is more difficult to understand. However, this could be affected by the complex distributions of the parameters found within bins of redshift or luminosity, by observational measurement processes, or could be a real astrophysical effect. The 2D shapes of the clusters are consistent with no evolution with luminosity or redshift.
We investigated the intrinsic distribution of parameters as a function of luminosity and redshift, by fitting normal, skew normal, dual normal, and interpolated models. We do not find that a particular parameter distribution is preferred in all bins for each of the parameters. The exceptions are the concentration and ellipticity, which favour a normal distribution in most cases. The central density parameter distribution favours interpolated or skew models in different bins and often strongly disfavours a normal distribution, which implies that a more complex model is required. The central slope or cuspiness parameter usually favours skew normal or interpolated models. When models are fitted to the whole cluster sample, there is stronger evidence for non-normal distributions in many cases, in particular the central density, concentration in scaled aperture, and cuspiness.
The intrinsic distribution of parameters is compared against that for SZ-selected cluster samples, which should not be biased by cool cores. Despite modelling using the selection function and looking at the difference in concentration for the same clusters, we find that eROSITA clusters remain more concentrated than those in SZ surveys, with around 15–35% more flux within 0.1R500. The differences could be due to selection effects on the SZ-detected objects, problems with our selection function, or there could be observation effects that might bias the concentration in eRASS1-detected clusters. In addition, the eRASS1 clusters show central density gradients that are considerably larger than the SZ objects. Despite the difference in concentration and inner slopes, we find little difference in the scaled central densities for the clusters between the eRASS1- and SZ-selected objects. In addition, the 2D shape of objects measured by ellipticity, slosh, and multipole magnitudes looks rather similar between the eRASS1 and SPT samples, although Planck-selected clusters are less elliptical.
This analysis leads the way for the study of the intrinsic morphology of still larger samples of clusters detected by eROSITA. Deeper eROSITA surveys will also reduce the statistical uncertainty for many of the parameters for the brightest clusters. It will also be important to make more detailed studies of the selection function to study the intrinsic distribution of these parameters.
Acknowledgments
This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft- und Raumfahrt (DLR). The SRG spacecraft was built by Lavochkin Association (NPOL) and its subcontractors, and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tübingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. The eROSITA data shown here were processed using the eSASS/NRTA software system developed by the German eROSITA consortium. E.B., V.G., A.L. and X.Z. acknowledge financial support from the European Research Council (ERC) Consolidator Grant under the European Union’s Horizon 2020 research and innovation program (grant agreement CoG DarkQuest No 101002585). V.G. acknowledges the financial contribution from the contracts Prin-MUR 2022 supported by Next Generation EU (M4.C2.1.1, n.20227RNLY3 The concordance cosmological model: stress-tests with galaxy clusters). A.L. acknowledges the supports from the National Natural Science Foundation of China (Grant No. 12588202). A.L. is supported by the China Manned Space Program with grant no. CMS-CSST-2025-A04.
References
- Andrade-Santos, F., Jones, C., Forman, W. R., et al. 2017, ApJ, 843, 76 [Google Scholar]
- Bahar, Y. E., Bulbul, E., Clerc, N., et al. 2022, A&A, 661, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Battaglia, N., Bond, J. R., Pfrommer, C., & Sievers, J. L. 2012, ApJ, 758, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Bauer, F. E., Fabian, A. C., Sanders, J. S., Allen, S. W., & Johnstone, R. M. 2005, MNRAS, 359, 1481 [NASA ADS] [CrossRef] [Google Scholar]
- Biffi, V., Borgani, S., Murante, G., et al. 2016, ApJ, 827, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015, ApJS, 216, 27 [Google Scholar]
- Böhringer, H., Pratt, G. W., Arnaud, M., et al. 2010, A&A, 514, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brunner, H., Liu, T., Lamer, G., et al. 2022, A&A, 661, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buchner, J. 2021, J. Open Source Softw., 6, 3001 [CrossRef] [Google Scholar]
- Bulbul, E., Liu, A., Kluge, M., et al. 2024, A&A, 685, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buote, D. A., & Tsai, J. C. 1995, ApJ, 452, 522 [Google Scholar]
- Burenin, R. A., Vikhlinin, A., Hornstrup, A., et al. 2007, ApJS, 172, 561 [Google Scholar]
- Campitiello, M. G., Ettori, S., Lovisari, L., et al. 2022, A&A, 665, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chiu, I. N., Ghirardini, V., Liu, A., et al. 2022, A&A, 661, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clerc, N., Comparat, J., Seppi, R., et al. 2024, A&A, 687, A238 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Comparat, J., Eckert, D., Finoguenov, A., et al. 2020, Open J. Astrophys., 3, 13 [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Edge, A. C., & Stewart, G. C. 1991, MNRAS, 252, 414 [NASA ADS] [CrossRef] [Google Scholar]
- Evrard, A. E., Mohr, J. J., Fabricant, D. G., & Geller, M. J. 1993, ApJ, 419, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Fabian, A. C. 2012, ARA&A, 50, 455 [Google Scholar]
- Gallo, S., Douspis, M., Soubrié, E., & Salvati, L. 2024, A&A, 686, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bahar, Y. E., Bulbul, E., et al. 2022, A&A, 661, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hudson, D. S., Mittal, R., Reiprich, T. H., et al. 2010, A&A, 513, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kass, R. E., & Raftery, A. E. 1995, J. Am. Stat. Assoc., 90, 773 [Google Scholar]
- Kluge, M., Comparat, J., Liu, A., et al. 2024, A&A, 688, A210 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lotz, J. M., Primack, J., & Madau, P. 2004, AJ, 128, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Lovisari, L., & Reiprich, T. H. 2019, MNRAS, 483, 540 [Google Scholar]
- Lovisari, L., Forman, W. R., Jones, C., et al. 2017, ApJ, 846, 51 [Google Scholar]
- Lovisari, L., Schellenberger, G., Sereno, M., et al. 2020, ApJ, 892, 102 [Google Scholar]
- Maughan, B. J., Giles, P. A., Randall, S. W., Jones, C., & Forman, W. R. 2012, MNRAS, 421, 1583 [Google Scholar]
- McDonald, M., Allen, S. W., Bayliss, M., et al. 2017, ApJ, 843, 28 [Google Scholar]
- Melin, J. B., Bartlett, J. G., & Delabrouille, J. 2005, A&A, 429, 417 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Migkas, K., Kox, D., Schellenberger, G., et al. 2024, A&A, 688, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mittal, R., Hicks, A., Reiprich, T. H., & Jaritz, V. 2011, A&A, 532, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nurgaliev, D., McDonald, M., Benson, B. A., et al. 2013, ApJ, 779, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Nurgaliev, D., McDonald, M., Benson, B. A., et al. 2017, ApJ, 841, 5 [Google Scholar]
- Pratt, G. W., Croston, J. H., Arnaud, M., & Böhringer, H. 2009, A&A, 498, 361 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Arnaud, M., Piffaretti, R., et al. 2010, A&A, 511, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Arnaud, M., Biviano, A., et al. 2019, Space Sci. Rev., 215, 25 [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Ramos-Ceja, M. E., Pacaud, F., Reiprich, T. H., et al. 2019, A&A, 626, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Riva, G., Pratt, G. W., Rossetti, M., et al. 2024, A&A, 691, A340 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rossetti, M., Gastaldello, F., Eckert, D., et al. 2017, MNRAS, 468, 1917 [Google Scholar]
- Ruan, J. J., Quinn, T. R., & Babul, A. 2013, MNRAS, 432, 3508 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, J. S., Fabian, A. C., Russell, H. R., & Walker, S. A. 2018, MNRAS, 474, 1065 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, J. S., Bahar, Y. E., Bulbul, E., et al. 2025, A&A, 695, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Santos, J. S., Rosati, P., Tozzi, P., et al. 2008, A&A, 483, 35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Santos, J. S., Tozzi, P., Rosati, P., & Böhringer, H. 2010, A&A, 521, A64 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spinelli, C., Veronica, A., Pacaud, F., et al. 2025, A&A, 700, A220 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [Google Scholar]
- Sunyaev, R., Arefiev, V., Babyshkin, V., et al. 2021, A&A, 656, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Takizawa, M., Nagino, R., & Matsushita, K. 2010, PASJ, 62, 951 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Valdarnini, R., & Sarazin, C. L. 2021, MNRAS, 504, 5409 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Burenin, R., Forman, W. R., et al. 2007, in Heating versus Cooling in Galaxies and Clusters of Galaxies, eds. H. Böhringer, G. W. Pratt, A. Finoguenov, & P. Schuecker, 48 [Google Scholar]
- Wong, A. W. C., & Taylor, J. E. 2012, ApJ, 757, 102 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Simulations
To calculate our selection function as a function of morphological parameter, we made simulations of clusters and attempted to detect them. The approach we used was much simplified over the simulations of Comparat et al. (2020). Rather than include a proper clustered AGN background, we simulated a single cluster at a time, assuming a smooth point source free X-ray background map. To simulate a cluster, we randomly chose positions within the sky regions used for eROSITA cluster detection. The object was randomly assigned a log L500 from a regularly spaced grid of 21 values between 42.5 and 45.0 log erg s−1. Redshifts were randomly taken from the list 0.02, 0.035, 0.05, 0.07, 0.1, 0.15, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 1.0, and 1.2. In total, around 6 × 105 objects were simulated.
The covariance matrix method described in Comparat et al. (2020) was used to generate a random cluster mass, temperature and emissivity profiles. Clusters were assigned to a grid point by generating a mass function (Tinker et al. 2008) for the relevant redshift and assigning randomly generated clusters nearby in mass and redshift. Those clusters with luminosities close to the grid point value were assigned to it. Rather than use the emissivity profile directly, which can be noisy or may not be a valid 3D projection, we fitted a full Vikhlinin density model (Vikhlinin et al. 2007) after projection to the emissivity profile, and used the best fitting model to generate a new emissivity profile for simulation. Model concentration, density and cuspiness values were computed from this fitted model profile.
To create a simulated eROSITA event list, we used sixte 3.1.1 (Dauser et al. 2019), providing an eRASS1 input attitude file. The input file describing the model for sixte contained an image of the cluster following the emissivity profile with a symmetric shape and a model spectrum given by the cluster temperature and Galactic absorption for the sky position. The cluster source was defined to have a flux such that the X-ray luminosity within r500 matched the chosen luminosity. No AGNs were included in the simulation. An X-ray background model was also included, taken from wavelet-filtered sky maps of the real eRASS1 sky, where structures below scales of around 30 arcmin were removed. The simulated flux of these maps was scaled to produce the count rate within our 0.2-2.3 keV band, once the sixte particle background model rate was subtracted.
The cluster region was simulated using a box of dimensions 8r500, with a minimum size of 1.5 deg. The output event files from sixte were merged into a single event file and then filtered using the standard eROSITA detector mask, flags, patterns and the good time intervals (GTIs) used for eRASS1. Images in the 0.2-2.3 keV band were created. Exposure maps were taken from the eRASS1 all sky exposure maps.
To replicate cluster detection, we used the eSASS (Brunner et al. 2022) version eSASSusers_240410_0_3 on the simulated image. erbox was used on the simulated image to make a list of sources (with likemin = 6, nruns = 2, boxsize = 4 and bkima_flag=N). This source list was supplied to erbackmap to make an initial background map (using scut = 0.00005, mlmin = 6, maxcut = 0.5, smoothval = 15, snr = 40, smoothmax = 360). erbox was used a second time using the background map (with likemin = 4 and bkima_flag=Y). erbackmap was run a second time to produce a new background map based on the generated source list. We ran erbox again using the previous background map and made a new background map using erbackmap.
As the high luminosity, nearby clusters produce a large number of events in their output files, the photon detection mode of the ermldet maximum likelihood detection software is unusably slow for these clusters. Therefore, we ran it up to twice, once in image mode and, if the cluster was not detected with a high enough significance, in photon mode. The threshold we use to decide to use photon mode is if ℒext < 30, well above the threshold of 6 used to select the cosmology sample. ermldet was run with parameters likemin = 5, extlikemin = 3, cutrad = 15, multrad = 20, extmin = 2, extmax = 15, nmaxfit = 4, and nmulsou = 2. For the image mode we set shapelet_flag=no and photon_flag=no, while for photon mode these are both set to yes.
A cluster was detected if there is an extended object within radii of 6 (z ≤ 0.05), 4 (0.05 ≤ z < 0.2), 3 (0.2 ≤ z < 0.4), and 2 arcmin (z ≥ 0.4) from the input cluster position. For those clusters we detected, we ran MBProj2D on the images (excluding TMs 5 and 7), to obtain the total number of cluster counts, the cluster luminosity, concentration, central density, and cuspiness. The MBProj2D modelling is described in Paper I.
There are some limitations on the accuracy of the simulations from which the selection function have been derived, some of which we discussed in Paper I. Firstly, the simulations were of spherical clusters with no contaminating point sources. To calculate the parameters which depend on cluster radius, we assumed that the input cluster mass was correct, rather than obtaining it from the simulated data. We also did not account for redshift uncertainties for the objects, although this should be a relatively small effect given the quality of the X-ray detections. Another potential shortcoming is that clusters were simulated individually with random rather than correlated positions, underestimating effects due to nearby objects seen in real systems (e.g. Ramos-Ceja et al. 2019; Spinelli et al. 2025).
Appendix B: Modelling the selection function
The simulation and detection procedure above describes the standard eROSITA detection pipeline. The clusters we study also have additional selection applied of ℒext > 6 and a minimum of 50 or 100 counts. These selections were applied after the detection is run on the simulated clusters, to further restrict those clusters which are detected.
After studying the results of the simulations, we found that the cluster selection can be well described by a function of three values, the redshift, the morphological parameter in question, and a log count-like quantity, Q. We define Q as
![Mathematical equation: $$ \begin{aligned} Q(L_{500},z,t,N_{\rm H}) = \log L_{500} -&2 \log \left[ D_L(z)/D_L(z = 0.2) \right] + \nonumber \\&\log (t / t_{\rm ref}) + A(L_{500}, z, N_{\rm H}), \end{aligned} $$](/articles/aa/full_html/2026/02/aa56830-25/aa56830-25-eq15.gif) (B.1)
(B.1)
where L500 is the 0.2-2.3 keV cluster luminosity, DL(z) is the luminosity distance of an object at the given redshift, t is the exposure time, tref is a reference exposure time (90.8s), and A accounts for photoelectric absorption by our Galaxy. A is the median log difference in flux between an absorbed (with column density NH) and unabsorbed spectral model, with temperatures sampled from the simulated clusters with the given redshift and luminosity. For a particular cluster, the only part of Q which varies during the modelling analysis is L500. We did not find a significant effect on the selection function due to the background count rate, nor the exposure time once it is included in Q.
We fitted a model to the simulated clusters in this three-dimensional space. The model is a sum of Gaussian components, each with a free central position, normalisation, and covariance matrix. The selection function must lie in the range [0, 1] for any set of parameters. Therefore, we applied the logistic sigmoid function to the sum to ensure the output is in this range.
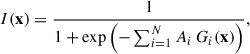 (B.2)
(B.2)
where Gi is a multivariate Gaussian function with mean μi and covariance matrix Σi, N is the number of components, and Ai is the normalisation of component i (which can be negative). x is the three-dimensional vector (Q, log z, Y), where Y is the morphological parameter in question.
This function was fitted to the results of the simulations binned in the three-dimensional space. Q was binned into 80 equal-sized bins between 40.2 and 47.0. We used 20 bins between −2.0 and 0.0 for concentration parameters. For ns we used 80 bins between −2.0 and 2.5. For n50 we used 80 bins between −5.0 and 0.0. For cuspiness, we used 80 bins between −3 and 3. The redshift values used the same grid as in Appendix A.
In each bin we know the total number of simulations done and the number which resulted in a detection. The binomial likelihood for n trials with k detections can be calculated. To fit the selection function to the simulation data we maximised the total likelihood of all the bins. It is difficult to choose the best value of N for the analysis. We tested different values, finding that N = 8 was a reasonable compromise between modelling the shape of the function and being able to find a likelihood maximum in a reasonable time. To prevent the model becoming undefined beyond the range of the simulations, for each of the redshift grid points, we added fake simulations in alternate bins with extreme values of Q where no simulations were done. For Q values lower than the 0.1 percentile for that redshift the k was set to 0, while k was set to n above the 99.9 percentile, with n set to 6.
 |
Fig. B.1. Selection function for different morphological selections. The selection function model for the 50 count subsample is shown as a function of Q and log z. From left to right, are shown no morphological selection, and selection for low, medium and high values of c500, ns, 0, and α. |
We found in Paper I that the selection function is not strongly affected by the parameters which affect the 2D shape of the cluster, rather than its profile, i.e. ϵ, H and M1 to M4. In this case for these parameters, the selection function does not include the parameter and is only modelled in two dimensions. Figure B.1 shows the selection function as a function of Q and log z for different morphological parameter values. Although the selection function is seen to vary relatively strongly at high redshift with concentration, it is harder to see the effect of the increase in central density, because higher values (∼1.9) are necessary to see the effect here.
We compared our selection function with the standard eROSITA one (Clerc et al. 2024) to check for consistency. Taking an exposure time of 100s and NH = 3 × 1020 cm−2, we compared the results for a grid of redshift and luminosity, converting the input to count rates as input for the standard selection function. We find that the there is reasonable agreement, except in the lowest 0.05 redshift bin. In general, the selection function generated in this paper is a little steeper, and reaches a value of 0.5 at most 0.1 dex lower in luminosity than the standard selection function. A likely reason for the differences between our selection function and the standard eROSITA ones, is that we include neither clustered background point sources nor other extended sources.
Appendix C: Scaling relation parameters
Table C.1 lists the median values from the MCMC chain and their 1σ posterior probability widths for the two different cluster samples. Corner plots showing the distribution of parameter values in the MCMC chains are shown in Fig. C.1 and C.2. In these corner plots we show the results for the standard analysis (clusters with more than 50 counts, allowing an evolution of the distribution width and fitting for the cluster position), a second where the cluster is fixed at the peak position, a third where the width evolution parameters are fixed at 0, and finally with no evolution in width but only studying clusters with more than 100 counts.
Parameters and their one-dimensional uncertainties for their scaling relations assuming normal scatter.
 |
Fig. C.1. MCMC corner plots for the analysis of the scaling relation of concentration, c500 (top left) and c80 − 800 (top right), and density, ns, 0 (bottom left) and n50 (bottom right). The contours contain 39.3, 67.5, 86.4, and 95% of the samples. The contours are shown for the analysis with evolution in mean and width, where the centre positions of the clusters are fitted for, the same but using the peak cluster positions, a scaling relation with no evolution in width, with the fitted centres, and the same but only using clusters with more than 100 counts instead of 50 counts. |
 |
Fig. C.2. MCMC corner plots for the analysis of the evolution of the inner density slope, α (top left), α50 (top right), ellipticity, ϵ (bottom left), and slosh, H (bottom right). The description is the same as Fig. C.1, except that cluster position is always fitted for ellipticity and slosh. |
Appendix D: Distribution detailed results
Figure D.1 and Fig. D.2 show distributions for three of the four models (normal, skew normal, and interpolated). The parameters shown are the concentrations, the central densities, the cuspiness, the ellipticity, and slosh. The distributions were generated from the equal-weighted posterior samples produced by UltraNest.
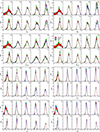 |
Fig. D.1. Distributions of concentration and density parameters in five bins of redshift and luminosity, after taking account of selection effects and the luminosity function. Shown are the distributions (median and 1σ range) for normal, skew normal, and interpolated PDFs. The edges of the redshift bins are 0.0, 0.1, 0.2, 0.3, 0.4, and 1.5. The edges of the luminosity bins are 41.1, 43.3, 43.7, 44.0, 44.3, and 45.6 log erg s−1. |
All Tables
Parameters and their one-dimensional uncertainties for their scaling relations assuming normal scatter.
All Figures
|
Fig. 1. Clusters with > 50 counts plotted on PDFs combining the maximum likelihood scaling relation, selection function, and mass function. The clusters in four redshift bins are shown, plotting the concentration, c500 (left), and scaled density, ns, 0 (right). The images show the average maximum likelihood scaling relation combined with the selection function and mass function for the clusters in the redshift ranges, with the solid contour lines at difference levels of −2, −4, −6, −8, and −10 from the maximum. The dashed contour lines show the average selection function, at levels of 0.05, 0.2, 0.4, 0.6, 0.8, and 0.95. |
| In the text | |
|
Fig. 2. Evolution of mean and width for several parameters. Left: confidence contours for the evolution of μ, with the results using the cluster fit positions shown as solid lines and the peak-centred cluster results shown as dashed lines. Right: confidence contours of the evolution of σ. The contours contain 39.3, 67.5, 86.4, and 95% of the MCMC samples. See Appendix C for corner plots of the other parameters. |
| In the text | |
|
Fig. 3. Comparison of model distributions in bins of redshift and luminosity. We show the difference in Bayesian evidence (the Bayes factor) between each model and the model with the greatest Bayesian evidence, where the models with the greatest evidence are plotted at lower values and the best model has a value of 1. We show typical thresholds for Bayes factors from Kass & Raftery (1995). |
| In the text | |
|
Fig. 4. Comparison of different distribution models for the whole sample. Left panel: model comparison, as in Fig. 3, for each parameter, assuming that the clusters have a single distribution. Models with greater evidence have lower values. Right panels: PDFs of each parameter, for each of the model types, coloured as in the left panel. The shaded regions contain 68.27% of the samples. |
| In the text | |
|
Fig. 5. Comparison of eRASS1 probability densities compared to SPT- and Planck-selected samples. The distribution of the parameters for the Chandra-SPT sample is plotted as a histogram, with the median value indicated by a dashed line. The Planck values are for ESZ clusters from Lovisari et al. (2017). The model distribution for the eRASS1 clusters in the high luminosity bin is plotted (log LX = 44.3 − 45.6, fitted using interpolated model). For those parameters where we fitted a scaling relation (Appendix C), we computed matched PDFs given the redshift and luminosities of the SPT and Planck samples. The distributions of parameter values for the bright 300 count cluster eRASS1 subset are also plotted. |
| In the text | |
|
Fig. B.1. Selection function for different morphological selections. The selection function model for the 50 count subsample is shown as a function of Q and log z. From left to right, are shown no morphological selection, and selection for low, medium and high values of c500, ns, 0, and α. |
| In the text | |
|
Fig. C.1. MCMC corner plots for the analysis of the scaling relation of concentration, c500 (top left) and c80 − 800 (top right), and density, ns, 0 (bottom left) and n50 (bottom right). The contours contain 39.3, 67.5, 86.4, and 95% of the samples. The contours are shown for the analysis with evolution in mean and width, where the centre positions of the clusters are fitted for, the same but using the peak cluster positions, a scaling relation with no evolution in width, with the fitted centres, and the same but only using clusters with more than 100 counts instead of 50 counts. |
| In the text | |
|
Fig. C.2. MCMC corner plots for the analysis of the evolution of the inner density slope, α (top left), α50 (top right), ellipticity, ϵ (bottom left), and slosh, H (bottom right). The description is the same as Fig. C.1, except that cluster position is always fitted for ellipticity and slosh. |
| In the text | |
|
Fig. D.1. Distributions of concentration and density parameters in five bins of redshift and luminosity, after taking account of selection effects and the luminosity function. Shown are the distributions (median and 1σ range) for normal, skew normal, and interpolated PDFs. The edges of the redshift bins are 0.0, 0.1, 0.2, 0.3, 0.4, and 1.5. The edges of the luminosity bins are 41.1, 43.3, 43.7, 44.0, 44.3, and 45.6 log erg s−1. |
| In the text | |
 |
Fig. D.2. Distributions of cuspiness, ellipticity, and slosh parameters, similarly to Fig. D.1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.