| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A92 | |
| Number of page(s) | 16 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/202555661 | |
| Published online | 04 September 2025 | |
Granulation signatures in 3D hydrodynamical simulations: Evaluating background model performance using a Bayesian nested sampling framework
1
Stellar Astrophysics Centre (SAC), Dept. of Physics and Astronomy, Aarhus University, Ny Munkegade 120, 8000 Aarhus C, Denmark
2
School of Physics and Astronomy, University of Birmingham, Edgbaston B15 2TT, UK
3
Center for Astronomy (ZAH/LSW), Heidelberg University, Königstuhl 12, 69117 Heidelberg, Germany
4
Rosseland Centre for Solar Physics, Institute of Theoretical Astrophysics, University of Oslo, PO Box 1029, Blindern, 0315 Oslo, Norway
5
School of Physical and Chemical Sciences – Te Kura Matū, University of Canterbury, Private Bag 4800, Christchurch 8140, Aotearoa, New Zealand
6
Aarhus Space Centre (SpaCe), Dept. of Physics and Astronomy, Aarhus University, Ny Munkegade 120, 8000 Aarhus C, Denmark
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
26
May
2025
Accepted:
14
July
2025
Abstract
Context. Understanding the granulation background signal is vital when interpreting the asteroseismic diagnostics of solar-like oscillators. Various descriptions exist throughout literature for modelling the surface manifestation of convection, with the choice of description affecting our interpretations.
Aims. We aim to evaluate the performance of and preference for various granulation background models for a suite of 3D hydrodynamical simulations of convection across the Hertzsprung-Russell diagram, thereby expanding the number of simulations and coverage of parameter space for which such investigations have been made.
Methods. We took a statistical approach by considering the granulation signatures in power density spectra of 3D hydrodynamical simulations, in which no biases or systematics of observational origin are present. To properly contrast the performance of the background models, we developed a Bayesian nested sampling framework for model inference and comparison. This framework was subsequently extended to real stellar data using the solar analogue KIC 8006161 (Doris) and the Sun.
Results. We find that multi-component models are consistently preferred over a single-component model, with each tested multicomponent model demonstrating merit in specific cases. This occurs for simulations with no magnetic activity, ruling out stellar faculae as the sole source of the second granulation component. Similar to a previous study, we find that a hybrid model with a single overall amplitude and two characteristic frequencies performs well for numerous simulations. Additionally, a tentative third granulation component beyond the value of νmax is seen for some simulations, but its potential presence in observations requires further study.
Conclusions. Studying the granulation signatures in these simulations paves the way for studying real stars with accurate granulation models. This deeper understanding of the granulation signal may lead to complementary methods to existing algorithms for determining stellar parameters, with the goal of providing an independent radius estimate for stars where oscillations are not observable.
Key words: asteroseismology / Sun: granulation / stars: atmospheres / stars: evolution / stars: interiors
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The modelling of turbulent convection in stars is a longstanding challenge in modern astrophysics. Not only does its treatment in stellar evolution codes through the mixing length theory (Böhm-Vitense 1958; Kippenhahn et al. 2013; Trampedach et al. 2014; Li et al. 2024) deserve careful consideration, but so does the interpretation of the surface signatures of convection, granulation. The convective motions are sensitive to the density profile of the outer regions of a solar-like star, and any star with a convective envelope will display granulation. Several studies have investigated this phenomenon observationally (Mathur et al. 2011; Kallinger et al. 2014) and, in line with the theoretical predictions, found that the amplitudes and timescales of the granulation scale with the frequency of maximum oscillation power, νmax (Kjeldsen & Bedding 2011; Chaplin et al. 2011b). The scaling of νmax with stellar evolution, similarly to that of convective motions, depends on fundamental stellar parameters, following 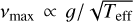 . This suggests a link between granulation-related signals and global stellar properties, a relationship that is exploited by algorithms such as Flicker and FliPer to estimate surface gravities (Bastien et al. 2016; Bugnet et al. 2018).
. This suggests a link between granulation-related signals and global stellar properties, a relationship that is exploited by algorithms such as Flicker and FliPer to estimate surface gravities (Bastien et al. 2016; Bugnet et al. 2018).
In this work, we consider the quasi-periodic brightness fluctuations caused by the granulation – which occur over a wide range of amplitudes and timescales – from a theoretical standpoint using 3D hydrodynamical simulations of convection (hereafter simply simulations). Several previous studies have taken this theoretical approach when investigating the signatures of granulation (for an extensive comparison of simulations and observations, see Zhou et al. 2021). Mathur et al. (2011) were the first to consider the power density spectra (PDSs) of such simulations, finding that the trends broadly reproduced the observed scaling relations for granulation amplitudes and timescales in their red giant sample, albeit with notable systematic discrepancies. Samadi et al. (2013a,b) used a theoretical model for the PDSs of the simulations to support the observed scaling with νmax; however, they also noted the importance of the Mach number in controlling the theoretical granulation parameters. Recently, Rodríguez Díaz et al. (2022) used a subset of the STAGGER grid (Magic et al. 2013) to calculate extended time series for a number of simulations. In their work, they derive new scaling relations for the standard deviation and autocorrelation time of the time series and compare them to the ones found previously; however, they do not investigate the granulation signatures in frequency space.
A thorough understanding of the underlying granulation background profile in the PDS is invaluable when interpreting the stellar oscillations of a solar-like oscillator (e.g. Kallinger et al. 2014; Sreenivas et al. 2024). Lundkvist et al. (2021) investigated the performance of various background model descriptions for a solar simulation, finding that a model with two timescales is optimal. In a sense, the simulations can provide a unique testing ground for such evaluations, where no biases or systematics of observational origin are present – just the pure granulation signal stemming from the convective motions. In this work, we therefore aim to extend the work of Lundkvist et al. (2021) by comparing the performance of several granulation background descriptions to the suite of simulations by Rodríguez Díaz et al. (2022), which are distributed across the Hertzsprung-Russell (HR) diagram. In doing so, we develop a Bayesian nested sampling framework for the granulation background fitting and subsequent model comparison in order to evaluate the merit of various granulation background descriptions extensively used in the scientific community.
In Sect. 2 we present the suite of simulations from Rodríguez Díaz et al. (2022) and the theoretical background for describing the granulation background signal. Afterwards, in Sect. 3, we outline the Bayesian nested sampling methodology used in this paper. Sect. 4 contains the resulting model preferences across the suite of simulations and the recovered scaling of the granulation parameters with νmax. To test the developed framework, in Sect. 5 we apply it to the solar analogue KIC 8006161 (also known as Doris) and the Sun, before evaluating the performance of the models. Lastly, further discussions and closing remarks on the future applications are made in Sects. 6 and 7.
2 Describing the granulation background in 3D simulations
The suite of simulations that we consider originate from the work of Rodríguez Díaz et al. (2022), wherein the detailed creation, descriptions, and studies of the simulations can be found (see e.g. their Table 1). In the present work we only consider the resulting time series (Bigot et al. in prep), which were obtained from simulations uniquely suited to our study for two reasons.
Firstly, they have extremely extended durations, having been run for more than 1000 convective turnover times – which is defined as the time it takes a convective element to complete an upward (or downward) motion from the bottom to the top (or vice versa) of the simulation box (Dethero et al. 2024, Eq. (4)). Additionally, a simulation snapshot is stored every 60 s for the main-sequence simulations, and ≈30 minutes for the simulations of the most evolved RGB stars. This relatively small sampling interval ensures that the Nyquist frequency (the point at which any frequency below is free of aliasing distortions due to the sampling, Shannon 1949) of the resulting time series is significantly higher than νmax.
Secondly, due to the compressible nature of the simulations used in this study, the stochastic excitation of standing sound waves is a natural phenomenon that occurs. The resonance modes of the simulation domain (box) are referred to as ‘box modes’ and present as large-amplitude Lorentzian peaks in the simulations, which may affect the underlying granulation profile. For the simulation suite of Rodríguez Díaz et al. (2022), the box modes have been artificially damped and removed from the time series. The combination of the above makes these simulations particularly apt for providing sufficient resolution as well as avoiding the influence of the prominent box modes in the PDS.
Figure 1 shows the distribution of the simulations in a Kiel diagram (spectroscopic HR diagram). There are 27 simulations spread out, as is indicated in the figure, between 13 different positions in the Kiel diagram (five different potential metallic-ity bins per location). Each simulation provides a time series of the horizontally averaged radiative flux as described by Ludwig (2006). We re-scaled the radiative flux of the simulation box to the entire stellar surface following the approach described by Trampedach et al. (1998) and Ludwig (2006), and subsequently calculated the PDS according to Handberg & Lund (2014). Figure 2 shows the time series and PDS for a solar, subgiant (SGB), and red-giant (RGB) simulation. Contrasted with observed solar-like stars, one can notice the absence of a rise in power at very low frequencies (the ‘activity’) and the lack of an oscillation excess near the indicated νmax. Furthermore, due to the prolonged time series that we consider, the granulation profile of the simulations extends to the very high-frequency regime with low power.
 |
Fig. 1 Kiel diagram displaying the simulation suite from Rodríguez Díaz et al. (2022). The available simulations are plotted for their associated metallicity in vertical stacks. The target (Teff, log g) position for each cluster is indicated by the connected black point. Note that the actual temperature of the relaxed simulations differs slightly from the target value. A sample of solar metallicity stellar evolution tracks with masses ranging from 0.8–2.0 M⊙ have been overplotted to guide the eye. |
 |
Fig. 2 Time series and PDS of three simulations from Rodríguez Díaz et al. (2022), as a reformatted version of their Fig. 3. The time series are plotted as a function of convective turnover times and coloured as indicated by the legend. For each PDS, the raw spectrum is shown in grey with a binned version overplotted in black. The vertical dashed lines indicate the values of νmax ≃ 3094, 363, 12.7 μHz for the solar, SGB, and RGB simulations, respectively. |
2.1 Models for the granulation background signal
Inferring the characteristics of stellar granulation has been done by using various combinations of background components to model the granulation in the PDS. Harvey (1985) used a profile in which an inverse term with a specific exponent, 1/(1 + (πτν)2), controlled the decline of the power in the PDS with increasing frequency, ν, for a given characteristic timescale, τ. Harvey (1985) adopted an exponent of 2 (i.e. a Lorentzian function, following the Fourier transform of the assumed granulation signal in the time domain); however, the choice of exponent has a direct consequence for the shape of the background component, which may introduce systematics if the exponent is not properly accounted for. Each component is thereby described by an amplitude and associated characteristic frequency, νl = (1∕2πτ)l, and an exponent, l. In the following, we present the models for the granulation background signal that are considered in this work, all of which are summarised in Table 1.
Kallinger et al. (2014) performed an evaluation of various background models for main-sequence and RGB stars using data from the Kepler mission (Borucki et al. 2010). They concluded that across their sample their best-performing model was model F, dubbed a super-Lorentzian function, which has two separate components for the granulation background. Given the methodology and stellar sample studied in Kallinger et al. (2014), the exponents of this super-Lorentzian function were found to be indistinguishable from 4. Moreover, this value enabled the background model to reproduce the granulation profile in an extended region around the oscillation excesses of the red giants studied. In this work we have instead chosen, however, to use their model H, which is a generalised version of model F in which the exponents can vary freely. This avoids limiting the explored parameter space by choosing model F, which exists as a nested model inside the generalised model H (i.e. F is a special case of model H in which the exponents equal 4). Additionally, to contrast the performance of single-component and multi-component models, the single-component model, denoted as D, is also included.
Lundkvist et al. (2021) evaluated all the background models of Kallinger et al. (2014) for a 3D hydrodynamical simulation of the Sun from the CO5BOLD code (Freytag et al. 2012). In doing so, they also proposed a new hybrid background model with a single amplitude but two characteristic frequencies describing it, one with a locked exponent of 2 and the other one free. In this work we generalise this model by allowing the exponent to vary, denoting it as model J. The previously locked exponent came from the expectations of a traditional Harvey profile, yet both exponents are expected to match the predictions from Kolmogorov theory of l ~ 5/3 and k ~ 17/3 (Krishan 1991; Hirzberger et al. 1997; Krishan et al. 2002). These expectations are incorporated through the priors outlined in Sect. 3.4.
Lastly, during the preparations for this work, we found that the PDS of several simulations showed a potential bump in power beyond νmax (seen e.g. for the RGB star in Fig. 2 at ν ≈ 16 μHz). This hypothetical third component of the granulation is not clearly seen in real stars, where it would likely be obscured by either an oscillation excess or the level of the white noise. We chose to hypothesise a background model with three individual components, model T, and to evaluate it on equal grounds to the other models across the suite of simulations, despite the reservations about its realistic feasibility. Such a model was also considered by Zhou et al. (2021) (see their Sect. 5.1), who found its performance to be comparable to a two-component model such as H.
For each model seen in Table 1, we have an underlying expectation that the components appear at gradually increasing frequency regimes. For example, for model H, which is thoroughly discussed in Kallinger et al. (2014), the expectation is that both components lie below νmax- the first at lower frequencies and the second just prior to the oscillation excess. These expectations are encoded in our priors to be presented in Sect. 3.4.
Background models used in this work, listed in order of increasing complexity.
2.2 Describing a stellar power-density spectrum
The aim of this work is to evaluate the performance of background models on simulated models of convection. However, while the simulations provide a unique testing ground, the goal is, in time, to proceed to stellar data. To this end, we wish to compare the model performance while they take the functional form that approximates observational data. This means that although the simulations do not contain stellar activity, rotation, or stellar pulsations, we include additional terms to describe them. When applying the framework to the simulations, we can in turn set priors to reflect the non-existence of these terms (see Sect. 3.4). Here, we introduce the various components and their functional form, before arriving at the complete expression that we fit to the data.
Due to the sampling effects introduced by integrating in discretised measurements of the otherwise continuous stellar variations, a partial cancellation of the signal at higher frequencies occurs (Chaplin et al. 2011b). It was found by Kallinger et al. (2014) to influence both the granulation amplitudes and timescales, especially for stars with higher values of νmax. This damping is called apodisation and is a function of frequency and the Nyquist frequency, νNyq, of the time series, calculated as
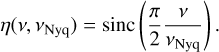 (1)
(1)
Since we are interested in the integrated granulation amplitudes, the apodisation must be accounted for if present. For real stars (such as in Sect. 5) the apodisation factor, η(ν, νNyq), was calculated following Eq. (1) and applied as a multiplicative factor to the background model during the sampling. However, in the case of the simulations, the apodisation was not applied. The simulation snapshots were saved instantaneously at a particular point in time (i.e. at infinitely sharp times); thus, the apodisation stemming from the integration time is not present.
In stellar data, a rise in power is seen in the low-frequency regime. This is often attributed to a combination of stellar activity, rotation peaks, and instrumental effects. We chose to simply describe it by a Harvey-profile with a fixed exponent of 2, amplitude, a2, and a characteristic frequency, b2 (Kallinger et al. 2014; Samadi et al. 2019):
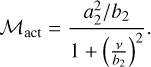 (2)
(2)
Solar-like oscillators show an oscillation excess that presents as a forest of individual Lorentzian peaks on top of the granulation background (Chaplin & Miglio 2013). This can be assumed to be Gaussian and centred at the value of νmax (Bedding 2014), with Posc describing the height and σ the standard deviation:
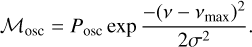 (3)
(3)
Throughout this work, when a calculation of νmax was required we calculated it from the asteroseismic scaling relation (Chaplin & Miglio 2013):
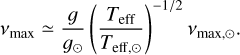 (4)
(4)
Lastly, the white noise level of a real star, in the simulations the end of the granulation slope, is described by a constant offset, W . The constant noise component, W, is unaffected by the apodisation sampling effect, and thus no correction by η(ν, νNyq) was applied to it.
Combining all the components outlined above, we arrived at the complete expression that was fitted to a given PDS:
![Mathematical equation: M(\nu) = \eta(\nu,\nu_\mathrm{Nyq})^2 \left[\xi\mathcal{M}_\mathrm{gran} + \mathcal{M}_\mathrm{osc} + \xi_\mathrm{act}\mathcal{M}_\mathrm{act}\right] + W .](/articles/aa/full_html/2025/09/aa55661-25/aa55661-25-eq10.png) (5)
(5)
Here, a given background model from Table 1 is denoted by Mgran. We reiterate that the apodisation factor, η(ν, νNyq)2, defined in Eq. (1) was not applied when considering the simulations. The factor ξ, as was described in Kallinger et al. (2014), normalises the model components such that the square of the amplitude reflects the area under the function in the PDS1. For a fixed integer value exponent, ξ has analytical solutions, which for an exponent of 2 results in ξ = ξact = (2∕π)2, explaining the multiplication factor on the activity term in Eq. (5). When the exponents are freely varied, as is the case for all of the background models included in this work, ξ does not have an analytical solution and has to be calculated after the fit has been carried out. An approximation of the ξ factors is given in Karoff et al. (2013),
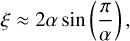 (6)
(6)
where α denotes the inferred exponent of a given granulation component (as is seen in Table 1). Equation (6) holds for all our background models except model J as it is the hybrid model. In this case, we can instead numerically integrate the obtained fit solutions to evaluate the normalisation factor, ξ, and obtain the normalised model amplitude.
3 Bayesian nested-sampling
We sampled the background models in a Bayesian manner. Bayes’ theorem states that the posterior probability density for a set of parameters, θ, given the observed data, D, and model, M, is defined as
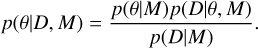 (7)
(7)
Here, p(θ| M) describes the priors on the model parameters to be introduced in Sect. 3.4 and p(D|θ, M) is the likelihood (see Sect. 3.1). The factor p(D|M) normalises the numerator, and is known as the marginal likelihood or evidence, Z, for the data, D, given model M . It is obtained through an integration over all model parameters,
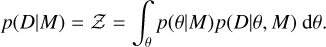 (8)
(8)
The approach to performing the sampling is to build a framework using nested sampling (Skilling 2004). The benefits of nested sampling is that it is able to handle multi-modal posteriors (see e.g. Cai et al. 2022; Dittmann 2024), ensuring convergence to global as opposed to local solutions. Furthermore, it can provide an estimate of Z by approximating the integral of the prior volume, meaning we obtain estimates of both the evidence and samples of the posterior simultaneously. This is contrary to, for example, Markov Chain Monte Carlo methods, which do not generally produce the model evidence and only return samples that are proportional to the posterior. The developed framework uses the software Dynesty2, which is implemented in Python and developed by Speagle (2020). As nested sampling provides an estimate of the evidence, the change in evidence between iterations may be used to set well-defined convergence criteria for the sampling; set to ∆ log(Z) = 0.1 for all purposes of this work, reflecting a strict convergence criteria resulting in increased precision for the obtained evidence.
3.1 Likelihood function
The likelihood function describing independent frequency data in the power spectrum was combined with the χ2 probability distribution function with 2 degrees of freedom (Anderson et al. 1990; Appourchaux 2003; Handberg & Campante 2011),
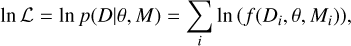 (9)
(9)
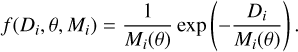 (10)
(10)
Here, D denotes the data, θ the model parameters, and M the given model described by Eq. (5). The index, i, refers to individual frequency bins in the data, with Di and Mi(θ) representing the observed or simulated and modelled power (predicted by a given granulation background) at the i-th frequency bin, respectively. Equations (9) and (10) were combined to provide the log-likelihood expression to be used in this work.
3.2 Mixed-model likelihood approach
In Fig. 2, components in the PDS at very high frequency and low power can be seen. For the evaluation of the granulation model performance, we wish to focus on the regions of the PDS where the granulation signal in real stars is visible, while being insensitive to the regions where simulation artefacts could dominate – such as numerical effects or Lorentzian tails at very high frequencies. For this purpose we implemented a mixed-model likelihood of the form
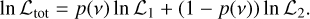 (11)
(11)
Here, L1 is the likelihood including a given background model from Eq. (9). In the second term, L2 is assumed to be a standard χ2 distribution with a constant mean set to 1 % of the power near νmax. The factor p(ν) is a sigmoid function, with upper and lower asymptotes of 1 and 0, respectively. The plateau and slope of the sigmoid is set according to νmax of the given simulation.
Using this sigmoid as the mixture coefficient is a subjective choice acting as an informed prior, the use of which in Bayesian analysis is motivated by Gelman et al. (2020). The choice of the sigmoid function ensures that we do not attempt to implement some complex model for the data, and allows us to instead use Harvey profiles to model it, despite them not reflecting all nuances present in the simulations. Using the sigmoid as the mixture coefficient means that at lower frequency the likelihood described by Eq. (9), which contains our granulation background model, dominates entirely. As we transition past the value of νmax, the sigmoid weight decreases towards 0, allowing L2 (i.e. the constant χ2 likelihood) increasing importance. This effectively reduces the weight of the contributions from the high-frequency components by allowing L2 to absorb the features of the PDS for which we do not have a good model. Hence, our later inferences on model preference are based on granulation signatures similar to our expectation for real stars and not affected by simulation-specific nuances.
Figure 3 visualises the mixed-model likelihood set-up by showing the PDS of the RGB simulation previously shown in Fig. 2. The sigmoid weight, as was described above, was dynamically set according to the computed νmax of the simulation. This is indicated in the figure and one can see how the influence of the high-frequency components begins to be lessened after passing the value of νmax.
3.3 Model comparison
A key aspect of this work is being able to compare the performance of the background models across the simulation suite. Making this comparison means asking a different question than was asked previously. For the fitting of the background models, we wanted to know the optimal parameters, θ, given the data, D, and model, M. Instead, we now want to determine the probability of model M1 given the data, D, and compare it to the probability of another model, M2, given the same data. Hence, we wrote up the posterior odds ratio (see Appendix A for a complete derivation),
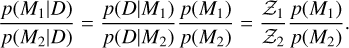 (12)
(12)
The ratio, 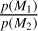 , is the prior odds ratio and reflects our subjective beliefs regarding the considered models. For example, one may consider the single-component model (D) too simplistic to describe the multiple types of variability in stellar data (Kallinger et al. 2014; Zhou et al. 2021; Lundkvist et al. 2021), and we would therefore have a prior preference for the two-component model (H) in comparison. Model comparisons are often simplified by considering only evidence ratios, implicitly setting the prior odds, p(M1)/p(M2) = 1 (e.g. Handberg & Campante 2011; Müllner et al. 2021). This choice assumes no prior preference between models, irrespective of whether one is more physically motivated or sophisticated than another. In this work, we adopt the same convention for simplicity, but explicitly acknowledge the underlying assumptions this entails.
, is the prior odds ratio and reflects our subjective beliefs regarding the considered models. For example, one may consider the single-component model (D) too simplistic to describe the multiple types of variability in stellar data (Kallinger et al. 2014; Zhou et al. 2021; Lundkvist et al. 2021), and we would therefore have a prior preference for the two-component model (H) in comparison. Model comparisons are often simplified by considering only evidence ratios, implicitly setting the prior odds, p(M1)/p(M2) = 1 (e.g. Handberg & Campante 2011; Müllner et al. 2021). This choice assumes no prior preference between models, irrespective of whether one is more physically motivated or sophisticated than another. In this work, we adopt the same convention for simplicity, but explicitly acknowledge the underlying assumptions this entails.
 |
Fig. 3 PDS with sigmoid weighting for the mixed-model likelihood approach for a RGB simulation. The raw spectrum is shown in grey with a binned version overplotted in black. The opacity of the binned PDS is set by the value of the sigmoid weight, indicated by the red profile gradually decreasing from 1 towards 0, as is indicated by the right-hand axis. The mean of the constant χ2 likelihood, L2, is indicated by the horizontal dashed orange line. The νmax of the simulation is indicated by the vertical dashed black line. |
3.4 Priors
In Bayesian analysis, the prior is used to encode our subjective pre-existing belief about the given parameter. The priors that we use are not restrictive, i.e. we allow the prior volume to be large despite the associated computational costs. This choice is made in light of the current limited understanding of the granulation background and the parameters describing its component(s), particularly in the context of the simulations.
The priors for the amplitudes and timescales are set as lognormal distributions, limiting the parameters to being positive, but allowing for an extended tail of the distribution to higher values. Kallinger et al. (2014) derived various scaling relations for the granulation amplitudes and characteristic frequencies in their work, which we generally relied on to inform our priors, with certain nuances depending on the model (see Appendix B). Normal distributions were assumed for the exponents, centred on the optimal values found by Kallinger et al. (2014) and Lundkvist et al. (2021), again depending on the model. In Sect. 2.2 the inclusion of activity and oscillation terms was discussed. We set log-normal priors that reflect their non-existence in the simulations, i.e. an amplitude of ∼0. For an overview of the specific priors for each model and their parameters, see Appendix B.
4 Model preference across the simulation suite
We applied the framework outlined throughout Sects. 2 and 3 to all simulations seen in Fig. 1. We thereby obtained the posterior distributions for the model parameters, adopting the best-fit estimate as the median of the given distribution with uncertainties as the 16th and 84th percentiles. Furthermore, as is outlined in Sect. 3.3, the nested sampling provides the model evidence, Z, when sampling a given model from Table 1. This allowed us to evaluate the model preferences across the simulation suite.
Figure 4 shows the evidence ratios (i.e. assuming the prior odds ratio, p(M1)/p(M2) = 1) of all simulations for the indicated comparisons. One can immediately notice that model D is not preferred over J for any simulation. Model J is preferred over model H in the vast majority of cases, with a few exceptions. Comparing model H to T, we see that model T is clearly preferred except for a few simulations in which they perform similarly. A three-component model is thus generally preferred over a two-component model for the simulations, despite the reduction in the importance of the high-frequency components. Lastly, we compared the hybrid model J to T. Here the situation is complicated: for some simulations, model J is overwhelmingly preferred; for others, it is the opposite. A notable number of simulations (∼8–10) show no significant preference for either model. We note that the apparent non-monotonic model preference in some panels for the solar-like simulation cluster likely arises from the shorter time series duration of the [Fe/H] = 0.0 simulation (∼5 days) compared to the others (∼9–10 days). Lastly, although the Bayesian evidence marginalises over the number of free parameters (see Eq. (8)), it is interesting to see how model J outperforms H and often T while containing fewer free parameters.
Figure 5 shows the samples of models D, J, H, and T for a SGB simulation as an example, for which the model evidence ratios of Fig. 4 show a clear preference for model T. The evidence provides statistically rigorous conclusions regarding model preference, and a visual inspection reveals that the single-component model D fails to represent the data, as it reproduces neither the amplitude level nor the correct shape of the decline in power. Similarly, model H struggles to accurately represent the granulation signal with its two individual components, placing one term below νmax and one above. Model J shifts its upper characteristic frequency past νmax and thereby better represents the data. However, superior to all others in this case is model T, which places two of its components below νmax and the last above. In cases such as the one shown in Fig. 5, model T clearly fits the data better than the remaining models, despite the contributions from the high-frequency components being reduced by the mixed-model likelihood. This interpretation is confirmed by the model evidence we obtained for each sampled background model for this simulation. However, for a number of simulations the third component of model T produces an unnecessarily complicated fit with more free parameters – which is penalised in the marginalisation over all parameters in Eq. (8) – causing models J or H to be preferred, as is presented in Fig. 4.
Given the results presented above, we note that models J, H, and T all have merit for specific simulations. In the following, we evaluate the behaviour of the granulation parameters across the simulation suite for the models, before continuing to the application of the framework to real stellar data in Sect. 5.
 |
Fig. 4 Evidence ratios for the specified model comparisons in increasing complexity. The format of the vertical stacks follow the metallicity convention introduced in Fig. 1, but are now coloured according to the evidence ratios, as is indicated by the colour bar. The Jeffreys scale for model comparison (Jeffreys 1961) is indicated on the colour bar, where beyond |dlog(Z)| ≳ 10 we have overwhelming preference for one model over the other. On the contrary, when |d log(Z)| ≲ 2, no significant preference for either model over the other is found. The levels where |dlog(Z)| ≃ 2 and 5 indicate significant and decisive preference, respectively. |
4.1 Granulation amplitudes and characteristic frequencies
Essential outputs of the nested sampling are samples from the posterior for each fitted parameter. These allow us to inspect the behaviour of the various parameters in the components of the granulation background profiles across the suite of simulations. In Figs. 6 and 7, we show the median of the posterior with uncertainties as the 16th and 84th percentiles for the amplitudes and characteristic frequencies, respectively. For all four background models, the amplitudes decrease with νmax as was expected (Kjeldsen & Bedding 2011; Mathur et al. 2011; Samadi et al. 2013b; Kallinger et al. 2014; Rodríguez Díaz et al. 2022) and generally follow the observationally determined scaling from Kallinger et al. (2014). Notably, the tentative third component of model T shows a similar dependence on νmax, but with significant scatter.
The total bolometric intensity fluctuation stemming from granulation can be estimated as 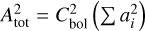 , where
, where 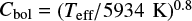 and ai are the normalised amplitude(s) of the given model (Michel et al. 2009; Ballot et al. 2011). Following this, we propagated the errors on the individual normalised amplitudes onto the total granulation amplitude, providing fractional errors in the range 2–10%. For model T specifically, we inspected the residuals in the total granulation amplitude. We found that removing the contribution to Atot of this tentative third component did not increase the scatter in the residuals, as the amplitude of the third component is orders of magnitude lower than the first and second components.
and ai are the normalised amplitude(s) of the given model (Michel et al. 2009; Ballot et al. 2011). Following this, we propagated the errors on the individual normalised amplitudes onto the total granulation amplitude, providing fractional errors in the range 2–10%. For model T specifically, we inspected the residuals in the total granulation amplitude. We found that removing the contribution to Atot of this tentative third component did not increase the scatter in the residuals, as the amplitude of the third component is orders of magnitude lower than the first and second components.
We fitted a power law of the form 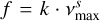 to the total granulation amplitudes Atot for the solar metallicity [Fe/H] = 0.0 dex simulations using the iminuit package3 with the MINUIT algorithm (James & Roos 1975). Per the results in Fig. 4, we omitted the amplitudes estimated by model D, resulting in three fits for the remaining models with 11 data points each. The results are shown in Fig. 6: we found that k = 3040 ± 90, 3140 ± 70, 3050 ± 100 and s = -0.516 ± 0.005, -0.522 ± 0.004, -0.515 ± 0.006, for models J, H, and T, respectively. These results are significantly different from the relation
to the total granulation amplitudes Atot for the solar metallicity [Fe/H] = 0.0 dex simulations using the iminuit package3 with the MINUIT algorithm (James & Roos 1975). Per the results in Fig. 4, we omitted the amplitudes estimated by model D, resulting in three fits for the remaining models with 11 data points each. The results are shown in Fig. 6: we found that k = 3040 ± 90, 3140 ± 70, 3050 ± 100 and s = -0.516 ± 0.005, -0.522 ± 0.004, -0.515 ± 0.006, for models J, H, and T, respectively. These results are significantly different from the relation 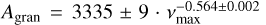 ppm found by Kallinger et al. (2014). This is not entirely surprising as the underlying methodology and the nature of the data (real stars vs simulations) are different. Yet, it emphasises how the determined granulation amplitudes depend on the specific dataset and the chosen model to describe the overall granulation background. Lastly, it is clear from the amplitudes seen in Fig. 6 that a change in the metallicity affects the obtained granulation amplitudes, generally hinting that a decrease in metallicity reduces the granulation amplitude. This trend was also found by Rodríguez Díaz et al. (2022) when inspecting the standard deviation of the simulation time series, and seconds the observational findings of Corsaro et al. (2017) and Yu et al. (2018).
ppm found by Kallinger et al. (2014). This is not entirely surprising as the underlying methodology and the nature of the data (real stars vs simulations) are different. Yet, it emphasises how the determined granulation amplitudes depend on the specific dataset and the chosen model to describe the overall granulation background. Lastly, it is clear from the amplitudes seen in Fig. 6 that a change in the metallicity affects the obtained granulation amplitudes, generally hinting that a decrease in metallicity reduces the granulation amplitude. This trend was also found by Rodríguez Díaz et al. (2022) when inspecting the standard deviation of the simulation time series, and seconds the observational findings of Corsaro et al. (2017) and Yu et al. (2018).
The characteristic frequencies in Fig. 7 similarly scale with νmax, where b and d follow the relation derived by Kallinger et al. (2014). The correlation is also seen for the third granulation component of model T. This is interesting and suggests the presence of a genuine granulation component beyond νmax. However, we caution that while the granulation is expected to scale with νmax, so are the simulation box modes and their harmonics (Nordlund & Stein 2001; Zhou et al. 2021). While the principle box modes are damped in the simulation suite of Rodríguez Díaz et al. (2022), any tentative residuals of the harmonics could be what the third component of model T seeks to model.
 |
Fig. 5 Fits of models D, J, H, and T for a SGB simulation with Teff = 5500 K, log g = 3.5 dex, and [Fe/H] = 0.0 dex. The models were fitted to the unbinned PDS shown in grey, but for clarity a binned version is overplotted, indicating the sigmoid weighting as in Fig. 3. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors were used to repeatedly plot the model alongside, as an indicator of the scatter. For models H and T, the individual components are plotted as dashed green profiles. For model J, the values of the two characteristic frequencies are instead shown as vertical dashed green lines. The value of νmax is indicated by the vertical dashed black line and the offset (as the power of the last points of the simulation PDS) by the horizontal dashed orange line. |
 |
Fig. 6 Granulation amplitudes, normalised by ξi as explained in Sect. 2.2, obtained as the median of the posterior with uncertainties as the 16th and 84th percentiles (often too small to be seen). The colours indicate metallicity following the convention in Fig. 1. The different symbols indicate the various background models. The panels show the amplitudes, a, c, and e, plotted for the associated models. The last panel shows the total granulation amplitude, Atot. In the panels for which direct comparisons to the relations derived in Kallinger et al. (2014) can be made, they are plotted as dashed red profiles. Three power-law fits are shown as the dash-dotted black profiles for the total granulation amplitudes, which completely overlap. |
 |
Fig. 7 Characteristic frequencies obtained as the median of the posterior with uncertainties as the 16th and 84th percentiles (often too small to be seen). The colours indicate metallicity, following the convention in Fig. 1. The different symbols indicate the various background models. In the panels for which direct comparisons to the relations derived in Kallinger et al. (2014) can be made, they are plotted as red dashed profiles. |
Median values of the exponents recovered from the fitting across the simulation suite.
4.2 Exponents of background models
The exponents of the characteristic frequencies control how rapidly the power of the respective granulation component declines. Kallinger et al. (2014) found that for their best-fitting model with two individual components, both exponents were indistinguishable from 4 given the data. Lundkvist et al. (2021) discussed the free exponent of their hybrid model for a solar simulation, finding that a value of around 6 was preferred, but also noting that for the two-component model H values different from 4 were found. In the following, we briefly summarise the median values obtained in this work.
Table 2 shows the median value of the exponent across the simulation suite for the components of the given model. Model D, akin to the standard Harvey profile (Harvey 1985), but with a free exponent, finds an exponent far higher than the originally proposed value of 2. For model J, both exponents are also recovered at values somewhat higher than the expected from the work of Lundkvist et al. (2021). Model H, which according to Kallinger et al. (2014) should display exponents close to 4, returns exponents for both components that are significantly larger than expected. For the three-component model T, a naive expectation simply extrapolating from the two-component model results in the exponents of the inner two components being higher than expected. However, we stress that the exponents may well change when altering the model description. The third component displays the highest exponent of all, corresponding to the sharpest decline in the power with increasing frequency. Thus, across the simulation suite we find for all tested background model descriptions that the exponents are higher than expected.
The simulations are a unique testing ground where no oscillation excess or white noise level can affect our investigations. This results in the granulation profile being visible at lower power and higher frequencies than would be feasible to observe for real stars. That we find higher exponents of the granulation components could suggest that for real stars, the oscillations and white noise levels artificially decrease the granulation exponents. Verifying this indication requires further study, including the first application and subsequent performance assessment of models J and T to stellar data.
5 Extension to stellar data
The development of this framework, while focusing on the unique testing grounds provided by the simulations, is aimed at future application to stellar data. To this end, we tested its performance by carrying out the same model comparison as was done for the simulations for a solar analogue KIC 8006161, popularly called Doris, and subsequently the Sun itself. The difference here to the methods used for the simulation results in Sect. 4 is that we did not use the mixed-model likelihood to reduce the weight of the high frequency regions described in Sect. 3.2. Instead, we used the χ2 likelihood from Eqs. (9) and (10). This choice was motivated by the fact that the granulation background does not extend to very high frequency and low power (as was seen in e.g. Fig. 2); rather, the signal is dominated by an oscillation excess and white noise level. Hence, the priors for the activity and oscillation excess components were changed to reflect their presence (see Appendix B), and νmax was now treated as a fit parameter.
 |
Fig. 8 Fits of models D, J, H, and T to Doris. The models are fitted to the unbinned PDS shown in grey, but for clarity, a binned version is overplotted. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors are plotted to indicate the scatter. For models D, H, and T, the individual components are plotted as dashed green profiles. For model J, the values of the two characteristic frequencies are shown as vertical dashed green lines. The fitted value of νmax is given and indicated by the vertical dashed black line, while the noise is shown by the horizontal dashed orange line. The activity component is the dash-dotted green line. The fitted model without the influence of the oscillation excess in plotted as the dashed blue profile, visible underneath the oscillation excess. |
5.1 Doris – KIC 8006161
Doris was observed by Kepler in short cadence in quarters Q5-17 and has νmax ≈ 3575 µHz, Teff ≈ 5488 K, [Fe/H] ≈ 0.34 dex, and log(g) = 4.94 dex (Lund et al. 2017). We used the full short cadence time series after applying the KASOC filter (Handberg & Lund 2014)4 and computed the PDS following Handberg & Lund (2014).
Figure 8 presents the model fits to Doris. Inspecting the top two panels for models D and J, we see that near the granulation plateau (middle region starting at ν ~ 100 µHz) they perform somewhat similarly. Models H and T are more versatile due to their multiple individual components and thereby describe the transition from the activity component (end of initial slope near ν ~ 30 µHz) to the granulation plateau differently. As was seen for the simulations, model T places two components below νmax and one just above, featuring a very low amplitude in comparison to the two inner components. Nevertheless, model T uses its third component to lift the granulation background slightly underneath the oscillation excess. By inspecting the obtained values of νmax in Fig. 8, we see clearly that they are affected by the underlying model for the granulation background, which is in agreement with the results of Sreenivas et al. (2024).
Table 3 gives the evidence ratios for the same model comparisons as are shown for the simulations in Sect. 4. The picture is quite clear: model J is overwhelmingly preferred to model D, while the same is true for models H or T compared with model J. Models H and T perform similarly, though with a slight preference for model T. Notably, as was seen for several simulations in Sect. 4, model T is quantitatively preferred, here for a real star. This puts into question whether the preference found for the simulations truly was a real granulation signature beyond νmax and not some box mode residual. Yet, in our work the oscillation excess is somewhat crudely modelled by a Gaussian envelope. We note that it is conceivable that the implementation of a more complex model for the oscillations, such as a Voigt profile (Tepper-García 2006) or a mixture model for the likelihood to allow for ‘noise peaks’ (Littenberg & Cornish 2015), could eliminate the preference for model T.
Evidence ratios for model comparison of Doris (KIC 8006161).
 |
Fig. 9 Fit of model T to ≃1150 days of VIRGO data of the Sun. The nomenclature of the plot is as explained in Fig. 8 and the legend. |
5.2 The Sun as a star
Given the results found for Doris, we chose to further test the framework for the Sun. The Sun is very bright, far surpassing what is achievable for other stars, resulting in an extremely low white noise level. In a sense, we may consider the Sun as a star without noise for us to extend our framework to. For this purpose, we used blue-band VIRGO time series data (Froehlich et al. 1988) with a duration identical to that available for Doris ( ≃ 1150 days), taken during the solar minimum between cycle 23 and 24. The PDS was calculated following Handberg & Lund (2014).
Figure 9 shows the fit of model T to the Sun, while the presentation of the other fits and model evidences may be found in Appendix C. In contrast to Doris in Fig. 8, one can clearly see that the white noise is an order of magnitude lower in this case. In the absence of the white noise, we see that model T finds a clear use for its third component beyond νmax, and the evidence indicates an overwhelming preference for model T. Moreover, allowing a third component enables the two inner components to describe the granulation in the frequency regions according to the scaling relations found by Kallinger et al. (2014); in Fig. C.1, it can be seen how model H otherwise shifts its outer component below the oscillation excess in an attempt to better match the presence of power at higher frequencies.
However, while the results found for the Sun corroborate a tentative third granulation component, the nuances mentioned in Sect. 5.1 persist. For the Sun specifically, high radial order n modes can be observed, which directly affects the shape of the oscillation excess. This could lead to a contribution in lifting the underlying slope at the high-frequency end of the oscillation excess, resulting in the preference for model T. An improved model description for the oscillations in the context of investigating the granulation components is thereby further justified for future pursuits.
6 Discussion
This discussion briefly summarises certain results of the present work and relates them to existing findings in literature, before highlighting potential future directions.
6.1 Granulation components and faculae
It was repeatedly seen in Sect. 4 that a background model with two characteristic frequencies (i.e. components) – or more – always outperformed the single-component model. In Fig. 4, this is true for all but a single SGB simulation. However, for this specific simulation a significant modulation signal is present in the PDS, for which the origin is unknown yet clearly artificial.
Notably, this preference occurs in simulations with no magnetic activity. Karoff et al. (2013) argued that a two-component model is required to describe the signal from stellar faculae, which originate from the presence of magnetic fields. Given that we find that multi-component models are preferred in describing the granulation signal of the simulations, we can infer that stellar faculae are not the only potential source of the secondary component.
Magic & Asplund (2014) performed a detailed analysis of the distribution of granule size for Stagger-grid models. They found a broad distribution of granule size that contains two main groups, one smaller than the mean granule size and the other larger (Magic & Asplund 2014, Fig. 3). Furthermore, when investigating the intensity distribution of the granules, differences in the mean bolometric intensities between these two groups were found, the smaller granules being darker and the larger brighter. As the characteristic timescale and lifetime of the granulation correlates with its size, and variations in the intensities were found, granulation power spectra predicted by such surface convection simulations ought to be multi-component. Further considerations of such findings in 3D hydrodynamical simulations and their synergies with observed granulation signals may provide an avenue for deriving more physically grounded models for the granulation background.
Observationally, Kallinger et al. (2014) found that a singlecomponent model is only applicable if the white noise dominates the background, such that the individual components of the granulation and their shape are hidden. How the model preferences in our framework depend on the signal-to-noise ratio and the resolution of observations will be evaluated when applying the framework to a broader range of real stars (Larsen et al., in prep.).
6.2 Interplay of granulation and oscillation signals
For future applications, the interplay between the amplitude of granulation and stellar oscillations deserves consideration. Sreenivas et al. (2025) studied their wavelength dependence and found that the signal from granulation and oscillations have the same wavelength dependence, avoiding the situation where one would obscure the signal of the other.
Intriguing regions for potential utilisation of the granulation background signal and its connection to the underlying stellar parameters (e.g. log(g) using the FliPer algorithm by Bugnet et al. 2018), are stars for which the granulation background may be resolved but the oscillations are not. This could potentially happen if significant damping due to rotation or magnetic fields is present for the oscillations (Chaplin et al. 2011a; Huber et al. 2011; Campante et al. 2014). Furthermore, it could possibly provide an avenue for obtaining a deeper understanding and characterisation of the stars observed by Kepler and TESS (Ricker et al. 2014) for which no oscillations were or are found. For Kepler, Mathur et al. (2017) found ∼2/3 of the observed red giants to be oscillating, and for TESS specifically, Hey et al. (2024) highlighted how limitations in data quality and cadence can complicate the detection and interpretation of oscillation signals for subsequent asteroseismic diagnostics. Applying the developed framework to such cases could provide valuable insights into the nuances of the granulation background, without the presence of robust asteroseismic detections.
7 Conclusion
This work has extended the coverage of PDSs from 3D hydrodynamical simulations for which the performances of various granulation background models have been evaluated. Using the suite of 27 simulations from Rodríguez Díaz et al. (2022), a Bayesian nested sampling framework has been developed for model inference and performance comparison for different background model descriptions. This framework is suitable for further application to stellar data beyond the test cases of Doris and the Sun, in the search for accurate granulation background descriptions. The main insights and conclusions of this work are summarised as follows:
Multi-component granulation background descriptions are always preferred to a single-component model. The hybrid model (J), two-component model (H), and three-component model (T) all have merit for future applications in specific regions of the HR diagram. As the simulations have no magnetic activity and a single-component model is never preferred, stellar faculae cannot be the only source of the second background component;
A tentative preference for a third granulation component beyond the value of νmax was found for numerous simulations. Determining whether this signal is a numerical artefact or a potentially real higher-frequency granulation component will require further study of stellar data of high quality, and likely also developments in the applied model for the oscillation excess;
KIC 8006161, Doris, was used to test the developed framework on stellar data. Upon comparing the models, no significant difference was found between a two-and three-component model, but the single-component and hybrid models were not favoured in this specific case. The results clearly show that the chosen granulation background description affects the νmax determination significantly, and show that the developed framework is suitable for future application to observational data. In the unique case of the Sun, an overwhelming preference for a three-component model was found, yet this may be due to the assumed model for the oscillation excess or the nuances of solar data.
This work presents the preference among different granulation background models used as literature standards and potential extensions of this. Yet, we caution against drawing a direct connection between the conclusions reached here on the basis of simulations and those of real observations. As is seen and discussed in Sects. 4, 5, and 6, the tentative third component of model T may be describing different contributions in the simulations and the observations. For the simulations, it could be reproducing the decrease in the granulation slope beyond νmax, while for the observations it may be handling potential residuals from the oscillation excess. Hence, further rigorous testing and scrutiny of the models showing merit (J, H, and T) during application to a wide range of stars is needed to assess the most suitable background description for application to real stars (Larsen et al., in prep.).
The future potential of drawing on the information embedded in the granulation signal is manifold. With the continuous observations by TESS and the upcoming PLAnetary Transits and Oscillations of stars mission (PLATO; Rauer et al. 2025), the wealth of time series data for a wide variety of stars is increasing steadily. Developing our understanding of the surface manifestation of convection may unveil independent ways of characterising solar-like stars from such observations, potentially yielding not only inferences about the surface gravity but direct information on stellar radii.
Acknowledgements
The authors thank the anonymous referee for the constructive comments made on our paper. JRL wishes to thank the members of SAC in Aarhus and the Sun, Stars and Exoplanets group in Birmingham for comments and discussions regarding the paper. This work was supported by a research grant (42101) from VILLUM FONDEN. MSL acknowledges support from The Independent Research Fund Denmark’s Inge Lehmann program (grant agreement no.: 1131-00014B). Funding for the Stellar Astrophysics Centre was provided by The Danish National Research Foundation (grant agreement no.: DNRF106). The numerical results presented in this work were partly obtained at the Centre for Scientific Computing, Aarhus https://phys.au.dk/forskning/faciliteter/cscaa/. This paper received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (CartographY GA. 804752). This paper includes data collected by the Kepler mission and obtained from the MAST data archive at the Space Telescope Science Institute (STScI). Funding for the Kepler mission was provided by the NASA Science Mission Directorate.
Data availability
The data is available and the fitting framework accessible on GitHub following reasonable request to the first author.
References
- Anderson, E. R., Duvall, Thomas L. J., & Jefferies, S. M. 1990, ApJ, 364, 699 [NASA ADS] [CrossRef] [Google Scholar]
- Appourchaux, T. 2003, A&A, 412, 903 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ballot, J., Barban, C., & van’t Veer-Menneret, C. 2011, A&A, 531, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bastien, F. A., Stassun, K. G., Basri, G., & Pepper, J. 2016, ApJ, 818, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Bedding, T. R. 2014, in Asteroseismology, eds. P. L. Pallé, & C. Esteban, 60 [Google Scholar]
- Böhm-Vitense, E. 1958, ZAp, 46, 108 [NASA ADS] [Google Scholar]
- Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977 [Google Scholar]
- Bugnet, L., García, R. A., Davies, G. R., et al. 2018, A&A, 620, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cai, X., McEwen, J. D., & Pereyra, M. 2022, Stat. Comput., 32, 87 [Google Scholar]
- Campante, T. L., Chaplin, W. J., Lund, M. N., et al. 2014, ApJ, 783, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Chaplin, W. J., & Miglio, A. 2013, ARA&A, 51, 353 [Google Scholar]
- Chaplin, W. J., Bedding, T. R., Bonanno, A., et al. 2011a, ApJ, 732, L5 [CrossRef] [Google Scholar]
- Chaplin, W. J., Kjeldsen, H., Bedding, T. R., et al. 2011b, ApJ, 732, 54 [CrossRef] [Google Scholar]
- Corsaro, E., Mathur, S., García, R. A., et al. 2017, A&A, 605, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dethero, M. G., Pratt, J., Vlaykov, D. G., et al. 2024, A&A, 692, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dittmann, A. 2024, Open J. Astrophys., 7, 79 [Google Scholar]
- Freytag, B., Steffen, M., Ludwig, H. G., et al. 2012, J. Computat. Phys., 231, 919 [NASA ADS] [CrossRef] [Google Scholar]
- Froehlich, C., Andersen, B. N., Berthomieu, G., et al. 1988, VIRGO: The solar monitor experiment on SOHO, In ESA, The SOHO Mission. Scientific and Technical Aspects of the Instruments, 19 (See N90-13302 04-92) [Google Scholar]
- Gelman, A., Vehtari, A., Simpson, D., et al. 2020, arXiv e-prints [arXiv:2011.01808] [Google Scholar]
- Handberg, R., & Campante, T. L. 2011, A&A, 527, A56 [CrossRef] [EDP Sciences] [Google Scholar]
- Handberg, R., & Lund, M. N. 2014, MNRAS, 445, 2698 [Google Scholar]
- Harvey, J. 1985, in ESA Special Publication, 235, Future Missions in Solar, Heliospheric & Space Plasma Physics, eds. E. Rolfe, & B. Battrick, 199 [Google Scholar]
- Hekker, S., Kallinger, T., Baudin, F., et al. 2009, A&A, 506, 465 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hey, D., Huber, D., Ong, J., Stello, D., & Foreman-Mackey, D. 2024, arXiv e-prints [arXiv:2403.02489] [Google Scholar]
- Hirzberger, J., Vázquez, M., Bonet, J. A., Hanslmeier, A., & Sobotka, M. 1997, ApJ, 480, 406 [NASA ADS] [CrossRef] [Google Scholar]
- Huber, D., Bedding, T. R., Stello, D., et al. 2011, ApJ, 743, 143 [Google Scholar]
- James, F., & Roos, M. 1975, Comput. Phys. Commun., 10, 343 [Google Scholar]
- Jeffreys, H. 1961, Theory of Probability, 3rd edn. (Oxford University Press) [Google Scholar]
- Kallinger, T., De Ridder, J., Hekker, S., et al. 2014, A&A, 570, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karoff, C., Campante, T. L., Ballot, J., et al. 2013, ApJ, 767, 34 [Google Scholar]
- Kippenhahn, R., Weigert, A., & Weiss, A. 2013, Stellar Structure and Evolution (Heidelberg: Springer Berlin) [Google Scholar]
- Kjeldsen, H., & Bedding, T. R. 2011, A&A, 529, L8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krishan, V. 1991, MNRAS, 250, 50 [Google Scholar]
- Krishan, V., Paniveni, U., Singh, J., & Srikanth, R. 2002, MNRAS, 334, 230 [Google Scholar]
- Li, Y., Bedding, T. R., Huber, D., et al. 2024, ApJ, 974, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Littenberg, T. B., & Cornish, N. J. 2015, Phys. Rev. D, 91, 084034 [Google Scholar]
- Ludwig, H. G. 2006, A&A, 445, 661 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lund, M. N., Silva Aguirre, V., Davies, G. R., et al. 2017, ApJ, 835, 172 [Google Scholar]
- Lundkvist, M. S., Ludwig, H.-G., Collet, R., & Straus, T. 2021, MNRAS, 501, 2512 [CrossRef] [Google Scholar]
- Magic, Z., & Asplund, M. 2014, arXiv e-prints [arXiv:1405.7628] [Google Scholar]
- Magic, Z., Collet, R., Asplund, M., et al. 2013, A&A, 557, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathur, S., Hekker, S., Trampedach, R., et al. 2011, ApJ, 741, 119 [Google Scholar]
- Mathur, S., Huber, D., Batalha, N. M., et al. 2017, ApJS, 229, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Michel, E., Samadi, R., Baudin, F., et al. 2009, A&A, 495, 979 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morey, R. D., Romeijn, J.-W., & Rouder, J. N. 2016, J. Math. Psychol., 72, 6 [CrossRef] [Google Scholar]
- Müllner, M., Zwintz, K., Corsaro, E., et al. 2021, A&A, 647, A168 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nordlund, Å., & Stein, R. F. 2001, ApJ, 546, 576 [Google Scholar]
- Rauer, H., Aerts, C., Cabrera, J., et al. 2025, Exp. Astron., 59, 26 [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2014, SPIE Conf. Ser., 9143, 914320 [Google Scholar]
- Rodríguez Díaz, L. F., Bigot, L., Aguirre Børsen-Koch, V., et al. 2022, MNRAS, 514, 1741 [CrossRef] [Google Scholar]
- Samadi, R., Belkacem, K., & Ludwig, H. G. 2013a, A&A, 559, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Samadi, R., Belkacem, K., Ludwig, H. G., et al. 2013b, A&A, 559, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Samadi, R., Deru, A., Reese, D., et al. 2019, A&A, 624, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shannon, C. 1949, Proc. IRE, 37, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Skilling, J. 2004, in American Institute of Physics Conference Series, 735, Bayesian Inference and Maximum Entropy Methods in Science and Engineering: 24th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, eds. R. Fischer, R. Preuss, & U. V. Toussaint (AIP), 395 [Google Scholar]
- Speagle, J. S. 2020, MNRAS, 493, 3132 [Google Scholar]
- Sreenivas, K. R., Bedding, T. R., Li, Y., et al. 2024, MNRAS, 530, 3477 [NASA ADS] [CrossRef] [Google Scholar]
- Sreenivas, K. R., Bedding, T. R., Huber, D., et al. 2025, MNRAS, 537, 3265 [Google Scholar]
- Stello, D., Chaplin, W. J., Basu, S., Elsworth, Y., & Bedding, T. R. 2009, MNRAS, 400, L80 [Google Scholar]
- Tepper-García, T. 2006, MNRAS, 369, 2025 [CrossRef] [Google Scholar]
- Trampedach, R., Christensen-Dalsgaard, J., Nordlund, A., & Stein, R. F. 1998, in The First MONS Workshop: Science with a Small Space Telescope, eds. H. Kjeldsen, & T. R. Bedding, 59 [Google Scholar]
- Trampedach, R., Stein, R. F., Christensen-Dalsgaard, J., Nordlund, Å., & Asplund, M. 2014, MNRAS, 445, 4366 [NASA ADS] [CrossRef] [Google Scholar]
- Yu, J., Huber, D., Bedding, T. R., et al. 2018, ApJS, 236, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, Y., Nordlander, T., Casagrande, L., et al. 2021, MNRAS, 503, 13 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A Posterior Odds Ratio
Model comparison within the Bayesian school of thought means evaluating the posterior probability odds ratio, also referred to as the Bayes factor (Morey et al. 2016). To compare model A and B given data D, we must evaluate 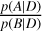 . We may use Bayes theorem to rewrite this as,
. We may use Bayes theorem to rewrite this as,
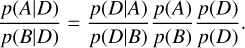 (A.1)
(A.1)
The last factor describing the prior of the data thus cancels. The second term is the prior odds ratio and reflects the prior beliefs before considering the data. The first term depends on the data and has to be calculated. For e.g. the numerator this may be considered as a marginalisation over the free parameters θA of a given model MA,
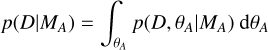 (A.2)
(A.2)
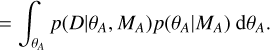 (A.3)
(A.3)
Here, we have used the product rule of probability p(x, y|z) = p(x|y, z)p(y|z) to rewrite the integrand. The integrand is now split into two parts, representing the likelihood and the prior, respectively. We may recognise this integration as the marginalised likelihood, i.e. model evidence Z. These steps can be repeated for model MB with parameters θB and Eq. A.1 may then be written as,
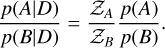 (A.4)
(A.4)
Appendix B Overview of priors
This appendix specifies the various priors used in this work, compiled in Table B.2. They largely rely on the various scaling relations for the granulation amplitudes and characteristic frequencies derived in Kallinger et al. (2014). For modified and new background models, the expected behaviour of the component is encoded in the prior, but still based on the scaling relations of Kallinger et al. (2014). E.g. for the third high frequency component of model T, the priors are set to reflect a lower amplitude and higher frequency than the second component. As model J takes a different shape than the rest, we derived our own scaling relation for its amplitude. This was done by first running test-fits with wide priors set by the scaling relations of Kallinger et al. (2014), before deriving a scaling relation for the amplitude based on the preliminary outcomes, and subsequently using it when producing the results of this work. The exponents of the various models are set following the best-fitting solutions found by Kallinger et al. (2014) and Lundkvist et al. (2021).
Log-space parameters for the power law scaling relations from Table 2 of Kallinger et al. (2014).
Compilation of the priors used for the fit parameters of the various models.
Appendix C Granulation in the Sun
As presented in Sect. 5.2, the developed framework was applied to solar VIRGO data. Figure C.1 shows the results for all four models, while Table C.1 indicate the obtained evidence ratios. The results displayed in the table indicate large preferences for a given model over another, concluding that model T is to be overwhelmingly preferred in the case of the Sun.
Evidence ratios for model comparison of the Sun.
 |
Fig. C.1 Fits of models D, J, H, and T to ≃ 1150 days of VIRGO timeseries data of the Sun. The models are fitted to the unbinned PDS shown in grey, but for clarity, a binned version is overplotted. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors are used to repeatedly plot the model alongside, as an indicator of the scatter. For models D, H, and T, the individual components are plotted as dashed green profiles. For model J, instead the values of the two characteristic frequencies are shown as vertical dashed red lines. The fitted value of νmax is given and indicated by the vertical dashed black line, while the noise is shown by the horizontal dashed orange line. The activity component is the dash-dotted green line. The fitted model without the influence of the oscillation excess in plotted as the dashed blue profile. |
ξ ensures that ![Mathematical equation: $\int_0^\infty(\xi/b)/[1+(\nu/b)^n] \ \textup{d}\nu = 1$](/articles/aa/full_html/2025/09/aa55661-25/aa55661-25-eq30.png) , satisfying Parseval’s theorem such that the area under the function in the PDS equals a2, which in turn equals the variance in the time series (Kallinger et al. 2014).
, satisfying Parseval’s theorem such that the area under the function in the PDS equals a2, which in turn equals the variance in the time series (Kallinger et al. 2014).
The background of nested sampling in Dynesty and the documentation can be found here: https://dynesty.readthedocs.io/en/stable/overview.html
Retrieved from the KASOC database: https://kasoc.phys.au.dk
All Tables
Median values of the exponents recovered from the fitting across the simulation suite.
Log-space parameters for the power law scaling relations from Table 2 of Kallinger et al. (2014).
All Figures
|
Fig. 1 Kiel diagram displaying the simulation suite from Rodríguez Díaz et al. (2022). The available simulations are plotted for their associated metallicity in vertical stacks. The target (Teff, log g) position for each cluster is indicated by the connected black point. Note that the actual temperature of the relaxed simulations differs slightly from the target value. A sample of solar metallicity stellar evolution tracks with masses ranging from 0.8–2.0 M⊙ have been overplotted to guide the eye. |
| In the text | |
|
Fig. 2 Time series and PDS of three simulations from Rodríguez Díaz et al. (2022), as a reformatted version of their Fig. 3. The time series are plotted as a function of convective turnover times and coloured as indicated by the legend. For each PDS, the raw spectrum is shown in grey with a binned version overplotted in black. The vertical dashed lines indicate the values of νmax ≃ 3094, 363, 12.7 μHz for the solar, SGB, and RGB simulations, respectively. |
| In the text | |
|
Fig. 3 PDS with sigmoid weighting for the mixed-model likelihood approach for a RGB simulation. The raw spectrum is shown in grey with a binned version overplotted in black. The opacity of the binned PDS is set by the value of the sigmoid weight, indicated by the red profile gradually decreasing from 1 towards 0, as is indicated by the right-hand axis. The mean of the constant χ2 likelihood, L2, is indicated by the horizontal dashed orange line. The νmax of the simulation is indicated by the vertical dashed black line. |
| In the text | |
|
Fig. 4 Evidence ratios for the specified model comparisons in increasing complexity. The format of the vertical stacks follow the metallicity convention introduced in Fig. 1, but are now coloured according to the evidence ratios, as is indicated by the colour bar. The Jeffreys scale for model comparison (Jeffreys 1961) is indicated on the colour bar, where beyond |dlog(Z)| ≳ 10 we have overwhelming preference for one model over the other. On the contrary, when |d log(Z)| ≲ 2, no significant preference for either model over the other is found. The levels where |dlog(Z)| ≃ 2 and 5 indicate significant and decisive preference, respectively. |
| In the text | |
|
Fig. 5 Fits of models D, J, H, and T for a SGB simulation with Teff = 5500 K, log g = 3.5 dex, and [Fe/H] = 0.0 dex. The models were fitted to the unbinned PDS shown in grey, but for clarity a binned version is overplotted, indicating the sigmoid weighting as in Fig. 3. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors were used to repeatedly plot the model alongside, as an indicator of the scatter. For models H and T, the individual components are plotted as dashed green profiles. For model J, the values of the two characteristic frequencies are instead shown as vertical dashed green lines. The value of νmax is indicated by the vertical dashed black line and the offset (as the power of the last points of the simulation PDS) by the horizontal dashed orange line. |
| In the text | |
|
Fig. 6 Granulation amplitudes, normalised by ξi as explained in Sect. 2.2, obtained as the median of the posterior with uncertainties as the 16th and 84th percentiles (often too small to be seen). The colours indicate metallicity following the convention in Fig. 1. The different symbols indicate the various background models. The panels show the amplitudes, a, c, and e, plotted for the associated models. The last panel shows the total granulation amplitude, Atot. In the panels for which direct comparisons to the relations derived in Kallinger et al. (2014) can be made, they are plotted as dashed red profiles. Three power-law fits are shown as the dash-dotted black profiles for the total granulation amplitudes, which completely overlap. |
| In the text | |
|
Fig. 7 Characteristic frequencies obtained as the median of the posterior with uncertainties as the 16th and 84th percentiles (often too small to be seen). The colours indicate metallicity, following the convention in Fig. 1. The different symbols indicate the various background models. In the panels for which direct comparisons to the relations derived in Kallinger et al. (2014) can be made, they are plotted as red dashed profiles. |
| In the text | |
|
Fig. 8 Fits of models D, J, H, and T to Doris. The models are fitted to the unbinned PDS shown in grey, but for clarity, a binned version is overplotted. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors are plotted to indicate the scatter. For models D, H, and T, the individual components are plotted as dashed green profiles. For model J, the values of the two characteristic frequencies are shown as vertical dashed green lines. The fitted value of νmax is given and indicated by the vertical dashed black line, while the noise is shown by the horizontal dashed orange line. The activity component is the dash-dotted green line. The fitted model without the influence of the oscillation excess in plotted as the dashed blue profile, visible underneath the oscillation excess. |
| In the text | |
|
Fig. 9 Fit of model T to ≃1150 days of VIRGO data of the Sun. The nomenclature of the plot is as explained in Fig. 8 and the legend. |
| In the text | |
|
Fig. C.1 Fits of models D, J, H, and T to ≃ 1150 days of VIRGO timeseries data of the Sun. The models are fitted to the unbinned PDS shown in grey, but for clarity, a binned version is overplotted. The model is plotted in red using the median of the obtained posteriors for each fit parameter. Additionally, 50 randomly drawn samples from the posteriors are used to repeatedly plot the model alongside, as an indicator of the scatter. For models D, H, and T, the individual components are plotted as dashed green profiles. For model J, instead the values of the two characteristic frequencies are shown as vertical dashed red lines. The fitted value of νmax is given and indicated by the vertical dashed black line, while the noise is shown by the horizontal dashed orange line. The activity component is the dash-dotted green line. The fitted model without the influence of the oscillation excess in plotted as the dashed blue profile. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.