| Issue |
A&A
Volume 705, January 2026
|
|
|---|---|---|
| Article Number | A244 | |
| Number of page(s) | 15 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202557168 | |
| Published online | 23 January 2026 | |
Consensus-based algorithm for the nonparametric detection of star clusters (CANDiSC)
1
Instituto de Astrofísica, Depto. de Fisica y Astronomía, Facultad de Ciencias Exactas, Universidad Andrés Bello,
Av. Fernández Concha 700,
Las Condes, Santiago,
Chile
2
Instituto de Astronomía, Universidad Católica del Norte,
Av. Angamos
0610,
Antofagasta,
Chile
3
Universidad Católica del Norte, Departamento de Ingeniería de Sistemas y Computación,
Av. Angamos
0610,
Antofagasta,
Chile
4
Vatican Observatory,
V00120
Vatican City State,
Italy
5
Centro de Astronomía (CITEVA), Universidad de Antofagasta,
Av. Angamos 601,
Antofagasta,
Chile
6
Millennium Institute of Astrophysics (MAS),
Nuncio Monseñor Sotero Sanz 100, Of. 104,
Providencia, Santiago,
Chile
7
Departamento de Astronomia, Instituto de Astronomia, Geofísica e Ciências Atmosféricas, Universidade de São Paulo,
Rua do Matão 1226, Cidade Universitária,
São Paulo
05508-090,
Brazil
8
ESO – European Southern Observatory,
Alonso de Cordova
3107,
Vitacura, Santiago,
Chile
9
Departamento de Física, Universidade Federal de Santa Catarina,
Trindade
88040-900,
Florianópolis,
Brazil
10
Universidade de São Paulo, IAG,
Rua do Matão 1226, Cidade Universitária,
São Paulo
05508-900,
Brazil
11
Observatorio Astronómico, Universidad Nacional de Córdoba,
Laprida 854,
X5000BGR
Córdoba,
Argentina
12
Instituto de Astronomía Teórica y Experimental (CONICET-UNC),
Laprida 854,
X5000BGR
Córdoba,
Argentina
13
Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET),
Godoy Cruz 2290,
Ciudad Autónoma de Buenos Aires,
Argentina
14
School of Physics and Astronomy, Sun Yat-sen University,
Zhuhai
519082,
China
15
Departamento de Matemática, Facultad de Ingeniería, Universidad de Atacama,
Copiapó,
Chile
★ Corresponding authors: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
9
September
2025
Accepted:
1
December
2025
Abstract
Context. The VISTA Variables in the Vía Láctea (VVV) and its eXtension (VVVX) are near-infrared surveys mapping the Galactic bulge and adjacent disk. These datasets have enabled the discovery of numerous star clusters obscured by high and spatially variable extinction. However, most previous searches relied on visual inspection of individual tiles, which is inefficient and biased against faint or low-density systems.
Aims. We aim to develop an automated, homogeneous algorithm for systematic cluster detection across different surveys. Here, we aim to apply our method to VVVX data covering low-latitude regions of the Galactic bulge and disk, affected by extinction and crowding.
Methods. We introduce the Consensus-based Algorithm for Nonparametric Detection of Star Clusters (CANDiSC), which integrates kernel-density estimation (KDE), Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and nearest-neighbor density estimation (NNDE) within a consensus framework. A stellar overdensity is classified as a candidate if identified by at least two of these methods. We applied CANDiSC to 680 tiles in the VVVX PSF photometric catalogue, covering ≈ 1100, deg2.
Results. We detect 163 stellar overdensities, of which 118 are known clusters. Cross-matching with recen catalogues yields five additional matches, leaving 40 likely new candidates absent from existing compilations. The estimated false-positive rate is below 5%.
Conclusions. CANDiSC offers a robust and scalable approach for detecting stellar clusters in deep, near-infrared surveys, successfully recovering known systems and revealing new candidates in the obscured and crowded regions of the Galactic plane.
Key words: Galaxy: bulge / Galaxy: disk / Galaxy: general / globular clusters: general / open clusters and associations: general
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Star clusters are essential building blocks of galaxies and serve as key tracers of stellar evolution, Galactic structure, and chemical-enrichment histories. In the past two decades, wide-field surveys such as the Two Micron All Sky Survey (2MASS; Skrutskie et al. 2006), Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010), Gaia (Gaia Collaboration 2016; Gaia Collaboration 2021), and the VISTA Variables in the Vía Láctea (VVV) and its extension (VVVX) surveys (Minniti et al. 2010; Saito et al. 2024) have greatly expanded the census of stellar clusters in the Milky Way.
We are now witnessing the arrival of even more powerful wide-field surveys, including the Legacy Survey of Space and Time (The LSST Collaboration; Abell et al. 2009), Euclid (Blanchard et al. 2020), and the Nancy Grace Roman Space Telescope (Spergel et al. 2015), which promise to deliver unprecedented photometric and astrometric coverage of the Galaxy. These developments have motivated the emergence of automated and semi-automated techniques to identify star clusters in large and complex datasets.
Among the most widely used approaches for star cluster detection are density-based algorithms such as DBSCAN (Castro-Ginard et al. 2018; Hunt & Reffert 2023), kinematic methods leveraging Gaia proper motions and parallaxes (Cantat-Gaudin et al. 2018; He et al. 2022a), unsupervised machine-learning techniques (Castro-Ginard et al. 2020; Hao et al. 2022), and statistical membership estimation frameworks such as UPMASK and pyUPMASK (Krone-Martins & Moitinho 2014; Pera et al. 2021). These methods have collectively contributed to the discovery of hundreds of clusters across the Galactic disk, halo, and nearby satellites.
Despite this progress, the inner regions of the Milky Way, particularly the bulge and low-latitude disk, remain relatively unexplored due to severe and spatially variable extinction, as well as high source crowding (Minniti et al. 2017c, 2021a). Near-infrared surveys such as the VVVX (Saito et al. 2024) offer a unique opportunity to probe these obscured regions. However, most cluster searches in the VVV and VVVX data have relied on manual visual inspection of individual tiles (e.g., Bica et al. 2018a; Minniti et al. 2017c, 2021e; Garro et al. 2022c, 2024a), a process that is time-consuming, subjective, and biased against faint or diffuse clusters.
The primary objective of this work is to develop and apply a homogeneous, fully automated detection algorithm capable of systematically uncovering stellar cluster candidates across the VVVX footprint, with particular sensitivity to those hidden in high-extinction regions. A secondary goal is to minimize the contamination rate in the final candidate list. As argued in Obasi et al. (2025), many existing supervised and unsupervised cluster detection pipelines suffer from contamination rates as high as 20–30%, which can hinder statistical studies of cluster populations.
To this end, we introduce CANDiSC, a consensus-based, unsupervised clustering framework that combines three independent density-based methods to robustly detect stellar over-densities while minimizing false positives. In this paper, we present the first application of CANDiSC to the VVVX dataset, demonstrate its ability to recover known clusters, and report the discovery of dozens of new candidate systems. While tailored for the VVV and VVVX survey, CANDiSC is designed to be easily adapted to future large-scale photometric surveys such as LSST, Euclid, and Roman1.
This paper is structured as follows. Section 2 describes the VVVX dataset used in this study. Section 3 presents the CAN-DISC algorithm and its implementation. Section 4 summarises the results of the cluster detection. In Sect. 5, we discuss the robustness, limitations, and broader implications of our findings. Section 6 provides concluding remarks and outlines future directions.
 |
Fig. 1 Survey area used in this study. The gray shaded region indicates the 680 VVVX tiles included in the analysis, while the black shaded region shows tiles that were excluded. |
2 Datasets
The VVVX survey (Saito et al. 2024) is the extended phase of the original VISTA Variables in the Vía Láctea (VVV) survey (Minniti et al. 2010), conducted using the 4.1-m VISTA InfraRed CAMera (VIRCAM) on the VISTA Telescope (Emerson & Sutherland 2010) at ESO’s Paranal Observatory. The VVVX survey covers approximately 1700 deg2 in the near-infrared (J, H, Ks) bands, targeting the Galactic bulge and adjacent disk over a longitude range of approximately −130◦ < l < +20◦. With its high spatial resolution and 80% completeness down to ~17.5 mag in the Ks band (Saito et al. 2024), VVVX is ideally suited for detecting obscured stellar populations in the crowded and highly extincted regions of the inner Galaxy. The VVVX survey provides deep, near-infrared photometry with limiting magnitudes of J ≈ 20, H ≈ 19, and Ks ≈ 17.5, delivered as FITS catalogs containing right ascension (RA), declination (Dec), and magnitudes for point sources. The data used in this study are organized into tiles, each covering 1.646 deg2, and include 680 VVVX fields not previously covered in the VVV original footprint. The surveyed region excludes the inner bulge and focuses mainly on the Galactic disk. Figure 1 shows the VVVX footprint used in this work. Tiles that were included in the analysis are shaded in gray, while those that were excluded, particularly near the central bulge, are shaded in black. In this work, we used the point-spread-function (PSF) photometric catalogs produced by Alonso-García et al. (in prep.) using DoPHOT, based on a reprocessing of the VVVX dataset not covered in the VVV original footprint. The catalogs provide high-fidelity photometry for over 700 million sources, with uniform coverage and improved depth compared to previous catalogs based on aperture photometry. No photometric cuts or quality filters were applied prior to the application of the CANDiSC algorithm; this choice was made in order to preserve sensitivity to faint or sparse cluster candidates. The only constraints imposed during detection are a magnitude cut at Ks < 17.5 and a color-magnitude filter (J − Ks) applied within the algorithm to isolate likely cluster members (see Sect. 3). We caution that some problems may occur in the vicinity of very bright saturated objects.
 |
Fig. 2 Color-magnitude and spatial distributions of stars in tiles b0411 (M54), upper panel, and e0621 (Pismis 2), bottom panel. Left panels: 2D histograms showing all sources in (J − Ks) versus Ks diagram. Middle panels: sources passing color-magnitude selection (0.4 < J − Ks < 1.4, Ks < 17.5) are overlaid in red, with the selection boundaries marked by dashed blue lines. Right panels: spatial distributions in RA versus Dec, where all stars are shown in gray, and color-selected sources are shown in red. Blue crosses mark the cluster centers, and dashed blue circles indicate a 0.3◦ radius. |
3 Methodology
3.1 Overview
In this section, we present the Consensus-based Algorithm for Nonparametric Detection of Star Clusters (CANDiSC), which was developed to identify stellar overdensities in the crowded and highly extincted Galactic bulge and disk using near-infrared data from the VVVX survey (Saito et al. 2024). CANDiSC combines three unsupervised density-estimation techniques commonly applied in the literature for overdensity detection: Gaussian kernel-density estimation (KDE; Parzen 1962), density-based spatial clustering of applications with noise (DBSCAN; Ester et al. 1996), and nearest-neighbor density estimation (NNDE; Loftsgaarden & Quesenberry 1965). To enhance robustness against noise and variable cluster morphologies, CANDiSC employs a consensus voting scheme to select candidate cluster members. This ensemble approach is particularly well suited for detecting faint or irregular clusters in crowded fields, such as the inner bulge and disk. By combining the outputs of multiple unsupervised methods, the algorithm increases robustness against false positives and enhances sensitivity to low-density overdensities that may be missed by individual classifiers. As demonstrated in this work, the code successfully identifies candidate clusters with a few members and recovers systems with non-symmetric or sparse morphologies.
3.2 Data preprocessing
To reduce foreground contamination and enhance contrast in the highly reddened Galactic bulge and disk, we applied a color-magnitude filter:
![Mathematical equation: $\left( {J - {K_s}} \right) \in [0.4,1.4],\quad J < 18.5,\quad {K_s} < 17.5,$](/articles/aa/full_html/2026/01/aa57168-25/aa57168-25-eq1.png) (1)
(1)
which is designed to retain distant main-sequence and giant stars while minimizing the contribution from nearby dwarfs and background galaxies. These cuts are optimized for the depth and extinction characteristics of the VVVX survey in the inner bulge area 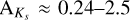 . Figure 2 presents color-magnitude and spatial diagnostic plots for two known clusters in our sample: the globular cluster M54 (tile b0411, centered at RA = 283.75°, Dec = −30.46°) and the open cluster Pismis 2 (tile e0621, cen-tered at RA = 124.48°, Dec = −41.67°). Each row in the figure corresponds to one cluster: M54 in the top panels and Pismis 2 in the bottom panels. The left panel of each row displays (J − Ks) versus Ks color-magnitude diagram of all the stars in the field where the cluster center is located. The log-normalized color-scale indicates stellar density, revealing a broad distribution peaking around J − Ks ∼ 0.5–1.5 and Ks ~ 14–17, which is consistent with a mix of cluster members and field stars. The middle panels highlight stars selected using the color-magnitude cuts described above, overlaid in red on the same CMDs. The dashed blue lines indicate the filter boundaries. This selection effectively isolates the cluster’s main sequence and red giant branch, although some field contamination remains. The right panels show the spatial distribution of stars in equatorial coordinates. All stars are shown in gray, while color-cut-selected stars are plotted in red. A blue cross marks the cluster center, and a dashed blue circle denotes a 0.3-degree radius region used to visualize the cluster extent.
. Figure 2 presents color-magnitude and spatial diagnostic plots for two known clusters in our sample: the globular cluster M54 (tile b0411, centered at RA = 283.75°, Dec = −30.46°) and the open cluster Pismis 2 (tile e0621, cen-tered at RA = 124.48°, Dec = −41.67°). Each row in the figure corresponds to one cluster: M54 in the top panels and Pismis 2 in the bottom panels. The left panel of each row displays (J − Ks) versus Ks color-magnitude diagram of all the stars in the field where the cluster center is located. The log-normalized color-scale indicates stellar density, revealing a broad distribution peaking around J − Ks ∼ 0.5–1.5 and Ks ~ 14–17, which is consistent with a mix of cluster members and field stars. The middle panels highlight stars selected using the color-magnitude cuts described above, overlaid in red on the same CMDs. The dashed blue lines indicate the filter boundaries. This selection effectively isolates the cluster’s main sequence and red giant branch, although some field contamination remains. The right panels show the spatial distribution of stars in equatorial coordinates. All stars are shown in gray, while color-cut-selected stars are plotted in red. A blue cross marks the cluster center, and a dashed blue circle denotes a 0.3-degree radius region used to visualize the cluster extent.
For computational efficiency, we implemented a conditional down-sampling scheme for large catalogs; we retained 10% of sources for datasets (each photometric tile processed) exceeding 3 million entries, 30% for those above 1.7 million, 60% for >1.4 million, all sources for catalogues smaller than 1.2 million. Random selection ensures spatial uniformity while significantly reducing memory usage and maintaining statistical completeness.
3.3 Spatial filtering and sub-tiling
To focus on high-density regions, we applied spatial binning using a 2D histogram of RA and Dec with 120 bins per degree, resulting in bin sizes of approximately 0.00833 degrees (30 arc-sec) in both RA and Dec, scaled to the data’s extent. Only bins with source counts above the 80th percentile of the non-empty bin distribution are retained. To prevent overfitting in crowded fields, bins with more than 10 000 sources are further down-sampled to a maximum of 10 000 sources by random selection. The filtered data are subdivided into a 4 × 4 grid of spatial sub-tiles to account for localized extinction and density gradients. Sub-tiles with fewer than five sources were excluded to ensure robust clustering.
3.4 Density-estimation techniques
Consensus-based algorithm for nonparametric detection of star clusters employs three unsupervised methods to identify over-dense regions within each sub-tile, using sigma-clipped statistics (3σ clipping) to define robust local density thresholds. In the following subsection, we describe each method in detail and summarize how CANDiSC combines their outputs in a consensus approach to flag a target as a cluster candidate.
3.4.1 Kernel-density estimation
Kernel-density estimation is a widely used nonparametric method for estimating the continuous spatial density of point sources, particularly effective in crowded stellar fields (Vio et al. 1994; Ferdosi et al. 2011; Seleznev 2016; Nambiar et al. 2019, and references therein). It works by placing a Gaussian kernel on each star’s position and summing the contributions to produce a density estimate at each star’s location. In our implementation, KDE uses a Gaussian kernel with a bandwidth of h, optimized for the typical angular sizes of VVVX clusters (∼0.05−0.2°). After testing several values, we found h = 0.1° to be most effective. The local density at a star’s position, x, is estimated as
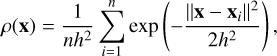 (2)
(2)
where n is the number of stars and xi are their positions. The choice of h is critical; smaller values retain compact structures but amplify noise, while larger values suppress noise but may over-smooth true overdensities (see, e.g., Ferdosi et al. 2011). To identify candidate clusters, we selected stars with KDE-estimated densities, ρ, exceeding a threshold of 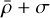 , where
, where 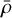 and σ are the σ-clipped mean and standard deviation (using a 1σ clip) of the density field, reducing the impact of outliers and background inhomogeneities. Stars with
and σ are the σ-clipped mean and standard deviation (using a 1σ clip) of the density field, reducing the impact of outliers and background inhomogeneities. Stars with 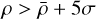 are flagged as overdense, effectively isolating smooth, centrally concentrated stellar systems.
are flagged as overdense, effectively isolating smooth, centrally concentrated stellar systems.
3.4.2 Dbscan
DBSCAN is a widely used unsupervised clustering algorithm that identifies dense groupings of points without requiring assumptions about cluster number or shape (see, e.g., Castro-Ginard et al. 2020; He et al. 2022a,b; Prisinzano et al. 2022; Strantzalis et al. 2024). Clusters are defined as regions where a minimum number of stars (min_samples) lie within a specified neighborhood radius (ε). Points satisfying this condition are labeled as core points, while nearby points are border points. Isolated points that do not meet either criterion are classified as noise. In our implementation, we adopted ε = 0.1° and min_samples = 5, values optimized for typical VVVX cluster sizes. For each group identified by DBSCAN, we compute its effective density as
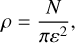 (3)
(3)
where N is the number of member stars. We define overdense clusters as those with 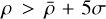 , where
, where 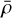 and σ are the mean and standard deviation of cluster densities after 3σ clipping, ensuring robustness against outliers. DBSCAN’s ability to recover arbitrarily shaped structures makes it well suited for the crowded and highly variable stellar environments of the inner Galactic bulge. Moreover, it provides a complementary detection strategy to KDE, enhancing redundancy and robustness in our overall pipeline, with both methods using 3σ clipping for consistency in outlier removal (though KDE applies a less stringent initial threshold of
and σ are the mean and standard deviation of cluster densities after 3σ clipping, ensuring robustness against outliers. DBSCAN’s ability to recover arbitrarily shaped structures makes it well suited for the crowded and highly variable stellar environments of the inner Galactic bulge. Moreover, it provides a complementary detection strategy to KDE, enhancing redundancy and robustness in our overall pipeline, with both methods using 3σ clipping for consistency in outlier removal (though KDE applies a less stringent initial threshold of 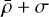 for candidate selection).
for candidate selection).
3.4.3 Nearest-neighbor density estimation (NNDE)
The third clustering algorithm employed in this study is NNDE (Loftsgaarden & Quesenberry 1965), a non-parametric method that estimates local stellar density based on the distance to the k-th nearest neighbor. The density around each star is given by
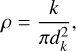 (4)
(4)
where dk is the distance to the k-th nearest neighbor. In our implementation, we adopt k = 5, based on sensitivity tests using values of k = 3, 5, 7, and 10, which showed that k = 5 offers a good balance between sensitivity to local overdensities and robustness against noise in the VVVX dataset. This choice is also supported by statistical studies recommending small k values for local density estimation (e.g.; Kung et al. 2012). We identify overdense sources as those with 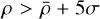 , where
, where 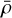 and σ are calculated after applying 3σ clipping to the full density distribution. NNDE is highly sensitive to local variations in source density and naturally adapts to changes in crowding, making it effective in both the dense stellar fields of the Galactic bulge and more diffuse regions (Casertano & Hut 1985). NNDE serves as the final redundancy to KDE and DBSCAN, enhancing the algorithm’s ability to detect low-contrast and irregularly shaped stellar overdensities that may be missed by the other two methods.
and σ are calculated after applying 3σ clipping to the full density distribution. NNDE is highly sensitive to local variations in source density and naturally adapts to changes in crowding, making it effective in both the dense stellar fields of the Galactic bulge and more diffuse regions (Casertano & Hut 1985). NNDE serves as the final redundancy to KDE and DBSCAN, enhancing the algorithm’s ability to detect low-contrast and irregularly shaped stellar overdensities that may be missed by the other two methods.
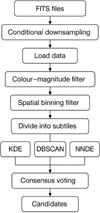 |
Fig. 3 Flowchart of CANDiSC, the Consensus-based Algorithm for Nonparametric Detection of Star Clusters. |
3.5 Consensus detection strategy
Each of the three detection techniques: KDE, DBSCAN, and NNDE produces a binary mask indicating whether a star lies in a locally overdense region within a given sub-tile. To reduce method-specific biases and improve detection reliability, we implemented a consensus voting scheme. A star is flagged as a candidate cluster member if it is identified as overdense by at least two of the three methods:
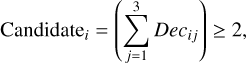 (5)
(5)
where Decij = 1 if method j identifies star i as overdense, and 0 otherwise. This majority-voting approach minimizes spurious detections caused by noise or local field fluctuations in any single method while maintaining sensitivity to genuine stellar over-densities. When combining independent density estimators, the final list of candidate members is statistically robust and physically meaningful, which is especially important in the crowded and differentially extinct fields. A schematic overview of the detection pipeline is shown in Fig. 3.
3.6 Parallel execution and output
Given the high computational demand, especially for large tiles, the pipeline is parallelized using joblib.Parallel with memory-aware core allocation.
Candidate stars (RA, Dec) are saved as FITS tables for further analysis. The pipeline is implemented in Python, using scikit-learn (Pedregosa et al. 2011) for DBSCAN and NNDE, scipy (Virtanen et al. 2020) for KDE, and astropy (Robitaille et al. 2013) for FITS handling and σ-clipped statistics.
Clusters used for validation of CANDiSC code.
 |
Fig. 4 Density distribution maps for VVVX tiles containing clusters used to validate CANDiSC code. Left panel: stellar-density maps for fields of M54 (b0411), NGC 6652 (b0436), NGC 6293 (b0490), and NGC6325 (b0492). The upper and lower subpanels correspond to different tiles. Right panel: same maps as in left panel, now overplotted with candidate cluster members identified by CANDiSC. The legend indicates the number of recovered members for each cluster. |
3.7 Validation of the algorithm with VVVX data
To validate the performance and reliability of CANDiSC, we applied the full detection pipeline to a test sample of well-characterized globular and open clusters within the footprint of the VVVX survey. These clusters are distributed across varying degrees of crowding, extinction, and structural concentration, providing a representative benchmark for inner Galaxy cluster detection. The sample, summarized in Table 1, includes classical bulge globular clusters such as M54, NGC 6652, NGC 6293, and NGC 6325, as well as looser open clusters including ESO 425-3. The columns show the VVVX tile name, literature cluster name, object type, central coordinates (J2000), and the number of member stars detected by CANDiSC.
CANDiSC was executed on ten VVVX tiles containing these clusters, each processed through the full pipeline described in Sect. 3. For each tile, the algorithm outputs a FITS file named membership_candidates.fits, which stores the RA and Dec of all stars identified as candidate cluster members.
The detection parameters for each of the underlying methods; KDE bandwidth, h; DBSCAN neighborhood radius, ε; min_samples; NNDE neighbor count; k; and the overdensity detection threshold, σ, were optimized through an extensive grid search combined with objective performance evaluation test. For KDE, h was varied between 0.05° and 0.2° in steps of 0.025°, which reflects the expected angular sizes of VVVX clusters. For DBSCAN, ε ranged from 0.05° to 0.15° in steps of 0.025°, and min_samples ranged from 3 to 10. For NNDE, k values of 3, 5, and 7 were tested. The detection threshold σ was varied between 3.0 and 6.0. We selected optimal parameter combinations by maximizing the recovery rate of known cluster members and minimizing false positives, as quantified through cross-matching with the literature catalog of Kharchenko et al. (2013). Finally, visual inspection of the output density maps was conducted, and it serves as an additional qualitative check to confirm spatial clustering.
Each detection was then manually inspected to verify the presence of spatial clustering and its consistency with known cluster positions. Remarkably, even in cases of highly dispersed open clusters such as ESO 425−3 (detected in tile e0609), a single overdensity was sufficient to justify re-running the code with an adjusted set of parameters particularly by widening or contracting the range of the color cut, as described below. When the object is statistically significant, modifying certain parameters can enhance the number of detected members, thereby improving the overall recovery of the cluster members.
Figures 4–5 illustrate the validation results. The left panels show the stellar-density distribution in fields containing M54 (b0411), NGC 6652 (b0436), NGC 6293 (b0490), NGC 6325 (b0492), CWNU 4193 (e0618), CL Pismis 2 (e0621), CL Haffner 15 (e0613), and M19 (b0503). The right panels show the same fields with candidate members identified by CANDiSC overplotted.
Positional accuracy of the detected candidates exceeds 99%, as confirmed by cross-matching with cluster centers from the literature. The algorithm is highly selective, identifying only localized overdensities consistent with known clusters, and avoids false positives in uniform fields. In Sect. 4.2, we report that the overall false-positive rate is below 5%, with the majority of spurious detections attributable to dark nebula, variable stars, and eclipsing binaries in crowded fields, likely flagged due to local density fluctuations or photometric outliers. Notably, each of these spurious detections contains fewer than five member stars. We note that for the sparse or open clusters, expanding the color cut to 0.3≤J-Ks ≤ 1.4, increase the number of detected stars significantly (e.g., ESO 425-3, which was improved from 1 to 15 members). This suggests the need for a flexible color cut in low-density environments. These results affirm that CANDiSC reliably recovers genuine stellar overdensities in both compact and diffuse clusters and can operate effectively in the challenging inner Galaxy environment targeted by infrared surveys such as VVVX.
 |
Fig. 5 Same as Fig. 4 but for CWNU 4193 (e0618), Pismis 2 (e0621), Haffner 15 (e0613), and M 19 (e0503). The maps show the stellar-density distributions in each VVVX tile, with the identified cluster members overplotted. The legend reports the number of recovered members for each cluster. |
3.8 Validation of the algorithm with synthetic data
We constructed a synthetic dataset designed to reproduce the characteristics of the VVVX observations, allowing us to quantify, in a controlled setting, the detection efficiency and photometric recovery performance of our pipeline and to expose potential limitations that cannot be directly probed with real data. A suite of artificial stellar clusters was injected into realistic VVVX fields as shown in Figure 6, where we show one example of our generated synthetic data overplotted with the injected cluster members. These simulations were generated using a custom Python framework that models both field and cluster populations via KDEs of the observed photometric distributions.
Figure 7 illustrates an example of the observed and synthetic datasets (left–right), with the upper panels showing their respective CMDs and the lower panels their color-color diagram distributions. Field stars were resampled from the empirical J-Ks versus Ks and J-H versus H-Ks density distributions of the input catalog. This ensures that the synthetic background accurately reproduces the color-magnitude structure and completeness characteristics of the data.
Cluster members were spatially distributed according to a Plummer-like profile (Plummer 1911) and assigned photometry drawn from the same KDE models, with an optional locus prior to preserve the median (J-Ks vs. Ks) relation of the field population. Differential reddening was simulated by applying a Gaussian extinction patch centered on each cluster, adopting the extinction ratios AJ/AV = 0.282, AH/AV = 0.175, and AKs/AV = 0.114 (Cardelli et al. 1989).
The simulations span a three-dimensional grid of cluster parameters: richness (N⋆ = 80–600), angular half-light radius (rh = 0.005–0.03°), and line-of-sight extinction (AV = 0.5–3.0 mag). Each configuration was realized five times to account for stochastic variance, resulting in a total of 315 synthetic fields. Every realization is stored as a combined FITS catalog containing both field and cluster stars, together with a separate CSV catalog listing only cluster members. This dataset provides a reproducible and statistically controlled framework for evaluating the completeness and parameter-recovery accuracy of our cluster detection algorithm.
After creating our synthetic dataset, we processed it through the CANDiSC pipeline using the default settings described in Sect. 3.7. We initially found that the pipeline has difficulty recovering clusters with fewer than 60 members, as these tend to blend with the field stars. Based on this, we set a minimum cluster size of 80 members and then explored the effect of varying key parameters to enhance detection sensitivity. Specifically, we adjusted the spatial binning threshold to the 90th percentile of nonzero histogram bins (from the default 80th percentile) to focus on denser regions. For overdensity detection, we set the KDE bandwidth to 0.09 (from 0.1); the DBSCAN ϵ to 0.08 (from 0.1), with a minimum of 15 samples (from 5); and the NNDE k to 10 (from 5), all while increasing the σ threshold to 4.0 (from 3.0) for all methods to enforce stricter overdensity criteria. The results and detailed diagnostics of these analyses are presented in Appendix B. Here, we only summarize the global completeness behavior relevant to the main catalog. A full evaluation of the recovery distributions, the dependence on extinction and cluster size, the astrometric offsets, and the purity-completeness relation are provided in Appendix B. To summarize the pipeline’s performance across the full parameter space of the synthetic injections, in Fig. 8 we present the completeness surface maps for the default and tuned configurations. These maps highlight the global dependence of detection efficiency on cluster richness and extinction, and they provide the overview that complements the detailed diagnostics discussed in Appendix B. The default configuration (left panel) shows a clear “sweet spot” at R ~ 300 and AV ~ 1 mag, where completeness exceeds 80%, with detection limits primarily driven by extinction and cluster size. The tuned configuration (right panel) shows notable improvements at the low-richness and high-extinction edges of the parameter space. For example, the recovery rate increases to 0.53 at AV = 0.5, R = 80, and to 0.27 at AV = 3.0, R = 80, compared to 0.40 and 0.00 in the default case. While these gains indicate enhanced sensitivity to faint or reddened clusters, the improvement across intermediate richness values is less uniform, with the most significant enhancement occurring near the lower R boundary.
 |
Fig. 6 Density distribution map of synthetic injection field in RA, Dec. The background color-scale represents the squared and logarithmically normalized spatial density of all injected stars. Blue points denote the positions of the recovered members of the injected cluster containing 600 stars. |
 |
Fig. 7 Observed (left) and synthetic (right) catalogs of the VVVX-like color-magnitude (top panels) and color-color diagram (bottom panels). The synthetic catalog reproduces the observed near-infrared stellar locus and photometric distributions using KDE resampling and a locus prior. |
 |
Fig. 8 Two-dimensional completeness surface (heat map) showing mean recovery rate as function of cluster radius (R) and extinction (AV; left-right panel default and tuned configuration). For the default configuration, completeness decreases toward smaller radii and higher extinctions, and it becomes extreme at R=80, where it drops to 0. In contrast, for tuned settings, completeness gradually increases toward larger radii and lower extinction. The plot also shows the parameter space where the pipeline remains reliable. |
4 Results
We applied the CANDiSC algorithm to the full set of VVVX fields not previously covered in the VVV original footprint. Each tile corresponds to a specific region in the VVVX survey, and in total we analyzed 680 tiles. After processing, CANDiSC identified 163 candidate stellar overdensities. Among these, 118 objects correspond to known entries in the SIMBAD database2, including several clusters previously discovered in the VVVX footprint (see Garro et al. 2022a, 2024b). Each of these candidate stellar overdensities was visually inspected using composite images available in SIMBAD, including Pan-STARRS DR1 color images (constructed from g and z bands) and DECam Plane Survey DR1 images (in g, r, and z bands). These visual inspections confirmed that the spatial overdensities are consistent with stellar clusters. Representative examples of the newly detected candidates are shown in Fig. 9. In the upper panels, we show cluster candidates detected in tiles e0602 (left) and e1022 (right), located at RA, Dec = 108.095°, 18.160° and 127.91°, −41.78°, respectively. The lower panels− display candidates from tiles e0965 (left) and e1047 (right), cen-tered at RA, Dec = 275.12°, −14.23° and 110.75°, −16.67°, respectively.
Furthermore, we retrieved the Gaia counterparts for each detected overdensity and analyzed three distinct properties: proper motion, CMD, and spatial stellar distribution. These were used to assess whether the identified overdensities show the expected characteristics of stellar clusters. Figure 10 presents these diagnostics for the clusters shown in Fig. 9. The left panel shows the distribution of stars in proper motion space. The x-axis represents the proper motion in (µα cos δ), and the y-axis shows the proper motion in (µδ), both in (mas yr−1). All stars within a radius of r ∼ 0.4 deg. and a parallax tolerance of 0.5 mas are plotted in gray. The cluster members, identified using the HDBSCAN algorithm, are highlighted in red, and the inset is projected onto this region. The inset in the upper left corner zooms in on the overdense area, where red points mark stars located within a 2σ threshold around the proper-motion peak indicated with a black dot. This tight grouping confirms the reliability of the identified members.
The middle panel shows the Gaia CMD, with BP−RP color versus G-band magnitude. Gray points represent the full stellar population in the field, while red points indicate the cluster members, albeit with some residual field contamination. These members form a clear sequence that is consistent with a single-age stellar population, suggesting the presence of a main sequence and possibly a turn-off or red giant branch. In contrast, the broader distribution of field stars, particularly at fainter magnitudes (G > 16), highlights the effectiveness of the selection criteria based on proper motion and parallax.
The right panel shows the spatial distribution of stars around the cluster center. The x-axis indicates the offset in (∆RA cos Dec) and the y-axis the offset in (∆Dec), both in degrees. Gray points represent all stars within a radius of approximately 0.4°, while red points mark the HDBSCAN-selected cluster members, which still show some residual field contamination. The members are concentrated within about 0.3° of the cluster center, which is consistent with a typical tidal radius, whereas the field stars are more widely scattered. The central overdensity of each cluster is also indicated by a gray circle.
To determine whether the remaining 45 detections are new, we cross-matched them against recently published cluster cat-alogs (Qin et al. 2023; Hunt & Reffert 2023; He et al. 2022a; Gupta et al. 2024). Given the high stellar density and source confusion in the inner bulge and disk, as well as possible astro-metric offsets between catalogs, we performed a cross-match analysis to evaluate the optimal radius for source association. We tested a range of radii from 30′′ to 360′′ and calculated the cumulative number of matches as a function of radius. Figure 11 shows the resulting curve: the number of matches increases steeply up to ∼60′′, beyond which the growth plateaus, indicating the increasing contribution of spurious matches. We adopted a matching radius of 60′′, marked by the vertical dashed red line and highlighted at the point (60′′, 5). While this value captures most genuine associations, it is unusually large and may reflect underlying astrometric discrepancies, which will be further assessed in future work. The coordinates of our cluster candidates used for the cross-match correspond to the centroid of the stellar overdensity identified by CANDiSC. For the reference catalogs, we adopted the published central coordinates. This approach ensures that the cross-match is performed consistently using centroid-based positions in both datasets. The cross-match revealed the following:
zero matches with the catalog of Qin et al. (2023);
five matches with Hunt & Reffert (2023), but the number increases to seven at 360′′;
one match with He et al. (2022a) at 300′′ radii;
zero matches with Gupta et al. (2024).
After accounting for all overlaps, we identify 40 candidate clusters that, to the best of our knowledge, are not present in any existing public catalog, assuming a 60′′ matching radius. A summary of the detection and cross-matching results is provided in Table 2. Tables A.1 and A.2 show the 40 new candidates and ten rows of the recovered clusters, respectively. The complete catalogs comprising both tables are available online in machine-readable format3. These new candidates will be discussed in detail in a forthcoming paper.
Figure 12 shows the distribution of cluster candidates identified by CANDiSC in Galactic coordinates. The upper left panel presents these candidates overlaid on an Aitoff projection of the VVVX survey footprint. Red points indicate our new detections, while blue points correspond to 7884 previously known inner bulge/disk clusters compiled from literature sources based on VVV and VVVX data (Barbá et al. 2015, Barbá et al. 2019; Bica et al. 2018a; Bidin et al. 2011; Borissova et al. 2011, 2014, 2018, 2020; Camargo & Minniti 2019; Dias et al. 2022; Garro et al. 2020, 2021, 2022b,c,a, 2024a; Ivanov et al. 2017; Minniti et al. 2011, 2017b,c,a, 2019, 2021b,e,c; Obasi et al. 2021; Saroon et al. 2024). The upper right panel compares our detections with the distribution of known Milky Way clusters from the catalogue of Bica et al. (2018b), which contains over 10 000 entries. Galactic longitude (l) ranges from −60° to +60°, and latitude (b) from −15° to +15°.
We also show a smoothed stellar-density model, combining a bulge component with the exponential scale lengths l0 = 10° and b0 = 5° and a disk component with l0 = 20° and b0 = 2°. The density field is normalized and color-coded, with a horizontal color bar indicating the scale. Known clusters from Bica et al. (2018b) are plotted as gray points, with point sizes scaled to their major axis in arcminutes; a separate color bar indicates this scale. Axis labels indicate Galactic longitude and latitude in degrees, and a grid is overlaid for reference. The legend in the upper right corner identifies all plotted elements.
The bottom panel shows the same data in equatorial coordinates (RA, Dec). Our new detections follow the overall spatial distribution of known VVV and VVVX clusters, supporting the robustness of the search method. At the same time, they extend the census into regions of the VVVX footprint that were sparsely populated in the literature, thereby highlighting underexplored areas of the inner Galaxy.
 |
Fig. 9 Composite images of subset of newly detected cluster candidates. Upper row: clusters from tiles e0602 and e1022. Lower row: clusters from tiles e0965 and e1047. Panels a and c are based on Pan-STARRS images, and panels b and d use DECam Plane Survey (DECaPS) DR1 color composites constructed from the g, r, and z bands. |
 |
Fig. 10 Diagnostic plots for a candidate stellar cluster identified in the VVVX survey using Gaia data. Left: proper motion diagram (µα cos δ vs. µδ, in mas yr−1), where gray points represent all stars within 0.4 degrees and 0.5 mas of the cluster center. A red dot where the inset line is projected indicate HDBSCAN-selected members. The inset highlights stars within 2σ of the proper motion centroid in black dot. Middle: Gaia color–magnitude diagram (BP–RP vs. G), showing HDBSCAN-selected cluster members (red) tracing a distinct main sequence, albeit contaminated among field stars (gray). Right: spatial distribution in ∆RAcos (Dec) and ∆Dec (degrees). HDBSCAN selected Cluster members (red) are concentrated within 0.3 degrees of the center, while field stars (gray) appear scattered. We indicate the cluster overdensity, centered on the black circle with a radius of 0.15°, which is clearly distinct from the surrounding field. Each panel corresponds to one of the clusters shown in Fig. 9: the first panel shows the cluster centered on tile 0602 (panel a), the second panel on tile e1022 panel b, and the third and fourth panels on tiles e0965 (panel c) and e1047 (panel d), respectively. |
 |
Fig. 11 Cross-match analysis of 60 candidate stellar overdensities with recent cluster catalogs. |
Summary of cluster detection and cross-identification results.
 |
Fig. 12 Top left: spatial distribution of newly detected VVVX clusters (red) overplotted with previously detected VVV and VVVX clusters (blue). Top right: same plot, but showing only our new detections and known clusters from Bica et al. (2018b, gray). Bottom: our new detections (red) overplotted with previously known VVV and VVVX clusters in equatorial coordinates (RA, Dec). |
4.1 Limitations of CANDiSC
One of the limitations of CANDiSC is that the cluster membership recovery depends on the adopted color cut. In stellar clusters, especially those in the inner bulge and disk, stellar colors vary significantly due to a combination of extinction, crowding, and metallicity effects. Although stellar color broadly correlates with cluster age, this relationship is complex in these regions. The color cuts inherently limit the range of physical parameters such as age, extinction, and distance for which the cluster search is effective. This is particularly relevant for clusters in regions of high and spatial differential reddening or those at greater distances, where the stellar colors may be shifted outside the initial cut range.
After testing several color cuts, we adopted an initial selection of (J − Ks) ∈ [0.4, 1.4], which is generally sensitive to a wide range of cluster populations. In some cases this cut yielded only a single likely member, but such detections were sufficient to motivate a refined cut for verifying potential overdensities. This choice may also explain the lack of overlap with mid-infrared clusters identified by Gupta et al. (2024).
Our default selection entirely missed the most heavily reddened inner-bulge systems, such as Liller 1 (Pallanca et al. 2021), 2MASS-GC02 (Alonso-García et al. 2015), and VVV-CL160 (Minniti et al. 2021b), which have extreme colors (J − Ks ~ 1.5–4) outside the adopted range. The challenge is that no single color cut can isolate all clusters simultaneously without first correcting the tiles for differential reddening, a procedure that is computationally prohibitive to apply on the fly. While the color cut we adopted performs well for less reddened regions, it limits the recovery of clusters with extreme reddening or those in the far bulge. Nonetheless, this limitation is a trade-off between computational efficiency and completeness.
Although these objects lie outside our primary search region, which is less reddened and well-suited to the adopted cut, we tested their recovery using tailored ranges matched to their known reddening. For Liller 1, we adopted 1.8 < J − Ks < 2.8, Ks < 15; for 2MASS-GC02, it was 2.0 < J − Ks < 4.0, Ks < 17.5, while for VVV-CL160 we adopted, 1.6 < J − Ks < 2.4, Ks < 16.0. This approach successfully recovered both systems, but failed to retrieve VVV-CL160.
This experiment suggests an avenue for future work: systematically applying color cuts tailored to differential reddening across the bulge may reveal additional, heavily obscured globular clusters that remain undetected. Remarkably, even with this initial color cut, CANDiSC successfully identified several known clusters with very low membership counts, underscoring its sensitivity. For example, tile e1090 at RA, Dec = 174.30°, −62.74° yielded only two members, but it corresponds to [FSR2007] 1591 in the Kharchenko et al. (2013) catalog. Similarly, only two members were identified in tile e1058 (RA, Dec = 119.84°, −30.76°), associated with [FSR2007] 1336 (Kharchenko et al. 2013). Even more striking are cases where only a single member was detected, yet these correspond to known clusters: for example, e0692 (RA, Dec = 114.29°, −26.37°) is associated with CL Alessi 18 (Kronberger et al. 2006), e0609 (113.86°, −27.69°) with ESO 429-3 (Kharchenko et al. 2013), and e1095 (113.69°, −19.80°) with DSH S0734.6–1947 (Kronberger et al. 2006). Notably, the globular cluster NGC 6355 (Di Criscienzo et al. 2006) in tile b0463 (260.99°, −26.35°), located in a high-extinction bulge region, was also identified by just one member. Following the identification of these clusters with low member counts, we broadened the adopted color-cut range to improve the isolation and recovery of cluster members. Because these clusters are generally redder than our default color selection, primarily due to spatial differential reddening expanding the color range, as summarized in Table 3, allowed us to retrieve additional members. Overall, the initial (J − Ks) range of [0.4, 1.4] remained the most robust for detecting diverse cluster populations across the survey. In general, after testing various color cuts, we find that when the number of recovered members is fewer than five in all the color cuts adopted, the corresponding target should be treated with caution.
4.2 False positives
While the CANDiSC algorithm demonstrates high reliability, we assessed its susceptibility to false-positive detections, particularly in cases where fewer than five members are recovered. Such low member detections are more prone to contamination from non-cluster sources, including isolated evolved stars, variable stars, and dark nebulae that may mimic the spatial profile of genuine clusters. Out of the 163 targets identified by CANDiSC, we find three objects that are likely false positives based on cross-identification with SIMBAD. These are listed below.
Tile e0787, which at coordinates RA, Dec = 131.85°, −39.03° matches the dark nebula TGU H1669 (Dobashi et al. 2005), with two members detected by CANDiSC.
Tile e0770, which at RA, Dec = 115.53°, −17.82° corresponds to the variable star ATO J115.5033−17.8211 (Zacharias et al. 2013), with one member recovered.
Tile e0854, which at RA, Dec = 117.33°, −19.05° matches the eclipsing binary Gaia DR3 5715909087889352320 (Eyer et al. 2023), with three members detected.
To assess the robustness of our selection criteria against contamination, we varied the color cut for these false-positive cases by adopting the following intervals: 0.3 ≤ J − Ks ≤ 1.4, 0.6 ≤ J − Ks ≤ 2.0, and 0.5 ≤ J − Ks ≤ 1.4. For tile e0787, zero mem- were bers recovered across all cuts. Similarly, tile e0770 returned zero detections for each cut. For tile e0854, only two members were recovered in the first interval, with none in the others. These results suggest that contaminating sources rarely reproduce the typical color distribution of real clusters, which generally spans J − Ks values from 0.3 to 2.0. This provides an additional validation step that supports the reliability of our final cluster sample. If we only consider these three confirmed misidentifications, the contamination rate is 3/163 ≈ 1.8%. We note that this value only represents confirmed misidentifications based on visual and photometric inspection, and therefore it should be considered a lower limit to the true contamination rate, as additional false positives may remain among the unconfirmed candidates. We emphasize that all candidate detections were visually inspected using composite color images from Pan-STARRS (Tonry et al. 2012) and DECAPS DR1 (Schlafly et al. 2018).
Effect of (J − Ks) color cuts on star recovery in known clusters.
4.3 Parameter sensitivity
We also assessed the robustness of the CANDiSC detections by performing an internal validation by varying the core parameters of the algorithm: the KDE bandwidth, h; the DBSCAN radius, ε; the number of neighbors, k, for NNDE; and the detection threshold, σ. These parameters were adjusted independently within plausible ranges informed by visual inspection and empirical tuning (see Sect. 3.7). We find that the number of detected over-densities remains relatively stable within the h = 0.08°–0.12°, ε = 0.08°–0.15° and k = 3–6 ranges. Beyond these ranges, the algorithm either begins to over-smooth the stellar-density field, merging distinct structures, or becomes overly sensitive to noise, particularly in sparse fields.
 |
Fig. 13 Distribution of recovered cluster members across all 163 detected overdensities. The blue shade shows the new detection from this work. |
4.4 Statistical summary of detections
In total, CANDiSC identified 163 candidate stellar overdensi-ties across the studied 680 VVVX tiles. The number of cluster members per detection spans a wide range, from one up to more than 1000. Figure 13 presents the distribution of member counts for all detected clusters. Most detections fall within the range of five to 100 members, with a peak near 12. A substantial number of candidates have between 12 and 40 members, while a smaller group exceeds 100 members. Detections with fewer than five members were reviewed individually, as discussed in Sect. 4.2. This assessment is based on the default color cut; varying the color-cut thresholds can affect the number of recovered members, as previously discussed.
5 Discussion
The CANDiSC algorithm introduces a consensus-based, unsupervised approach for the detection of stellar clusters, optimized for wide-field photometric surveys. Initially designed for the VVVX survey, CANDiSC operates on a minimal set of inputs, namely stellar coordinates and a photometric color-magnitude filter, and requires no prior assumptions about cluster morphology or location. Its architecture combines three independent, density-based clustering methods (KDE, DBSCAN, NNDE), flagging an overdensity only when detected by at least two methods. This strategy enhances robustness and reduces false positives while preserving sensitivity to a wide range of cluster morphologies.
Unlike earlier efforts that relied heavily on manual inspection of individual tiles to identify overdensities (e.g., Bica et al. 2018a; Garro et al. 2020, 2022a, 2024a; Minniti et al. 2017c, 2021e,d), CANDiSC enables a fully automated, homogeneous analysis of the entire VVVX footprint. When applied to all 680 VVVX tiles, CANDiSC successfully recovered all previously known clusters in the region and identified several new candidates, including objects likely missed due to their low surface density or high extinction. This highlights the algorithm’s potential to uncover hidden stellar systems that escape visual detection.
While these results are promising, several limitations must be acknowledged. First, the consensus requirement can lead to missed detections: if an overdensity is detected by only one of the three methods, it is discarded. This deliberate design choice prioritizes purity over completeness, aiming to limit contamination. As shown in Sect. 4.2, the lower limit for the contamination rate is estimated to be 1.8%, which is primarily due to isolated evolved stars or compact nebular structures being misidentified as clusters. Second, due to hardware constraints, a down-sampling step was implemented for tiles containing more than ∼1.2 million stars (see Sect. 3.2). This step may introduce incompleteness in particularly crowded or diffuse regions. However, stress tests across multiple down-sampling levels (10, 20, 50, 80, and 90%) confirmed that CANDiSC consistently recovered known clusters, even when visual overdensities were no longer apparent. We therefore consider this limitation to be well controlled in practice.
Despite these caveats, the performance of CANDiSC validates its utility as a scalable and objective tool for cluster detection in large photometric surveys. Its sensitivity to low-density structures and its ability to suppress false positives make it well suited for applications beyond VVVX, including forthcoming datasets from LSST (LSST collaboration; Abell et al. 2009) and Euclid (Blanchard et al. 2020). A follow-up study (Obasi et al., in prep.) is currently underway to characterize the new cluster candidates using Gaia DR3 (Gaia Collaboration 2021), 2MASS (Skrutskie et al. 2006), and the Dark Energy Camera Plane Survey (DECaPS; Schlafly et al. 2018; Saydjari et al. 2023). This will enable the derivation of physical and structural parameters such as extinction, distance, metallicity, and age. The study will provide further insight into the formation and dynamical evolution of these systems within the Galaxy.
6 Final remarks
We developed and applied a Consensus-based Algorithm for Nonparametric Detection of Star Clusters (CANDiSC) algorithm for the detection of stellar clusters, to the full VVVX survey footprint shown in Fig. 1. Our method combines three independent clustering techniques (KDE, DBSCAN, NNDE) and flags a stellar overdensity only when detected by at least two of these techniques independently.
Applying CANDiSC to 680 VVVX tiles, we identified 163 cluster candidates. Of these, 118 match known clusters in the SIMBAD database, while five correspond to entries in recently published catalogs not yet reflected in SIMBAD. We find 40 candidates that appear to be previously uncatalogued and may represent new stellar clusters. These include objects located in regions of high extinction or low surface density, or in areas where both conditions occur, which are often missed by traditional methods.
The success of CANDiSC in recovering all previously known clusters in the VVVX footprint, while also uncovering new systems, demonstrates its robustness and reliability. It provides a valuable tool for mining large photometric datasets in a reproducible and scalable manner. In a forthcoming paper, we will characterize these new candidates using complementary datasets including Gaia DR3, 2MASS, and DECaPS and VVVX to derive distances, extinctions, metallicities, and ages.
Data availability
The tables associated with this article, including the compilation of 788 known VVV and VVVX clusters, the full catalogue of 163 CANDiSC detections, and the list of 40 newly identified cluster candidates (organized at the CDS as Tables 1–3), are available at the CDS via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/705/A244.
Acknowledgements
This work was funded by the Postdoctoral Talent Attraction Competition for Research Centers and Institutes of the Universidad Andrés Bello (UNAB) 2025, project Nº. DI-07-25/ATP. J.G.F-T gratefully acknowledges the grants support provided by ANID Fondecyt Postdoc No. 3230001 (Sponsoring researcher), the Joint Committee ESO-Government of Chile under the agreement 2023 ORP 062/2023, and the support of the Doctoral Program in Artificial Intelligence, DISC-UCN. D.M. gratefully acknowledges support from the Center for Astrophysics and Associated Technologies CATA by the ANID BASAL projects ACE210002 and FB210003, by Fondecyt Project No. 1220724. M.G. gratefully acknowledges support from Fondecyt through grant 1240755. B.P.L.F. acknowledges financial support from Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq, Brazil; procs. 140642/2021-8 and 314718/2025-7) and Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES, Brazil; Finance Code 001; proc. 88887.935756/2024-00). This study was financed, in part, by the São Paulo Research Foundation (FAPESP), Brazil; Process Number 2025/05050-3. . J.A.-G. acknowledges support from DGI-UAntof and Mineduc-UA Cod. 2355. B.T. gratefully acknowledges support from the National Natural Science Foundation of China through grants NOs. 12473035 and 12233013, China Manned Space Project under grant NO. CMS-CSST-2025-A13 and CMS-CSST-2021-A08. R.K.S. acknowledges support from CNPq/Brazil through projects 308298/2022-5 and 421034/2023-8. We gratefully acknowledge the use of data from the ESO Public Survey program IDs 179.B-2002 and 198.B-2004 taken with the VISTA telescope and data products from the Cambridge Astronomical Survey Unit.
References
- Abell, P. A., Allison, J., Anderson, S. F., et al., 2009. Lsst science book, version 2.0 [Google Scholar]
- Alonso-García, J., Dékány, I., Catelan, M., et al. 2015, AJ, 149, 99 [CrossRef] [Google Scholar]
- Barbá, R., Roman-Lopes, A., Castellón, J. N., et al. 2015, A&A, 581, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barbá, R. H., Minniti, D., Geisler, D., et al. 2019, ApJS, 870, L24 [Google Scholar]
- Bica, E., Minniti, D., Bonatto, C., & Hempel, M. 2018a, PASA, 35, e025 [Google Scholar]
- Bica, E., Pavani, D. B., Bonatto, C. J., & Lima, E. F. 2018b, AJ, 157, 12 [Google Scholar]
- Bidin, C. M., Mauro, F., Geisler, D., et al. 2011, A&A, 535, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanchard, A., Camera, S., Carbone, C., et al. 2020, A&A, 642, A191 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borissova, J., Bonatto, C., Kurtev, R., et al. 2011, A&A, 532, A131 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borissova, J., Chené, A.-N., Alegría, S. R., et al. 2014, A&A, 569, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borissova, J., Ivanov, V., Lucas, P., et al. 2018, MNRAS, 481, 3902 [NASA ADS] [CrossRef] [Google Scholar]
- Borissova, J., Kurtev, R., Amarinho, N., et al. 2020, MNRAS, 499, 3522 [NASA ADS] [CrossRef] [Google Scholar]
- Camargo, D., & Minniti, D. 2019, MNRAS, 484, L90 [Google Scholar]
- Cantat-Gaudin, T., Jordi, C., Vallenari, A., et al. 2018, A&A, 618, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, AJ, 345, 245 [NASA ADS] [Google Scholar]
- Casertano, S., & Hut, P. 1985, ApJ, 298, 80 [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2018, A&A, 618, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2020, A&A, 635, A45 Di Criscienzo, M., Caputo, F., Marconi, M., & Musella, I. 2006, MNRAS, 365, 1357 [Google Scholar]
- Dias, B., Palma, T., Minniti, D., et al. 2022, A&A, 657, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dobashi, K., Uehara, H., Kandori, R., et al. 2005, PASJ, 57, S1 [Google Scholar]
- Emerson, J., & Sutherland, W. 2010, The Messenger, 139, 2 [NASA ADS] [Google Scholar]
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. 1996, in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, 226 [Google Scholar]
- Eyer, L., Audard, M., Holl, B., et al. 2023, A&A, 674, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ferdosi, B., Buddelmeijer, H., Trager, S., Wilkinson, M., & Roerdink, J. 2011, A&A, 531, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2016, A&A, 595, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Gómez, M., et al. 2020, A&A, 642, L19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Gómez, M., et al. 2021, A&A, 649, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Alessi, B., et al. 2022a, A&A, 659, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Gómez, M., et al. 2022b, A&A, 658, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Gómez, M., et al. 2022c, A&A, 662, A95 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., Alonso-García, J., et al. 2024a, A&A, 688, L3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garro, E., Minniti, D., & Fernández-Trincado, J. 2024b, A&A, 687, A214 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gupta, A., Ivanov, V. D., Preibisch, T., & Minniti, D. 2024, A&A, 692, A194 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hao, C., Xu, Y., Wu, Z., et al. 2022, A&A, 660, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- He, Z., Liu, X., Luo, Y., Wang, K., & Jiang, Q. 2022a, ApJS, 264, 8 [Google Scholar]
- He, Z., Wang, K., Luo, Y., et al. 2022b, ApJS, 262, 7 [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivanov, V. D., Piatti, A. E., Beamín, J.-C., et al. 2017, A&A, 600, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N., Piskunov, A., Schilbach, E., Röser, S., & Scholz, R.-D. 2013, A&A, 558, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kronberger, M., Teutsch, P., Alessi, B., et al. 2006, A&A, 447, 921 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krone-Martins, A., & Moitinho, A. 2014, A&A, 561, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kung, Y.-H., Lin, P.-S., & Kao, C.-H. 2012, Stat. Probab. Lett., 82, 1786 [Google Scholar]
- Loftsgaarden, D. O., & Quesenberry, C. P. 1965, Ann. Math. Statist., 36, 1049 [Google Scholar]
- Minniti, D., Lucas, P., Emerson, J., et al. 2010, New. Astron., 15, 433 [CrossRef] [Google Scholar]
- Minniti, D., Hempel, M., Toledo, I., et al. 2011, A&A, 527, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minniti, D., Alonso-García, J., Braga, V., et al. 2017a, Research Notes of the American Astronomical Society, 1, 16 [Google Scholar]
- Minniti, D., Alonso-García, J., & Pullen, J. 2017b, Research Notes of the American Astronomical Society, 1, 54 [Google Scholar]
- Minniti, D., Geisler, D., Alonso-García, J., et al. 2017c, ApJ, 849, L24 [Google Scholar]
- Minniti, D., Alonso-García, J., Borissova, J., et al. 2019, rnaas, 3, 101 [Google Scholar]
- Minniti, D., Fernández-Trincado, J., Smith, L., et al. 2021a, A&A, 648, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minniti, D., Fernández-Trincado, J. G., Gómez, M., et al. 2021b, A&A, 650, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minniti, D., Gómez, M., Alonso-García, J., Saito, R., & Garro, E. 2021c, A&A, 650, L12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minniti, D., Palma, T., & Clariá, J. 2021d, Boletín de la Asociación Argentina de Astronomía, 62 [Google Scholar]
- Minniti, D., Ripepi, V., Fernández-Trincado, J., et al. 2021e, A&A, 647, L4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nambiar, S., Das, S., Vig, S., & Gorthi, R. S. S. 2019, MNRAS, 482, 3789 [NASA ADS] [CrossRef] [Google Scholar]
- Obasi, C., Gomez, M., Minniti, D., & Alonso-Garcia, J. 2021, A&A, 654, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Obasi, C., Garro, E., Fernández-Trincado, J., et al. 2025, A&A, 695, A235 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pallanca, C., Ferraro, F. R., Lanzoni, B., et al. 2021, ApJ, 917, 92 [NASA ADS] [CrossRef] [Google Scholar]
- Parzen, E. 1962, Ann. Math. Statist., 33, 1065 [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach Learn. Res., 12, 2825 [Google Scholar]
- Pera, M. S., Perren, G. I., Moitinho, A., Navone, H. D., & Vazquez, R. A. 2021, A&A, 650, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Plummer, H. C. 1911, MNRAS, 71, 460 [Google Scholar]
- Prisinzano, L., Damiani, F., Sciortino, S., et al. 2022, A&A, 664, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Qin, S., Zhong, J., Tang, T., & Chen, L. 2023, ApJS, 265, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Robitaille, T. P., Tollerud, E. J., Greenfield, P., et al. 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saito, R., Hempel, M., Alonso-García, J., et al. 2024, A&A, 689, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saroon, S., Dias, B., Minniti, D., et al. 2024, A&A, 689, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saydjari, A. K., Schlafly, E. F., Lang, D., et al. 2023, ApJS, 264, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., Green, G. M., Lang, D., et al. 2018, ApJS, 234, 39 [Google Scholar]
- Seleznev, A. F. 2016, MNRAS, 456, 3757 [Google Scholar]
- Skrutskie, M., Cutri, R., Stiening, R., et al. 2006, AJ, 131, 1163 [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, arXiv e-print [arXiv:1503.03757] [Google Scholar]
- Strantzalis, A., Lazarou, D., Hatzidimitriou, D., et al. 2024, A&A, 681, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tonry, J., Stubbs, C. W., Lykke, K. R., et al. 2012, ApJ, 750, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Vio, R., Fasano, G., Lazzarin, M., & Lessi, O. 1994, A&A, 289, 640 [NASA ADS] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Wright, E. L., Eisenhardt, P. R., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Zacharias, N., Finch, C., Girard, T., et al. 2013, AJ, 145, 44 [NASA ADS] [CrossRef] [Google Scholar]
CANDiSC is not yet publicly available. A future version incorporating additional multi-survey parameters will be released upon completion of ongoing development.
All tables are provided in electronic form and are available at the CDS.
The complete list of 788 VVV and VVVX clusters will be made available at CDS.
Appendix A Detected clusters
We show in Table A.1 the 40 rows of new cluster candidates detected by CANDiSC that are not currently listed in the SIM-BAD database. Column 1 contains the VVVX cluster IDs, Column 2 the corresponding VVVX tile names, and Columns 3 and 4 the equatorial coordinates (RA, Dec). Columns 5–8 present the number of sources recovered for different color cuts, as detailed in the Table 3 footnote. Table A.2 presents the first 10 rows of previously known clusters recovered by CANDiSC, including their literature names, tile names, and coordinates (RA, Dec). The complete catalog of recovered clusters is also provided as a machine-readable table.
Appendix B Validation
This appendix provides the full set of validation diagnostics derived from the synthetic cluster injections described in Sect. 3.7. These results expand upon the global completeness trends discussed in the main text by presenting the figure-by-figure behavior of the pipeline across the three-dimensional parameter space spanned by the simulations. The figures include recovery fraction distributions, the dependence of completeness on extinction, richness, and size, astrometric offsets, and the purity-completeness relation. Together, they provide a detailed view of the strengths and limitations of both the default and tuned configurations of CANDiSC.
Figure B.1 shows the histogram of recovery fractions for the synthetic VVVX-like injections (315 realizations with cluster richness N = {80, 100, 200, 300, 400, 500, 600}, half-light radius rh = {0.005°, 0.01°, 0.03°}, and extinction AV = {0.5, 1.5, 3.0} mag). The left panel (default configuration) reveals a right-skewed distribution with a dominant peak near 1.0 (perfect recovery) and a tail between 0.1 and 0.8. Approximately 32% of clusters are perfectly recovered, primarily low-extinction, high-richness cases. In contrast, the tuned configuration exhibits denser mid-range bins (0.4–0.8), indicating fewer partial recoveries and improved handling of marginal overdensities.
Recovery efficiency declines as extinction increases. For the default configuration, completeness decreases from 0.45 at AV = 0.5 mag to 0.20 at AV = 3.0 mag (Fig. B.2, left panel). In the tuned configuration (Fig. B.2, right panel), the decline is slightly shallower, from 0.40 to 0.25 over the same interval, reflecting improved sensitivity to reddened clusters.
Figure B.3 shows recovery as a function of cluster size. In the default configuration (upper left), completeness increases from approximately 0.10 at R = 80 to 0.40 at R = 600, with a decrease from ∼0.55 at rh = 0.005° to ∼0.10 at rh = 0.03°, indicating strong performance for compact clusters but difficulty with diffuse ones. The tuned configuration (lower right) shows gains across the parameter space, rising from ∼0.20 at R = 80 to ∼0.45 at R = 600, while maintaining the expected decline with increasing rh.
Astrometric accuracy remains excellent in both configurations (Fig. B.4). The default setup peaks at offsets below 0.025 arcsec with a tail to 0.175 arcsec, while the tuned configuration yields a slightly tighter distribution with a shorter tail (∼0.15 arcsec). The purity-completeness relation (Fig. B.5) displays the typical tradeoff: high purity at low completeness and declining purity at higher completeness. The tuned configuration shifts the curve marginally toward higher completeness at fixed purity.
Across the 315 realizations, the default configuration recovers 245 clusters (77.78%), while the tuned setup recovers 226 (71.75%). Although the tuned configuration detects fewer clusters overall, it performs better on low-richness (N ≲ 200) and extended (rh ≳ 0.01°) systems, reflecting a shift from maximizing detections to improving sensitivity to faint structures.
For the main catalog, we adopt the default CANDiSC settings, which maximise the number of reliably recovered clusters and perform robustly for compact and moderately extincted systems. Despite slightly lower sensitivity to faint or diffuse clusters, the default configuration maintains strong astrometric precision, a low contamination rate (mean spurious fraction of 5.9%), and a completeness of ~30–35% in typical VVVX conditions (AV ∼ 1–2 mag, rh ∼ 0.01°). Incorporating multi-band priors and astrometric information (proper motion, parallax, and radial velocity), as well as applying de-noising techniques, is expected to improve both the detection and the accurate recovery of reddened and diffuse clusters in future work. The recovery behaviour as a function of cluster size and extinction is well-characterised, providing a robust foundation for further tuning and follow-up studies targeting fainter or more extended cluster populations.
 |
Fig. B.1 Histograms of recovery fractions for all injected synthetic clusters for the default (left) and tuned configurations (right). The distribution is right-skewed, indicating that the detection pipeline recovers most clusters well, while a small subset shows partial or failed recovery. |
 |
Fig. B.2 Mean recovery fraction as a function of extinction (AV) for both the default and tuned configurations. The recovery efficiency decreases systematically with increasing AV, reflecting the reduced detectability of clusters toward the bulge and disk, where spatial extinction is problematic and can blend the clusters’ overdensity. |
 |
Fig. B.3 Top left: Mean recovery fraction as a function of the input cluster radius parameter (R) for the default configuration. Top right: Dependence of the mean recovery fraction on the half-light radius (rh). Bottom: Same plots but for the tuned configuration. |
 |
Fig. B.4 Histograms of the mean positional offset between injected and recovered cluster centers for the default (left) and tuned (right) configurations. The distribution peaks near zero, indicating accurate centroid recovery, with a small tail toward larger offsets corresponding to marginal or blended detections. |
 |
Fig. B.5 Scatter plot showing the tradeoff between completeness (recovery fraction) and purity (1 - spurious fraction) for all injected clusters, comparing the default (left) and tuned (right) configurations. The relationship illustrates the balance between maximizing true detections and minimizing false positives. |
New cluster candidates detected by the CANDiSC algorithm in the VVVX survey.
Previously known stellar clusters recovered by the CANDiSC algorithm in the VVVX survey (extract).
All Tables
Previously known stellar clusters recovered by the CANDiSC algorithm in the VVVX survey (extract).
All Figures
|
Fig. 1 Survey area used in this study. The gray shaded region indicates the 680 VVVX tiles included in the analysis, while the black shaded region shows tiles that were excluded. |
| In the text | |
|
Fig. 2 Color-magnitude and spatial distributions of stars in tiles b0411 (M54), upper panel, and e0621 (Pismis 2), bottom panel. Left panels: 2D histograms showing all sources in (J − Ks) versus Ks diagram. Middle panels: sources passing color-magnitude selection (0.4 < J − Ks < 1.4, Ks < 17.5) are overlaid in red, with the selection boundaries marked by dashed blue lines. Right panels: spatial distributions in RA versus Dec, where all stars are shown in gray, and color-selected sources are shown in red. Blue crosses mark the cluster centers, and dashed blue circles indicate a 0.3◦ radius. |
| In the text | |
|
Fig. 3 Flowchart of CANDiSC, the Consensus-based Algorithm for Nonparametric Detection of Star Clusters. |
| In the text | |
|
Fig. 4 Density distribution maps for VVVX tiles containing clusters used to validate CANDiSC code. Left panel: stellar-density maps for fields of M54 (b0411), NGC 6652 (b0436), NGC 6293 (b0490), and NGC6325 (b0492). The upper and lower subpanels correspond to different tiles. Right panel: same maps as in left panel, now overplotted with candidate cluster members identified by CANDiSC. The legend indicates the number of recovered members for each cluster. |
| In the text | |
|
Fig. 5 Same as Fig. 4 but for CWNU 4193 (e0618), Pismis 2 (e0621), Haffner 15 (e0613), and M 19 (e0503). The maps show the stellar-density distributions in each VVVX tile, with the identified cluster members overplotted. The legend reports the number of recovered members for each cluster. |
| In the text | |
|
Fig. 6 Density distribution map of synthetic injection field in RA, Dec. The background color-scale represents the squared and logarithmically normalized spatial density of all injected stars. Blue points denote the positions of the recovered members of the injected cluster containing 600 stars. |
| In the text | |
|
Fig. 7 Observed (left) and synthetic (right) catalogs of the VVVX-like color-magnitude (top panels) and color-color diagram (bottom panels). The synthetic catalog reproduces the observed near-infrared stellar locus and photometric distributions using KDE resampling and a locus prior. |
| In the text | |
|
Fig. 8 Two-dimensional completeness surface (heat map) showing mean recovery rate as function of cluster radius (R) and extinction (AV; left-right panel default and tuned configuration). For the default configuration, completeness decreases toward smaller radii and higher extinctions, and it becomes extreme at R=80, where it drops to 0. In contrast, for tuned settings, completeness gradually increases toward larger radii and lower extinction. The plot also shows the parameter space where the pipeline remains reliable. |
| In the text | |
|
Fig. 9 Composite images of subset of newly detected cluster candidates. Upper row: clusters from tiles e0602 and e1022. Lower row: clusters from tiles e0965 and e1047. Panels a and c are based on Pan-STARRS images, and panels b and d use DECam Plane Survey (DECaPS) DR1 color composites constructed from the g, r, and z bands. |
| In the text | |
|
Fig. 10 Diagnostic plots for a candidate stellar cluster identified in the VVVX survey using Gaia data. Left: proper motion diagram (µα cos δ vs. µδ, in mas yr−1), where gray points represent all stars within 0.4 degrees and 0.5 mas of the cluster center. A red dot where the inset line is projected indicate HDBSCAN-selected members. The inset highlights stars within 2σ of the proper motion centroid in black dot. Middle: Gaia color–magnitude diagram (BP–RP vs. G), showing HDBSCAN-selected cluster members (red) tracing a distinct main sequence, albeit contaminated among field stars (gray). Right: spatial distribution in ∆RAcos (Dec) and ∆Dec (degrees). HDBSCAN selected Cluster members (red) are concentrated within 0.3 degrees of the center, while field stars (gray) appear scattered. We indicate the cluster overdensity, centered on the black circle with a radius of 0.15°, which is clearly distinct from the surrounding field. Each panel corresponds to one of the clusters shown in Fig. 9: the first panel shows the cluster centered on tile 0602 (panel a), the second panel on tile e1022 panel b, and the third and fourth panels on tiles e0965 (panel c) and e1047 (panel d), respectively. |
| In the text | |
|
Fig. 11 Cross-match analysis of 60 candidate stellar overdensities with recent cluster catalogs. |
| In the text | |
|
Fig. 12 Top left: spatial distribution of newly detected VVVX clusters (red) overplotted with previously detected VVV and VVVX clusters (blue). Top right: same plot, but showing only our new detections and known clusters from Bica et al. (2018b, gray). Bottom: our new detections (red) overplotted with previously known VVV and VVVX clusters in equatorial coordinates (RA, Dec). |
| In the text | |
|
Fig. 13 Distribution of recovered cluster members across all 163 detected overdensities. The blue shade shows the new detection from this work. |
| In the text | |
|
Fig. B.1 Histograms of recovery fractions for all injected synthetic clusters for the default (left) and tuned configurations (right). The distribution is right-skewed, indicating that the detection pipeline recovers most clusters well, while a small subset shows partial or failed recovery. |
| In the text | |
|
Fig. B.2 Mean recovery fraction as a function of extinction (AV) for both the default and tuned configurations. The recovery efficiency decreases systematically with increasing AV, reflecting the reduced detectability of clusters toward the bulge and disk, where spatial extinction is problematic and can blend the clusters’ overdensity. |
| In the text | |
|
Fig. B.3 Top left: Mean recovery fraction as a function of the input cluster radius parameter (R) for the default configuration. Top right: Dependence of the mean recovery fraction on the half-light radius (rh). Bottom: Same plots but for the tuned configuration. |
| In the text | |
|
Fig. B.4 Histograms of the mean positional offset between injected and recovered cluster centers for the default (left) and tuned (right) configurations. The distribution peaks near zero, indicating accurate centroid recovery, with a small tail toward larger offsets corresponding to marginal or blended detections. |
| In the text | |
|
Fig. B.5 Scatter plot showing the tradeoff between completeness (recovery fraction) and purity (1 - spurious fraction) for all injected clusters, comparing the default (left) and tuned (right) configurations. The relationship illustrates the balance between maximizing true detections and minimizing false positives. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.