| Issue |
A&A
Volume 701, September 2025
|
|
|---|---|---|
| Article Number | A201 | |
| Number of page(s) | 23 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202554340 | |
| Published online | 16 September 2025 | |
AMICO galaxy clusters in KiDS-1000: Cosmological sample
1
Zentrum für Astronomie, Universitatät Heidelberg, Philosophenweg 12, D-69120 Heidelberg, Germany
2
Institute for Theoretical Physics, Philosophenweg 16, D-69120 Heidelberg, Germany
3
INAF – Osservatorio Astronomico di Padova, Via dell’Osservatorio 5, I-35122 Padova, Italy
4
Dipartimento di Fisica e Astronomia “Augusto Righi” – Alma Mater Studiorum Università di Bologna, Via Piero Gobetti 93/2, I-40129 Bologna, Italy
5
INAF – Osservatorio di Astrofisica e Scienza dello Spazio di Bologna, Via Gobetti 93/3, I-40129 Bologna, Italy
6
INFN – Sezione di Bologna, Viale Berti Pichat 6/2, I-40127 Bologna, Italy
7
INAF – Osservatorio Astronomico di Capodimonte, Salita Moiariello 16, Napoli 80131, Italy
8
INAF, Istituto di Radioastronomia, Via Piero Gobetti 101, 40129 Bologna, Italy
9
Institute for Astronomy, University of Edinburgh, Blackford Hill, Edinburgh EH9 3HJ, UK
10
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing, 44780 Bochum, Germany
11
Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas (CIEMAT), Av. Complutense 40, E-28040 Madrid, Spain
12
Institute of Cosmology & Gravitation, Dennis Sciama Building, University of Portsmouth, Portsmouth PO1 3FX, United Kingdom
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
1
March
2025
Accepted:
24
July
2025
Abstract
Context. Galaxy clusters provide key insights into cosmic structure formation and galaxy formation, and they are essential for cosmological studies.
Aims. We present a catalog of galaxy clusters detected in the Kilo-Degree Survey (KiDS-DR4) optimized for cosmological analyses and investigations of cluster properties. Each detection includes probabilistic membership assignments for the KiDS-DR4 galaxies within the magnitude range 15 < r′< 24.
Methods. Using the Adaptive Matched Identifier of Clustered Objects (AMICO) algorithm, we identified 23 965 clusters over an effective area of about 839 deg2 in the redshift range 0.1 ≤ z ≤ 0.9, with a signal-to-noise ratio of S/N > 3.5. The sample is highly homogeneous across the entire survey thanks to the restrictive galaxy selection criteria we adopted. Spectroscopic data from the GAMA survey were used to calibrate the photometric redshift of the clusters and assess their uncertainties. We introduced algorithmic enhancements to AMICO to mitigate border effects among neighbor tiles. Quality flags are also provided for each cluster detection. The sample purity and completeness assessments were estimated using the SINFONIA data driven approach, thus avoiding strong assumptions embedded in numerical simulations. We introduced a blinding scheme of the selection function that is intended to support the cosmological analyses.
Results. Our cluster sample includes 321 cross-matches with the X-ray eRASS1 “primary” sample and 235 matches with the ACT-DR5 cluster sample. We derived a mass-proxy scaling relation based on intrinsic richness, λ*, using masses from the eRASS1 catalog.
Conclusions. The KiDS-DR4 cluster catalog provides a valuable dataset for investigating galaxy cluster properties and contributes to cosmological studies by offering a large, well-characterized cluster sample.
Key words: galaxies: clusters: general / galaxies: evolution / cosmology: observations / large-scale structure of Universe
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Galaxy clusters serve as powerful laboratories for acquiring new insights into the physics of galaxy formation, feedback mechanisms, the distribution of dark matter, and properties of dark energy as well as cosmology in general. Such possibilities are derived from the fact that galaxy clusters represent the culminating phase of cosmic structure formation in the highly nonlinear regime. Over the past decade, a large effort has been dedicated to assembling galaxy cluster catalogs optimized for cosmological analyses. In this effort, the redMaPPer algorithm has been successfully applied to Sloan Digital Sky Survey (SDSS) and Dark Energy Survey (DES) datasets, providing extensive optically selected cluster samples that have been used to derive cosmological constraints from abundance and clustering statistics (Rykoff et al. 2014, 2016; Costanzi et al. 2013, 2021). In parallel, Sunyaev-Zel’dovich (SZ) and X-ray surveys, such as Planck, Atacama Cosmology Telescope (ACT), South Pole Telescope (SPT), and more recently eROSITA’s eRASS1, have yielded independent constraints on cosmological parameters as well (Bleem et al. 2015; Planck Collaboration XXVII 2016; Bocquet et al. 2019; Abbott et al. 2020; Garrel et al. 2022; Bulbul et al. 2024; Ghirardini et al. 2024; Seppi et al. 2024; Artis et al. 2025). These multi-wavelength efforts highlight the efficiency of galaxy clusters as cosmological probes.
In this context, the KiDS-DR4 cluster sample presented in this work contributes a valuable and independent dataset, leveraging deep high-quality optical and near-infrared data with well-calibrated photometric redshifts across a wide area. For the cluster detections, we used algorithms to detect galaxy clusters in optical surveys. The Adaptive Matched Identifier of Clustered Objects (AMICO) algorithm (Maturi et al. 2005; Bellagamba et al. 2018; Maturi et al. 2019) has proven to be particularly effective. It has enabled the creation of comprehensive galaxy cluster samples based on KiDS-DR3, miniJPAS, and COSMOS datasets (Maturi et al. 2019, 2023; Toni et al. 2024), and it has been selected to be implemented in the scientific pipeline of the ESA mission Euclid after a dedicated challenge (Euclid Collaboration: Adam et al. 2019). The AMICO-KiDS-DR3 catalog, for instance, has been the basis for numerous studies, including investigations of the properties of brightest cluster galaxies (BCGs; Radovich et al. 2020; Castignani et al. 2022, 2023), the redshift evolution of the luminosity function of cluster galaxies (Puddu et al. 2021), weak lensing mass-richness scaling relations (Bellagamba et al. 2019; Sereno et al. 2020; Lesci et al. 2022a,b), luminosity scaling relations (Smit et al. 2022), splashback radius measurements (Giocoli et al. 2024), large-scale stacked weak lensing profiles (Giocoli et al. 2021), halo bias (Ingoglia et al. 2022), and the clustering of galaxy clusters (Lesci et al. 2022b; Romanello et al. 2024).
In this paper, we present and characterize the galaxy cluster sample and probabilistic cluster memberships produced with AMICO from the fourth data release of the Kilo-Degree Survey (KiDS-DR4; Kuijken et al. 2019). Compared to KiDS-DR3, the KiDS-DR4 dataset offers high-quality optical imaging across a wider area (1000 versus 400 deg2) and is complemented by near-infrared coverage from the VIKING survey (Edge et al. 2013). For brevity, we refer to the combined datasets collectively as KiDS-DR4. The survey’s homogeneity, depth (r < 25), high-quality lensing measurements (with mean seeing in the r-band of 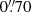 acquired exclusively during dark time), and broad spectral coverage (ugriZYJHKs) ensure optimal photometric redshifts, making it ideal for studies in cosmology, galaxy evolution, and galaxy cluster science.
acquired exclusively during dark time), and broad spectral coverage (ugriZYJHKs) ensure optimal photometric redshifts, making it ideal for studies in cosmology, galaxy evolution, and galaxy cluster science.
For the present analysis, we introduced several enhancements to the AMICO algorithm and extended our methodology to evaluate the sample purity and completeness using the selection function extractor (SINFONIA) as described in Maturi et al. (2019). Since one of our main scientific drivers is to use the cluster sample to constrain cosmological parameters, we also implemented and applied a blinding strategy to the selection function of the sample. The unblinding was performed after the completion of the cosmological analysis based on cluster counts presented in Lesci et al. (2025).
The GAMA spectroscopic survey, augmented with higher-redshift spectroscopic data from van den Busch et al. (2022), was used to calibrate the cluster photometric redshifts and to assign spectroscopic redshifts whenever available. Additionally, we explored the cross-matching of our cluster sample with the DES catalog created with RedMaPPer (Rykoff et al. 2014), the X-ray eRASS1 (Bulbul et al. 2024), and SZ ACT-DR5 (Hilton et al. 2021) cluster catalogs. This provided mass-proxy scaling relations and allowed us to investigate the most significant mismatches; specifically, we focused on X-ray detections lacking an optical counterpart and vice versa.
The paper is organized as follows. In Sect. 2 we describe the KiDS-DR4 dataset. In Sect. 3 we detail the improvements made to the AMICO algorithm and present the galaxy cluster sample. In Sect. 4, we discuss the mock galaxy catalogs generated with SINFONIA, which are used to estimate the sample purity and completeness and to evaluate the uncertainties of the associated observables. The cross-matching of our cluster sample with X-ray and SZ data is presented in Sect. 5. Finally, in Sect. 6 we draw our conclusions. In Appendix B we present the blinding strategy adopted for the cosmological analyses. In this work, we assume a flat Λ cold dark matter (ΛCDM) cosmological model with parameters Ωm = 0.3, ΩΛ = 0.7, and h = 0.7. Unless otherwise stated, all uncertainties are quoted at the 1σ level, and all magnitudes are given in the AB system.
2. The KiDS-DR4 dataset
A detailed description of the KiDS-ESO-DR4 release (DR4 hereafter) was given in Kuijken et al. (2019). In summary, it consists of a northern patch (KiDS-N) and a southern patch (KiDS-S), covering a 1000 deg2 area in total. ugri photometry was obtained with the OmegaCAM camera attached on the ESO VLT Survey Telescope (VST), on tiles covering approximately 1 deg2 each (Kuijken 2011). In DR4, mean limiting magnitudes (5σ in a 2″ aperture) in the ugri bands are 24.23 ± 0.12, 25.12 ± 0.14, 25.02 ± 0.13, 23.68 ± 0.27, respectively. In addition to the optical bands, DR4 also includes near-IR (ZYJHKs) photometry observed with the VIKING survey (Edge et al. 2013) on the ESO VISTA telescope. In DR4, a reprocessing of the VIKING images was done (Wright et al. 2019), to ensure that photometry is consistent across the nine bands. Photometric redshifts were computed using the Bayesian template fitting code BPZ (Benítez 2000), which derives best-fitting SEDs and the photometric redshift posterior probability distribution (PDF), based on a prior redshift probability distribution. In DR4, the prior described in Kuijken et al. (2019) was chosen, since it was found to best reduce uncertainties on photometric redshifts and catastrophic failures for faint, high-redshift galaxies: the reason for that was that the photometric catalog needed to be optimized for weak lensing analyses, which is the main science driver of the KiDS survey. However, it was known that this prior was not optimal for bright, low-redshift galaxies, which are instead fundamental for our cluster search. Therefore, for this work, we decided to use instead the prior adopted in KiDS-DR3 (de Jong et al. 2015) as already done for the AMICO-KiDS-DR3 cluster sample (Maturi et al. 2019).
We note that KiDS is a very homogeneous survey in terms of exposure time. Despite this, the r-band 5σ detection limit of galaxies shows some scatter, as displayed in the top panel of Fig. 1. In the figure, gray, blue, and red respectively represent the entire dataset, the KiDS-N stripes, and the KiDS-S stripes. Therefore, to ensure nearly perfect homogeneity and optimize the final cluster sample for cosmological analyses, we selected only galaxies with a total r-band magnitude brighter than the depth limit of the worst tile (i.e., r < 24), as in the previous analysis by Maturi et al. (2019). We also exclude the outlier tile KiDS_DR4.1_196.0_1.5 from the analysis, as it has an r-band 5σ galaxy depth of 23.1 only. After the application of this magnitude cut, the number density of galaxies in the KiDS-N and KiDS-S stripes peaks at the same value of the number density, as shown in the central panel of Fig. 1. In Fig. 2, we show the footprints of the KiDS-DR3 and KiDS-DR4 datasets, compared to the RedMaPPer-DES, eRASS1, and ACR-DR5 cluster samples, which are discussed in Sect. 5.
 |
Fig. 1. Key statistical properties for each individual tile of the KiDS-DR4 dataset. Gray, blue and red histograms refer to the entire dataset, to the KiDS-N and KiDS-S stripes, respectively. The distribution of the survey depth in the r-band, the galaxy number density per arcmin2, and the effective area of each tile are shown in top, central, and bottom panels, respectively. |
 |
Fig. 2. Footprint of KiDS-DR4 data (black area) overlapped by KiDS-DR3 data (gray area), showing the increase in area coverage. For comparison, the RedMaPPer-DES (green crosses), eRASS1 (blue circles) and ACR-DR5 (red points) cluster samples are also shown. |
To avoid regions affected by cosmetic artifacts, we dropped galaxies with a MASK flag in the KiDS-DR4 photometric catalog corresponding to manually masked regions (MASK = 3), halos around bright stars in the r-band (MASK = 12), or outside the area covered by all nine bands (MASK = 14). These restrictive criteria are intended to deliver a final sample of clusters that is as homogeneous and pure as possible across the entire survey. The effective area of the survey is 838.783 deg2. The bottom panel of Fig. 1 shows the distribution of the effective area in square degrees of each individual survey tile.
Additionally, we identified a few regions affected by reflections within the optical system, caused by bright stars outside the field of view or by other cosmetic defects not fully captured by the masks mentioned above. We identified these regions as significant spatial 2-dimensional overdensities of entries in the KiDS-DR4 galaxy catalog, ρ, with density values exceeding ten times the rms of the background density fluctuations, i.e. farti = ρ/σbkg > 10. To be sure that we are not rejecting true galaxy overdensities, we adopted relatively small pixels in the evaluation of the density maps, lpix = 0.3 arcmin, we considered overdensities produced by the entire line-of-sight (thus discarding redshift clustering), and used a large threshold to exclude these areas.
In Fig. 3, we show the distribution of the number of survey tiles as a function of the area affected by these artifacts. As visible in the figure, there is a flat tail extending beyond 5 arcmin2 containing 19 tiles that we list in Table 1. As examples, the left panels of Fig. 4 show the aforementioned fluctuations, farti, of the best and worst tiles listed in Table 1 (top and bottom panels, respectively), while in the right panels we show the corresponding masked pixels exceeding the farti > 10 threshold. We note that the intensity and values of the color maps are in logarithmic scale.
 |
Fig. 3. Distribution of the area of each tile affected by unmasked image artifacts mainly caused by spurious reflections and ghosts from bright stars located outside the field of view. |
 |
Fig. 4. Fluctuations of the spatial number density of galaxy catalog entries relative to its background rms, farti, for the KiDS_DR4.0_185.0_-0.5 (top left) and KiDS_DR4.0_218.6_2.5 (bottom left) tiles, which are the best and worst tiles listed in Table 1, respectively. The values are shown using a logarithmic scale, shown below the panels. Pixels with farti > 10 are used to create additional masks to identify image artifacts, as displayed in the corresponding right panels. The displayed areas are 1.4 deg on each side. The white square box enclosing most of the area marks the boundary of the survey tile, while the other white contours indicate examples of the handmade polygons enclosing the largest artifacts.
Table 1. List of tiles where the cosmetic artifacts cover an area larger than 5 arcmin2. Tile ID identifies the tile name, whereas Aarti is the area covered by artifacts in square arcminutes. |
Since the area of the most affected tiles is small (at most 1% of the total area), we do not exclude these tiles from our analysis. Instead, we discard the galaxies that fall within these regions when applying AMICO to identify clusters. Additionally, we assign to each cluster detection a flag, ARTIFACTS_FLAG, to facilitate a potential subsequent rejection. This flag takes the value 0 if the detection occurs in a tile with no artifacts or with a total affected area smaller than 5 arcmin2, the value 1 for detections in tiles with a total affected area larger than 5 arcmin2, and the value 2 for those located in the manually created masks enclosing the largest contiguous compromised regions.
The latest and final KiDS data release (DR5) has recently been published (Wright et al. 2024). This release offers expanded coverage, twice the depth in the i-band, and improved photometric redshifts. Cluster detection with AMICO and the corresponding cosmological analysis was also carried out using this new dataset.
3. The AMICO galaxy cluster sample
3.1. Basics of the detection algorithm
We detect galaxy clusters using the AMICO algorithm (Maturi et al. 2005; Bellagamba et al. 2018; Maturi et al. 2019). We refer to these papers for a more complete description of the mathematical derivation, and of the cluster model implemented in this code. Here, we summarize the core concepts and discuss in detail the specific setup, the differences, and new features implemented for this specific study.
The AMICO algorithm employs an unbiased linear optimal matched filter specifically designed to maximize the signal-to-noise ratio of cluster detections. This optimization assumes that the data, D, can be modeled as D(x, z, m) = Aτ(x, z, m)+N(z, m), where τ is a cluster template characterizing the observational properties of clusters, N represents the noise from field galaxies, and A is an amplitude factor that scales with the cluster’s richness. The amplitude A is derived using a linear estimator obtained through the constrained optimization procedure detailed in Maturi et al. (2019). To characterize the luminosity distribution of cluster members, as in the previous KiDS-DR3 data analysis, the cluster model used as a template, τ, assumes a Schechter luminosity function, Φ(m) (Schechter 1976), with a faint-end slope α = −1.06 from Zenteno et al. (2016) and m* in the r-band from Hennig et al. (2017).
Additionally, it describes the projected density of cluster members assuming a Navarro-Frenk-White (NFW) radial profile (Navarro et al. 1997) scaled to match the radius R200 = 1 Mpc1. The weight of each galaxy at a given redshift is given by its own photo-z probabilistic redshift distribution, P(z), as provided by BPZ. Beyond the list of cluster detections, the algorithm calculates the probability of each galaxy being a member of a detected cluster. This probability is then used to estimate the apparent richness λ, i.e. the number of observable members in a cluster, and the intrinsic richness λ*, defined as the number of cluster members with an r-band magnitude brighter than m* + 1.5 within a radial distance R200. Here, the radius R200 and the characteristic magnitude in the Schechter luminosity function, m*, are inherited from the model used to construct the optimal filter. Two different signal-to-noise ratios for the amplitude A, are returned: one accounts for the noise induced by field galaxies only (SN_NO_CLUSTERS), while the other additionally includes the shot noise due to the cluster members (S/N).
3.2. Application to the KiDS-DR4 dataset
We considered galaxies within the magnitude range 15 < r′< 24. Unlike in the KiDS-DR3 analysis, where noise properties N were estimated on a tile-by-tile basis, in this work we derived them across the entire survey area to leverage the survey homogeneity and apply the same filter throughout the survey. This approach enhances the statistical robustness of the noise estimate and simplifies both the analysis and interpretation of the results. The sky was sampled in steps of 0.3 arcmin and redshift intervals of Δz = 0.01. The search was conducted over the redshift range 0.05 < z < 1.2, with the final cluster sample restricted to 0.1 < z < 0.9. The initial broader redshift range was adopted to mitigate border effects at high redshifts due to the possible truncations of the galaxy P(z). To maintain sensitivity near the edges of each survey tile, we included a buffer of 0.1 deg on each side. Consequently, AMICO was run on overlapping square areas of 1.2 deg per side.
A word of caution must be raised for detections at z > 0.8, as the value of m* + 1.5 used to define the λ* mass proxy approaches the sample’s magnitude limit of r = 24. As a result, λ* becomes strongly redshift-dependent and, given the small number of galaxies at those redshifts, increasingly unstable. Nevertheless, we chose to include these high-redshift detections, even though they are less robust, as they represent promising candidates that may be confirmed with deeper or complementary multi-wavelength data.
 |
Fig. 5. Duplicate detections occurring when merging overlapping survey tiles. Duplicates are identified by a maximum angular separation of ΔR < 1.2 arcmin and a redshift difference of Δz = 0.015(1 + z). The strong correlation between their intrinsic richness (λ*1 and λ*2) confirms that these detections originate from the same structure. The color scale represents their redshift separation. |
 |
Fig. 6. Average properties of detections as a function of their distance from the tile border, ΔR: amplitude, A (top-left panel); signal-to-noise ratio, S/N (top-right panel), apparent richness, λ (bottom left); and intrinsic richness, λ* (bottom right). The results for all detections are shown in black. Those within 5 arcmin of a tile border having a neighboring tile are shown in blue, and those with a missing neighboring tile are shown in red. Most values are insensitive to the tiling scheme, except for λ* near the survey’s external borders and in regions with missing tiles within the overall area. |
The catalogs of cluster detections obtained from each survey tile are then combined into a master catalog. To avoid duplicate entries due to tile overlaps, we apply a geometric cut dictated by the tiles geometry and identify pairs with differences in angular position and redshift smaller than ΔR < 1.2 arcmin (equivalent to 2 pixels of the AMICO amplitude maps) and Δz < 0.015(1 + z), respectively. We retain both detections if they are located within the same survey tile; otherwise, we keep only the detection closest to the center of its respective tile. The repeated objects are shown in Fig.5 as a function of their intrinsic richness λ*. The clear correlation between their intrinsic richness (which is not used for their identification) demonstrates that distinct nearby clusters are not mistaken as duplicates. Indeed, after the removal of the duplicates, the probabilistic membership of galaxies has been re-adjusted to ensure consistency with the purged catalog. The number of rejected duplicates is minimal, specifically 31 entries, because the buffer areas between tiles are small.
3.3. Testing and flagging detections in the proximity of areas with missing data
To verify the behavior of the detections at the interface between tiles, we show in Fig. 6 the average values of the signal-to-noise ratio, S/N; amplitude, A; the apparent richness, λ; and the intrinsic richness, λ*, as a function of their distance from the edge of the survey tile to which they belong. We distinguished between all detections (black lines) and those within ΔR < 5 arcmin, which we further divided into categories of those having a neighboring tile (blue lines), where border effects should be minimal due to the overlapping tile scheme we implemented, and those without a neighboring tile, where border effects are expected (red lines). The latter case occurs at the survey’s edge or where tiles within the survey area had not yet been observed in KiDS-DR4. It is clear from the figure that the overall average values of A, S/N, and λ are not affected by border effects. This is because the filter construction accounts for the presence of missing data when evaluating the amplitude and the signal-to-noise ratio. Moreover, the mask fraction used to correct the apparent richness is accurate. However, the intrinsic richness of detections within 3 arcmin of the tile edge is overestimated. The reason for this overestimation is that we applied for λ* the same correction factor used for λ, which does not account for the magnitude selection criteria imposed in the definition of λ*. This results in an overcorrection of its value. In fact, the brightest galaxies used in the evaluation of λ* are preferentially located closer to the cluster center, and their number is less affected by masks, which generally tend to “erode” the outer regions of clusters.
To enable in the catalog the selection of clusters based on their proximity to tile edges, we include two parameters: the minimum distance of each detection from the edge of its host survey tile, denoted as TILE_EDGE_DISTANCE, and a flag, TILE_EDGE_FLAG, which can assume the following three possible values:
-
0: assigned to detections located more than ΔR > 5 arcmin away from the tile edge.
-
1: assigned to detections within ΔR < 5 arcmin of the tile edge, in cases where an adjacent neighboring tile is present. These detections are minimally impacted by edge effects, as the data are not truncated unless the cluster’s radius exceeds 0.1 deg (the width of the buffer region used for tile overlap).
-
2: assigned to detections within ΔR < 5 arcmin of the tile edge, in cases where no adjacent neighboring tile exists. This scenario typically occurs at the survey’s boundaries or near unobserved regions. Although similar to TILE_EDGE_FLAG = 1, the absence of a neighboring tile increases the likelihood of edge effects or anomalies, particularly due to minor image artifacts at the tile boundaries.
We conducted a similar analysis, this time examining how detections are influenced by the masked fraction, defined as the proportion of cluster members located within masked regions. This evaluation is based on the density profile used in the filter model described in Sect. 3.1. Unlike the edge-proximity analysis, this study considers the entire survey area, not just regions near tile edges. As in the previous analysis of border effects, we categorize detections according to the three values of TILE_EDGE_FLAG. Fig. 7 presents the results for the same set of average quantities as in the previous figure, but analyzed as a function of the masked fraction of detections. The average values of A, S/N, λ, and λ* remain unbiased for masked fractions up to 30%. Beyond this threshold, deviations from the global average value become apparent, indicating the presence of a bias. Among these quantities, the intrinsic richness λ* is the most robust, showing a good consistency up to a masked fraction of 40%. In any case, the number of detections with masked fractions exceeding 0.3 is notably small, as illustrated in the central panel of Fig. 8.
 |
Fig. 7. Same as Fig. 6, but as a function of the masked fraction of each detection. All quantities remain stable up to a masked fraction of 0.3, with λ* remaining stable up to 0.4. |
 |
Fig. 8. Main properties of the cluster sample. Top panel: Average number of detections per survey tile as a function of the signal-to-noise ratio for the entire sample (gray histogram) and for the KiDS-N and KiDS-S stripes (blue and red lines, respectively). Central panel: Redshift distribution for five different S/N cutoffs. Bottom panel: Distribution of the masked fraction of detections in different redshift intervals. |
3.4. The cluster sample
The resulting catalog comprises 23 965 detections with S/N > 3.5. Fig. 8 provides an overview of the principal properties of the identified cluster sample. In the top panel, we display the average number of detections per tile as a function of the signal-to-noise ratio for the entire sample (gray histogram) and for the KiDS-N and KiDS-S stripes (blue and red lines, respectively). The distributions for both survey regions are very similar, despite the KiDS-S stripe being, on average, slightly deeper than the KiDS-N one. Again, this similarity shows the effectiveness of the conservative cut of r < 24 applied to the input galaxy sample, as discussed in Sect. 2. The central panel displays the redshift distribution. A discontinuity is visible at z ∼ 0.35, due to issues with photometric redshifts occurring at the transition between the g- and r-bands of the 4000 Å break. This feature, which was much more prominent in the KiDS-DR3 analysis, is here significantly alleviated thanks to the incorporation of the NIR data from the VIKING survey. The bottom panel illustrates the distribution and the cumulative of the masked fraction for detections with S/N > 3.5. Among these detections, 96%, 85%, 53%, and 19% have masked fractions below 30%, 20%, 10%, and 5%, respectively. Higher-redshift detections tend to have slightly lower masked fractions compared to those at lower redshifts, due to their smaller angular extent.
Due to their definitions, the amplitude A and intrinsic richness λ* serve as nearly redshift-independent mass proxies. For the amplitude, this redshift independence arises because the cluster template used in the AMICO filtering process is built to incorporate the survey’s magnitude limits. For the intrinsic richness, it is achieved thanks to the embedded magnitude cut, which is never below r < 24 at all redshifts. As expected, the minimum detectable cluster mass increases with redshift, leading to a corresponding rise in the lower values of both amplitude and intrinsic richness. Conversely, the lower limit of the apparent richness, λ, which represents the number of observable galaxies, remains relatively constant with redshift. This behavior is expected, as the survey’s sensitivity to galaxy cluster detection primarily depends on the number of member galaxies that can be observed, as quantified by the apparent richness λ.
Fig. 9 displays the number density of cluster detections as a function of the r-band magnitude depth for each tile, with each point representing an individual tile. The outlier tile that we excluded is visible in the bottom-left corner, marked with an “x”. For the remaining tiles, there is no apparent correlation between the survey depth and the number density of detections. Furthermore, the local survey depth and the number density of detections follow a Gaussian distribution with the same mean for both the KiDS-N and KiDS-S stripes (see the side panel). The only notable difference is that the scatter is slightly larger for the KiDS-N stripe. This confirms that the initial galaxy selection, with the magnitude cut at r < 24, effectively homogenized the properties of the survey to a very high degree.
 |
Fig. 9. Left panel: Number density of detections with S/N > 3.5 as a function of the survey tile depth in the r-band. Each point represents an individual tile. Side panel: Probability distribution of the number of detections per tile for the entire sample (gray histogram) and for the KiDS-N and KiDS-S stripes (blue and red lines, respectively). The corresponding values of the mean μ and RMS σ are reported in the legend. The absence of any significant correlation and the Gaussian shape of the number density distributions indicate the homogeneity of the survey clusters detection efficiency when a strict cutoff of r < 24 is applied in the selection of the input galaxy sample. A few outliers are visible, corresponding to tiles with problematic photometry (see their list in Table 1). We excluded from the analysis the tile marked with an “x” (see bottom-left corner). |
Finally, the analysis has been enhanced with new features recently introduced in AMICO. These features include the following:
-
An estimate of the probabilistic redshift distribution, Pdet(z), for each detection. This is calculated as the weighted sum of the P(z) distributions of individual galaxies, where the weights correspond to the probabilistic association of each galaxy with the given detection.
-
The 16th and 84th percentiles of Pdet(z). These represent the 1σ lower and upper bounds of the redshift uncertainties for each detection and are denoted as σz, min and σz, max.
-
An ODDS value for each detection defining the probability that the true redshift lies within ±0.1 of the best-fit photo-z. It is computed as ODDS = ∫z−z+Pdet(z)dz with integration limits z− and z+ corresponding to a redshift interval of width 0.2 (1 + zdet) centered on the mode of Pdet(z) (Benítez 2000).
The upper and lower bounds, the symmetrized redshift uncertainty, and the ODDS values for each detection are shown (with colors depending on their S/N) in the different panels of Fig. 10, from top to bottom. As expected, detections with higher signal-to-noise ratios exhibit smaller redshift uncertainties. More specifically, the average redshift uncertainties, σ/(1 + z), are 0.01, 0.009, 0.008 and 0.007 for S/N > 3.5, 4.0, 4.5 and 5.0, respectively. These uncertainties are smaller than those estimated using GAMA spectroscopic redshifts, as is discussed in Sect. 3.5. This difference may be attributed to the input P(z) of the galaxies photometric redshifts being slightly too optimistic, i.e. narrower than what they should be. In the distribution of ODDS values, a population of detections between redshift z = 0.5 and z = 0.8 with very low ODDS values appears. However, this population of detections is not of concern, as no other quantities characterizing them exhibit any peculiar or anomalous behavior. Additionally, visual inspection of the gri color composite images of these objects reveals no issues that would suggest problems with their reliability. Therefore, we decided not to flag them as the anomaly seems to be related to the ODDS estimate itself.
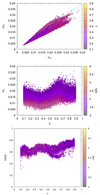 |
Fig. 10. Top panel: Upper and lower 67% percentile limits of the redshift probability distribution, Pdet(z), for each cluster detection. Central panel: Redshift uncertainty derived from the previous percentiles. Bottom panel: ODDS values, where it is possible to notice that a subpopulation of detections in the redshift range 0.5 < z < 0.75 exhibits significantly lower ODDS values compared to the other detections. Data are colored according to their redshift in the upper panel and according to S/N in the other two panels. |
3.5. Redshift calibration with GAMA spectroscopic redshifts
The Galaxy and Mass Assembly (GAMA) survey consists (Driver et al. 2011; Liske et al. 2015) of spectroscopic observations carried out with the Anglo-Australian Telescope’s AAOmega spectrograph across four equatorial and one southern field. In its Data Release 4 (Driver et al. 2022), GAMA incorporated KiDS-DR4 photometry within an overlapping area of approximately 210 deg2 (Bellstedt et al. 2020). From this dataset, we selected galaxies with reliable redshifts (NQ > 2; Driver et al. 2022) and further augmented the spectroscopic sample with higher-redshift estimates from van den Busch et al. (2022). We used this combined spectroscopic sample to evaluate the redshift uncertainties in our cluster sample and to investigate the presence of potential biases.
We considered GAMA spectroscopic redshifts for cluster members with an AMICO probabilistic membership exceeding 90%. This high probability threshold ensures that the selected members can be confidently associated with their respective detections. We do not impose a minimum requirement on the number of spectroscopic galaxies per cluster detection: a cluster is assigned a spectroscopic redshift even if it contains only one member with a spec-z. However, we provide information on the number of spectra used for each cluster detection along with additional parameters to access the reliability of the spectroscopic evaluation and facilitate further selections based on the specificity of the science goals. These additional quantities, all based on members with a probabilistic association greater than P > 90%, are included in the final catalog for each cluster detection. They are the following:
-
SPEC_NGAL: The number of members with an associated spectroscopic redshifts.
-
SPEC_SUMP: The sum of the AMICO membership probabilities for galaxies having a spectroscopic redshift.
-
SPEC_ZAVE: The weighted average of the spectroscopic redshifts, where the weights are given by the AMICO membership probabilities.
-
SPEC_ZMED: The median spectroscopic redshift of members with spectroscopic redshifts.
-
SPEC_RMS: The RMS scatter around the spectroscopic weighted average.
A total of 4883 detections have been assigned a spectroscopic redshift. In Fig. 11, we display the distribution of the number of cluster members with spectroscopic information. We found that 1343, 237 and 50 detections have more than 2, 5 and 10 members with P > 0.9 and a spectroscopic redshift, respectively.
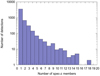 |
Fig. 11. Distribution of the number of detections as a function of the number of spectroscopic members with a probabilistic membership association greater than 90%. |
In the left panel of Fig. 12 we show the deviation between the cluster redshifts computed by AMICO using the galaxies’ photometric redshifts, and the corresponding spectroscopic redshift estimates. A clear bias is observed in the photo-z estimates for clusters at z < 0.4, which we modeled using a sigmoid function:
 |
Fig. 12. Scatter of the detections’ redshifts obtained with AMICO (based on galaxy photo-zs) with respect to the corresponding spectroscopic redshifts. Left and right panels show the values before and after redshift calibration, respectively. The left panel also displays the associated bias model (red solid line) and the final limits used for the k-sigma clipping (dashed red line). In the right panel, the dashed red lines show the final 1σ uncertainty. |
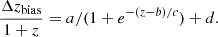 (1)
(1)
Here a, b, c, and d are free parameters that are determined using Orthogonal Distance Regression (ODR) combined with an iterative approach to handle outliers in an effective way. This functional form effectively captures the discontinuity caused by the transition of the 4000 Å break between the g- and r-bands at z ∼ 0.34 already discussed in Sect. 3.4. The fit is restricted to cluster detections with S/N > 3.5 within the redshift range 0.1 < z < 0.8, as spectroscopic data are sparse at higher redshifts. The aforementioned iterative procedure begins with an initial fit of the bias model to all data points, providing a preliminary estimate of the RMS for bias-corrected photometric redshifts. In each subsequent iteration, we apply the bias correction and clip all data points deviating by more than 3σ from their corresponding spectroscopic redshifts. The model parameters are then re-fitted, and the RMS is recomputed for the following iteration. Five iterations ensure convergence. The final model and the boundaries for the k-sigma clipping are reported in the left panel of Fig. 12 as solid and dashed red lines, respectively. The best-fit parameter values for the bias model are
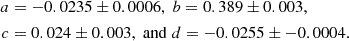 (2)
(2)
The right panel of the same figure shows the scatter of the photometric redshifts of the cluster detections after the bias correction, together with their RMS. The RMS for bias-corrected photometric redshifts, determined using this k-sigma clipping method, is σz/(1 + z) = 0.014 for the entire sample, while for detections with S/N > 4.0, S/N > 4.5 and S/N > 5.0, the corresponding RMS values are 0.013, 0.012 and 0.0118, respectively. These scatters are approximately 1.5 times larger than those estimated using the percentiles of the detection probability redshift distribution, Pdet(z), which is derived from the weighted P(z) of cluster members, as discussed above. This discrepancy may arise from an overestimation of errors based on the spectroscopic redshifts, potentially due to member misassociations. Alternatively, Pdet(z) might be narrower than the true distribution. Although the difference is not substantial, we consider safer to rely on the errors derived from the spectroscopic redshift estimates, as they are based on external data rather than an internal evaluation.
To test the stability of this approach, we also evaluated σz using two alternative robust estimators: (1) the Interquartile Range (IQR) clipping, which is similar to k-sigma clipping but based on data distribution quartiles, and (2) the Median Absolute Deviation (MAD), a method that relies on the median and the absolute deviations from the median, thus avoiding the dependency on arbitrary parameters, such as the k-value used in the other methods. Both these methods yielded σz = 0.014(1 + z), further validating the robustness of our approach. Additionally, repeating this analysis by considering members with a probabilistic association with clusters greater than P > 0.95 (instead of P > 0.9) produced consistent results, with a redshift uncertainty of σz = 0.0138(1 + z).
Table 2 lists all entries of the AMICO-KiDS-DR4 cluster catalog. For convenience, the column number of each entry is indicated between parentheses. Missing values are labeled as “−99”. A gallery of postage-stamp gri-color composite images of newly discovered clusters, which allows one to assess the data quality, is presented in Appendix A.
Descriptions of the columns present in the AMICO-KiDS-DR4 galaxy cluster catalog.
4. Quality assessment of the cluster sample
The sample purity and selection function are derived from the analysis of mock data using the data-driven approach implemented in the Selection Function extrActor (SINFONIA) code. This method has been previously employed by Maturi et al. (2019) to characterize the AMICO-KiDS-DR3 cluster sample and is currently used as a part of the Euclid cluster pipeline. The core methodology of SINFONIA relies on a Monte Carlo approach, using the probabilistic galaxy memberships provided by AMICO to generate a mock galaxy catalog that distinguishes between field galaxies and cluster members. This is done by reproducing the survey properties, such as the actual masks, galaxy density, photometry and photo-zs.
After generating the mock galaxy sample, the procedure involves running the detection algorithm on the mock data and comparing the resulting detections to the “true” clusters in the mock galaxy catalog. This comparison is used to derive the statistical properties of the sample, such as purity, completeness, and the uncertainties associated with the key quantities characterizing the cluster detections. This data-driven approach avoids the need for numerical simulations, which often fail to capture the full complexity of the data and can introduce biases due to the cosmological and astrophysical assumptions they rely on.
In this work, we have significantly enhanced the SINFONIA code, achieving an acceleration by nearly a factor of 10. Additionally, we introduced new features, including mock clusters with an ellipsoidal shape and an additional Monte Carlo extraction method used to select the properties of the mock clusters to be generated (see Sects. 4.2 and 4.3 for details).
4.1. Stacks of mock cluster members
Before generating the actual mock clusters, we randomly extract galaxies based on their probabilistic membership association, Pi(j). A higher value of Pi(j) indicates a larger probability for the i-th galaxy to be selected. Here the i index refers to galaxies, while j refers to the detection with which the galaxy is associated. During this extraction process, we only consider members associated with detections that meet the criteria S/N > 2.5 and MASK_FRAC < 0.25.
The extracted potential cluster members are grouped into bins defined by the redshift and the apparent richness of the parent detection (z, λ). Additionally, the radial distance of each galaxy from the parent detection center is recorded. This setup allows us to populate a mock cluster at a specific redshift z and richness λ by selecting galaxies from the overall population of members belonging to the corresponding (z, λ) bin. The large pool of available members enables the use of fine-grained bins with Δλ = 5 and Δz = 0.01.
In contrast to our previous analysis of KiDS-DR3 data, where bins were defined solely by redshift and richness, the current study introduces an additional refinement by grouping detections into sets of 50 tiles having a similar survey depth. This refinement ensures that the galaxies within each bin exhibit uniform data quality, particularly in terms of photometry and photometric redshifts (deeper tiles have better photometry and photo-zs). Consequently, these bins gain a third dimension, representing the depth of the tiles. These are the bins containing the members used to generate individual realizations of mock clusters.
4.2. Monte Carlo extraction of the properties of the mock clusters
Before extracting the members to generate individual realizations of mock clusters we need first to define their key properties, such as number, position, redshift and richness. There are various way to do that depending on the goal. For instance, if the intention is the quantification of detection blending as a function of angular and/or redshift separation, pairs of clusters with various separations could be generated in the data. Here, we aim at characterizing the sample purity and completeness of the detected clusters across the range of richness they exhibit while preserving the three-dimensional auto-correlation of clusters and their cross-correlation with the field galaxies. To achieve this, the number of mock clusters, visible cluster members (λ), redshifts, and angular positions of the mock clusters are directly derived from the sample of cluster detections identified in KiDS-DR4.
Since not all detections correspond to real clusters, particularly at lower signal-to-noise ratios, we first assessed the probability of each detection being a true cluster. This probability was used to perform the Monte Carlo extraction required to populate the mocks with clusters. To achieve this, we derived the cumulative distribution function (CDF) of detections, sorted according to a quality indicator, namely, the signal-to-noise ratio provided by AMICO. The CDF is computed in distinct redshift intervals to account for potential redshift-dependent variations in the statistics. The resulting CDFs for all considered redshift intervals are shown in Fig. 13. A clear redshift-dependent trend is observed, with the CDFs shifting to higher values of S/N at lower redshifts. However, this trend inverts below z = 0.3, corresponding to the threshold where the properties of photometric redshifts change due to the transition of the 4000 Å break between the g- and r-bands.
 |
Fig. 13. Cumulative distribution function of the number of detections as a function of the signal-to-noise ratio, computed excluding the cluster shot noise contribution. Different colors represent distinct redshift intervals, as labeled. Solid and dashed lines refer to redshift intervals above and below z ∼ 0.3, respectively, near which a noticeable transition in the photo-z properties occurs, as shown in Fig. 12. |
The CDFs, one for each redshift interval zbin, were then employed for the random sampling of detections, with higher signal-to-noise ratios corresponding to higher probabilities, Pextraction = CDF(z, S/N). of being selected. The properties of the extracted detections – such as position, redshift, and richness – serve as the basis for defining the properties of the mock clusters. Conversely, detections that are not selected are labeled as spurious, and the probabilistic memberships of all galaxies associated with them are removed accordingly. At this stage, the probabilistic membership of each galaxy reflects the likelihood that the galaxy belongs to a specific detection, conditional on the probability of that detection being a true cluster. This approach integrates our best understanding of the sample while eliminating any ambiguity associated with applying a hard signal-to-noise ratio threshold. By considering all detections, including those with very low signal-to-noise ratio values (approaching zero), we ensure a comprehensive and unbiased treatment avoiding any arbitrary cut off in the sample selection.
4.3. Realization of individual mock galaxy clusters
In the previous step, the list of the key properties of clusters and cluster members were defined. Next we describe the generation of individual realizations of mock clusters by finalizing their final properties such as position, redshift, richness, actual members, and ellipsoidal shape.
The apparent richness, λ, remains unchanged to ensure consistency with the probabilistic memberships used in the process, maintaining a statistically compatible number of galaxies (field and cluster members combined) with the original catalog. Only the angular sky positions and redshifts are randomly perturbed, with displacements drawn from flat distributions: a maximum displacement of ΔR = 250 kpc/h (consistent with the typical core radius of detected clusters) and a maximum of Δz = 0.03 (three times the redshift resolution of AMICO). These limits allow nearby clusters to nearly overlap without erasing their spatial correlations. The angular diameter distance used to calculate physical separations on the sky assumes the ΛCDM cosmology defined in the Introduction. The exact cosmology is not critical here since the perturbations serve only to slightly reshuffle cluster positions while preserving their auto-correlation and the correlation with the large scale structure. Throughout the whole process, survey masks are carefully preserved. If the redshift reshuffling results in an empty redshift-richness bin, SINFONIA begins an alternate search, prioritizing redshift first and then richness, to find a bin populated with cluster members. If no populated bin is found after 5 iterations per dimension, resulting in a total of 25 attempts, the cluster is not generated. This occurred in only 9% of the mock tiles and for a few clusters per mock tile.
In Fig. 14, we show the deviation in the number of galaxies per tile between the original dataset and the corresponding mocks. The fluctuations around zero are due to the Monte Carlo process used to extract both field galaxies and cluster members. The tiles with the largest negative deviations correspond to the cases mentioned above where clusters could not be generated. Overall, the maximum deviation is well below 1%, with only three tiles showing deviations exceeding 1.5%. The colors in the figure represent the masked fraction of each tile.
 |
Fig. 14. Deviation with respect to the original dataset of the total number of galaxies (field and member galaxies combined) in each mock tile (including the surrounding buffer area) plotted against the corresponding number of galaxies in the original KiDS data. Colors represent the masked fraction of each tile. |
In addition to position and richness, we assign each cluster an ellipticity for the projected density of its members. This is necessary because mock members are generated by extracting them from stacks that comprise several cluster detections. These detections have uncorrelated intrinsic three-dimensional shapes and orientations. Consequently, if no asymmetry is imposed, the spatial distribution of members within a mock cluster would exhibit circular symmetry. To address this, we applied a coordinate transformation to the members’ sky coordinates using the following Jacobian matrix:
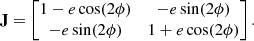 (3)
(3)
This transformation imparts an “ellipsoidal” shape to clusters by adding a trace-free component to a diagonal matrix, analogous to the Jacobian used in gravitational lensing with zero magnification. The position angle ϕ of the major axis is randomly selected, while the projected ellipticity, e ≡ (a − b)/(a + b), is drawn from a distribution that mimics the properties of dark matter halos in N-body simulations (Despali et al. 2017) and are therefore not based on direct measurements from our observational data. Here, a and b represent the major and minor axes of the ellipsoid, respectively.
4.4. Mock field galaxies
Field galaxies are randomly selected from the full KiDS-DR4 galaxy sample based on heir probability of not being associated with any mock cluster. The field probability for the i-th galaxy is calculated as Pifield = 1 − ∑jPi(j), where the index j runs over all detections to which the galaxy is probabilistically associated. A higher value of Pifield corresponds to a larger probability for the galaxy to be extracted and classified as a field galaxy.
Unlike in our previous analysis of KiDS-DR3 data, in this study we do not perturb the angular positions of field galaxies, thus preserving their intrinsic clustering properties. As a result, the three-dimensional correlation of the noise is maintained throughout the process. The randomization of field galaxies naturally emerges from the Monte Carlo extraction based on galaxy memberships, and from the sampling of mock clusters discussed in Sect. 4.2, which influences the field galaxy population as well.
We note that each galaxy can only be extracted once during the generation of field galaxies. However, it can, in principle, be extracted again during the generation of mock clusters. In any case, the galaxy’s final location, when extracted as cluster members, will differ from its original position, as it depends on the location of the mock cluster it is assigned to, along with the additional spatial angular randomization applied within each mock cluster.
4.5. Detection of clusters in the mock data
To evaluate sample purity, completeness, and the scatter of all observable quantities, we ran AMICO on the mock galaxy catalog using the exact same methodology as for the real data. The left panel of Fig. 15 shows the number of detections per tile for real data and mocks, colored according to their signal-to-noise ratio (S/N), while the right panel displays the relative deviation between mocks and real data. There is a 6% excess in the number of detections with high S/N values (S/N > 5.0) in the mocks compared to the real data. At lower S/N values, the number of detections in the mock data is lower than in the real data, with a maximum deviation of 12% for detections in the redshift range 0.35 < z < 0.7. This pattern suggests that larger mock clusters are somewhat easier to detect, whereas the smaller ones are more challenging with respect to those in the real data. Since spurious detections are largely unaffected due to the scheme described in Sect. 4.2, this deviation likely originates from the injected mock clusters. In fact, their generation is influenced by spurious detections and by the overestimation of the radial profile of the P(z) used to extract their members (the probabilistic membership relies on a cluster model assuming a relatively large mass, 1014 M⊙/h), resulting in clusters with a spatial density of galaxies lower than expected.
 |
Fig. 15. Comparison of the number of detections per tile (including the buffer area) in the original and in the mock catalogs. Colors refer to different signal-to-noise ratio thresholds. The left panel displays the absolute numbers, while the right panel shows the relative deviations. |
Despite these deviations, the distribution of counts across all observable quantities is well reproduced, and the full range of redshifts and richness values is adequately covered. This is made evident in Fig. 16, where we show the distribution of detections as a function of several parameters: signal-to-noise ratio for both KiDS-N and KiDS-S stripes, redshift, amplitude, intrinsic richness, and apparent richness. The solid lines represent the distributions for the real data. For completeness, we also show the correlation between A and λ*, which again well matches the one observed in the real data.
 |
Fig. 16. Comparison of the key properties computed in the original AMICO-KiDS-DR4 sample (solid lines) and in the mock sample (solid bars). Different panels show the distributions of signal-to-noise ratio for the entire sample and for both KiDS-N and KiDS-S stripes (top left); redshift, z (top center); amplitude, A (top right); intrinsic richness, λ* (bottom left); and apparent richness, λ (bottom center). The bottom-right panel shows the correlation between A and λ* in the mocks. |
It is important to note that cluster catalogs are typically truncated at S/N thresholds where sample purity and completeness are sufficiently high. For instance, cosmological samples often require high purity (e.g., P > 95%, corresponding to S/N ∼ 4.5). Therefore, in this regime, the mock catalogs effectively resample the data while preserving the expected total number of detections, ensuring consistency with the real data.
4.6. Estimate of the uncertainty of the AMICO observables
We compare now the properties of the detections in the mocks with the corresponding true values to evaluate the scatter of the observables, as well as the sample purity and completeness.
To achieve this, we perform a three-dimensional matching between detections and mock clusters. The matching criteria are an angular distance smaller than ΔR = 0.5 Mpc/h and a redshift difference of Δz = 0.05(1 + z). Additionally, we sort the detections and mock clusters in descending order of apparent richness, prioritizing larger detections for matching with larger clusters. This strategy minimizes confusion with the more abundantlow-richness objects and effectively implements an implicit “soft” matching based on richness, following Maturi et al. (2019). The scatter in redshift, amplitude, intrinsic richness and apparent richness, is presented in the different panels of Fig. 17. For the lowest values of A, λ, and λ*, the sample selection bias, typically affecting samples in the low signal-to-noise regime (where preferentially noise-scattered high estimates are selected), is evident. Where the sample is complete, the intrinsic richness λ* appears unbiased across the full sample, confirming the overall good behavior of the estimates. The apparent richness λ shows instead a slight negative bias at redshifts z > 0.6, while the amplitude A exhibits a trend transitioning from a slight positive to a slight negative bias. In the redshift range 0.6 < z < 0.8, the amplitude bias is negligible. The Malmquist bias, which is caused by the sample selection and not by the detection algorithm, affects estimates close to the detection limit. As expected, all bias contributions are smaller for detections with higher signal-to-noise ratios, where the measurements are inherently more robust. We note that no intrinsic redshift bias can be measured within this approach because the redshifts of the mock clusters are directly based on the original photo-zs, and therefore the scatter is inherently defined in the photo-z space. To estimate the bias, an independent reference redshift catalog, such as the GAMA spectroscopic redshifts discussed in Sect. 3.5, is required.
 |
Fig. 17. Scatter plots comparing the mock measured versus mock true values (e.g., Δλ = λobs − λtrue) of amplitude, A (top-left panels); apparent richness, λ (top-right panels); intrinsic richness, λ* (bottom-left panels); and redshift, z (bottom-right panels). Each analysis is presented for four different bins in redshift, as labeled in each subpanel. The color bars refer to different values of S/N. |
In the left panel of Fig. 18, we show the scatter in redshift for three different S/N bins: the scatter turns out not to depend on the detection significance, with σz/(1 + z)∼0.008. Comparing this result with the spectroscopic measurements given in Sect. 3.5, it appears that this uncertainty is slightly underestimated by the same amount as those based on the detections Pdet(z), which directly rely on the photo-z. Again, this might be due to an underestimation of the photo-z uncertainties of the input galaxies. Even if the difference is not substantial, we recommend the use of the error estimates based on the spec-z, as they rely on independent data.
 |
Fig. 18. Scatter between the observed and true values for redshift in three different bins of S/N (left panel) and for angular and physical separations (central and right panels, respectively) in three different redshift intervals. The dashed lines represent the corresponding best-fit Gaussian and Rayleigh distributions for redshift and radius, respectively. |
The central (right) panel of the same figure displays, for three different redshift intervals, the scatter due to angular (physical) spatial miscentering. The angular displacement is largely determined by the angular resolution of the AMICO sky sampling adopted in this study, which is 0.3 arcmin, and shows a minimal dependence on the cluster redshift. The scatter in angular displacement is σr = 0.19, 0.18, and 0.17 arcmin (0.026, 0.045, and 0.051 Mpc/h) for detections in the redshift intervals 0.1 < z < 0.3, 0.3 < z < 0.6, and 0.6 < z < 0.9, respectively. The dashed lines represent the best-fit Rayleigh distributions for these scatters. Erroneously matched mock clusters contribute to extending the tail visible in these distributions. To better understand and interpret these results, we recall that the mock clusters are modeled with ellipsoidal shapes, lacking any substructure or irregularity. As a result, their centers are better defined compared to real clusters which can have more complex morphologies. Consequently, the positional uncertainties derived here reflect purely algorithmic errors rather than incorporating these additional complexities present in real clusters and, more importantly, the intrinsic ambiguity in the definition of their center.
4.7. Sample purity and selection function
The sample purity is defined as the ratio between the detections with a matched counterpart in the mocks and the total number of detections. This ratio is evaluated in bins of true redshift and different observed properties of the mock clusters. The results are shown in Fig. 19 for amplitude A, intrinsic richness λ*, apparent richness λ, signal-to-noise ratio S/N, and for an alternative definition of the signal-to-noise ratio that excludes the shot noise contribution from cluster members (SN_NO_CLUSTER). For a given fixed value of purity, all observables exhibit a redshift dependence except for SN_NO_CLUSTER. A few isolated points at low observable values, with apparent 100% purity (see the panels referring to λ* and SN_NO_CLUSTER), result from random matches of single detections with mock clusters and should be disregarded. The choice of observable used for selection clearly influences the resulting sample. The choice should be based on the science goal at hand.
 |
Fig. 19. Sample purity derived from the SINFONIA mocks as a function of true redshift and various observables. From left to right, the different panels refer to amplitude, A; intrinsic richness, λ*; observed richness, λ; signal-to-noise ratio, S/N; and signal-to-noise ratio excluding the shot noise contribution from clusters. |
The completeness is defined as the ratio between the detections with a matched counterpart in the mocks and the total number of clusters in the mocks. This ratio is evaluated in bins of true redshift and expected input cluster properties. Completeness is a critical quantity that was initially blinded to preserve the integrity of the cosmological analysis based on this cluster sample (Lesci et al. 2025). Blinding safeguards against subjective influences and ensures the robustness of the derived cosmological constraints. Details on the blinding procedure are provided in Appendix B, and the corresponding selection functions based on λ* for the three blind realizations are shown in Fig. B.1. Now that the cosmological analysis has been completed (Lesci et al. 2025), the unblinding has been carried out, and the true selection function, displayed in the central panel of Fig. B.1, is publicly available.
5. Matching with external catalogs of clusters
We compared our cluster sample, restricted to S/N > 3.5, with three external cluster catalogs: the DES catalog created with RedMaPPer (Rykoff et al. 2016), the eRASS1 X-ray cluster sample produced by the extended ROentgen Survey with an Imaging Telescope Array (eROSITA, Bulbul et al. 2024), and the cluster sample identified via SZ effect in the ACTpol data (Hilton et al. 2021). The comparison is performed over the effective area covered by the KiDS-DR4 data. To match AMICO detections with clusters in the external catalogs, we employed the same geometric matching procedure introduced in Sect. 4.6. This method includes a preliminary sorting step based on the detection significance to ensure that the most significant detections are prioritized. In this case, a maximum redshift discrepancy of Δz = 0.1(1 + z) and a spatial separation of 0.5 Mpc/h are used as matching criteria.
5.1. RedMaPPer cluster catalog
In this section we compare our catalog with the cluster sample identified using the redMaPPer algorithm, which exploits the red sequence of galaxy clusters to detect them in photometric data (Rykoff et al. 2014). This sample spans both the DES Science Verification (SV) and SDSS DR8 photometric datasets, comprising a total of 1055 entries within the KiDS-DR4 effective area in the redshift range 0.1 < z < 0.6. Using the three-dimensional matching approach outlined earlier, we achieve 902 (i.e., 88%) positive matches. The redMaPPer detections with no AMICO counterpart are highlighted in the left panel of Fig. 20 as the red points.
 |
Fig. 20. Left panel: Distribution in the richness-redshift plane of all RedMaPPer detections present in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the RedMaPPer and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Comparison between the RedMaPPer richness, λRM, and the AMICO intrinsic richness, λ*, for the matched objects. Data are color coded according to three different redshift intervals. The dashed line indicates the equality line. |
The central panel of the same figure shows the angular displacement between the RedMaPPer and AMICO detections for three distinct redshift intervals. The distributions feature a σ value for a Rayleigh distribution ranging from 0.29 (at high redshift) to 0.2 arcmin (at low redshift). A tail extending toward larger separations, which is particularly noticeable at lower redshifts, can be observed. This extended tail is likely a result of a different definition adopted for the cluster center: AMICO centers are determined using the spatial distribution of all member galaxies, whereas RedMaPPer centers are defined by the location of the candidate brightest central galaxy (BCG). A detailed analysis of the BCGs identified in our sample will be provided in a dedicated paper (Radovich et al., in prep.).
In the right panel of Fig. 20, we compare the richness estimates provided by the two detection algorithms. The results exhibit a strong correlation across the entire redshift range probed by RedMaPPer and agree well despite their different definitions. This consistency arises because the AMICO intrinsic richness λ* primarily accounts for the brightest member galaxies, which are predominantly the red elliptical galaxies targeted by RedMaPPer.
To better understand the origin of the mismatch between RedMaPPer and AMICO detections at redshifts z < 0.6, we visually inspected KiDS gri color-composite images of the 30 richest AMICO detections that lack an apparent RedMaPPer counterpart. These detections have a minimum richness of λ* ≥ 63.9. Our inspection revealed the following cases:
-
Six RedMaPPer detections are located at nearly identical sky positions to AMICO detections but were not automatically matched due to redshift discrepancies that slighlty exceed the adopted matching tolerance.
-
Four AMICO detections have RedMaPPer counterparts with consistent redshifts, but angular positions that are too distant to satisfy the matching criteria. This mismatch arises from the differing centering strategies of the two algorithms: RedMaPPer aims to identify the central dominant galaxy, but in these cases, it selects a bright, isolated galaxy that is offset from the main galaxy overdensity traced by AMICO.
-
Fourteen detections exhibit a clear overdensity of elliptical galaxies in the KiDS color images but lack a nearby RedMaPPer detection. All are located at z > 0.35, and nearly half (six) lie at z > 0.55, close to the upper redshift limit of the RedMaPPer catalog.
-
Two detections show a galaxy overdensity, but not as prominent as the previous ones. In one case, missing photometric bands prevented the creation of a proper color composite image making visual inspection difficult.
-
Four detections are clearly caused by imaging artifacts. However, they fall within those faulty areas that we manually masked during post-processing and are therefore excluded from our sample (see Sect. 3.2).
We also performed a visual inspection of the 30 RedMaPPer detections without an AMICO counterpart. Our analysis revealed the following:
-
Two RedMaPPer detections have a corresponding AMICO counterpart with consistent sky position but a redshift difference slightly exceeding the matching threshold.
-
Nine clusters have AMICO counterparts at similar redshift but with a larger angular separations up to 2.5′. As in the previous analysis, this is due to the different definition of the cluster centers of the two codes.
-
Three detections correspond to asymmetric clusters composed by two galaxy clumps. In these cases, RedMaPPer and AMICO appear to select different components of the same overall system.
-
Five detections lie within large masked regions of the KiDS data where AMICO does not search for clusters. An additional one falls in a tile rejected due to significant image artifacts.
-
Three RedMaPPer detections do not correspond to obvious galaxy overdensities in the visual inspection. One is centered on a galaxy extremely close to a bright star (RMJ144349.2+011943.0), another lacks any evident overdensity (RMJ084122.4+020707.5), and the third lies in between three AMICO detections, one of which has the same redshift, suggesting possible miscentering issues (RMJ084122.4+020707.5).
-
Eight detections show no AMICO counterpart. Except in one case, the RedMaPPer detections are not that evident in the images but some galaxy overdensity is visible.
In conclusion, the majority of unmatched RedMaPPer detections can be attributed to differences in centering strategies, redshift mismatches near the matching threshold, or the presence of masks and artifacts in the KiDS data which are excluded in our analysis. Only a minority lacks a plausible AMICO counterpart entirely, and in many of those cases, image quality or morphological complexity likely played a role. This analysis reinforces the importance of understanding algorithmic differences when comparing cluster catalogs and accurate sample purity and completeness estimates.
5.2. eRASS1 cluster catalog
The eRASS1 cluster samples (Bulbul et al. 2024) were derived from the first six months of operations of the eROSITA X-ray space telescope (Predehl et al. 2021), as part of the extended ROentgen Survey with an Imaging Telescope Array (eRASS1), and processed by the German eROSITA Consortium (eROSITA-DE, Merloni et al. 2024). eROSITA operates in the energy range 0.2 to 8 keV, focusing on a uniform all-sky flux limit of F0.5 − 2 keV > 5 × 10−14 erg s−1 cm−2. Cluster candidates were primarily identified in the 0.2 − 2.3 keV band, which is the eROSITA’s most sensitive spectral range. These X-ray detections are limited to half of the sky that is accessible to the eROSITA-DE Consortium: this overlaps nearly all of the KiDS-N stripe and approximately 65% of the KiDS-S stripe. The missing parts fall within the sky area managed by the Russian eROSITA-RU Consortium or in the Galactic equatorial stripe, which was excluded from the X-ray analysis. Two main cluster samples were produced: the “cosmological” and “primary” catalogs.
The “cosmological” sample of eRASS1 contains 5258 detections, of which 224 overlap the effective area of KiDS-DR4. Using the automated matching criteria described above, 91% of these X-ray detections (corresponding to 204 objects) were successfully matched to an AMICO cluster. For the remaining X-ray detections without an AMICO counterpart, a visual inspection of KiDS gri color-composite images revealed the following:
-
Three detections correspond to regions without any evident overdensity of galaxies, with one X-ray detection possibly caused by the presence of an active galactic nucleus.
-
Two detections contain two distinct visible galaxy overdensities. In both cases, one of the two overdensities is very near the X-ray detection center, but AMICO assigned as the center the other overdensity, located outside the matching radius. Increasing the matching radius to 1 Mpc/h would have resolved these mismatches.
-
Two detections have clear AMICO counterparts just outside the matching radius.
-
Six detections are near the edges of large regions which are masked because of the presence of bright stars and star halos. For this reason, they are not found by AMICO.
-
Seven detections correspond to low-redshift clusters (0.12 < z < 0.17) where the poor photo-z quality led to missed identifications by AMICO.
This analysis emphasizes the high correspondence between the X-ray-based eRASS1 clusters and the optically detected AMICO clusters, particularly at higher redshifts, where the photo-z accuracy improves.
We also performed the matching with the eRASS1 ‘primary’ cluster sample, which comprises 12 247 clusters. Of these, 10 020 objects lie within the redshift interval 0.05 < z < 1 and have a non-zero X-ray luminosity. Similarly to the “cosmological” sample, we selected only objects inside the KiDS-DR4 effective area, yielding 409 clusters. Of these, 321, i.e. 78%, are matched to AMICO detections.
The key properties of the matched clusters (including those visually inspected mentioned above) are shown in Fig. 21. In the left panel we show the matched (gray) and not matched (red) eRASS1 detections falling in the KiDS-DR4 area as a function of redshift and mass. The angular scatter between the centers of the X-ray and AMICO detections, shown in the central panel, decreases with increasing redshift: the values of the RMS are σr = 0.45 arcmin for 0.1 < z < 0.3, σr = 0.36 arcmin for 0.3 < z < 0.6 and σr = 0.22 arcmin for 0.6 < z < 0.9.
 |
Fig. 21. Left panel: Distribution in the mass-redshift plane of all eRASS1 primary clusters in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the eRASS1 primary and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Relation between the AMICO intrinsic richness, λ*, and the eRASS1 X-ray derived mass, M500, for the matched objects. Data are color coded according to three different redshift intervals. The dashed line indicates the best-fit scaling relation with γ = 0, and the shaded region indicates the RMS of the points around the best-fit model. |
The right panel of Fig. 21 displays the relationships between the AMICO intrinsic richness, λ*, and the X-ray derived mass, M5002, showing the existence of a strong correlation at all redshifts. Using orthogonal distance regression, we fit a mass–proxy scaling relation (see also Bellagamba et al. 2019; Lesci et al. 2022a):
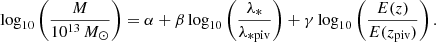 (4)
(4)
Here, E(z)≡H(z)/H0 is computed assuming a flat ΛCDM model with ΩΛ = 0.7, H0 = 70 km/s/Mpc and we set λ*piv = 30 as well as zpiv = 0.35. Assuming no redshift dependence, i.e. γ = 0, the best-fit parameters are α = 0.94 ± 0.03 and β = 1.78 ± 0.10, while leaving γ free we obtain α = 0.91 ± 0.04, β = 1.85 ± 0.12 and γ = −0.7 ± 0.4. The fit accounts for the uncertainties in mass, λ*, and redshift. In both cases, the RMS around the best-fitting model is 0.31 dex. The mass estimates derived using this scaling relation are reported in the final catalog, and are also shown in the right panel of Fig. 21. For simplicity of representation, we plot the scaling relation without accounting for the mild redshift evolution. Notice that here we present the results for the “primary” eRASS1 sample, but for the “cosmological” eRASS1 sample, which is restricted to higher masses, the amount of scatter for all shown quantities is very similar. Mass scaling relations derived from a subset of clusters using KiDS weak gravitational lensing data is presented by Lesci et al. (2025), where both the cosmological parameters and the scaling relation parameters are simultaneously fitted.
5.3. Atacama Cosmology Telescope DR5 cluster sample
The Atacama Cosmology Telescope (ACT) is a single-dish millimetric telescope located in Chile (Swetz et al. 2011; Thornton et al. 2016). The SZ-detected cluster sample was obtained using the Advanced ACTPol receiver mounted on ACT, employing the 98 and 150 GHz channels, which provide beam FWHM values of 2.2 arcmin and 1.4 arcmin, respectively. The detections were identified using a multi-channel optimal matched filter, yielding a sample of 4195 entries having an optical counterpart and a signal-to-noise ratio S/N > 4. This sample covers an area of 13 211 deg2 and spans the redshift range 0.04 < z < 1.91 (Hilton et al. 2021). Among these SZ cluster detections, 267 fall within the KiDS-DR4 effective area and are in the redshift range 0.1 < z < 0.9 covered by our AMICO catalog. Of these SZ detections, 235 have an AMICO counterpart, corresponding to a matching fraction of 88%. Considering separate redshift intervals 0.1 < z < 0.3, 0.3 < z < 0.7, and 0.7 < z < 0.9, the recovery fractions are 83%, 92%, and 78%, respectively. By relaxing the angular constraints from 0.5 Mpc/h to 1 Mpc/h, the number of matched clusters increases to 244, resulting in a recovery fraction of 91% over the entire redshift range 0.1 < z < 0.9, and 92%, 95%, and 80% for the intervals 0.1 < z < 0.3, 0.1 < z < 0.7, and 0.7 < z < 0.9, respectively. The reduction in sensitivity in the highest redshift bin is primarily due to the limited number of galaxies observable beyond z > 0.8, where the sample depth reaches m* + 1.5 (see Sect. 3.2). Despite the reduced sensitivity, AMICO remains effective at detecting significant structures thanks to its optimal filtering approach, which assigns higher weights to intrinsically brighter galaxies, such as the brightest group galaxies. These luminous galaxies, detectable even at high redshifts, serve as reliable tracers of galaxy clusters. Their large weight in the filtering scheme enhances the likelihood of identifying genuine overdensities, even under limited sensitivity.
We show the matched (gray) and not matched (red) ACT detections falling in the KiDS-DR4 area as a function of redshift and mass M2003 in the left panel of Fig. 22. The σ parameters of the Rayleigh distribution fitting the angular displacement between the ACT SZ sample and AMICO optical detections is σr = 0.39 arcmin, σr = 0.44 arcmin, and σr = 0.43 arcmin for the redshift intervals 0.1 < z < 0.3, 0.3 < z < 0.6, and 0.6 < z < 0.9, respectively, as shown in central panel of the same figure. The differences in these scatters across redshift intervals are primarily due to small-number statistics rather than an intrinsic redshift dependency. The right panel displays the relationships between the AMICO intrinsic richness λ* and the SZ-derived mass M200. Also in this case there is a strong correlation at all redshifts but we prefer not to derive a scaling relation the ACT sample covers a rather small mass interval.
 |
Fig. 22. Left panel: Distribution in the mass-redshift plane of all ACT SZ clusters in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the ACT and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Relation between the AMICO intrinsic richness, λ*, and the ACT SZ-derived mass, M200, for the matched objects. Data are color coded according to three different redshift intervals. |
After visually inspecting all unmatched objects, we identified the following cases:
-
One ACT detection with coordinates just outside a large masked region. While this cluster was retained in the ACT catalog, a significant fraction of its members are masked, then explaining the missing match.
-
Four ACT detections with no visible galaxies in the images, despite their relatively low redshift.
-
Twelve ACT detections that are clearly possible matches but they were not automatically matched because their redshift falls right outside the matching threshold.
We also visually inspected the 30 AMICO detections with the highest intrinsic richness λ* (covering the interval 86 < λ* < 122) that lacked a corresponding ACT counterpart. Of these detections twenty-eight are due to clear galaxy overdensities; one is of dubious origin, being located in one of the tiles with significant artifacts; and one is a spurious detection at the very edge of the survey, caused by a bright star that was not masked in the input data.
6. Conclusions
We used the AMICO algorithm to detect 23 965 galaxy clusters with a signal-to-noise ratio greater than 3.5 in the redshift range 0.1 ≤ z ≤ 0.9 across the effective area of 839 deg2 covered by the KiDS-DR4 dataset. This cluster sample is accompanied by a probabilistic membership association with the AMICO clusters of all KiDS-DR4 galaxies within the magnitude range 15 < r′< 24. Our analysis was optimized for cosmological studies, prioritizing data homogeneity over redshift range or depth.
For each cluster detection, we have provided basic information, including celestial coordinates, redshift, amplitude, apparent richness, intrinsic richness, and two mass estimates based on mass-proxy scaling relations obtained using eRASS1 X-ray data. Mass scaling relations based on a subset of clusters based on the KiDS weak gravitational lensing data will be presented by Lesci et al. (2025). The redshift estimates were calibrated using the GAMA spectroscopic dataset. When available, spectroscopic redshifts were associated with the detections, alongside quality flags and indicators to characterize the reliability of these spectroscopic estimates. These indicators include the number of galaxies with AMICO membership and spectroscopic redshifts, the weighted average of spectroscopic redshifts using AMICO membership probabilities as weights, the median spectroscopic redshift, and the RMS of the weighted average. We have provided cluster redshift uncertainties based on photo-zs as well as on the estimated scatter with respect to the spectroscopic redshifts.
We conducted an extensive evaluation of detections near tile borders and masks to identify potential issues. We also enhanced AMICO with additional features, including a probability redshift distribution, Pdet(z), for each detection, from which we derived the 67th percentile redshift uncertainties and ODDS values analogous to the BPZ galaxy photo-zs; a flag distinguishing detections near tile edges with or without a neighboring tile; and a flag identifying detections in tiles with potentially problematic photometry.
The sample’s purity, completeness, and uncertainties in observable quantities (redshift, angular position, amplitude, apparent richness, and intrinsic richness) were evaluated using the SINFONIA. SINFONIA is a data-driven method that constructs mock galaxy catalogs while preserving the statistical properties of the original dataset. These mocks were then processed with AMICO to evaluate the aforementioned quantities. In this study, we further enhanced SINFONIA by incorporating mock clusters with ellipsoidal shapes, an improved mask-treatment scheme, and probabilistic weighting to better represent the likelihood of detections being real clusters in the mock generation process. This latter feature eliminates any arbitrariness associated with signal-to-noise ratio cutoffs when selecting detections to produce the mock clusters. By deriving sample purity and completeness without relying on numerical simulations, we mitigated biases and model dependencies in astrophysical and cosmological analyses of the cluster sample. Additionally, we implemented a blinding scheme for the selection function, introducing perturbations to shift cosmological parameter estimates based on cluster counts in a controlled way. Three realizations of the perturbed selection function were stored, and the key identifying the original unperturbed version has been released following the completion of the cosmological analysis of this sample.
Additionally, we cross-matched the AMICO-KiDS-DR4 cluster sample with external datasets, namely the RedMaPPer, X-ray eRASS1, and ACT-POL cluster samples, considering only detections falling within the KiDS-DR4 effective area. For RedMaPPer, limited to 0.1 < z < 0.6, we found a 88% matching rate with AMICO clusters. Angular displacements between matched clusters show a “compact core” with a tail extending to larger separations, likely due to differing center definitions. The RedMaPPer centers are in fact based on individual bright galaxies, while the AMICO centers are based on the overall associated members. Richness estimates correlate strongly with AMICO’s λ* and align well with RedMaPPer’s values, as both estimates are driven by the brightest cluster galaxies. In the cross-match with the X-ray eRASS1 “primary” cluster sample, we identified 321 matches (78% of the sample) within the KiDS-DR4 effective area. The eRASS1 sample includes M500 estimates, which strongly correlate with the AMICO intrinsic richness, λ*.
We provide a mass-proxy scaling relation based on λ* and conducted a visual inspection of the brightest eRASS1 sources without an AMICO counterpart. This inspection indicates that three unmatched sources may be X-ray point sources (active galactic nuclei) misclassified as clusters rather than galaxy clusters, two cases are due to bimodal galaxy distributions causing different centers, two detections have AMICO counterparts just outside the matching radius, six are missed by AMICO because next to masked areas, and seven are missed due to their low redshifts (0.12 < z < 0.17), where photo-z quality is poor. In the other cases, no galaxy overdensity is visible in the images. A similar analysis was performed for the ACT-DR5 SZ cluster sample, yielding a positive match for 88% of its clusters across the redshift range covered by KiDS-DR4 and 93% over the range 0.3 < z < 0.7, where the AMICO efficiency is the highest. This new KiDS-DR4 galaxy cluster sample represents a valuable resource for investigating the fundamental properties of galaxy clusters and advancing cosmological studies.
Data availability
The photometric galaxies catalog and the masks of the KiDS-DR4 survey are publicly available as explained in the KiDS web portal4.
The AMICO-KIDS-DR4 cluster sample, probabilistic memberships, sample purity, and selection function will be made publicly available on the KiDS data products web portal but can already be obtained on request, after evaluation. Please contact the lead author.
Here, R200 is the radius within which the average density of a halo is 200 times the critical density of the universe.
Here, M500 is the mass included inside a radius within which the average density of a halo is 500 times the critical density of the universe.
Here, M200 is the mass included inside a radius within which the average density of a halo is 200 times the critical density of the universe.
Acknowledgments
The KiDS-1000 results in this paper are based on data products from observations made with ESO Telescopes at the La Silla Paranal Observatory under programme IDs 177.A-3016, 177.A-3017 and 177.A-3018, and on data products produced by Target/OmegaCEN, INAF-OACN, INAF-OAPD, and the KiDS production team, on behalf of the KiDS consortium. LM acknowledges the financial contribution from the PRIN-MUR 2022 20227RNLY3 grant “The concordance cosmological model: stress-tests with galaxy clusters” supported by Next Generation EU and from the grant ASI n. 2024-10-HH.0 “Attività scientifiche per la missione Euclid – fase E”. GC acknowledges the support from the Next Generation EU funds within the National Recovery and Resilience Plan (PNRR), Mission 4 – Education and Research, Component 2 – From Research to Business (M4C2), Investment Line 3.1 – Strengthening and creation of Research Infrastructures, Project IR0000012 – “CTA+ – Cherenkov Telescope Array Plus”. MR acknowledges financial support from the INAF mini-grant 2022 “GALCLOCK”. BG acknowledges support from the UKRI Stephen Hawking Fellowship (grant reference EP/Y017137/1). HH is supported by a DFG Heisenberg grant (Hi 1495/5-1), the DFG Collaborative Research Center SFB1491, an ERC Consolidator Grant (No. 770935), and the DLR project 50QE2305. SJ acknowledges the Dennis Sciama Fellowship at the University of Portsmouth and the Ramón y Cajal Fellowship from the Spanish Ministry of Science.
References
- Abbott, T. M. C., Abdalla, F. B., Alarcon, A., et al. 2018, Phys. Rev. D, 98, 043526 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, T. M. C., Aguena, M., Alarcon, A., et al. 2020, Phys. Rev. D, 102, 023509 [Google Scholar]
- Artis, E., Bulbul, E., Grandis, S., et al. 2025, A&A, 696, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bellagamba, F., Roncarelli, M., Maturi, M., & Moscardini, L. 2018, MNRAS, 473, 5221 [NASA ADS] [CrossRef] [Google Scholar]
- Bellagamba, F., Sereno, M., Roncarelli, M., et al. 2019, MNRAS, 484, 1598 [Google Scholar]
- Bellstedt, S., Driver, S. P., Robotham, A. S. G., et al. 2020, MNRAS, 496, 3235 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [Google Scholar]
- Blake, C., Joudaki, S., Heymans, C., et al. 2016, MNRAS, 456, 2806 [NASA ADS] [CrossRef] [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015, ApJS, 216, 27 [Google Scholar]
- Bocquet, S., Dietrich, J. P., Schrabback, T., et al. 2019, ApJ, 878, 55 [Google Scholar]
- Bulbul, E., Liu, A., Kluge, M., et al. 2024, A&A, 685, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castignani, G., Radovich, M., Combes, F., et al. 2022, A&A, 667, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castignani, G., Radovich, M., Combes, F., et al. 2023, A&A, 672, A139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Conley, A., Goldhaber, G., Wang, L., et al. 2006, ApJ, 644, 1 [Google Scholar]
- Costanzi, M., Villaescusa-Navarro, F., Viel, M., et al. 2013, JCAP, 12, 012 [Google Scholar]
- Costanzi, M., Saro, A., Bocquet, S., et al. 2021, Phys. Rev. D, 103, 043522 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Despali, G., Giocoli, C., Bonamigo, M., Limousin, M., & Tormen, G. 2017, MNRAS, 466, 181 [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Driver, S. P., Bellstedt, S., Robotham, A. S. G., et al. 2022, MNRAS, 513, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Euclid Collaboration (Adam, R., et al.) 2019, A&A, 627, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garrel, C., Pierre, M., Valageas, P., et al. 2022, A&A, 663, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bulbul, E., Artis, E., et al. 2024, A&A, 689, A298 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giocoli, C., Marulli, F., Moscardini, L., et al. 2021, A&A, 653, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giocoli, C., Palmucci, L., Lesci, G. F., et al. 2024, A&A, 687, A79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hennig, C., Mohr, J. J., Zenteno, A., et al. 2017, MNRAS, 467, 4015 [NASA ADS] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Miller, L., et al. 2012, MNRAS, 427, 146 [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Ingoglia, L., Covone, G., Sereno, M., et al. 2022, MNRAS, 511, 1484 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [Google Scholar]
- Kuijken, K. 2011, The Messenger, 146, 8 [NASA ADS] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lesci, G. F., Marulli, F., Moscardini, L., et al. 2022a, A&A, 659, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lesci, G. F., Nanni, L., Marulli, F., et al. 2022b, A&A, 665, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lesci, G. F., Marulli, F., Moscardini, L., et al. 2025, A&A, submitted [arXiv:2507.14285] [Google Scholar]
- Liske, J., Baldry, I. K., Driver, S. P., et al. 2015, MNRAS, 452, 2087 [Google Scholar]
- Maccoun, R., & Perlmutter, S. 2015, Nature, 526, 187 [Google Scholar]
- Maturi, M., Meneghetti, M., Bartelmann, M., Dolag, K., & Moscardini, L. 2005, A&A, 442, 851 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maturi, M., Bellagamba, F., Radovich, M., et al. 2019, MNRAS, 485, 498 [Google Scholar]
- Maturi, M., Finoguenov, A., Lopes, P. A. A., et al. 2023, A&A, 678, A145 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Muir, J., Bernstein, G. M., Huterer, D., et al. 2020, MNRAS, 494, 4454 [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Ota, N., Mitsuishi, I., Babazaki, Y., et al. 2020, PASJ, 72, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Puddu, E., Radovich, M., Sereno, M., et al. 2021, A&A, 645, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Radovich, M., Tortora, C., Bellagamba, F., et al. 2020, MNRAS, 498, 4303 [NASA ADS] [CrossRef] [Google Scholar]
- Romanello, M., Marulli, F., Moscardini, L., et al. 2024, A&A, 682, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Rykoff, E. S., Rozo, E., Hollowood, D., et al. 2016, ApJS, 224, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. 1976, ApJ, 203, 297 [Google Scholar]
- Seppi, R., Comparat, J., Ghirardini, V., et al. 2024, A&A, 686, A196 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sereno, M., Ettori, S., Lesci, G. F., et al. 2020, MNRAS, 497, 894 [NASA ADS] [CrossRef] [Google Scholar]
- Smit, M., Dvornik, A., Radovich, M., et al. 2022, A&A, 659, A195 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Suyu, S. H., Bonvin, V., Courbin, F., et al. 2017, MNRAS, 468, 2590 [Google Scholar]
- Swetz, D. S., Ade, P. A. R., Amiri, M., et al. 2011, ApJS, 194, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Thornton, R. J., Ade, P. A. R., Aiola, S., et al. 2016, ApJS, 227, 21 [Google Scholar]
- Toni, G., Maturi, M., Finoguenov, A., Moscardini, L., & Castignani, G. 2024, A&A, 687, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Troxel, M. A., MacCrann, N., Zuntz, J., et al. 2018, Phys. Rev. D, 98, 043528 [Google Scholar]
- van den Busch, J. L., Wright, A. H., Hildebrandt, H., et al. 2022, A&A, 664, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- von der Linden, A., Mantz, A., Allen, S. W., et al. 2014, MNRAS, 443, 1973 [NASA ADS] [CrossRef] [Google Scholar]
- Wen, Z. L., & Han, J. L. 2015, ApJ, 807, 178 [Google Scholar]
- Wen, Z. L., & Han, J. L. 2021, MNRAS, 500, 1003 [Google Scholar]
- Wen, Z. L., & Han, J. L. 2022, MNRAS, 513, 3946 [NASA ADS] [CrossRef] [Google Scholar]
- Wen, Z. L., & Han, J. L. 2024, ApJS, 272, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, A. H., Hildebrandt, H., Kuijken, K., et al. 2019, A&A, 632, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, A. H., Kuijken, K., Hildebrandt, H., et al. 2024, A&A, 686, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zenteno, A., Mohr, J. J., Desai, S., et al. 2016, MNRAS, 462, 830 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Examples of newly discovered rich clusters
To provide a visual impression of the data quality, Fig. A.1 presents gri-color composite images of newly discovered clusters with intrinsic richness λ* > 60, spanning a broad redshift range. The main properties of these clusters are summarized in Table A.1. To assess whether these clusters were not previously detected in other surveys, we searched for already known clusters within 10′ from the AMICO center in the SIMBAD database5. We further verified that the clusters were not contained in the cluster catalogs6 based on the DESI (Wen & Han 2024), Dark Energy and unWISE (Wen & Han 2022), Subaru Hyper-SuprimeCam and unWISE (Wen & Han 2021), SDSS (Wen & Han 2015) surveys, eRASS1 and ACT. All of them are outside the areas covered by these catalogs, with the exception of 6835: this cluster is within the SDSS footprint, but due to the high redshift (z ∼ 0.8) it was not detected by Wen & Han (2015).
Main properties of the clusters shown in Fig. A.1.
 |
Fig. A.1. Gallery showcasing a selection of newly discovered clusters with λ* > 60. The images are arranged from left to right and top to bottom, following the order of the entries in Table A.1. The cluster center is marked with a green “x”, while cluster members are highlighted with circles, with colors indicating their probabilistic membership. The top-left subpanels provide a zoomed-in view of the central region without overlays. Each postage stamp image covers an area of 7 arcmin per side. |
Appendix B: Blinding for cosmological applications
Blinding is a fundamental practice in cosmological analyses, and in physics more broadly, to mitigate potential observer biases arising from unavoidable subjective choices, such as thresholds for data selection, data binning, etc. (Conley et al. 2006; Heymans et al. 2012; von der Linden et al. 2014; Maccoun & Perlmutter 2015; Kuijken et al. 2015; Blake et al. 2016; Suyu et al. 2017; Hildebrandt et al. 2017; Troxel et al. 2018; Abbott et al. 2018; Ota et al. 2020; Muir et al. 2020). In this work, we implement a blinding strategy based on controlled perturbations of the selection function derived from the matching of true and detected clusters in the SINFONIA mock catalogs (see Sect. 4.7). The selection function plays a pivotal role in modeling cluster counts, which represent one of the most powerful probes to constrain the main cosmological parameters using galaxy clusters.
Our blinding scheme for cosmological analysis, based on cluster counts, involves the following key steps:
-
Halo Ratio Computation: Using the Jenkins et al. (2001) mass function, we compute the ratio of the number of halos as a function of redshift and mass between a reference flat cosmology (h = 0.6736, Ωm = 0.3, S8 = 0.78, σ8 = 0.86) and another flat cosmology with Ωm = 0.3 and S8 randomly drawn from a uniform distribution in the range 0.65 < S8 < 0.91.
-
Mapping to mass proxy: The mass dependence of this "perturbation ratio" is mapped onto the amplitude mass proxy, A, using the scaling relation from Bellagamba et al. (2019), recalibrated for KiDS-DR4 data.
-
Perturbation of the matching: The original matching of detected clusters with S/N < 6.5 is perturbed by applying the "perturbation ratio" in each redshift and amplitude bin, artificially modifying the number of matches. Entries with S/N > 6.5 are left unaffected to preserve the statistical integrity of high signal-to-noise detections, ensuring that an excessive presence or absence of such clusters does not inadvertently reveal the blinding status.
-
Selection function evaluation: We calculate the selection function for the original, unperturbed matching catalog (the "true" selection function) and for two perturbed, blinded matching catalogs (the "blinds"). To mitigate shot noise in the matching counts, particularly for extreme values of richness, we interpolate the selection functions using Chebyshev polynomials of order one and window size of three.
In Fig. B.1, we compare the true, unperturbed selection function with two blinded versions. The solid lines represent the smoothed selection functions, obtained using Chebyshev polynomials and used in the cosmological analysis, while the dashed lines show the corresponding unsmoothed versions. We considered seven redshift intervals spanning the range 0.1 < z < 0.9, but display only four of them not to overcrowd the plots. We considered seven redshift intervals running from 0.1 to 0.9, but we display here only four of them not to overcrowd the plots. The selection function is shown as a function of λ*, the mass proxy used in our cosmological analysis. The true selection function was kept concealed until the completion of the analysis and is now publicly available (central panel of Fig. B.1).
 |
Fig. B.1. Selection function of the AMICO catalog as a function of the intrinsic richness λ* computed in four different redshift intervals, centered in the values reported in the legend. The solid lines represent the smoothed versions derived from Chebyshev polynomials, while the dashed lines refer to the unsmoothed versions. The three panels include the original (central panel) and two blinded versions of the selection function. |
All Tables
List of tiles where the cosmetic artifacts cover an area larger than 5 arcmin2. Tile ID identifies the tile name, whereas Aarti is the area covered by artifacts in square arcminutes.
Descriptions of the columns present in the AMICO-KiDS-DR4 galaxy cluster catalog.
All Figures
|
Fig. 1. Key statistical properties for each individual tile of the KiDS-DR4 dataset. Gray, blue and red histograms refer to the entire dataset, to the KiDS-N and KiDS-S stripes, respectively. The distribution of the survey depth in the r-band, the galaxy number density per arcmin2, and the effective area of each tile are shown in top, central, and bottom panels, respectively. |
| In the text | |
|
Fig. 2. Footprint of KiDS-DR4 data (black area) overlapped by KiDS-DR3 data (gray area), showing the increase in area coverage. For comparison, the RedMaPPer-DES (green crosses), eRASS1 (blue circles) and ACR-DR5 (red points) cluster samples are also shown. |
| In the text | |
|
Fig. 3. Distribution of the area of each tile affected by unmasked image artifacts mainly caused by spurious reflections and ghosts from bright stars located outside the field of view. |
| In the text | |
|
Fig. 4. Fluctuations of the spatial number density of galaxy catalog entries relative to its background rms, farti, for the KiDS_DR4.0_185.0_-0.5 (top left) and KiDS_DR4.0_218.6_2.5 (bottom left) tiles, which are the best and worst tiles listed in Table 1, respectively. The values are shown using a logarithmic scale, shown below the panels. Pixels with farti > 10 are used to create additional masks to identify image artifacts, as displayed in the corresponding right panels. The displayed areas are 1.4 deg on each side. The white square box enclosing most of the area marks the boundary of the survey tile, while the other white contours indicate examples of the handmade polygons enclosing the largest artifacts.
Table 1. List of tiles where the cosmetic artifacts cover an area larger than 5 arcmin2. Tile ID identifies the tile name, whereas Aarti is the area covered by artifacts in square arcminutes. |
| In the text | |
|
Fig. 5. Duplicate detections occurring when merging overlapping survey tiles. Duplicates are identified by a maximum angular separation of ΔR < 1.2 arcmin and a redshift difference of Δz = 0.015(1 + z). The strong correlation between their intrinsic richness (λ*1 and λ*2) confirms that these detections originate from the same structure. The color scale represents their redshift separation. |
| In the text | |
|
Fig. 6. Average properties of detections as a function of their distance from the tile border, ΔR: amplitude, A (top-left panel); signal-to-noise ratio, S/N (top-right panel), apparent richness, λ (bottom left); and intrinsic richness, λ* (bottom right). The results for all detections are shown in black. Those within 5 arcmin of a tile border having a neighboring tile are shown in blue, and those with a missing neighboring tile are shown in red. Most values are insensitive to the tiling scheme, except for λ* near the survey’s external borders and in regions with missing tiles within the overall area. |
| In the text | |
|
Fig. 7. Same as Fig. 6, but as a function of the masked fraction of each detection. All quantities remain stable up to a masked fraction of 0.3, with λ* remaining stable up to 0.4. |
| In the text | |
|
Fig. 8. Main properties of the cluster sample. Top panel: Average number of detections per survey tile as a function of the signal-to-noise ratio for the entire sample (gray histogram) and for the KiDS-N and KiDS-S stripes (blue and red lines, respectively). Central panel: Redshift distribution for five different S/N cutoffs. Bottom panel: Distribution of the masked fraction of detections in different redshift intervals. |
| In the text | |
|
Fig. 9. Left panel: Number density of detections with S/N > 3.5 as a function of the survey tile depth in the r-band. Each point represents an individual tile. Side panel: Probability distribution of the number of detections per tile for the entire sample (gray histogram) and for the KiDS-N and KiDS-S stripes (blue and red lines, respectively). The corresponding values of the mean μ and RMS σ are reported in the legend. The absence of any significant correlation and the Gaussian shape of the number density distributions indicate the homogeneity of the survey clusters detection efficiency when a strict cutoff of r < 24 is applied in the selection of the input galaxy sample. A few outliers are visible, corresponding to tiles with problematic photometry (see their list in Table 1). We excluded from the analysis the tile marked with an “x” (see bottom-left corner). |
| In the text | |
|
Fig. 10. Top panel: Upper and lower 67% percentile limits of the redshift probability distribution, Pdet(z), for each cluster detection. Central panel: Redshift uncertainty derived from the previous percentiles. Bottom panel: ODDS values, where it is possible to notice that a subpopulation of detections in the redshift range 0.5 < z < 0.75 exhibits significantly lower ODDS values compared to the other detections. Data are colored according to their redshift in the upper panel and according to S/N in the other two panels. |
| In the text | |
|
Fig. 11. Distribution of the number of detections as a function of the number of spectroscopic members with a probabilistic membership association greater than 90%. |
| In the text | |
|
Fig. 12. Scatter of the detections’ redshifts obtained with AMICO (based on galaxy photo-zs) with respect to the corresponding spectroscopic redshifts. Left and right panels show the values before and after redshift calibration, respectively. The left panel also displays the associated bias model (red solid line) and the final limits used for the k-sigma clipping (dashed red line). In the right panel, the dashed red lines show the final 1σ uncertainty. |
| In the text | |
|
Fig. 13. Cumulative distribution function of the number of detections as a function of the signal-to-noise ratio, computed excluding the cluster shot noise contribution. Different colors represent distinct redshift intervals, as labeled. Solid and dashed lines refer to redshift intervals above and below z ∼ 0.3, respectively, near which a noticeable transition in the photo-z properties occurs, as shown in Fig. 12. |
| In the text | |
|
Fig. 14. Deviation with respect to the original dataset of the total number of galaxies (field and member galaxies combined) in each mock tile (including the surrounding buffer area) plotted against the corresponding number of galaxies in the original KiDS data. Colors represent the masked fraction of each tile. |
| In the text | |
|
Fig. 15. Comparison of the number of detections per tile (including the buffer area) in the original and in the mock catalogs. Colors refer to different signal-to-noise ratio thresholds. The left panel displays the absolute numbers, while the right panel shows the relative deviations. |
| In the text | |
|
Fig. 16. Comparison of the key properties computed in the original AMICO-KiDS-DR4 sample (solid lines) and in the mock sample (solid bars). Different panels show the distributions of signal-to-noise ratio for the entire sample and for both KiDS-N and KiDS-S stripes (top left); redshift, z (top center); amplitude, A (top right); intrinsic richness, λ* (bottom left); and apparent richness, λ (bottom center). The bottom-right panel shows the correlation between A and λ* in the mocks. |
| In the text | |
|
Fig. 17. Scatter plots comparing the mock measured versus mock true values (e.g., Δλ = λobs − λtrue) of amplitude, A (top-left panels); apparent richness, λ (top-right panels); intrinsic richness, λ* (bottom-left panels); and redshift, z (bottom-right panels). Each analysis is presented for four different bins in redshift, as labeled in each subpanel. The color bars refer to different values of S/N. |
| In the text | |
|
Fig. 18. Scatter between the observed and true values for redshift in three different bins of S/N (left panel) and for angular and physical separations (central and right panels, respectively) in three different redshift intervals. The dashed lines represent the corresponding best-fit Gaussian and Rayleigh distributions for redshift and radius, respectively. |
| In the text | |
|
Fig. 19. Sample purity derived from the SINFONIA mocks as a function of true redshift and various observables. From left to right, the different panels refer to amplitude, A; intrinsic richness, λ*; observed richness, λ; signal-to-noise ratio, S/N; and signal-to-noise ratio excluding the shot noise contribution from clusters. |
| In the text | |
|
Fig. 20. Left panel: Distribution in the richness-redshift plane of all RedMaPPer detections present in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the RedMaPPer and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Comparison between the RedMaPPer richness, λRM, and the AMICO intrinsic richness, λ*, for the matched objects. Data are color coded according to three different redshift intervals. The dashed line indicates the equality line. |
| In the text | |
|
Fig. 21. Left panel: Distribution in the mass-redshift plane of all eRASS1 primary clusters in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the eRASS1 primary and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Relation between the AMICO intrinsic richness, λ*, and the eRASS1 X-ray derived mass, M500, for the matched objects. Data are color coded according to three different redshift intervals. The dashed line indicates the best-fit scaling relation with γ = 0, and the shaded region indicates the RMS of the points around the best-fit model. |
| In the text | |
|
Fig. 22. Left panel: Distribution in the mass-redshift plane of all ACT SZ clusters in the KiDS effective area. Objects with no AMICO counterpart are displayed in red. Central panel: Distribution of the angular displacement between the centers of the matched detections between the ACT and AMICO samples for three different redshift intervals. The best-fit Rayleigh distributions are shown as dashed lines; the values of their corresponding σr are also reported in the legend. Right panel: Relation between the AMICO intrinsic richness, λ*, and the ACT SZ-derived mass, M200, for the matched objects. Data are color coded according to three different redshift intervals. |
| In the text | |
|
Fig. A.1. Gallery showcasing a selection of newly discovered clusters with λ* > 60. The images are arranged from left to right and top to bottom, following the order of the entries in Table A.1. The cluster center is marked with a green “x”, while cluster members are highlighted with circles, with colors indicating their probabilistic membership. The top-left subpanels provide a zoomed-in view of the central region without overlays. Each postage stamp image covers an area of 7 arcmin per side. |
| In the text | |
|
Fig. B.1. Selection function of the AMICO catalog as a function of the intrinsic richness λ* computed in four different redshift intervals, centered in the values reported in the legend. The solid lines represent the smoothed versions derived from Chebyshev polynomials, while the dashed lines refer to the unsmoothed versions. The three panels include the original (central panel) and two blinded versions of the selection function. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.